 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Overparameterization Improves StyleGAN Inversion
May 12, 2022
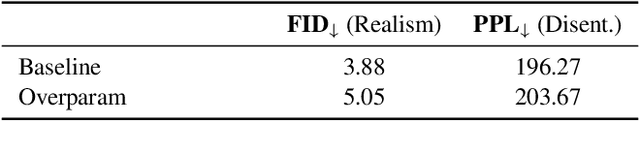
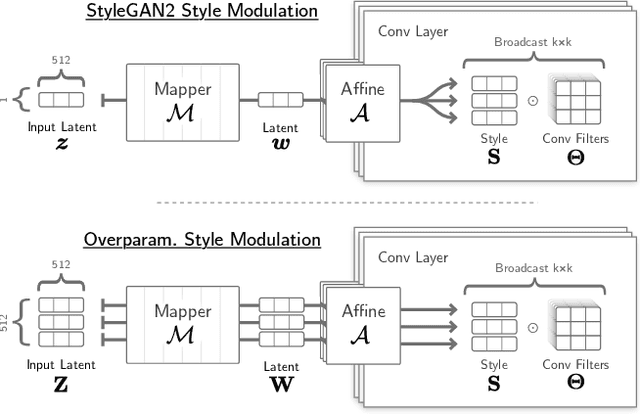
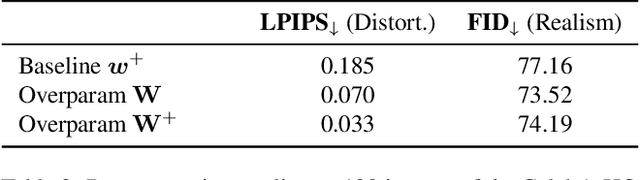
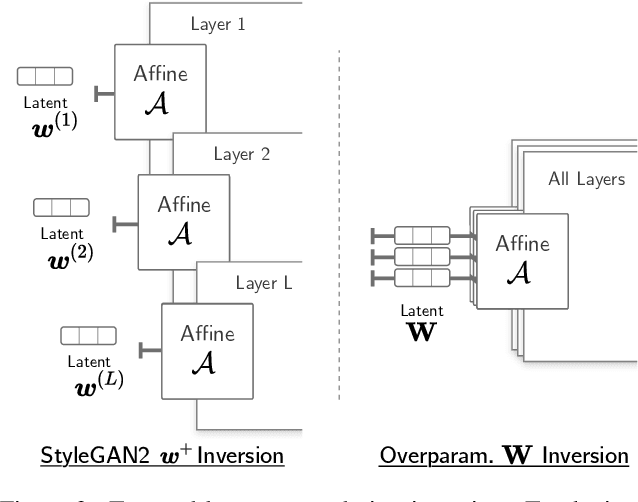
Deep generative models like StyleGAN hold the promise of semantic image editing: modifying images by their content, rather than their pixel values. Unfortunately, working with arbitrary images requires inverting the StyleGAN generator, which has remained challenging so far. Existing inversion approaches obtain promising yet imperfect results, having to trade-off between reconstruction quality and downstream editability. To improve quality, these approaches must resort to various techniques that extend the model latent space after training. Taking a step back, we observe that these methods essentially all propose, in one way or another, to increase the number of free parameters. This suggests that inversion might be difficult because it is underconstrained. In this work, we address this directly and dramatically overparameterize the latent space, before training, with simple changes to the original StyleGAN architecture. Our overparameterization increases the available degrees of freedom, which in turn facilitates inversion. We show that this allows us to obtain near-perfect image reconstruction without the need for encoders nor for altering the latent space after training. Our approach also retains editability, which we demonstrate by realistically interpolating between images.
