 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Contrastive Learning of Image Representations with Cross-Video Cycle-Consistency
May 13, 2021
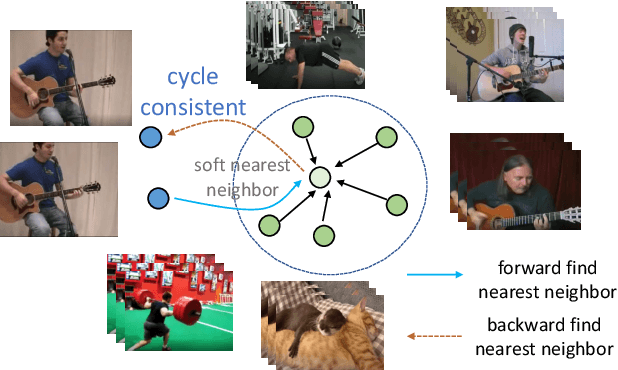
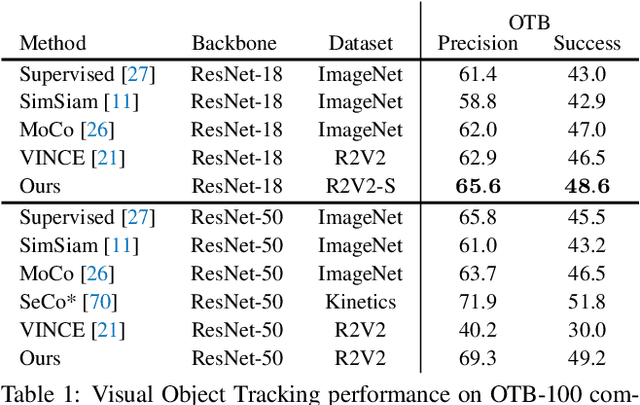
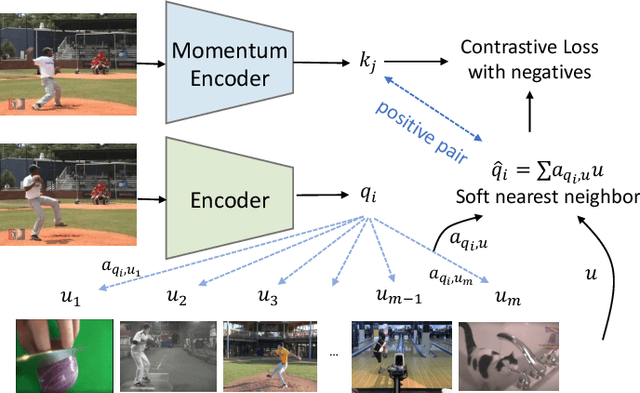
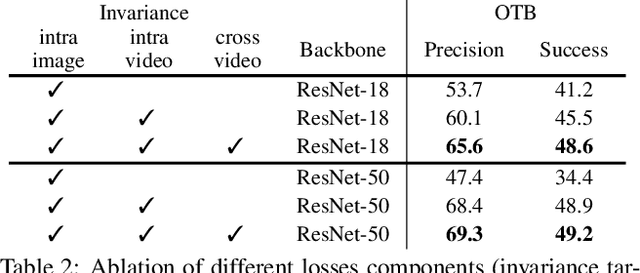
Recent works have advanced the performance of self-supervised representation learning by a large margin. The core among these methods is intra-image invariance learning. Two different transformations of one image instance are considered as a positive sample pair, where various tasks are designed to learn invariant representations by comparing the pair. Analogically, for video data, representations of frames from the same video are trained to be closer than frames from other videos, i.e. intra-video invariance. However, cross-video relation has barely been explored for visual representation learning. Unlike intra-video invariance, ground-truth labels of cross-video relation is usually unavailable without human labors. In this paper, we propose a novel contrastive learning method which explores the cross-video relation by using cycle-consistency for general image representation learning. This allows to collect positive sample pairs across different video instances, which we hypothesize will lead to higher-level semantics. We validate our method by transferring our image representation to multiple downstream tasks including visual object tracking, image classification, and action recognition. We show significant improvement over state-of-the-art contrastive learning methods. Project page is available at https://happywu.github.io/cycle_contrast_video.
