 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic Structured Illumination Microscopy with a Neural Space-time Model
Jun 03, 2022
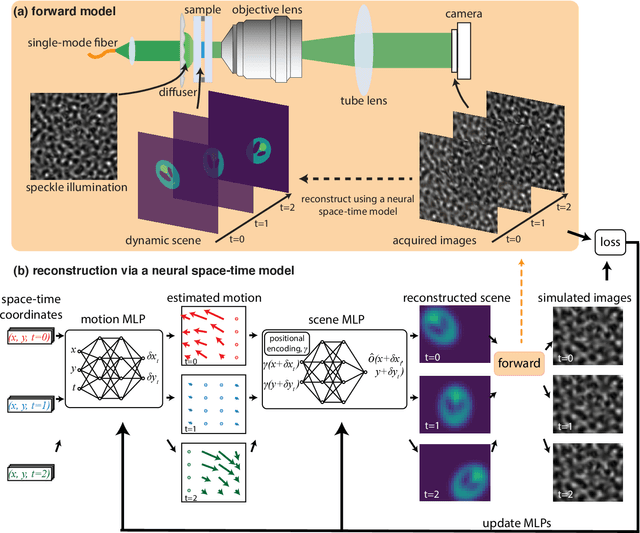
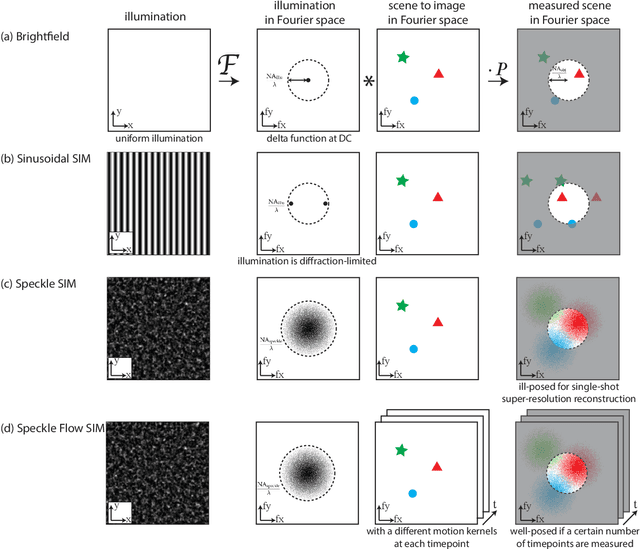
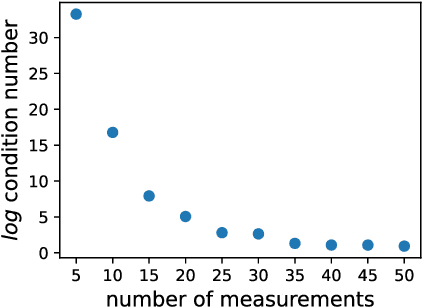
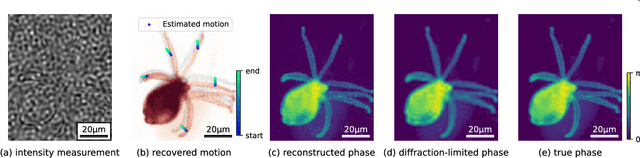
Structured illumination microscopy (SIM) reconstructs a super-resolved image from multiple raw images; hence, acquisition speed is limited, making it unsuitable for dynamic scenes. We propose a new method, Speckle Flow SIM, that models sample motion during the data capture in order to reconstruct dynamic scenes with super-resolution. Speckle Flow SIM uses fixed speckle illumination and relies on sample motion to capture a sequence of raw images. Then, the spatio-temporal relationship of the dynamic scene is modeled using a neural space-time model with coordinate-based multi-layer perceptrons (MLPs), and the motion dynamics and the super-resolved scene are jointly recovered. We validated Speckle Flow SIM in simulation and built a simple, inexpensive experimental setup with off-the-shelf components. We demonstrated that Speckle Flow SIM can reconstruct a dynamic scene with deformable motion and 1.88x the diffraction-limited resolution in experiment.
