 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Optimization-Derived Learning with Essential Convergence Analysis of Training and Hyper-training
Jun 16, 2022
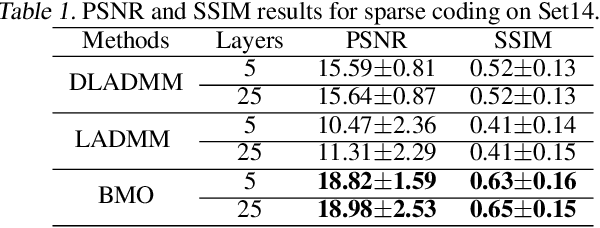

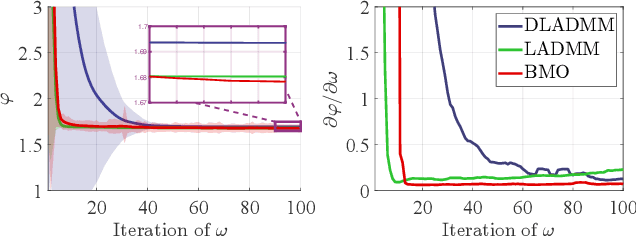
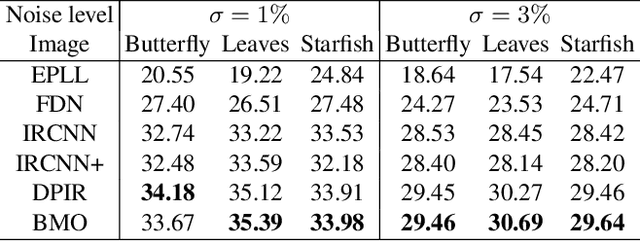
Recently, Optimization-Derived Learning (ODL) has attracted attention from learning and vision areas, which designs learning models from the perspective of optimization. However, previous ODL approaches regard the training and hyper-training procedures as two separated stages, meaning that the hyper-training variables have to be fixed during the training process, and thus it is also impossible to simultaneously obtain the convergence of training and hyper-training variables. In this work, we design a Generalized Krasnoselskii-Mann (GKM) scheme based on fixed-point iterations as our fundamental ODL module, which unifies existing ODL methods as special cases. Under the GKM scheme, a Bilevel Meta Optimization (BMO) algorithmic framework is constructed to solve the optimal training and hyper-training variables together. We rigorously prove the essential joint convergence of the fixed-point iteration for training and the process of optimizing hyper-parameters for hyper-training, both on the approximation quality, and on the stationary analysis. Experiments demonstrate the efficiency of BMO with competitive performance on sparse coding and real-world applications such as image deconvolution and rain streak removal.
Voxel-MAE: Masked Autoencoders for Pre-training Large-scale Point Clouds
Jun 27, 2022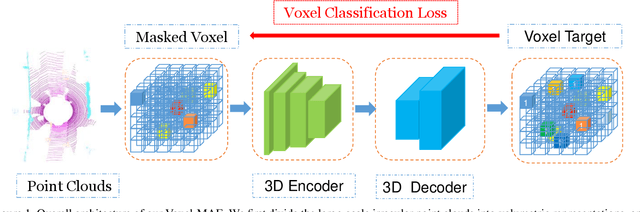
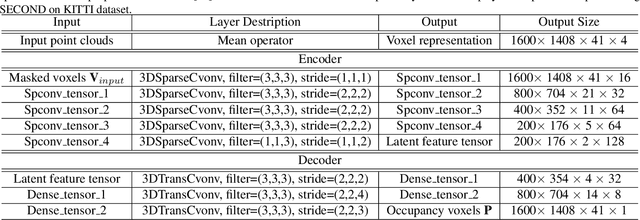
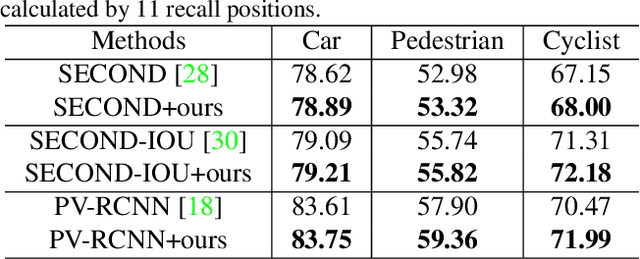
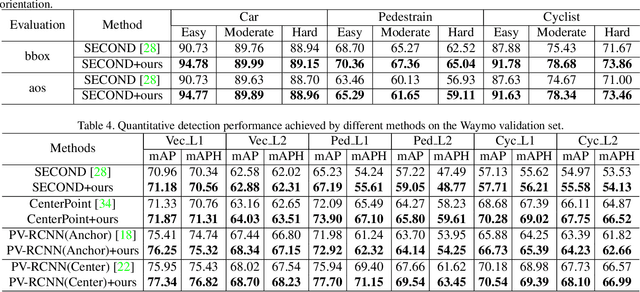
