 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End AI-based MRI Reconstruction and Lesion Detection Pipeline for Evaluation of Deep Learning Image Reconstruction
Sep 23, 2021
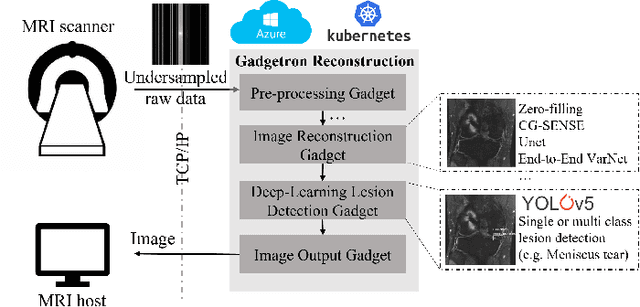
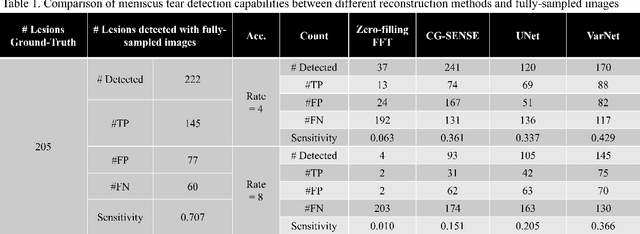
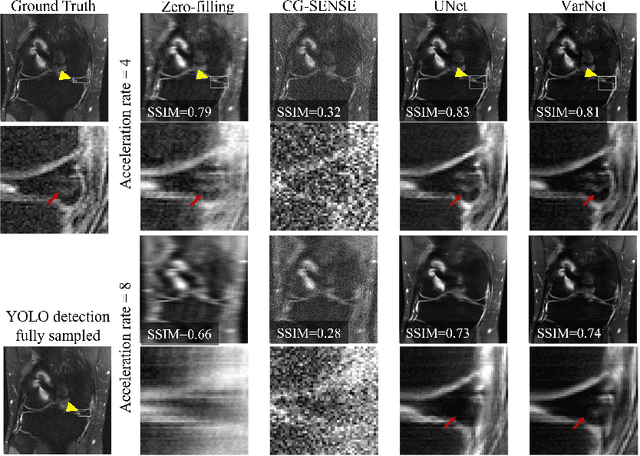

Deep learning techniques have emerged as a promising approach to highly accelerated MRI. However, recent reconstruction challenges have shown several drawbacks in current deep learning approaches, including the loss of fine image details even using models that perform well in terms of global quality metrics. In this study, we propose an end-to-end deep learning framework for image reconstruction and pathology detection, which enables a clinically aware evaluation of deep learning reconstruction quality. The solution is demonstrated for a use case in detecting meniscal tears on knee MRI studies, ultimately finding a loss of fine image details with common reconstruction methods expressed as a reduced ability to detect important pathology like meniscal tears. Despite the common practice of quantitative reconstruction methodology evaluation with metrics such as SSIM, impaired pathology detection as an automated pathology-based reconstruction evaluation approach suggests existing quantitative methods do not capture clinically important reconstruction outcomes.