Speaking-Rate-Controllable HiFi-GAN Using Feature Interpolation
Apr 22, 2022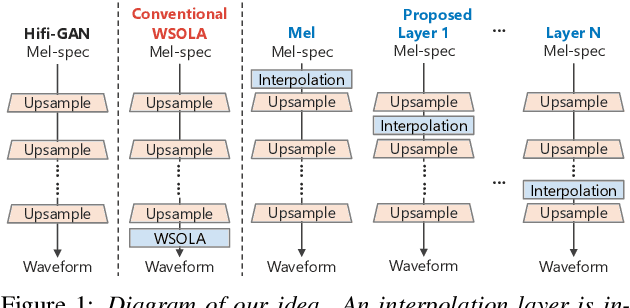

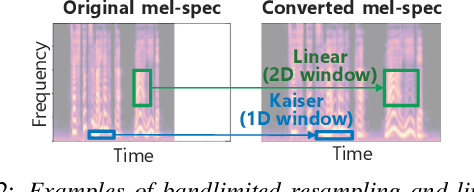
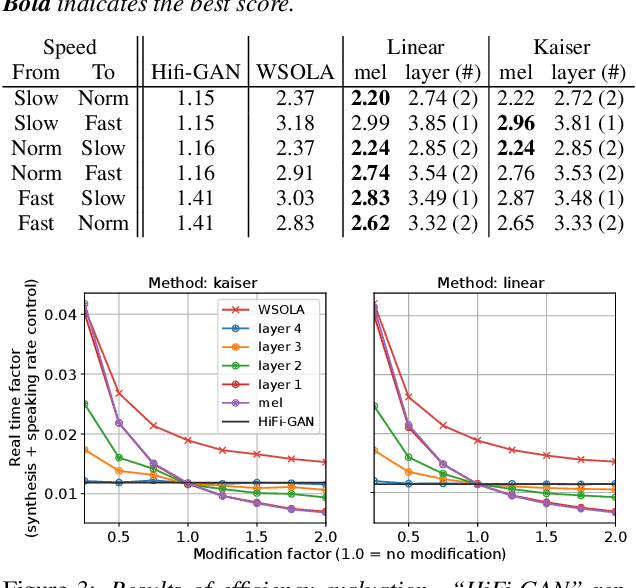
This paper presents a speaking-rate-controllable HiFi-GAN neural vocoder. Original HiFi-GAN is a high-fidelity, computationally efficient, and tiny-footprint neural vocoder. We attempt to incorporate a speaking rate control function into HiFi-GAN for improving the accessibility of synthetic speech. The proposed method inserts a differentiable interpolation layer into the HiFi-GAN architecture. A signal resampling method and an image scaling method are implemented in the proposed method to warp the mel-spectrograms or hidden features of the neural vocoder. We also design and open-source a Japanese speech corpus containing three kinds of speaking rates to evaluate the proposed speaking rate control method. Experimental results of comprehensive objective and subjective evaluations demonstrate that 1) the proposed method outperforms a baseline time-scale modification algorithm in speech naturalness, 2) warping mel-spectrograms by image scaling obtained the best performance among all proposed methods, and 3) the proposed speaking rate control method can be incorporated into HiFi-GAN without losing computational efficiency.