Mask-based pre-training has achieved great success for self-supervised learning in image, video, and language, without manually annotated supervision. However, it has not yet been studied about large-scale point clouds with redundant spatial information in autonomous driving. As the number of large-scale point clouds is huge, it is impossible to reconstruct the input point clouds. In this paper, we propose a mask voxel classification network for large-scale point clouds pre-training. Our key idea is to divide the point clouds into voxel representations and classify whether the voxel contains point clouds. This simple strategy makes the network to be voxel-aware of the object shape, thus improving the performance of the downstream tasks, such as 3D object detection. Our Voxel-MAE with even a 90% masking ratio can still learn representative features for the high spatial redundancy of large-scale point clouds. We also validate the effectiveness of Voxel-MAE in unsupervised domain adaptative tasks, which proves the generalization ability of Voxel-MAE. Our Voxel-MAE proves that it is feasible to pre-train large-scale point clouds without data annotations to enhance the perception ability of the autonomous vehicle. Extensive experiments show great effectiveness of our pre-trained model with 3D object detectors (SECOND, CenterPoint, and PV-RCNN) on two popular datasets (KITTI, Waymo). Codes are publicly available at https://github.com/chaytonmin/Voxel-MAE.
Evaluation of Deep Neural Network Domain Adaptation Techniques for Image Recognition
Sep 28, 2021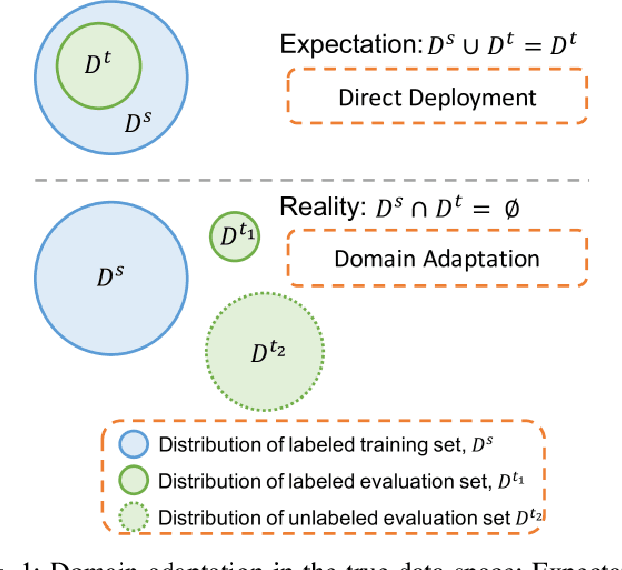
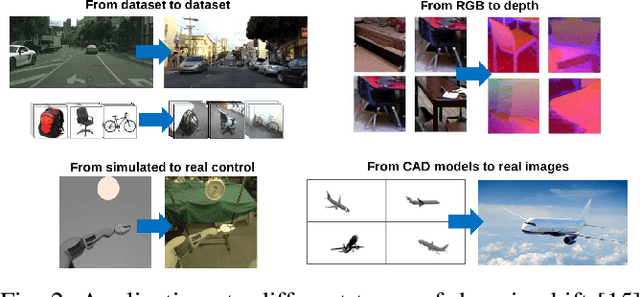
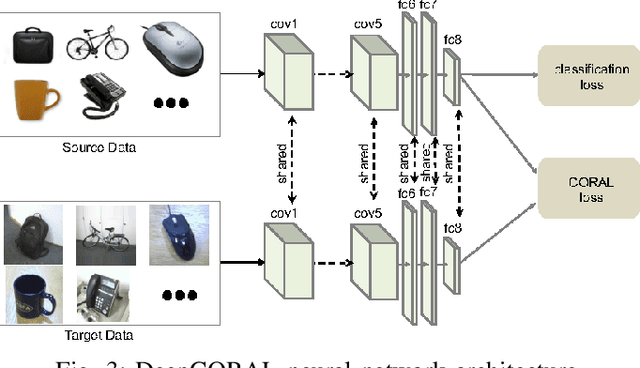
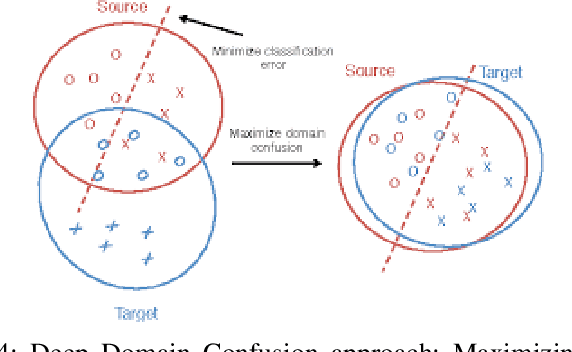
It has been well proved that deep networks are efficient at extracting features from a given (source) labeled dataset. However, it is not always the case that they can generalize well to other (target) datasets which very often have a different underlying distribution. In this report, we evaluate four different domain adaptation techniques for image classification tasks: DeepCORAL, DeepDomainConfusion, CDAN and CDAN+E. These techniques are unsupervised given that the target dataset dopes not carry any labels during training phase. We evaluate model performance on the office-31 dataset. A link to the github repository of this report can be found here: https://github.com/agrija9/Deep-Unsupervised-Domain-Adaptation.