Few-Shot Non-Parametric Learning with Deep Latent Variable Model
Jun 23, 2022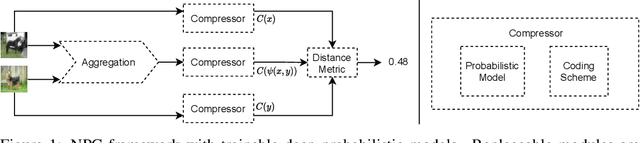
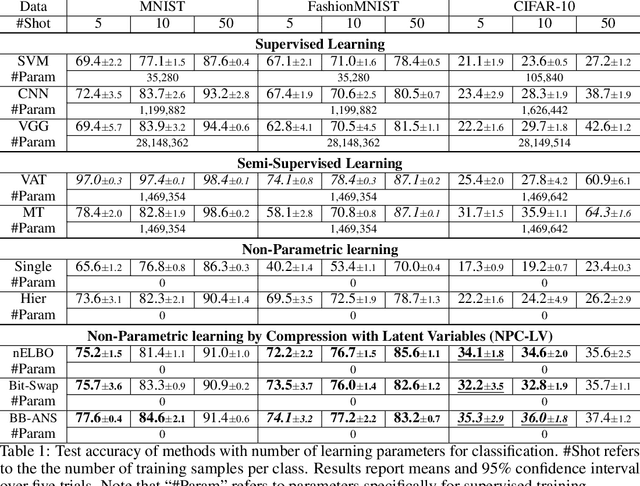
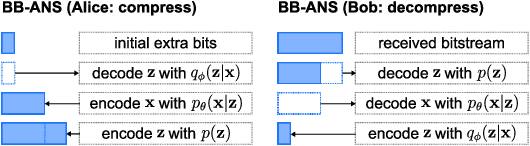
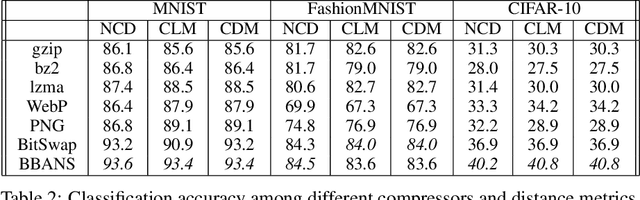
Most real-world problems that machine learning algorithms are expected to solve face the situation with 1) unknown data distribution; 2) little domain-specific knowledge; and 3) datasets with limited annotation. We propose Non-Parametric learning by Compression with Latent Variables (NPC-LV), a learning framework for any dataset with abundant unlabeled data but very few labeled ones. By only training a generative model in an unsupervised way, the framework utilizes the data distribution to build a compressor. Using a compressor-based distance metric derived from Kolmogorov complexity, together with few labeled data, NPC-LV classifies without further training. We show that NPC-LV outperforms supervised methods on all three datasets on image classification in low data regime and even outperform semi-supervised learning methods on CIFAR-10. We demonstrate how and when negative evidence lowerbound (nELBO) can be used as an approximate compressed length for classification. By revealing the correlation between compression rate and classification accuracy, we illustrate that under NPC-LV, the improvement of generative models can enhance downstream classification accuracy.
SRWarp: Generalized Image Super-Resolution under Arbitrary Transformation
Apr 21, 2021
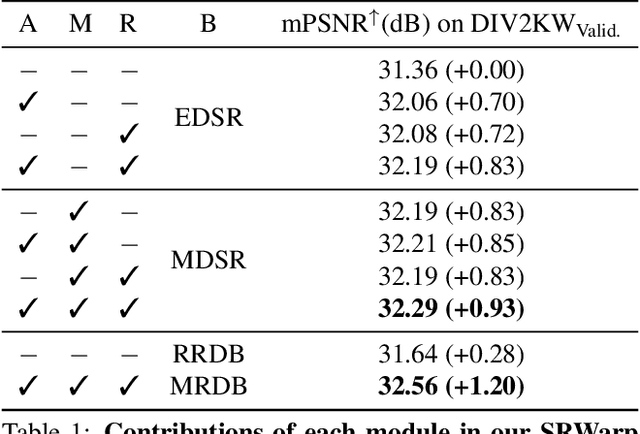

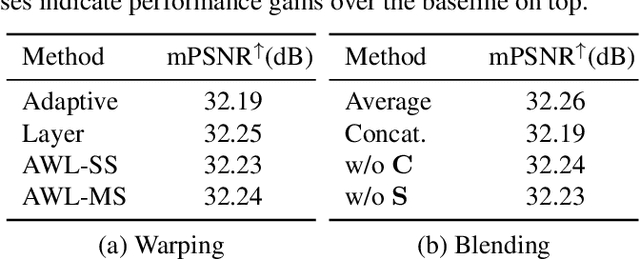
Deep CNNs have achieved significant successes in image processing and its applications, including single image super-resolution (SR). However, conventional methods still resort to some predetermined integer scaling factors, e.g., x2 or x4. Thus, they are difficult to be applied when arbitrary target resolutions are required. Recent approaches extend the scope to real-valued upsampling factors, even with varying aspect ratios to handle the limitation. In this paper, we propose the SRWarp framework to further generalize the SR tasks toward an arbitrary image transformation. We interpret the traditional image warping task, specifically when the input is enlarged, as a spatially-varying SR problem. We also propose several novel formulations, including the adaptive warping layer and multiscale blending, to reconstruct visually favorable results in the transformation process. Compared with previous methods, we do not constrain the SR model on a regular grid but allow numerous possible deformations for flexible and diverse image editing. Extensive experiments and ablation studies justify the necessity and demonstrate the advantage of the proposed SRWarp method under various transformations.
