 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Supervised Domain Adaptation for Diabetic Retinopathy Grading using Vessel Image Reconstruction
Jul 20, 2021
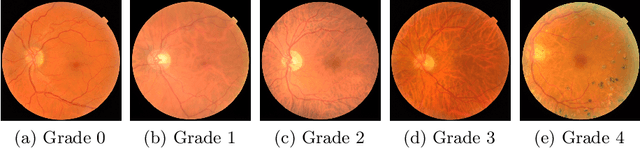
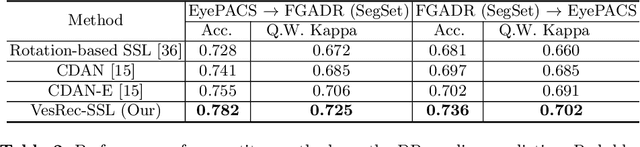
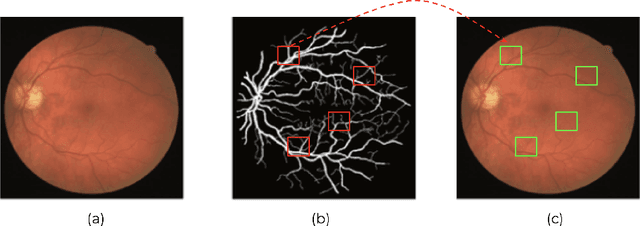
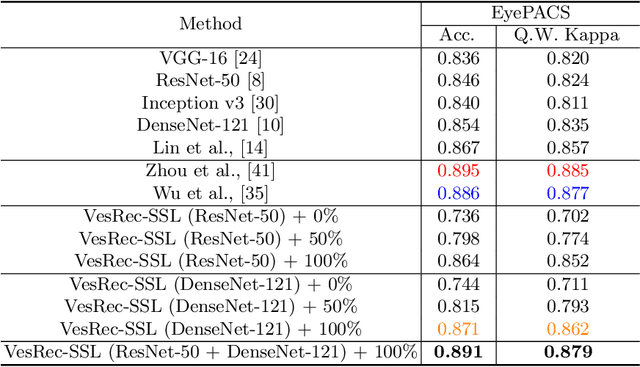
This paper investigates the problem of domain adaptation for diabetic retinopathy (DR) grading. We learn invariant target-domain features by defining a novel self-supervised task based on retinal vessel image reconstructions, inspired by medical domain knowledge. Then, a benchmark of current state-of-the-art unsupervised domain adaptation methods on the DR problem is provided. It can be shown that our approach outperforms existing domain adaption strategies. Furthermore, when utilizing entire training data in the target domain, we are able to compete with several state-of-the-art approaches in final classification accuracy just by applying standard network architectures and using image-level labels.
Transformer-based Personalized Attention Mechanism (PersAM) for Medical Images with Clinical Records
Jun 07, 2022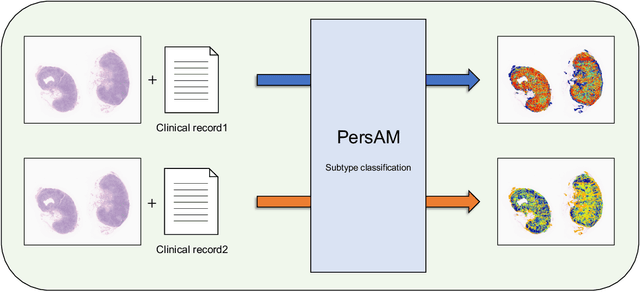
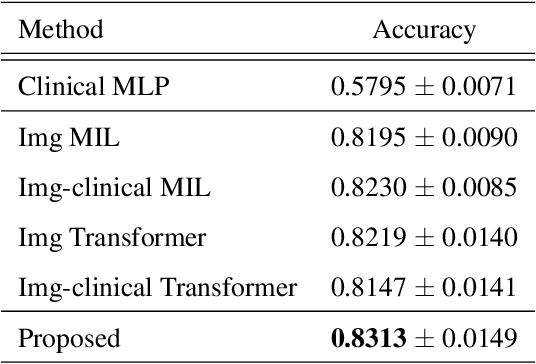
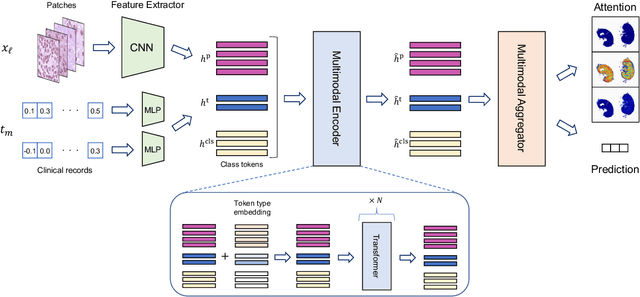
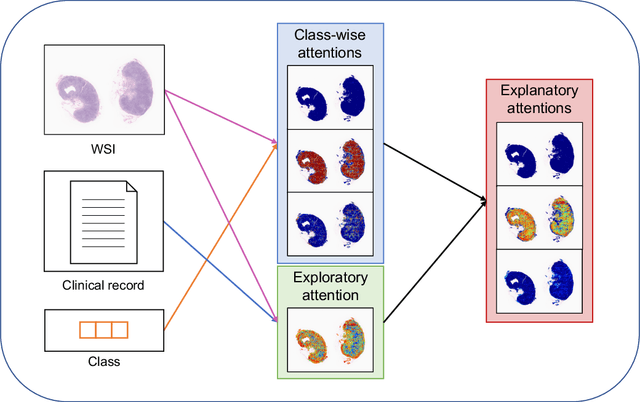
In medical image diagnosis, identifying the attention region, i.e., the region of interest for which the diagnosis is made, is an important task. Various methods have been developed to automatically identify target regions from given medical images. However, in actual medical practice, the diagnosis is made based not only on the images but also on a variety of clinical records. This means that pathologists examine medical images with some prior knowledge of the patients and that the attention regions may change depending on the clinical records. In this study, we propose a method called the Personalized Attention Mechanism (PersAM), by which the attention regions