 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ImPosIng: Implicit Pose Encoding for Efficient Camera Pose Estimation
May 05, 2022
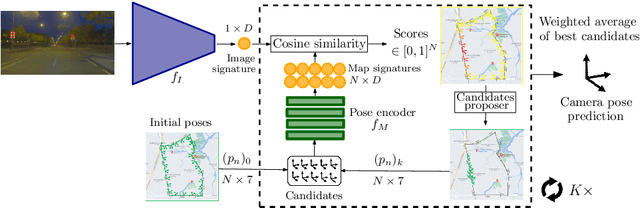
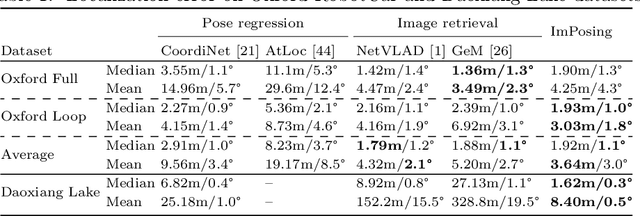


We propose a novel learning-based formulation for camera pose estimation that can perform relocalization accurately and in real-time in city-scale environments. Camera pose estimation algorithms determine the position and orientation from which an image has been captured, using a set of geo-referenced images or 3D scene representation. Our new localization paradigm, named Implicit Pose Encoding (ImPosing), embeds images and camera poses into a common latent representation with 2 separate neural networks, such that we can compute a similarity score for each image-pose pair. By evaluating candidates through the latent space in a hierarchical manner, the camera position and orientation are not directly regressed but incrementally refined. Compared to the representation used in structure-based relocalization methods, our implicit map is memory bounded and can be properly explored to improve localization performances against learning-based regression approaches. In this paper, we describe how to effectively optimize our learned modules, how to combine them to achieve real-time localization, and demonstrate results on diverse large scale scenarios that significantly outperform prior work in accuracy and computational efficiency.
Deep Tiny Network for Recognition-Oriented Face Image Quality Assessment
Jun 09, 2021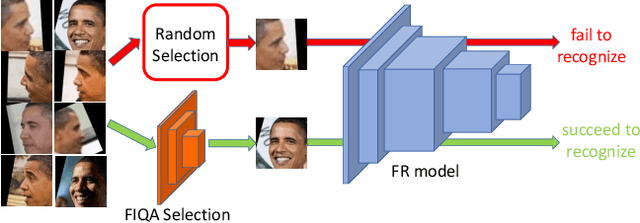
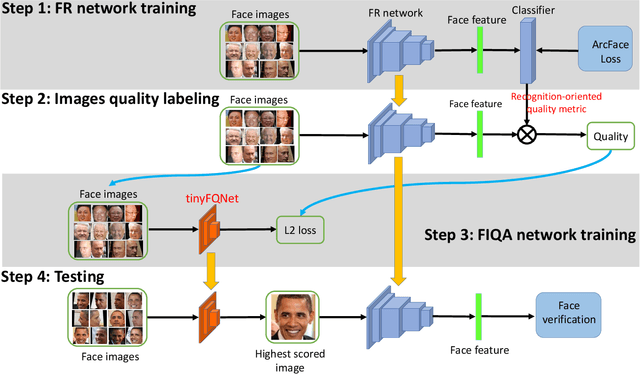
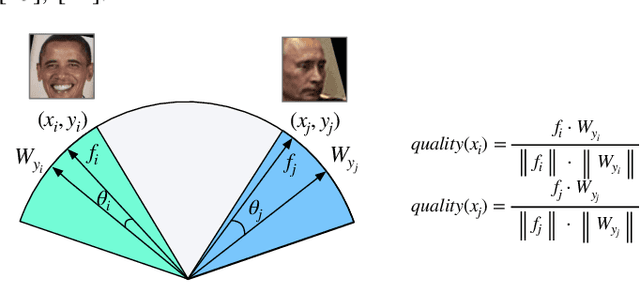
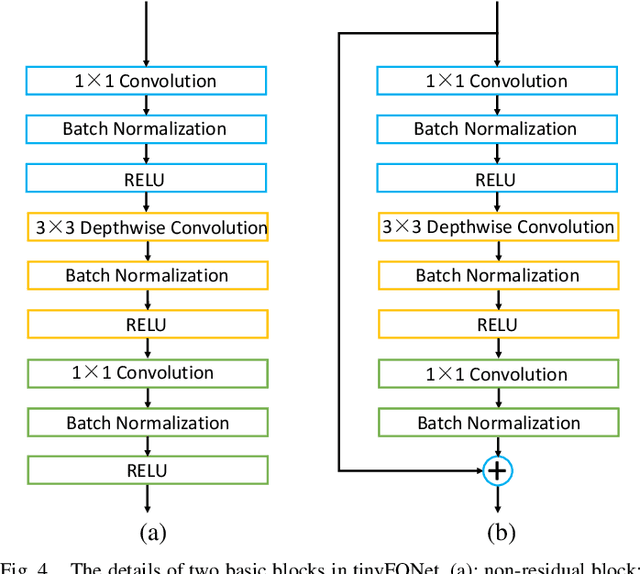