Can Audio Captions Be Evaluated with Image Caption Metrics?
Oct 10, 2021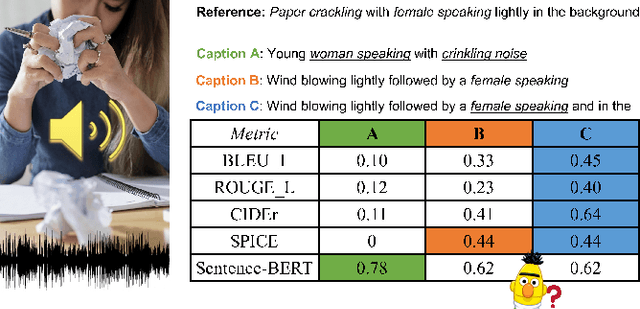

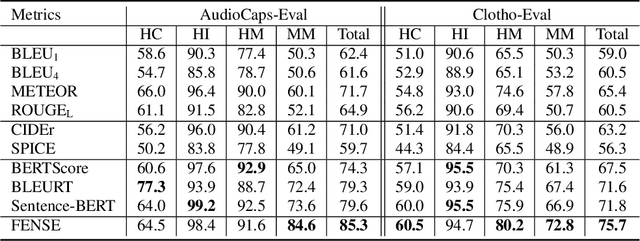
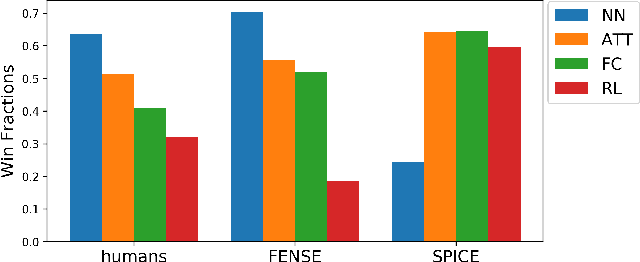
Automated audio captioning aims at generating textual descriptions for an audio clip. To evaluate the quality of generated audio captions, previous works directly adopt image captioning metrics like SPICE and CIDEr, without justifying their suitability in this new domain, which may mislead the development of advanced models. This problem is still unstudied due to the lack of human judgment datasets on caption quality. Therefore, we firstly construct two evaluation benchmarks, AudioCaps-Eval and Clotho-Eval. They are established with pairwise comparison instead of absolute rating to achieve better inter-annotator agreement. Current metrics are found in poor correlation with human annotations on these datasets. To overcome their limitations, we propose a metric named FENSE, where we combine the strength of Sentence-BERT in capturing similarity, and a novel Error Detector to penalize erroneous sentences for robustness. On the newly established benchmarks, FENSE outperforms current metrics by 14-25% accuracy. Code, data and web demo available at: https://github.com/blmoistawinde/fense
TransBoost: Improving the Best ImageNet Performance using Deep Transduction
May 27, 2022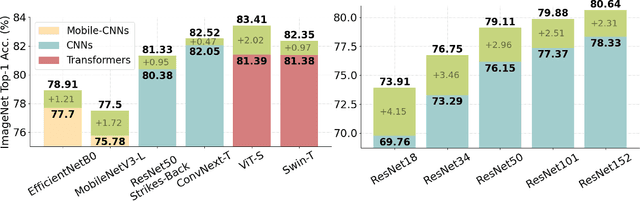
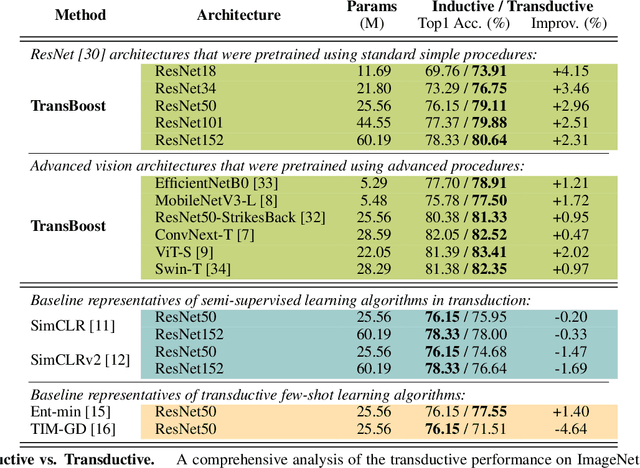
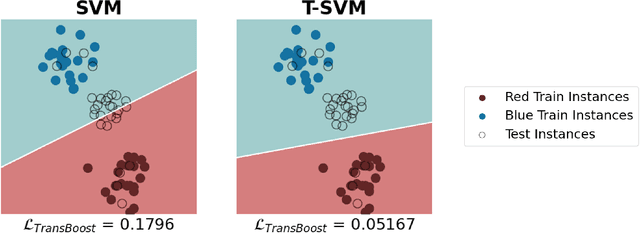