Contrastive Learning for Unpaired Image-to-Image Translation
Aug 18, 2020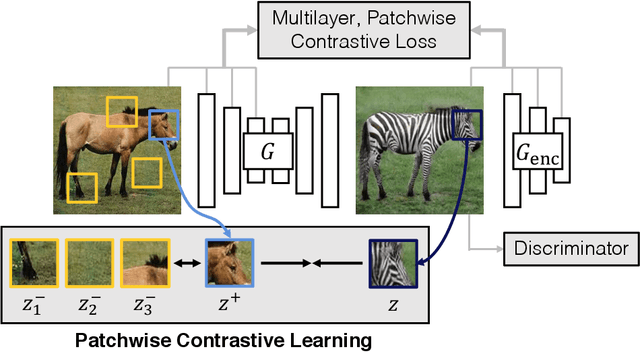
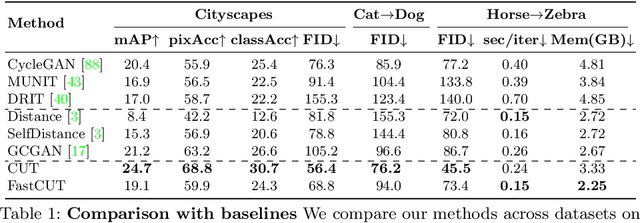
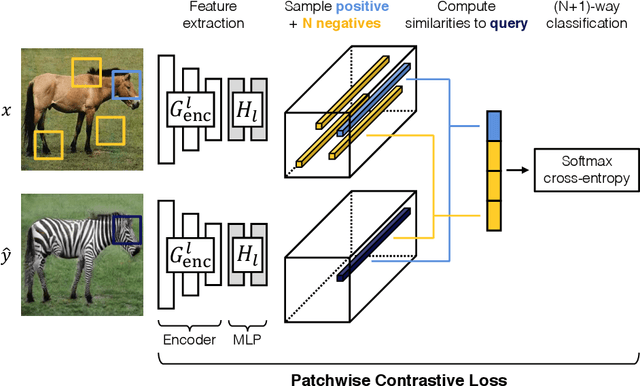
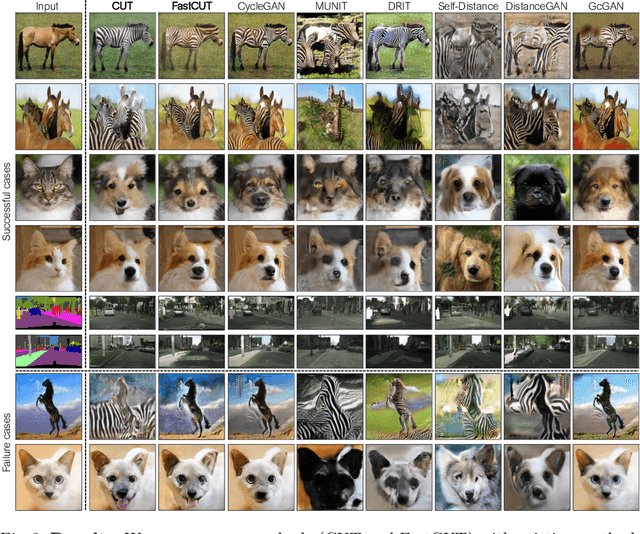
In image-to-image translation, each patch in the output should reflect the content of the corresponding patch in the input, independent of domain. We propose a straightforward method for doing so -- maximizing mutual information between the two, using a framework based on contrastive learning. The method encourages two elements (corresponding patches) to map to a similar point in a learned feature space, relative to other elements (other patches) in the dataset, referred to as negatives. We explore several critical design choices for making contrastive learning effective in the image synthesis setting. Notably, we use a multilayer, patch-based approach, rather than operate on entire images. Furthermore, we draw negatives from within the input image itself, rather than from the rest of the dataset. We demonstrate that our framework enables one-sided translation in the unpaired image-to-image translation setting, while improving quality and reducing training time. In addition, our method can even be extended to the training setting where each "domain" is only a single image.
