 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
QuTI! Quantifying Text-Image Consistency in Multimodal Documents
Apr 28, 2021
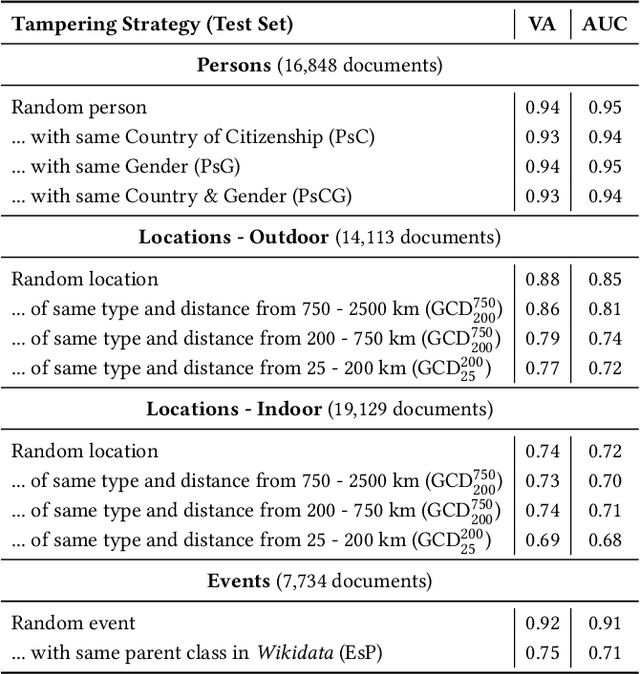
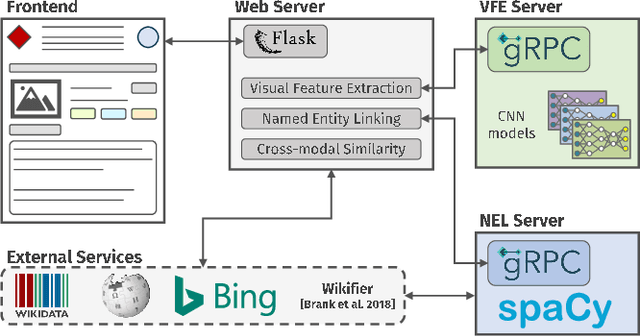
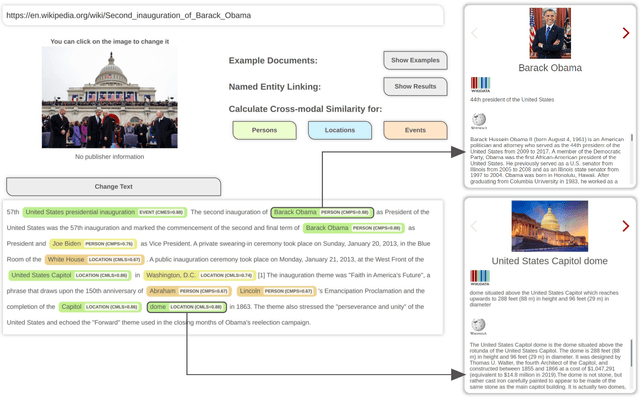
The World Wide Web and social media platforms have become popular sources for news and information. Typically, multimodal information, e.g., image and text is used to convey information more effectively and to attract attention. While in most cases image content is decorative or depicts additional information, it has also been leveraged to spread misinformation and rumors in recent years. In this paper, we present a Web-based demo application that automatically quantifies the cross-modal relations of entities (persons, locations, and events) in image and text. The applications are manifold. For example, the system can help users to explore multimodal articles more efficiently, or can assist human assessors and fact-checking efforts in the verification of the credibility of news stories, tweets, or other multimodal documents.
