 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Neural Correlates of Image Texture in the Human Vision Using Magnetoencephalography
Nov 16, 2021
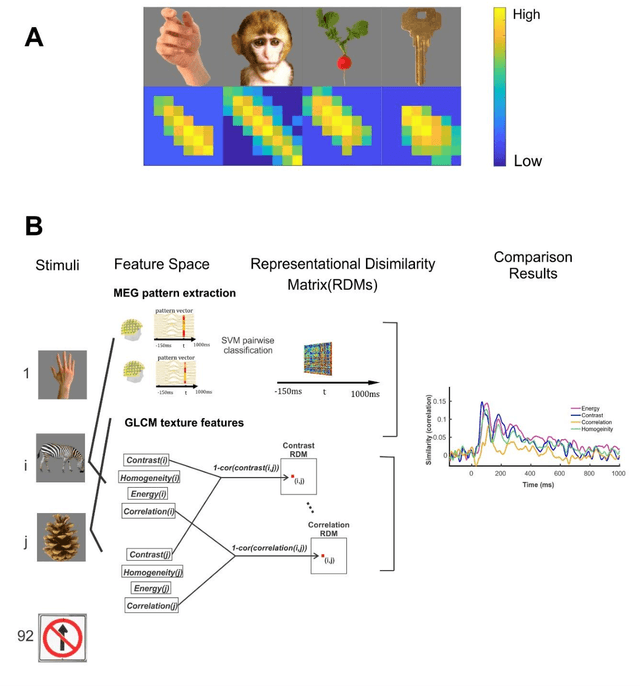
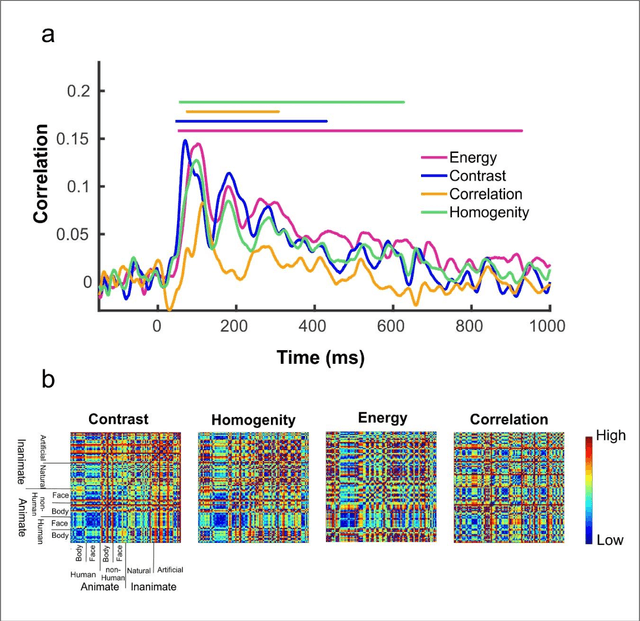
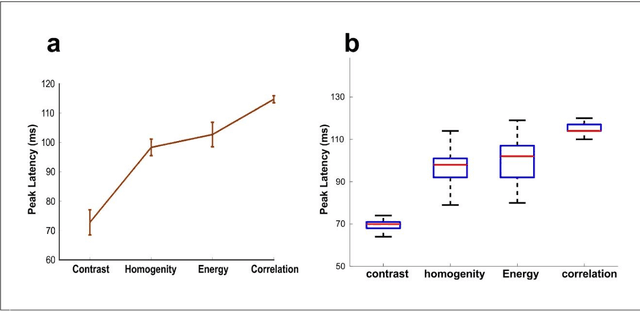
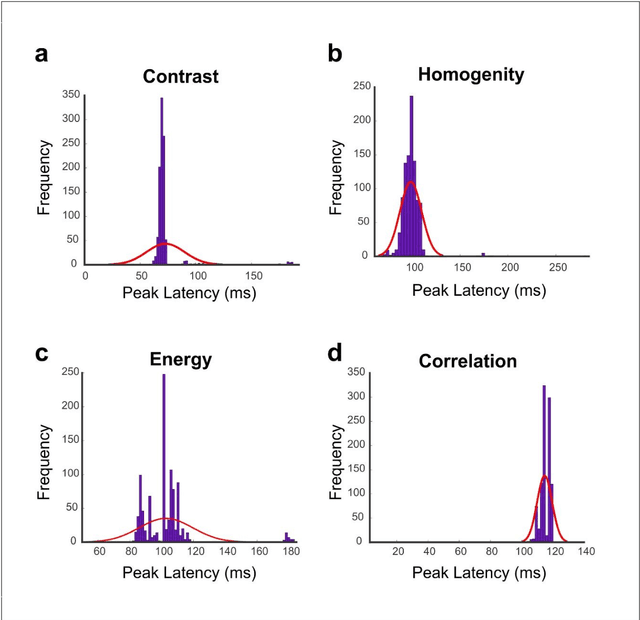
Undoubtedly, textural property of an image is one of the most important features in object recognition task in both human and computer vision applications. Here, we investigated the neural signatures of four well-known statistical texture features including contrast, homogeneity, energy, and correlation computed from the gray level co-occurrence matrix (GLCM) of the images viewed by the participants in the process of magnetoencephalography (MEG) data collection. To trace these features in the human visual system, we used multivariate pattern analysis (MVPA) and trained a linear support vector machine (SVM) classifier on every timepoint of MEG data representing the brain activity and compared it with the textural descriptors of images using the Spearman correlation. The result of this study demonstrates that hierarchical structure in the processing of these four texture descriptors in the human brain with the order of contrast, homogeneity, energy, and correlation. Additionally, we found that energy, which carries broad texture property of the images, shows a more sustained statistically meaningful correlation with the brain activity in the course of time.
CE-Dedup: Cost-Effective Convolutional Neural Nets Training based on Image Deduplication
Aug 23, 2021
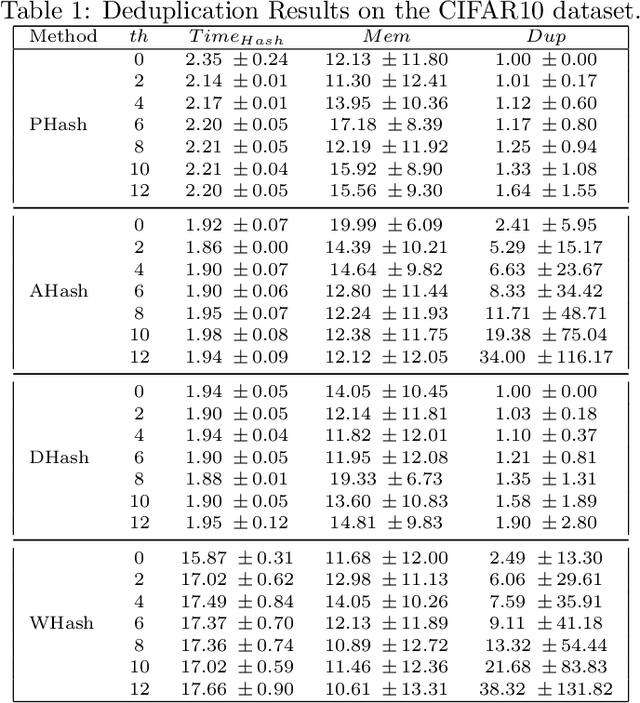

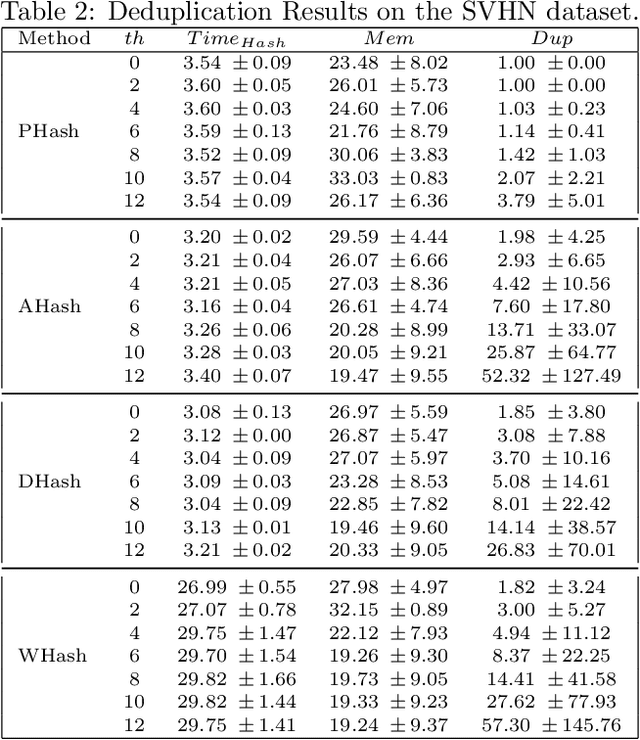
