 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
InvNorm: Domain Generalization for Object Detection in Gastrointestinal Endoscopy
May 05, 2022
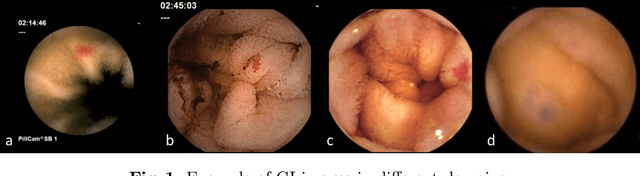
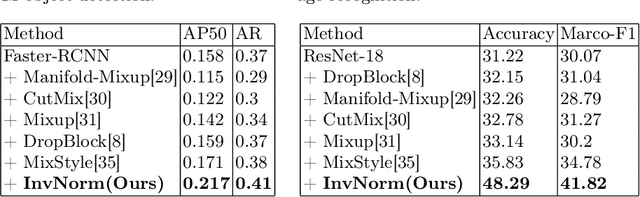
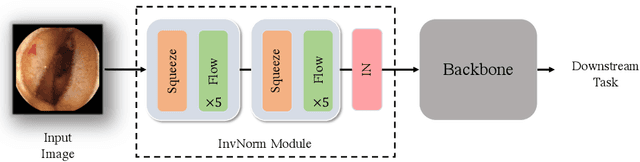
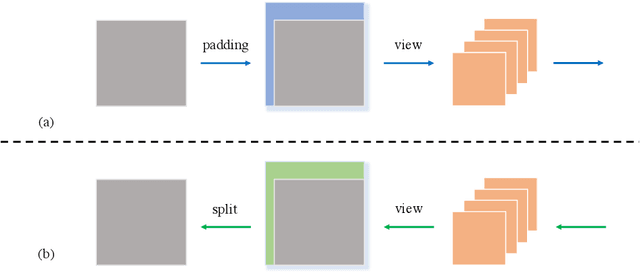
Domain Generalization is a challenging topic in computer vision, especially in Gastrointestinal Endoscopy image analysis. Due to several device limitations and ethical reasons, current open-source datasets are typically collected on a limited number of patients using the same brand of sensors. Different brands of devices and individual differences will significantly affect the model's generalizability. Therefore, to address the generalization problem in GI(Gastrointestinal) endoscopy, we propose a multi-domain GI dataset and a light, plug-in block called InvNorm(Invertible Normalization), which could achieve a better generalization performance in any structure. Previous DG(Domain Generalization) methods fail to achieve invertible transformation, which would lead to some misleading augmentation. Moreover, these models would be more likely to lead to medical ethics issues. Our method utilizes normalizing flow to achieve invertible and explainable style normalization to address the problem. The effectiveness of InvNorm is demonstrated on a wide range of tasks, including GI recognition, GI object detection, and natural image recognition.
Rethinking the Image Feature Biases Exhibited by Deep CNN Models
Nov 03, 2021
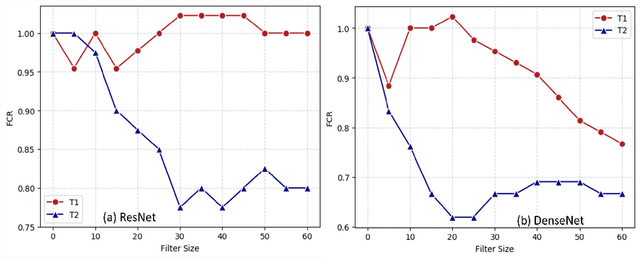


In recent years, convolutional neural networks (CNNs) have been applied successfully in many fields. However, such deep neural models are still regarded as black box in most tasks. One of the fundamental issues underlying this problem is understanding which features are most influential in image recognition tasks and how they are processed by CNNs. It is widely accepted that CNN models combine low-level features to form complex shapes until the object can be readily classified, however, several recent studies have argued that texture features are more important than other features. In this paper, we assume that the importance of certain features varies depending on specific tasks, i.e., specific tasks exhibit a feature bias. We designed two classification tasks based on human intuition to train deep neural models to identify anticipated biases. We devised experiments comprising many tasks to test these biases for the ResNet and DenseNet models. From the results, we conclude that (1) the combined effect of certain features is typically far more influential than any single feature; (2) in different tasks, neural models can perform different biases, that is, we can design a specific task to make a neural model biased toward a specific anticipated feature.
