 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SpectralFormer: Rethinking Hyperspectral Image Classification with Transformers
Jul 07, 2021
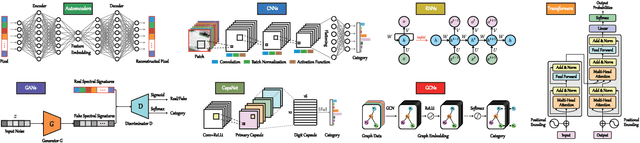
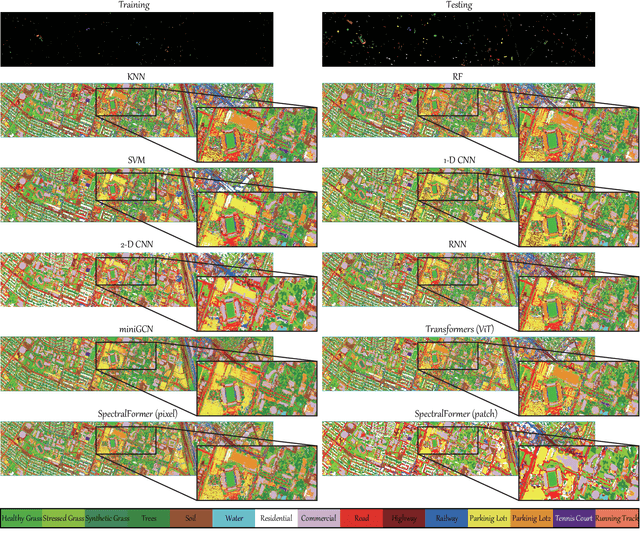
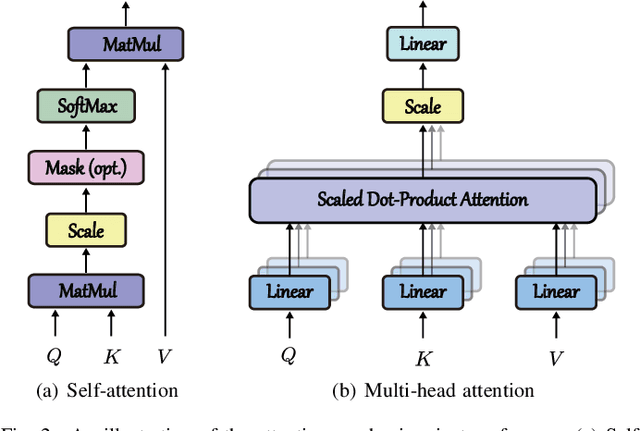
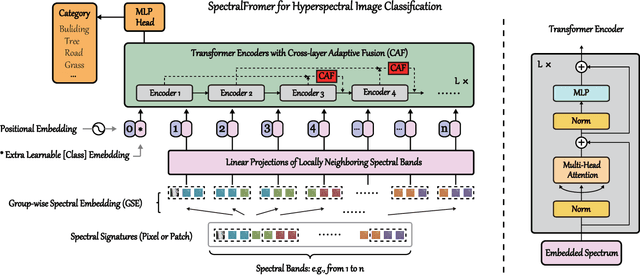
Hyperspectral (HS) images are characterized by approximately contiguous spectral information, enabling the fine identification of materials by capturing subtle spectral discrepancies. Owing to their excellent locally contextual modeling ability, convolutional neural networks (CNNs) have been proven to be a powerful feature extractor in HS image classification. However, CNNs fail to mine and represent the sequence attributes of spectral signatures well due to the limitations of their inherent network backbone. To solve this issue, we rethink HS image classification from a sequential perspective with transformers, and propose a novel backbone network called \ul{SpectralFormer}. Beyond band-wise representations in classic transformers, SpectralFormer is capable of learning spectrally local sequence information from neighboring bands of HS images, yielding group-wise spectral embeddings. More significantly, to reduce the possibility of losing valuable information in the layer-wise propagation process, we devise a cross-layer skip connection to convey memory-like components from shallow to deep layers by adaptively learning to fuse "soft" residuals across layers. It is worth noting that the proposed SpectralFormer is a highly flexible backbone network, which can be applicable to both pixel- and patch-wise inputs. We evaluate the classification performance of the proposed SpectralFormer on three HS datasets by conducting extensive experiments, showing the superiority over classic transformers and achieving a significant improvement in comparison with state-of-the-art backbone networks. The codes of this work will be available at \url{https://sites.google.com/view/danfeng-hong} for the sake of reproducibility.
