 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
How Far Can I Go ? : A Self-Supervised Approach for Deterministic Video Depth Forecasting
Jul 01, 2022
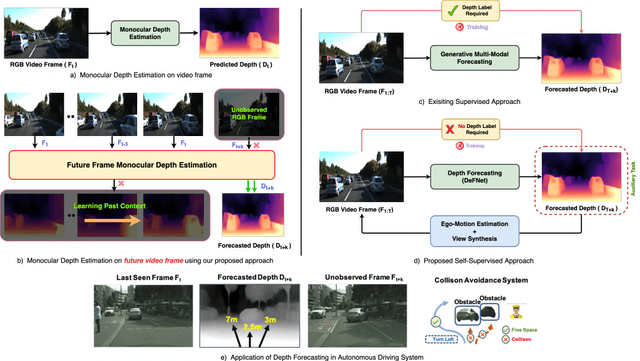
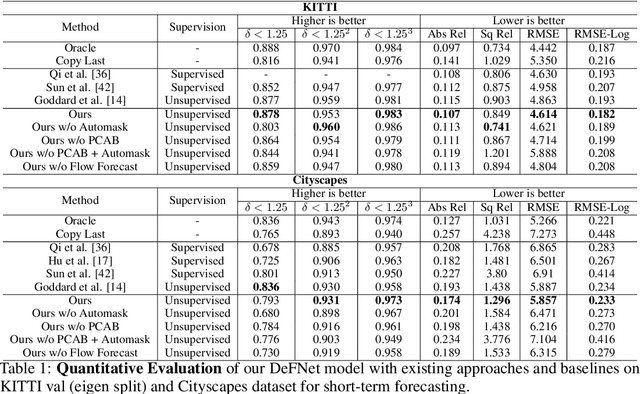
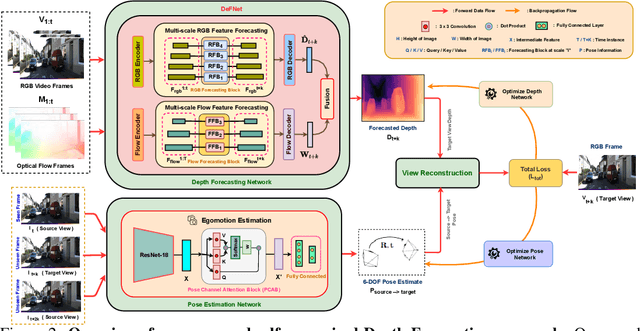
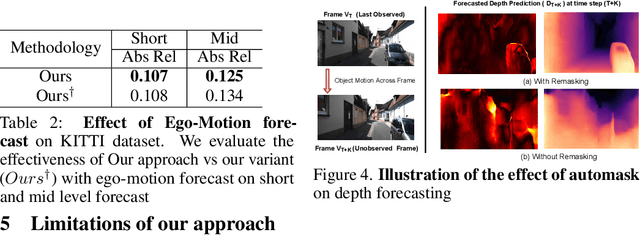
In this paper we present a novel self-supervised method to anticipate the depth estimate for a future, unobserved real-world urban scene. This work is the first to explore self-supervised learning for estimation of monocular depth of future unobserved frames of a video. Existing works rely on a large number of annotated samples to generate the probabilistic prediction of depth for unseen frames. However, this makes it unrealistic due to its requirement for large amount of annotated depth samples of video. In addition, the probabilistic nature of the case, where one past can have multiple future outcomes often leads to incorrect depth estimates. Unlike previous methods, we model the depth estimation of the unobserved frame as a view-synthesis problem, which treats the depth estimate of the unseen video frame as an auxiliary task while synthesizing back the views using learned pose. This approach is not only cost effective - we do not use any ground truth depth for training (hence practical) but also deterministic (a sequence of past frames map to an immediate future). To address this task we first develop a novel depth forecasting network DeFNet which estimates depth of unobserved future by forecasting latent features. Second, we develop a channel-attention based pose estimation network that estimates the pose of the unobserved frame. Using this learned pose, estimated depth map is reconstructed back into the image domain, thus forming a self-supervised solution. Our proposed approach shows significant improvements in Abs Rel metric compared to state-of-the-art alternatives on both short and mid-term forecasting setting, benchmarked on KITTI and Cityscapes. Code is available at https://github.com/sauradip/depthForecasting
Adaptive Fusion Affinity Graph with Noise-free Online Low-rank Representation for Natural Image Segmentation
Oct 22, 2021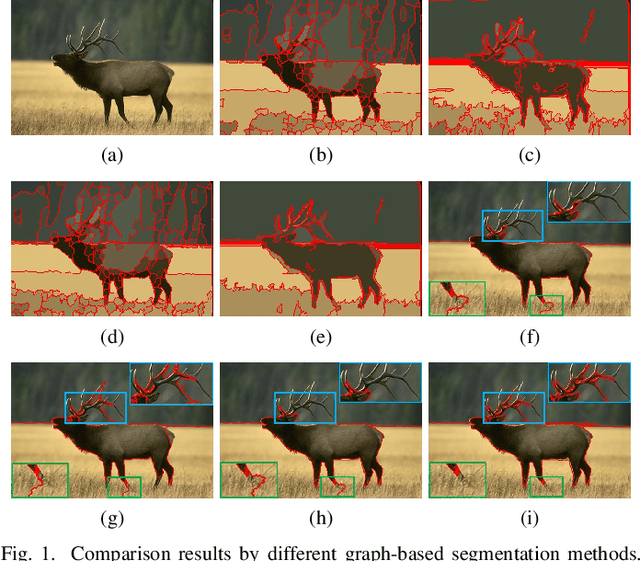



Affinity graph-based segmentation methods have become a major trend in computer vision. The performance of these methods relies on the constructed affinity graph, with particular emphasis on the neighborhood topology and pairwise affinities among superpixels. Due to the advantages of assimilating different graphs, a multi-scale fusion graph has a better performance than a single graph with