 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning the Effect of Registration Hyperparameters with HyperMorph
Mar 30, 2022
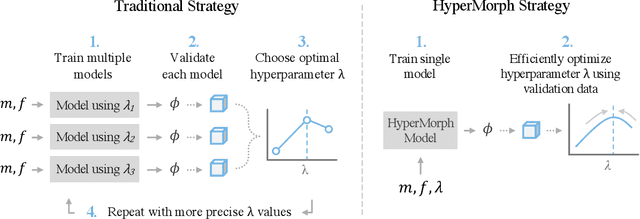
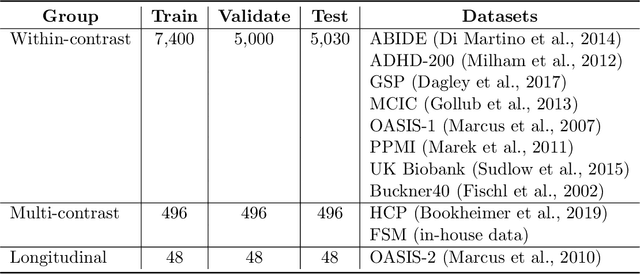
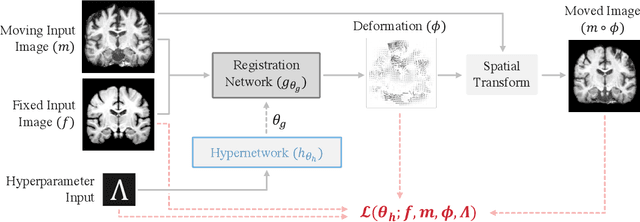

We introduce HyperMorph, a framework that facilitates efficient hyperparameter tuning in learning-based deformable image registration. Classical registration algorithms perform an iterative pair-wise optimization to compute a deformation field that aligns two images. Recent learning-based approaches leverage large image datasets to learn a function that rapidly estimates a deformation for a given image pair. In both strategies, the accuracy of the resulting spatial correspondences is strongly influenced by the choice of certain hyperparameter values. However, an effective hyperparameter search consumes substantial time and human effort as it often involves training multiple models for different fixed hyperparameter values and may lead to suboptimal registration. We propose an amortized hyperparameter learning strategy to alleviate this burden by learning the impact of hyperparameters on deformation fields. We design a meta network, or hypernetwork, that predicts the parameters of a registration network for input hyperparameters, thereby comprising a single model that generates the optimal deformation field corresponding to given hyperparameter values. This strategy enables fast, high-resolution hyperparameter search at test-time, reducing the inefficiency of traditional approaches while increasing flexibility. We also demonstrate additional benefits of HyperMorph, including enhanced robustness to model initialization and the ability to rapidly identify optimal hyperparameter values specific to a dataset, image contrast, task, or even anatomical region, all without the need to retrain models. We make our code publicly available at http://hypermorph.voxelmorph.net.
