 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Eye-gaze-guided Vision Transformer for Rectifying Shortcut Learning
May 25, 2022
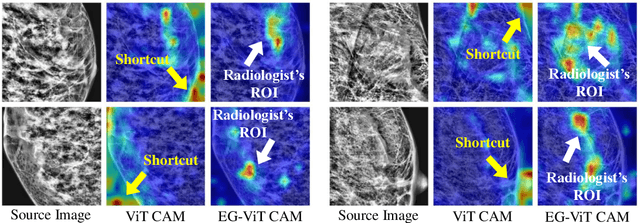
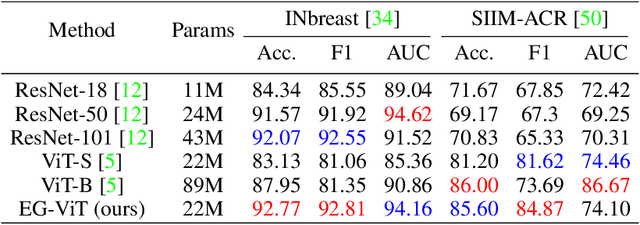
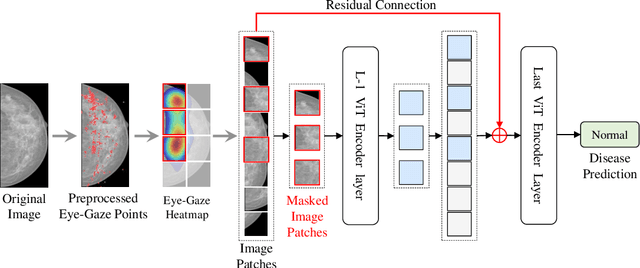
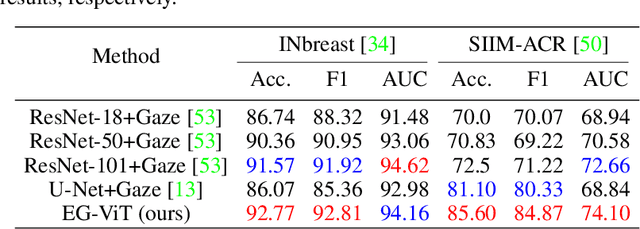
Learning harmful shortcuts such as spurious correlations and biases prevents deep neural networks from learning the meaningful and useful representations, thus jeopardizing the generalizability and interpretability of the learned representation. The situation becomes even more serious in medical imaging, where the clinical data (e.g., MR images with pathology) are limited and scarce while the reliability, generalizability and transparency of the learned model are highly required. To address this problem, we propose to infuse human experts' intelligence and domain knowledge into the training of deep neural networks. The core idea is that we infuse the visual attention information from expert radiologists to proactively guide the deep model to focus on regions with potential pathology and avoid being trapped in learning harmful shortcuts. To do so, we propose a novel eye-gaze-guided vision transformer (EG-ViT) for diagnosis with limited medical image data. We mask the input image patches that are out of the radiologists' interest and add an additional residual connection in the last encoder layer of EG-ViT to maintain the correlations of all patches. The experiments on two public datasets of INbreast and SIIM-ACR demonstrate our EG-ViT model can effectively learn/transfer experts' domain knowledge and achieve much better performance than baselines. Meanwhile, it successfully rectifies the harmful shortcut learning and significantly improves the EG-ViT model's interpretability. In general, EG-ViT takes the advantages of both human expert's prior knowledge and the power of deep neural networks. This work opens new avenues for advancing current artificial intelligence paradigms by infusing human intelligence.