Unsupervised Remote Sensing Super-Resolution via Migration Image Prior
May 23, 2021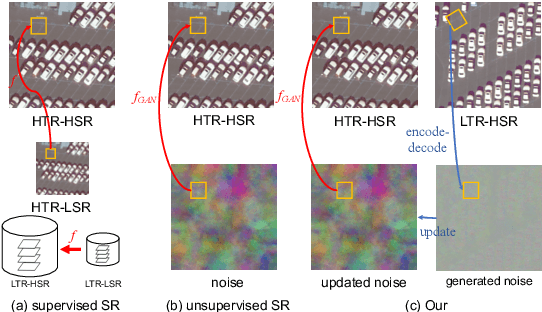
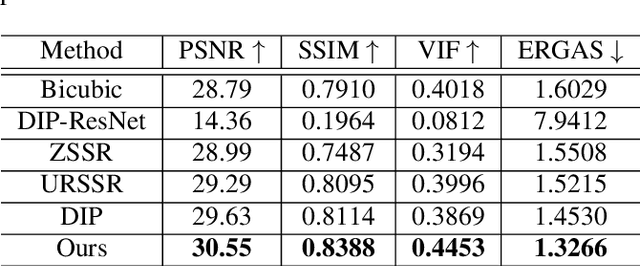
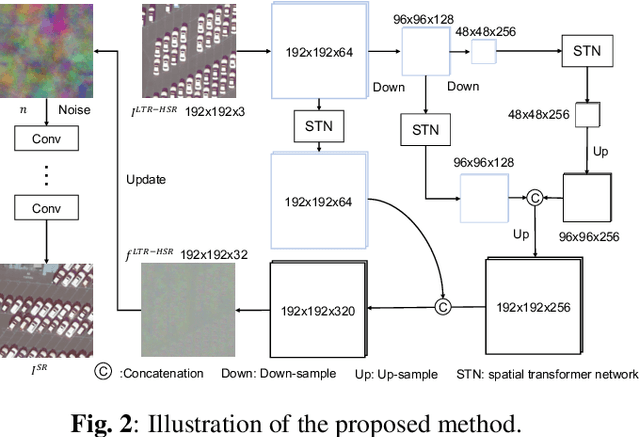
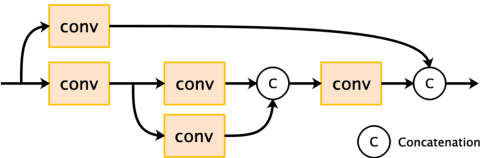
Recently, satellites with high temporal resolution have fostered wide attention in various practical applications. Due to limitations of bandwidth and hardware cost, however, the spatial resolution of such satellites is considerably low, largely limiting their potentials in scenarios that require spatially explicit information. To improve image resolution, numerous approaches based on training low-high resolution pairs have been proposed to address the super-resolution (SR) task. Despite their success, however, low/high spatial resolution pairs are usually difficult to obtain in satellites with a high temporal resolution, making such approaches in SR impractical to use. In this paper, we proposed a new unsupervised learning framework, called "MIP", which achieves SR tasks without low/high resolution image pairs. First, random noise maps are fed into a designed generative adversarial network (GAN) for reconstruction. Then, the proposed method converts the reference image to latent space as the migration image prior. Finally, we update the input noise via an implicit method, and further transfer the texture and structured information from the reference image. Extensive experimental results on the Draper dataset show that MIP achieves significant improvements over state-of-the-art methods both quantitatively and qualitatively. The proposed MIP is open-sourced at http://github.com/jiaming-wang/MIP.