Affective Image Content Analysis: Two Decades Review and New Perspectives
Jun 30, 2021
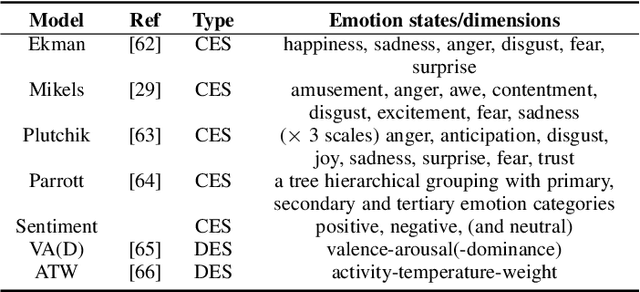
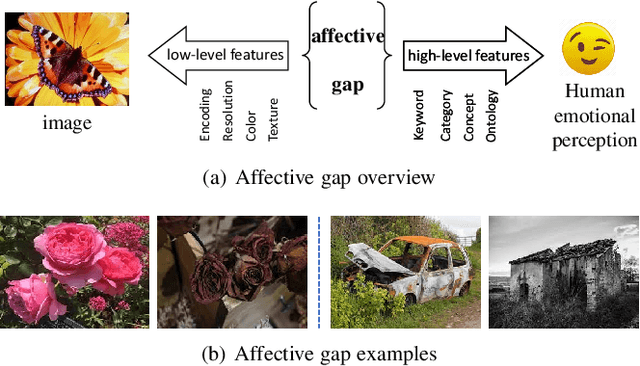

Images can convey rich semantics and induce various emotions in viewers. Recently, with the rapid advancement of emotional intelligence and the explosive growth of visual data, extensive research efforts have been dedicated to affective image content analysis (AICA). In this survey, we will comprehensively review the development of AICA in the recent two decades, especially focusing on the state-of-the-art methods with respect to three main challenges -- the affective gap, perception subjectivity, and label noise and absence. We begin with an introduction to the key emotion representation models that have been widely employed in AICA and description of available datasets for performing evaluation with quantitative comparison of label noise and dataset bias. We then summarize and compare the representative approaches on (1) emotion feature extraction, including both handcrafted and deep features, (2) learning methods on dominant emotion recognition, personalized emotion prediction, emotion distribution learning, and learning from noisy data or few labels, and (3) AICA based applications. Finally, we discuss some challenges and promising research directions in the future, such as image content and context understanding, group emotion clustering, and viewer-image interaction.
NLHD: A Pixel-Level Non-Local Retinex Model for Low-Light Image Enhancement
Jun 15, 2021


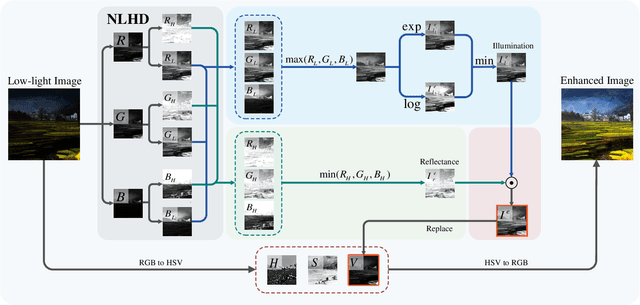
Retinex model has been applied to low-light image enhancement in many existing methods. More appropriate decomposition of a low-light image can help achieve better image enhancement. In this paper, we propose a new pixel-level non-local Haar transform based illumination and reflectance decomposition method (NLHD). The unique low-frequency coefficient of Haar transform on each similar pixel group is used to reconstruct the illumination component, and the rest of all high-frequency coefficients are employed to reconstruct the reflectance component. The complete similarity of pixels in a matched similar pixel group and the simple separable Haar transform help to obtain more appropriate image decomposition; thus, the image is hardly sharpened in the image brightness enhancement procedure. The exponential transform and logarithmic transform are respectively implemented on the illumination component. Then a minimum fusion strategy on the results of these two transforms is utilized to achieve more natural illumination component enhancement. It can alleviate the mosaic artifacts produced in the darker regions by the exponential transform with a gamma value less than 1 and reduce information loss caused by excessive enhancement of the brighter regions due to the logarithmic transform. Finally, the Retinex model is applied to the enhanced illumination and reflectance to achieve image enhancement. We also develop a local noise level estimation based noise suppression method and a non-local saturation reduction based color deviation correction method. These two methods can respectively attenuate noise or color deviation usually presented in the enhanced results of the extremely dark low-light images. Experiments on benchmark datasets show that the proposed method can achieve better low-light image enhancement results on subjective and objective evaluations than most existing methods.