Face recognition has made significant progress in recent years due to deep convolutional neural networks (CNN). In many face recognition (FR) scenarios, face images are acquired from a sequence with huge intra-variations. These intra-variations, which are mainly affected by the low-quality face images, cause instability of recognition performance. Previous works have focused on ad-hoc methods to select frames from a video or use face image quality assessment (FIQA) methods, which consider only a particular or combination of several distortions. In this work, we present an efficient non-reference image quality assessment for FR that directly links image quality assessment (IQA) and FR. More specifically, we propose a new measurement to evaluate image quality without any reference. Based on the proposed quality measurement, we propose a deep Tiny Face Quality network (tinyFQnet) to learn a quality prediction function from data. We evaluate the proposed method for different powerful FR models on two classical video-based (or template-based) benchmark: IJB-B and YTF. Extensive experiments show that, although the tinyFQnet is much smaller than the others, the proposed method outperforms state-of-the-art quality assessment methods in terms of effectiveness and efficiency.
Generating natural images with direct Patch Distributions Matching
Mar 22, 2022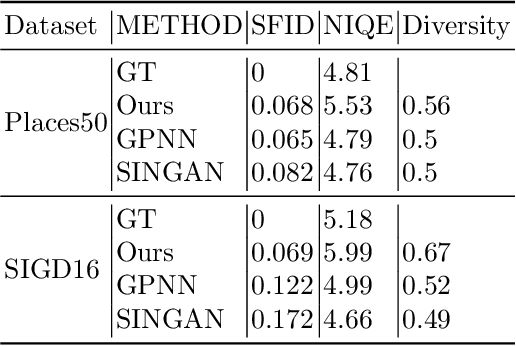


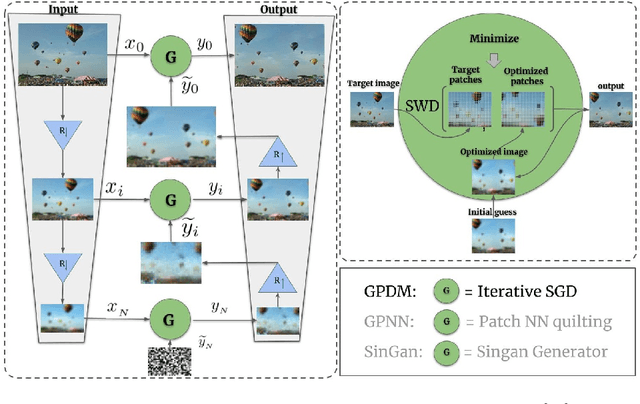
Many traditional computer vision algorithms generate realistic images by requiring that each patch in the generated image be similar to a patch in a training image and vice versa. Recently, this classical approach has been replaced by adversarial training with a patch discriminator. The adversarial approach avoids the computational burden of finding nearest neighbors of patches but often requires very