Efficient Human-in-the-loop System for Guiding DNNs Attention
Jun 14, 2022

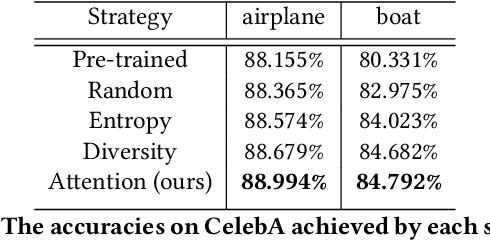
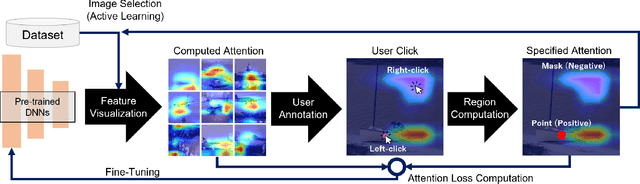
Attention guidance is an approach to addressing dataset bias in deep learning, where the model relies on incorrect features to make decisions. Focusing on image classification tasks, we propose an efficient human-in-the-loop system to interactively direct the attention of classifiers to the regions specified by users, thereby reducing the influence of co-occurrence bias and improving the transferability and interpretability of a DNN. Previous approaches for attention guidance require the preparation of pixel-level annotations and are not designed as interactive systems. We present a new interactive method to allow users to annotate images with simple clicks, and study a novel active learning strategy to significantly reduce the number of annotations. We conducted both a numerical evaluation and a user study to evaluate the proposed system on multiple datasets. Compared to the existing non-active-learning approach which usually relies on huge amounts of polygon-based segmentation masks to fine-tune or train the DNNs, our system can save lots of labor and money and obtain a fine-tuned network that works better even when the dataset is biased. The experiment results indicate that the proposed system is efficient, reasonable, and reliable.
SpecNet2: Orthogonalization-free spectral embedding by neural networks
Jun 14, 2022
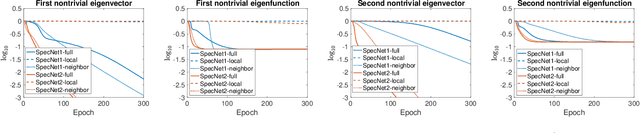

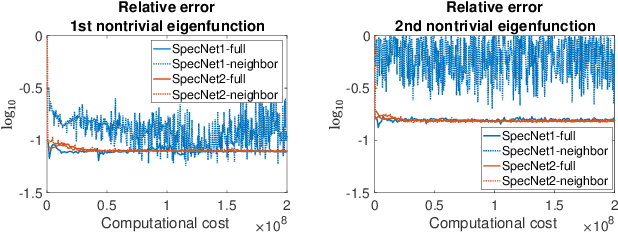
Spectral methods which represent data points by eigenvectors of kernel matrices or graph Laplacian matrices have been a primary tool in unsupervised data analysis. In many application scenarios, parametrizing the spectral embedding by a neural network that can be trained over batches of data samples gives a promising way to achieve automatic out-of-sample extension as well as computational scalability. Such an approach was taken in the original paper of SpectralNet (Shaham et al. 2018), which we call SpecNet1. The current paper introduces a new neural network approach, named SpecNet2, to compute spectral embedding which optimizes an equivalent objective of the eigen-problem and removes the orthogonalization layer in SpecNet1. SpecNet2 also allows separating the sampling of rows and columns of the graph affinity matrix by tracking the neighbors of each data point through the gradient formula. Theoretically, we show that any local minimizer of the new orthogonalization-free objective reveals the leading eigenvectors. Furthermore, global convergence for this new orthogonalization-free objective using a batch-based gradient descent method is proved. Numerical experiments demonstrate the improved performance and computational efficiency of SpecNet2 on simulated data and image datasets.
