 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End Learned Image Compression with Quantized Weights and Activations
Nov 17, 2021
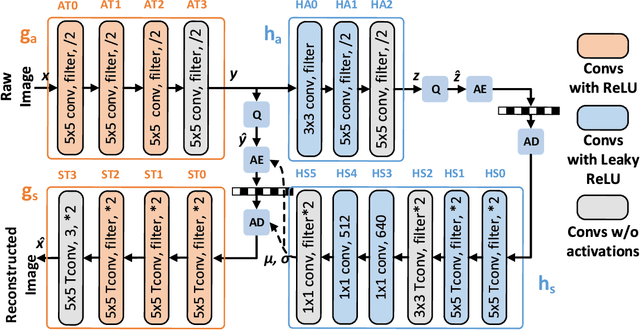

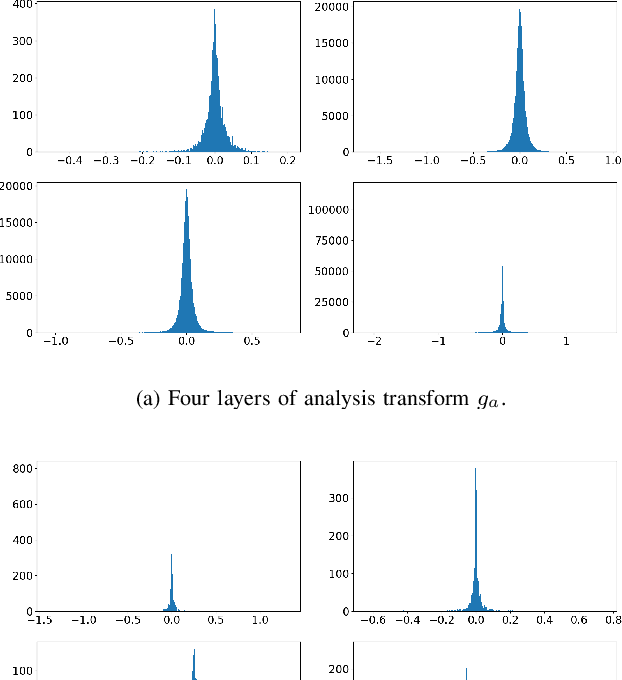
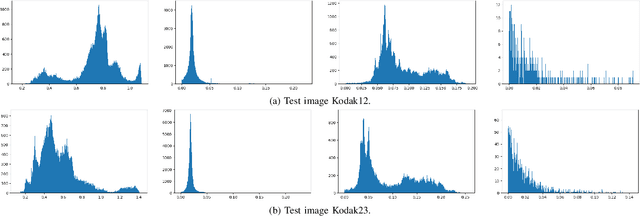
End-to-end Learned image compression (LIC) has reached the traditional hand-crafted methods such as BPG (HEVC intra) in terms of the coding gain. However, the large network size prohibits the usage of LIC on resource-limited embedded systems. This paper reduces the network complexity by quantizing both weights and activations. 1) For the weight quantization, we study different kinds of grouping and quantization scheme at first. A channel-wise non-linear quantization scheme is determined based on the coding gain analysis. After that, we propose a fine tuning scheme to clip the weights within a certain range so that the quantization error can be reduced. 2) For the activation quantization, we first propose multiple non-linear quantization codebooks with different maximum dynamic ranges. By selecting an optimal one through a multiplexer, the quantization range can be saturated to the greatest extent. In addition, we also exploit the mean-removed quantization for the analysis transform outputs in order to reduce the bit-width cost for the specific channel with the large non-zero mean. By quantizing each weight and activation element from 32-bit floating point to 8-bit fixed point, the memory cost for both weight and activation can be reduced by 75% with negligible coding performance loss. As a result, our quantized LIC can still outperform BPG in terms of MS-SSIM. To our best knowledge, this is the first work to give a complete analysis on the coding gain and the memory cost for a quantized LIC network, which validates the feasibility of the hardware implementation.
