 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Contributions to interframe coding
Mar 31, 2022
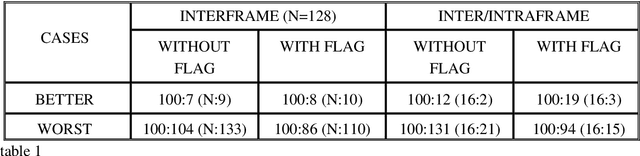
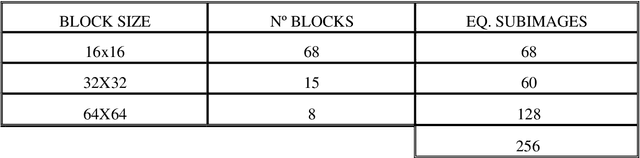
Advanced motion models (4 or 6 parameters) are needed for a good representation of the motion experimented by the different objects contained in a sequence of images. If the image is split in very small blocks, then an accurate description of complex movements can be achieved with only 2 parameters. This alternative implies a large set of vectors per image. We propose a new approach to reduce the number of vectors, using different block sizes as a function of the local characteristics of the image, without increasing the error accepted with the smallest blocks. A second algorithm is proposed for an inter/intraframe coder.
* 6 pages, published in Workshop on image analysis & synthesis in image coding. October 1994. Berlin. pp. C3.1 to C3.6. arXiv admin note: text overlap with arXiv:2203.00445
Exploring Explicit and Implicit Visual Relationships for Image Captioning
May 06, 2021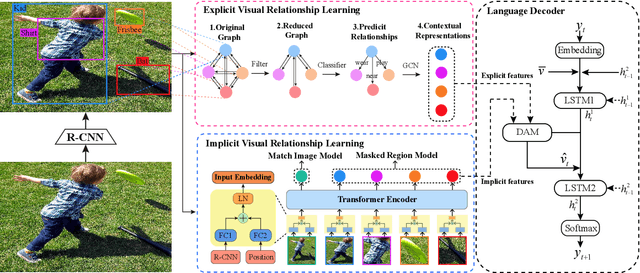
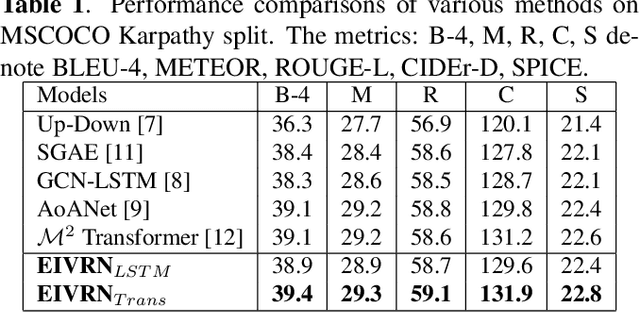
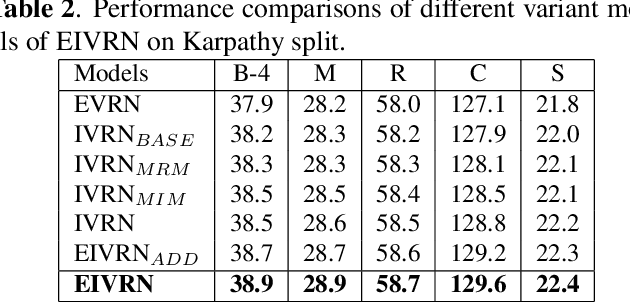
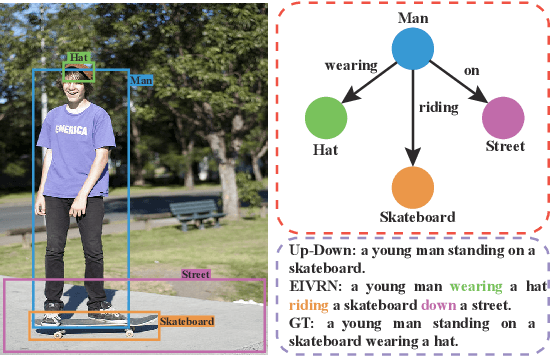
Image captioning is one of the most challenging tasks in AI, which aims to automatically generate textual sentences for an image. Recent methods for image captioning follow encoder-decoder framework that transforms the sequence of salient regions in an image into natural language descriptions. However, these models usually lack the comprehensive understanding of the contextual interactions reflected on various visual relationships between objects. In this paper, we explore explicit and implicit visual relationships to enrich region-level representations for image captioning. Explicitly, we build semantic graph over object pairs and exploit gated graph convolutional networks (Gated GCN) to selectively aggregate local neighbors' information. Implicitly, we draw global interactions among the detected objects through region-based bidirectional encoder representations from transformers (Region BERT) without extra relational annotations. To evaluate the effectiveness and superiority of our proposed method, we conduct extensive experiments on Microsoft COCO benchmark and achieve remarkable improvements compared with strong baselines.