How Many Events do You Need? Event-based Visual Place Recognition Using Sparse But Varying Pixels
Jun 28, 2022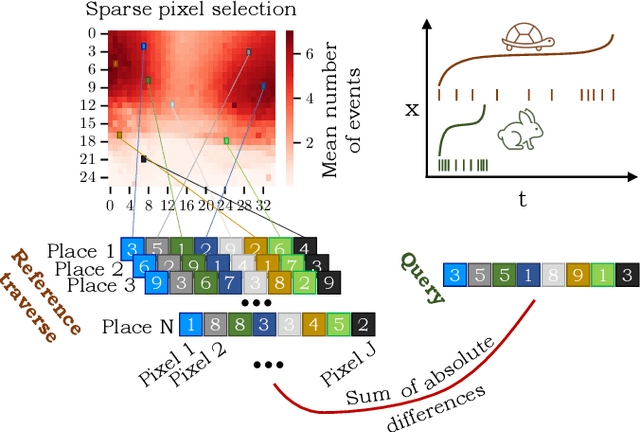
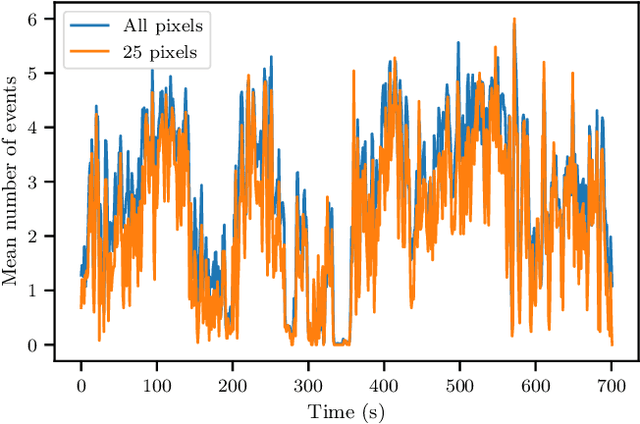
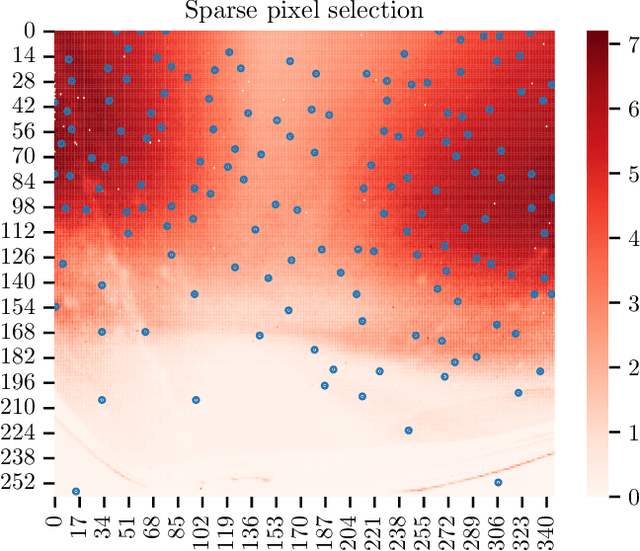

Event cameras continue to attract interest due to desirable characteristics such as high dynamic range, low latency, virtually no motion blur, and high energy efficiency. One of the potential applications of event camera research lies in visual place recognition for robot localization, where a query observation has to be matched to the corresponding reference place in the database. In this letter, we explore the distinctiveness of event streams from a small subset of pixels (in the tens or hundreds). We demonstrate that the absolute difference in the number of events at those pixel locations accumulated into event frames can be sufficient for the place recognition task, when pixels that display large variations in the reference set are used. Using such sparse (over image coordinates) but varying (variance over the number of events per pixel location) pixels enables frequent and computationally cheap updates of the location estimates. Furthermore, when event frames contain a constant number of events, our method takes full advantage of the event-driven nature of the sensory stream and displays promising robustness to changes in velocity. We evaluate our proposed approach on the Brisbane-Event-VPR dataset in an outdoor driving scenario, as well as the newly contributed indoor QCR-Event-VPR dataset that was captured with a DAVIS346 camera mounted on a mobile robotic platform. Our results show that our approach achieves competitive performance when compared to several baseline methods on those datasets, and is particularly well suited for compute- and energy-constrained platforms such as interplanetary rovers.