Iterative RAKI with Complex-Valued Convolution for Improved Image Reconstruction with Limited Scan-Specific Training Samples
Jan 10, 2022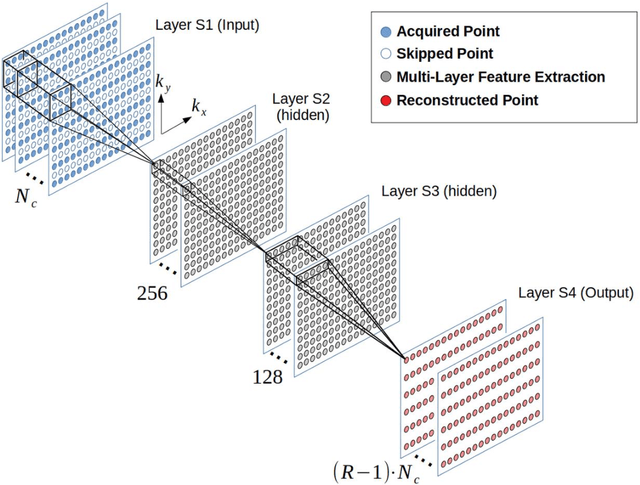
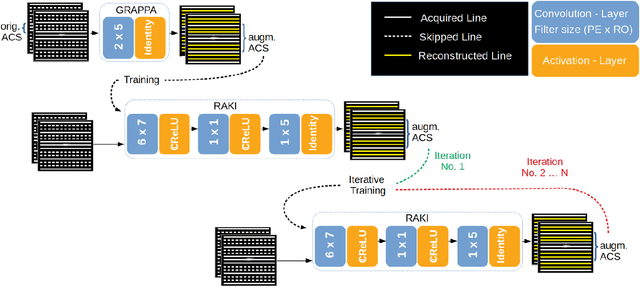
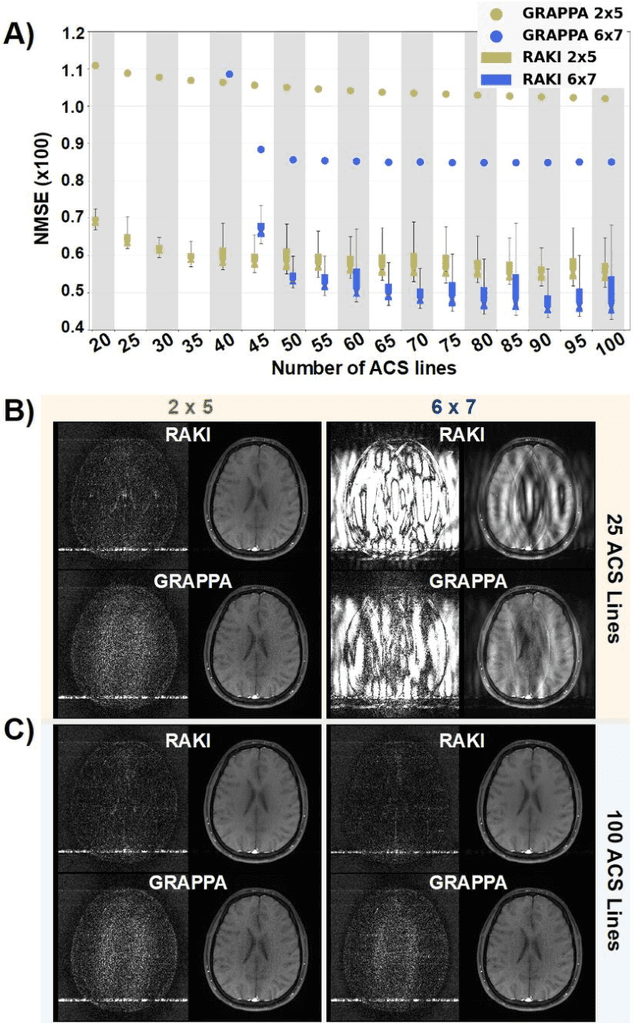
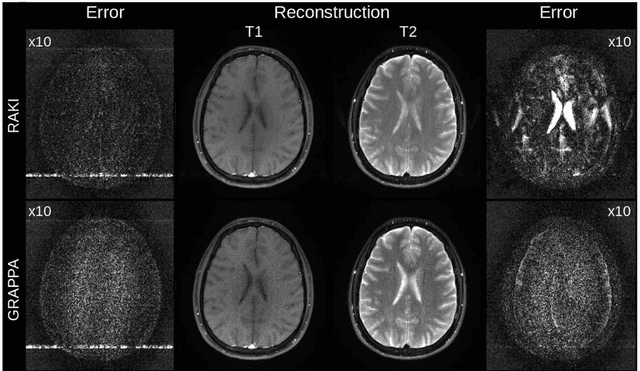
MRI scan time reduction is commonly achieved by Parallel Imaging methods, typically based on uniform undersampling of the inverse image space (a.k.a. k-space) and simultaneous signal reception with multiple receiver coils. The GRAPPA method interpolates missing k-space signals by linear combination of adjacent, acquired signals across all coils, and can be described by a convolution in k-space. Recently, a more generalized method called RAKI was introduced. RAKI is a deep-learning method that generalizes GRAPPA with additional convolution layers, on which a non-linear activation function is applied. This enables non-linear estimation of missing signals by convolutional neural networks. In analogy to GRAPPA, the convolution kernels in RAKI are trained using scan-specific training samples obtained from auto-calibration-signals (ACS). RAKI provides superior reconstruction quality compared to GRAPPA, however, often requires much more ACS due to its increased number of unknown parameters. In order to overcome this limitation, this study investigates the influence of training data on the reconstruction quality for standard 2D imaging, with particular focus on its amount and contrast information. Furthermore, an iterative k-space interpolation approach (iRAKI) is evaluated, which includes training data augmentation via an initial GRAPPA reconstruction, and refinement of convolution filters by iterative training. Using only 18, 