Text to Image Generation with Semantic-Spatial Aware GAN
Apr 14, 2021
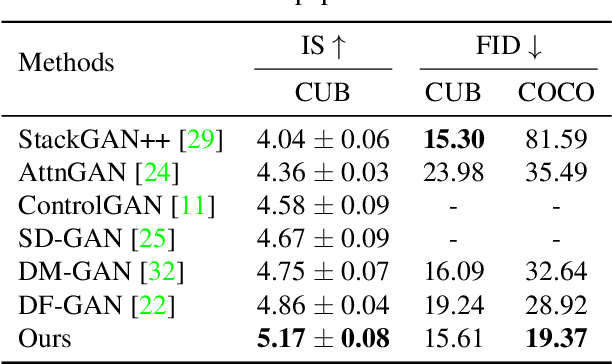


A text to image generation (T2I) model aims to generate photo-realistic images which are semantically consistent with the text descriptions. Built upon the recent advances in generative adversarial networks (GANs), existing T2I models have made great progress. However, a close inspection of their generated images reveals two major limitations: (1) The condition batch normalization methods are applied on the whole image feature maps equally, ignoring the local semantics; (2) The text encoder is fixed during training, which should be trained with the image generator jointly to learn better text representations for image generation. To address these limitations, we propose a novel framework Semantic-Spatial Aware GAN, which is trained in an end-to-end fashion so that the text encoder can exploit better text information. Concretely, we introduce a novel Semantic-Spatial Aware Convolution Network, which (1) learns semantic-adaptive transformation conditioned on text to effectively fuse text features and image features, and (2) learns a mask map in a weakly-supervised way that depends on the current text-image fusion process in order to guide the transformation spatially. Experiments on the challenging COCO and CUB bird datasets demonstrate the advantage of our method over the recent state-of-the-art approaches, regarding both visual fidelity and alignment with input text description. Code is available at https://github.com/wtliao/text2image.
Image Feature Information Extraction for Interest Point Detection: A Comprehensive Review
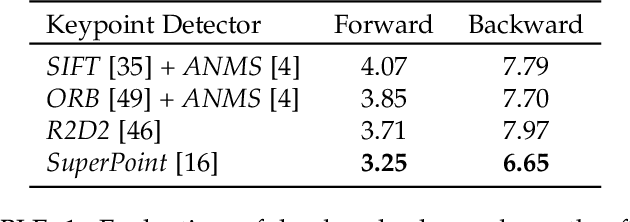
Jun 20, 2021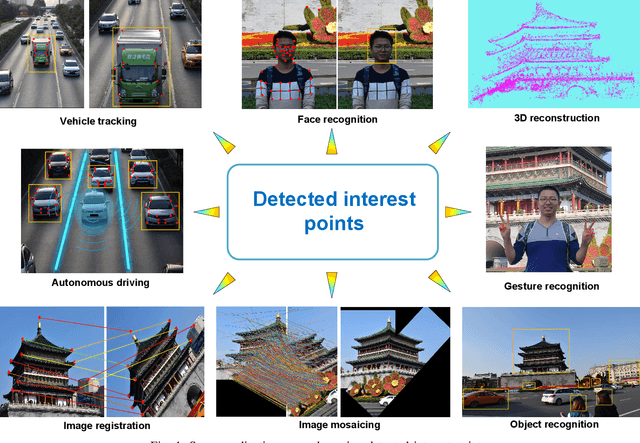
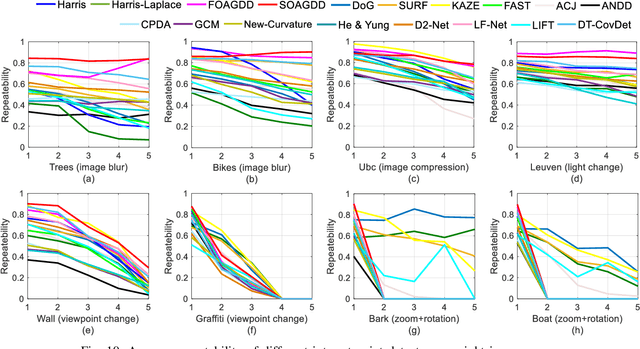

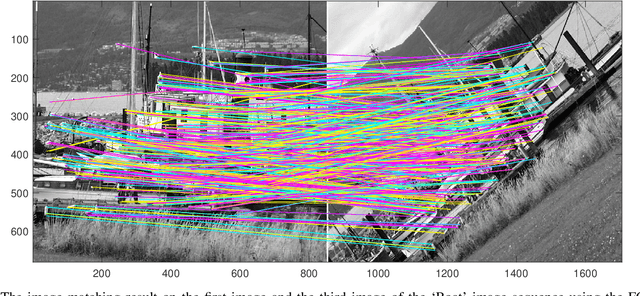