in medical images are adaptively changed according to the clinical records. The primary idea of the PersAM method is to encode the relationships between the medical images and clinical records using a variant of Transformer architecture. To demonstrate the effectiveness of the PersAM method, we applied it to a large-scale digital pathology problem of identifying the subtypes of 842 malignant lymphoma patients based on their gigapixel whole slide images and clinical records.
Precise Aerial Image Matching based on Deep Homography Estimation
Jul 19, 2021

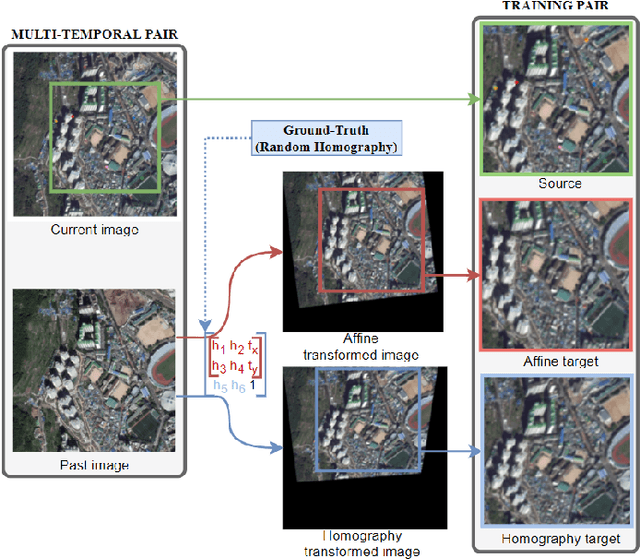
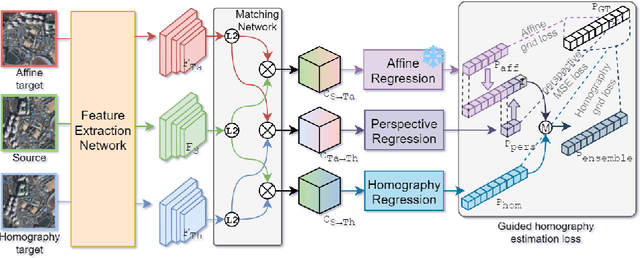
Aerial image registration or matching is a geometric process of aligning two aerial images captured in different environments. Estimating the precise transformation parameters is hindered by various environments such as time, weather, and viewpoints. The characteristics of the aerial images are mainly composed of a straight line owing to building and road. Therefore, the straight lines are distorted when estimating homography parameters directly between two images. In this paper, we propose a deep homography alignment network to precisely match two aerial images by progressively estimating the various transformation parameters. The proposed network is possible to train the matching network with a higher degree of freedom by progressively analyzing the transformation parameters. The precision matching performances have been increased by applying homography transformation. In addition, we introduce a method that can effectively learn the difficult-to-learn homography estimation network. Since there is no published learning data for aerial image registration, in this paper, a pair of images to which random homography transformation is applied within a certain range is used for learning. Hence, we could confirm that the deep homography alignment network shows high precision matching performance compared with conventional works.