Transformer-based Context Condensation for Boosting Feature Pyramids in Object Detection
Jul 14, 2022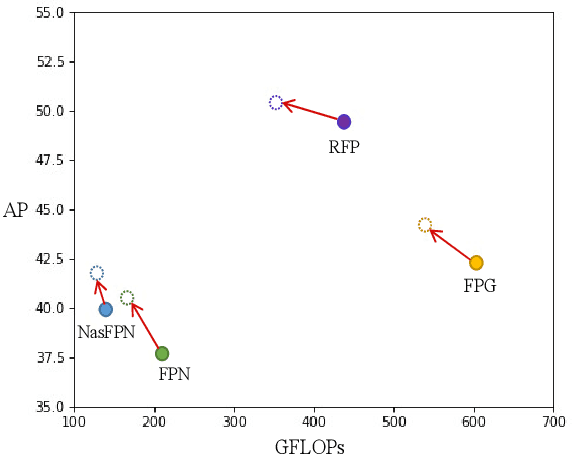
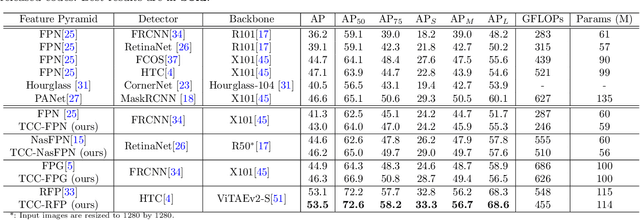
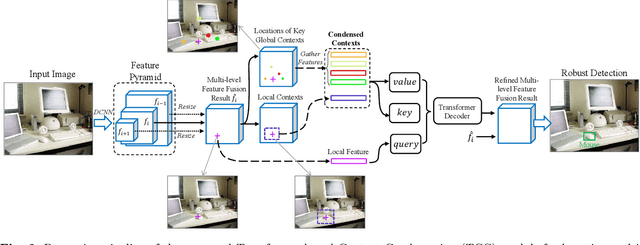

Current object detectors typically have a feature pyramid (FP) module for multi-level feature fusion (MFF) which aims to mitigate the gap between features from different levels and form a comprehensive object representation to achieve better detection performance. However, they usually require heavy cross-level connections or iterative refinement to obtain better MFF result, making them complicated in structure and inefficient in computation. To address these issues, we propose a novel and efficient context modeling mechanism that can help existing FPs deliver better MFF results while reducing the computational costs effectively. In particular, we introduce a novel insight that comprehensive contexts can be decomposed and condensed into two types of representations for higher efficiency. The two representations include a locally concentrated representation and a globally summarized representation, where the former focuses on extracting context cues from nearby areas while the latter extracts key representations of the whole image scene as global context cues. By collecting the condensed contexts, we employ a Transformer decoder to investigate the relations between them and each local feature from the FP and then refine the MFF results accordingly. As a result, we obtain a simple and light-weight Transformer-based Context Condensation (TCC) module, which can boost various FPs and lower their computational costs simultaneously. Extensive experimental results on the challenging MS COCO dataset show that TCC is compatible to four representative FPs and consistently improves their detection accuracy by up to 7.8 % in terms of average precision and reduce their complexities by up to around 20% in terms of GFLOPs, helping them achieve state-of-the-art performance more efficiently. Code will be released.