Interest point detection is one of the most fundamental and critical problems in computer vision and image processing. In this paper, we carry out a comprehensive review on image feature information (IFI) extraction techniques for interest point detection. To systematically introduce how the existing interest point detection methods extract IFI from an input image, we propose a taxonomy of the IFI extraction techniques for interest point detection. According to this taxonomy, we discuss different types of IFI extraction techniques for interest point detection. Furthermore, we identify the main unresolved issues related to the existing IFI extraction techniques for interest point detection and any interest point detection methods that have not been discussed before. The existing popular datasets and evaluation standards are provided and the performances for eighteen state-of-the-art approaches are evaluated and discussed. Moreover, future research directions on IFI extraction techniques for interest point detection are elaborated.
From Keypoints to Object Landmarks via Self-Training Correspondence: A novel approach to Unsupervised Landmark Discovery
May 31, 2022
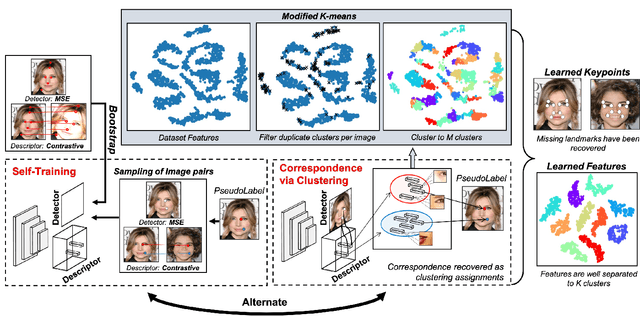
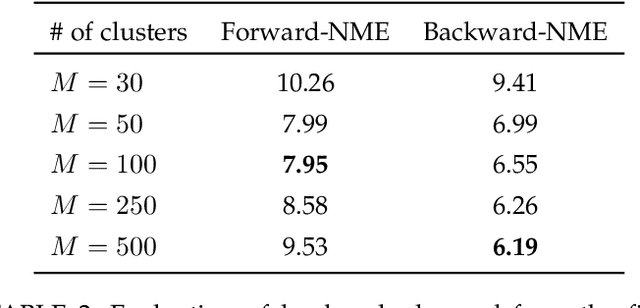
This paper proposes a novel paradigm for the unsupervised learning of object landmark detectors. Contrary to existing methods that build on auxiliary tasks such as image generation or equivariance, we propose a self-training approach where, departing from generic keypoints, a landmark detector and descriptor is trained to improve itself, tuning the keypoints into distinctive landmarks. To this end, we propose an iterative algorithm that alternates between producing new pseudo-labels through feature clustering and learning distinctive features for each pseudo-class through contrastive learning. With a shared backbone for the landmark detector and descriptor, the keypoint locations progressively converge to stable landmarks, filtering those less stable. Compared to previous works, our approach can learn points that are more flexible in terms of capturing large viewpoint changes. We validate our method on a variety of difficult datasets, including LS3D, BBCPose, Human3.6M and PennAction, achieving new state of the art results.