Transferring Fairness under Distribution Shifts via Fair Consistency Regularization
Jun 26, 2022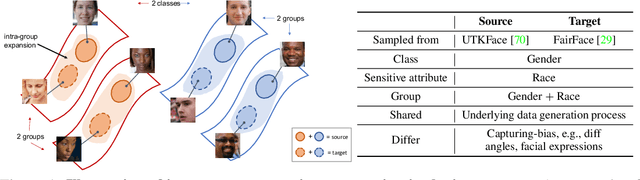
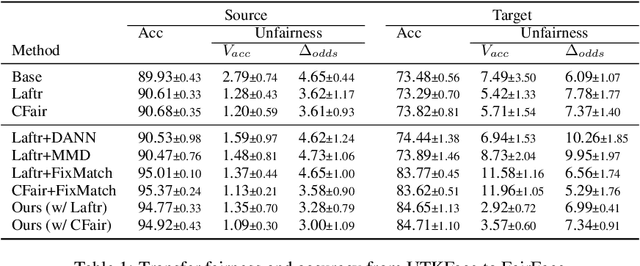
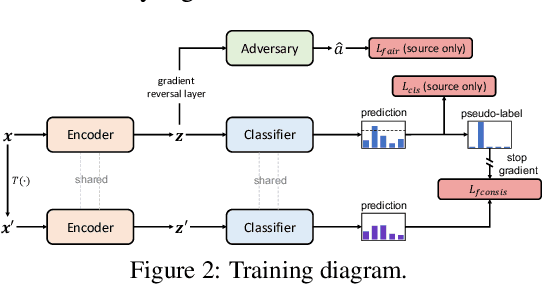
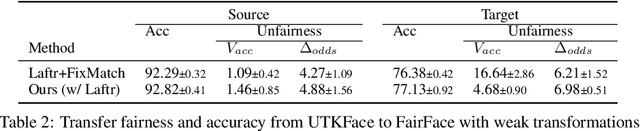
The increasing reliance on ML models in high-stakes tasks has raised a major concern on fairness violations. Although there has been a surge of work that improves algorithmic fairness, most of them are under the assumption of an identical training and test distribution. In many real-world applications, however, such an assumption is often violated as previously trained fair models are often deployed in a different environment, and the fairness of such models has been observed to collapse. In this paper, we study how to transfer model fairness under distribution shifts, a widespread issue in practice. We conduct a fine-grained analysis of how the fair model is affected under different types of distribution shifts and find that domain shifts are more challenging than subpopulation shifts. Inspired by the success of self-training in transferring accuracy under domain shifts, we derive a sufficient condition for transferring group fairness. Guided by it, we propose a practical algorithm with a fair consistency regularization as the key component. A synthetic dataset benchmark, which covers all types of distribution shifts, is deployed for experimental verification of the theoretical findings. Experiments on synthetic and real datasets including image and tabular data demonstrate that our approach effectively transfers fairness and accuracy under various distribution shifts.
Evaluating Contrastive Models for Instance-based Image Retrieval
Apr 30, 2021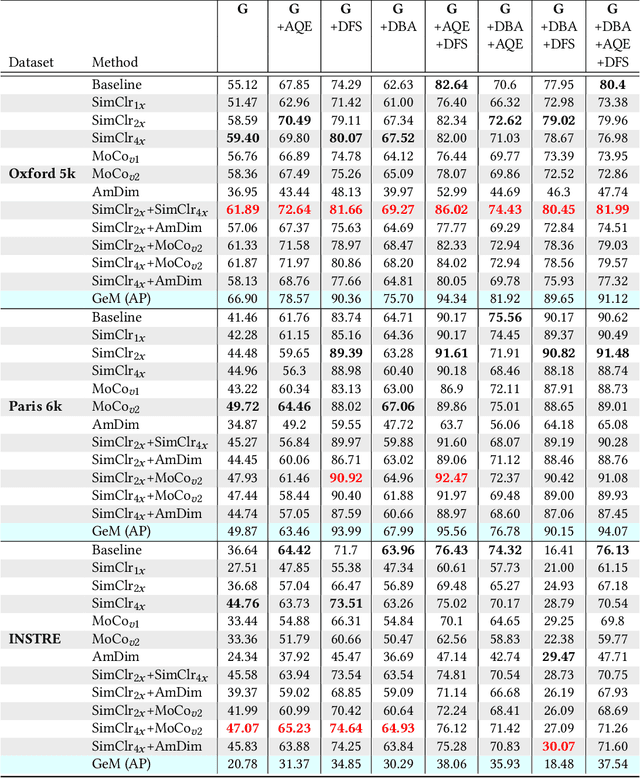
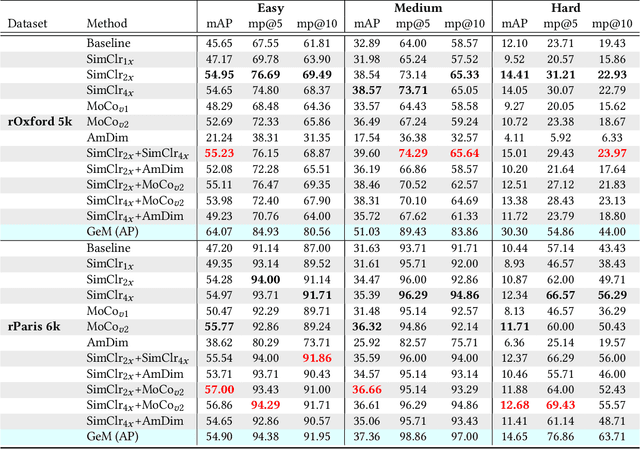
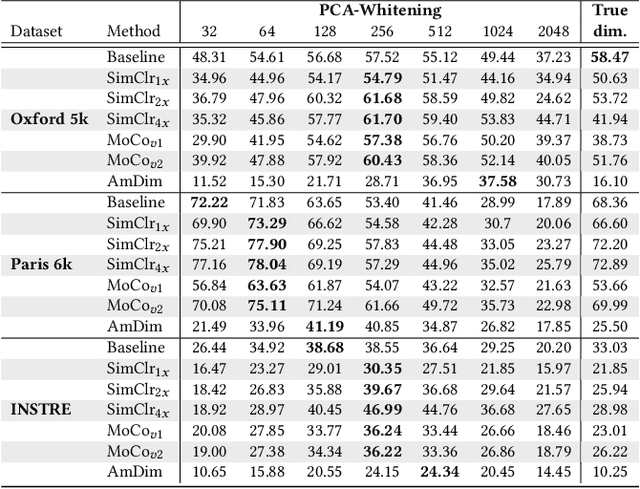