RankSEG: A Consistent Ranking-based Framework for Segmentation
Jun 27, 2022
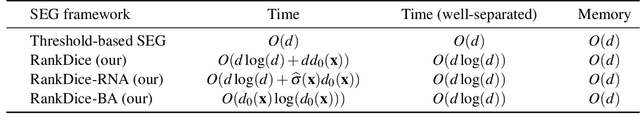
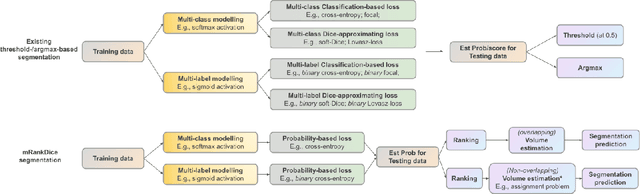
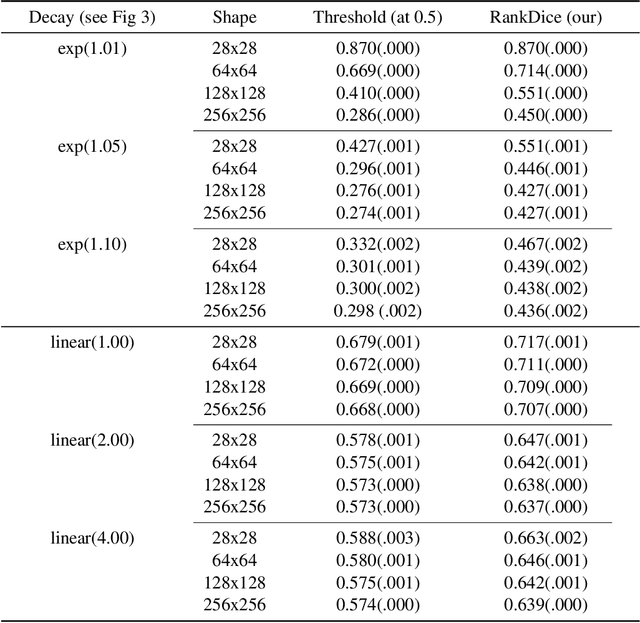
Segmentation has emerged as a fundamental field of computer vision and natural language processing, which assigns a label to every pixel/feature to extract regions of interest from an image/text. To evaluate the performance of segmentation, the Dice and IoU metrics are used to measure the degree of overlap between the ground truth and the predicted segmentation. In this paper, we establish a theoretical foundation of segmentation with respect to the Dice/IoU metrics, including the Bayes rule and Dice/IoU-calibration, analogous to classification-calibration or Fisher consistency in classification. We prove that the existing thresholding-based framework with most operating losses are not consistent with respect to the Dice/IoU metrics, and thus may lead to a suboptimal solution. To address this pitfall, we propose a novel consistent ranking-based framework, namely RankDice/RankIoU, inspired by plug-in rules of the Bayes segmentation rule. Three numerical algorithms with GPU parallel execution are developed to implement the proposed framework in large-scale and high-dimensional segmentation. We study statistical properties of the proposed framework. We show it is Dice-/IoU-calibrated, and its excess risk bounds and the rate of convergence are also provided. The numerical effectiveness of RankDice/mRankDice is demonstrated in various simulated examples and Fine-annotated CityScapes and Pascal VOC datasets with state-of-the-art deep learning architectures.