An Efficient Architecture and High-Throughput Implementation of CCSDS-123.0-B-2 Hybrid Entropy Coder Targeting Space-Grade SRAM FPGA Technology
May 09, 2022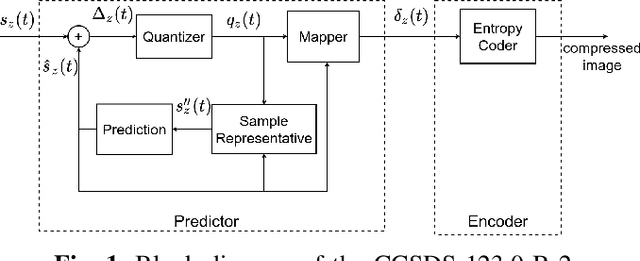
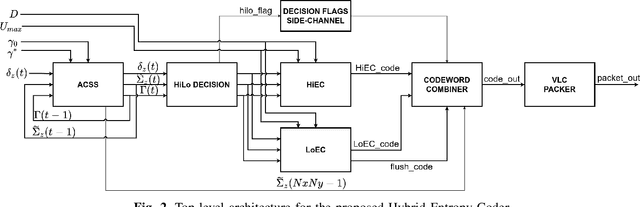
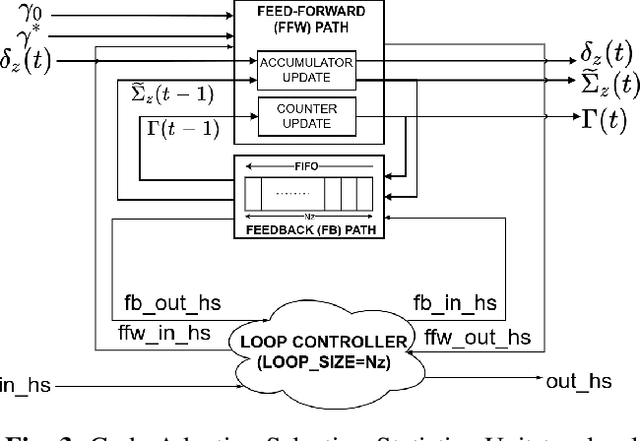
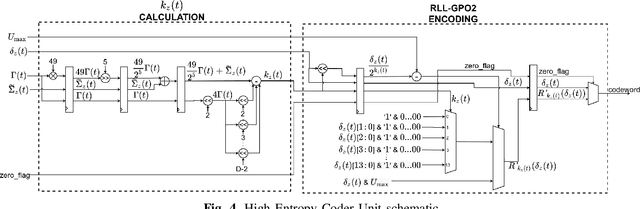
Nowadays, hyperspectral imaging is recognized as cornerstone remote sensing technology. The explosive growth in image data volume and instrument data rates, compete with limited on-board storage resources and downlink bandwidth, making hyperspectral image data compression a mission critical on-board processing task. The Consultative Committee for Space Data Systems (CCSDS) extended the previous issue of the CCSDS-123.0 Recommended Standard for multi- and hyperspectral image compression to provide with Near-Lossless compression functionality. A key feature of the CCSDS-123.0-B-2 is the improved Hybrid Entropy Coder, which at low bit rates, provides substantially better compression performance than the Issue 1 entropy coders. In this paper, we introduce a high-throughput hardware implementation of the CCSDS-123.0-B-2 Hybrid Entropy Coder. The introduced architecture exploits the systolic design pattern to provide modularity and latency insensitivity in a deep and elastic pipeline achieving a constant throughput of 1 sample/cycle with a small FPGA resource footprint. This architecture is described in portable VHDL RTL and is implemented, validated and demonstrated on a commercially available Xilinx KCU105 development board hosting a Xilinx Kintex Ultrascale XCKU040 SRAM FPGA, and thus, is directly transferable to Xilinx Radiation Tolerant Kintex UltraScale XQRKU060 space-grade devices for space deployments. Moreover, state-of-the-art SpaceFibre (ECSS-E-ST-50-11C) serial link interface and test equipment were used in the validation platform to emulate an on-board deployment. The introduced CCSDS-123.0-B-2 Hybrid Entropy Encoder achieves a constant throughput performance of 305 MSamples/s. To the best of our knowledge, this is the first published fully-compliant architecture and high-throughput implementation of the CCSDS-123.0-B-2 Hybrid Entropy Coder, targeting space-grade FPGA technology.