In this work, we evaluate contrastive models for the task of image retrieval. We hypothesise that models that are learned to encode semantic similarity among instances via discriminative learning should perform well on the task of image retrieval, where relevancy is defined in terms of instances of the same object. Through our extensive evaluation, we find that representations from models trained using contrastive methods perform on-par with (and outperforms) a pre-trained supervised baseline trained on the ImageNet labels in retrieval tasks under various configurations. This is remarkable given that the contrastive models require no explicit supervision. Thus, we conclude that these models can be used to bootstrap base models to build more robust image retrieval engines.
RAMS-Trans: Recurrent Attention Multi-scale Transformer forFine-grained Image Recognition
Jul 17, 2021
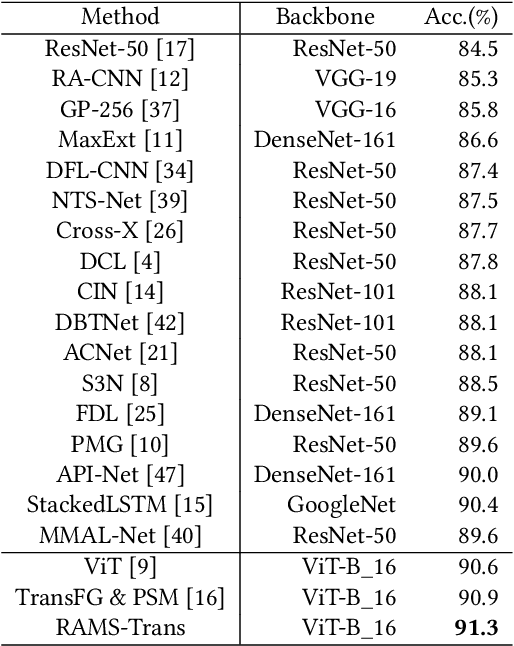
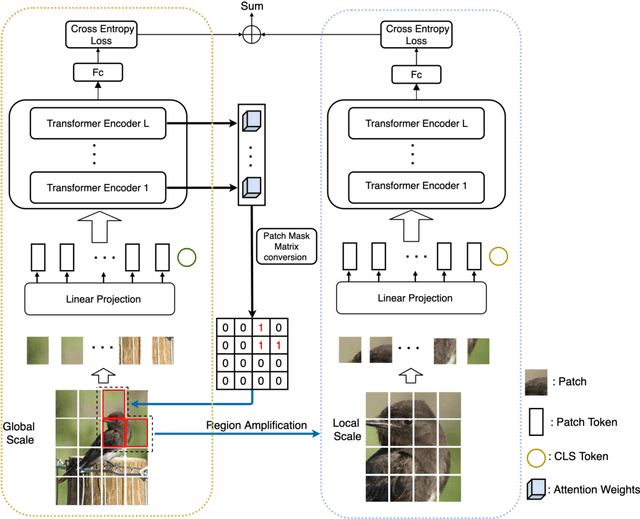
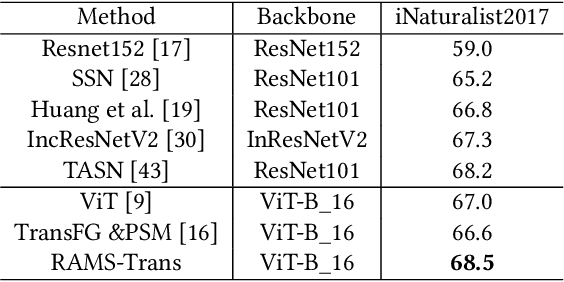
In fine-grained image recognition (FGIR), the localization and amplification of region attention is an important factor, which has been explored a lot by convolutional neural networks (CNNs) based approaches. The recently developed vision transformer (ViT) has achieved promising results on computer vision tasks. Compared with CNNs, Image sequentialization is a brand new manner. However, ViT is limited in its receptive field size and thus lacks local attention like CNNs due to the fixed size of its patches, and is unable to generate multi-scale features to learn discriminative region attention. To facilitate the learning of discriminative region attention without box/part annotations, we use the strength of the attention weights to measure the importance of the patch tokens corresponding to the raw images. We propose the recurrent attention multi-scale transformer (RAMS-Trans), which uses the transformer's self-attention to recursively