Mean Field inference of CRFs based on GAT
May 29, 2022
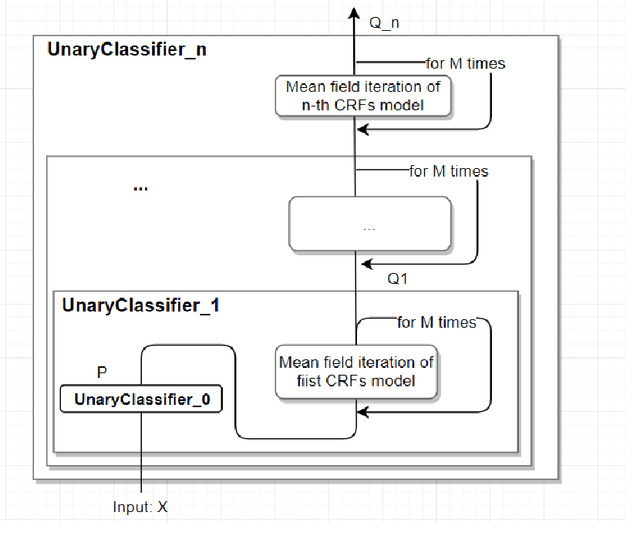

In this paper we propose an improved mean-field inference algorithm for the fully connected paired CRFs model. The improved method Message Passing operation is changed from the original linear convolution to the present graph attention operation, while the process of the inference algorithm is turned into the forward process of the GAT model. Combined with the mean-field inferred label distribution, it is equivalent to the output of a classifier with only unary potential. To this end, we propose a graph attention network model with residual structure, and the model approach is applicable to all sequence annotation tasks, such as pixel-level image semantic segmentation tasks as well as text annotation tasks.
Few-Shot Learning for Image Classification of Common Flora
May 07, 2021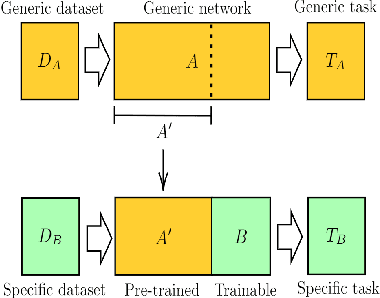
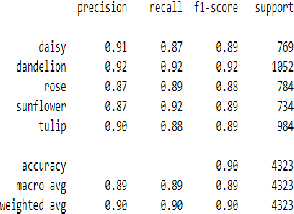
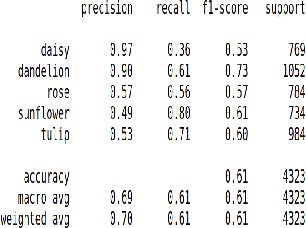
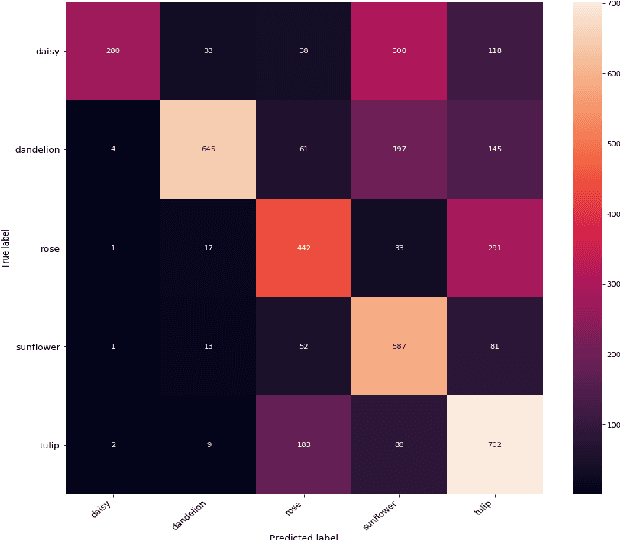
The use of meta-learning and transfer learning in the task of few-shot image classification is a well researched area with many papers showcasing the advantages of transfer learning over meta-learning in cases where data is plentiful and there is no major limitations to computational resources. In this paper we will showcase our experimental results from testing various state-of-the-art transfer learning weights and architectures versus similar state-of-the-art works in the meta-learning field for image classification utilizing Model-Agnostic Meta Learning (MAML). Our results show that both practices provide adequate performance when the dataset is sufficiently large, but that they both also struggle when data sparsity is introduced to maintain sufficient performance. This problem is moderately reduced with the use of image augmentation and the fine-tuning of hyperparameters. In this paper we will discuss: (1) our process