Monitoring of Pigmented Skin Lesions Using 3D Whole Body Imaging
May 14, 2022
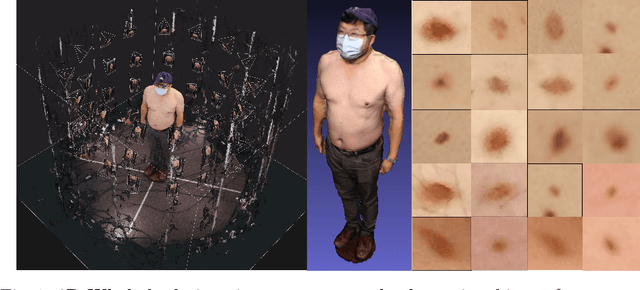


Modern data-driven machine learning research that enables revolutionary advances in image analysis has now become a critical tool to redefine how skin lesions are documented, mapped, and tracked. We propose a 3D whole body imaging prototype to enable rapid evaluation and mapping of skin lesions. A modular camera rig arranged in a cylindrical configuration is designed to automatically capture synchronised images from multiple angles for entire body scanning. We develop algorithms for 3D body image reconstruction, data processing and skin lesion detection based on deep convolutional neural networks. We also propose a customised, intuitive and flexible interface that allows the user to interact and collaborate with the machine to understand the data. The hybrid of the human and computer is represented by the analysis of 2D lesion detection, 3D mapping and data management. The experimental results using synthetic and real images demonstrate the effectiveness of the proposed solution by providing multiple views of the target skin lesion, enabling further 3D geometry analysis. Skin lesions are identified as outliers which deserve more attention from a skin cancer physician. Our detector identifies lesions at a comparable performance level as a physician. The proposed 3D whole body imaging system can be used by dermatological clinics, allowing for fast documentation of lesions, quick and accurate analysis of the entire body to detect suspicious lesions. Because of its fast examination, the method might be used for screening or epidemiological investigations. 3D data analysis has the potential to change the paradigm of total-body photography with many applications in skin diseases, including inflammatory and pigmentary disorders.
The split Gibbs sampler revisited: improvements to its algorithmic structure and augmented target distribution
Jun 28, 2022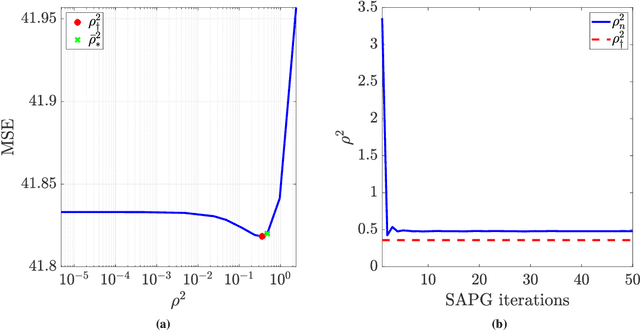


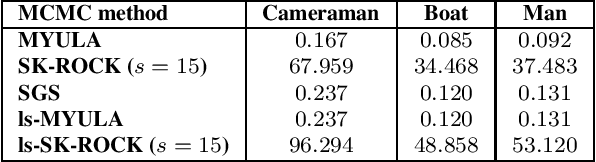
This paper proposes a new accelerated proximal Markov chain Monte Carlo (MCMC) methodology to perform Bayesian computation efficiently in imaging inverse problems. The proposed methodology is derived from the Langevin diffusion process and stems from tightly integrating two state-of-the-art proximal Langevin MCMC samplers, SK-ROCK and split Gibbs sampling (SGS), which employ distinctively different strategies to improve convergence speed. More precisely, we show how to integrate, at the level of the Langevin diffusion process, the proximal SK-ROCK sampler which is based on a stochastic Runge-Kutta-Chebyshev approximation of the diffusion, with the model augmentation and relaxation strategy that SGS exploits to speed up Bayesian computation at the expense of asymptotic bias. This leads to