Better Self-training for Image Classification through Self-supervision
Sep 09, 2021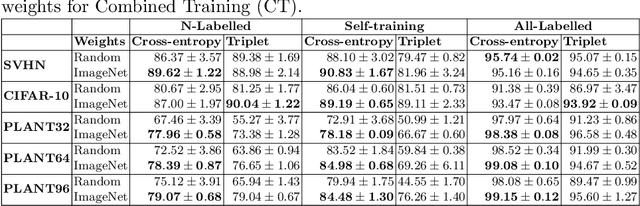
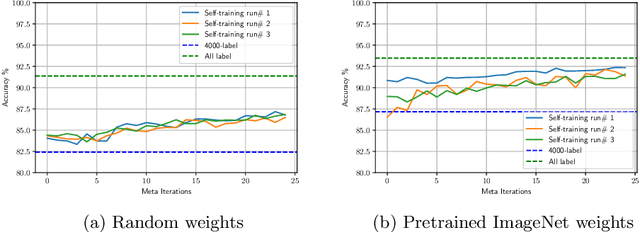
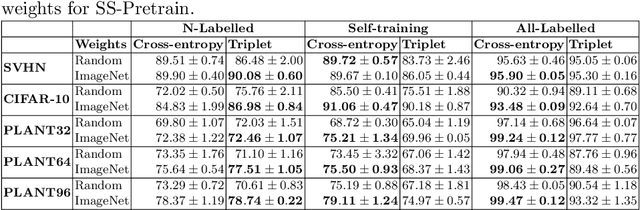
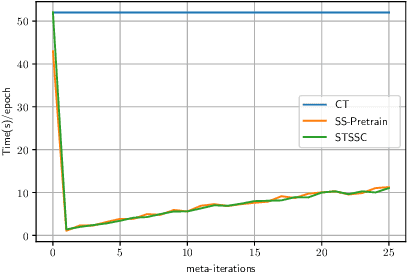
Self-training is a simple semi-supervised learning approach: Unlabelled examples that attract high-confidence predictions are labelled with their predictions and added to the training set, with this process being repeated multiple times. Recently, self-supervision -- learning without manual supervision by solving an automatically-generated pretext task -- has gained prominence in deep learning. This paper investigates three different ways of incorporating self-supervision into self-training to improve accuracy in image classification: self-supervision as pretraining only, self-supervision performed exclusively in the first iteration of self-training, and self-supervision added to every iteration of self-training. Empirical results on the SVHN, CIFAR-10, and PlantVillage datasets, using both training from scratch, and Imagenet-pretrained weights, show that applying self-supervision only in the first iteration of self-training can greatly improve accuracy, for a modest increase in computation time.
HASA: Hybrid Architecture Search with Aggregation Strategy for Echinococcosis Classification and Ovary Segmentation in Ultrasound Images
Apr 20, 2022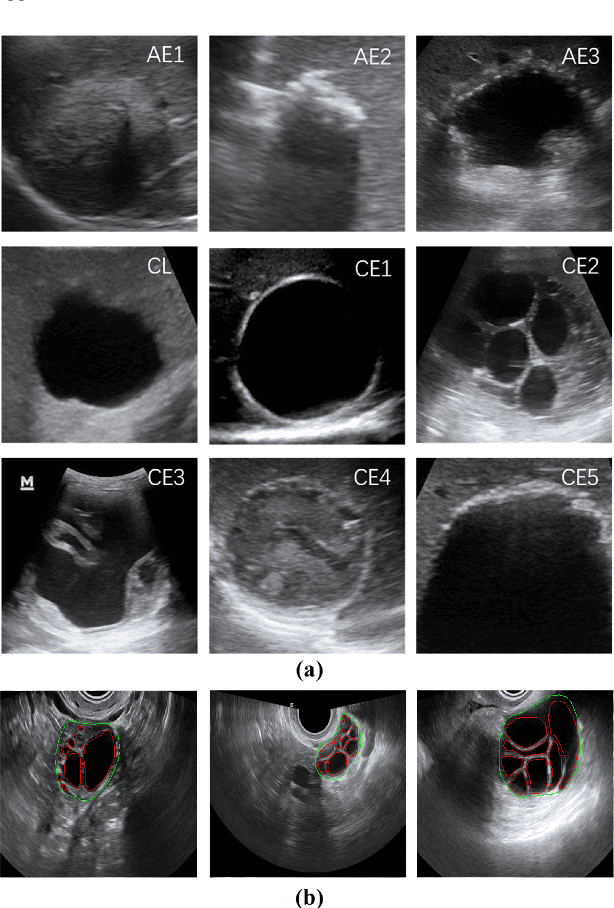
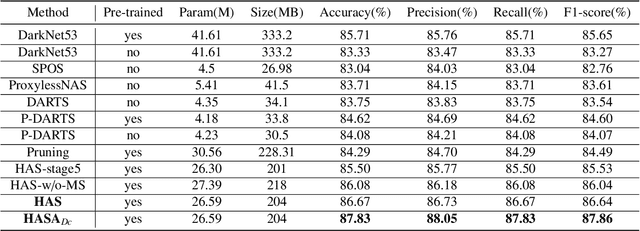
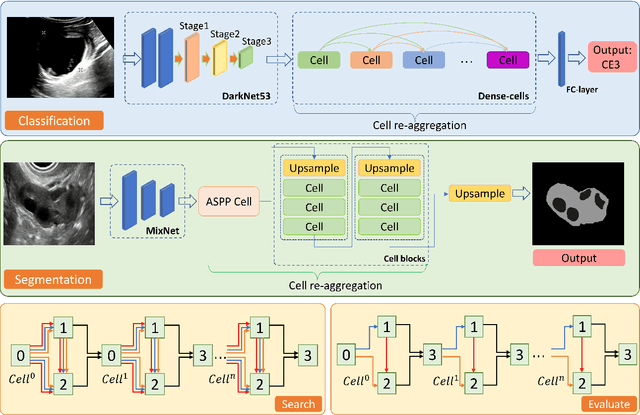
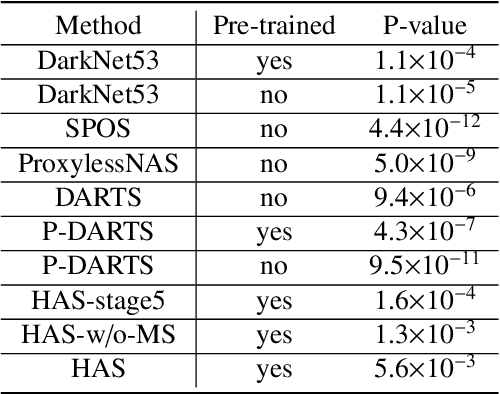