Attributed to the ever-increasing large image datasets, Convolutional Neural Networks (CNNs) have become popular for vision-based tasks. It is generally admirable to have larger-sized datasets for higher network training accuracies. However, the impact of dataset quality has not to be involved. It is reasonable to assume the near-duplicate images exist in the datasets. For instance, the Street View House Numbers (SVHN) dataset having cropped house plate digits from 0 to 9 are likely to have repetitive digits from the same/similar house plates. Redundant images may take up a certain portion of the dataset without consciousness. While contributing little to no accuracy improvement for the CNNs training, these duplicated images unnecessarily pose extra resource and computation consumption. To this end, this paper proposes a framework to assess the impact of the near-duplicate images on CNN training performance, called CE-Dedup. Specifically, CE-Dedup associates a hashing-based image deduplication approach with downstream CNNs-based image classification tasks. CE-Dedup balances the tradeoff between a large deduplication ratio and a stable accuracy by adjusting the deduplication threshold. The effectiveness of CE-Dedup is validated through extensive experiments on well-known CNN benchmarks. On one hand, while maintaining the same validation accuracy, CE-Dedup can reduce the dataset size by 23%. On the other hand, when allowing a small validation accuracy drop (by 5%), CE-Dedup can trim the dataset size by 75%.
Unseen Object 6D Pose Estimation: A Benchmark and Baselines
Jun 23, 2022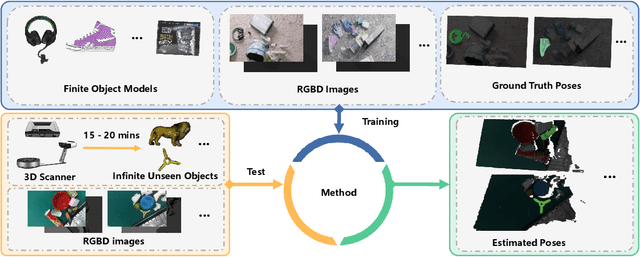
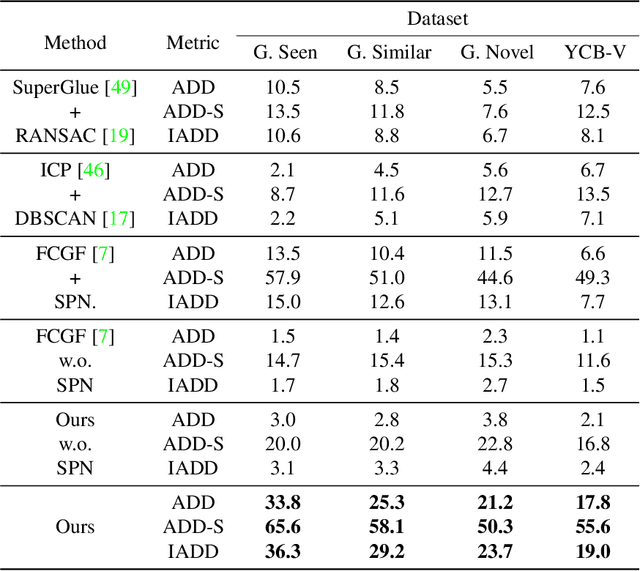

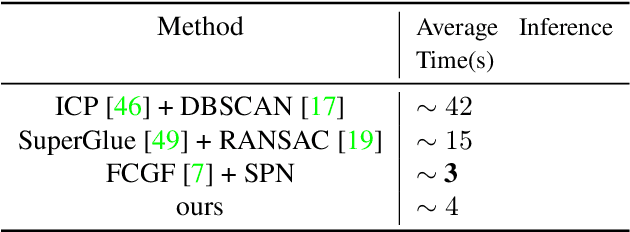