learn discriminative region attention in a multi-scale manner. Specifically, at the core of our approach lies the dynamic patch proposal module (DPPM) guided region amplification to complete the integration of multi-scale image patches. The DPPM starts with the full-size image patches and iteratively scales up the region attention to generate new patches from global to local by the intensity of the attention weights generated at each scale as an indicator. Our approach requires only the attention weights that come with ViT itself and can be easily trained end-to-end. Extensive experiments demonstrate that RAMS-Trans performs better than concurrent works, in addition to efficient CNN models, achieving state-of-the-art results on three benchmark datasets.
Neural Fashion Image Captioning : Accounting for Data Diversity
Jun 24, 2021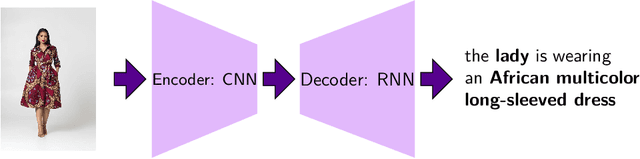
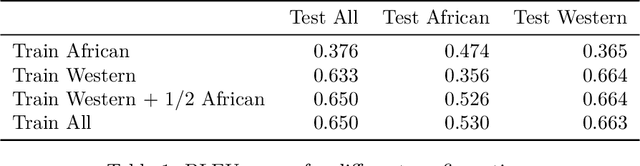

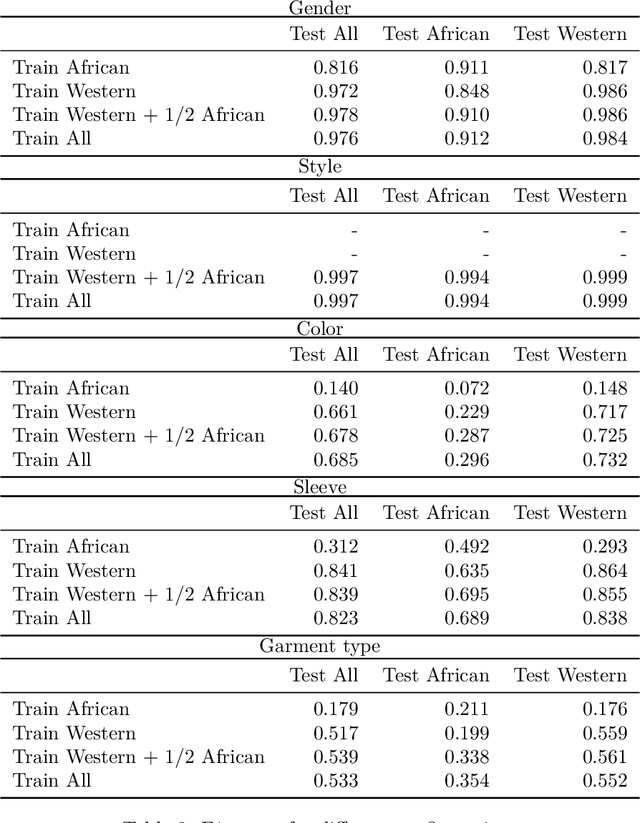
Image captioning has increasingly large domains of application, and fashion is not an exception. Having automatic item descriptions is of great interest for fashion web platforms hosting sometimes hundreds of thousands of images. This paper is one of the first tackling image captioning for fashion images. To contribute addressing dataset diversity issues, we introduced the InFashAIv1 dataset containing almost 16.000 African fashion item images with their titles, prices and general descriptions. We also used the well known DeepFashion dataset in addition to InFashAIv1. Captions are generated using the Show and Tell model made of CNN encoder and RNN Decoder. We showed that jointly training the model on both datasets improves captions quality for African style fashion images, suggesting a transfer learning from Western style data. The InFashAIv1 dataset is released on Github to encourage works with more diversity inclusion.