a new and faster proximal SK-ROCK sampler that combines the accelerated quality of the original SK-ROCK sampler with the computational benefits of augmentation and relaxation. Moreover, rather than viewing the augmented and relaxed model as an approximation of the target model, positioning relaxation in a bias-variance trade-off, we propose to regard the augmented and relaxed model as a generalisation of the target model. This then allows us to carefully calibrate the amount of relaxation in order to simultaneously improve the accuracy of the model (as measured by the model evidence) and the sampler's convergence speed. To achieve this, we derive an empirical Bayesian method to automatically estimate the optimal amount of relaxation by maximum marginal likelihood estimation. The proposed methodology is demonstrated with a range of numerical experiments related to image deblurring and inpainting, as well as with comparisons with alternative approaches from the state of the art.
Surgical-VQA: Visual Question Answering in Surgical Scenes using Transformer
Jun 22, 2022
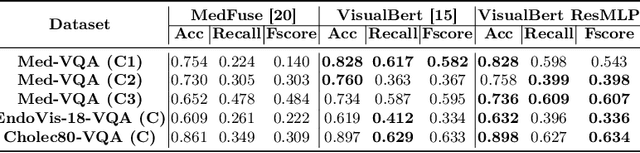
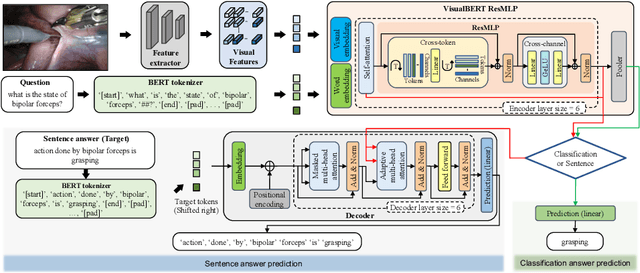
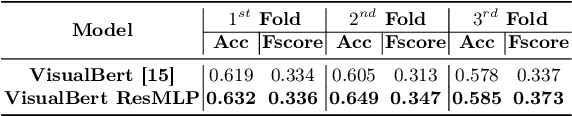
Visual question answering (VQA) in surgery is largely unexplored. Expert surgeons are scarce and are often overloaded with clinical and academic workloads. This overload often limits their time answering questionnaires from patients, medical students or junior residents related to surgical procedures. At times, students and junior residents also refrain from asking too many questions during classes to reduce disruption. While computer-aided simulators and recording of past surgical procedures have been made available for them to observe and improve their skills, they still hugely rely on medical experts to answer their questions. Having a Surgical-VQA system as a reliable 'second opinion' could act as a backup and ease the load on the medical experts in answering these questions. The lack of annotated medical data and the presence of domain-specific terms has limited the exploration of VQA for surgical procedures. In this work, we design a Surgical-VQA task that answers questionnaires on surgical procedures based on the surgical scene. Extending the MICCAI endoscopic vision challenge 2018 dataset and workflow recognition dataset further, we introduce two Surgical-VQA datasets with classification and sentence-based answers. To perform Surgical-VQA, we employ vision-text transformers models. We further introduce a residual MLP-based VisualBert encoder model that enforces interaction between visual and text tokens, improving performance in classification-based answering. Furthermore, we study the influence of the number of input image patches and temporal visual features on the model performance in both classification and sentence-based answering.