Towards Adversarial Attack on Vision-Language Pre-training Models
Jun 19, 2022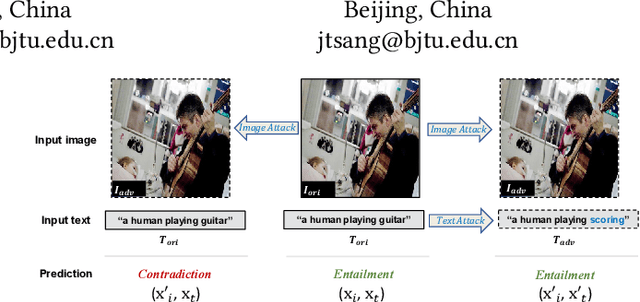

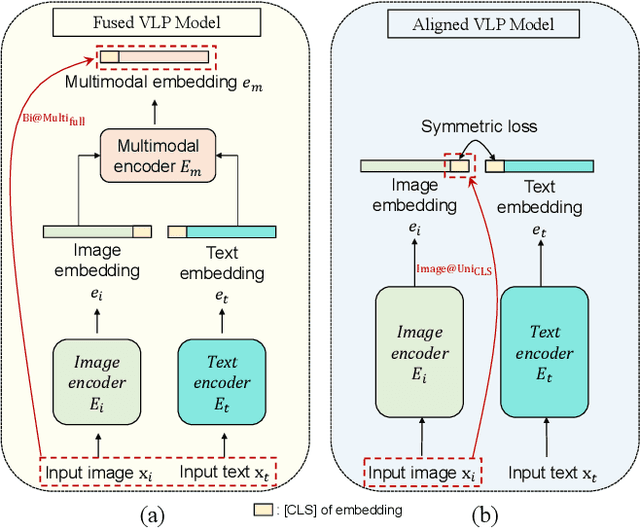
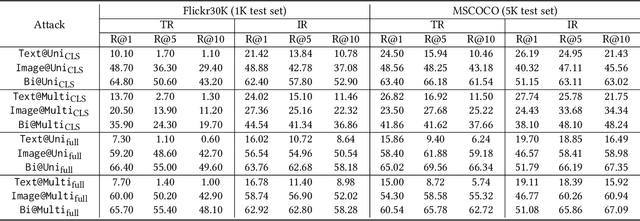
While vision-language pre-training model (VLP) has shown revolutionary improvements on various vision-language (V+L) tasks, the studies regarding its adversarial robustness remain largely unexplored. This paper studied the adversarial attack on popular VLP models and V+L tasks. First, we analyzed the performance of adversarial attacks under different settings. By examining the influence of different perturbed objects and attack targets, we concluded some key observations as guidance on both designing strong multimodal adversarial attack and constructing robust VLP models. Second, we proposed a novel multimodal attack method on the VLP models called Collaborative Multimodal Adversarial Attack (Co-Attack), which collectively carries out the attacks on the image modality and the text modality. Experimental results demonstrated that the proposed method achieves improved attack performances on different V+L downstream tasks and VLP models. The analysis observations and novel attack method hopefully provide new understanding into the adversarial robustness of VLP models, so as to contribute their safe and reliable deployment in more real-world scenarios.