Different from handcrafted features, deep neural networks can automatically learn task-specific features from data. Due to this data-driven nature, they have achieved remarkable success in various areas. However, manual design and selection of suitable network architectures are time-consuming and require substantial effort of human experts. To address this problem, researchers have proposed neural architecture search (NAS) algorithms which can automatically generate network architectures but suffer from heavy computational cost and instability if searching from scratch. In this paper, we propose a hybrid NAS framework for ultrasound (US) image classification and segmentation. The hybrid framework consists of a pre-trained backbone and several searched cells (i.e., network building blocks), which takes advantage of the strengths of both NAS and the expert knowledge from existing convolutional neural networks. Specifically, two effective and lightweight operations, a mixed depth-wise convolution operator and a squeeze-and-excitation block, are introduced into the candidate operations to enhance the variety and capacity of the searched cells. These two operations not only decrease model parameters but also boost network performance. Moreover, we propose a re-aggregation strategy for the searched cells, aiming to further improve the performance for different vision tasks. We tested our method on two large US image datasets, including a 9-class echinococcosis dataset containing 9566 images for classification and an ovary dataset containing 3204 images for segmentation. Ablation experiments and comparison with other handcrafted or automatically searched architectures demonstrate that our method can generate more powerful and lightweight models for the above US image classification and segmentation tasks.