Cascade Image Matting with Deformable Graph Refinement
May 08, 2021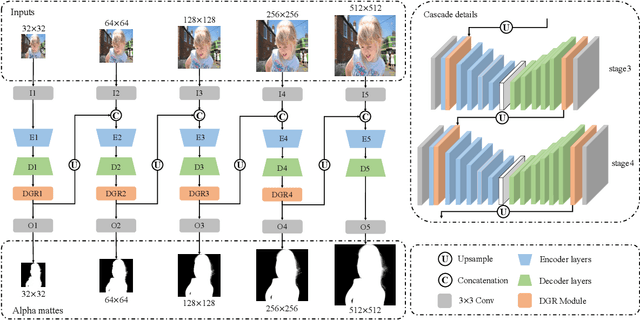
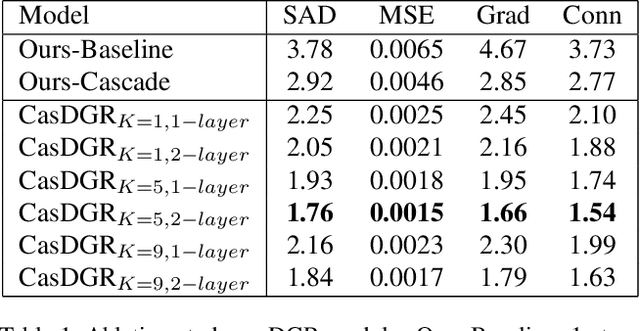
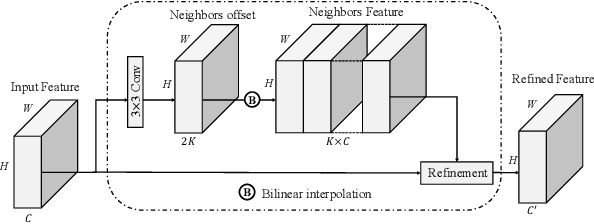
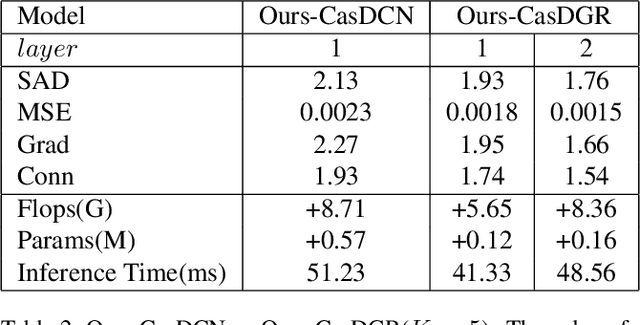
Image matting refers to the estimation of the opacity of foreground objects. It requires correct contours and fine details of foreground objects for the matting results. To better accomplish human image matting tasks, we propose the Cascade Image Matting Network with Deformable Graph Refinement, which can automatically predict precise alpha mattes from single human images without any additional inputs. We adopt a network cascade architecture to perform matting from low-to-high resolution, which corresponds to coarse-to-fine optimization. We also introduce the Deformable Graph Refinement (DGR) module based on graph neural networks (GNNs) to overcome the limitations of convolutional neural networks (CNNs). The DGR module can effectively capture long-range relations and obtain more global and local information to help produce finer alpha mattes. We also reduce the computation complexity of the DGR module by dynamically predicting the neighbors and apply DGR module to higher--resolution features. Experimental results demonstrate the ability of our CasDGR to achieve state-of-the-art performance on synthetic datasets and produce good results on real human images.