long training times and may fail to match the distribution of patches. In this paper we leverage the recently developed Sliced Wasserstein Distance and develop an algorithm that explicitly and efficiently minimizes the distance between patch distributions in two images. Our method is conceptually simple, requires no training and can be implemented in a few lines of codes. On a number of image generation tasks we show that our results are often superior to single-image-GANs, require no training, and can generate high quality images in a few seconds. Our implementation is available at https://github.com/ariel415el/GPDM
Out-of-Distribution Detection with Class Ratio Estimation
Jun 08, 2022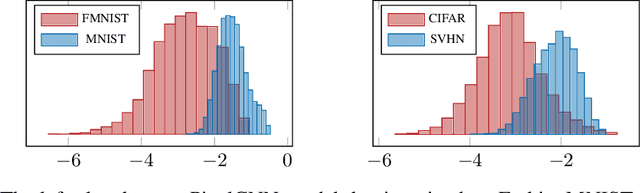
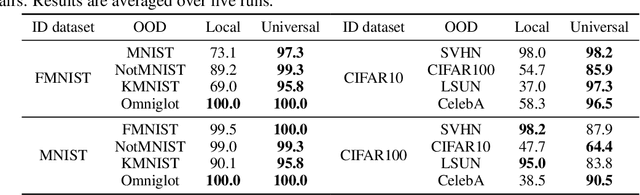
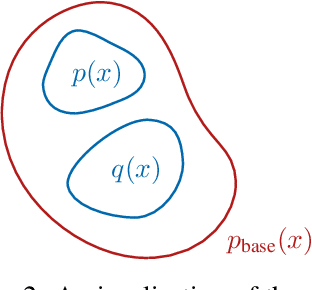
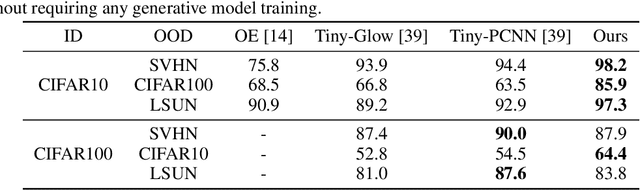
Density-based Out-of-distribution (OOD) detection has recently been shown unreliable for the task of detecting OOD images. Various density ratio based approaches achieve good empirical performance, however methods typically lack a principled probabilistic modelling explanation. In this work, we propose to unify density ratio based methods under a novel framework that builds energy-based models and employs differing base distributions. Under our framework, the density ratio can be viewed as the unnormalized density of an implicit semantic distribution. Further, we propose to directly estimate the density ratio of a data sample through class ratio estimation. We report competitive results on OOD image problems in comparison with recent work that alternatively requires training of deep generative models for the task. Our approach enables a simple and yet effective path towards solving the OOD detection problem.
