 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RangeSeg: Range-Aware Real Time Segmentation of 3D LiDAR Point Clouds
May 02, 2022
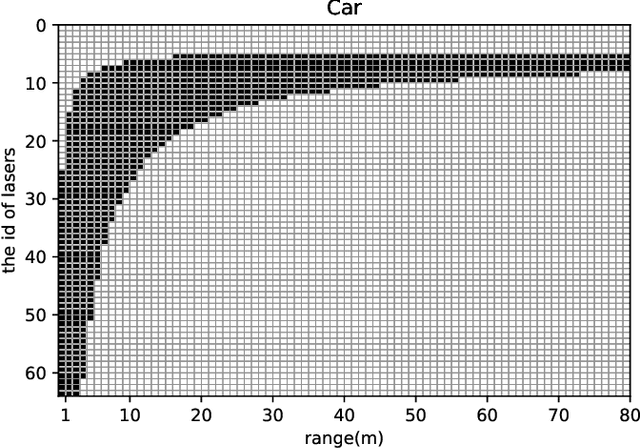
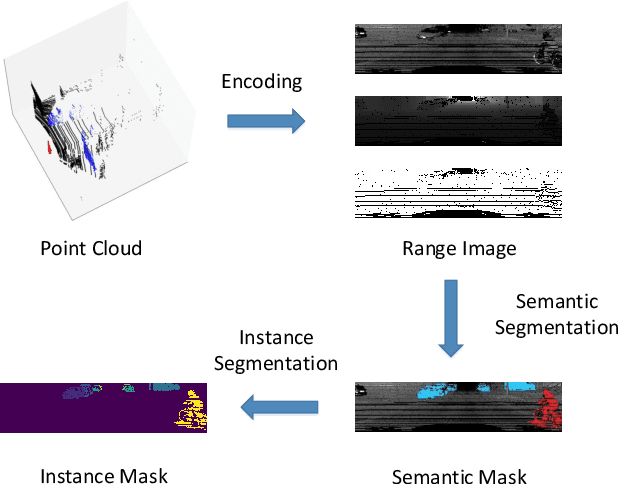
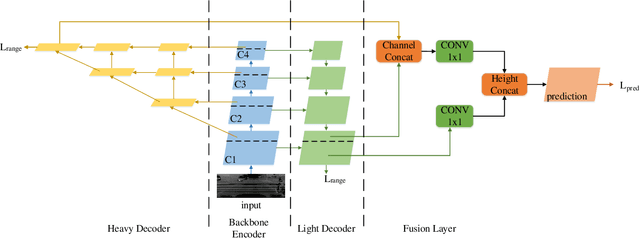
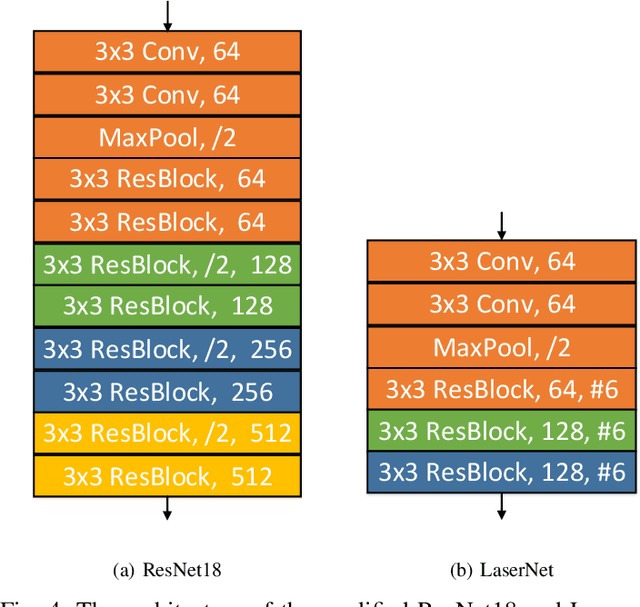
Semantic outdoor scene understanding based on 3D LiDAR point clouds is a challenging task for autonomous driving due to the sparse and irregular data structure. This paper takes advantages of the uneven range distribution of different LiDAR laser beams to propose a range aware instance segmentation network, RangeSeg. RangeSeg uses a shared encoder backbone with two range dependent decoders. A heavy decoder only computes top of a range image where the far and small objects locate to improve small object detection accuracy, and a light decoder computes whole range image for low computational cost. The results are further clustered by the DBSCAN method with a resolution weighted distance function to get instance-level segmentation results. Experiments on the KITTI dataset show that RangeSeg outperforms the state-of-the-art semantic segmentation methods with enormous speedup and improves the instance-level segmentation performance on small and far objects. The whole RangeSeg pipeline meets the real time requirement on NVIDIA\textsuperscript{\textregistered} JETSON AGX Xavier with 19 frames per second in average.