Dynamic Message Propagation Network for RGB-D Salient Object Detection
Jun 20, 2022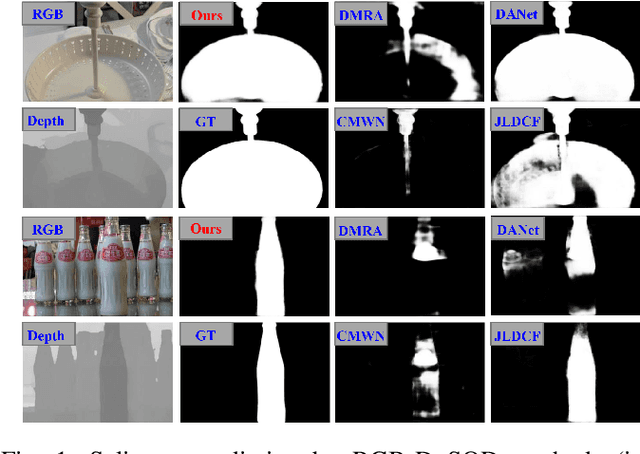
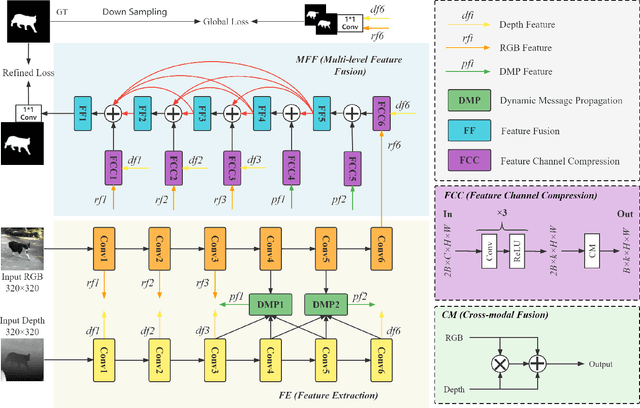
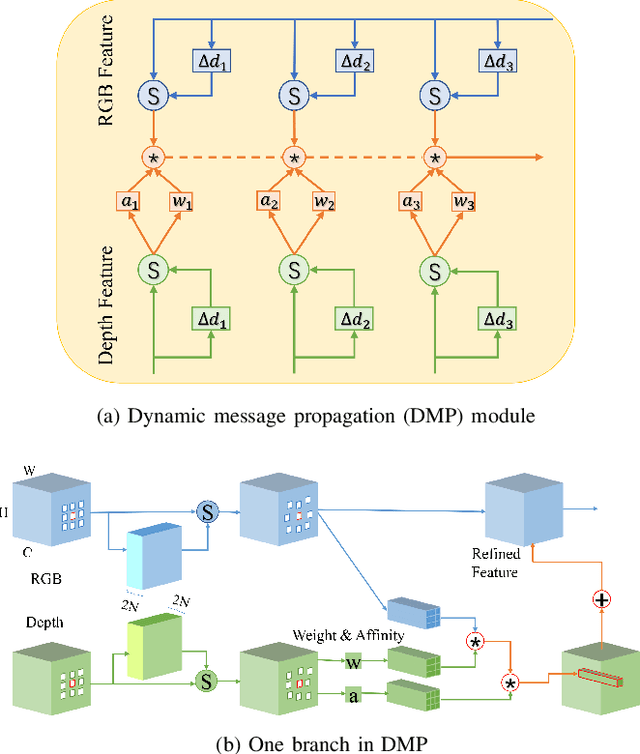
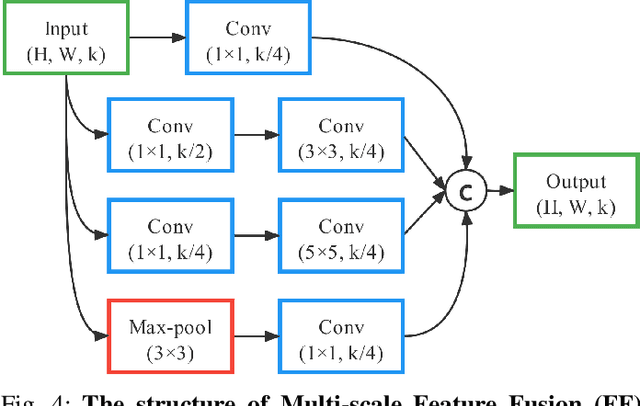
This paper presents a novel deep neural network framework for RGB-D salient object detection by controlling the message passing between the RGB images and depth maps on the feature level and exploring the long-range semantic contexts and geometric information on both RGB and depth features to infer salient objects. To achieve this, we formulate a dynamic message propagation (DMP) module with the graph neural networks and deformable convolutions to dynamically learn the context information and to automatically predict filter weights and affinity matrices for message propagation control. We further embed this module into a Siamese-based network to process the RGB image and depth map respectively and design a multi-level feature fusion (MFF) module to explore the cross-level information between the refined RGB and depth features. Compared with 17 state-of-the-art methods on six benchmark datasets for RGB-D salient object detection, experimental results show that our method outperforms all the others, both quantitatively and visually.