A Robust Backpropagation-Free Framework for Images
Jun 03, 2022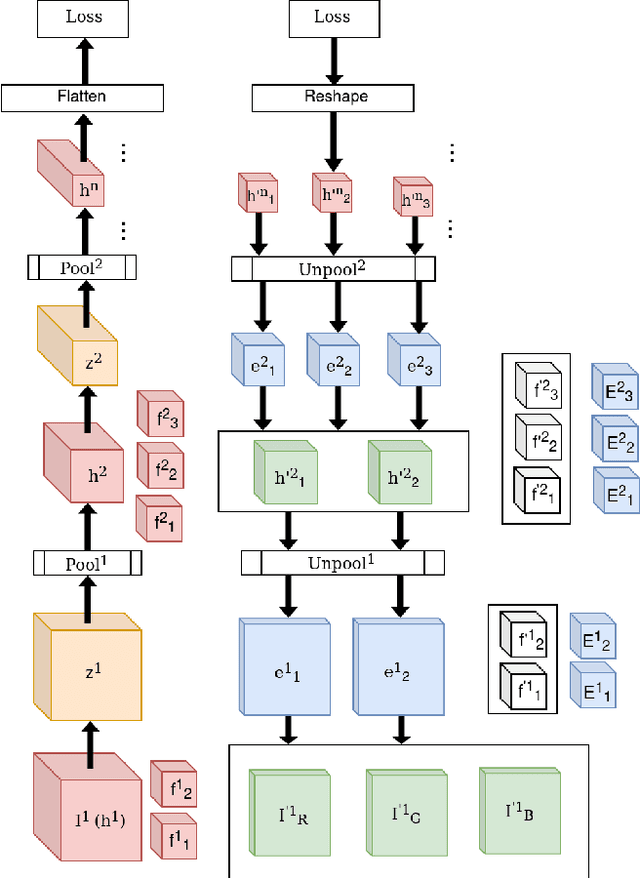
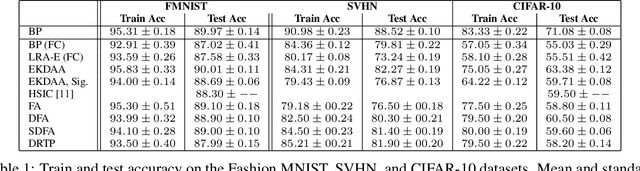
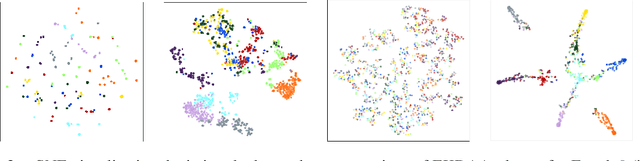
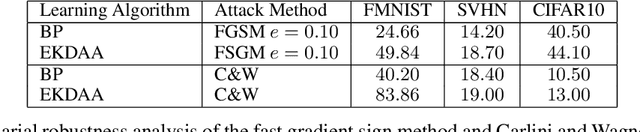
While current deep learning algorithms have been successful for a wide variety of artificial intelligence (AI) tasks, including those involving structured image data, they present deep neurophysiological conceptual issues due to their reliance on the gradients computed by backpropagation of errors (backprop) to obtain synaptic weight adjustments; hence are biologically implausible. We present a more biologically plausible approach, the error-kernel driven activation alignment (EKDAA) algorithm, to train convolution neural networks (CNNs) using locally derived error transmission kernels and error maps. We demonstrate the efficacy of EKDAA by performing the task of visual-recognition on the Fashion MNIST, CIFAR-10 and SVHN benchmarks as well as conducting blackbox robustness tests on adversarial examples derived from these datasets. Furthermore, we also present results for a CNN trained using a non-differentiable activation function. All recognition results nearly matches that of backprop and exhibit greater adversarial robustness compared to backprop.