of developing a robust multi-class convolutional neural network (CNN) for the task of few-shot image classification, (2) demonstrate that transfer learning is the superior method of helping create an image classification model when the dataset is large and (3) that MAML outperforms transfer learning in the case where data is very limited. The code is available here: github.com/JBall1/Few-Shot-Limited-Data
Compactification of the Rigid Motions Group in Image Processing
Jun 25, 2021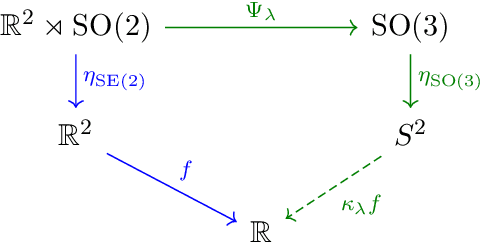
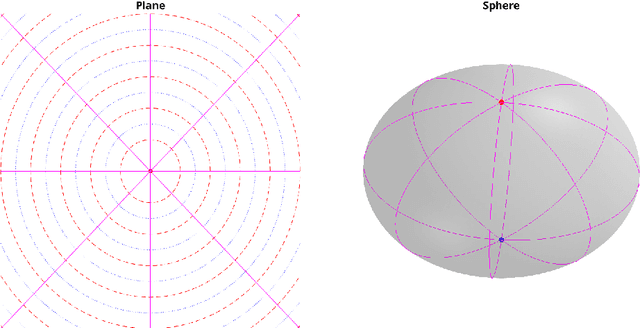
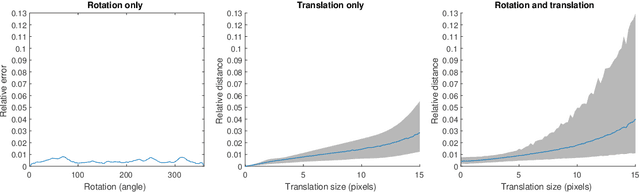
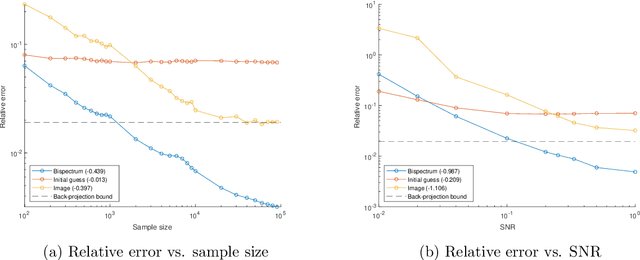
Image processing problems in general, and in particular in the field of single-particle cryo-electron microscopy, often require considering images up to their rotations and translations. Such problems were tackled successfully when considering images up to rotations only, using quantities which are invariant to the action of rotations on images. Extending these methods to cases where translations are involved is more complicated. Here we present a computationally feasible and theoretically sound approximate invariant to the action of rotations and translations on images. It allows one to approximately reduce image processing problems to similar problems over the sphere, a compact domain acted on by the group of 3D rotations, a compact group. We show that this invariant is induced by a family of mappings deforming, and thereby compactifying, the group structure of rotations and translations of the plane, i.e., the group of rigid motions, into the group of 3D rotations. Furthermore, we demonstrate its viability in two image processing tasks: multi-reference alignment and classification. To our knowledge, this is the first instance of a quantity that is either exactly or approximately invariant to rotations and translations of images that both rests on a sound theoretical foundation and also applicable in practice.