Adaptively Sparse Regularization for Blind Image Restoration
Jan 23, 2021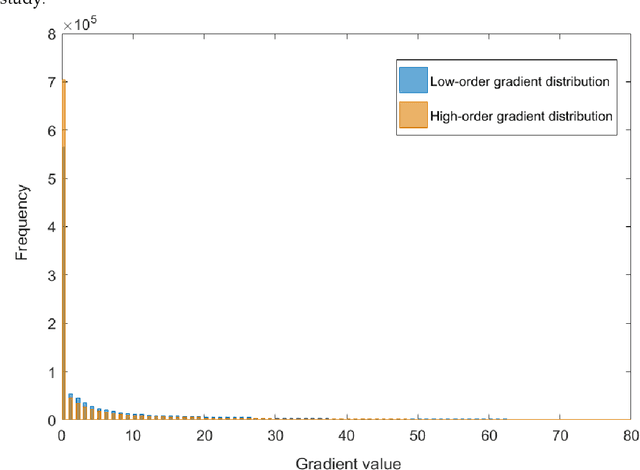
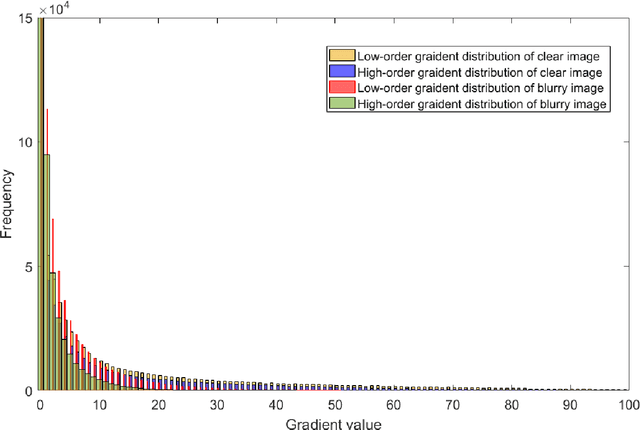

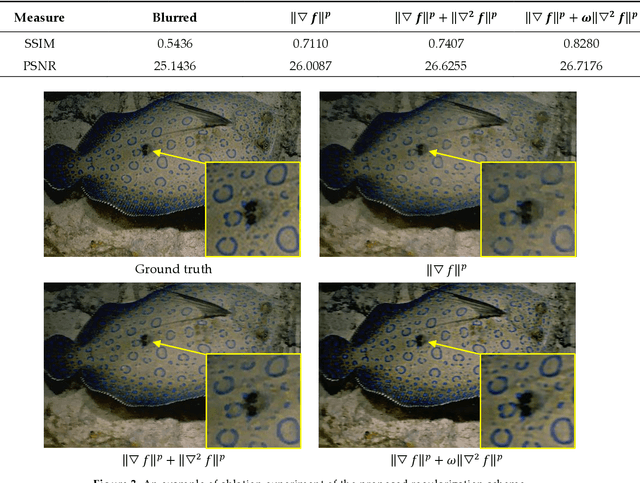
Image quality is the basis of image communication and understanding tasks. Due to the blur and noise effects caused by imaging, transmission and other processes, the image quality is degraded. Blind image restoration is widely used to improve image quality, where the main goal is to faithfully estimate the blur kernel and the latent sharp image. In this study, based on experimental observation and research, an adaptively sparse regularized minimization method is originally proposed. The high-order gradients combine with low-order ones to form a hybrid regularization term, and an adaptive operator derived from the image entropy is introduced to maintain a good convergence. Extensive experiments were conducted on different blur kernels and images. Compared with existing state-of-the-art blind deblurring methods, our method demonstrates superiority on the recovery accuracy.