Restore from Restored: Single-image Inpainting
Feb 16, 2021
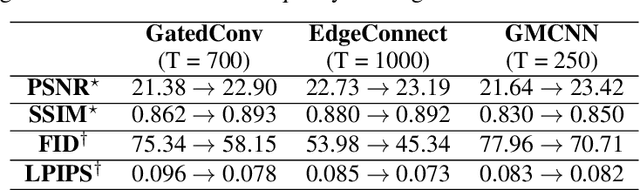
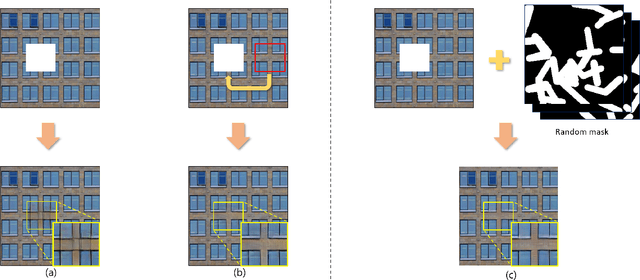
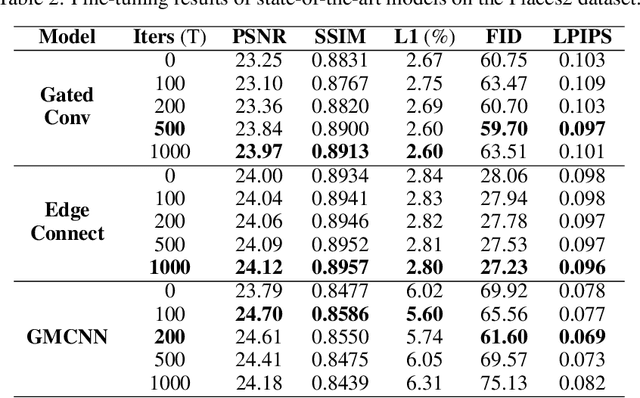
Recent image inpainting methods show promising results due to the power of deep learning, which can explore external information available from a large training dataset. However, many state-of-the-art inpainting networks are still limited in exploiting internal information available in the given input image at test time. To mitigate this problem, we present a novel and efficient self-supervised fine-tuning algorithm that can adapt the parameters of fully pretrained inpainting networks without using ground-truth clean image in this work. We upgrade the parameters of the pretrained networks by utilizing existing self-similar patches within the given input image without changing network architectures. Qualitative and quantitative experimental results demonstrate the superiority of the proposed algorithm and we achieve state-of-the-art inpainting results on publicly available numerous benchmark datasets.
Transductive image segmentation: Self-training and effect of uncertainty estimation
Aug 02, 2021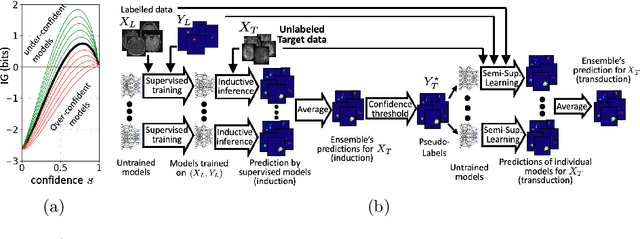

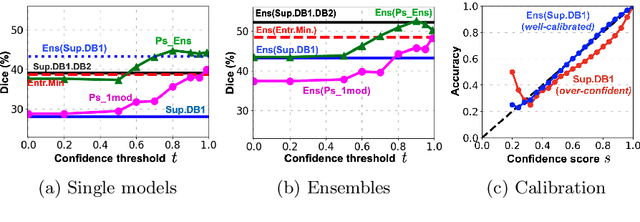
Semi-supervised learning (SSL) uses unlabeled data during training to learn better models. Previous studies on SSL for medical image segmentation focused mostly on improving model generalization to unseen data. In some applications, however, our primary interest is not generalization but to obtain optimal predictions on a specific unlabeled database that is fully available during model development. Examples include population studies for extracting imaging phenotypes. This work investigates an often overlooked aspect of SSL, transduction. It focuses on the quality of predictions made on the unlabeled data of interest when they are included for optimization during training, rather than improving generalization. We focus on the self-training framework and explore its potential for transduction. We analyze it through the lens of Information Gain and reveal that learning benefits from the use of calibrated or under-confident models. Our extensive experiments on a large MRI database for multi-class segmentation of traumatic brain lesions shows promising results when comparing transductive with inductive predictions. We believe this study will inspire further research on transductive learning, a well-suited paradigm for medical image analysis.