FIFO: Learning Fog-invariant Features for Foggy Scene Segmentation
Apr 04, 2022
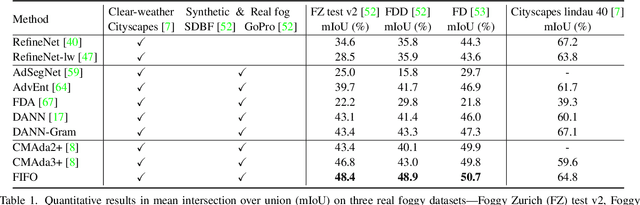
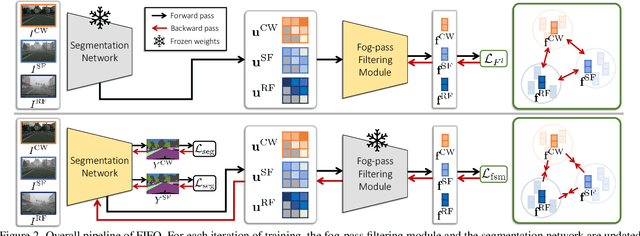
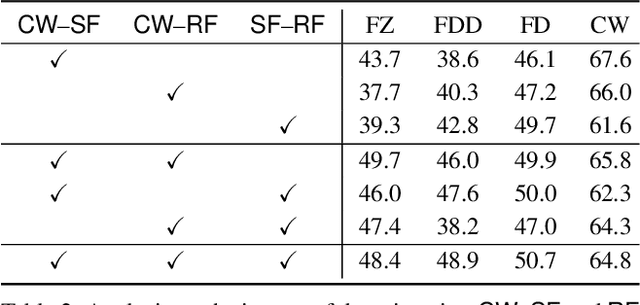
Robust visual recognition under adverse weather conditions is of great importance in real-world applications. In this context, we propose a new method for learning semantic segmentation models robust against fog. Its key idea is to consider the fog condition of an image as its style and close the gap between images with different fog conditions in neural style spaces of a segmentation model. In particular, since the neural style of an image is in general affected by other factors as well as fog, we introduce a fog-pass filter module that learns to extract a fog-relevant factor from the style. Optimizing the fog-pass filter and the segmentation model alternately gradually closes the style gap between different fog conditions and allows to learn fog-invariant features in consequence. Our method substantially outperforms previous work on three real foggy image datasets. Moreover, it improves performance on both foggy and clear weather images, while existing methods often degrade performance on clear scenes.
BadDet: Backdoor Attacks on Object Detection
May 28, 2022
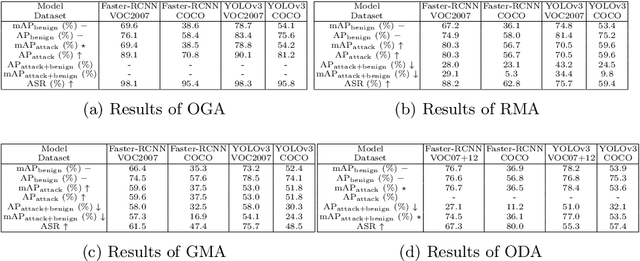


Deep learning models have been deployed in numerous real-world applications such as autonomous driving and surveillance. However, these models are vulnerable in adversarial environments. Backdoor attack is emerging as a severe security threat which injects a backdoor trigger into a small portion of training data such that the trained model behaves normally on benign inputs but gives incorrect predictions when the specific trigger appears. While most research in backdoor attacks focuses on image classification, backdoor attacks on object detection have not been explored but are of equal importance. Object detection has been adopted as an important module in various security-sensitive applications such as autonomous driving. Therefore, backdoor attacks on object detection could pose severe threats to human lives and properties. We propose four kinds of backdoor attacks for object detection task: 1) Object Generation Attack: a trigger can falsely generate an object of the target class; 2) Regional Misclassification Attack: a trigger can change the prediction of a surrounding object to the target class; 3) Global Misclassification Attack: a single trigger can change the predictions of all objects in an image to the target class; and 4) Object Disappearance Attack: a trigger can make the detector fail to detect the object of the target class. We develop appropriate metrics to evaluate the four backdoor attacks on object detection. We perform experiments using two typical object detection models -- Faster-RCNN and YOLOv3 on different datasets. More crucially, we demonstrate that even fine-tuning on another benign dataset cannot remove the backdoor hidden in the object detection model. To defend against these backdoor attacks, we propose Detector Cleanse, an entropy-based run-time detection framework to identify poisoned testing samples for any deployed object detector.