Deep Lucas-Kanade Homography for Multimodal Image Alignment
Apr 22, 2021
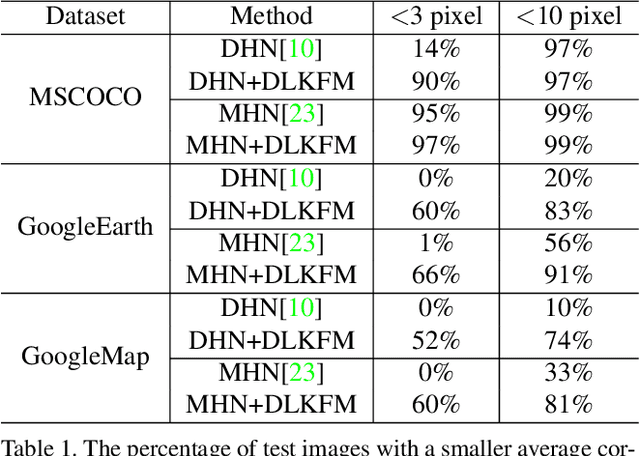
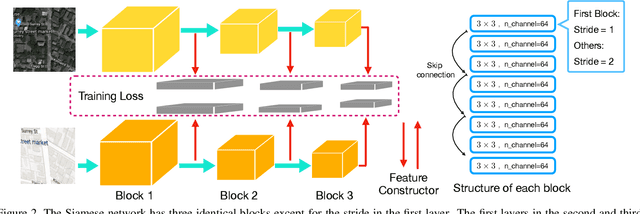

Estimating homography to align image pairs captured by different sensors or image pairs with large appearance changes is an important and general challenge for many computer vision applications. In contrast to others, we propose a generic solution to pixel-wise align multimodal image pairs by extending the traditional Lucas-Kanade algorithm with networks. The key contribution in our method is how we construct feature maps, named as deep Lucas-Kanade feature map (DLKFM). The learned DLKFM can spontaneously recognize invariant features under various appearance-changing conditions. It also has two nice properties for the Lucas-Kanade algorithm: (1) The template feature map keeps brightness consistency with the input feature map, thus the color difference is very small while they are well-aligned. (2) The Lucas-Kanade objective function built on DLKFM has a smooth landscape around ground truth homography parameters, so the iterative solution of the Lucas-Kanade can easily converge to the ground truth. With those properties, directly updating the Lucas-Kanade algorithm on our feature maps will precisely align image pairs with large appearance changes. We share the datasets, code, and demo video online.
Learning to Erase the Bayer-Filter to See in the Dark
Mar 08, 2022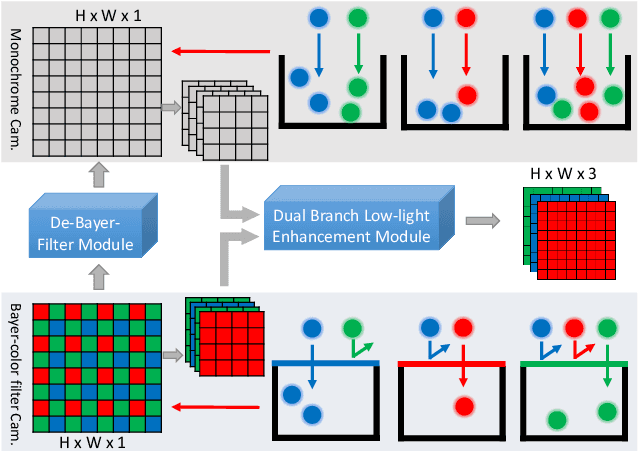


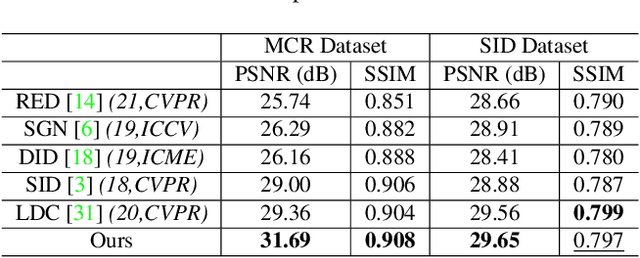
Low-light image enhancement - a pervasive but challenging problem, plays a central role in enhancing the visibility of an image captured in a poor illumination environment. Due to the fact that not all photons can pass the Bayer-Filter on the sensor of the color camera, in this work, we first present a De-Bayer-Filter simulator based on deep neural networks to generate a monochrome raw image from the colored raw image. Next, a fully convolutional network is proposed to achieve the low-light image enhancement by fusing colored raw data with synthesized monochrome raw data. Channel-wise attention is also introduced to the fusion process to establish a complementary interaction between features from colored and monochrome raw images. To train the convolutional networks, we propose a dataset with monochrome and color raw pairs named Mono-Colored Raw paired dataset (MCR) collected by using a monochrome camera without Bayer-Filter and a color camera with Bayer-Filter. The proposed pipeline take advantages of the fusion of the virtual monochrome and the color raw images and our extensive experiments indicate that significant improvement can be achieved by leveraging raw sensor data and data-driven learning.