Remember What You have drawn: Semantic Image Manipulation with Memory
Jul 27, 2021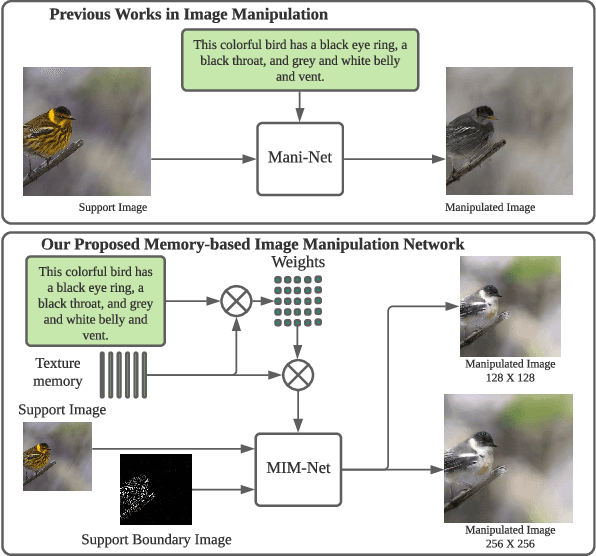
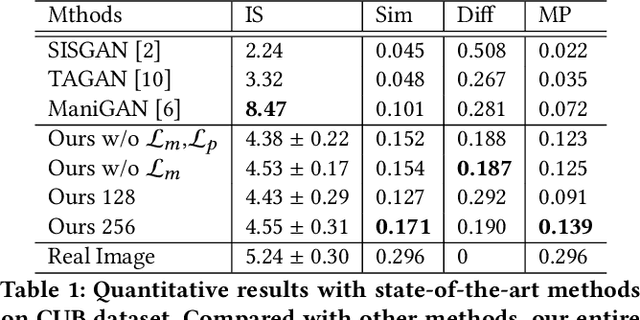


Image manipulation with natural language, which aims to manipulate images with the guidance of language descriptions, has been a challenging problem in the fields of computer vision and natural language processing (NLP). Currently, a number of efforts have been made for this task, but their performances are still distant away from generating realistic and text-conformed manipulated images. Therefore, in this paper, we propose a memory-based Image Manipulation Network (MIM-Net), where a set of memories learned from images is introduced to synthesize the texture information with the guidance of the textual description. We propose a two-stage network with an additional reconstruction stage to learn the latent memories efficiently. To avoid the unnecessary background changes, we propose a Target Localization Unit (TLU) to focus on the manipulation of the region mentioned by the text. Moreover, to learn a robust memory, we further propose a novel randomized memory training loss. Experiments on the four popular datasets show the better performance of our method compared to the existing ones.