PanFormer: a Transformer Based Model for Pan-sharpening
Mar 06, 2022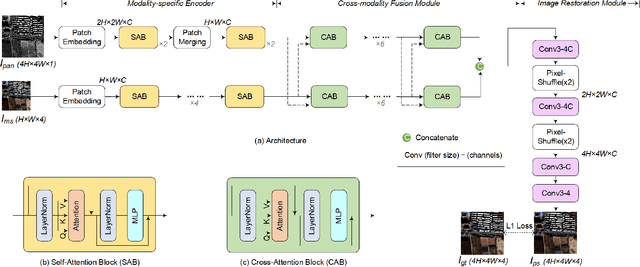
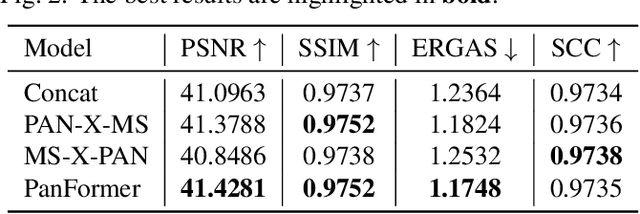
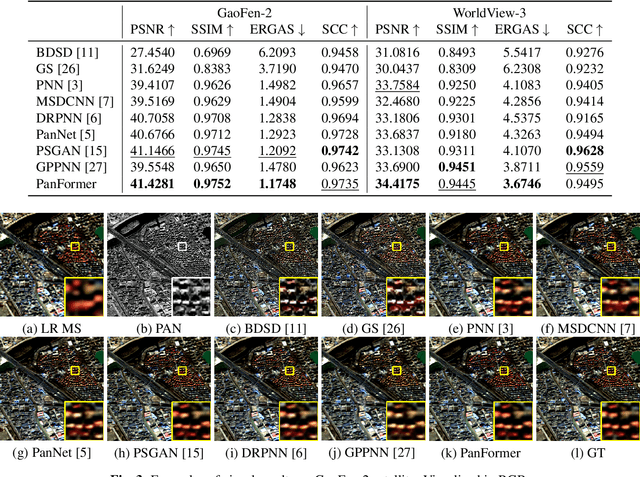
Pan-sharpening aims at producing a high-resolution (HR) multi-spectral (MS) image from a low-resolution (LR) multi-spectral (MS) image and its corresponding panchromatic (PAN) image acquired by a same satellite. Inspired by a new fashion in recent deep learning community, we propose a novel Transformer based model for pan-sharpening. We explore the potential of Transformer in image feature extraction and fusion. Following the successful development of vision transformers, we design a two-stream network with the self-attention to extract the modality-specific features from the PAN and MS modalities and apply a cross-attention module to merge the spectral and spatial features. The pan-sharpened image is produced from the enhanced fused features. Extensive experiments on GaoFen-2 and WorldView-3 images demonstrate that our Transformer based model achieves impressive results and outperforms many existing CNN based methods, which shows the great potential of introducing Transformer to the pan-sharpening task. Codes are available at https://github.com/zhysora/PanFormer.
Super-resolved multi-temporal segmentation with deep permutation-invariant networks
Apr 06, 2022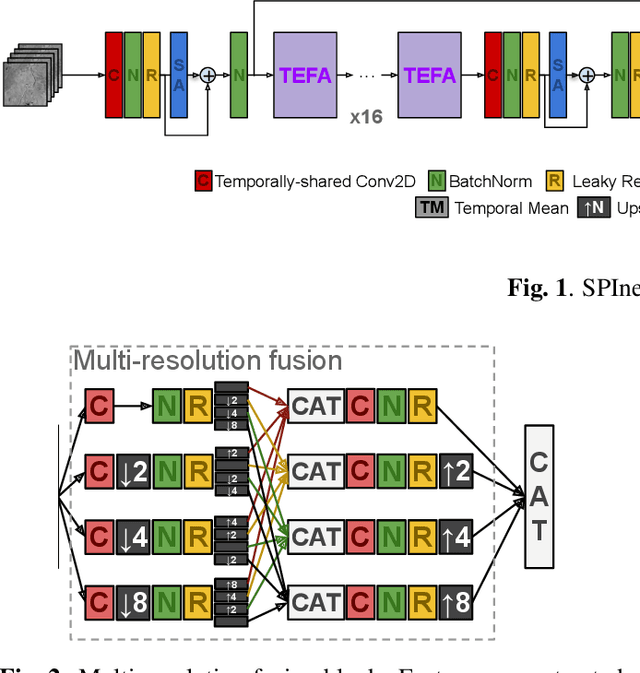
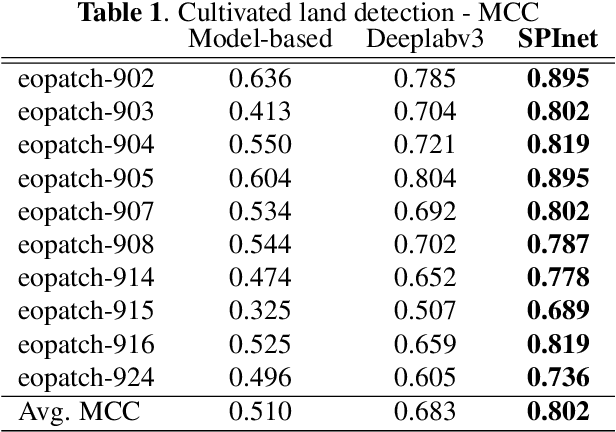


Multi-image super-resolution from multi-temporal satellite acquisitions of a scene has recently enjoyed great success thanks to new deep learning models. In this paper, we go beyond classic image reconstruction at a higher resolution by studying a super-resolved inference problem, namely semantic segmentation at a spatial resolution higher than the one of sensing platform. We expand upon recently proposed models exploiting temporal permutation invariance with a multi-resolution fusion module able to infer the rich semantic information needed by the segmentation task. The model presented in this paper has recently won the AI4EO challenge on Enhanced Sentinel 2 Agriculture.