PISE: Person Image Synthesis and Editing with Decoupled GAN
Mar 31, 2021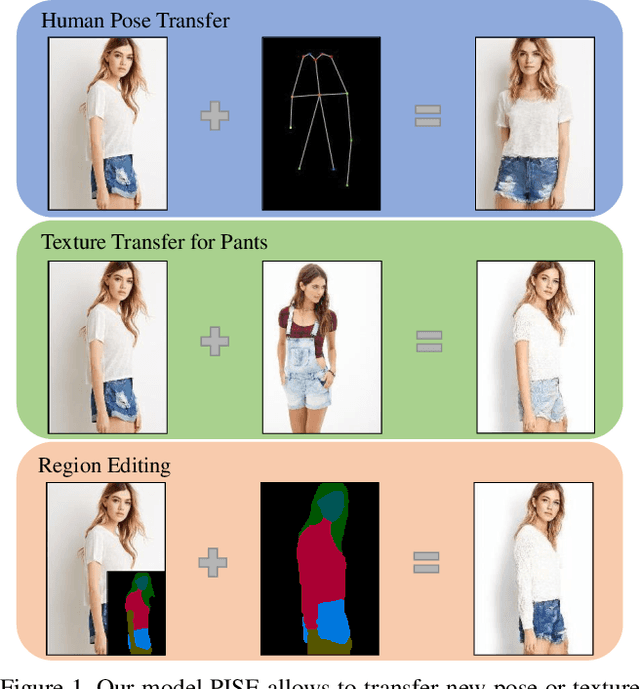
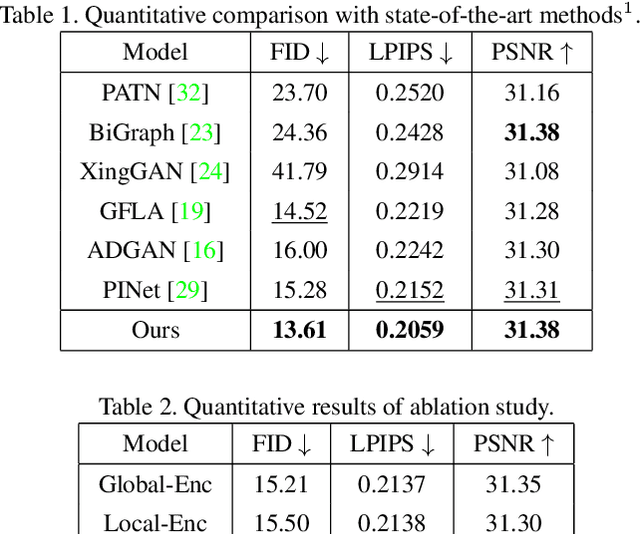
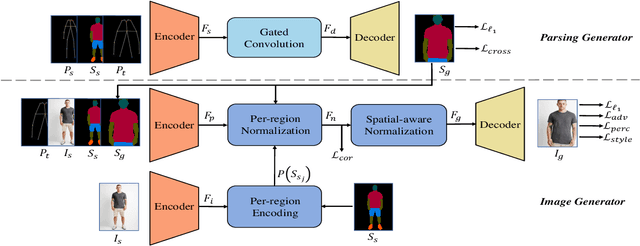
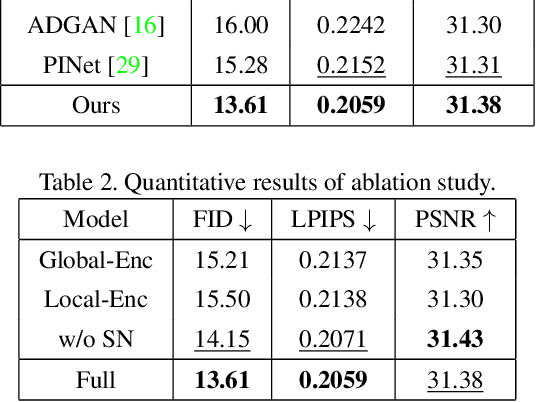
Person image synthesis, e.g., pose transfer, is a challenging problem due to large variation and occlusion. Existing methods have difficulties predicting reasonable invisible regions and fail to decouple the shape and style of clothing, which limits their applications on person image editing. In this paper, we propose PISE, a novel two-stage generative model for Person Image Synthesis and Editing, which is able to generate realistic person images with desired poses, textures, or semantic layouts. For human pose transfer, we first synthesize a human parsing map aligned with the target pose to represent the shape of clothing by a parsing generator, and then generate the final image by an image generator. To decouple the shape and style of clothing, we propose joint global and local per-region encoding and normalization to predict the reasonable style of clothing for invisible regions. We also propose spatial-aware normalization to retain the spatial context relationship in the source image. The results of qualitative and quantitative experiments demonstrate the superiority of our model on human pose transfer. Besides, the results of texture transfer and region editing show that our model can be applied to person image editing.