A Deep Learning-based Integrated Framework for Quality-aware Undersampled Cine Cardiac MRI Reconstruction and Analysis
May 02, 2022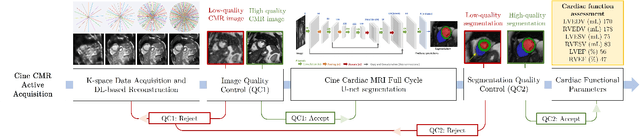

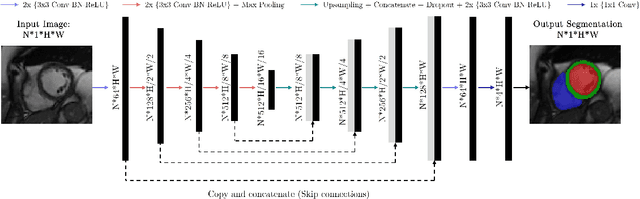
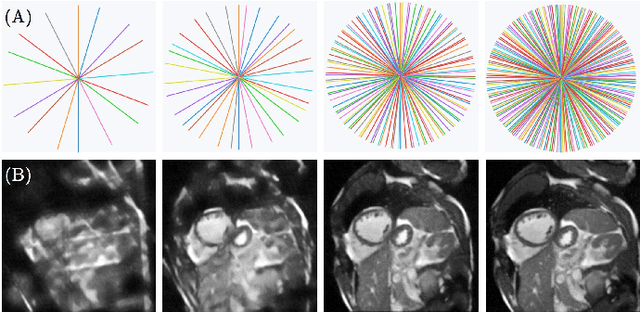
Cine cardiac magnetic resonance (CMR) imaging is considered the gold standard for cardiac function evaluation. However, cine CMR acquisition is inherently slow and in recent decades considerable effort has been put into accelerating scan times without compromising image quality or the accuracy of derived results. In this paper, we present a fully-automated, quality-controlled integrated framework for reconstruction, segmentation and downstream analysis of undersampled cine CMR data. The framework enables active acquisition of radial k-space data, in which acquisition can be stopped as soon as acquired data are sufficient to produce high quality reconstructions and segmentations. This results in reduced scan times and automated analysis, enabling robust and accurate estimation of functional biomarkers. To demonstrate the feasibility of the proposed approach, we perform realistic simulations of radial k-space acquisitions on a dataset of subjects from the UK Biobank and present results on in-vivo cine CMR k-space data collected from healthy subjects. The results demonstrate that our method can produce quality-controlled images in a mean scan time reduced from 12 to 4 seconds per slice, and that image quality is sufficient to allow clinically relevant parameters to be automatically estimated to within 5% mean absolute difference.
Computer Vision for Road Imaging and Pothole Detection: A State-of-the-Art Review of Systems and Algorithms
Apr 28, 2022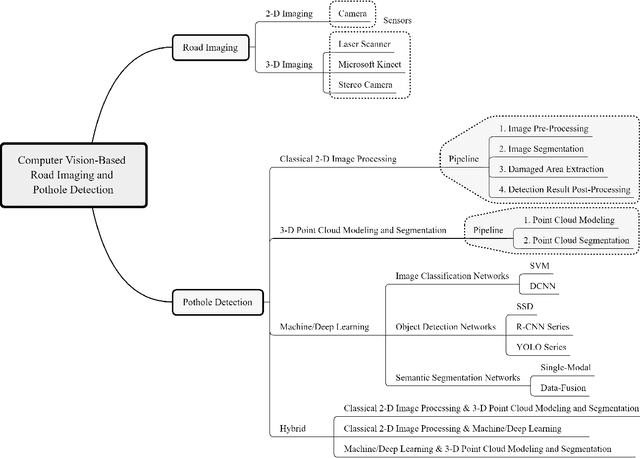
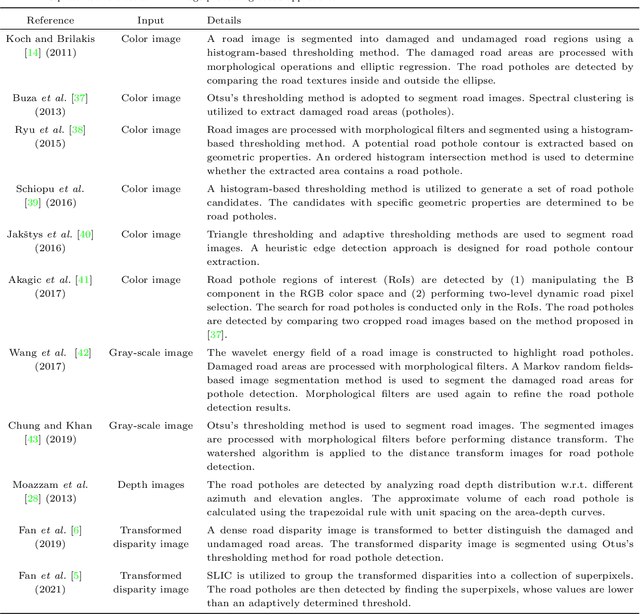

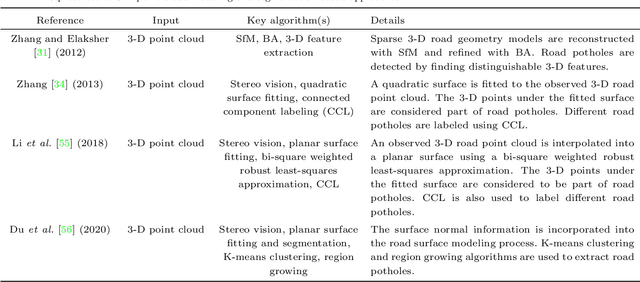