T-Net: Deep Stacked Scale-Iteration Network for Image Dehazing
Jun 05, 2021
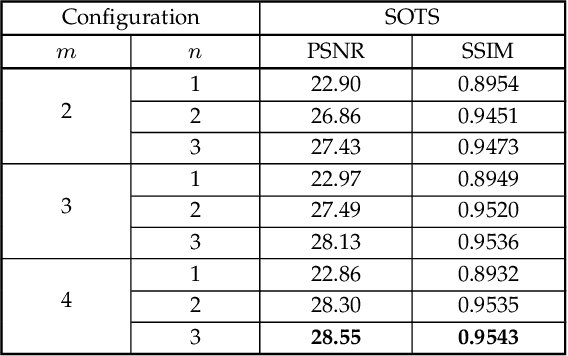
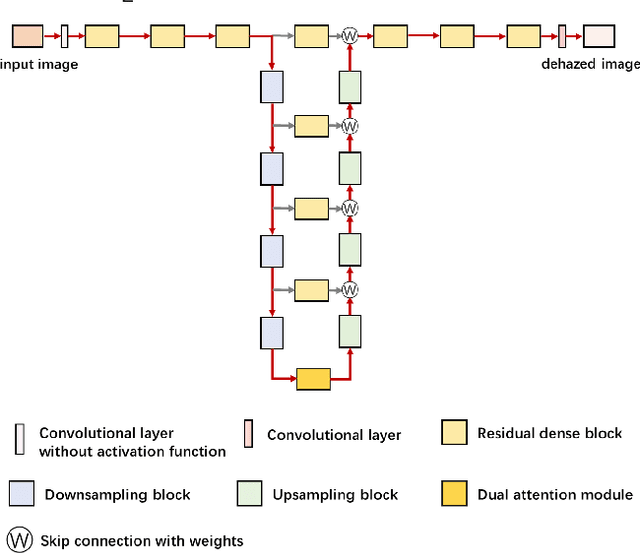
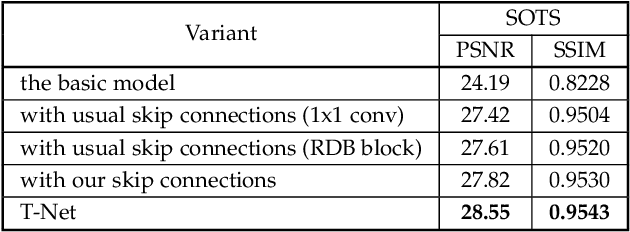
Hazy images reduce the visibility of the image content, and haze will lead to failure in handling subsequent computer vision tasks. In this paper, we address the problem of image dehazing by proposing a dehazing network named T-Net, which consists of a backbone network based on the U-Net architecture and a dual attention module. And it can achieve multi-scale feature fusion by using skip connections with a new fusion strategy. Furthermore, by repeatedly unfolding the plain T-Net, Stack T-Net is proposed to take advantage of the dependence of deep features across stages via a recursive strategy. In order to reduce network parameters, the intra-stage recursive computation of ResNet is adopted in our Stack T-Net. And we take both the stage-wise result and the original hazy image as input to each T-Net and finally output the prediction of clean image. Experimental results on both synthetic and real-world images demonstrate that our plain T-Net and the advanced Stack T-Net perform favorably against the state-of-the-art dehazing algorithms, and show that our Stack T-Net could further improve the dehazing effect, demonstrating the effectiveness of the recursive strategy.