Human vs Objective Evaluation of Colourisation Performance
Apr 11, 2022
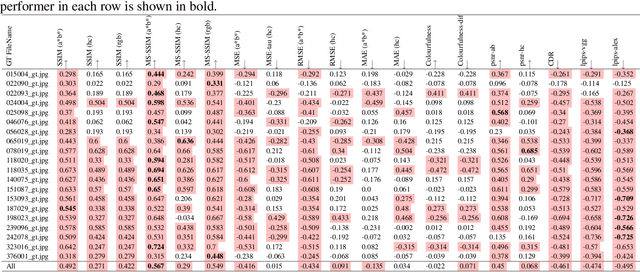
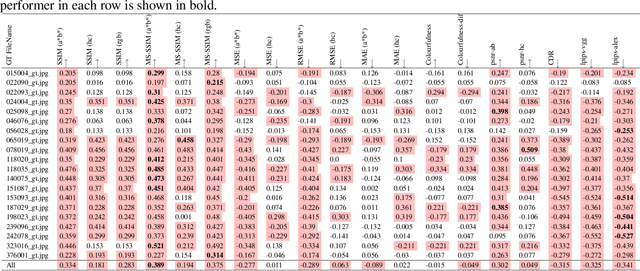
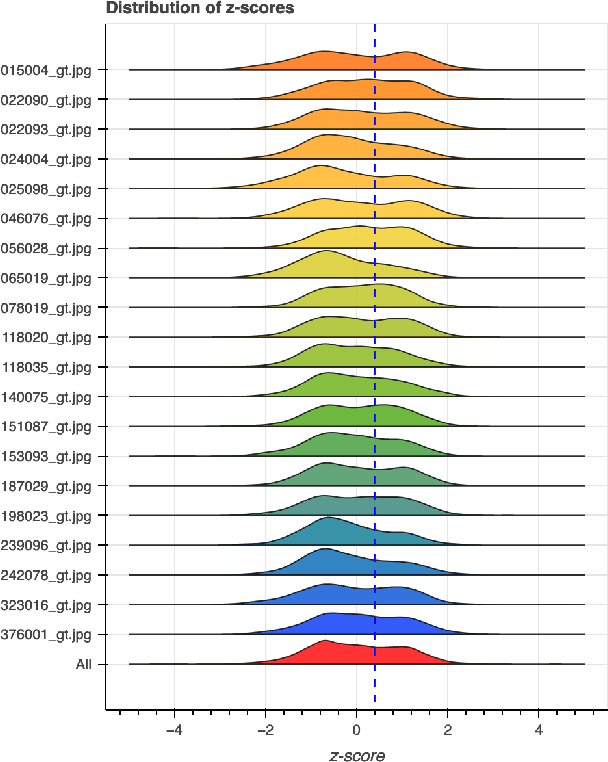
Automatic colourisation of grey-scale images is the process of creating a full-colour image from the grey-scale prior. It is an ill-posed problem, as there are many plausible colourisations for a given grey-scale prior. The current SOTA in auto-colourisation involves image-to-image type Deep Convolutional Neural Networks with Generative Adversarial Networks showing the greatest promise. The end goal of colourisation is to produce full colour images that appear plausible to the human viewer, but human assessment is costly and time consuming. This work assesses how well commonly used objective measures correlate with human opinion. We also attempt to determine what facets of colourisation have the most significant effect on human opinion. For each of 20 images from the BSD dataset, we create 65 recolourisations made up of local and global changes. Opinion scores are then crowd sourced using the Amazon Mechanical Turk and together with the images this forms an extensible dataset called the Human Evaluated Colourisation Dataset (HECD). While we find statistically significant correlations between human-opinion scores and a small number of objective measures, the strength of the correlations is low. There is also evidence that human observers are most intolerant to an incorrect hue of naturally occurring objects.