Computer vision algorithms have been prevalently utilized for 3-D road imaging and pothole detection for over two decades. Nonetheless, there is a lack of systematic survey articles on state-of-the-art (SoTA) computer vision techniques, especially deep learning models, developed to tackle these problems. This article first introduces the sensing systems employed for 2-D and 3-D road data acquisition, including camera(s), laser scanners, and Microsoft Kinect. Afterward, it thoroughly and comprehensively reviews the SoTA computer vision algorithms, including (1) classical 2-D image processing, (2) 3-D point cloud modeling and segmentation, and (3) machine/deep learning, developed for road pothole detection. This article also discusses the existing challenges and future development trends of computer vision-based road pothole detection approaches: classical 2-D image processing-based and 3-D point cloud modeling and segmentation-based approaches have already become history; and Convolutional neural networks (CNNs) have demonstrated compelling road pothole detection results and are promising to break the bottleneck with the future advances in self/un-supervised learning for multi-modal semantic segmentation. We believe that this survey can serve as practical guidance for developing the next-generation road condition assessment systems.
Guiding Visual Attention in Deep Convolutional Neural Networks Based on Human Eye Movements
Jun 21, 2022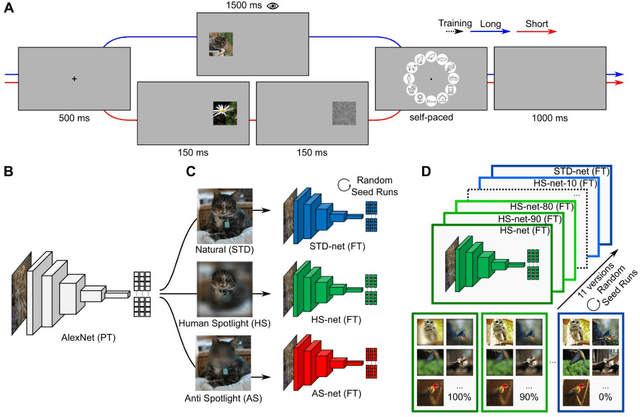
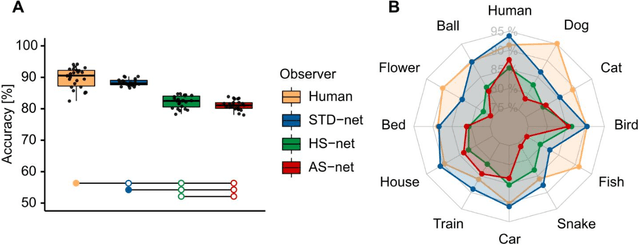
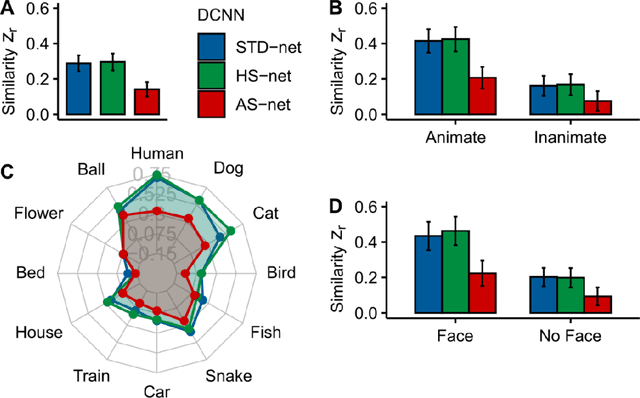
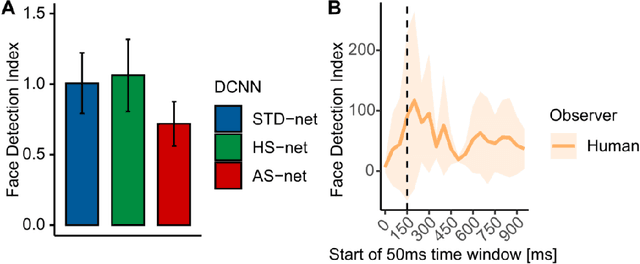
Deep Convolutional Neural Networks (DCNNs) were originally inspired by principles of biological vision, have evolved into best current computational models of object recognition, and consequently indicate strong architectural and functional parallelism with the ventral visual pathway throughout comparisons with neuroimaging and neural time series data. As recent advances in deep learning seem to decrease this similarity, computational neuroscience is challenged to reverse-engineer the biological plausibility to obtain useful models. While previous studies have shown that biologically inspired architectures are able to amplify the human-likeness of the models, in this study, we investigate a purely data-driven approach. We use human eye tracking data to directly