Neural Machine Translation with Phrase-Level Universal Visual Representations
Mar 19, 2022

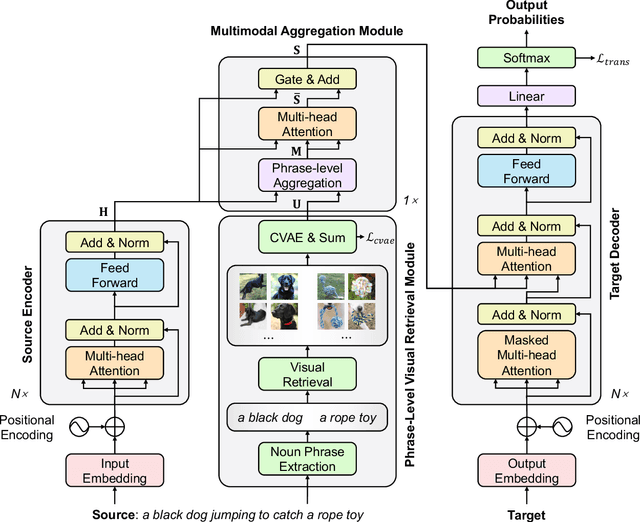
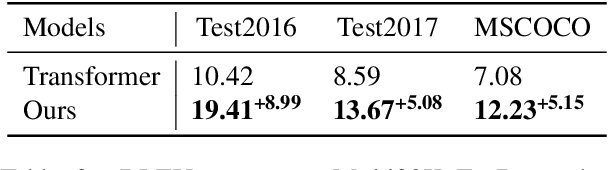
Multimodal machine translation (MMT) aims to improve neural machine translation (NMT) with additional visual information, but most existing MMT methods require paired input of source sentence and image, which makes them suffer from shortage of sentence-image pairs. In this paper, we propose a phrase-level retrieval-based method for MMT to get visual information for the source input from existing sentence-image data sets so that MMT can break the limitation of paired sentence-image input. Our method performs retrieval at the phrase level and hence learns visual information from pairs of source phrase and grounded region, which can mitigate data sparsity. Furthermore, our method employs the conditional variational auto-encoder to learn visual representations which can filter redundant visual information and only retain visual information related to the phrase. Experiments show that the proposed method significantly outperforms strong baselines on multiple MMT datasets, especially when the textual context is limited.
Differentiable Point-Based Radiance Fields for Efficient View Synthesis
Jun 08, 2022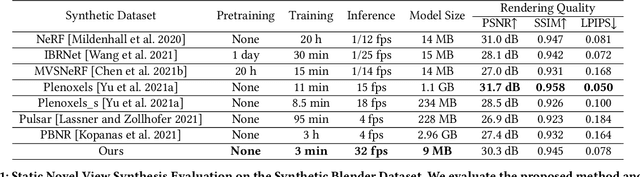
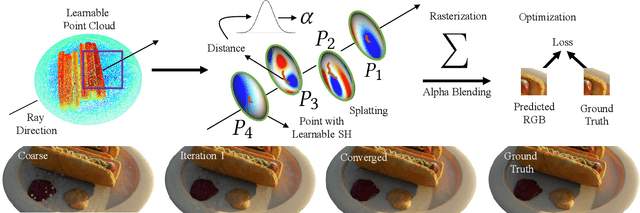
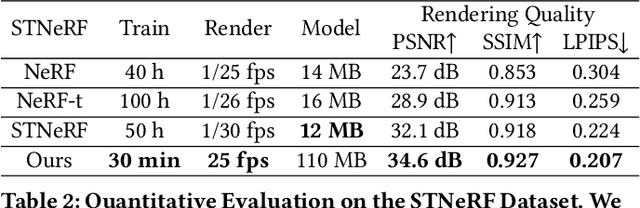

We propose a differentiable rendering algorithm for efficient novel view synthesis. By departing from volume-based representations in favor of a learned point representation, we improve on existing methods more than an order of magnitude in memory and runtime, both in training and inference. The method begins with a uniformly-sampled random point cloud and learns per-point position and view-dependent appearance, using a differentiable splat-based renderer to evolve the model to match a set of input images. Our method is up to 300x faster than NeRF in both training and inference, with only a marginal sacrifice in quality, while using less than 10~MB of memory for a static scene. For dynamic scenes, our method trains two orders of magnitude faster than STNeRF and renders at near interactive rate, while maintaining high image quality and temporal coherence even without imposing any temporal-coherency regularizers.