20 and 25 ACS lines (8%), iRAKI outperforms RAKI by suppressing residual artefacts occurring at accelerations factors R=4 and R=5, and yields strong noise suppression in comparison to GRAPPA, underlined by quantitative quality metrics. Combination with a phase-constraint yields further improvement. Additionally, iRAKI shows better performance than GRAPPA and RAKI in case of pre-scan calibration and strongly varying contrast between training- and undersampled data.
Technical Report (v1.0)--Pseudo-random Cartesian Sampling for Dynamic MRI
Jun 08, 2022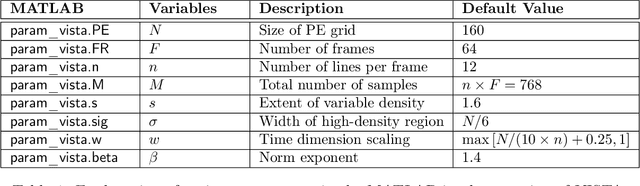
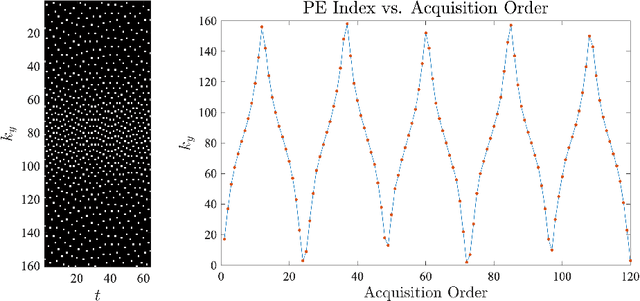
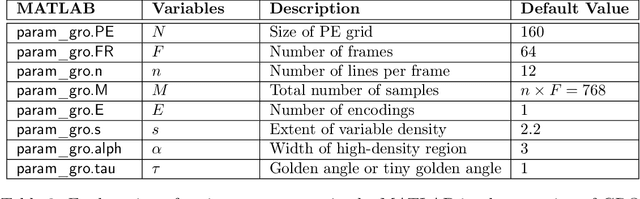
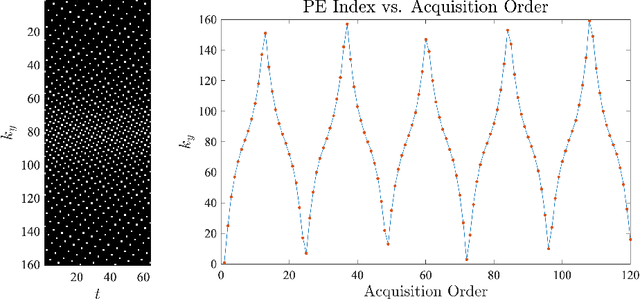
For an effective application of compressed sensing (CS), which exploits the underlying compressibility of an image, one of the requirements is that the undersampling artifact be incoherent (noise-like) in the sparsifying transform domain. For cardiovascular MRI (CMR), several pseudo-random sampling methods have been proposed that yield a high level of incoherence. In this technical report, we present a collection of five pseudo-random Cartesian sampling methods that can be applied to 2D cine and flow, 3D volumetric cine, and 4D flow imaging. Four out of the five presented methods yield fast computation for on-the-fly generation of the sampling mask, without the need to create and store pre-computed look-up tables. In addition, the sampling distribution is parameterized, providing control over the sampling density. For each sampling method in the report, (i) we briefly describe the methodology, (ii) list default values of the pertinent parameters, and (iii) provide a publicly available MATLAB implementation.