Explicit Boundary Guided Semi-Push-Pull Contrastive Learning for Better Anomaly Detection
Jul 04, 2022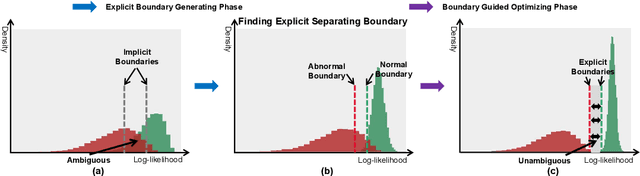
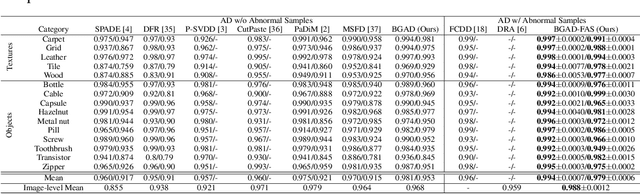
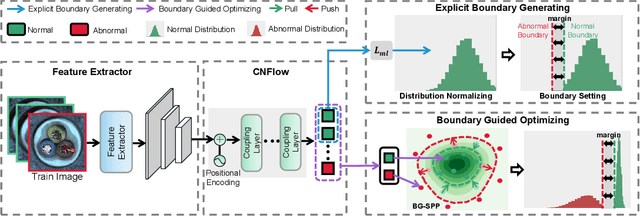

Most of anomaly detection algorithms are mainly focused on modeling the distribution of normal samples and treating anomalies as outliers. However, the discriminative performance of the model may be insufficient due to the lack of knowledge about anomalies. Thus, anomalies should be exploited as possible. However, utilizing a few known anomalies during training may cause another issue that model may be biased by those known anomalies and fail to generalize to unseen anomalies. In this paper, we aim to exploit a few existing anomalies with a carefully designed explicit boundary guided semi-push-pull learning strategy, which can enhance discriminability while mitigating bias problem caused by insufficient known anomalies. Our model is based on two core designs: First, finding one explicit separating boundary as the guidance for further contrastive learning. Specifically, we employ normalizing flow to learn normal feature distribution, then find an explicit separating boundary close to the distribution edge. The obtained explicit and compact separating boundary only relies on the normal feature distribution, thus the bias problem caused by a few known anomalies can be mitigated. Second, learning more discriminative features under the guidance of the explicit separating boundary. A boundary guided semi-push-pull loss is developed to only pull the normal features together while pushing the abnormal features apart from the separating boundary beyond a certain margin region. In this way, our model can form a more explicit and discriminative decision boundary to achieve better results for known and also unseen anomalies, while also maintaining high training efficiency. Extensive experiments on the widely-used MVTecAD benchmark show that the proposed method achieves new state-of-the-art results, with the performance of 98.8% image-level AUROC and 99.4% pixel-level AUROC.