StylizedNeRF: Consistent 3D Scene Stylization as Stylized NeRF via 2D-3D Mutual Learning
May 24, 2022

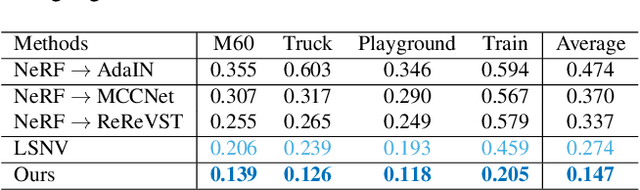
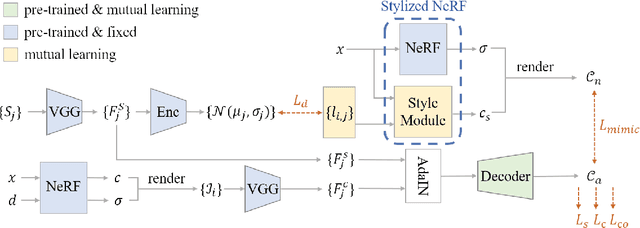
3D scene stylization aims at generating stylized images of the scene from arbitrary novel views following a given set of style examples, while ensuring consistency when rendered from different views. Directly applying methods for image or video stylization to 3D scenes cannot achieve such consistency. Thanks to recently proposed neural radiance fields (NeRF), we are able to represent a 3D scene in a consistent way. Consistent 3D scene stylization can be effectively achieved by stylizing the corresponding NeRF. However, there is a significant domain gap between style examples which are 2D images and NeRF which is an implicit volumetric representation. To address this problem, we propose a novel mutual learning framework for 3D scene stylization that combines a 2D image stylization network and NeRF to fuse the stylization ability of 2D stylization network with the 3D consistency of NeRF. We first pre-train a standard NeRF of the 3D scene to be stylized and replace its color prediction module with a style network to obtain a stylized NeRF.It is followed by distilling the prior knowledge of spatial consistency from NeRF to the 2D stylization network through an introduced consistency loss. We also introduce a mimic loss to supervise the mutual learning of the NeRF style module and fine-tune the 2D stylization decoder. In order to further make our model handle ambiguities of 2D stylization results, we introduce learnable latent codes that obey the probability distributions conditioned on the style. They are attached to training samples as conditional inputs to better learn the style module in our novel stylized NeRF. Experimental results demonstrate that our method is superior to existing approaches in both visual quality and long-range consistency.