Impact of a DCT-driven Loss in Attention-based Knowledge-Distillation for Scene Recognition
May 04, 2022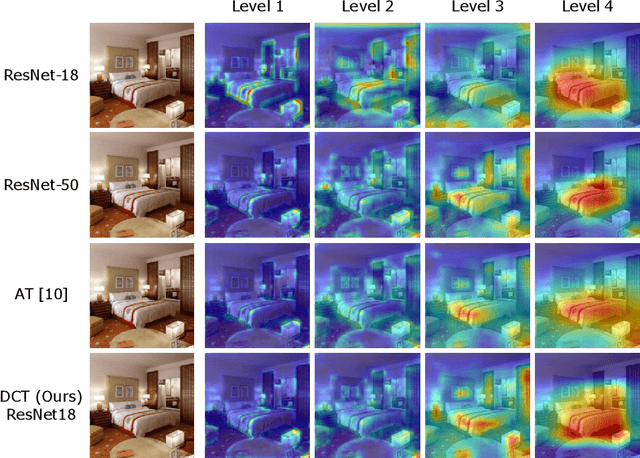

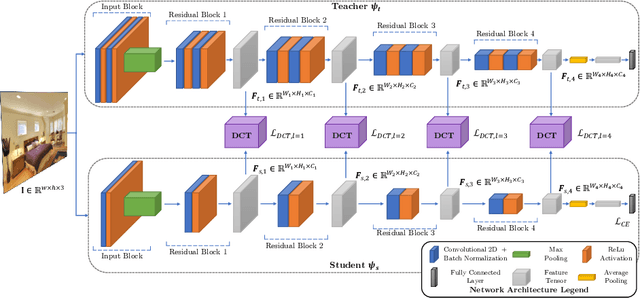
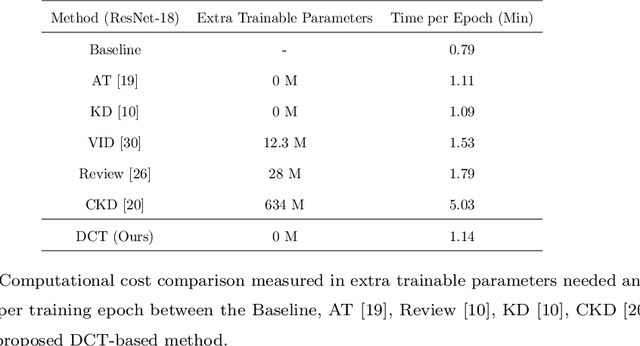
Knowledge Distillation (KD) is a strategy for the definition of a set of transferability gangways to improve the efficiency of Convolutional Neural Networks. Feature-based Knowledge Distillation is a subfield of KD that relies on intermediate network representations, either unaltered or depth-reduced via maximum activation maps, as the source knowledge. In this paper, we propose and analyse the use of a 2D frequency transform of the activation maps before transferring them. We pose that\textemdash by using global image cues rather than pixel estimates, this strategy enhances knowledge transferability in tasks such as scene recognition, defined by strong spatial and contextual relationships between multiple and varied concepts. To validate the proposed method, an extensive evaluation of the state-of-the-art in scene recognition is presented. Experimental results provide strong evidences that the proposed strategy enables the student network to better focus on the relevant image areas learnt by the teacher network, hence leading to better descriptive features and higher transferred performance than every other state-of-the-art alternative. We publicly release the training and evaluation framework used along this paper at http://www-vpu.eps.uam.es/publications/DCTBasedKDForSceneRecognition.