single-scale. However, these methods ignore the noise from images which influences the accuracy of pairwise similarities. Multi-scale combinatorial grouping and graph fusion also generate a higher computational complexity. In this paper, we propose an adaptive fusion affinity graph (AFA-graph) with noise-free low-rank representation in an online manner for natural image segmentation. An input image is first over-segmented into superpixels at different scales and then filtered by the proposed improved kernel density estimation method. Moreover, we select global nodes of these superpixels on the basis of their subspace-preserving presentation, which reveals the feature distribution of superpixels exactly. To reduce time complexity while improving performance, a sparse representation of global nodes based on noise-free online low-rank representation is used to obtain a global graph at each scale. The global graph is finally used to update a local graph which is built upon all superpixels at each scale. Experimental results on the BSD300, BSD500, MSRC, SBD, and PASCAL VOC show the effectiveness of AFA-graph in comparison with state-of-the-art approaches.
PriorityCut: Occlusion-guided Regularization for Warp-based Image Animation
Mar 22, 2021



Image animation generates a video of a source image following the motion of a driving video. State-of-the-art self-supervised image animation approaches warp the source image according to the motion of the driving video and recover the warping artifacts by inpainting. These approaches mostly use vanilla convolution for inpainting, and vanilla convolution does not distinguish between valid and invalid pixels. As a result, visual artifacts are still noticeable after inpainting. CutMix is a state-of-the-art regularization strategy that cuts and mixes patches of images and is widely studied in different computer vision tasks. Among the remaining computer vision tasks, warp-based image animation is one of the fields that the effects of CutMix have yet to be studied. This paper first presents a preliminary study on the effects of CutMix on warp-based image animation. We observed in our study that CutMix helps improve only pixel values, but disturbs the spatial relationships between pixels. Based on such observation, we propose PriorityCut, a novel augmentation approach that uses the top-k percent occluded pixels of the foreground to regularize warp-based image animation. By leveraging the domain knowledge in warp-based image animation, PriorityCut significantly reduces the warping artifacts in state-of-the-art warp-based image animation models on diverse datasets.