QuTI! Quantifying Text-Image Consistency in Multimodal Documents
Apr 28, 2021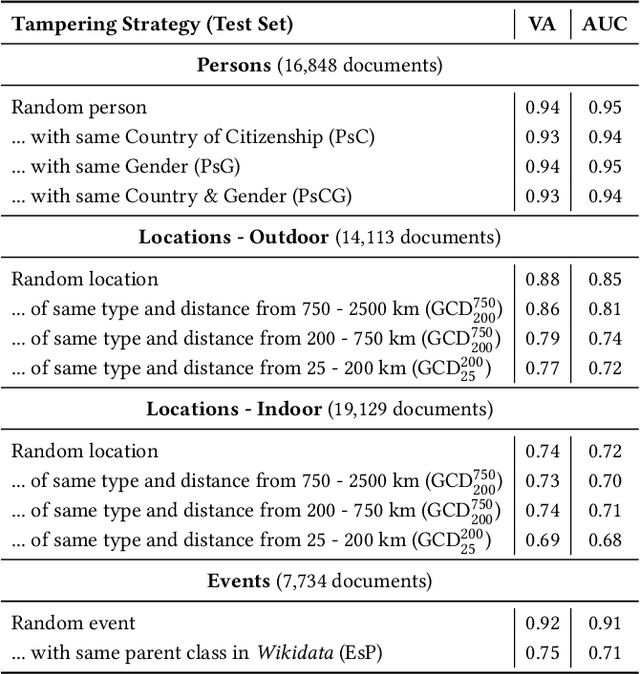
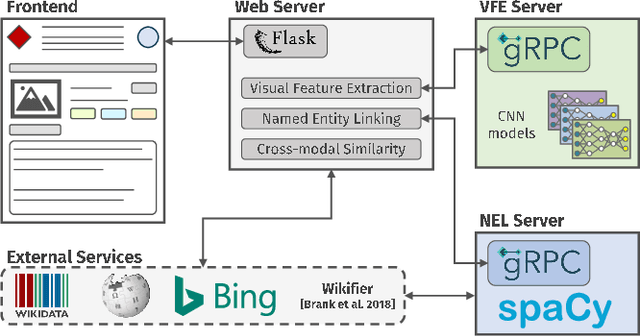
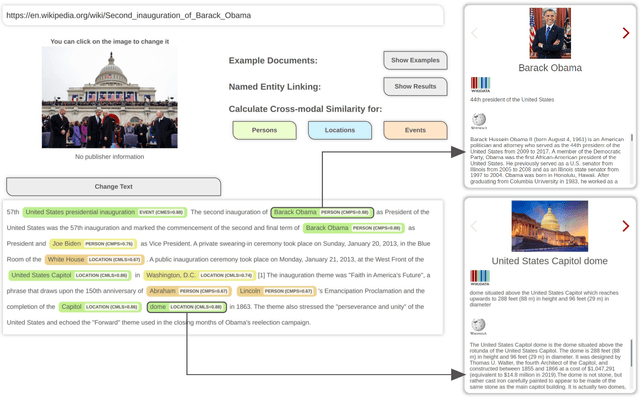
The World Wide Web and social media platforms have become popular sources for news and information. Typically, multimodal information, e.g., image and text is used to convey information more effectively and to attract attention. While in most cases image content is decorative or depicts additional information, it has also been leveraged to spread misinformation and rumors in recent years. In this paper, we present a Web-based demo application that automatically quantifies the cross-modal relations of entities (persons, locations, and events) in image and text. The applications are manifold. For example, the system can help users to explore multimodal articles more efficiently, or can assist human assessors and fact-checking efforts in the verification of the credibility of news stories, tweets, or other multimodal documents.
From Easy to Hard: Learning Language-guided Curriculum for Visual Question Answering on Remote Sensing Data
May 06, 2022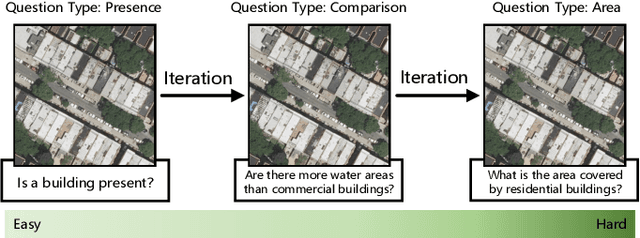
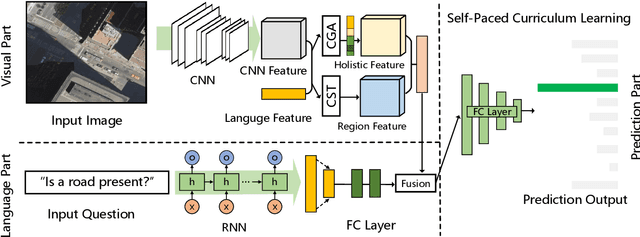
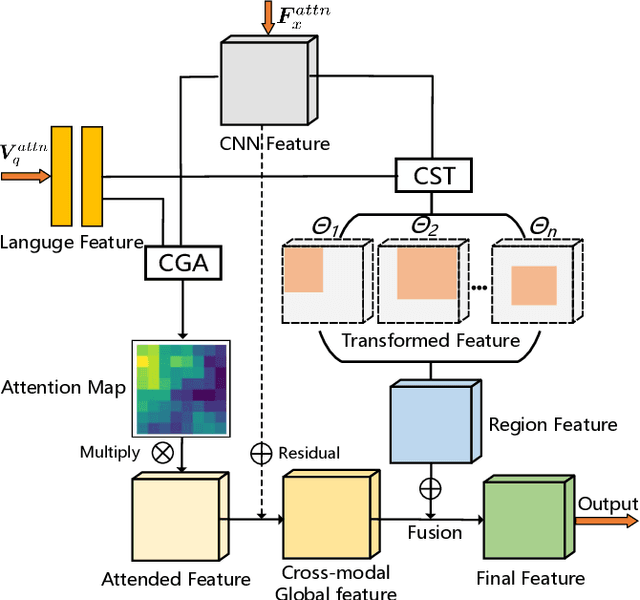
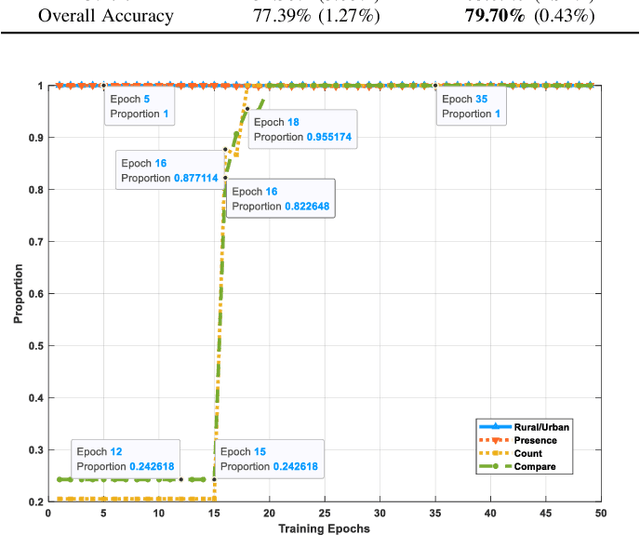
Visual question answering (VQA) for remote sensing scene has great potential in intelligent human-computer interaction system. Although VQA in computer vision has been widely researched, VQA for remote sensing data (RSVQA) is still in its infancy. There are two characteristics that need to be specially considered for the RSVQA task. 1) No object annotations are available in RSVQA datasets, which makes it difficult for models to exploit informative region representation; 2) There are questions with