2-d signature of images and texture classification
May 10, 2022

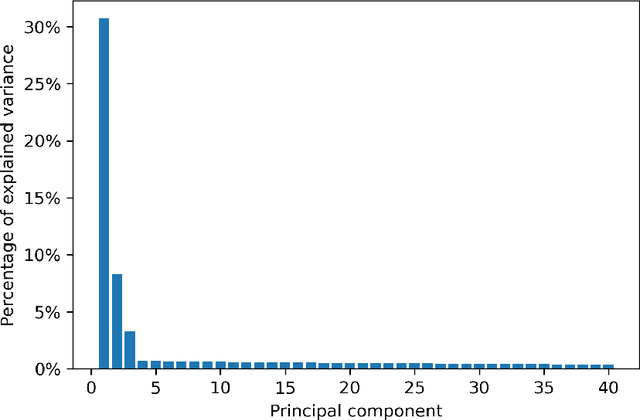
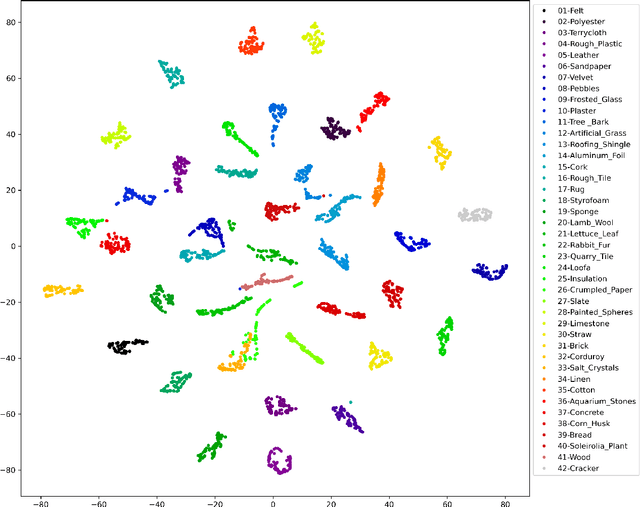
We introduce a proper notion of 2-dimensional signature for images. This object is inspired by the so-called rough paths theory, and it captures many essential features of a 2-dimensional object such as an image. It thus serves as a low-dimensional feature for pattern classification. Here we implement a simple procedure for texture classification. In this context, we show that a low dimensional set of features based on signatures produces an excellent accuracy.
Cooperative Training and Latent Space Data Augmentation for Robust Medical Image Segmentation
Jul 02, 2021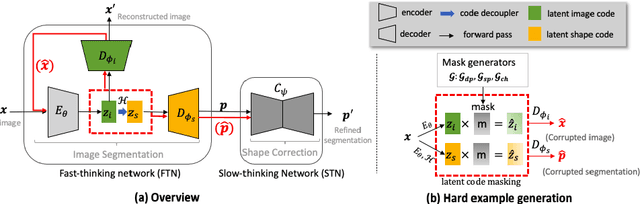
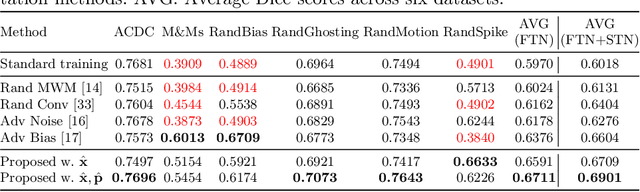
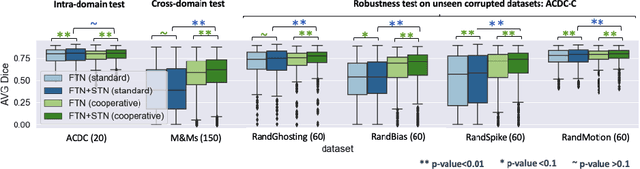
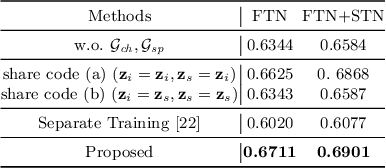
Deep learning-based segmentation methods are vulnerable to unforeseen data distribution shifts during deployment, e.g. change of image appearances or contrasts caused by different scanners, unexpected imaging artifacts etc. In this paper, we present a cooperative framework for training image segmentation models and a latent space augmentation method for generating hard examples. Both contributions improve model generalization and robustness with limited data. The cooperative training framework consists of a fast-thinking network (FTN) and a slow-thinking network (STN). The FTN learns decoupled image features and shape features for image reconstruction and segmentation tasks. The STN learns shape priors for segmentation correction and refinement. The two networks are trained in a cooperative manner. The latent space augmentation generates challenging examples for training by masking the decoupled latent space in both channel-wise and spatial-wise manners. We performed extensive experiments on public cardiac imaging datasets. Using only 10 subjects from a single site for training, we demonstrated improved cross-site segmentation performance and increased robustness against various unforeseen imaging artifacts compared to strong baseline methods. Particularly, cooperative training with latent space data augmentation yields 15% improvement in terms of average Dice score when compared to a standard training method.