Anatomy-Guided Weakly-Supervised Abnormality Localization in Chest X-rays
Jun 25, 2022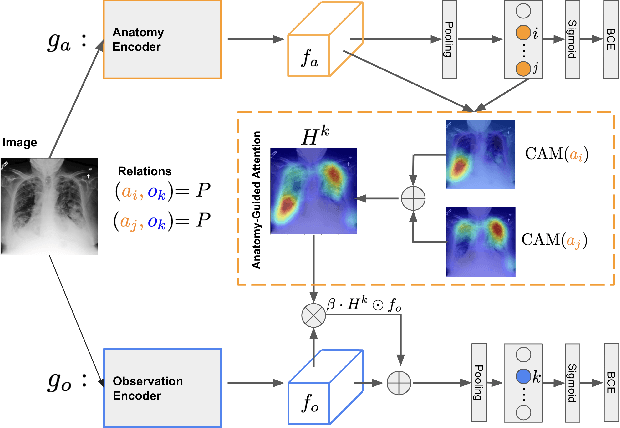
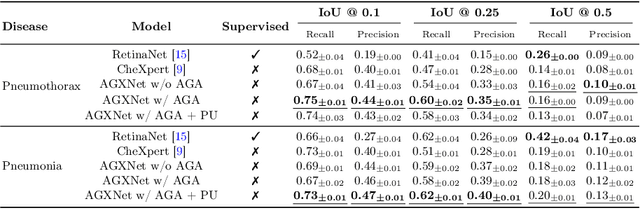
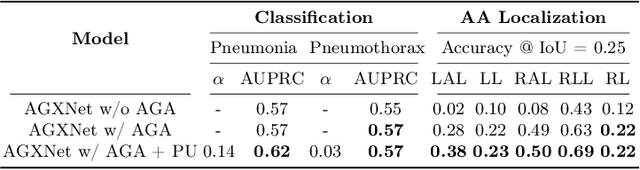
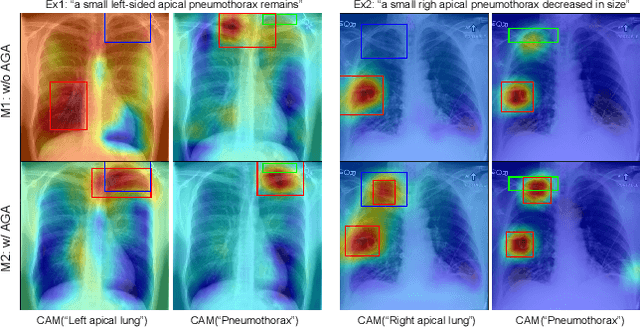
Creating a large-scale dataset of abnormality annotation on medical images is a labor-intensive and costly task. Leveraging weak supervision from readily available data such as radiology reports can compensate lack of large-scale data for anomaly detection methods. However, most of the current methods only use image-level pathological observations, failing to utilize the relevant anatomy mentions in reports. Furthermore, Natural Language Processing (NLP)-mined weak labels are noisy due to label sparsity and linguistic ambiguity. We propose an Anatomy-Guided chest X-ray Network (AGXNet) to address these issues of weak annotation. Our framework consists of a cascade of two networks, one responsible for identifying anatomical abnormalities and the second responsible for pathological observations. The critical component in our framework is an anatomy-guided attention module that aids the downstream observation network in focusing on the relevant anatomical regions generated by the anatomy network. We use Positive Unlabeled (PU) learning to account for the fact that lack of mention does not necessarily mean a negative label. Our quantitative and qualitative results on the MIMIC-CXR dataset demonstrate the effectiveness of AGXNet in disease and anatomical abnormality localization. Experiments on the NIH Chest X-ray dataset show that the learned feature representations are transferable and can achieve the state-of-the-art performances in disease classification and competitive disease localization results. Our code is available at https://github.com/batmanlab/AGXNet
Label-Efficient Self-Supervised Federated Learning for Tackling Data Heterogeneity in Medical Imaging
May 17, 2022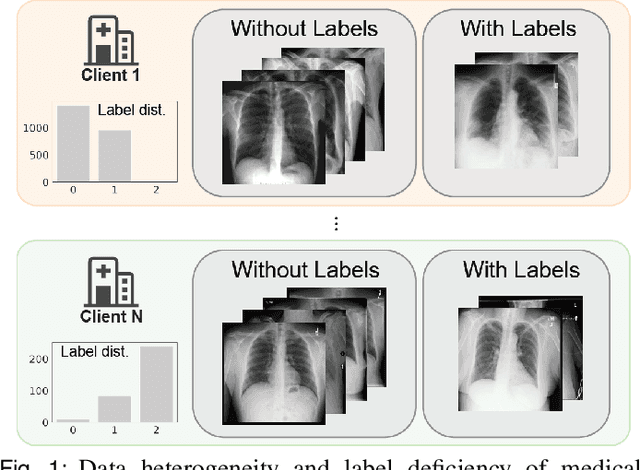