Image2Gif: Generating Continuous Realistic Animations with Warping NODEs
May 09, 2022
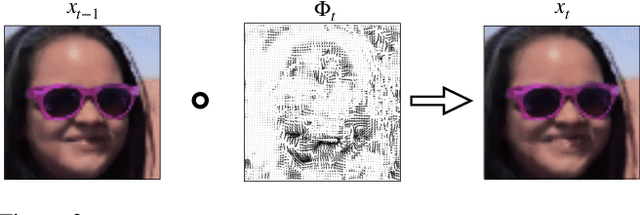
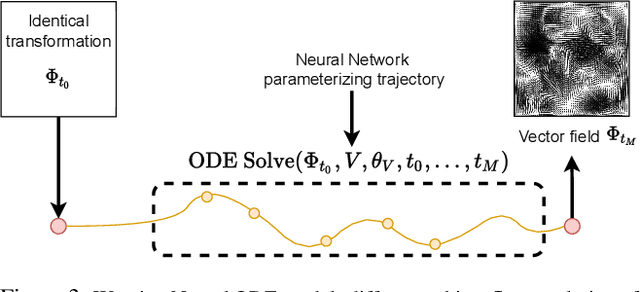
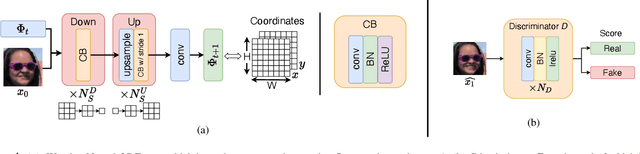
Generating smooth animations from a limited number of sequential observations has a number of applications in vision. For example, it can be used to increase number of frames per second, or generating a new trajectory only based on first and last frames, e.g. a motion of face emotions. Despite the discrete observed data (frames), the problem of generating a new trajectory is a continues problem. In addition, to be perceptually realistic, the domain of an image should not alter drastically through the trajectory of changes. In this paper, we propose a new framework, Warping Neural ODE, for generating a smooth animation (video frame interpolation) in a continuous manner, given two ("farther apart") frames, denoting the start and the end of the animation. The key feature of our framework is utilizing the continuous spatial transformation of the image based on the vector field, derived from a system of differential equations. This allows us to achieve the smoothness and the realism of an animation with infinitely small time steps between the frames. We show the application of our work in generating an animation given two frames, in different training settings, including Generative Adversarial Network (GAN) and with $L_2$ loss.
ESS: Learning Event-based Semantic Segmentation from Still Images
Mar 18, 2022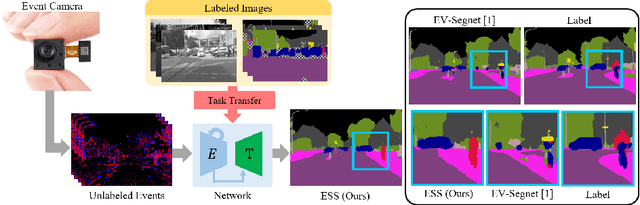

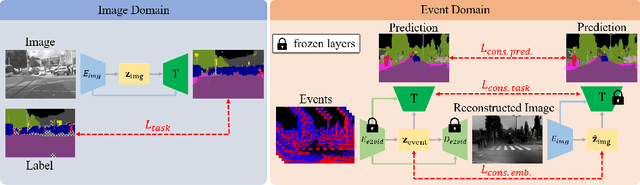
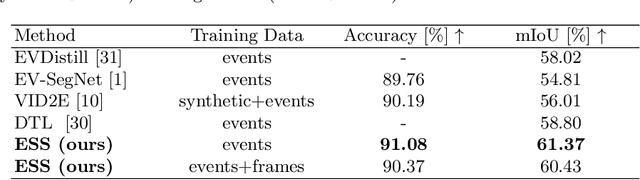
Retrieving accurate semantic information in challenging high dynamic range (HDR) and high-speed conditions remains an open challenge for image-based algorithms due to severe image degradations. Event cameras promise to address these challenges since they feature a much higher dynamic range and are resilient to motion blur. Nonetheless, semantic segmentation with event cameras is still in its infancy which is chiefly due to the novelty of the sensor, and the lack of high-quality, labeled datasets. In this work, we introduce ESS, which tackles this problem by directly transferring the semantic segmentation task from existing labeled image datasets to unlabeled events via unsupervised domain adaptation (UDA). Compared to existing UDA methods, our approach aligns recurrent, motion-invariant event embeddings with image embeddings. For this reason, our method neither requires video data nor per-pixel alignment between images and events and, crucially, does not need to hallucinate motion from still images. Additionally, to spur further research in event-based semantic segmentation, we introduce DSEC-Semantic, the first large-scale event-based dataset with fine-grained labels. We show that using image labels alone, ESS outperforms existing UDA approaches, and when combined with event labels, it even outperforms state-of-the-art supervised approaches on both DDD17 and DSEC-Semantic. Finally, ESS is general-purpose, which unlocks the vast amount of existing labeled image datasets and paves the way for new and exciting research directions in new fields previously inaccessible for event cameras.
