 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Collation: Matching illustrations in manuscripts
Aug 18, 2021

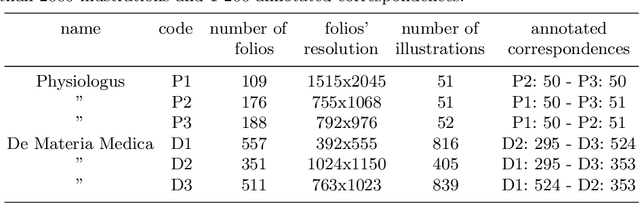


Illustrations are an essential transmission instrument. For an historian, the first step in studying their evolution in a corpus of similar manuscripts is to identify which ones correspond to each other. This image collation task is daunting for manuscripts separated by many lost copies, spreading over centuries, which might have been completely re-organized and greatly modified to adapt to novel knowledge or belief and include hundreds of illustrations. Our contributions in this paper are threefold. First, we introduce the task of illustration collation and a large annotated public dataset to evaluate solutions, including 6 manuscripts of 2 different texts with more than 2 000 illustrations and 1 200 annotated correspondences. Second, we analyze state of the art similarity measures for this task and show that they succeed in simple cases but struggle for large manuscripts when the illustrations have undergone very significant changes and are discriminated only by fine details. Finally, we show clear evidence that significant performance boosts can be expected by exploiting cycle-consistent correspondences. Our code and data are available on http://imagine.enpc.fr/~shenx/ImageCollation.
Leverage Your Local and Global Representations: A New Self-Supervised Learning Strategy
Apr 13, 2022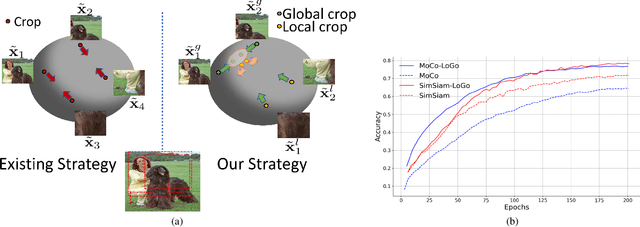
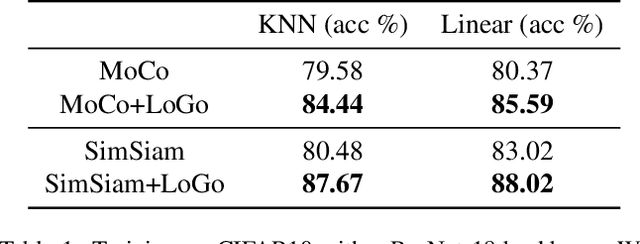
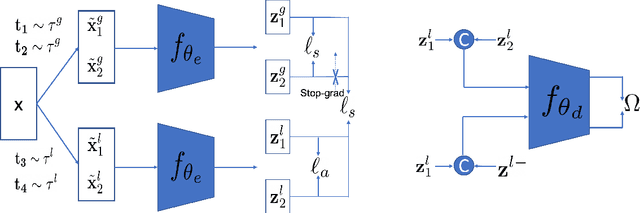
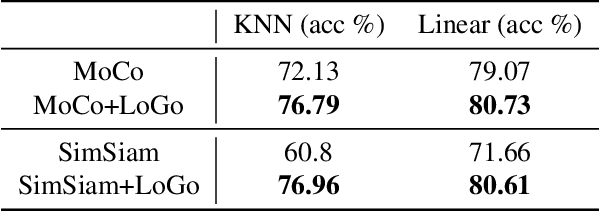
Self-supervised learning (SSL) methods aim to learn view-invariant representations by maximizing the similarity between the features extracted from different crops of the same image regardless of cropping size and content. In essence, this strategy ignores the fact that two crops may truly contain different image information, e.g., background and small objects, and thus tends to restrain the diversity of the learned representations. In this work, we address this issue by introducing a new self-supervised learning strategy, LoGo, that explicitly reasons about Local and Global crops. To achieve view invariance, LoGo encourages similarity between global crops from the same image, as well as between a global and a local crop. However, to correctly encode the fact that the content of smaller crops may differ entirely, LoGo promotes two local crops to have dissimilar representations, while being close to global crops. Our LoGo strategy can easily be applied to existing SSL methods. Our extensive experiments on a variety of datasets and using different self-supervised learning frameworks validate its superiority over existing approaches. Noticeably, we achieve better results than supervised models on transfer learning when using only 1/10 of the data.