Domain Composition and Attention for Unseen-Domain Generalizable Medical Image Segmentation
Sep 18, 2021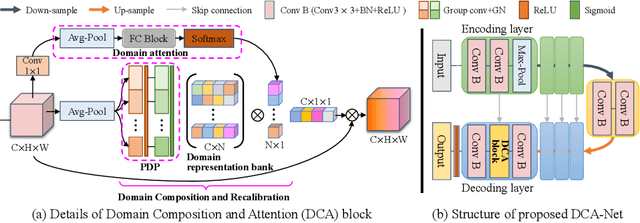
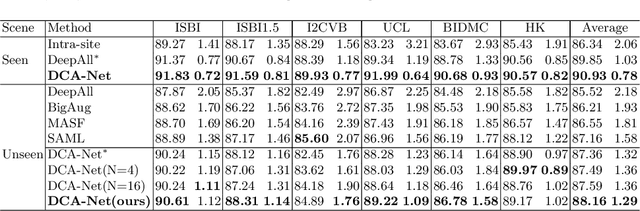
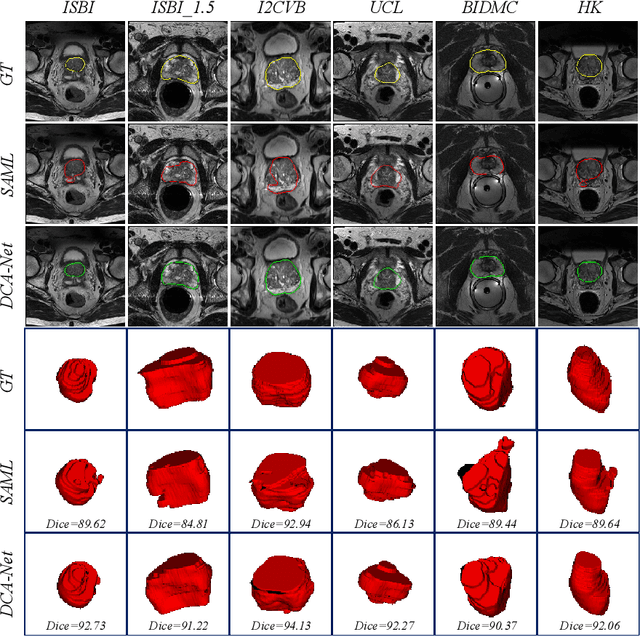
Domain generalizable model is attracting increasing attention in medical image analysis since data is commonly acquired from different institutes with various imaging protocols and scanners. To tackle this challenging domain generalization problem, we propose a Domain Composition and Attention-based network (DCA-Net) to improve the ability of domain representation and generalization. First, we present a domain composition method that represents one certain domain by a linear combination of a set of basis representations (i.e., a representation bank). Second, a novel plug-and-play parallel domain preceptor is proposed to learn these basis representations and we introduce a divergence constraint function to encourage the basis representations to be as divergent as possible. Then, a domain attention module is proposed to learn the linear combination coefficients of the basis representations. The result of linear combination is used to calibrate the feature maps of an input image, which enables the model to generalize to different and even unseen domains. We validate our method on public prostate MRI dataset acquired from six different institutions with apparent domain shift. Experimental results show that our proposed model can generalize well on different and even unseen domains and it outperforms state-of-the-art methods on the multi-domain prostate segmentation task.
Multi-scale Image Decomposition using a Local Statistical Edge Model
May 05, 2021

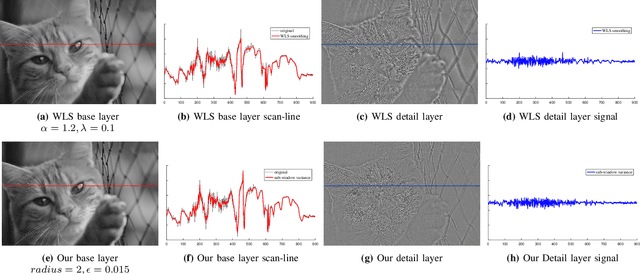

We present a progressive image decomposition method based on a novel non-linear filter named Sub-window Variance filter. Our method is specifically designed for image detail enhancement purpose; this application requires extraction of image details which are small in terms of both spatial and variation scales. We propose a local statistical edge model which develops its edge awareness using spatially defined image statistics. Our decomposition method is controlled by two intuitive parameters which allow the users to define what image details to suppress or enhance. By using the summed-area table acceleration method, our decomposition pipeline is highly parallel. The proposed filter is gradient preserving and this allows our enhancement results free from the gradient-reversal artefact. In our evaluations, we compare our method in various multi-scale image detail manipulation applications with other mainstream solutions.