Estimating the 6D pose for unseen objects is in great demand for many real-world applications. However, current state-of-the-art pose estimation methods can only handle objects that are previously trained. In this paper, we propose a new task that enables and facilitates algorithms to estimate the 6D pose estimation of novel objects during testing. We collect a dataset with both real and synthetic images and up to 48 unseen objects in the test set. In the mean while, we propose a new metric named Infimum ADD (IADD) which is an invariant measurement for objects with different types of pose ambiguity. A two-stage baseline solution for this task is also provided. By training an end-to-end 3D correspondences network, our method finds corresponding points between an unseen object and a partial view RGBD image accurately and efficiently. It then calculates the 6D pose from the correspondences using an algorithm robust to object symmetry. Extensive experiments show that our method outperforms several intuitive baselines and thus verify its effectiveness. All the data, code and models will be made publicly available. Project page: www.graspnet.net/unseen6d
Diversifying Semantic Image Synthesis and Editing via Class- and Layer-wise VAEs
Jun 29, 2021Semantic image synthesis is a process for generating photorealistic images from a single semantic mask. To enrich the diversity of multimodal image synthesis, previous methods have controlled the global appearance of an output image by learning a single latent space. However, a single latent code is often insufficient for capturing various object styles because object appearance depends on multiple factors. To handle individual factors that determine object styles, we propose a class- and layer-wise extension to the variational autoencoder (VAE) framework that allows flexible control