Vision Xformers: Efficient Attention for Image Classification
Aug 01, 2021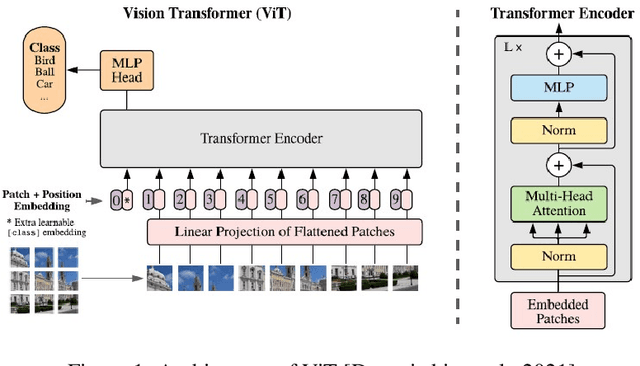

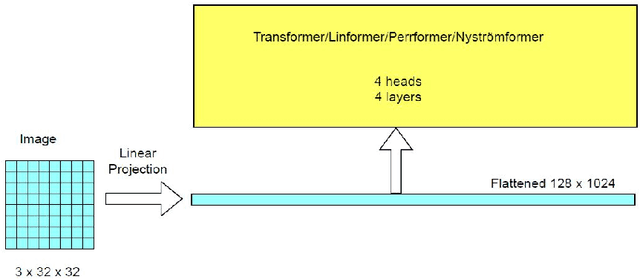

We propose three improvements to vision transformers (ViT) to reduce the number of trainable parameters without compromising classification accuracy. We address two shortcomings of the early ViT architectures -- quadratic bottleneck of the attention mechanism and the lack of an inductive bias in their architectures that rely on unrolling the two-dimensional image structure. Linear attention mechanisms overcome the bottleneck of quadratic complexity, which restricts application of transformer models in vision tasks. We modify the ViT architecture to work on longer sequence data by replacing the quadratic attention with efficient transformers, such as Performer, Linformer and Nystr\"omformer of linear complexity creating Vision X-formers (ViX). We show that all three versions of ViX may be more accurate than ViT for image classification while using far fewer parameters and computational resources. We also compare their performance with FNet and multi-layer perceptron (MLP) mixer. We further show that replacing the initial linear embedding layer by convolutional layers in ViX further increases their performance. Furthermore, our tests on recent vision transformer models, such as LeViT, Convolutional vision Transformer (CvT), Compact Convolutional Transformer (CCT) and Pooling-based Vision Transformer (PiT) show that replacing the attention with Nystr\"omformer or Performer saves GPU usage and memory without deteriorating the classification accuracy. We also show that replacing the standard learnable 1D position embeddings in ViT with Rotary Position Embedding (RoPE) give further improvements in accuracy. Incorporating these changes can democratize transformers by making them accessible to those with limited data and computing resources.
Domain Adaptive 3D Pose Augmentation for In-the-wild Human Mesh Recovery
Jun 21, 2022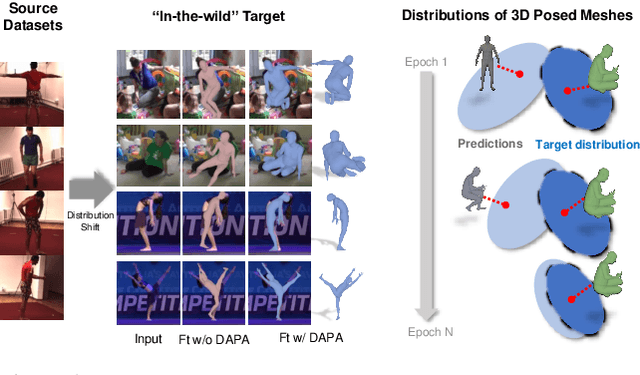
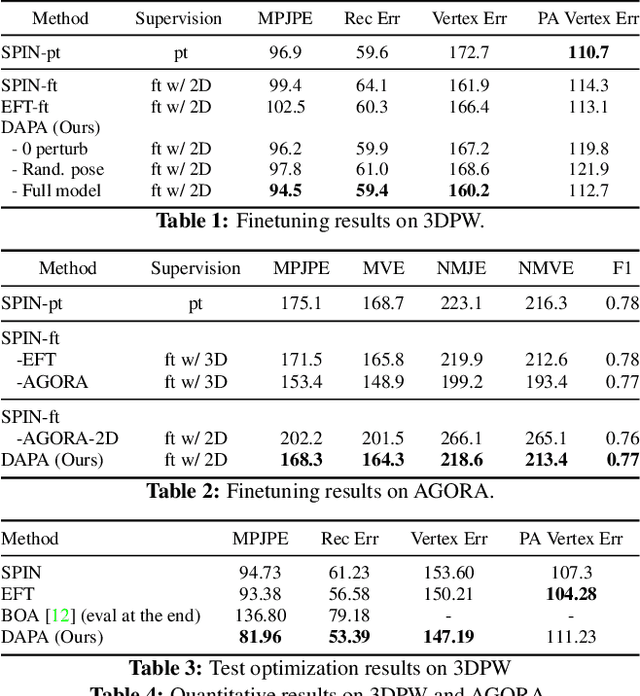
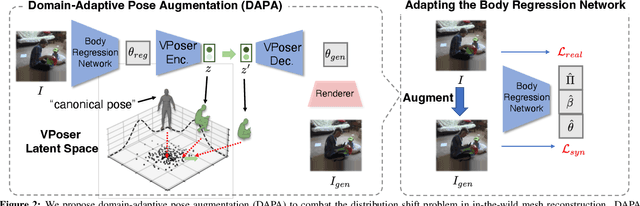