This paper deals with deep transductive learning, and proposes TransBoost as a procedure for fine-tuning any deep neural model to improve its performance on any (unlabeled) test set provided at training time. TransBoost is inspired by a large margin principle and is efficient and simple to use. The ImageNet classification performance is consistently and significantly improved with TransBoost on many architectures such as ResNets, MobileNetV3-L, EfficientNetB0, ViT-S, and ConvNext-T. Additionally we show that TransBoost is effective on a wide variety of image classification datasets.
On Pre-Training for Federated Learning
Jun 23, 2022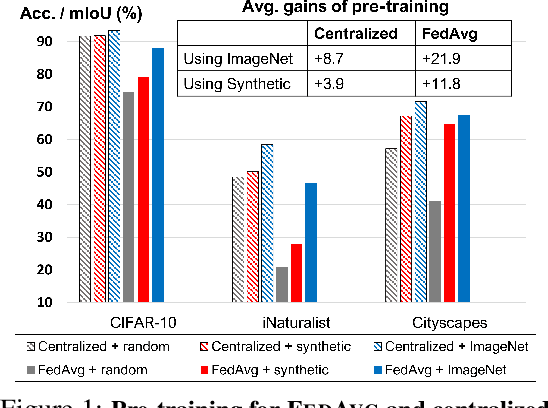
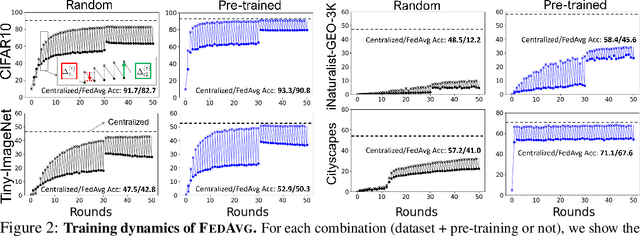
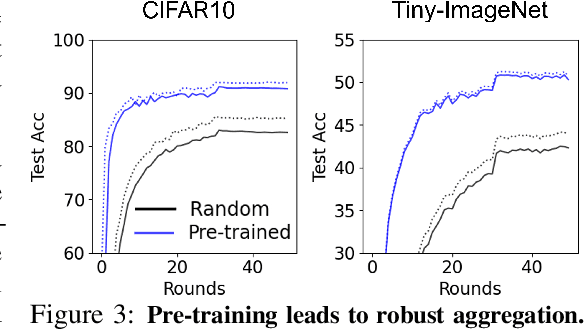
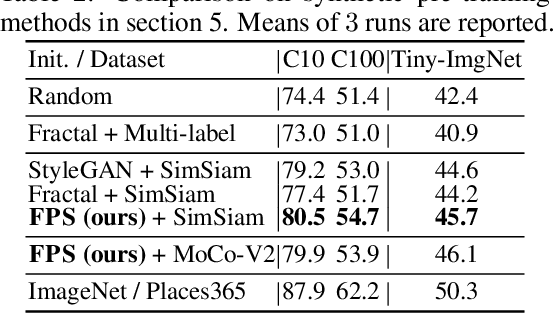
In most of the literature on federated learning (FL), neural networks are initialized with random weights. In this paper, we present an empirical study on the effect of pre-training on FL. Specifically, we aim to investigate if pre-training can alleviate the drastic accuracy drop when clients' decentralized data are non-IID. We focus on FedAvg, the fundamental and most widely used FL algorithm. We found that pre-training does largely close the gap between FedAvg and centralized learning under non-IID data, but this does not come from alleviating the well-known model drifting problem in FedAvg's local training. Instead, how pre-training helps FedAvg is by making FedAvg's global aggregation more stable. When pre-training using real data is not feasible for FL, we propose a novel approach to pre-train with synthetic data. On various image datasets (including one for segmentation), our approach with synthetic pre-training leads to a notable gain, essentially a critical step toward scaling up federated learning for real-world applications.