Incorporating Boundary Uncertainty into loss functions for biomedical image segmentation
Oct 31, 2021
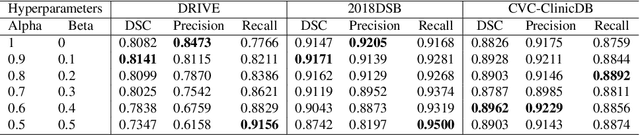
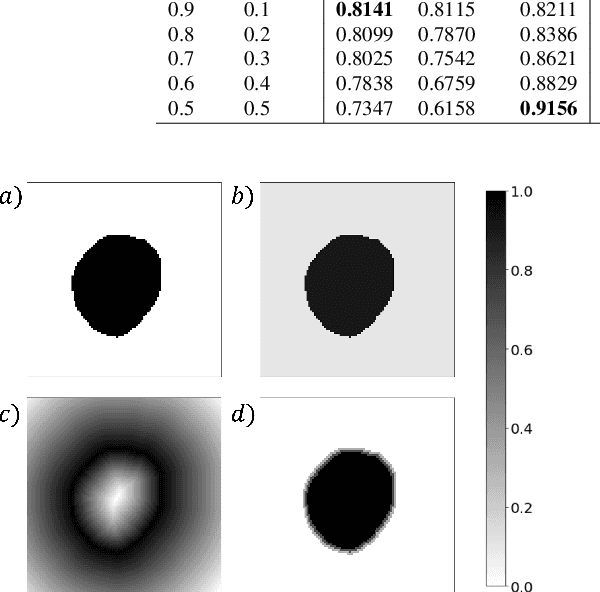

Manual segmentation is used as the gold-standard for evaluating neural networks on automated image segmentation tasks. Due to considerable heterogeneity in shapes, colours and textures, demarcating object boundaries is particularly difficult in biomedical images, resulting in significant inter and intra-rater variability. Approaches, such as soft labelling and distance penalty term, apply a global transformation to the ground truth, redefining the loss function with respect to uncertainty. However, global operations are computationally expensive, and neither approach accurately reflects the uncertainty underlying manual annotation. In this paper, we propose the Boundary Uncertainty, which uses morphological operations to restrict soft labelling to object boundaries, providing an appropriate representation of uncertainty in ground truth labels, and may be adapted to enable robust model training where systematic manual segmentation errors are present. We incorporate Boundary Uncertainty with the Dice loss, achieving consistently improved performance across three well-validated biomedical imaging datasets compared to soft labelling and distance-weighted penalty. Boundary Uncertainty not only more accurately reflects the segmentation process, but it is also efficient, robust to segmentation errors and exhibits better generalisation.
Set-based Meta-Interpolation for Few-Task Meta-Learning
May 20, 2022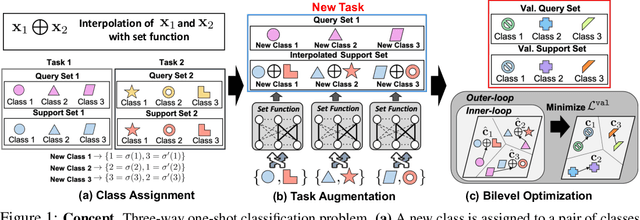
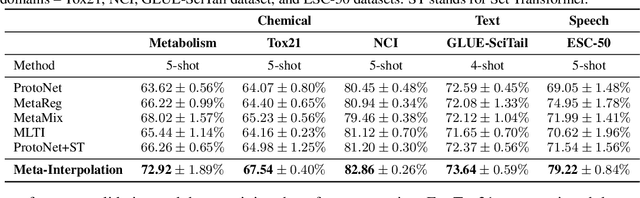
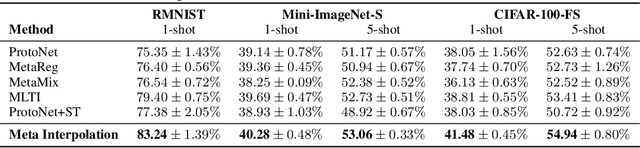
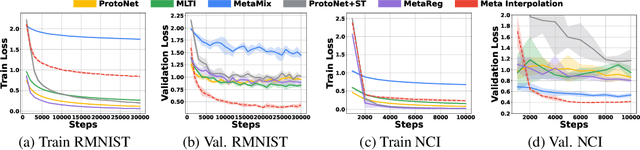
Meta-learning approaches enable machine learning systems to adapt to new tasks given few examples by leveraging knowledge from related tasks. However, a large number of meta-training tasks are still required for generalization to unseen tasks during meta-testing, which introduces a critical bottleneck for real-world problems that come with only few tasks, due to various reasons including the difficulty and cost of constructing tasks. Recently, several task augmentation methods have been proposed to tackle this issue using domain-specific knowledge to design augmentation techniques to densify the meta-training task distribution. However, such reliance on domain-specific knowledge renders these methods inapplicable to other domains. While Manifold Mixup based task augmentation methods are domain-agnostic, we empirically find them ineffective on non-image domains. To tackle these limitations, we propose a novel domain-agnostic task augmentation method, Meta-Interpolation, which utilizes expressive neural set functions to densify the meta-training task distribution using bilevel optimization. We empirically validate the efficacy of Meta-Interpolation on eight datasets spanning across various domains such as image classification, molecule property prediction, text classification and speech recognition. Experimentally, we show that Meta-Interpolation consistently outperforms all the relevant baselines. Theoretically, we prove that task interpolation with the set function regularizes the meta-learner to improve generalization.