ECLAD: Extracting Concepts with Local Aggregated Descriptors
Jun 09, 2022Convolutional neural networks are being increasingly used in critical systems, where ensuring their robustness and alignment is crucial. In this context, the field of explainable artificial intelligence has proposed the generation of high-level explanations through concept extraction. These methods detect whether a concept is present in an image, but are incapable of locating where. What is more, a fair comparison of approaches is difficult, as proper validation procedures are missing. To fill these gaps, we propose a novel method for automatic concept extraction and localization based on representations obtained through the pixel-wise aggregations of activation maps of CNNs. Further, we introduce a process for the validation of concept-extraction techniques based on synthetic datasets with pixel-wise annotations of their main components, reducing human intervention. Through extensive experimentation on both synthetic and real-world datasets, our method achieves better performance in comparison to state-of-the-art alternatives.
A Distillation Learning Model of Adaptive Structural Deep Belief Network for AffectNet: Facial Expression Image Database
Oct 25, 2021
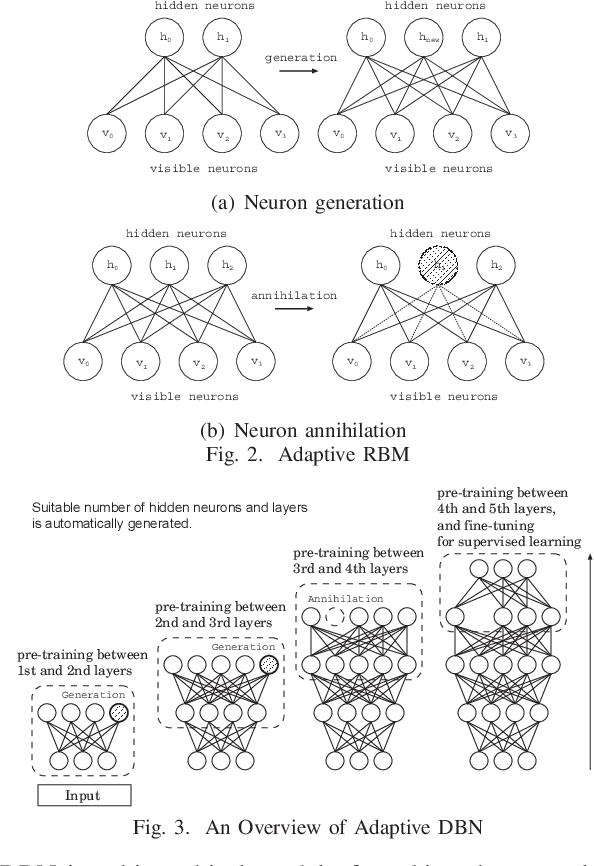
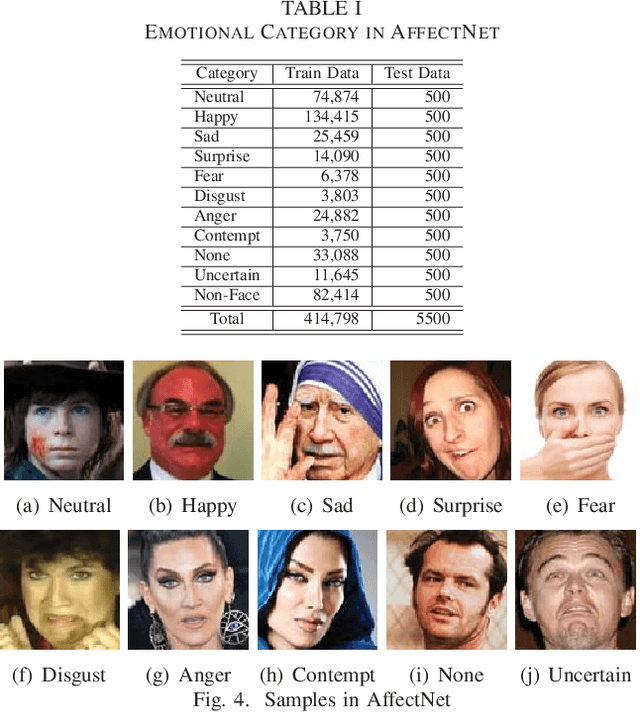
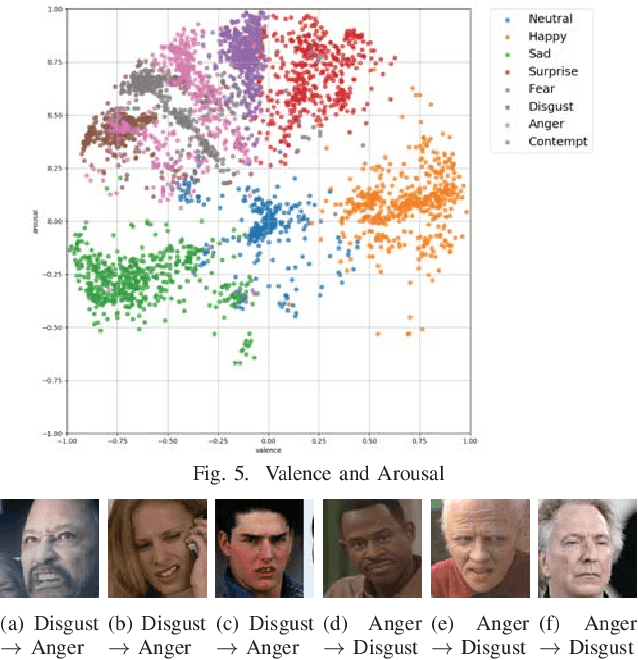
Deep Learning has a hierarchical network architecture to represent the complicated feature of input patterns. We have developed the adaptive structure learning method of Deep Belief Network (DBN) that can discover an optimal number of hidden neurons for given input data in a Restricted Boltzmann Machine (RBM) by neuron generation-annihilation algorithm, and can obtain the appropriate number of hidden layers in DBN. In this paper, our model is applied to a facial expression image data set, AffectNet. The system