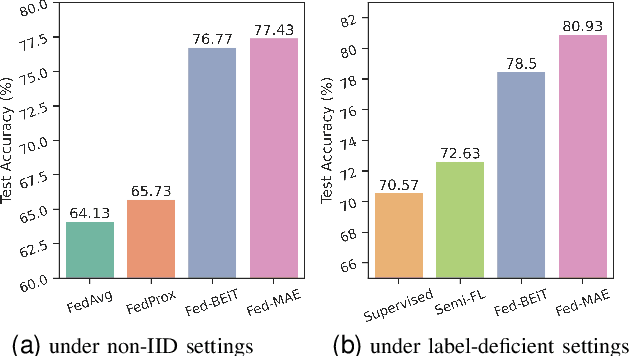
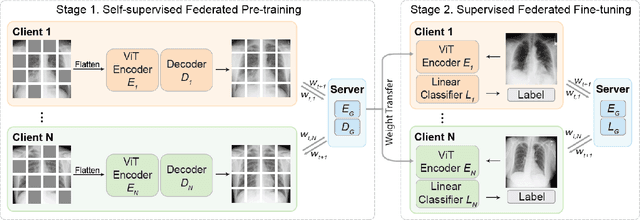
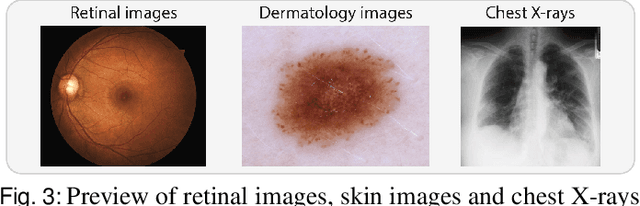
The curation of large-scale medical datasets from multiple institutions necessary for training deep learning models is challenged by the difficulty in sharing patient data with privacy-preserving. Federated learning (FL), a paradigm that enables privacy-protected collaborative learning among different institutions, is a promising solution to this challenge. However, FL generally suffers from performance deterioration due to heterogeneous data distributions across institutions and the lack of quality labeled data. In this paper, we present a robust and label-efficient self-supervised FL framework for medical image analysis. Specifically, we introduce a novel distributed self-supervised pre-training paradigm into the existing FL pipeline (i.e., pre-training the models directly on the decentralized target task datasets). Built upon the recent success of Vision Transformers, we employ masked image encoding tasks for self-supervised pre-training, to facilitate more effective knowledge transfer to downstream federated models. Extensive empirical results on simulated and real-world medical imaging federated datasets show that self-supervised pre-training largely benefits the robustness of federated models against various degrees of data heterogeneity. Notably, under severe data heterogeneity, our method, without relying on any additional pre-training data, achieves an improvement of 5.06%, 1.53% and 4.58% in test accuracy on retinal, dermatology and chest X-ray classification compared with the supervised baseline with ImageNet pre-training. Moreover, we show that our self-supervised FL algorithm generalizes well to out-of-distribution data and learns federated models more effectively in limited label scenarios, surpassing the supervised baseline by 10.36% and the semi-supervised FL method by 8.3% in test accuracy.