Segmenting Medical Instruments in Minimally Invasive Surgeries using AttentionMask
Mar 21, 2022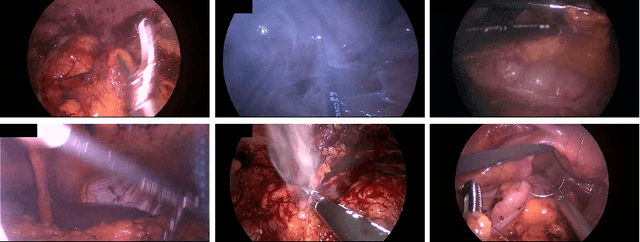
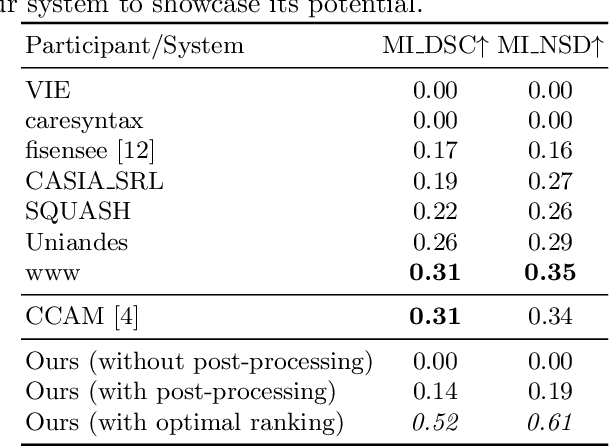
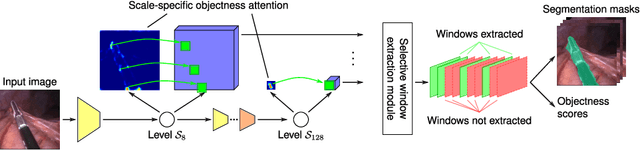
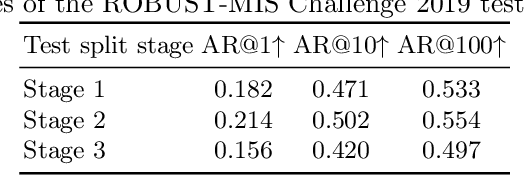
Precisely locating and segmenting medical instruments in images of minimally invasive surgeries, medical instrument segmentation, is an essential first step for several tasks in medical image processing. However, image degradations, small instruments, and the generalization between different surgery types make medical instrument segmentation challenging. To cope with these challenges, we adapt the object proposal generation system AttentionMask and propose a dedicated post-processing to select promising proposals. The results on the ROBUST-MIS Challenge 2019 show that our adapted AttentionMask system is a strong foundation for generating state-of-the-art performance. Our evaluation in an object proposal generation framework shows that our adapted AttentionMask system is robust to image degradations, generalizes well to unseen types of surgeries, and copes well with small instruments.