Subspace Representation Learning for Few-shot Image Classification
May 05, 2021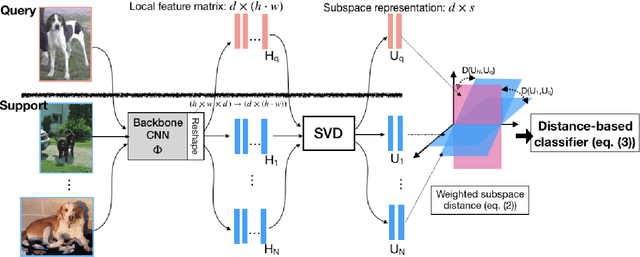
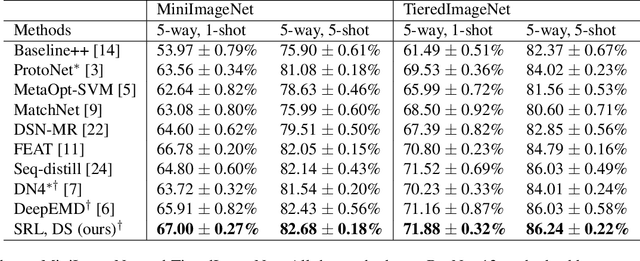
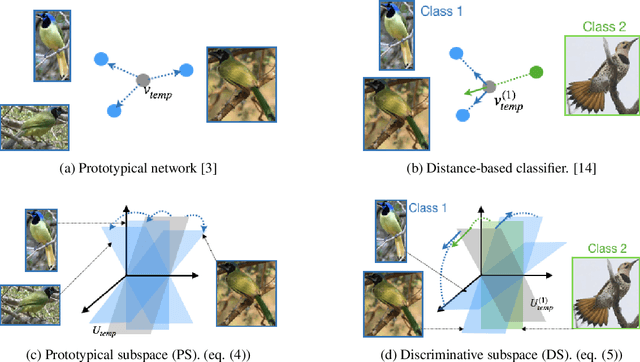
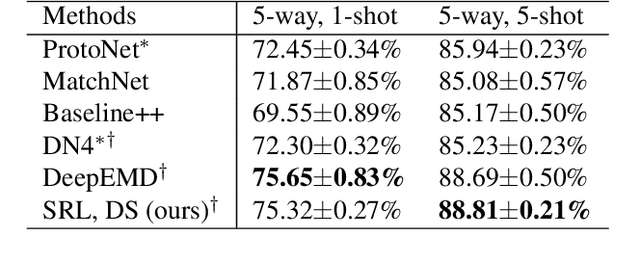
In this paper, we propose a subspace representation learning (SRL) framework to tackle few-shot image classification tasks. It exploits a subspace in local CNN feature space to represent an image, and measures the similarity between two images according to a weighted subspace distance (WSD). When K images are available for each class, we develop two types of template subspaces to aggregate K-shot information: the prototypical subspace (PS) and the discriminative subspace (DS). Based on the SRL framework, we extend metric learning based techniques from vector to subspace representation. While most previous works adopted global vector representation, using subspace representation can effectively preserve the spatial structure, and diversity within an image. We demonstrate the effectiveness of the SRL framework on three public benchmark datasets: MiniImageNet, TieredImageNet and Caltech-UCSD Birds-200-2011 (CUB), and the experimental results illustrate competitive/superior performance of our method compared to the previous state-of-the-art.
Image-Graph-Image Translation via Auto-Encoding
Dec 10, 2020

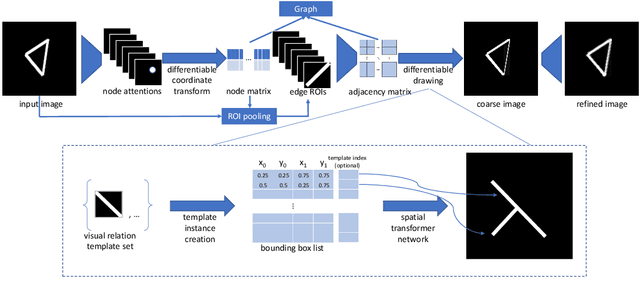
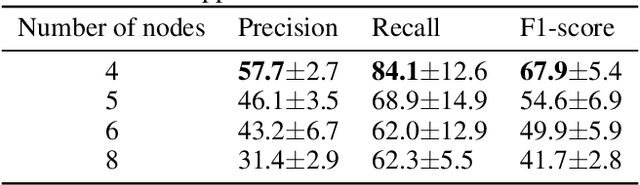
This work presents the first convolutional neural network that learns an image-to-graph translation task without needing external supervision. Obtaining graph representations of image content, where objects are represented as nodes and their relationships as edges, is an important task in scene understanding. Current approaches follow a fully-supervised approach thereby requiring meticulous annotations. To overcome this, we are the first to present a self-supervised approach based on a fully-differentiable auto-encoder in which the bottleneck encodes the graph's nodes and edges. This self-supervised approach can currently encode simple line drawings into graphs and obtains comparable results to a fully-supervised baseline in terms of F1 score on triplet matching. Besides these promising results, we provide several directions for future research on how our approach can be extended to cover more complex imagery.