Multimodal Fake News Detection via CLIP-Guided Learning
May 28, 2022
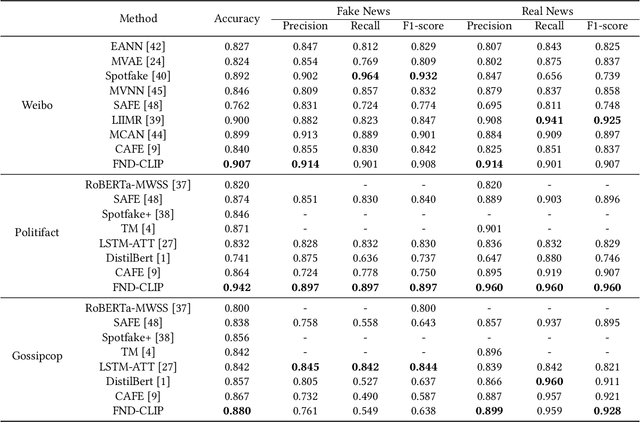
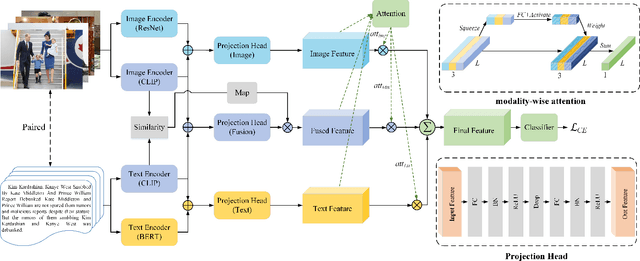
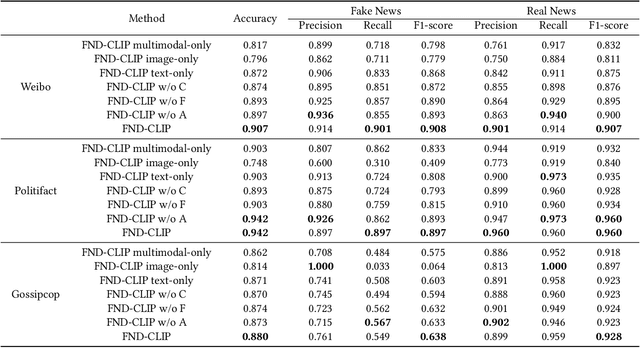
Multimodal fake news detection has attracted many research interests in social forensics. Many existing approaches introduce tailored attention mechanisms to guide the fusion of unimodal features. However, how the similarity of these features is calculated and how it will affect the decision-making process in FND are still open questions. Besides, the potential of pretrained multi-modal feature learning models in fake news detection has not been well exploited. This paper proposes a FND-CLIP framework, i.e., a multimodal Fake News Detection network based on Contrastive Language-Image Pretraining (CLIP). Given a targeted multimodal news, we extract the deep representations from the image and text using a ResNet-based encoder, a BERT-based encoder and two pair-wise CLIP encoders. The multimodal feature is a concatenation of the CLIP-generated features weighted by the standardized cross-modal similarity of the two modalities. The extracted features are further processed for redundancy reduction before feeding them into the final classifier. We introduce a modality-wise attention module to adaptively reweight and aggregate the features. We have conducted extensive experiments on typical fake news datasets. The results indicate that the proposed framework has a better capability in mining crucial features for fake news detection. The proposed FND-CLIP can achieve better performances than previous works, i.e., 0.7\%, 6.8\% and 1.3\% improvements in overall accuracy on Weibo, Politifact and Gossipcop, respectively. Besides, we justify that CLIP-based learning can allow better flexibility on multimodal feature selection.