Efficient fine-grained road segmentation using superpixel-based CNN and CRF models
Jun 22, 2022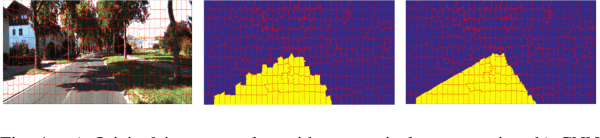
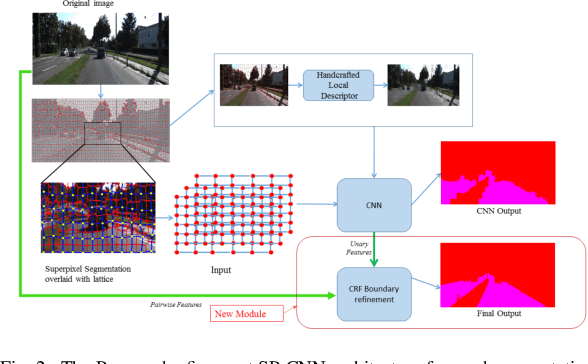

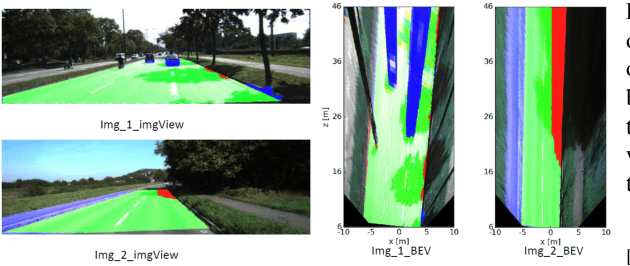
Towards a safe and comfortable driving, road scene segmentation is a rudimentary problem in camera-based advance driver assistance systems (ADAS). Despite of the great achievement of Convolutional Neural Networks (CNN) for semantic segmentation task, the high computational efforts of CNN based methods is still a challenging area. In recent work, we proposed a novel approach to utilise the advantages of CNNs for the task of road segmentation at reasonable computational effort. The runtime benefits from using irregular super pixels as basis for the input for the CNN rather than the image grid, which tremendously reduces the input size. Although, this method achieved remarkable low computational time in both training and testing phases, the lower resolution of the super pixel domain yields naturally lower accuracy compared to high cost state of the art methods. In this work, we focus on a refinement of the road segmentation utilising a Conditional Random Field (CRF).The refinement procedure is limited to the super pixels touching the predicted road boundary to keep the additional computational effort low. Reducing the input to the super pixel domain allows the CNNs structure to stay small and efficient to compute while keeping the advantage of convolutional layers and makes them eligible for ADAS. Applying CRF compensate the trade off between accuracy and computational efficiency. The proposed system obtained comparable performance among the top performing algorithms on the KITTI road benchmark and its fast inference makes it particularly suitable for realtime applications.