A Unified Meta-Learning Framework for Dynamic Transfer Learning
Jul 05, 2022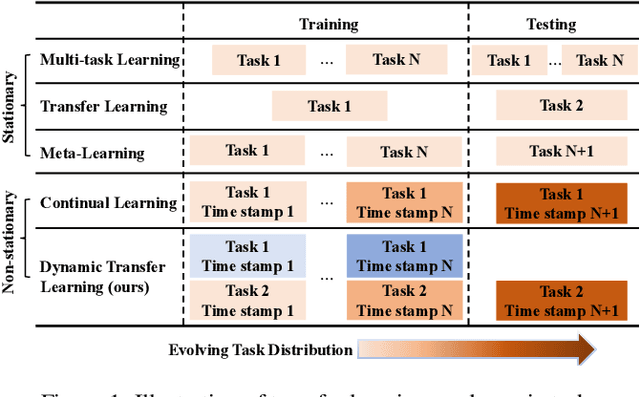

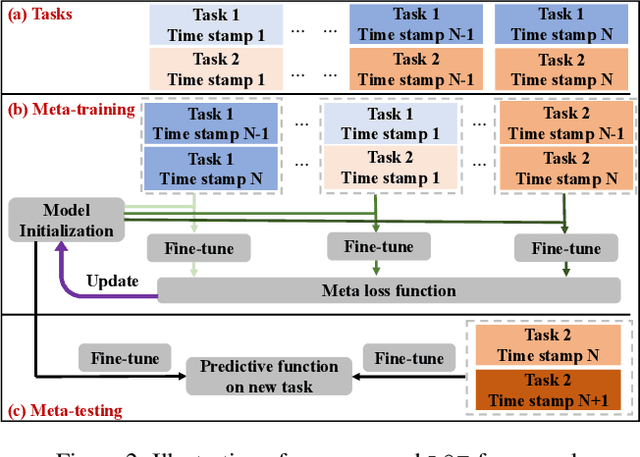
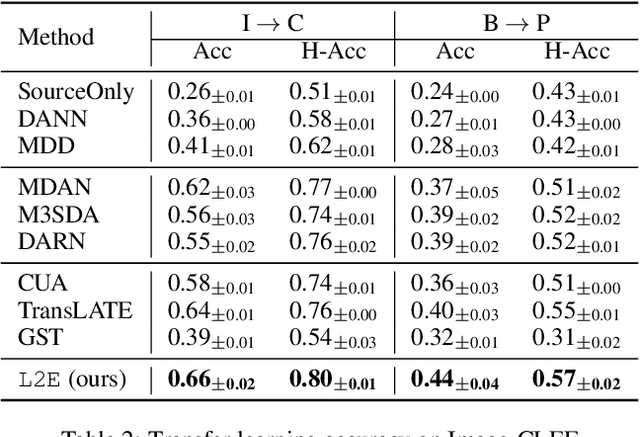
Transfer learning refers to the transfer of knowledge or information from a relevant source task to a target task. However, most existing works assume both tasks are sampled from a stationary task distribution, thereby leading to the sub-optimal performance for dynamic tasks drawn from a non-stationary task distribution in real scenarios. To bridge this gap, in this paper, we study a more realistic and challenging transfer learning setting with dynamic tasks, i.e., source and target tasks are continuously evolving over time. We theoretically show that the expected error on the dynamic target task can be tightly bounded in terms of source knowledge and consecutive distribution discrepancy across tasks. This result motivates us to propose a generic meta-learning framework L2E for modeling the knowledge transferability on dynamic tasks. It is centered around a task-guided meta-learning problem with a group of meta-pairs of tasks, based on which we are able to learn the prior model initialization for fast adaptation on the newest target task. L2E enjoys the following properties: (1) effective knowledge transferability across dynamic tasks; (2) fast adaptation to the new target task; (3) mitigation of catastrophic forgetting on historical target tasks; and (4) flexibility in incorporating any existing static transfer learning algorithms. Extensive experiments on various image data sets demonstrate the effectiveness of the proposed L2E framework.