clearly different difficulty levels for each image in the RSVQA task. Directly training a model with questions in a random order may confuse the model and limit the performance. To address these two problems, in this paper, a multi-level visual feature learning method is proposed to jointly extract language-guided holistic and regional image features. Besides, a self-paced curriculum learning (SPCL)-based VQA model is developed to train networks with samples in an easy-to-hard way. To be more specific, a language-guided SPCL method with a soft weighting strategy is explored in this work. The proposed model is evaluated on three public datasets, and extensive experimental results show that the proposed RSVQA framework can achieve promising performance.
An Iterative Labeling Method for Annotating Fisheries Imagery
Apr 27, 2022


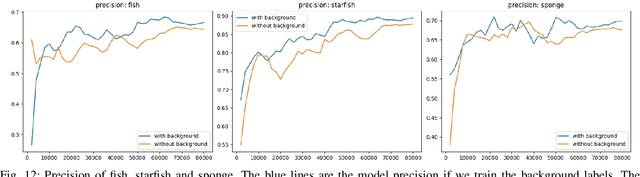
In this paper, we present a methodology for fisheries-related data that allows us to converge on a labeled image dataset by iterating over the dataset with multiple training and production loops that can exploit crowdsourcing interfaces. We present our algorithm and its results on two separate sets of image data collected using the Seabed autonomous underwater vehicle. The first dataset comprises of 2,026 completely unlabeled images, while the second consists of 21,968 images that were point annotated by experts. Our results indicate that training with a small subset and iterating on that to build a larger set of labeled data allows us to converge to a fully annotated dataset with a small number of iterations. Even in the case of a dataset labeled by experts, a single iteration of the methodology improves the labels by discovering additional complicated examples of labels associated with fish that overlap, are very small, or obscured by the contrast limitations associated with underwater imagery.