DA-DRN: Degradation-Aware Deep Retinex Network for Low-Light Image Enhancement
Oct 05, 2021
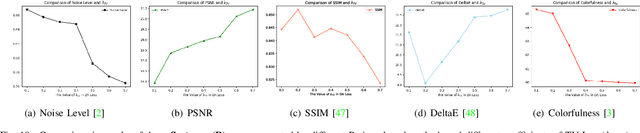

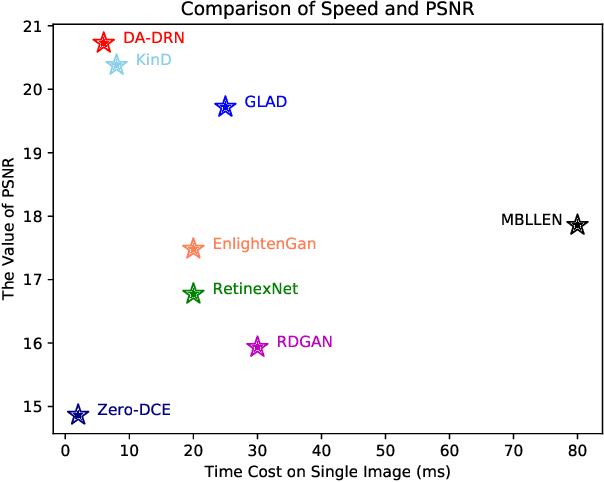
Images obtained in real-world low-light conditions are not only low in brightness, but they also suffer from many other types of degradation, such as color distortion, unknown noise, detail loss and halo artifacts. In this paper, we propose a Degradation-Aware Deep Retinex Network (denoted as DA-DRN) for low-light image enhancement and tackle the above degradation. Based on Retinex Theory, the decomposition net in our model can decompose low-light images into reflectance and illumination maps and deal with the degradation in the reflectance during the decomposition phase directly. We propose a Degradation-Aware Module (DA Module) which can guide the training process of the decomposer and enable the decomposer to be a restorer during the training phase without additional computational cost in the test phase. DA Module can achieve the purpose of noise removal while preserving detail information into the illumination map as well as tackle color distortion and halo artifacts. We introduce Perceptual Loss to train the enhancement network to generate the brightness-improved illumination maps which are more consistent with human visual perception. We train and evaluate the performance of our proposed model over the LOL real-world and LOL synthetic datasets, and we also test our model over several other frequently used datasets without Ground-Truth (LIME, DICM, MEF and NPE datasets). We conduct extensive experiments to demonstrate that our approach achieves a promising effect with good rubustness and generalization and outperforms many other state-of-the-art methods qualitatively and quantitatively. Our method only takes 7 ms to process an image with 600x400 resolution on a TITAN Xp GPU.