A Unified Sequence Interface for Vision Tasks
Jun 15, 2022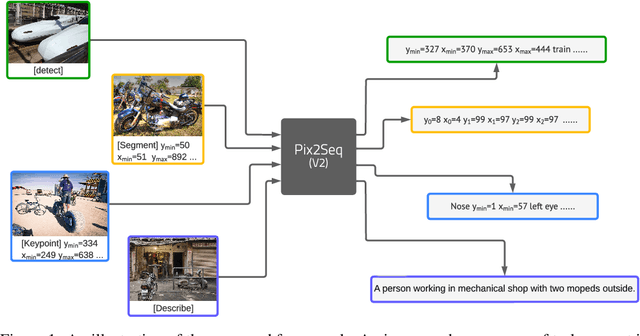
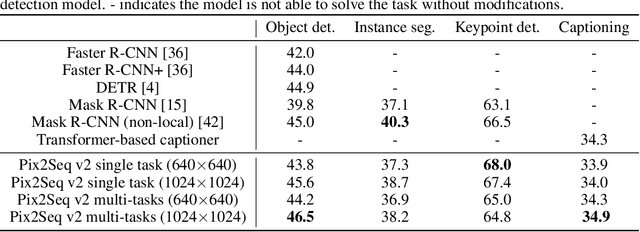
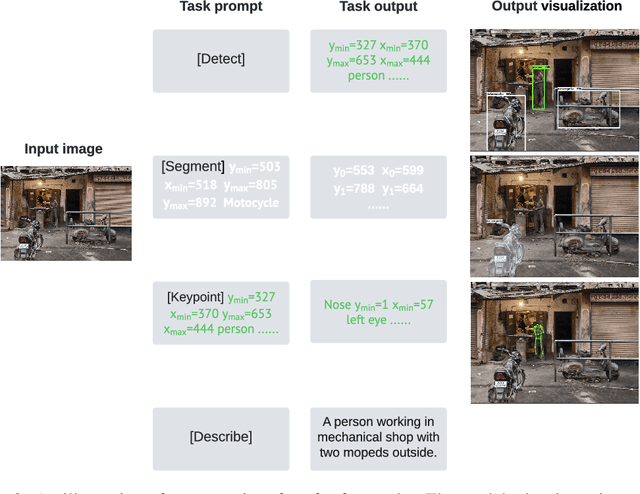

While language tasks are naturally expressed in a single, unified, modeling framework, i.e., generating sequences of tokens, this has not been the case in computer vision. As a result, there is a proliferation of distinct architectures and loss functions for different vision tasks. In this work we show that a diverse set of "core" computer vision tasks can also be unified if formulated in terms of a shared pixel-to-sequence interface. We focus on four tasks, namely, object detection, instance segmentation, keypoint detection, and image captioning, all with diverse types of outputs, e.g., bounding boxes or dense masks. Despite that, by formulating the output of each task as a sequence of discrete tokens with a unified interface, we show that one can train a neural network with a single model architecture and loss function on all these tasks, with no task-specific customization. To solve a specific task, we use a short prompt as task description, and the sequence output adapts to the prompt so it can produce task-specific output. We show that such a model can achieve competitive performance compared to well-established task-specific models.