Self-Supervised Domain Adaptation for Diabetic Retinopathy Grading using Vessel Image Reconstruction
Jul 20, 2021
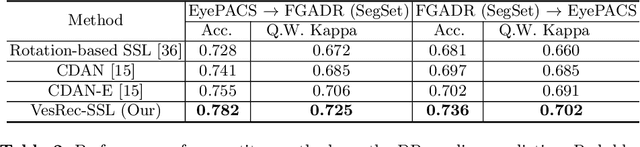
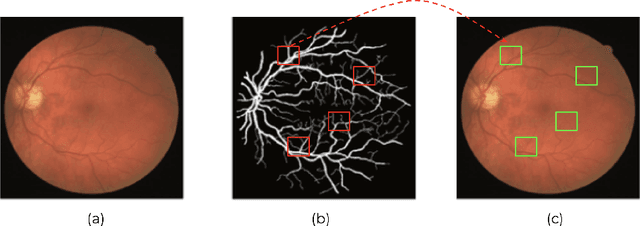
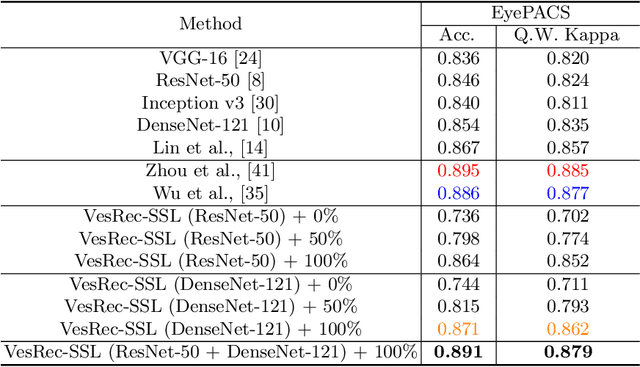
This paper investigates the problem of domain adaptation for diabetic retinopathy (DR) grading. We learn invariant target-domain features by defining a novel self-supervised task based on retinal vessel image reconstructions, inspired by medical domain knowledge. Then, a benchmark of current state-of-the-art unsupervised domain adaptation methods on the DR problem is provided. It can be shown that our approach outperforms existing domain adaption strategies. Furthermore, when utilizing entire training data in the target domain, we are able to compete with several state-of-the-art approaches in final classification accuracy just by applying standard network architectures and using image-level labels.
Attention-based Image Upsampling
Dec 17, 2020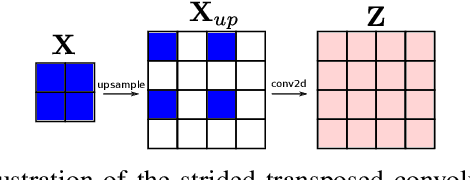
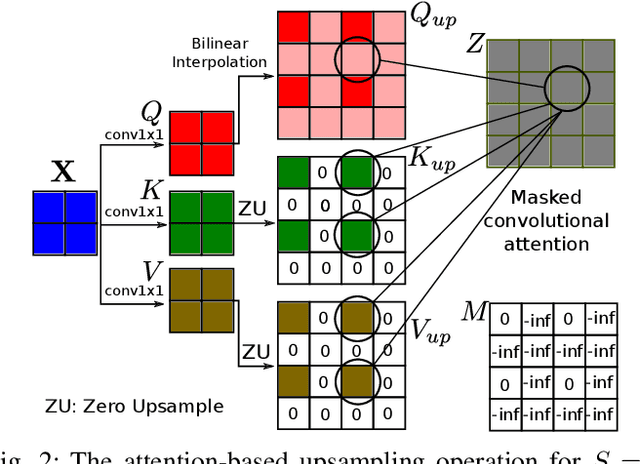
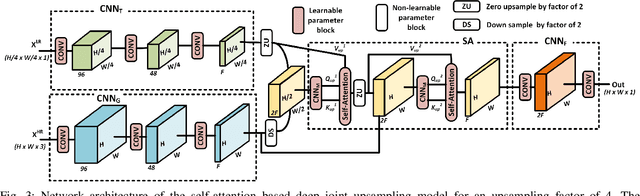

Convolutional layers are an integral part of many deep neural network solutions in computer vision. Recent work shows that replacing the standard convolution operation with mechanisms based on self-attention leads to improved performance on image classification and object detection tasks. In this work, we show how attention mechanisms can be used to replace another canonical operation: strided transposed convolution. We term our novel attention-based operation attention-based upsampling since it increases/upsamples the spatial dimensions of the feature maps. Through experiments on single image super-resolution and joint-image upsampling tasks, we show that attention-based upsampling consistently outperforms traditional upsampling methods based on strided transposed convolution or based on adaptive filters while using fewer parameters. We show that the inherent flexibility of the attention mechanism, which allows it to use separate sources for calculating the attention coefficients and the attention targets, makes attention-based upsampling a natural choice when fusing information from multiple image modalities.