Interpretable differential diagnosis for Alzheimer's disease and Frontotemporal dementia
Jun 15, 2022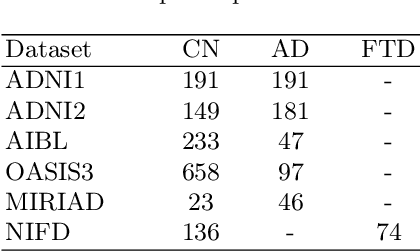
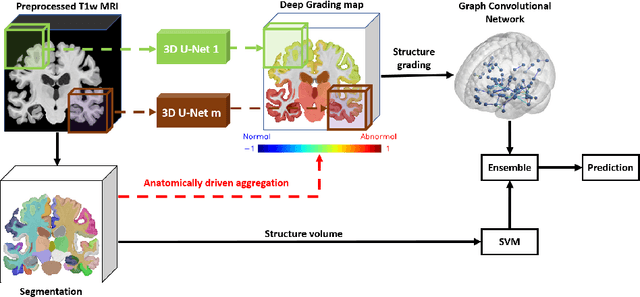
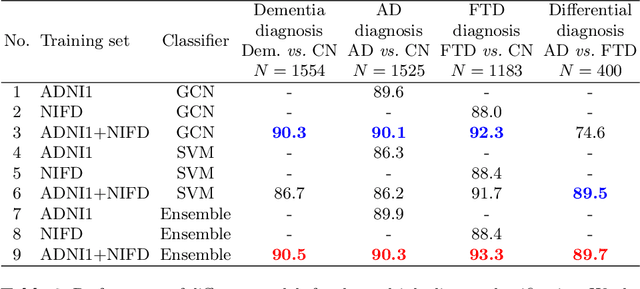
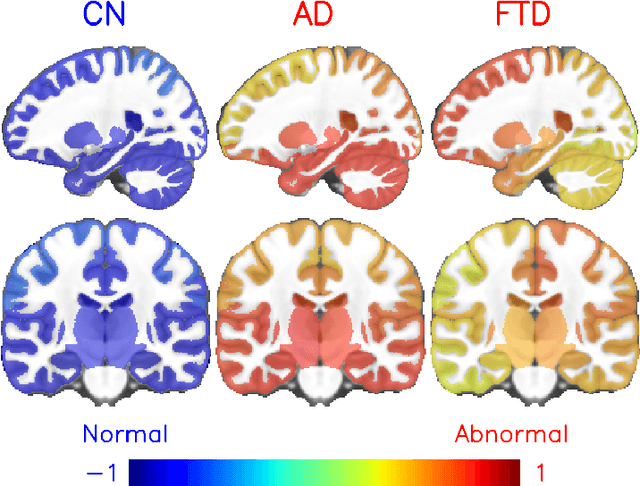
Alzheimer's disease and Frontotemporal dementia are two major types of dementia. Their accurate diagnosis and differentiation is crucial for determining specific intervention and treatment. However, differential diagnosis of these two types of dementia remains difficult at the early stage of disease due to similar patterns of clinical symptoms. Therefore, the automatic classification of multiple types of dementia has an important clinical value. So far, this challenge has not been actively explored. Recent development of deep learning in the field of medical image has demonstrated high performance for various classification tasks. In this paper, we propose to take advantage of two types of biomarkers: structure grading and structure atrophy. To this end, we propose first to train a large ensemble of 3D U-Nets to locally discriminate healthy versus dementia anatomical patterns. The result of these models is an interpretable 3D grading map capable of indicating abnormal brain regions. This map can also be exploited in various classification tasks using graph convolutional neural network. Finally, we propose to combine deep grading and atrophy-based classifications to improve dementia type discrimination. The proposed framework showed competitive performance compared to state-of-the-art methods for different tasks of disease detection and differential diagnosis.