Omni-Seg: A Single Dynamic Network for Multi-label Renal Pathology Image Segmentation using Partially Labeled Data
Dec 23, 2021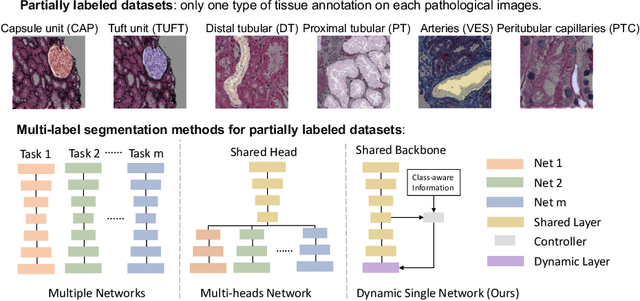
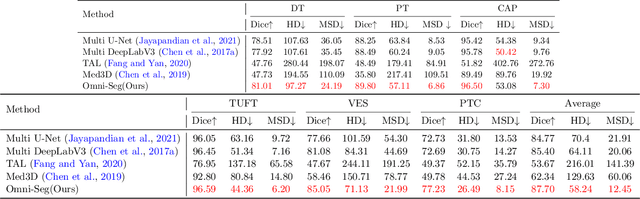
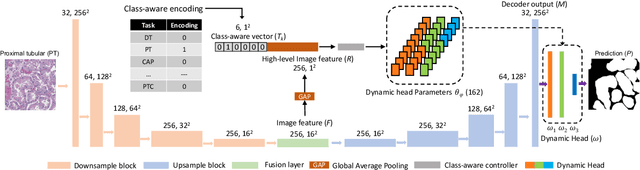
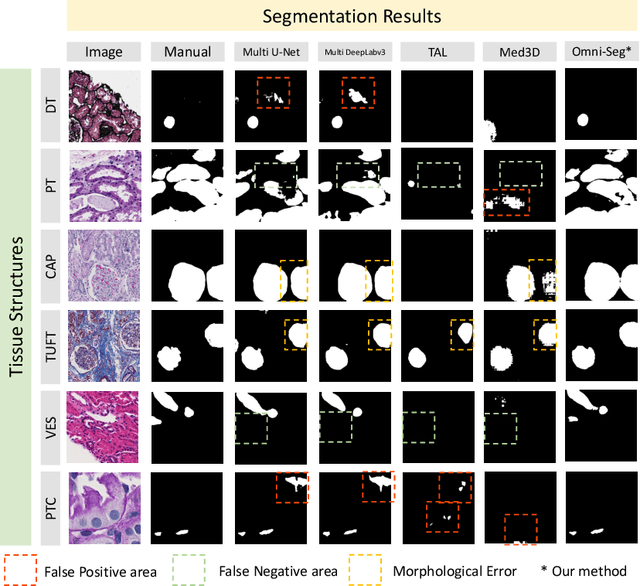
Computer-assisted quantitative analysis on Giga-pixel pathology images has provided a new avenue in precision medicine. The innovations have been largely focused on cancer pathology (i.e., tumor segmentation and characterization). In non-cancer pathology, the learning algorithms can be asked to examine more comprehensive tissue types simultaneously, as a multi-label setting. The prior arts typically needed to train multiple segmentation networks in order to match the domain-specific knowledge for heterogeneous tissue types (e.g., glomerular tuft, glomerular unit, proximal tubular, distal tubular, peritubular capillaries, and arteries). In this paper, we propose a dynamic single segmentation network (Omni-Seg) that learns to segment multiple tissue types using partially labeled images (i.e., only one tissue type is labeled for each training image) for renal pathology. By learning from ~150,000 patch-wise pathological images from six tissue types, the proposed Omni-Seg network achieved superior segmentation accuracy and less resource consumption when compared to the previous the multiple-network and multi-head design. In the testing stage, the proposed method obtains "completely labeled" tissue segmentation results using only "partially labeled" training images. The source code is available at https://github.com/ddrrnn123/Omni-Seg.