MCUa: Multi-level Context and Uncertainty aware Dynamic Deep Ensemble for Breast Cancer Histology Image Classification
Aug 24, 2021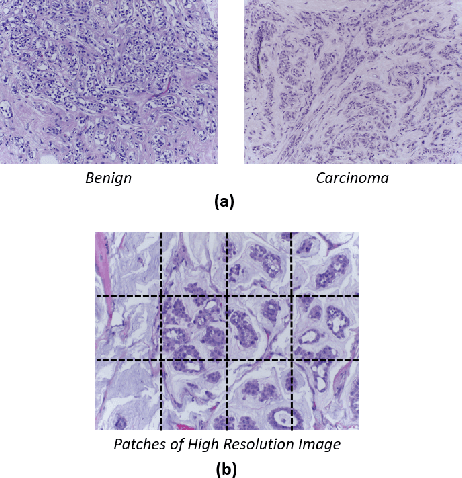
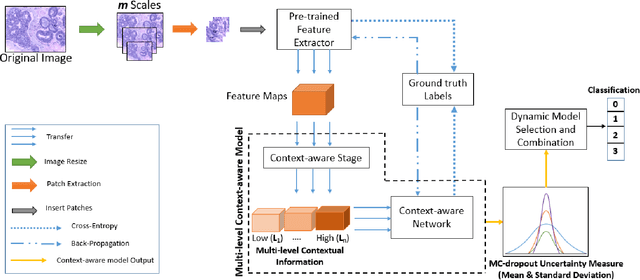

Breast histology image classification is a crucial step in the early diagnosis of breast cancer. In breast pathological diagnosis, Convolutional Neural Networks (CNNs) have demonstrated great success using digitized histology slides. However, tissue classification is still challenging due to the high visual variability of the large-sized digitized samples and the lack of contextual information. In this paper, we propose a novel CNN, called Multi-level Context and Uncertainty aware (MCUa) dynamic deep learning ensemble model.MCUamodel consists of several multi-level context-aware models to learn the spatial dependency between image patches in a layer-wise fashion. It exploits the high sensitivity to the multi-level contextual information using an uncertainty quantification component to accomplish a novel dynamic ensemble model.MCUamodelhas achieved a high accuracy of 98.11% on a breast cancer histology image dataset. Experimental results show the superior effectiveness of the proposed solution compared to the state-of-the-art histology classification models.
* accepted by IEEE Transactions on Biomedical Engineering
SeATrans: Learning Segmentation-Assisted diagnosis model via Transformer
Jun 22, 2022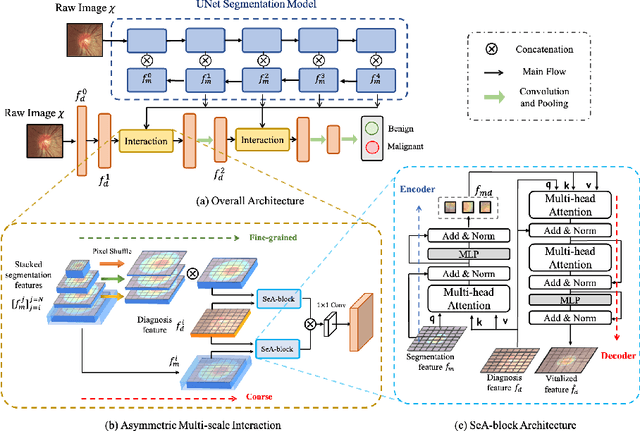
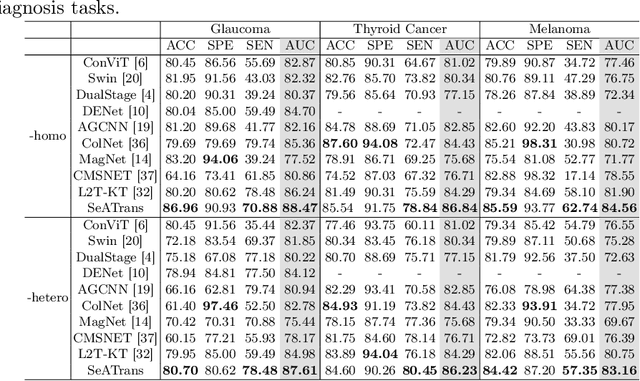
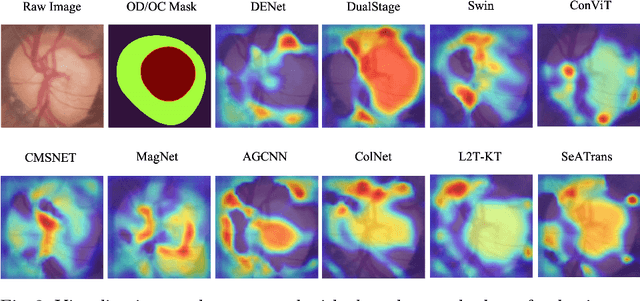
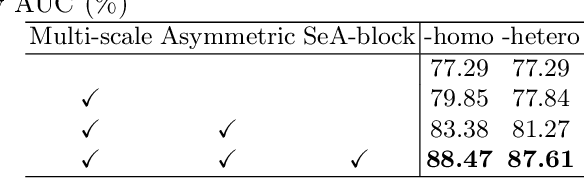