The developmental trajectory of object recognition robustness: children are like small adults but unlike big deep neural networks
May 20, 2022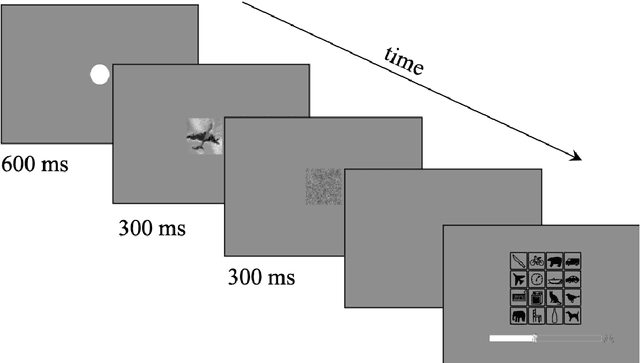
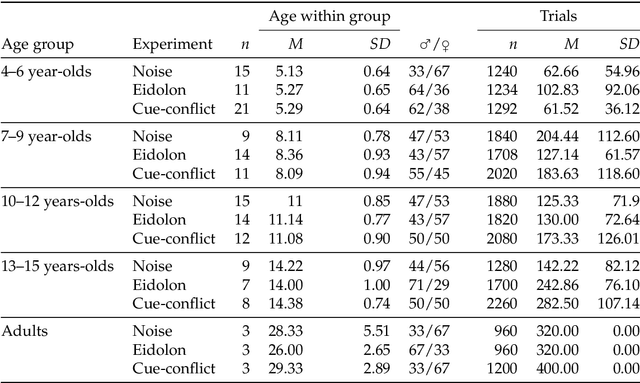


In laboratory object recognition tasks based on undistorted photographs, both adult humans and Deep Neural Networks (DNNs) perform close to ceiling. Unlike adults', whose object recognition performance is robust against a wide range of image distortions, DNNs trained on standard ImageNet (1.3M images) perform poorly on distorted images. However, the last two years have seen impressive gains in DNN distortion robustness, predominantly achieved through ever-increasing large-scale datasets$\unicode{x2014}$orders of magnitude larger than ImageNet. While this simple brute-force approach is very effective in achieving human-level robustness in DNNs, it raises the question of whether human robustness, too, is simply due to extensive experience with (distorted) visual input during childhood and beyond. Here we investigate this question by comparing the core object recognition performance of 146 children (aged 4$\unicode{x2013}$15) against adults and against DNNs. We find, first, that already 4$\unicode{x2013}$6 year-olds showed remarkable robustness to image distortions and outperform DNNs trained on ImageNet. Second, we estimated the number of $\unicode{x201C}$images$\unicode{x201D}$ children have been exposed to during their lifetime. Compared to various DNNs, children's high robustness requires relatively little data. Third, when recognizing objects children$\unicode{x2014}$like adults but unlike DNNs$\unicode{x2014}$rely heavily on shape but not on texture cues. Together our results suggest that the remarkable robustness to distortions emerges early in the developmental trajectory of human object recognition and is unlikely the result of a mere accumulation of experience with distorted visual input. Even though current DNNs match human performance regarding robustness they seem to rely on different and more data-hungry strategies to do so.
Monocular Depth Estimation Using Cues Inspired by Biological Vision Systems
Apr 21, 2022
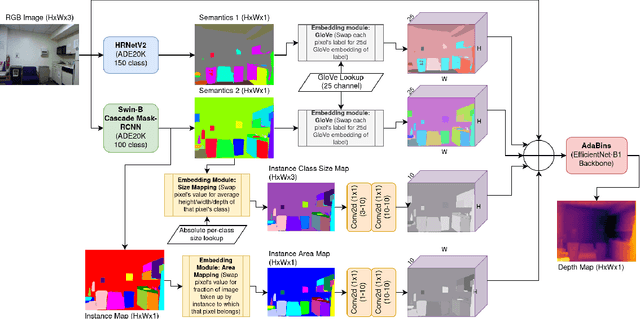
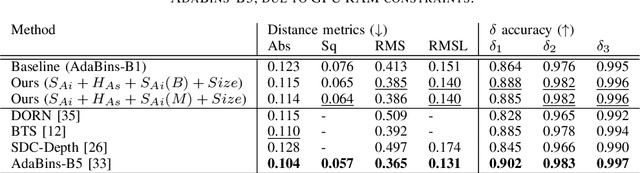
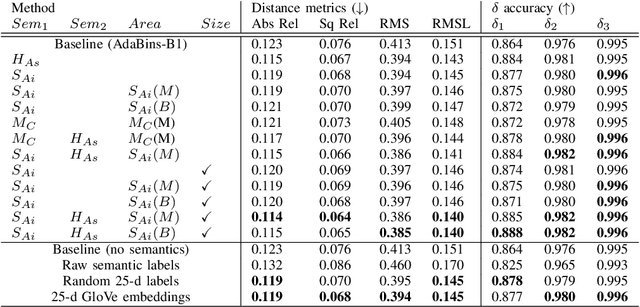
Monocular depth estimation (MDE) aims to transform an RGB image of a scene into a pixelwise depth map from the same camera view. It is fundamentally ill-posed due to missing information: any single image can have been taken from many possible 3D scenes. Part of the MDE task is, therefore, to learn which visual cues in the image can be used for depth estimation, and how. With training data limited by cost of annotation or network capacity limited by computational power, this is challenging. In this work we demonstrate that explicitly injecting visual cue information into the model is beneficial for depth estimation. Following research into biological vision systems, we focus on semantic information and prior knowledge of object sizes and their relations, to emulate the biological cues of relative size, familiar size, and absolute size. We use state-of-the-art semantic and instance segmentation models to provide external information, and exploit language embeddings to encode relational information between classes. We also provide a prior on the average real-world size of objects. This external information overcomes the limitation in data availability, and ensures that the limited capacity of a given network is focused on known-helpful cues, therefore improving performance. We experimentally validate our hypothesis and evaluate the proposed model on the widely used NYUD2 indoor depth estimation benchmark. The results show improvements in depth prediction when the semantic information, size prior and instance size are explicitly provided along with the RGB images, and our method can be easily adapted to any depth estimation system.