over each object class at the local to global levels by learning multiple latent spaces. Furthermore, we demonstrate that our method generates images that are both plausible and more diverse compared to state-of-the-art methods via extensive experiments with real and synthetic datasets inthree different domains. We also show that our method enables a wide range of applications in image synthesis and editing tasks.
A Systematic Collection of Medical Image Datasets for Deep Learning
Jun 24, 2021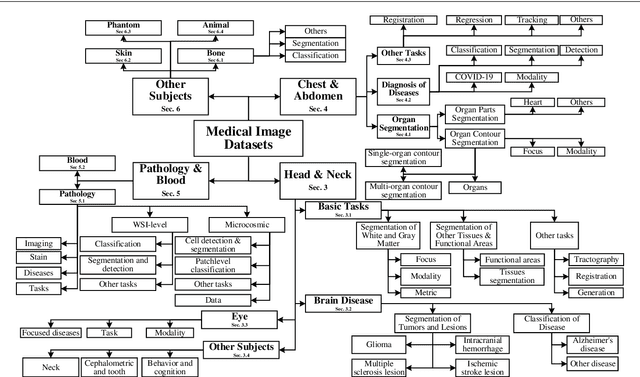
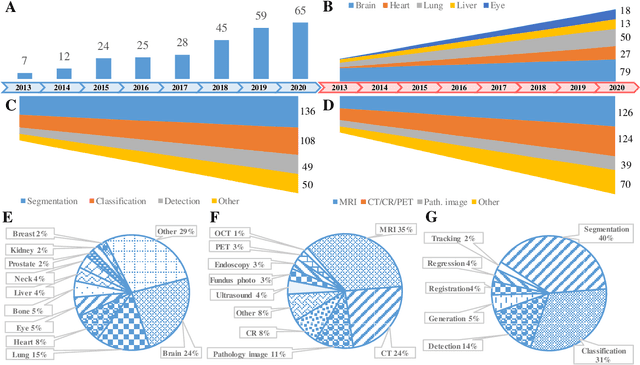
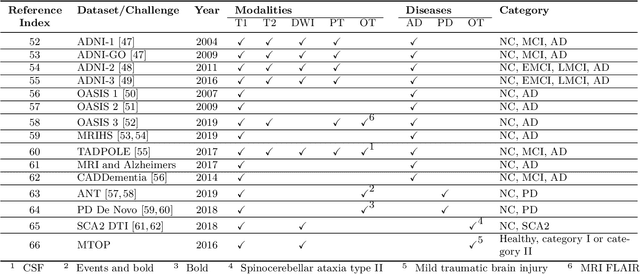
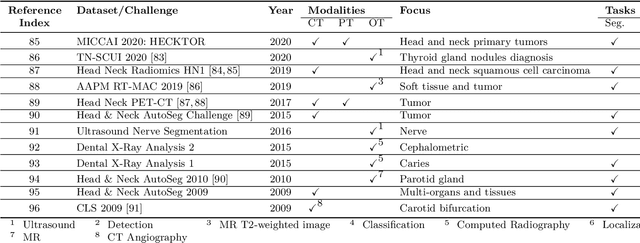
The astounding success made by artificial intelligence (AI) in healthcare and other fields proves that AI can achieve human-like performance. However, success always comes with challenges. Deep learning algorithms are data-dependent and require large datasets for training. The lack of data in the medical imaging field creates a bottleneck for the application of deep learning to medical image analysis. Medical image acquisition, annotation, and analysis are costly, and their usage is constrained by ethical restrictions. They also require many resources, such as human expertise and funding. That makes it difficult for non-medical researchers to have access to useful and large medical data. Thus, as comprehensive as possible, this paper provides a collection of medical image datasets with their associated challenges for deep learning research. We have collected information of around three hundred datasets and challenges mainly reported between 2013 and 2020 and categorized them into four categories: head & neck, chest & abdomen, pathology & blood, and ``others''. Our paper