Is a PET all you need? A multi-modal study for Alzheimer's disease using 3D CNNs
Jul 05, 2022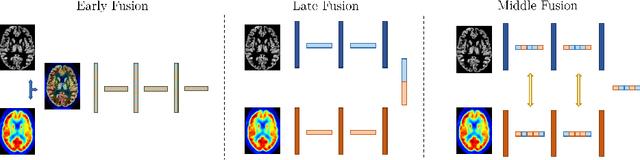
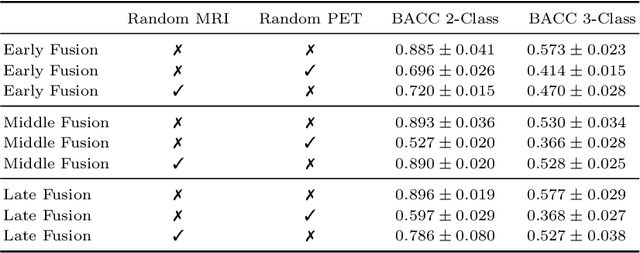

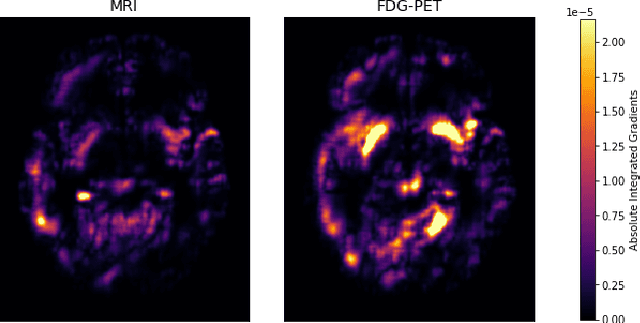
Alzheimer's Disease (AD) is the most common form of dementia and often difficult to diagnose due to the multifactorial etiology of dementia. Recent works on neuroimaging-based computer-aided diagnosis with deep neural networks (DNNs) showed that fusing structural magnetic resonance images (sMRI) and fluorodeoxyglucose positron emission tomography (FDG-PET) leads to improved accuracy in a study population of healthy controls and subjects with AD. However, this result conflicts with the established clinical knowledge that FDG-PET better captures AD-specific pathologies than sMRI. Therefore, we propose a framework for the systematic evaluation of multi-modal DNNs and critically re-evaluate single- and multi-modal DNNs based on FDG-PET and sMRI for binary healthy vs. AD, and three-way healthy/mild cognitive impairment/AD classification. Our experiments demonstrate that a single-modality network using FDG-PET performs better than MRI (accuracy 0.91 vs 0.87) and does not show improvement when combined. This conforms with the established clinical knowledge on AD biomarkers, but raises questions about the true benefit of multi-modal DNNs. We argue that future work on multi-modal fusion should systematically assess the contribution of individual modalities following our proposed evaluation framework. Finally, we encourage the community to go beyond healthy vs. AD classification and focus on differential diagnosis of dementia, where fusing multi-modal image information conforms with a clinical need.