The ability to perceive 3D human bodies from a single image has a multitude of applications ranging from entertainment and robotics to neuroscience and healthcare. A fundamental challenge in human mesh recovery is in collecting the ground truth 3D mesh targets required for training, which requires burdensome motion capturing systems and is often limited to indoor laboratories. As a result, while progress is made on benchmark datasets collected in these restrictive settings, models fail to generalize to real-world ``in-the-wild'' scenarios due to distribution shifts. We propose Domain Adaptive 3D Pose Augmentation (DAPA), a data augmentation method that enhances the model's generalization ability in in-the-wild scenarios. DAPA combines the strength of methods based on synthetic datasets by getting direct supervision from the synthesized meshes, and domain adaptation methods by using ground truth 2D keypoints from the target dataset. We show quantitatively that finetuning with DAPA effectively improves results on benchmarks 3DPW and AGORA. We further demonstrate the utility of DAPA on a challenging dataset curated from videos of real-world parent-child interaction.
MISS GAN: A Multi-IlluStrator Style Generative Adversarial Network for image to illustration translation
Aug 12, 2021
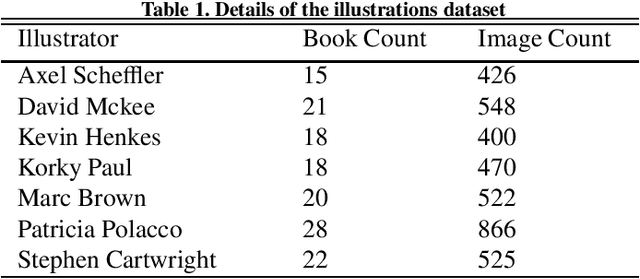
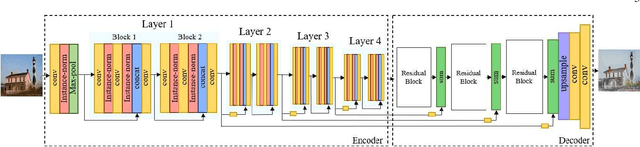

Unsupervised style transfer that supports diverse input styles using only one trained generator is a challenging and interesting task in computer vision. This paper proposes a Multi-IlluStrator Style Generative Adversarial Network (MISS GAN) that is a multi-style framework for unsupervised image-to-illustration translation, which can generate styled yet content preserving images. The illustrations dataset is a challenging one since it is comprised of illustrations of seven different illustrators, hence contains diverse styles. Existing methods require to train several generators (as the number of illustrators) to handle the different illustrators' styles, which limits their practical usage, or require to train an image specific network, which ignores the style information provided in other images of the illustrator. MISS GAN is both input image specific and uses the information of other images using only one trained model.