has three purposes: 1) to provide a most up to date and complete list that can be used as a universal reference to easily find the datasets for clinical image analysis, 2) to guide researchers on the methodology to test and evaluate their methods' performance and robustness on relevant datasets, 3) to provide a ``route'' to relevant algorithms for the relevant medical topics, and challenge leaderboards.
EFFGAN: Ensembles of fine-tuned federated GANs
Jun 23, 2022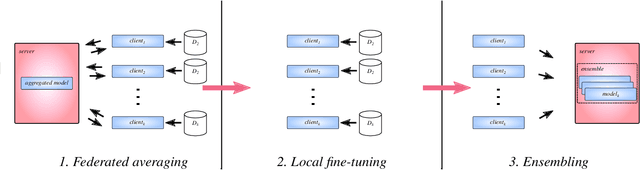


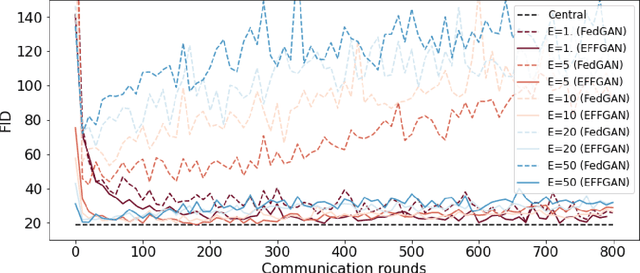
Generative adversarial networks have proven to be a powerful tool for learning complex and high-dimensional data distributions, but issues such as mode collapse have been shown to make it difficult to train them. This is an even harder problem when the data is decentralized over several clients in a federated learning setup, as problems such as client drift and non-iid data make it hard for federated averaging to converge. In this work, we study the task of how to learn a data distribution when training data is heterogeneously decentralized over clients and cannot be shared. Our goal is to sample from this distribution centrally, while the data never leaves the clients. We show using standard benchmark image datasets that existing approaches fail in this setting, experiencing so-called client drift when the local number of epochs becomes to large. We thus propose a novel approach we call EFFGAN: Ensembles of fine-tuned federated GANs. Being an ensemble of local expert generators, EFFGAN is able to learn the data distribution over all clients and mitigate client drift. It is able to train with a large number of local epochs, making it more communication efficient than previous works.