Egocentric Image Captioning for Privacy-Preserved Passive Dietary Intake Monitoring
Jul 01, 2021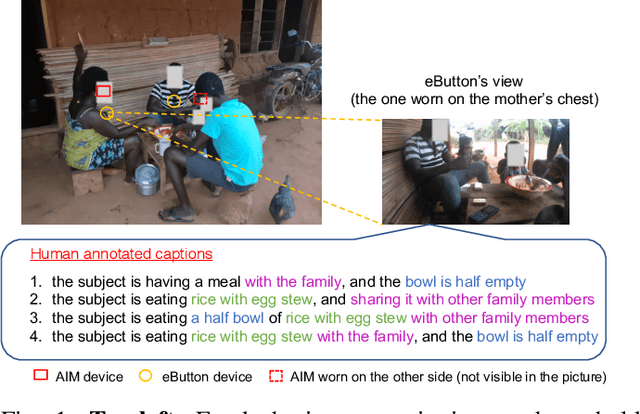
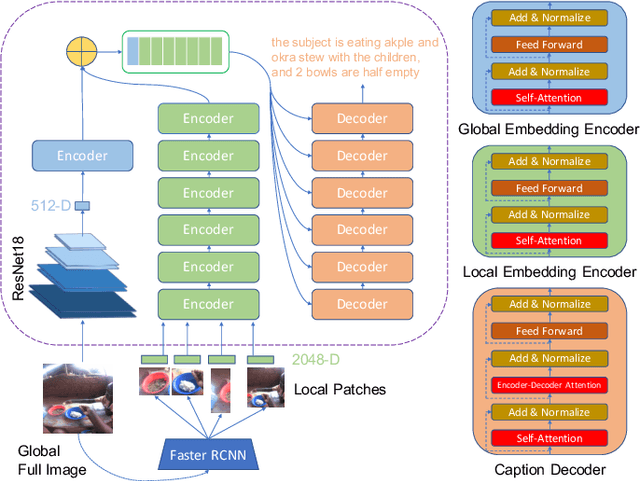
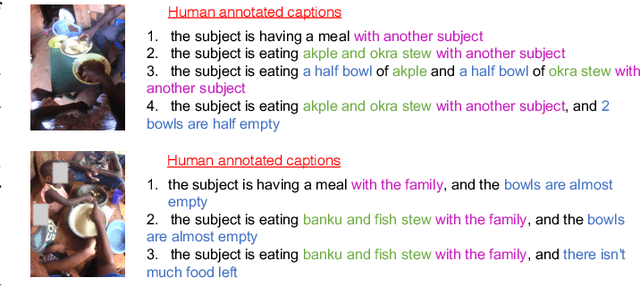
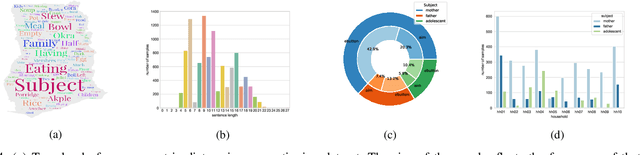
Camera-based passive dietary intake monitoring is able to continuously capture the eating episodes of a subject, recording rich visual information, such as the type and volume of food being consumed, as well as the eating behaviours of the subject. However, there currently is no method that is able to incorporate these visual clues and provide a comprehensive context of dietary intake from passive recording (e.g., is the subject sharing food with others, what food the subject is eating, and how much food is left in the bowl). On the other hand, privacy is a major concern while egocentric wearable cameras are used for capturing. In this paper, we propose a privacy-preserved secure solution (i.e., egocentric image captioning) for dietary assessment with passive monitoring, which unifies food recognition, volume estimation, and scene understanding. By converting images into rich text descriptions, nutritionists can assess individual dietary intake based on the captions instead of the original images, reducing the risk of privacy leakage from images. To this end, an egocentric dietary image captioning dataset has been built, which consists of in-the-wild images captured by head-worn and chest-worn cameras in field studies in Ghana. A novel transformer-based architecture is designed to caption egocentric dietary images. Comprehensive experiments have been conducted to evaluate the effectiveness and to justify the design of the proposed architecture for egocentric dietary image captioning. To the best of our knowledge, this is the first work that applies image captioning to dietary intake assessment in real life settings.