Clinically, the accurate annotation of lesions/tissues can significantly facilitate the disease diagnosis. For example, the segmentation of optic disc/cup (OD/OC) on fundus image would facilitate the glaucoma diagnosis, the segmentation of skin lesions on dermoscopic images is helpful to the melanoma diagnosis, etc. With the advancement of deep learning techniques, a wide range of methods proved the lesions/tissues segmentation can also facilitate the automated disease diagnosis models. However, existing methods are limited in the sense that they can only capture static regional correlations in the images. Inspired by the global and dynamic nature of Vision Transformer, in this paper, we propose Segmentation-Assisted diagnosis Transformer (SeATrans) to transfer the segmentation knowledge to the disease diagnosis network. Specifically, we first propose an asymmetric multi-scale interaction strategy to correlate each single low-level diagnosis feature with multi-scale segmentation features. Then, an effective strategy called SeA-block is adopted to vitalize diagnosis feature via correlated segmentation features. To model the segmentation-diagnosis interaction, SeA-block first embeds the diagnosis feature based on the segmentation information via the encoder, and then transfers the embedding back to the diagnosis feature space by a decoder. Experimental results demonstrate that SeATrans surpasses a wide range of state-of-the-art (SOTA) segmentation-assisted diagnosis methods on several disease diagnosis tasks.
A 51.3 TOPS/W, 134.4 GOPS In-memory Binary Image Filtering in 65nm CMOS
Jul 29, 2021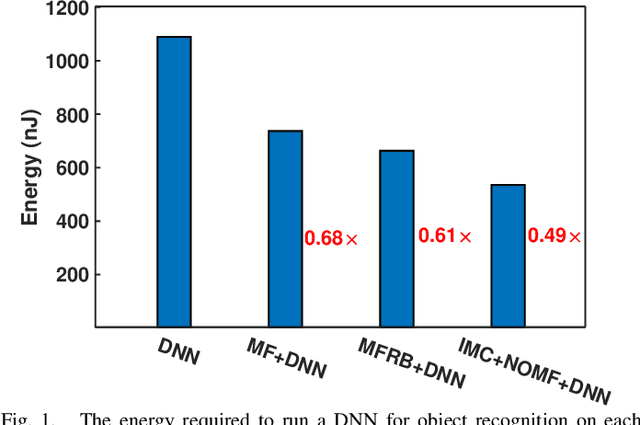
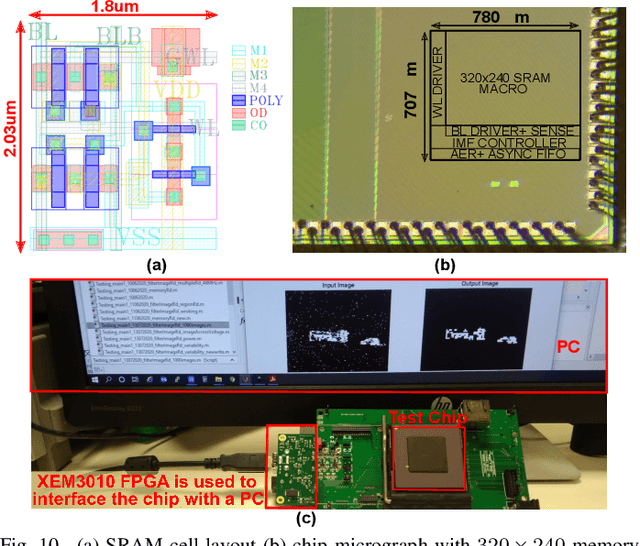
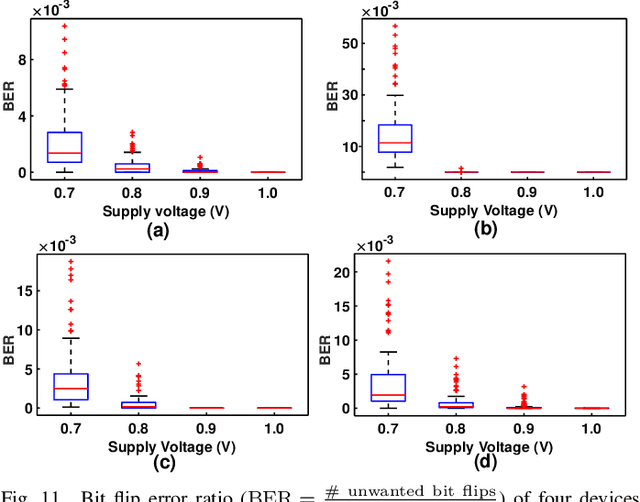
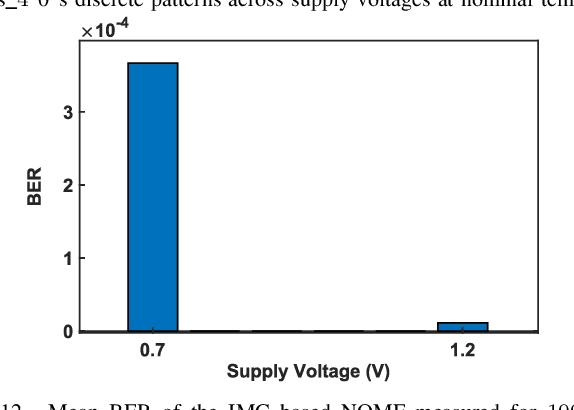