PhySRNet: Physics informed super-resolution network for application in computational solid mechanics
Jun 30, 2022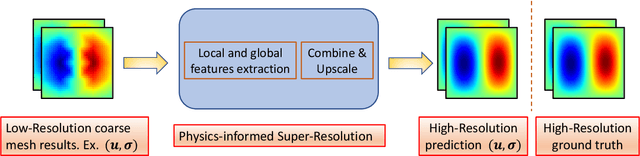
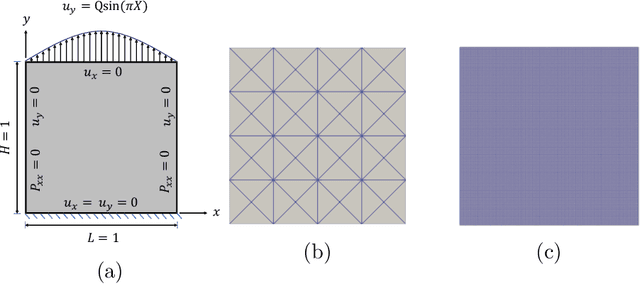
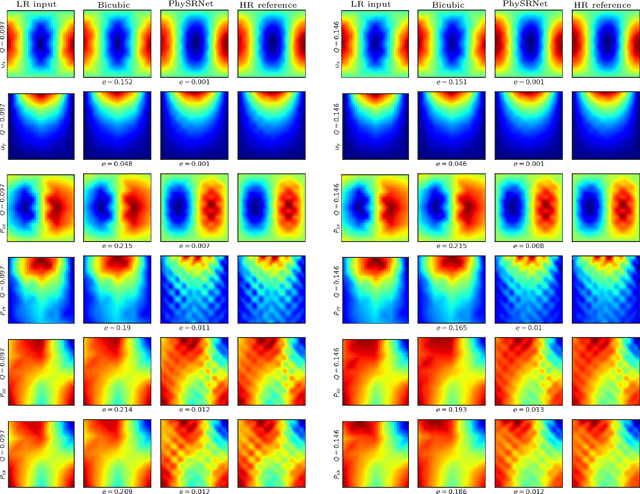
Traditional approaches based on finite element analyses have been successfully used to predict the macro-scale behavior of heterogeneous materials (composites, multicomponent alloys, and polycrystals) widely used in industrial applications. However, this necessitates the mesh size to be smaller than the characteristic length scale of the microstructural heterogeneities in the material leading to computationally expensive and time-consuming calculations. The recent advances in deep learning based image super-resolution (SR) algorithms open up a promising avenue to tackle this computational challenge by enabling researchers to enhance the spatio-temporal resolution of data obtained from coarse mesh simulations. However, technical challenges still remain in developing a high-fidelity SR model for application to computational solid mechanics, especially for materials undergoing large deformation. This work aims at developing a physics-informed deep learning based super-resolution framework (PhySRNet) which enables reconstruction of high-resolution deformation fields (displacement and stress) from their low-resolution counterparts without requiring high-resolution labeled data. We design a synthetic case study to illustrate the effectiveness of the proposed framework and demonstrate that the super-resolved fields match the accuracy of an advanced numerical solver running at 400 times the coarse mesh resolution while simultaneously satisfying the (highly nonlinear) governing laws. The approach opens the door to applying machine learning and traditional numerical approaches in tandem to reduce computational complexity accelerate scientific discovery and engineering design.