Coupling Visual Semantics of Artificial Neural Networks and Human Brain Function via Synchronized Activations
Jun 22, 2022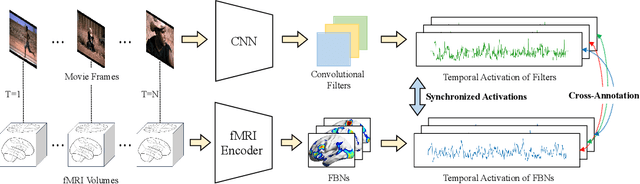
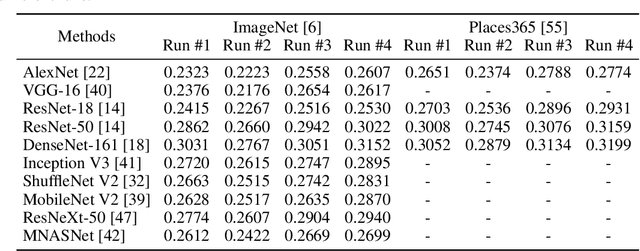
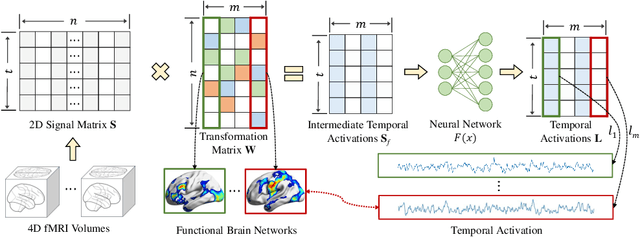
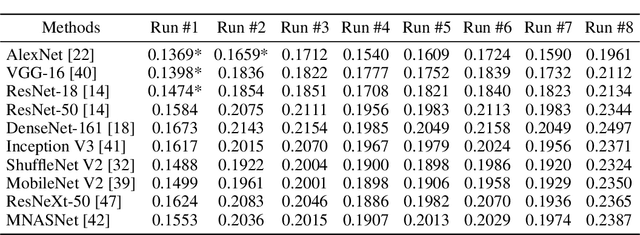
Artificial neural networks (ANNs), originally inspired by biological neural networks (BNNs), have achieved remarkable successes in many tasks such as visual representation learning. However, whether there exists semantic correlations/connections between the visual representations in ANNs and those in BNNs remains largely unexplored due to both the lack of an effective tool to link and couple two different domains, and the lack of a general and effective framework of representing the visual semantics in BNNs such as human functional brain networks (FBNs). To answer this question, we propose a novel computational framework, Synchronized Activations (Sync-ACT), to couple the visual representation spaces and semantics between ANNs and BNNs in human brain based on naturalistic functional magnetic resonance imaging (nfMRI) data. With this approach, we are able to semantically annotate the neurons in ANNs with biologically meaningful description derived from human brain imaging for the first time. We evaluated the Sync-ACT framework on two publicly available movie-watching nfMRI datasets. The experiments demonstrate a) the significant correlation and similarity of the semantics between the visual representations in FBNs and those in a variety of convolutional neural networks (CNNs) models; b) the close relationship between CNN's visual representation similarity to BNNs and its performance in image classification tasks. Overall, our study introduces a general and effective paradigm to couple the ANNs and BNNs and provides novel insights for future studies such as brain-inspired artificial intelligence.