has higher classification capability than the traditional CNN. However, our model was not able to classify some test cases correctly because human emotions contain many ambiguous features or patterns leading wrong answer by two or more annotators who have different subjective judgment for a facial image. In order to represent such cases, this paper investigated a distillation learning model of Adaptive DBN. The original trained model can be seen as a parent model and some child models are trained for some mis-classified cases. For the difference between the parent model and the child one, KL divergence is monitored and then some appropriate new neurons at the parent model are generated according to KL divergence to improve classification accuracy. In this paper, the classification accuracy was improved from 78.4% to 91.3% by the proposed method.
Fast Vision Transformers with HiLo Attention
May 26, 2022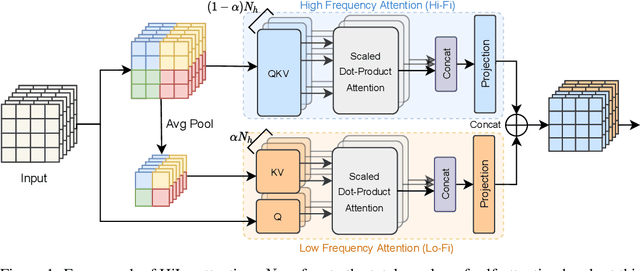
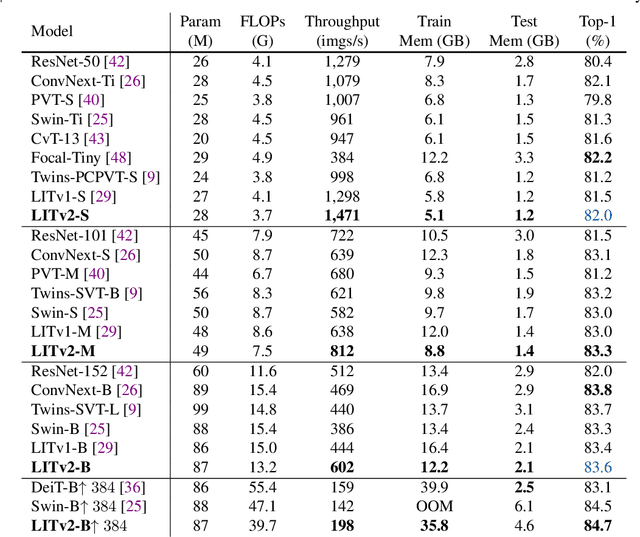
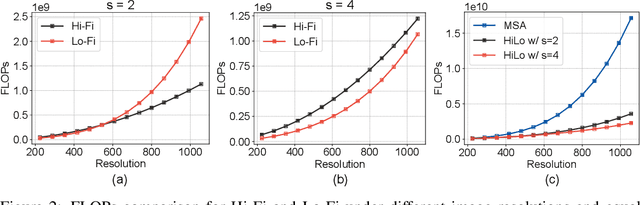
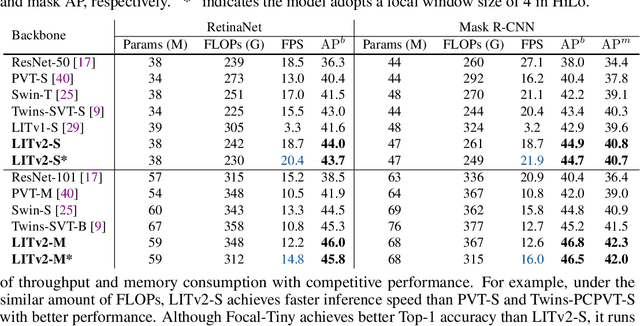
Vision Transformers (ViTs) have triggered the most recent and significant breakthroughs in computer vision. Their efficient designs are mostly guided by the indirect metric of computational complexity, i.e., FLOPs, which however has a clear gap with the direct metric such as throughput. Thus, we propose to use the direct speed evaluation on the target platform as the design principle for efficient ViTs. Particularly, we introduce LITv2, a simple and effective ViT which performs favourably against the existing state-of-the-art methods across a spectrum of different model sizes with faster speed. At the core of LITv2 is a novel self-attention mechanism, which we dub HiLo. HiLo is inspired by the insight that high frequencies in an image capture local fine details and low frequencies focus on global