Advancing 3D Medical Image Analysis with Variable Dimension Transform based Supervised 3D Pre-training
Jan 05, 2022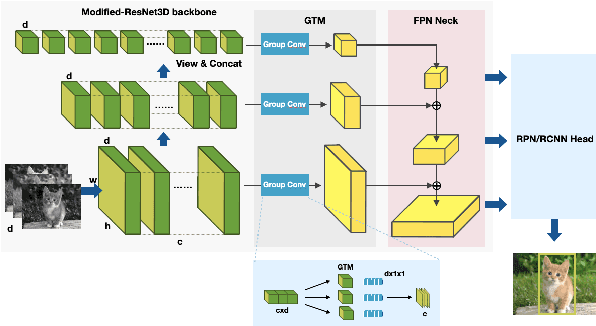
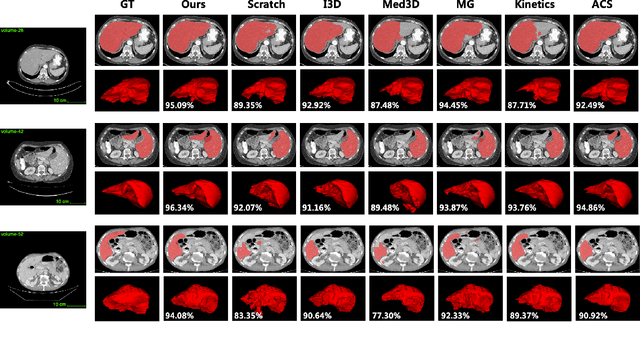
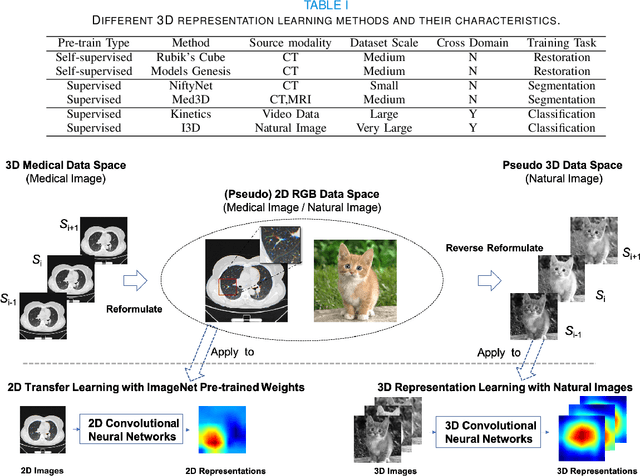
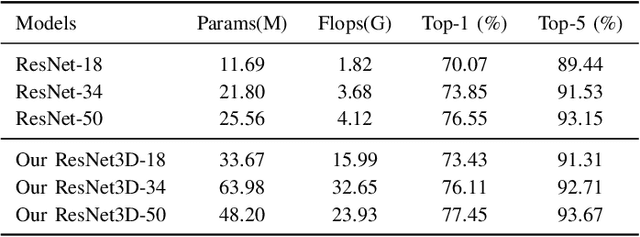
The difficulties in both data acquisition and annotation substantially restrict the sample sizes of training datasets for 3D medical imaging applications. As a result, constructing high-performance 3D convolutional neural networks from scratch remains a difficult task in the absence of a sufficient pre-training parameter. Previous efforts on 3D pre-training have frequently relied on self-supervised approaches, which use either predictive or contrastive learning on unlabeled data to build invariant 3D representations. However, because of the unavailability of large-scale supervision information, obtaining semantically invariant and discriminative representations from these learning frameworks remains problematic. In this paper, we revisit an innovative yet simple fully-supervised 3D network pre-training framework to take advantage of semantic supervisions from large-scale 2D natural image datasets. With a redesigned 3D network architecture, reformulated natural images are used to address the problem of data scarcity and develop powerful 3D representations. Comprehensive experiments on four benchmark datasets demonstrate that the proposed pre-trained models can effectively accelerate convergence while also improving accuracy for a variety of 3D medical imaging tasks such as classification, segmentation and detection. In addition, as compared to training from scratch, it