modify training examples and thereby guide the models' visual attention during object recognition in natural images either towards or away from the focus of human fixations. We compare and validate different manipulation types (i.e., standard, human-like, and non-human-like attention) through GradCAM saliency maps against human participant eye tracking data. Our results demonstrate that the proposed guided focus manipulation works as intended in the negative direction and non-human-like models focus on significantly dissimilar image parts compared to humans. The observed effects were highly category-specific, enhanced by animacy and face presence, developed only after feedforward processing was completed, and indicated a strong influence on face detection. With this approach, however, no significantly increased human-likeness was found. Possible applications of overt visual attention in DCNNs and further implications for theories of face detection are discussed.
Score-Based Generative Models Detect Manifolds
Jun 02, 2022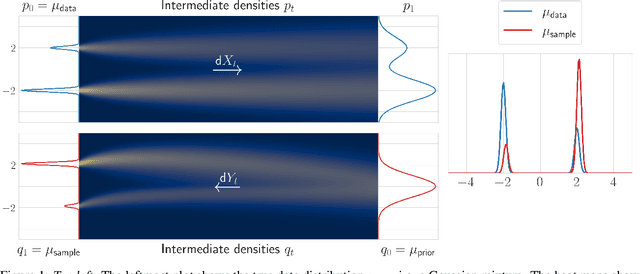
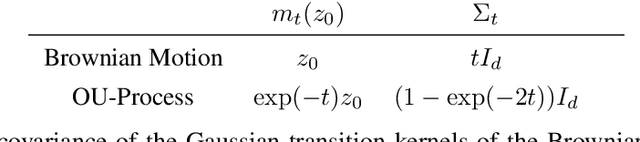


Score-based generative models (SGMs) need to approximate the scores $\nabla \log p_t$ of the intermediate distributions as well as the final distribution $p_T$ of the forward process. The theoretical underpinnings of the effects of these approximations are still lacking. We find precise conditions under which SGMs are able to produce samples from an underlying (low-dimensional) data manifold $\mathcal{M}$. This assures us that SGMs are able to generate the "right kind of samples". For example, taking $\mathcal{M}$ to be the subset of images of faces, we find conditions under which the SGM robustly produces an image of a face, even though the relative frequencies of these images might not accurately represent the true data generating distribution. Moreover, this analysis is a first step towards understanding the generalization properties of SGMs: Taking $\mathcal{M}$ to be the set of all training samples, our results provide a precise description of when the SGM memorizes its training data.