structures, whereas a multi-head self-attention layer neglects the characteristic of different frequencies. Therefore, we propose to disentangle the high/low frequency patterns in an attention layer by separating the heads into two groups, where one group encodes high frequencies via self-attention within each local window, and another group performs the attention to model the global relationship between the average-pooled low-frequency keys from each window and each query position in the input feature map. Benefit from the efficient design for both groups, we show that HiLo is superior to the existing attention mechanisms by comprehensively benchmarking on FLOPs, speed and memory consumption on GPUs. Powered by HiLo, LITv2 serves as a strong backbone for mainstream vision tasks including image classification, dense detection and segmentation. Code is available at https://github.com/zip-group/LITv2.
Data Augmentation using Random Image Cropping for High-resolution Virtual Try-On (VITON-CROP)
Nov 16, 2021

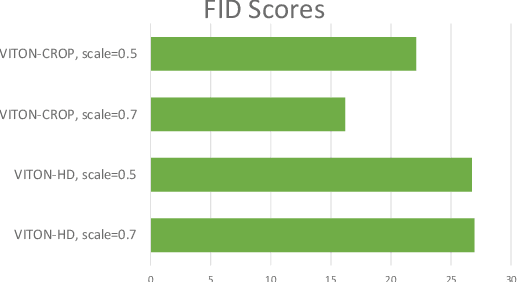
Image-based virtual try-on provides the capacity to transfer a clothing item onto a photo of a given person, which is usually accomplished by warping the item to a given human pose and adjusting the warped item to the person. However, the results of real-world synthetic images (e.g., selfies) from the previous method is not realistic because of the limitations which result in the neck being misrepresented and significant changes to the style of the garment. To address these challenges, we propose a novel method to solve this unique issue, called VITON-CROP. VITON-CROP synthesizes images more robustly when integrated with random crop augmentation compared to the existing state-of-the-art virtual try-on models. In the experiments, we demonstrate that VITON-CROP is superior to VITON-HD both qualitatively and quantitatively.