can save up to 60% of annotation efforts. On the NIH DeepLesion dataset, it likewise achieves state-of-the-art detection performance, outperforming earlier self-supervised and fully-supervised pre-training approaches, as well as methods that do training from scratch. To facilitate further development of 3D medical models, our code and pre-trained model weights are publicly available at https://github.com/urmagicsmine/CSPR.
LatentKeypointGAN: Controlling Images via Latent Keypoints -- Extended Abstract
May 06, 2022
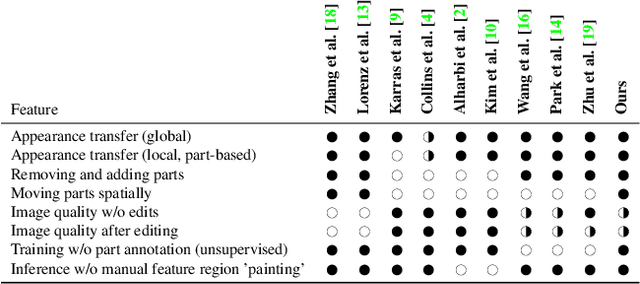
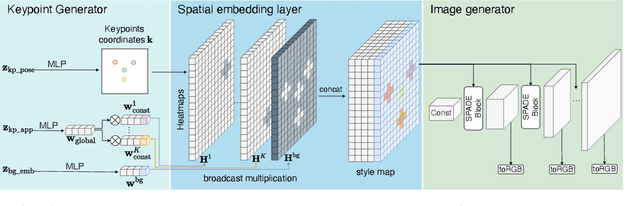
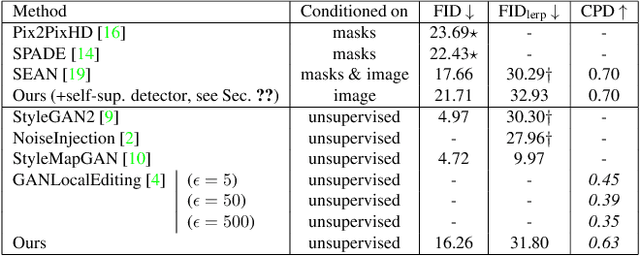
Generative adversarial networks (GANs) can now generate photo-realistic images. However, how to best control the image content remains an open challenge. We introduce LatentKeypointGAN, a two-stage GAN internally conditioned on a set of keypoints and associated appearance embeddings providing control of the position and style of the generated objects and their respective parts. A major difficulty that we address is disentangling the image into spatial and appearance factors with little domain knowledge and supervision signals. We demonstrate in a user study and quantitative experiments that LatentKeypointGAN provides an interpretable latent space that can be used to re-arrange the generated images by re-positioning and exchanging keypoint embeddings, such as generating portraits by combining the eyes, and mouth from different images. Notably, our method does not require labels as it is self-supervised and thereby applies to diverse application domains, such as editing portraits, indoor rooms, and full-body human poses.