Neuromorphic vision sensors (NVS) can enable energy savings due to their event-driven that exploits the temporal redundancy in video streams from a stationary camera. However, noise-driven events lead to the false triggering of the object recognition processor. Image denoise operations require memoryintensive processing leading to a bottleneck in energy and latency. In this paper, we present in-memory filtering (IMF), a 6TSRAM in-memory computing based image denoising for eventbased binary image (EBBI) frame from an NVS. We propose a non-overlap median filter (NOMF) for image denoising. An inmemory computing framework enables hardware implementation of NOMF leveraging the inherent read disturb phenomenon of 6T-SRAM. To demonstrate the energy-saving and effectiveness of the algorithm, we fabricated the proposed architecture in a 65nm CMOS process. As compared to fully digital implementation, IMF enables > 70x energy savings and a > 3x improvement of processing time when tested with the video recordings from a DAVIS sensor and achieves a peak throughput of 134.4 GOPS. Furthermore, the peak energy efficiencies of the NOMF is 51.3 TOPS/W, comparable with state of the art inmemory processors. We also show that the accuracy of the images obtained by NOMF provide comparable accuracy in tracking and classification applications when compared with images obtained by conventional median filtering.
X-ViT: High Performance Linear Vision Transformer without Softmax
May 27, 2022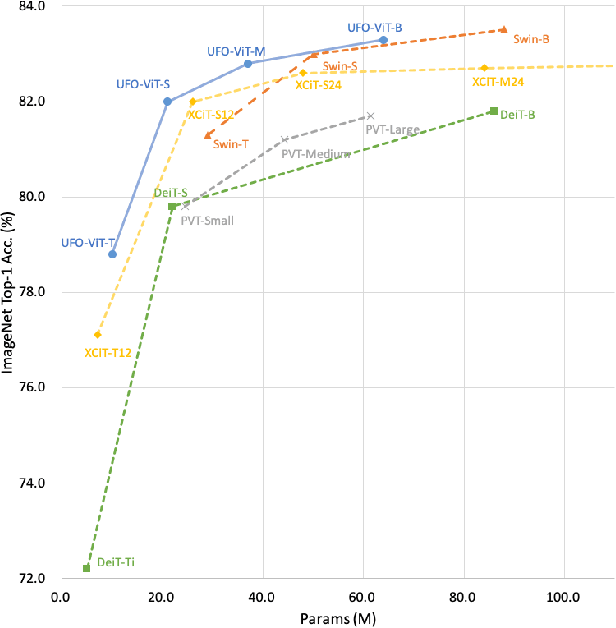

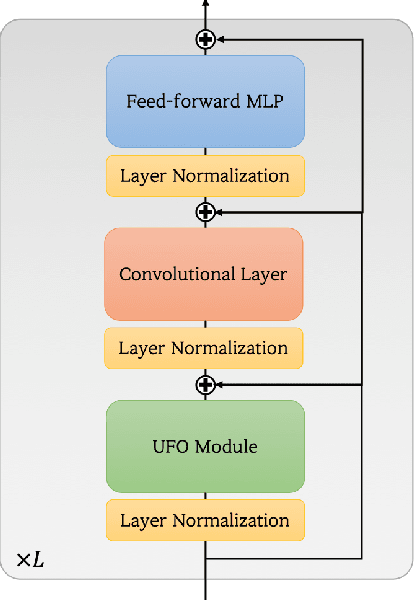