Efficient Stereo Depth Estimation for Pseudo LiDAR: A Self-Supervised Approach Based on Multi-Input ResNet Encoder
May 17, 2022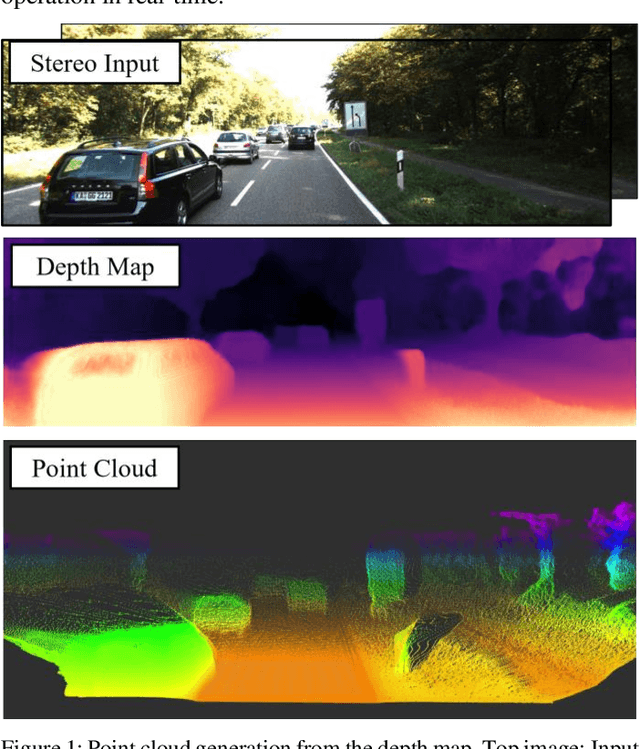

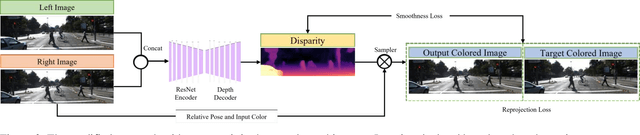
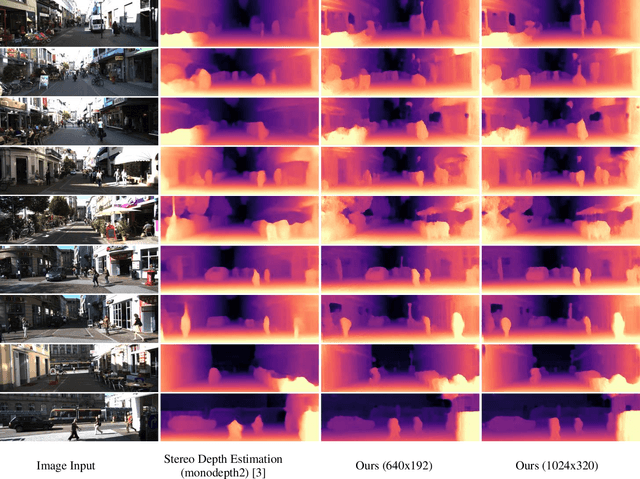
Perception and localization are essential for autonomous delivery vehicles, mostly estimated from 3D LiDAR sensors due to their precise distance measurement capability. This paper presents a strategy to obtain the real-time pseudo point cloud instead of the laser sensor from the image sensor. We propose an approach to use different depth estimators to obtain pseudo point clouds like LiDAR to obtain better performance. Moreover, the training and validating strategy of the depth estimator has adopted stereo imagery data to estimate more accurate depth estimation as well as point cloud results. Our approach to generating depth maps outperforms on KITTI benchmark while yielding point clouds significantly faster than other approaches.