Pseudo-Stereo for Monocular 3D Object Detection in Autonomous Driving
Mar 04, 2022
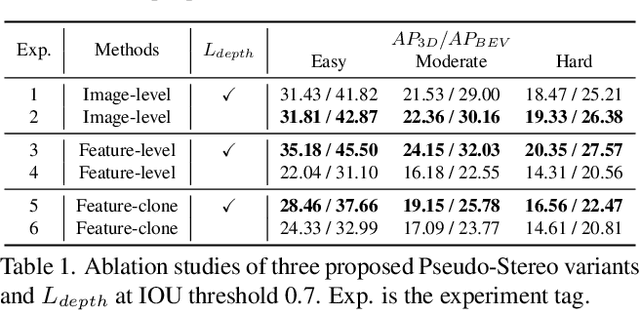
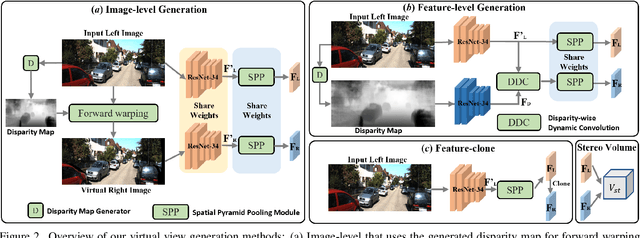
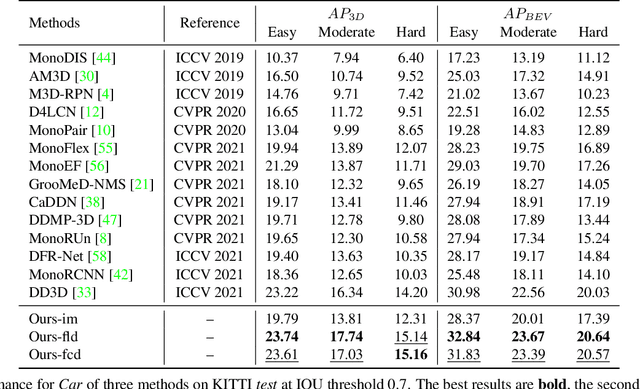
Pseudo-LiDAR 3D detectors have made remarkable progress in monocular 3D detection by enhancing the capability of perceiving depth with depth estimation networks, and using LiDAR-based 3D detection architectures. The advanced stereo 3D detectors can also accurately localize 3D objects. The gap in image-to-image generation for stereo views is much smaller than that in image-to-LiDAR generation. Motivated by this, we propose a Pseudo-Stereo 3D detection framework with three novel virtual view generation methods, including image-level generation, feature-level generation, and feature-clone, for detecting 3D objects from a single image. Our analysis of depth-aware learning shows that the depth loss is effective in only feature-level virtual view generation and the estimated depth map is effective in both image-level and feature-level in our framework. We propose a disparity-wise dynamic convolution with dynamic kernels sampled from the disparity feature map to filter the features adaptively from a single image for generating virtual image features, which eases the feature degradation caused by the depth estimation errors. Till submission (November 18, 2021), our Pseudo-Stereo 3D detection framework ranks 1st on car, pedestrian, and cyclist among the monocular 3D detectors with publications on the KITTI-3D benchmark. The code is released at https://github.com/revisitq/Pseudo-Stereo-3D.