Unsupervised Remote Sensing Super-Resolution via Migration Image Prior
May 08, 2021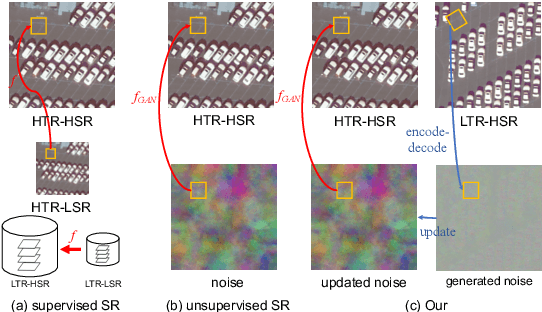
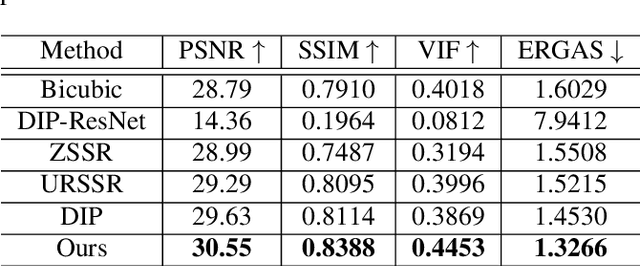
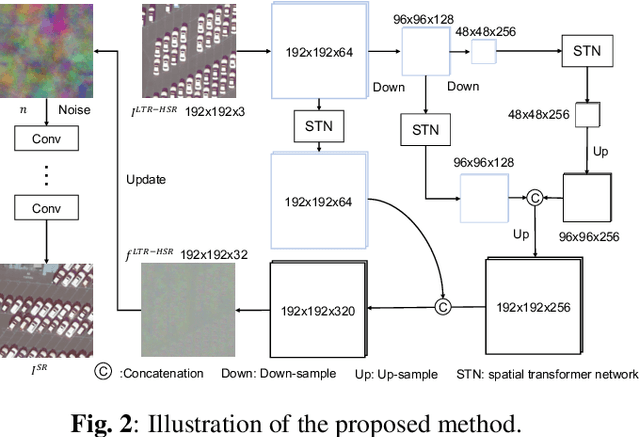
Recently, satellites with high temporal resolution have fostered wide attention in various practical applications. Due to limitations of bandwidth and hardware cost, however, the spatial resolution of such satellites is considerably low, largely limiting their potentials in scenarios that require spatially explicit information. To improve image resolution, numerous approaches based on training low-high resolution pairs have been proposed to address the super-resolution (SR) task. Despite their success, however, low/high spatial resolution pairs are usually difficult to obtain in satellites with a high temporal resolution, making such approaches in SR impractical to use. In this paper, we proposed a new unsupervised learning framework, called "MIP", which achieves SR tasks without low/high resolution image pairs. First, random noise maps are fed into a designed generative adversarial network (GAN) for reconstruction. Then, the proposed method converts the reference image to latent space as the migration image prior. Finally, we update the input noise via an implicit method, and further transfer the texture and structured information from the reference image. Extensive experimental results on the Draper dataset show that MIP achieves significant improvements over state-of-the-art methods both quantitatively and qualitatively. The proposed MIP is open-sourced at http://github.com/jiaming-wang/MIP.