Self-Calibrated Efficient Transformer for Lightweight Super-Resolution
Apr 19, 2022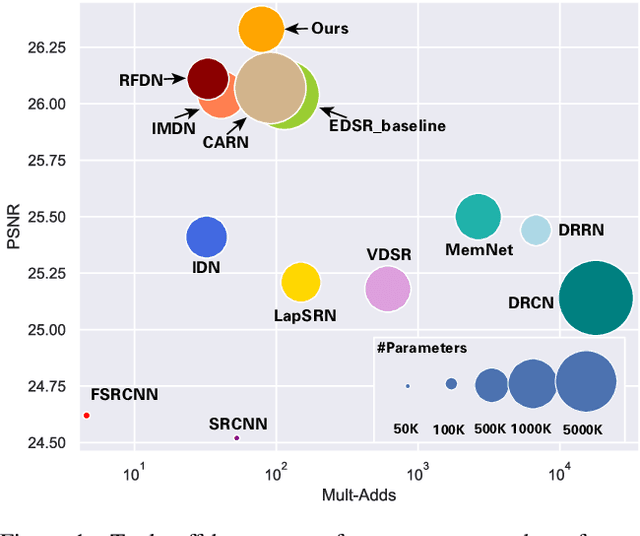
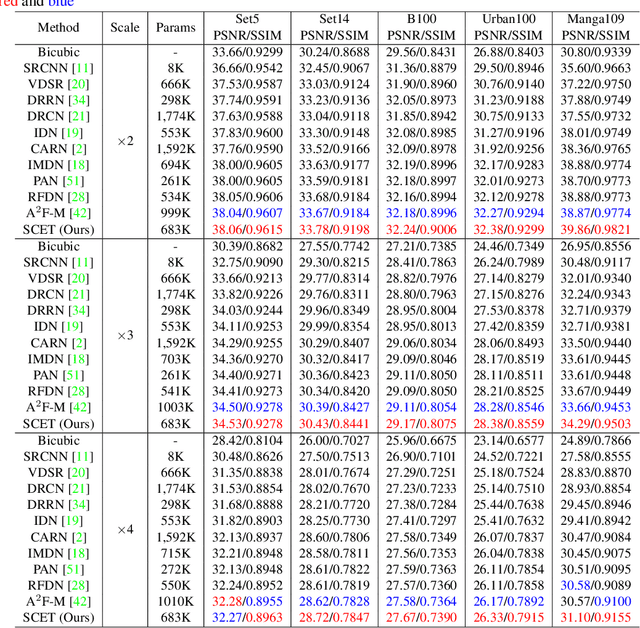
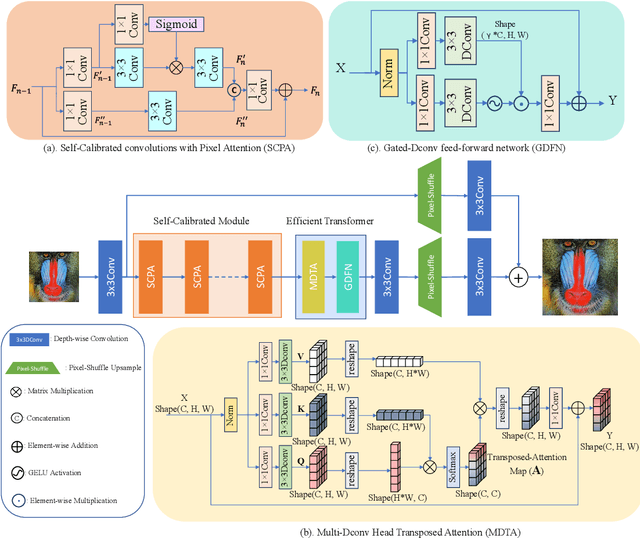
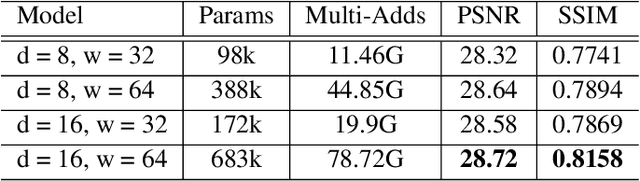
Recently, deep learning has been successfully applied to the single-image super-resolution (SISR) with remarkable performance. However, most existing methods focus on building a more complex network with a large number of layers, which can entail heavy computational costs and memory storage. To address this problem, we present a lightweight Self-Calibrated Efficient Transformer (SCET) network to solve this problem. The architecture of SCET mainly consists of the self-calibrated module and efficient transformer block, where the self-calibrated module adopts the pixel attention mechanism to extract image features effectively. To further exploit the contextual information from features, we employ an efficient transformer to help the network obtain similar features over long distances and thus recover sufficient texture details. We provide comprehensive results on different settings of the overall network. Our proposed method achieves more remarkable performance than baseline methods. The source code and pre-trained models are available at https://github.com/AlexZou14/SCET.