Large-Margin Representation Learning for Texture Classification
Jun 17, 2022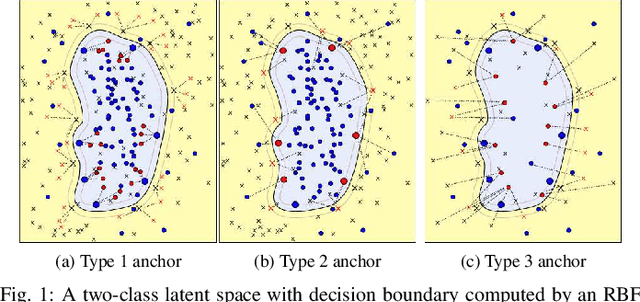

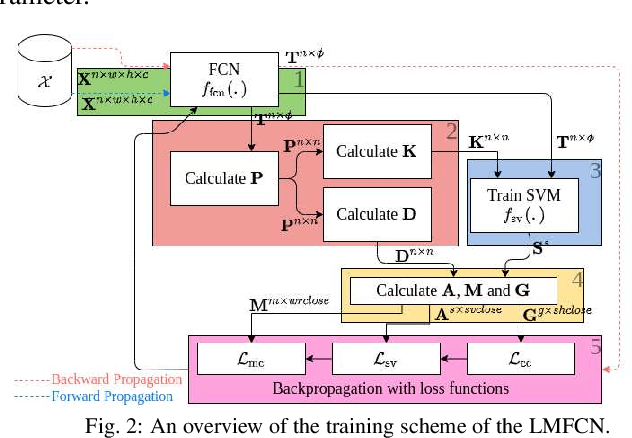
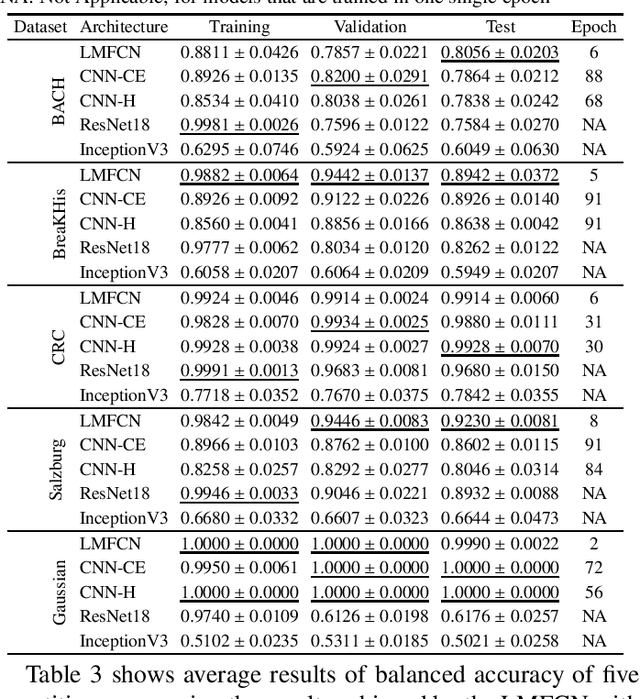
This paper presents a novel approach combining convolutional layers (CLs) and large-margin metric learning for training supervised models on small datasets for texture classification. The core of such an approach is a loss function that computes the distances between instances of interest and support vectors. The objective is to update the weights of CLs iteratively to learn a representation with a large margin between classes. Each iteration results in a large-margin discriminant model represented by support vectors based on such a representation. The advantage of the proposed approach w.r.t. convolutional neural networks (CNNs) is two-fold. First, it allows representation learning with a small amount of data due to the reduced number of parameters compared to an equivalent CNN. Second, it has a low training cost since the backpropagation considers only support vectors. The experimental results on texture and histopathologic image datasets have shown that the proposed approach achieves competitive accuracy with lower computational cost and faster convergence when compared to equivalent CNNs.