Orthonormal Product Quantization Network for Scalable Face Image Retrieval
Jul 01, 2021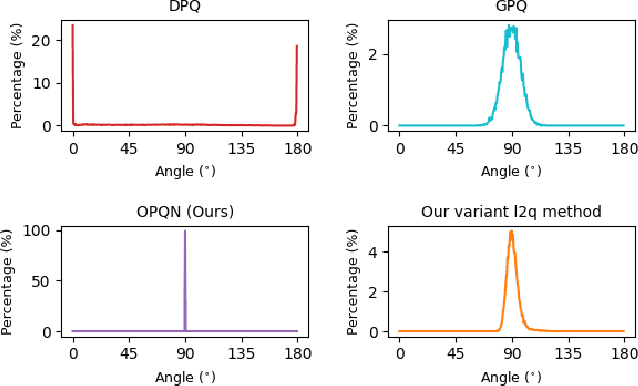
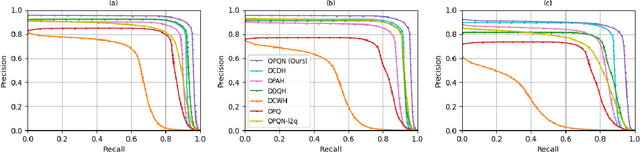
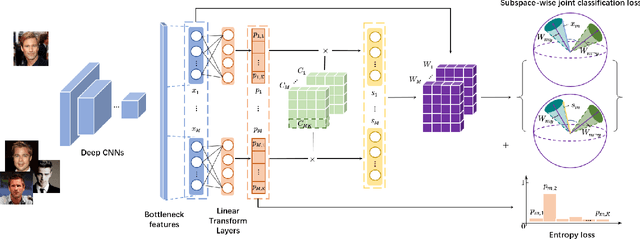
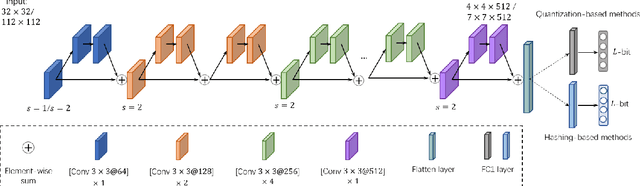
Recently, deep hashing with Hamming distance metric has drawn increasing attention for face image retrieval tasks. However, its counterpart deep quantization methods, which learn binary code representations with dictionary-related distance metrics, have seldom been explored for the task. This paper makes the first attempt to integrate product quantization into an end-to-end deep learning framework for face image retrieval. Unlike prior deep quantization methods where the codewords for quantization are learned from data, we propose a novel scheme using predefined orthonormal vectors as codewords, which aims to enhance the quantization informativeness and reduce the codewords' redundancy. To make the most of the discriminative information, we design a tailored loss function that maximizes the identity discriminability in each quantization subspace for both the quantized and the original features. Furthermore, an entropy-based regularization term is imposed to reduce the quantization error. We conduct experiments on three commonly-used datasets under the settings of both single-domain and cross-domain retrieval. It shows that the proposed method outperforms all the compared deep hashing/quantization methods under both settings with significant superiority. The proposed codewords scheme consistently improves both regular model performance and model generalization ability, verifying the importance of codewords' distribution for the quantization quality. Besides, our model's better generalization ability than deep hashing models indicates that it is more suitable for scalable face image retrieval tasks.