Fusion-Correction Network for Single-Exposure Correction and Multi-Exposure Fusion
Mar 05, 2022
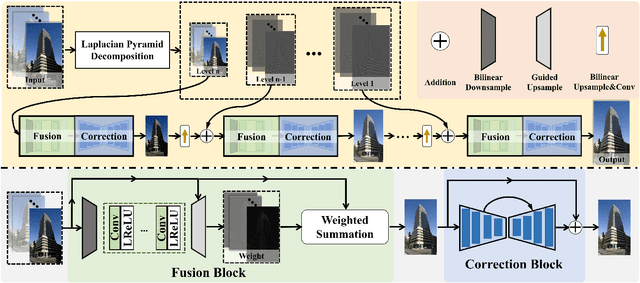


The photographs captured by digital cameras usually suffer from over-exposure or under-exposure problems. The Single-Exposure Correction (SEC) and Multi-Exposure Fusion (MEF) are two widely studied image processing tasks for image exposure enhancement. However, current SEC and MEF methods ignore the internal correlation between SEC and MEF, and are proposed under distinct frameworks. What's more, most MEF methods usually fail at processing a sequence containing only under-exposed or over-exposed images. To alleviate these problems, in this paper, we develop an integrated framework to simultaneously tackle the SEC and MEF tasks. Built upon the Laplacian Pyramid (LP) decomposition, we propose a novel Fusion-Correction Network (FCNet) to fuse and correct an image sequence sequentially in a multi-level scheme. In each LP level, the image sequence is feed into a Fusion block and a Correction block for consecutive image fusion and exposure correction. The corrected image is upsampled and re-composed with the high-frequency detail components in next-level, producing the base sequence for the next-level blocks. Experiments on the benchmark dataset demonstrate that our FCNet is effective on both the SEC and MEF tasks.
Semantically Self-Aligned Network for Text-to-Image Part-aware Person Re-identification
Aug 09, 2021
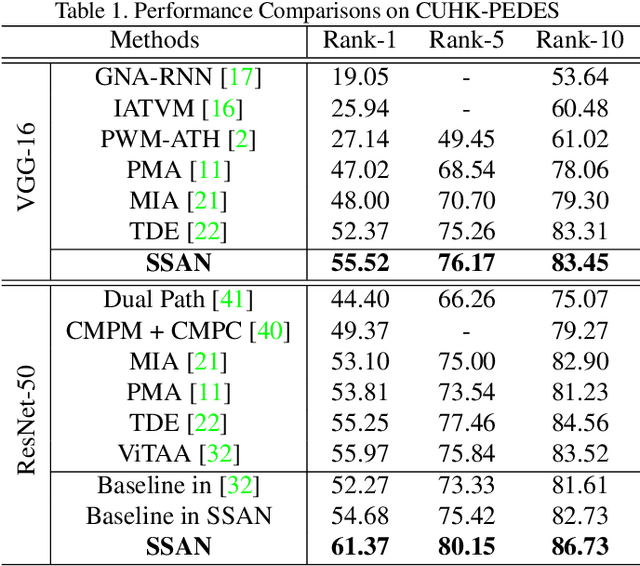
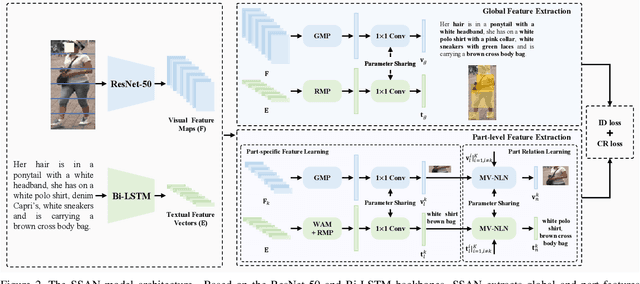
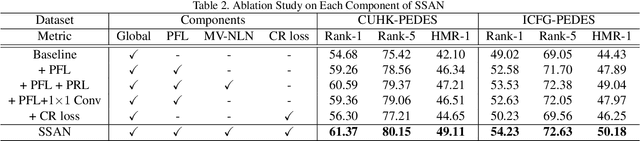
Text-to-image person re-identification (ReID) aims to search for images containing a person of interest using textual descriptions. However, due to the significant modality gap and the large intra-class variance in textual descriptions, text-to-image ReID remains a challenging problem. Accordingly, in this paper, we propose a Semantically Self-Aligned Network (SSAN) to handle the above problems. First, we propose a novel method that automatically extracts semantically aligned part-level features from the two modalities. Second, we design a multi-view non-local network that captures the relationships between body parts, thereby establishing better correspondences between body parts and noun phrases. Third, we introduce a Compound Ranking (CR) loss that makes use of textual descriptions for other images of the same identity to provide extra supervision, thereby effectively reducing the intra-class variance in textual features. Finally, to expedite future research in text-to-image ReID, we build a new database named ICFG-PEDES. Extensive experiments demonstrate that SSAN outperforms state-of-the-art approaches by significant margins. Both the new ICFG-PEDES database and the SSAN code are available at https://github.com/zifyloo/SSAN.