Neural Space-filling Curves
Apr 18, 2022
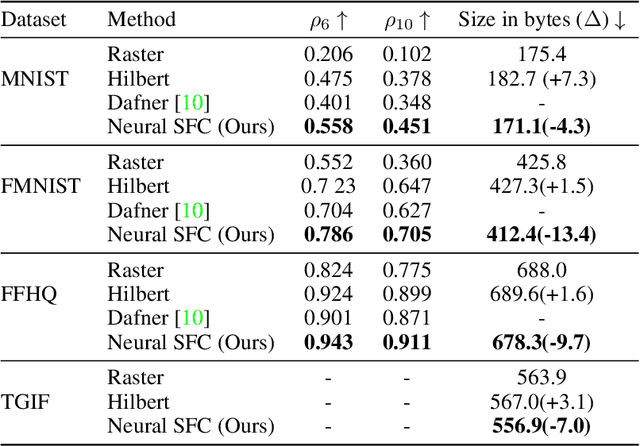
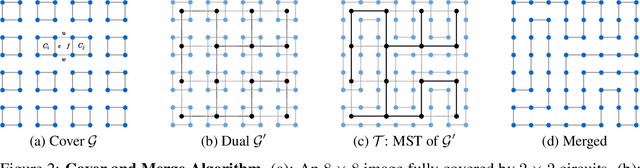
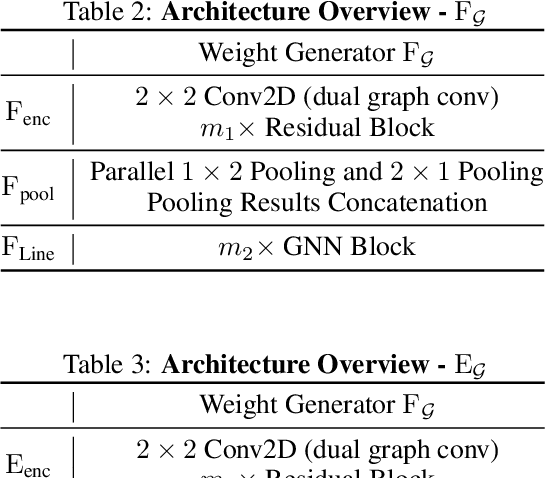
We present Neural Space-filling Curves (SFCs), a data-driven approach to infer a context-based scan order for a set of images. Linear ordering of pixels forms the basis for many applications such as video scrambling, compression, and auto-regressive models that are used in generative modeling for images. Existing algorithms resort to a fixed scanning algorithm such as Raster scan or Hilbert scan. Instead, our work learns a spatially coherent linear ordering of pixels from the dataset of images using a graph-based neural network. The resulting Neural SFC is optimized for an objective suitable for the downstream task when the image is traversed along with the scan line order. We show the advantage of using Neural SFCs in downstream applications such as image compression. Code and additional results will be made available at https://hywang66.github.io/publication/neuralsfc.