Learning TFIDF Enhanced Joint Embedding for Recipe-Image Cross-Modal Retrieval Service
Aug 02, 2021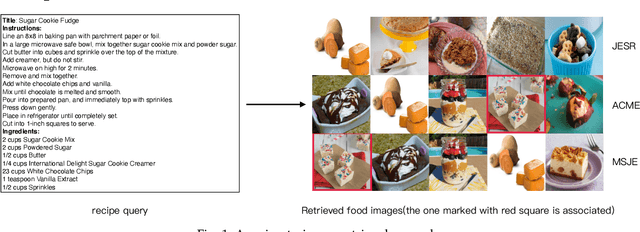

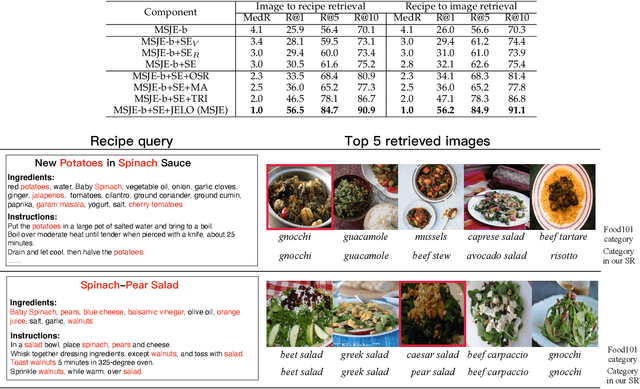
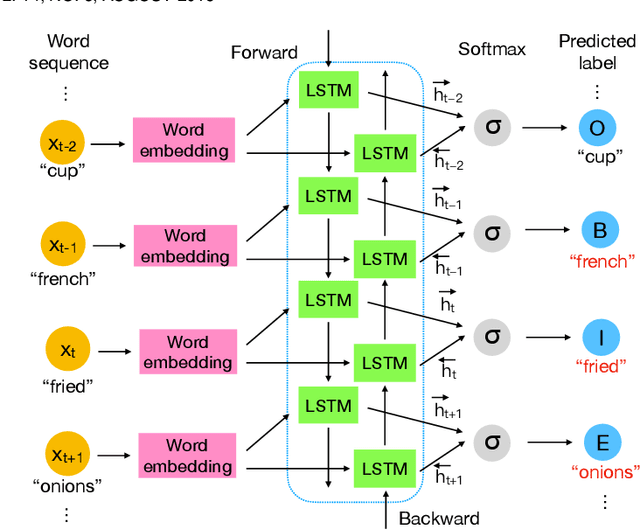
It is widely acknowledged that learning joint embeddings of recipes with images is challenging due to the diverse composition and deformation of ingredients in cooking procedures. We present a Multi-modal Semantics enhanced Joint Embedding approach (MSJE) for learning a common feature space between the two modalities (text and image), with the ultimate goal of providing high-performance cross-modal retrieval services. Our MSJE approach has three unique features. First, we extract the TFIDF feature from the title, ingredients and cooking instructions of recipes. By determining the significance of word sequences through combining LSTM learned features with their TFIDF features, we encode a recipe into a TFIDF weighted vector for capturing significant key terms and how such key terms are used in the corresponding cooking instructions. Second, we combine the recipe TFIDF feature with the recipe sequence feature extracted through two-stage LSTM networks, which is effective in capturing the unique relationship between a recipe and its associated image(s). Third, we further incorporate TFIDF enhanced category semantics to improve the mapping of image modality and to regulate the similarity loss function during the iterative learning of cross-modal joint embedding. Experiments on the benchmark dataset Recipe1M show the proposed approach outperforms the state-of-the-art approaches.
Image Restoration by Deep Projected GSURE
Feb 04, 2021



Ill-posed inverse problems appear in many image processing applications, such as deblurring and super-resolution. In recent years, solutions that are based on deep Convolutional Neural Networks (CNNs) have shown great promise. Yet, most of these techniques, which train CNNs using external data, are restricted to the observation models that have been used in the training phase. A recent alternative that does not have this drawback relies on learning the target image using internal learning. One such prominent example is the Deep Image Prior (DIP) technique that trains a network directly on the input image with a least-squares loss. In this paper, we propose a new image restoration framework that is based on minimizing a loss function that includes a "projected-version" of the Generalized SteinUnbiased Risk Estimator (GSURE) and parameterization of the latent image by a CNN. We demonstrate two ways to use our framework. In the first one, where no explicit prior is used, we show that the proposed approach outperforms other internal learning methods, such as DIP. In the second one, we show that our GSURE-based loss leads to improved performance when used within a plug-and-play priors scheme.