PolarFormer: Multi-camera 3D Object Detection with Polar Transformer
Jun 30, 2022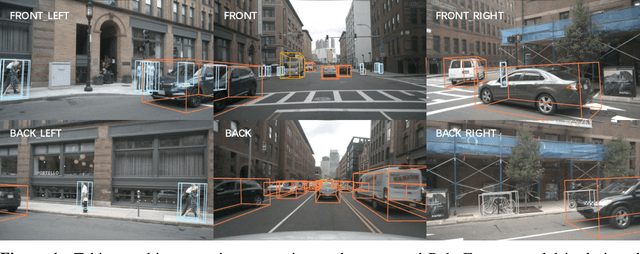
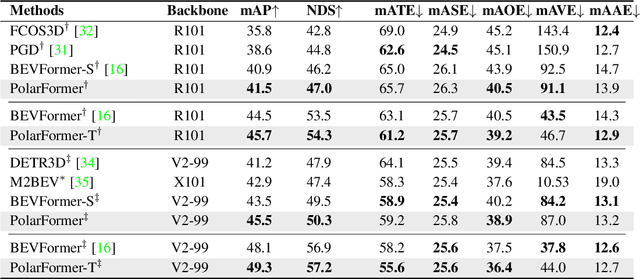
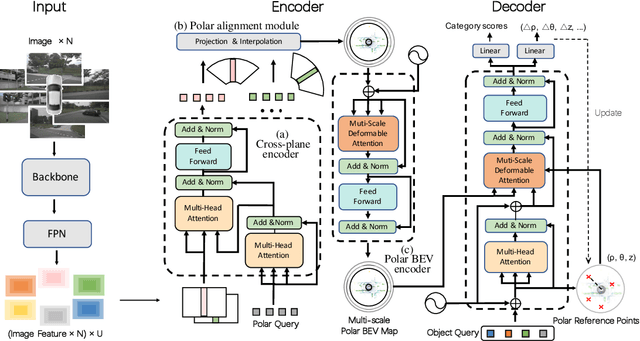
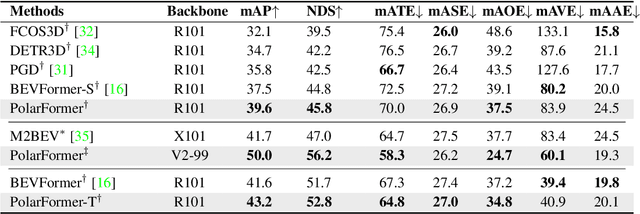
3D object detection in autonomous driving aims to reason "what" and "where" the objects of interest present in a 3D world. Following the conventional wisdom of previous 2D object detection, existing methods often adopt the canonical Cartesian coordinate system with perpendicular axis. However, we conjugate that this does not fit the nature of the ego car's perspective, as each onboard camera perceives the world in shape of wedge intrinsic to the imaging geometry with radical (non-perpendicular) axis. Hence, in this paper we advocate the exploitation of the Polar coordinate system and propose a new Polar Transformer (PolarFormer) for more accurate 3D object detection in the bird's-eye-view (BEV) taking as input only multi-camera 2D images. Specifically, we design a cross attention based Polar detection head without restriction to the shape of input structure to deal with irregular Polar grids. For tackling the unconstrained object scale variations along Polar's distance dimension, we further introduce a multi-scalePolar representation learning strategy. As a result, our model can make best use of the Polar representation rasterized via attending to the corresponding image observation in a sequence-to-sequence fashion subject to the geometric constraints. Thorough experiments on the nuScenes dataset demonstrate that our PolarFormer outperforms significantly state-of-the-art 3D object detection alternatives, as well as yielding competitive performance on BEV semantic segmentation task.