1st Place Solution for the UVO Challenge on Image-based Open-World Segmentation 2021
Oct 19, 2021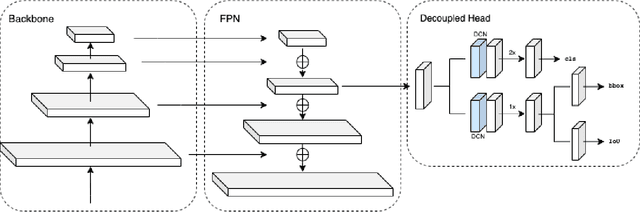

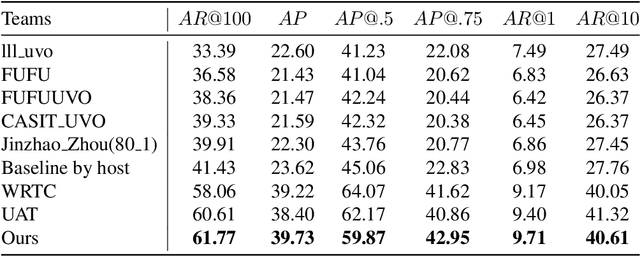
We describe our two-stage instance segmentation framework we use to compete in the challenge. The first stage of our framework consists of an object detector, which generates object proposals in the format of bounding boxes. Then, the images and the detected bounding boxes are fed to the second stage, where a segmentation network is applied to segment the objects in the bounding boxes. We train all our networks in a class-agnostic way. Our approach achieves the first place in the UVO 2021 Image-based Open-World Segmentation Challenge.
Spectral-Spatial Graph Reasoning Network for Hyperspectral Image Classification
Jun 26, 2021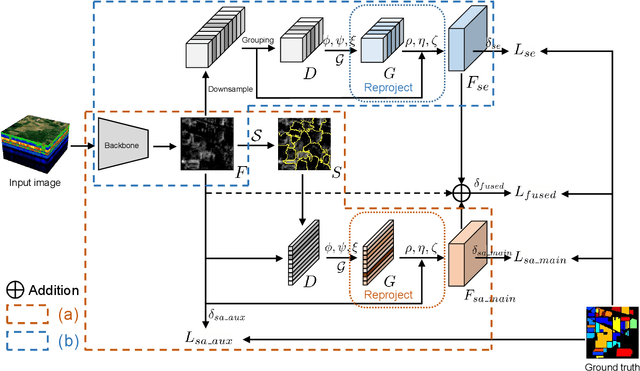


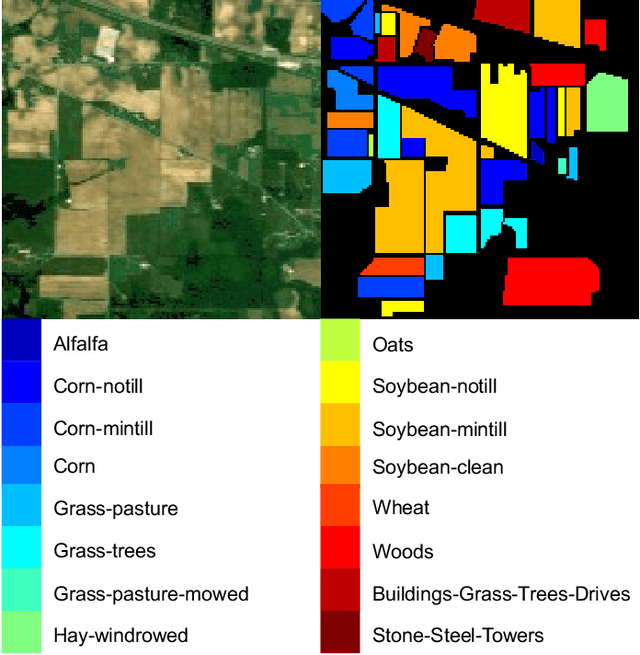
In this paper, we propose a spectral-spatial graph reasoning network (SSGRN) for hyperspectral image (HSI) classification. Concretely, this network contains two parts that separately named spatial graph reasoning subnetwork (SAGRN) and spectral graph reasoning subnetwork (SEGRN) to capture the spatial and spectral graph contexts, respectively. Different from the previous approaches implementing superpixel segmentation on the original image or attempting to obtain the category features under the guide of label image, we perform the superpixel segmentation on intermediate features of the network to adaptively produce the homogeneous regions to get the effective descriptors. Then, we adopt a similar idea in spectral part that reasonably aggregating the channels to generate spectral descriptors for spectral graph contexts capturing. All graph reasoning procedures in SAGRN and SEGRN are achieved through graph convolution. To guarantee the global perception ability of the proposed methods, all adjacent matrices in graph reasoning are obtained with the help of non-local self-attention mechanism. At last, by combining the extracted spatial and spectral graph contexts, we obtain the SSGRN to achieve a high accuracy classification. Extensive quantitative and qualitative experiments on three public HSI benchmarks demonstrate the competitiveness of the proposed methods compared with other state-of-the-art approaches.