DUET: Cross-modal Semantic Grounding for Contrastive Zero-shot Learning
Jul 04, 2022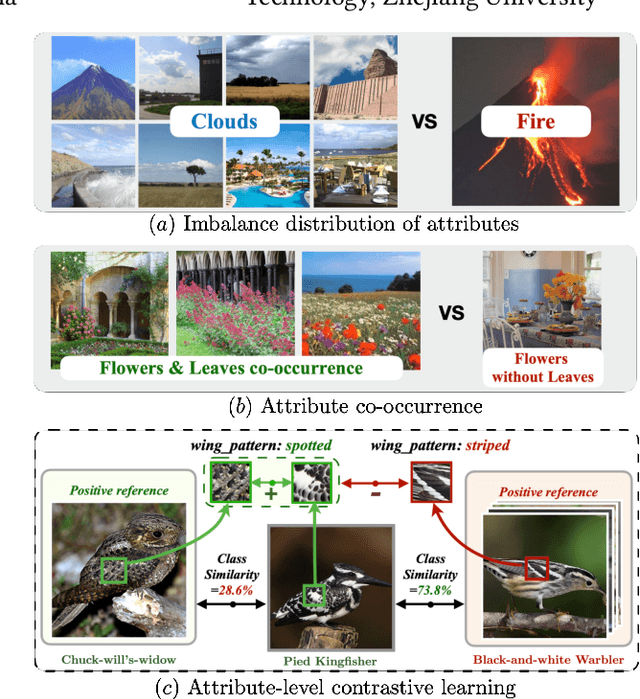
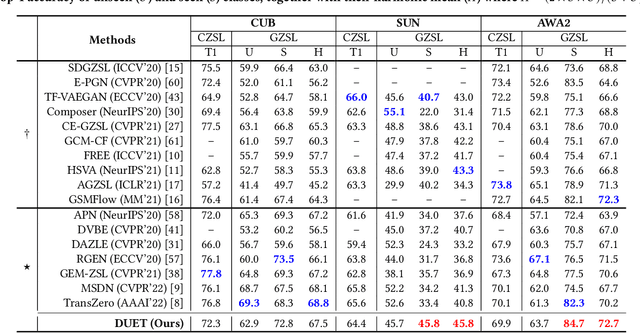
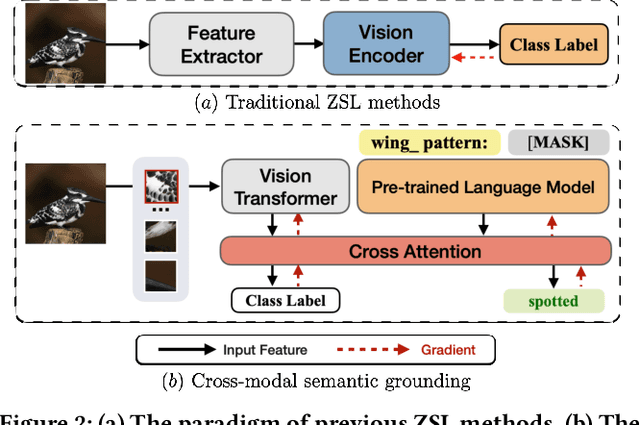
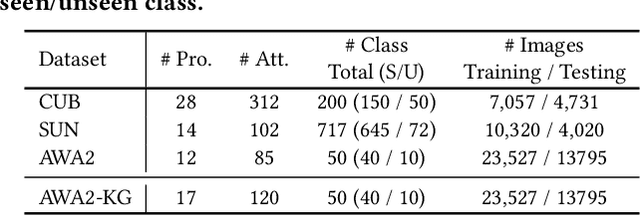
Zero-shot learning (ZSL) aims to predict unseen classes whose samples have never appeared during training, often utilizing additional semantic information (a.k.a. side information) to bridge the training (seen) classes and the unseen classes. One of the most effective and widely used semantic information for zero-shot image classification are attributes which are annotations for class-level visual characteristics. However, due to the shortage of fine-grained annotations, the attribute imbalance and co-occurrence, the current methods often fail to discriminate those subtle visual distinctions between images, which limits their performances. In this paper, we present a transformer-based end-to-end ZSL method named DUET, which integrates latent semantic knowledge from the pretrained language models (PLMs) via a self-supervised multi-modal learning paradigm. Specifically, we (1) developed a cross-modal semantic grounding network to investigate the model's capability of disentangling semantic attributes from the images, (2) applied an attribute-level contrastive learning strategy to further enhance the model's discrimination on fine-grained visual characteristics against the attribute co-occurrence and imbalance, and (3) proposed a multi-task learning policy for considering multi-model objectives. With extensive experiments on three standard ZSL benchmarks and a knowledge graph equipped ZSL benchmark, we find that DUET can often achieve state-of-the-art performance, its components are effective and its predictions are interpretable.