Joint Distribution Matters: Deep Brownian Distance Covariance for Few-Shot Classification
Apr 09, 2022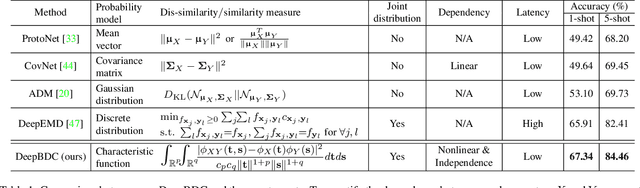
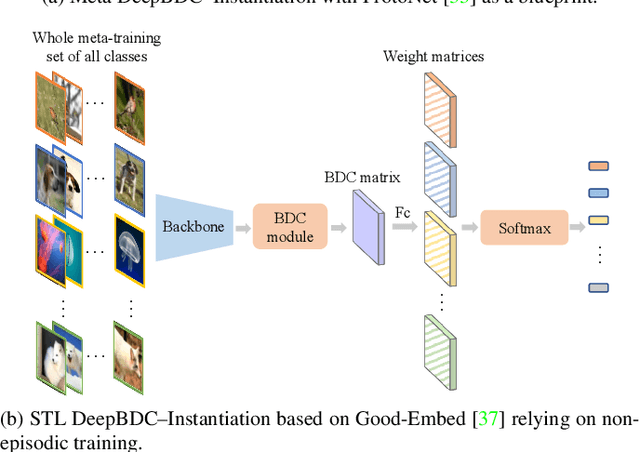
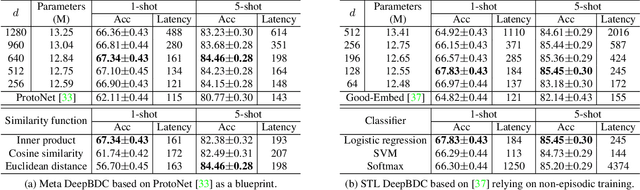
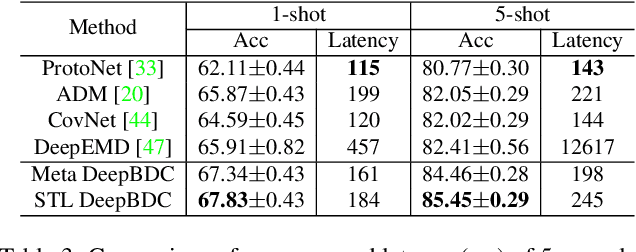
Few-shot classification is a challenging problem as only very few training examples are given for each new task. One of the effective research lines to address this challenge focuses on learning deep representations driven by a similarity measure between a query image and few support images of some class. Statistically, this amounts to measure the dependency of image features, viewed as random vectors in a high-dimensional embedding space. Previous methods either only use marginal distributions without considering joint distributions, suffering from limited representation capability, or are computationally expensive though harnessing joint distributions. In this paper, we propose a deep Brownian Distance Covariance (DeepBDC) method for few-shot classification. The central idea of DeepBDC is to learn image representations by measuring the discrepancy between joint characteristic functions of embedded features and product of the marginals. As the BDC metric is decoupled, we formulate it as a highly modular and efficient layer. Furthermore, we instantiate DeepBDC in two different few-shot classification frameworks. We make experiments on six standard few-shot image benchmarks, covering general object recognition, fine-grained categorization and cross-domain classification. Extensive evaluations show our DeepBDC significantly outperforms the counterparts, while establishing new state-of-the-art results. The source code is available at http://www.peihuali.org/DeepBDC
Enriching StyleGAN with Illumination Physics
May 20, 2022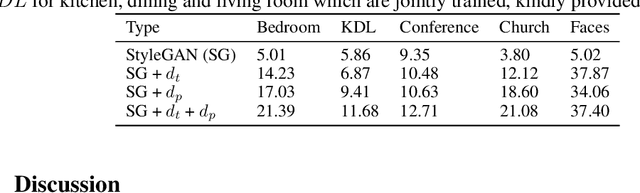
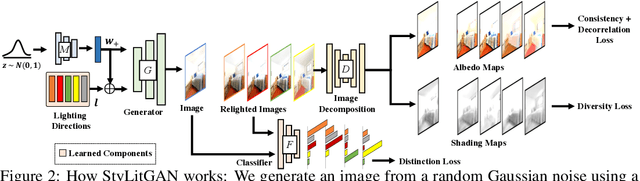


StyleGAN generates novel images of a scene from latent codes which are impressively disentangled. But StyleGAN generates images that are "like" its training set. This paper shows how to use simple physical properties of images to enrich StyleGAN's generation capacity. We use an intrinsic image method to decompose an image, then search the latent space of a pretrained StyleGAN to find novel directions that fix one component (say, albedo) and vary another (say, shading). Therefore, we can change the lighting of a complex scene without changing the scene layout, object colors, and shapes. Or we can change the colors of objects without changing shading intensity or their scene layout. Our experiments suggest the proposed method, StyLitGAN, can add and remove luminaires in the scene and generate images with realistic lighting effects -- cast shadows, soft shadows, inter-reflections, glossy effects -- requiring no labeled paired relighting data or any other geometric supervision. Qualitative evaluation confirms that our generated images are realistic and that we can change or fix components at will. Quantitative evaluation shows that pre-trained StyleGAN could not produce the images StyLitGAN produces; we can automatically generate realistic out-of-distribution images, and so can significantly enrich the range of images StyleGAN can produce.