Investigating Shift-Variance of Convolutional Neural Networks in Ultrasound Image Segmentation
Jul 22, 2021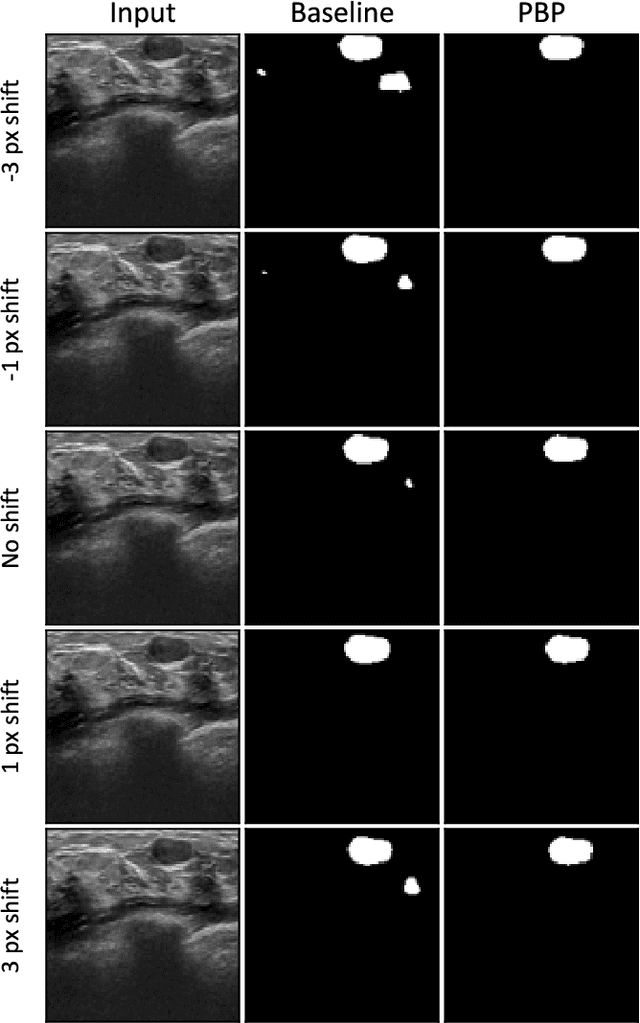
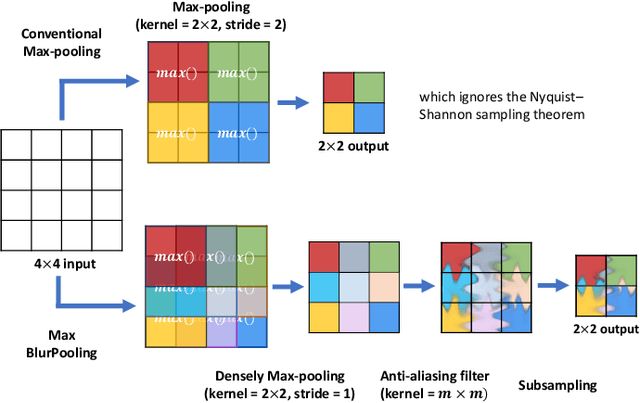
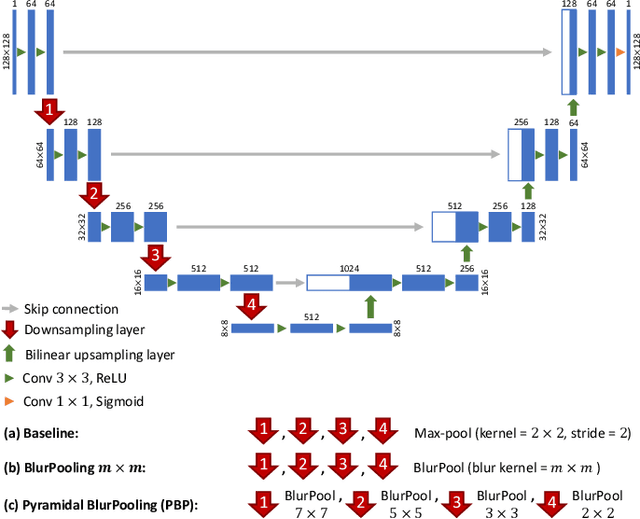
While accuracy is an evident criterion for ultrasound image segmentation, output consistency across different tests is equally crucial for tracking changes in regions of interest in applications such as monitoring the patients' response to treatment, measuring the progression or regression of the disease, reaching a diagnosis, or treatment planning. Convolutional neural networks (CNNs) have attracted rapidly growing interest in automatic ultrasound image segmentation recently. However, CNNs are not shift-equivariant, meaning that if the input translates, e.g., in the lateral direction by one pixel, the output segmentation may drastically change. To the best of our knowledge, this problem has not been studied in ultrasound image segmentation or even more broadly in ultrasound images. Herein, we investigate and quantify the shift-variance problem of CNNs in this application and further evaluate the performance of a recently published technique, called BlurPooling, for addressing the problem. In addition, we propose the Pyramidal BlurPooling method that outperforms BlurPooling in both output consistency and segmentation accuracy. Finally, we demonstrate that data augmentation is not a replacement for the proposed method. Source code is available at https://git.io/pbpunet and http://code.sonography.ai.