Vision transformers have become one of the most important models for computer vision tasks. Although they outperform prior works, they require heavy computational resources on a scale that is quadratic to the number of tokens, $N$. This is a major drawback of the traditional self-attention (SA) algorithm. Here, we propose the X-ViT, ViT with a novel SA mechanism that has linear complexity. The main approach of this work is to eliminate nonlinearity from the original SA. We factorize the matrix multiplication of the SA mechanism without complicated linear approximation. By modifying only a few lines of code from the original SA, the proposed models outperform most transformer-based models on image classification and dense prediction tasks on most capacity regimes.
Segmenting Medical Instruments in Minimally Invasive Surgeries using AttentionMask
Mar 21, 2022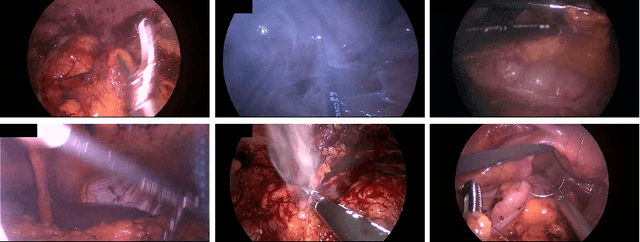
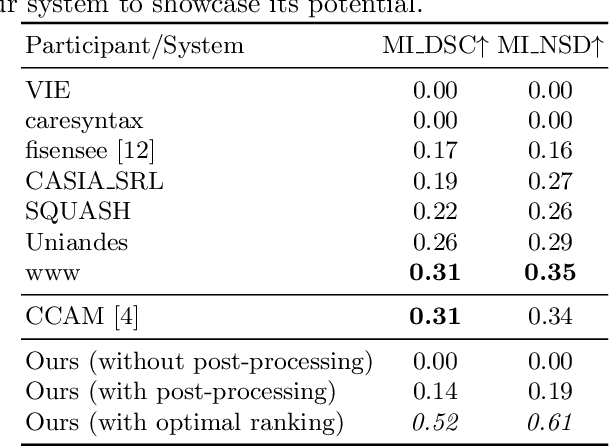
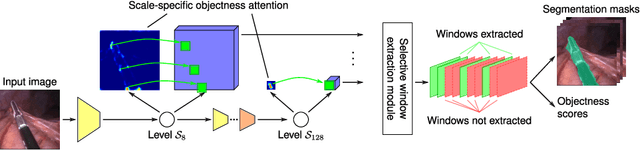
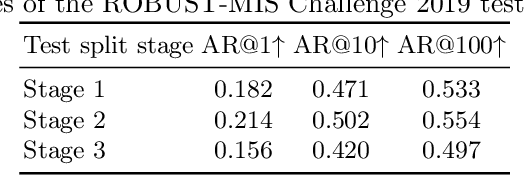
Precisely locating and segmenting medical instruments in images of minimally invasive surgeries, medical instrument segmentation, is an essential first step for several tasks in medical image processing. However, image degradations, small instruments, and the generalization between different surgery types make medical instrument segmentation challenging. To cope with these challenges, we adapt the object proposal generation system AttentionMask and propose a dedicated post-processing to select promising proposals. The results on the ROBUST-MIS Challenge 2019 show that our adapted AttentionMask system is a strong foundation for generating state-of-the-art performance. Our evaluation in an object proposal generation framework shows that our adapted AttentionMask system is robust to image degradations, generalizes well to unseen types of surgeries, and copes well with small instruments.