Multi-scale Self-calibrated Network for Image Light Source Transfer
Apr 18, 2021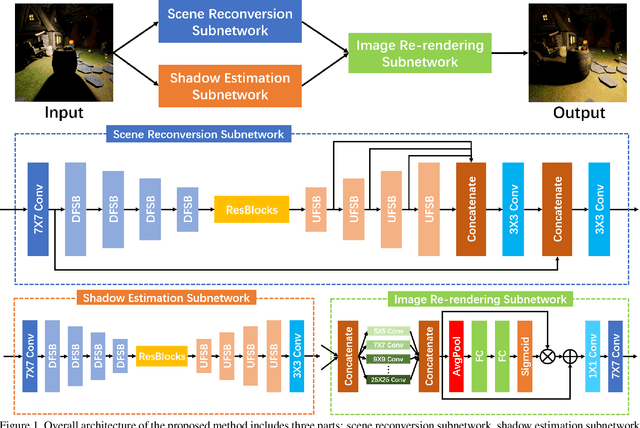
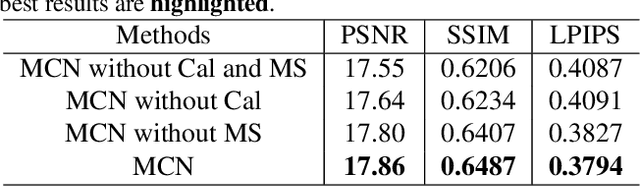
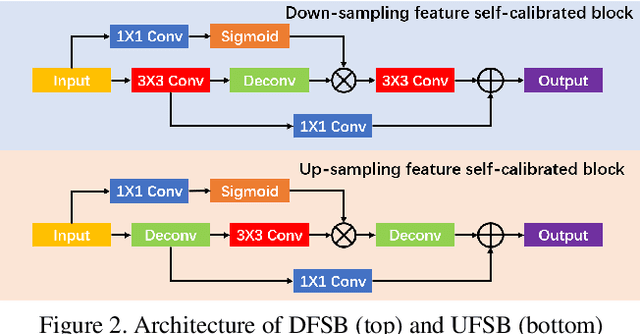
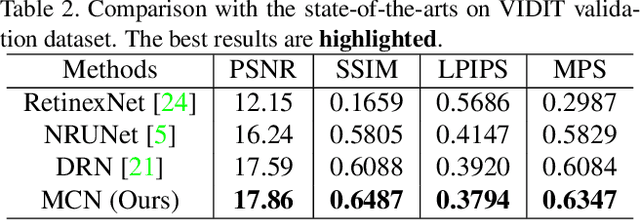
Image light source transfer (LLST), as the most challenging task in the domain of image relighting, has attracted extensive attention in recent years. In the latest research, LLST is decomposed three sub-tasks: scene reconversion, shadow estimation, and image re-rendering, which provides a new paradigm for image relighting. However, many problems for scene reconversion and shadow estimation tasks, including uncalibrated feature information and poor semantic information, are still unresolved, thereby resulting in insufficient feature representation. In this paper, we propose novel down-sampling feature self-calibrated block (DFSB) and up-sampling feature self-calibrated block (UFSB) as the basic blocks of feature encoder and decoder to calibrate feature representation iteratively because the LLST is similar to the recalibration of image light source. In addition, we fuse the multi-scale features of the decoder in scene reconversion task to further explore and exploit more semantic information, thereby providing more accurate primary scene structure for image re-rendering. Experimental results in the VIDIT dataset show that the proposed approach significantly improves the performance for LLST.