Bounding Box Tightness Prior for Weakly Supervised Image Segmentation
Oct 03, 2021
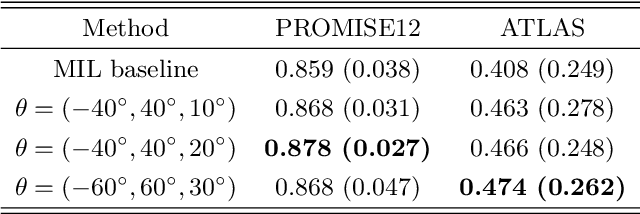
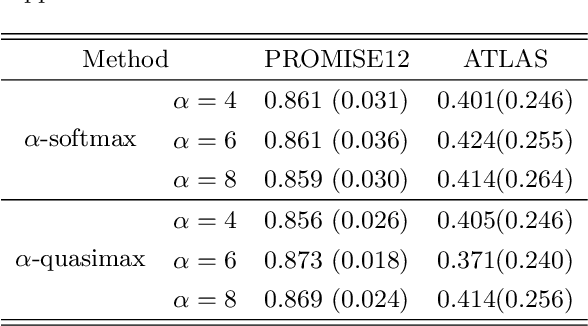
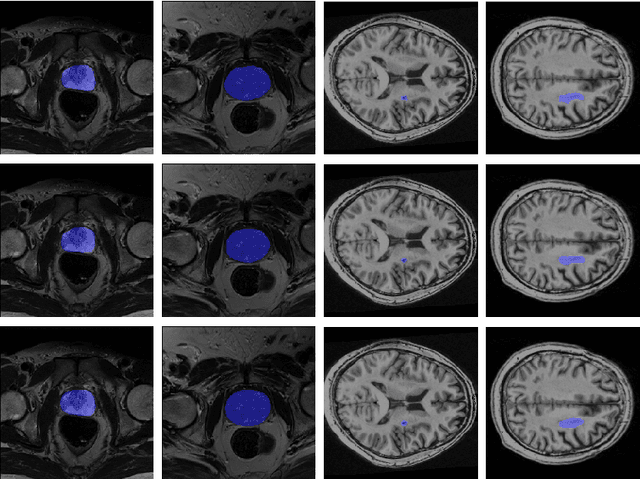
This paper presents a weakly supervised image segmentation method that adopts tight bounding box annotations. It proposes generalized multiple instance learning (MIL) and smooth maximum approximation to integrate the bounding box tightness prior into the deep neural network in an end-to-end manner. In generalized MIL, positive bags are defined by parallel crossing lines with a set of different angles, and negative bags are defined as individual pixels outside of any bounding boxes. Two variants of smooth maximum approximation, i.e., $\alpha$-softmax function and $\alpha$-quasimax function, are exploited to conquer the numeral instability introduced by maximum function of bag prediction. The proposed approach was evaluated on two pubic medical datasets using Dice coefficient. The results demonstrate that it outperforms the state-of-the-art methods. The codes are available at \url{https://github.com/wangjuan313/wsis-boundingbox}.