Deep Learning-Based Sparse Whole-Slide Image Analysis for the Diagnosis of Gastric Intestinal Metaplasia
Jan 05, 2022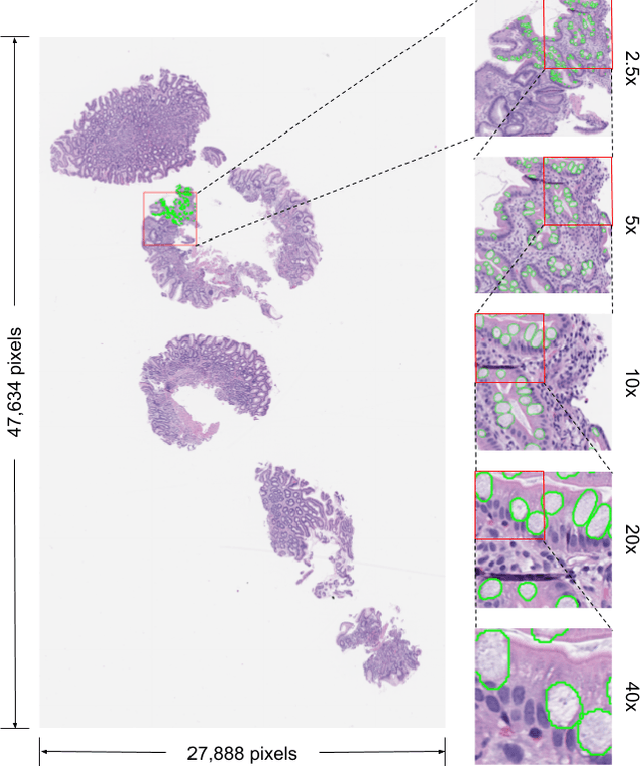
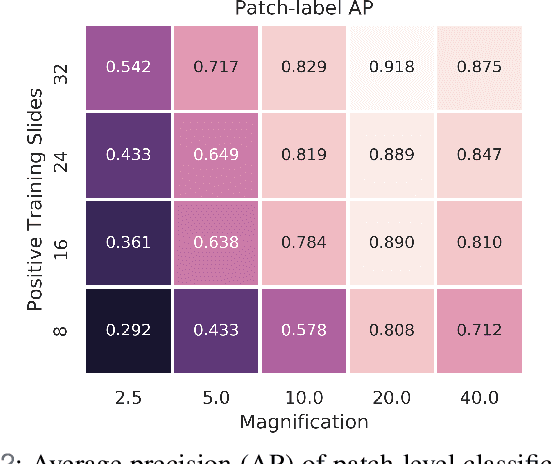
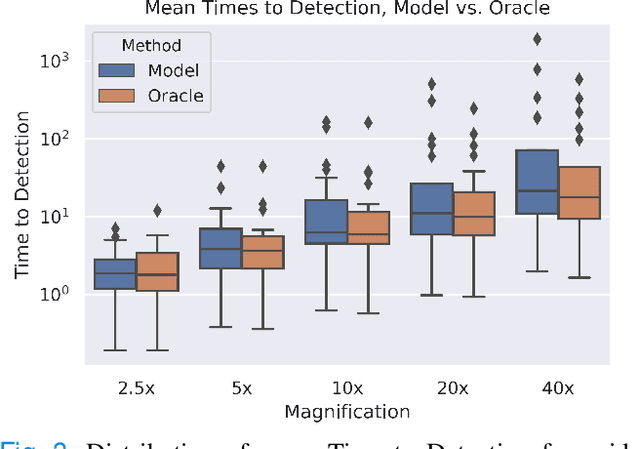
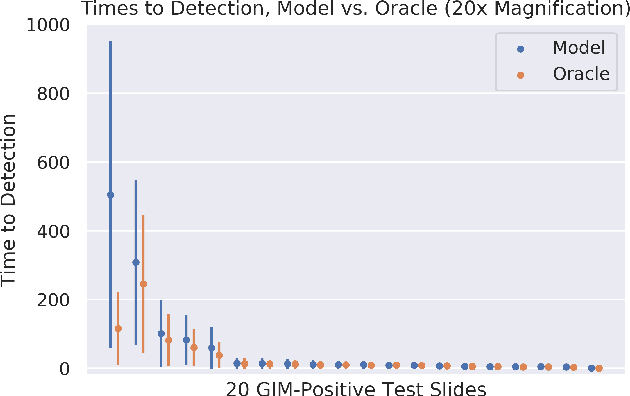
In recent years, deep learning has successfully been applied to automate a wide variety of tasks in diagnostic histopathology. However, fast and reliable localization of small-scale regions-of-interest (ROI) has remained a key challenge, as discriminative morphologic features often occupy only a small fraction of a gigapixel-scale whole-slide image (WSI). In this paper, we propose a sparse WSI analysis method for the rapid identification of high-power ROI for WSI-level classification. We develop an evaluation framework inspired by the early classification literature, in order to quantify the tradeoff between diagnostic performance and inference time for sparse analytic approaches. We test our method on a common but time-consuming task in pathology - that of diagnosing gastric intestinal metaplasia (GIM) on hematoxylin and eosin (H&E)-stained slides from endoscopic biopsy specimens. GIM is a well-known precursor lesion along the pathway to development of gastric cancer. We performed a thorough evaluation of the performance and inference time of our approach on a test set of GIM-positive and GIM-negative WSI, finding that our method successfully detects GIM in all positive WSI, with a WSI-level classification area under the receiver operating characteristic curve (AUC) of 0.98 and an average precision (AP) of 0.95. Furthermore, we show that our method can attain these metrics in under one minute on a standard CPU. Our results are applicable toward the goal of developing neural networks that can easily be deployed in clinical settings to support pathologists in quickly localizing and diagnosing small-scale morphologic features in WSI.