ResViT: Residual vision transformers for multi-modal medical image synthesis
Jun 30, 2021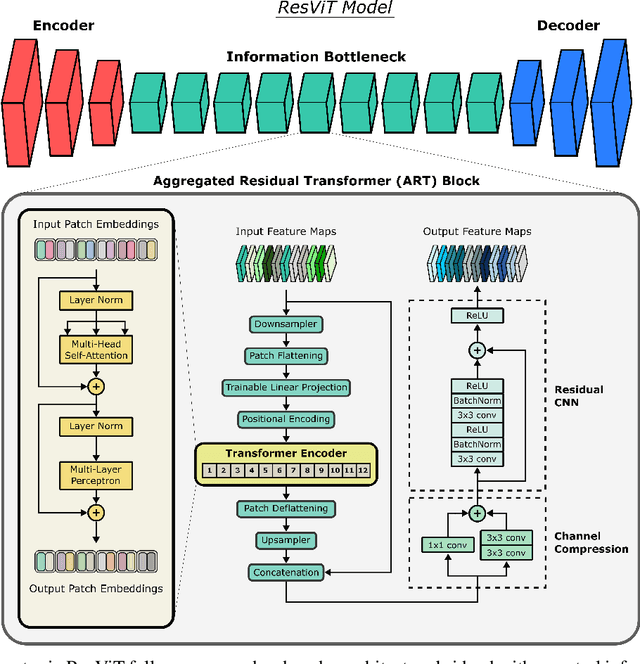
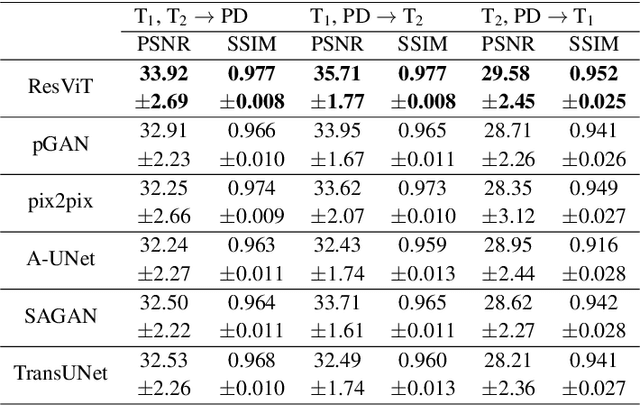
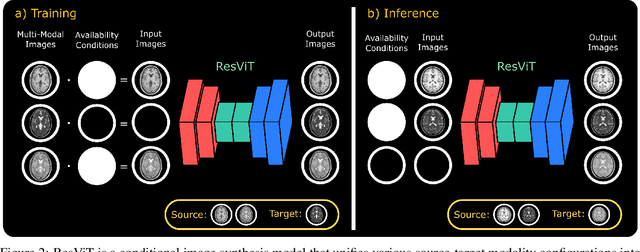
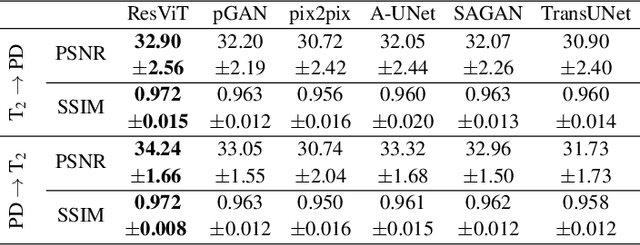
Multi-modal imaging is a key healthcare technology in the diagnosis and management of disease, but it is often underutilized due to costs associated with multiple separate scans. This limitation yields the need for synthesis of unacquired modalities from the subset of available modalities. In recent years, generative adversarial network (GAN) models with superior depiction of structural details have been established as state-of-the-art in numerous medical image synthesis tasks. However, GANs are characteristically based on convolutional neural network (CNN) backbones that perform local processing with compact filters. This inductive bias, in turn, compromises learning of long-range spatial dependencies. While attention maps incorporated in GANs can multiplicatively modulate CNN features to emphasize critical image regions, their capture of global context is mostly implicit. Here, we propose a novel generative adversarial approach for medical image synthesis, ResViT, to combine local precision of convolution operators with contextual sensitivity of vision transformers. Based on an encoder-decoder architecture, ResViT employs a central bottleneck comprising novel aggregated residual transformer (ART) blocks that synergistically combine convolutional and transformer modules. Comprehensive demonstrations are performed for synthesizing missing sequences in multi-contrast MRI and CT images from MRI. Our results indicate the superiority of ResViT against competing methods in terms of qualitative observations and quantitative metrics.