Segmentation Network with Compound Loss Function for Hydatidiform Mole Hydrops Lesion Recognition
Apr 11, 2022
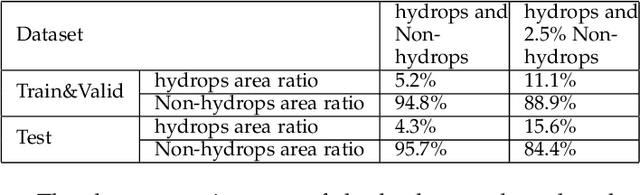

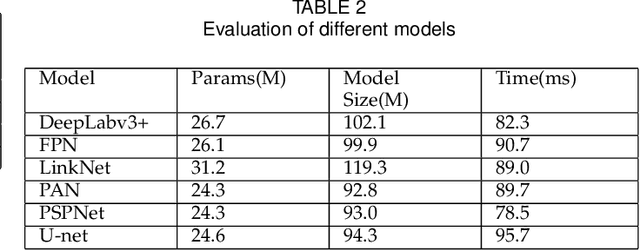
Pathological morphology diagnosis is the standard diagnosis method of hydatidiform mole. As a disease with malignant potential, the hydatidiform mole section of hydrops lesions is an important basis for diagnosis. Due to incomplete lesion development, early hydatidiform mole is difficult to distinguish, resulting in a low accuracy of clinical diagnosis. As a remarkable machine learning technology, image semantic segmentation networks have been used in many medical image recognition tasks. We developed a hydatidiform mole hydrops lesion segmentation model based on a novel loss function and training method. The model consists of different networks that segment the section image at the pixel and lesion levels. Our compound loss function assign weights to the segmentation results of the two levels to calculate the loss. We then propose a stagewise training method to combine the advantages of various loss functions at different levels. We evaluate our method on a hydatidiform mole hydrops dataset. Experiments show that the proposed model with our loss function and training method has good recognition performance under different segmentation metrics.
Optical modelling of accommodative light field display system and prediction of human eye responses
Apr 02, 2022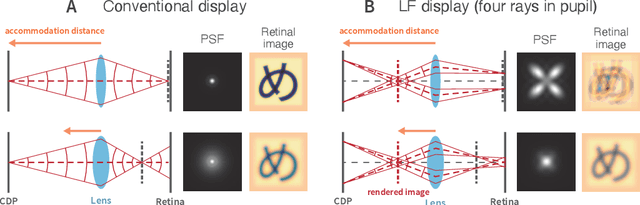
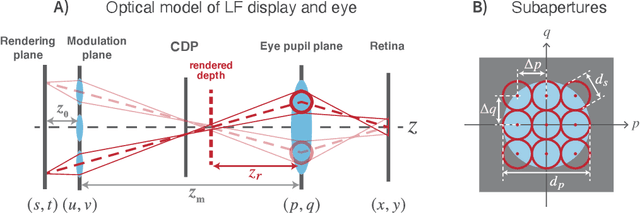
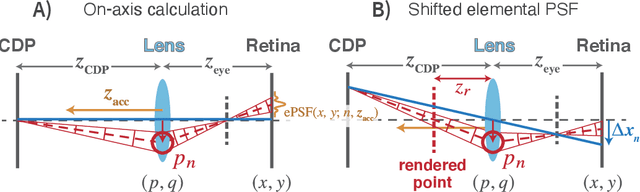
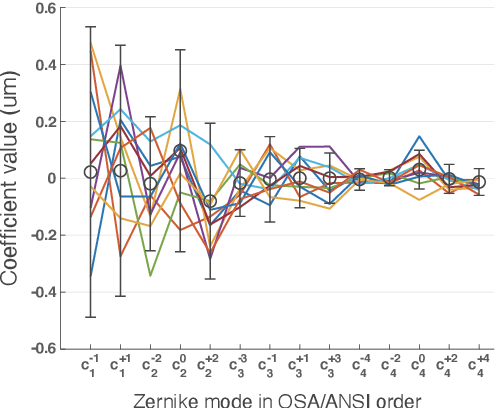
The spatio-angular resolution of a light field (LF) display is a crucial factor for delivering adequate spatial image quality and eliciting an accommodation response. Previous studies have modelled retinal image formation with an LF display and evaluated whether accommodation would be evoked correctly. The models were mostly based on ray-tracing and a schematic eye model, which pose computational complexity and inaccurately represent the human eye population's behaviour. We propose an efficient wave-optics-based framework to model the human eye and a general LF display. With the model, we simulated the retinal point spread function (PSF) of a point rendered by an LF display at various depths to characterise the retinal image quality. Additionally, accommodation responses to rendered LF images were estimated by computing the visual Strehl ratio based on the optical transfer function (VSOTF) from the PSFs. We assumed an ideal LF display that had an infinite spatial resolution and was free from optical aberrations in the simulation. We tested images rendered at 0--4 dioptres of depths having angular resolutions of up to 4x4 viewpoints within a pupil. The simulation predicted small and constant accommodation errors, which contradict the findings of previous studies. An evaluation of the optical resolution of the rendered retinal image suggested a trade-off between the maximum resolution achievable and the depth range of a rendered image where in-focus resolution is kept high. The proposed framework can be used to evaluate the upper bound of the optical performance of an LF display for realistically aberrated eyes, which may help to find an optimal spatio-angular resolution required to render a high quality 3D scene.