RES: A Robust Framework for Guiding Visual Explanation
Jun 27, 2022
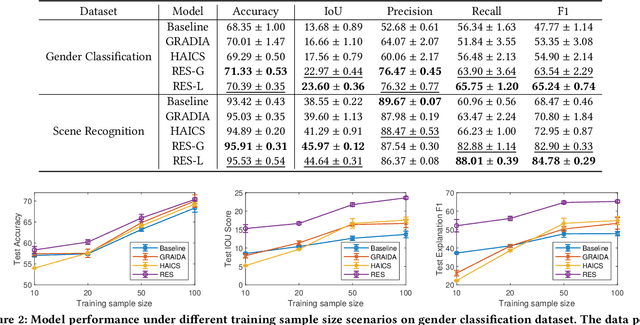
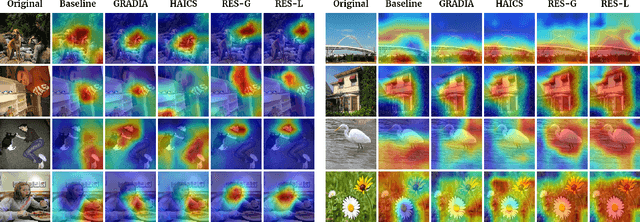
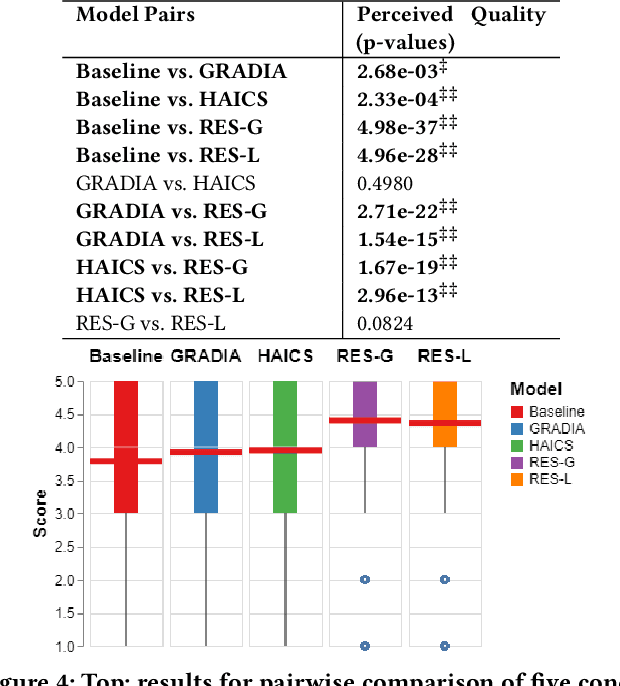
Despite the fast progress of explanation techniques in modern Deep Neural Networks (DNNs) where the main focus is handling "how to generate the explanations", advanced research questions that examine the quality of the explanation itself (e.g., "whether the explanations are accurate") and improve the explanation quality (e.g., "how to adjust the model to generate more accurate explanations when explanations are inaccurate") are still relatively under-explored. To guide the model toward better explanations, techniques in explanation supervision - which add supervision signals on the model explanation - have started to show promising effects on improving both the generalizability as and intrinsic interpretability of Deep Neural Networks. However, the research on supervising explanations, especially in vision-based applications represented through saliency maps, is in its early stage due to several inherent challenges: 1) inaccuracy of the human explanation annotation boundary, 2) incompleteness of the human explanation annotation region, and 3) inconsistency of the data distribution between human annotation and model explanation maps. To address the challenges, we propose a generic RES framework for guiding visual explanation by developing a novel objective that handles inaccurate boundary, incomplete region, and inconsistent distribution of human annotations, with a theoretical justification on model generalizability. Extensive experiments on two real-world image datasets demonstrate the effectiveness of the proposed framework on enhancing both the reasonability of the explanation and the performance of the backbone DNNs model.
* Published in KDD 2022