GenCo: Generative Co-training on Data-Limited Image Generation
Oct 04, 2021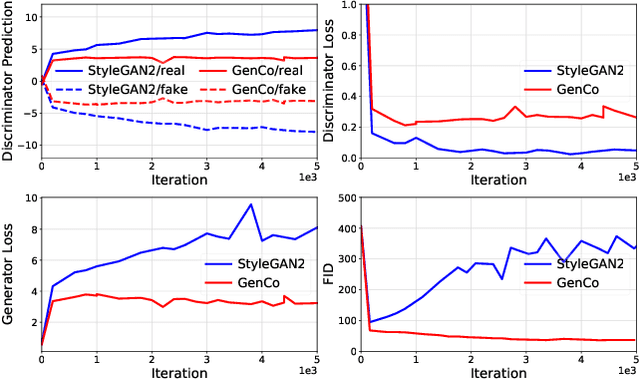
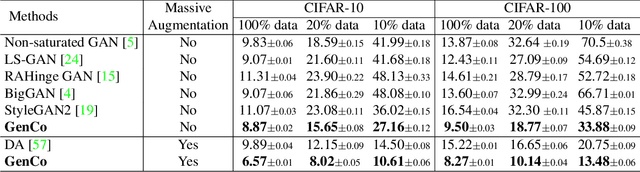
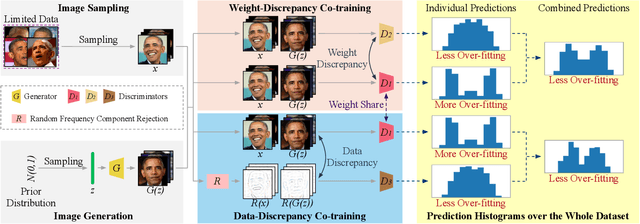
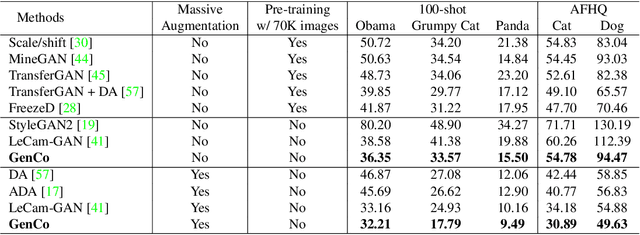
Training effective Generative Adversarial Networks (GANs) requires large amounts of training data, without which the trained models are usually sub-optimal with discriminator over-fitting. Several prior studies address this issue by expanding the distribution of the limited training data via massive and hand-crafted data augmentation. We handle data-limited image generation from a very different perspective. Specifically, we design GenCo, a Generative Co-training network that mitigates the discriminator over-fitting issue by introducing multiple complementary discriminators that provide diverse supervision from multiple distinctive views in training. We instantiate the idea of GenCo in two ways. The first way is Weight-Discrepancy Co-training (WeCo) which co-trains multiple distinctive discriminators by diversifying their parameters. The second way is Data-Discrepancy Co-training (DaCo) which achieves co-training by feeding discriminators with different views of the input images (e.g., different frequency components of the input images). Extensive experiments over multiple benchmarks show that GenCo achieves superior generation with limited training data. In addition, GenCo also complements the augmentation approach with consistent and clear performance gains when combined.
Spatial Cross-Attention Improves Self-Supervised Visual Representation Learning
Jun 07, 2022
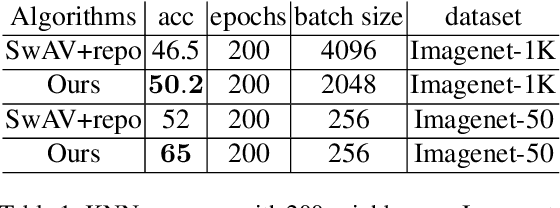
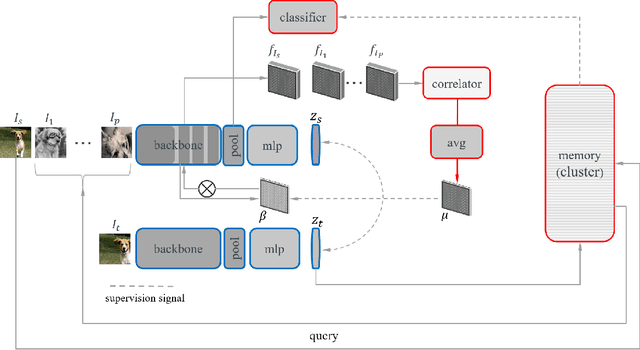
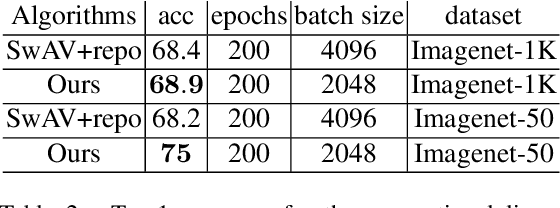
Unsupervised representation learning methods like SwAV are proved to be effective in learning visual semantics of a target dataset. The main idea behind these methods is that different views of a same image represent the same semantics. In this paper, we further introduce an add-on module to facilitate the injection of the knowledge accounting for spatial cross correlations among the samples. This in turn results in distilling intra-class information including feature level locations and cross similarities between same-class instances. The proposed add-on can be added to existing methods such as the SwAV. We can later remove the add-on module for inference without any modification of the learned weights. Through an extensive set of empirical evaluations, we verify that our method yields an improved performance in detecting the class activation maps, top-1 classification accuracy, and down-stream tasks such as object detection, with different configuration settings.