3DVSR: 3D EPI Volume-based Approach for Angular and Spatial Light field Image Super-resolution
Jan 04, 2022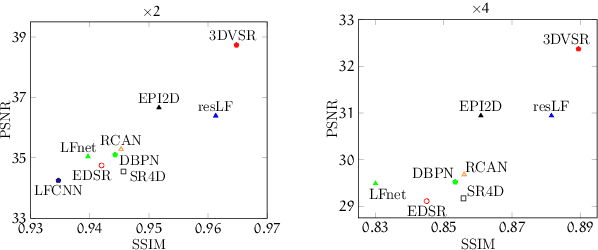
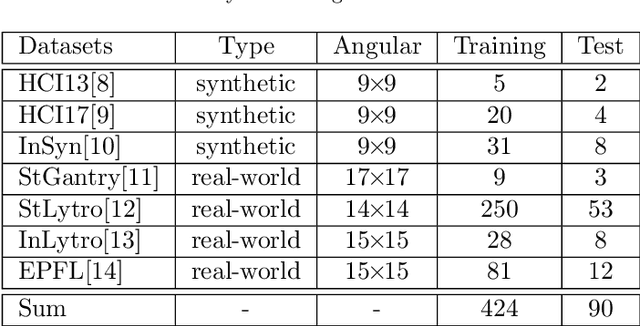
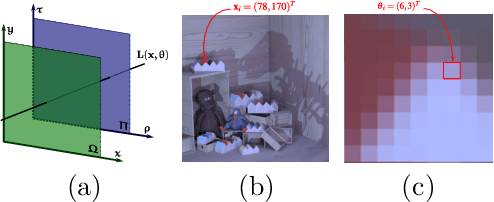

Light field (LF) imaging, which captures both spatial and angular information of a scene, is undoubtedly beneficial to numerous applications. Although various techniques have been proposed for LF acquisition, achieving both angularly and spatially high-resolution LF remains a technology challenge. In this paper, a learning-based approach applied to 3D epipolar image (EPI) is proposed to reconstruct high-resolution LF. Through a 2-stage super-resolution framework, the proposed approach effectively addresses various LF super-resolution (SR) problems, i.e., spatial SR, angular SR, and angular-spatial SR. While the first stage provides flexible options to up-sample EPI volume to the desired resolution, the second stage, which consists of a novel EPI volume-based refinement network (EVRN), substantially enhances the quality of the high-resolution EPI volume. An extensive evaluation on 90 challenging synthetic and real-world light field scenes from 7 published datasets shows that the proposed approach outperforms state-of-the-art methods to a large extend for both spatial and angular super-resolution problem, i.e., an average peak signal to noise ratio improvement of more than 2.0 dB, 1.4 dB, and 3.14 dB in spatial SR $\times 2$, spatial SR $\times 4$, and angular SR respectively. The reconstructed 4D light field demonstrates a balanced performance distribution across all perspective images and presents superior visual quality compared to the previous works.
SeeTheSeams: Localized Detection of Seam Carving based Image Forgery in Satellite Imagery
Aug 28, 2021
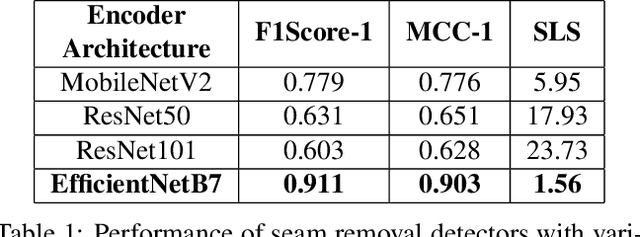

Seam carving is a popular technique for content aware image retargeting. It can be used to deliberately manipulate images, for example, change the GPS locations of a building or insert/remove roads in a satellite image. This paper proposes a novel approach for detecting and localizing seams in such images. While there are methods to detect seam carving based manipulations, this is the first time that robust localization and detection of seam carving forgery is made possible. We also propose a seam localization score (SLS) metric to evaluate the effectiveness of localization. The proposed method is evaluated extensively on a large collection of images from different sources, demonstrating a high level of detection and localization performance across these datasets. The datasets curated during this work will be released to the public.