An Efficient Modern Baseline for FloodNet VQA
May 30, 2022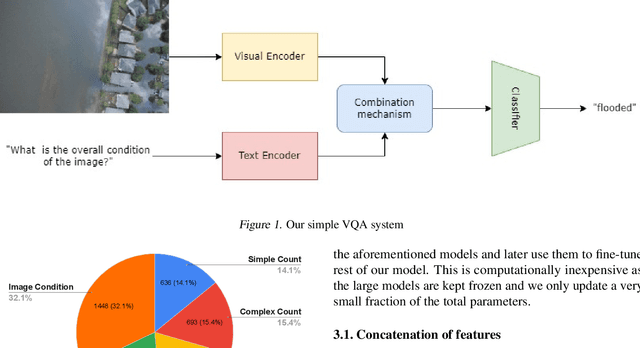
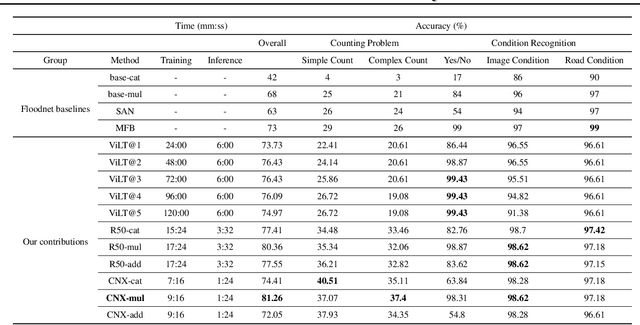
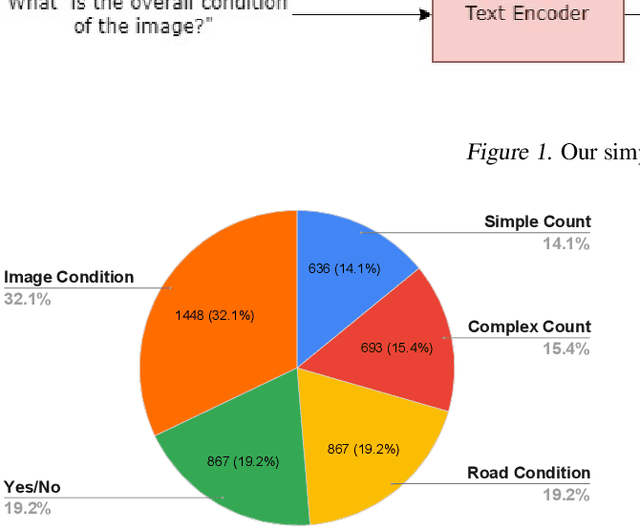
Designing efficient and reliable VQA systems remains a challenging problem, more so in the case of disaster management and response systems. In this work, we revisit fundamental combination methods like concatenation, addition and element-wise multiplication with modern image and text feature abstraction models. We design a simple and efficient system which outperforms pre-existing methods on the FloodNet dataset and achieves state-of-the-art performance. This simplified system requires significantly less training and inference time than modern VQA architectures. We also study the performance of various backbones and report their consolidated results. Code is available at https://github.com/sahilkhose/floodnet_vqa.