UTD-Yolov5: A Real-time Underwater Targets Detection Method based on Attention Improved YOLOv5
Jul 02, 2022
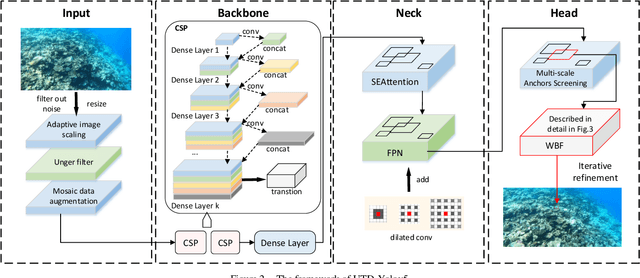
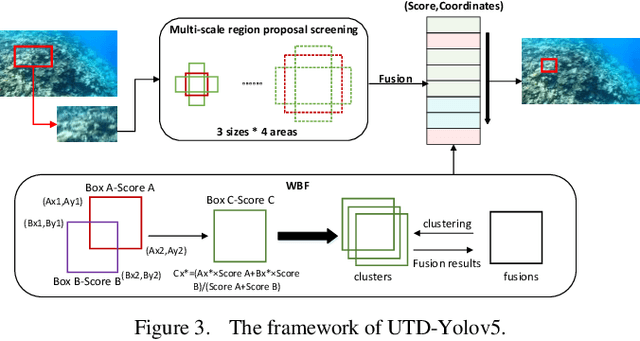

As the treasure house of nature, the ocean contains abundant resources. But the coral reefs, which are crucial to the sustainable development of marine life, are facing a huge crisis because of the existence of COTS and other organisms. The protection of society through manual labor is limited and inefficient. The unpredictable nature of the marine environment also makes manual operations risky. The use of robots for underwater operations has become a trend. However, the underwater image acquisition has defects such as weak light, low resolution, and many interferences, while the existing target detection algorithms are not effective. Based on this, we propose an underwater target detection algorithm based on Attention Improved YOLOv5, called UTD-Yolov5. It can quickly and efficiently detect COTS, which in turn provides a prerequisite for complex underwater operations. We adjusted the original network architecture of YOLOv5 in multiple stages, including: replacing the original Backbone with a two-stage cascaded CSP (CSP2); introducing the visual channel attention mechanism module SE; designing random anchor box similarity calculation method etc. These operations enable UTD-Yolov5 to detect more flexibly and capture features more accurately. In order to make the network more efficient, we also propose optimization methods such as WBF and iterative refinement mechanism. This paper conducts a lot of experiments based on the CSIRO dataset [1]. The results show that the average accuracy of our UTD-Yolov5 reaches 78.54%, which is a great improvement compared to the baseline.
Biologically inspired deep residual networks for computer vision applications
May 05, 2022
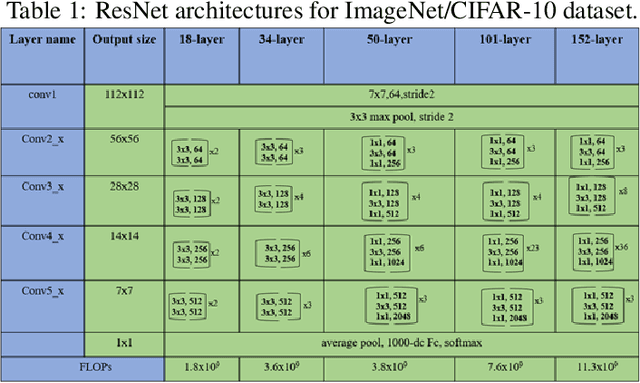

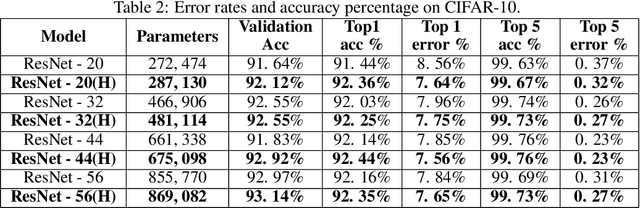
Deep neural network has been ensured as a key technology in the field of many challenging and vigorously researched computer vision tasks. Furthermore, classical ResNet is thought to be a state-of-the-art convolutional neural network (CNN) and was observed to capture features which can have good generalization ability. In this work, we propose a biologically inspired deep residual neural network where the hexagonal convolutions are introduced along the skip connections. The performance of different ResNet variants using square and hexagonal convolution are evaluated with the competitive training strategy mentioned by [1]. We show that the proposed approach advances the baseline image classification accuracy of vanilla ResNet architectures on CIFAR-10 and the same was observed over multiple subsets of the ImageNet 2012 dataset. We observed an average improvement by 1.35% and 0.48% on baseline top-1 accuracies for ImageNet 2012 and CIFAR-10, respectively. The proposed biologically inspired deep residual networks were observed to have improved generalized performance and this could be a potential research direction to improve the discriminative ability of state-of-the-art image classification networks.