Transformers Meet Visual Learning Understanding: A Comprehensive Review
Mar 24, 2022
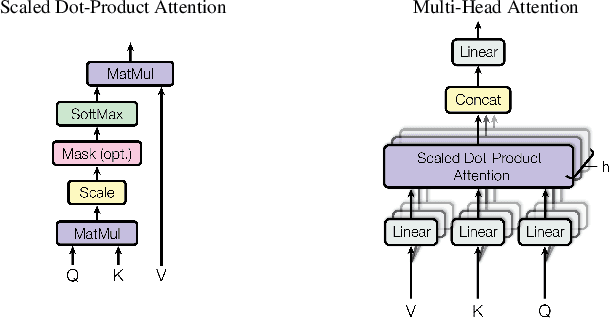
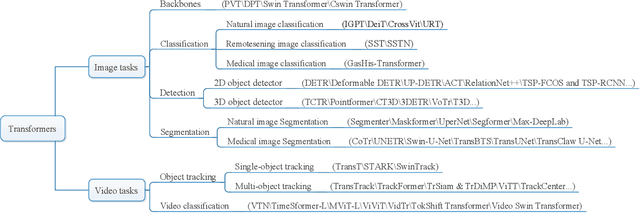
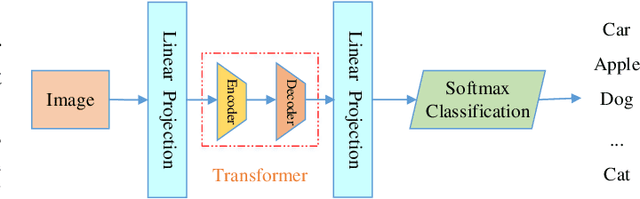
Dynamic attention mechanism and global modeling ability make Transformer show strong feature learning ability. In recent years, Transformer has become comparable to CNNs methods in computer vision. This review mainly investigates the current research progress of Transformer in image and video applications, which makes a comprehensive overview of Transformer in visual learning understanding. First, the attention mechanism is reviewed, which plays an essential part in Transformer. And then, the visual Transformer model and the principle of each module are introduced. Thirdly, the existing Transformer-based models are investigated, and their performance is compared in visual learning understanding applications. Three image tasks and two video tasks of computer vision are investigated. The former mainly includes image classification, object detection, and image segmentation. The latter contains object tracking and video classification. It is significant for comparing different models' performance in various tasks on several public benchmark data sets. Finally, ten general problems are summarized, and the developing prospects of the visual Transformer are given in this review.
TriHorn-Net: A Model for Accurate Depth-Based 3D Hand Pose Estimation
Jun 14, 2022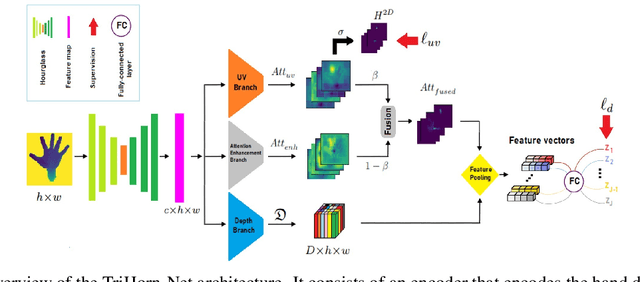

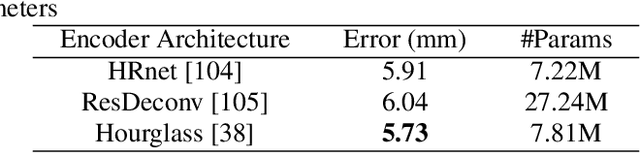
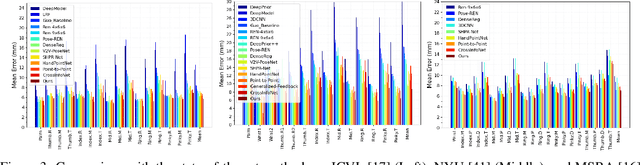
3D hand pose estimation methods have made significant progress recently. However, estimation accuracy is often far from sufficient for specific real-world applications, and thus there is significant room for improvement. This paper proposes TriHorn-Net, a novel model that uses specific innovations to improve hand pose estimation accuracy on depth images. The first innovation is the decomposition of the 3D hand pose estimation into the estimation of 2D joint locations in the depth image space (UV), and the estimation of their corresponding depths aided by two complementary attention maps. This decomposition prevents depth estimation, which is a more difficult task, from interfering with the UV estimations at both the prediction and feature levels. The second innovation is PixDropout, which is, to the best of our knowledge, the first appearance-based data augmentation method for hand depth images. Experimental results demonstrate that the proposed model outperforms the state-of-the-art methods on three public benchmark datasets.