Categorical Relation-Preserving Contrastive Knowledge Distillation for Medical Image Classification
Jul 07, 2021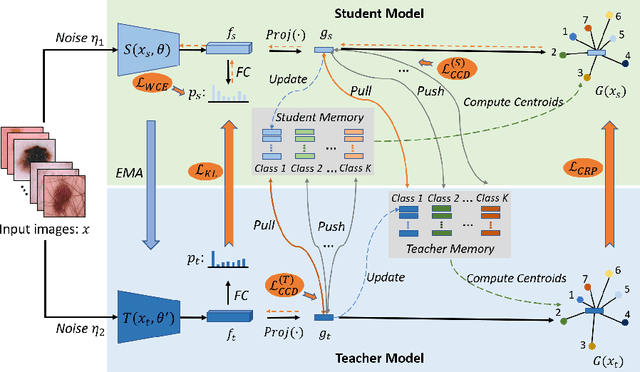
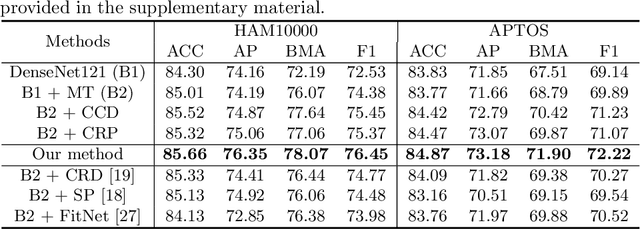
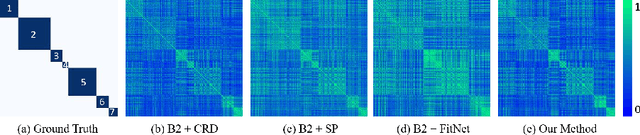
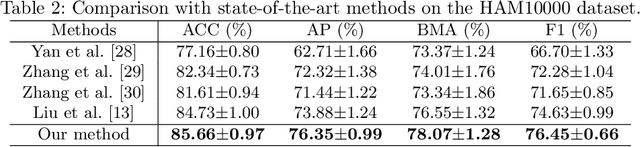
The amount of medical images for training deep classification models is typically very scarce, making these deep models prone to overfit the training data. Studies showed that knowledge distillation (KD), especially the mean-teacher framework which is more robust to perturbations, can help mitigate the over-fitting effect. However, directly transferring KD from computer vision to medical image classification yields inferior performance as medical images suffer from higher intra-class variance and class imbalance. To address these issues, we propose a novel Categorical Relation-preserving Contrastive Knowledge Distillation (CRCKD) algorithm, which takes the commonly used mean-teacher model as the supervisor. Specifically, we propose a novel Class-guided Contrastive Distillation (CCD) module to pull closer positive image pairs from the same class in the teacher and student models, while pushing apart negative image pairs from different classes. With this regularization, the feature distribution of the student model shows higher intra-class similarity and inter-class variance. Besides, we propose a Categorical Relation Preserving (CRP) loss to distill the teacher's relational knowledge in a robust and class-balanced manner. With the contribution of the CCD and CRP, our CRCKD algorithm can distill the relational knowledge more comprehensively. Extensive experiments on the HAM10000 and APTOS datasets demonstrate the superiority of the proposed CRCKD method.