Tune It or Don't Use It: Benchmarking Data-Efficient Image Classification
Aug 30, 2021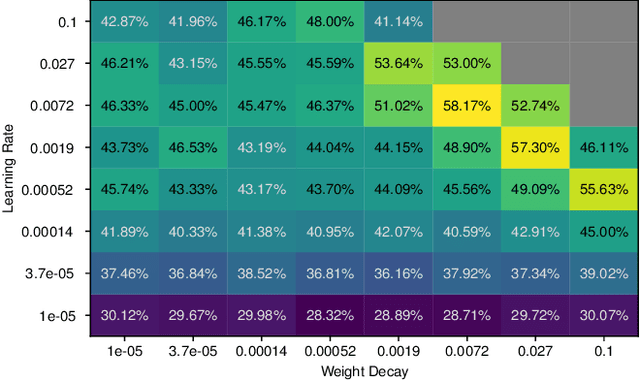
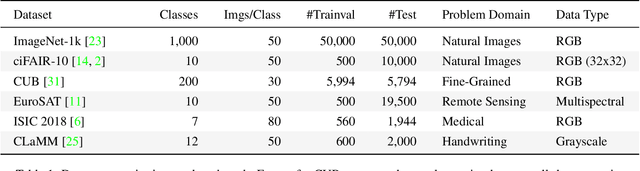

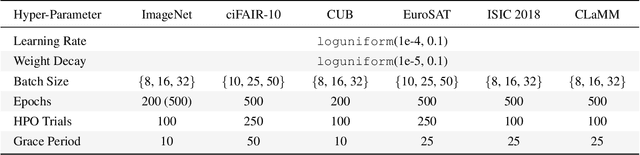
Data-efficient image classification using deep neural networks in settings, where only small amounts of labeled data are available, has been an active research area in the recent past. However, an objective comparison between published methods is difficult, since existing works use different datasets for evaluation and often compare against untuned baselines with default hyper-parameters. We design a benchmark for data-efficient image classification consisting of six diverse datasets spanning various domains (e.g., natural images, medical imagery, satellite data) and data types (RGB, grayscale, multispectral). Using this benchmark, we re-evaluate the standard cross-entropy baseline and eight methods for data-efficient deep learning published between 2017 and 2021 at renowned venues. For a fair and realistic comparison, we carefully tune the hyper-parameters of all methods on each dataset. Surprisingly, we find that tuning learning rate, weight decay, and batch size on a separate validation split results in a highly competitive baseline, which outperforms all but one specialized method and performs competitively to the remaining one.
Consistency Learning via Decoding Path Augmentation for Transformers in Human Object Interaction Detection
Apr 11, 2022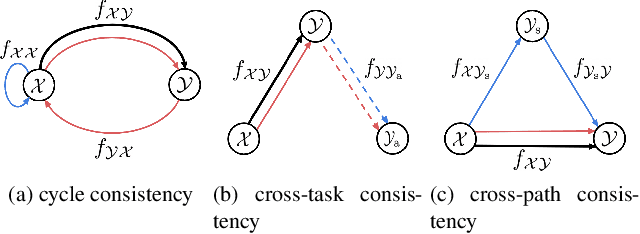
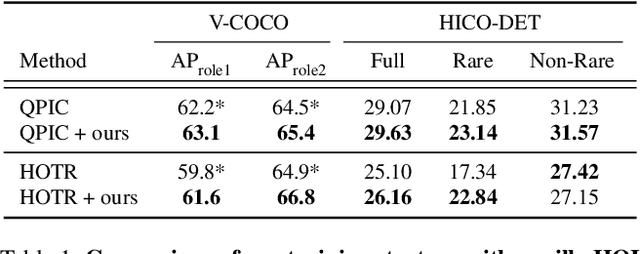
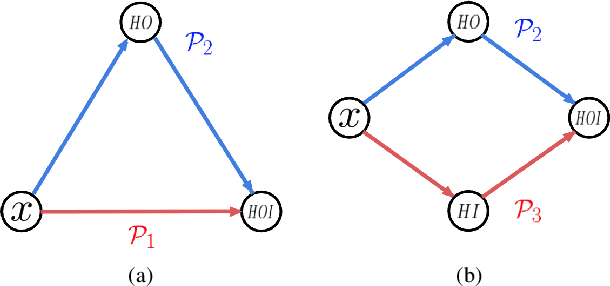
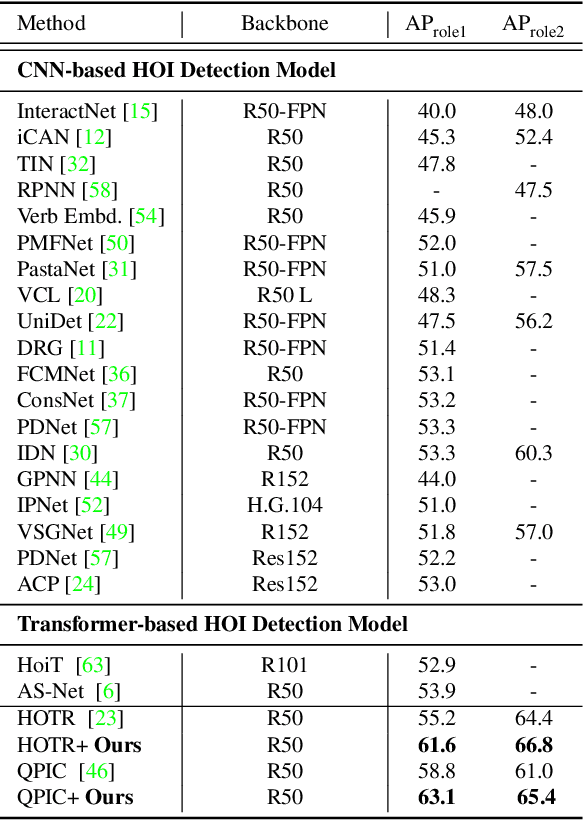
Human-Object Interaction detection is a holistic visual recognition task that entails object detection as well as interaction classification. Previous works of HOI detection has been addressed by the various compositions of subset predictions, e.g., Image -> HO -> I, Image -> HI -> O. Recently, transformer based architecture for HOI has emerged, which directly predicts the HOI triplets in an end-to-end fashion (Image -> HOI). Motivated by various inference paths for HOI detection, we propose cross-path consistency learning (CPC), which is a novel end-to-end learning strategy to improve HOI detection for transformers by leveraging augmented decoding paths. CPC learning enforces all the possible predictions from permuted inference sequences to be consistent. This simple scheme makes the model learn consistent representations, thereby improving generalization without increasing model capacity. Our experiments demonstrate the effectiveness of our method, and we achieved significant improvement on V-COCO and HICO-DET compared to the baseline models. Our code is available at https://github.com/mlvlab/CPChoi.
PoisonedEncoder: Poisoning the Unlabeled Pre-training Data in Contrastive Learning
May 17, 2022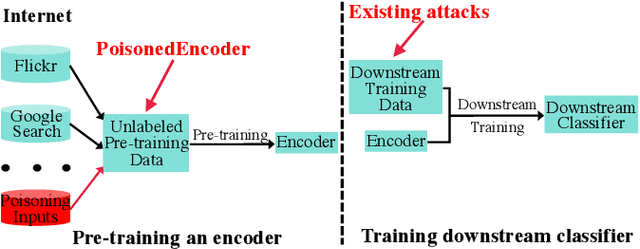
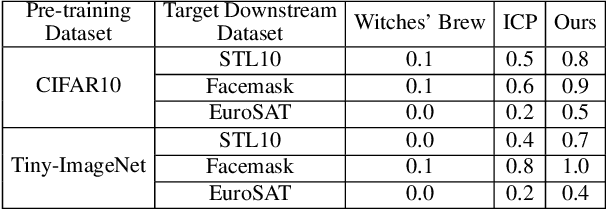
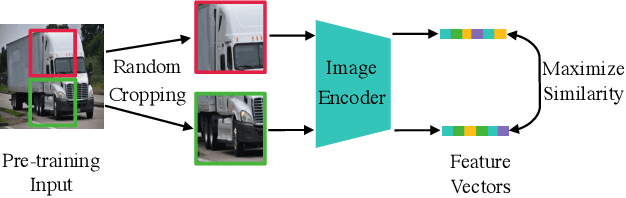

Contrastive learning pre-trains an image encoder using a large amount of unlabeled data such that the image encoder can be used as a general-purpose feature extractor for various downstream tasks. In this work, we propose PoisonedEncoder, a data poisoning attack to contrastive learning. In particular, an attacker injects carefully crafted poisoning inputs into the unlabeled pre-training data, such that the downstream classifiers built based on the poisoned encoder for multiple target downstream tasks simultaneously classify attacker-chosen, arbitrary clean inputs as attacker-chosen, arbitrary classes. We formulate our data poisoning attack as a bilevel optimization problem, whose solution is the set of poisoning inputs; and we propose a contrastive-learning-tailored method to approximately solve it. Our evaluation on multiple datasets shows that PoisonedEncoder achieves high attack success rates while maintaining the testing accuracy of the downstream classifiers built upon the poisoned encoder for non-attacker-chosen inputs. We also evaluate five defenses against PoisonedEncoder, including one pre-processing, three in-processing, and one post-processing defenses. Our results show that these defenses can decrease the attack success rate of PoisonedEncoder, but they also sacrifice the utility of the encoder or require a large clean pre-training dataset.