SaiNet: Stereo aware inpainting behind objects with generative networks
May 14, 2022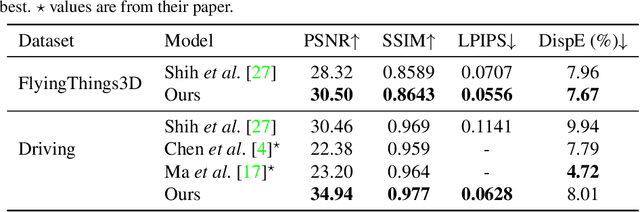
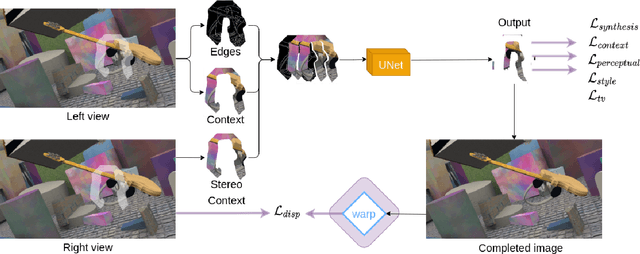


In this work, we present an end-to-end network for stereo-consistent image inpainting with the objective of inpainting large missing regions behind objects. The proposed model consists of an edge-guided UNet-like network using Partial Convolutions. We enforce multi-view stereo consistency by introducing a disparity loss. More importantly, we develop a training scheme where the model is learned from realistic stereo masks representing object occlusions, instead of the more common random masks. The technique is trained in a supervised way. Our evaluation shows competitive results compared to previous state-of-the-art techniques.
Structure-Aware Motion Transfer with Deformable Anchor Model
Apr 11, 2022
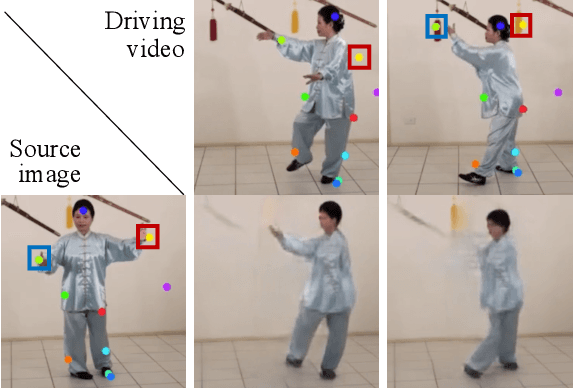

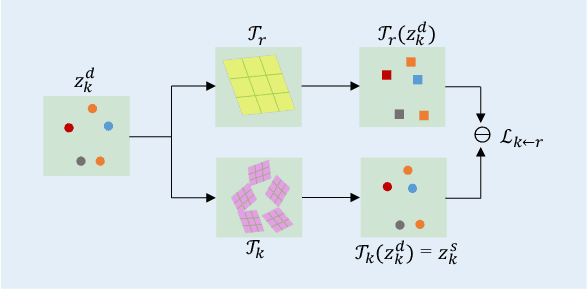
Given a source image and a driving video depicting the same object type, the motion transfer task aims to generate a video by learning the motion from the driving video while preserving the appearance from the source image. In this paper, we propose a novel structure-aware motion modeling approach, the deformable anchor model (DAM), which can automatically discover the motion structure of arbitrary objects without leveraging their prior structure information. Specifically, inspired by the known deformable part model (DPM), our DAM introduces two types of anchors or keypoints: i) a number of motion anchors that capture both appearance and motion information from the source image and driving video; ii) a latent root anchor, which is linked to the motion anchors to facilitate better learning of the representations of the object structure information. Moreover, DAM can be further extended to a hierarchical version through the introduction of additional latent anchors to model more complicated structures. By regularizing motion anchors with latent anchor(s), DAM enforces the correspondences between them to ensure the structural information is well captured and preserved. Moreover, DAM can be learned effectively in an unsupervised manner. We validate our proposed DAM for motion transfer on different benchmark datasets. Extensive experiments clearly demonstrate that DAM achieves superior performance relative to existing state-of-the-art methods.