k-means Mask Transformer
Jul 08, 2022
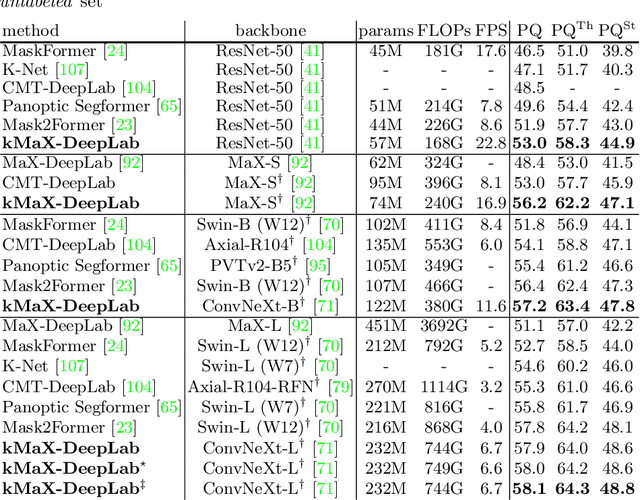
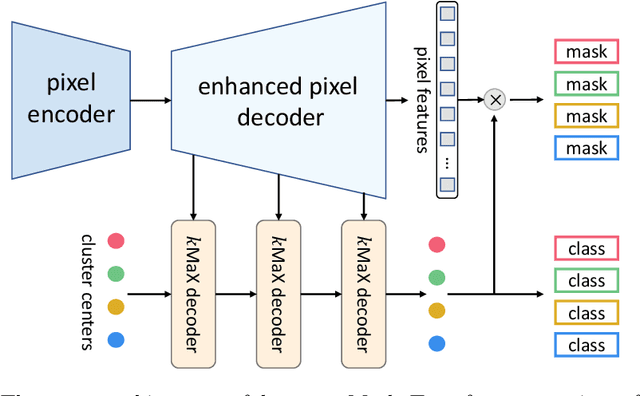
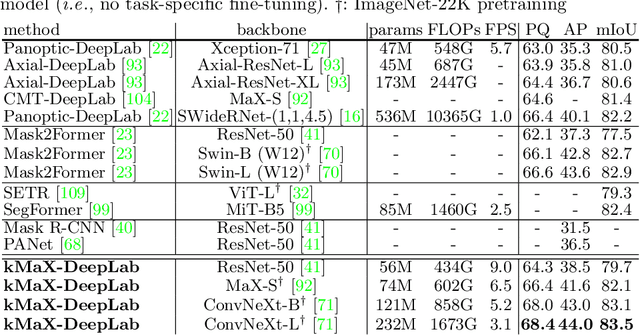
The rise of transformers in vision tasks not only advances network backbone designs, but also starts a brand-new page to achieve end-to-end image recognition (e.g., object detection and panoptic segmentation). Originated from Natural Language Processing (NLP), transformer architectures, consisting of self-attention and cross-attention, effectively learn long-range interactions between elements in a sequence. However, we observe that most existing transformer-based vision models simply borrow the idea from NLP, neglecting the crucial difference between languages and images, particularly the extremely large sequence length of spatially flattened pixel features. This subsequently impedes the learning in cross-attention between pixel features and object queries. In this paper, we rethink the relationship between pixels and object queries and propose to reformulate the cross-attention learning as a clustering process. Inspired by the traditional k-means clustering algorithm, we develop a k-means Mask Xformer (kMaX-DeepLab) for segmentation tasks, which not only improves the state-of-the-art, but also enjoys a simple and elegant design. As a result, our kMaX-DeepLab achieves a new state-of-the-art performance on COCO val set with 58.0% PQ, and Cityscapes val set with 68.4% PQ, 44.0% AP, and 83.5% mIoU without test-time augmentation or external dataset. We hope our work can shed some light on designing transformers tailored for vision tasks. Code and models are available at https://github.com/google-research/deeplab2