 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Out-of-Distribution Detection with Class Ratio Estimation
Jun 08, 2022
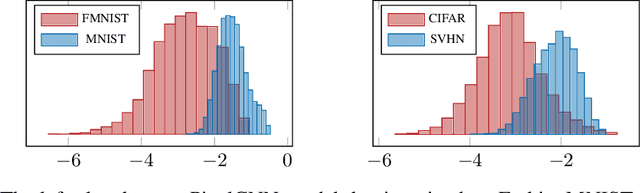
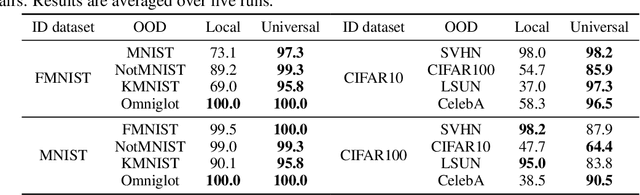
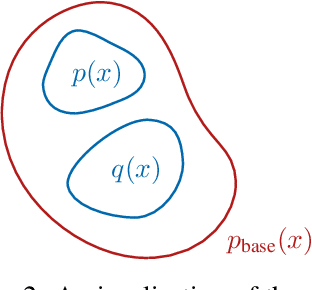
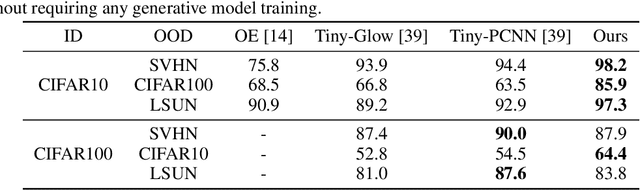
Density-based Out-of-distribution (OOD) detection has recently been shown unreliable for the task of detecting OOD images. Various density ratio based approaches achieve good empirical performance, however methods typically lack a principled probabilistic modelling explanation. In this work, we propose to unify density ratio based methods under a novel framework that builds energy-based models and employs differing base distributions. Under our framework, the density ratio can be viewed as the unnormalized density of an implicit semantic distribution. Further, we propose to directly estimate the density ratio of a data sample through class ratio estimation. We report competitive results on OOD image problems in comparison with recent work that alternatively requires training of deep generative models for the task. Our approach enables a simple and yet effective path towards solving the OOD detection problem.
Optical modelling of accommodative light field display system and prediction of human eye responses
Apr 02, 2022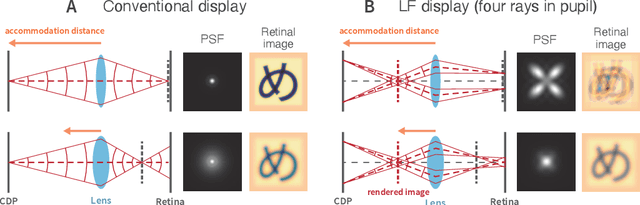
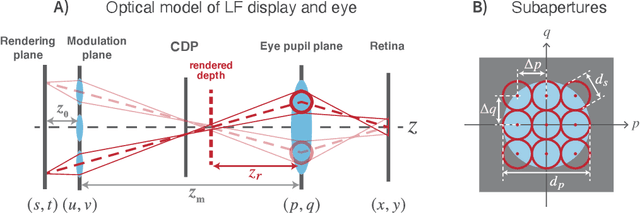
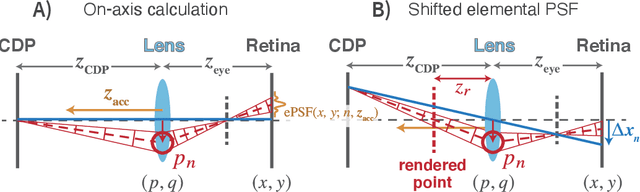
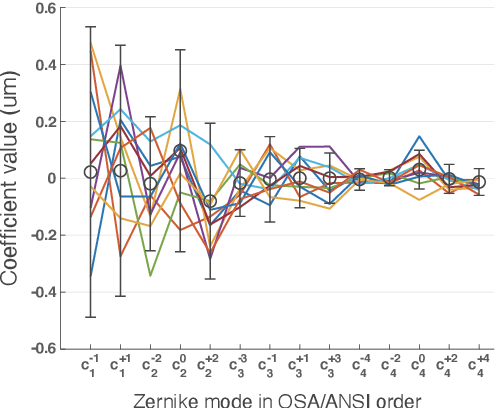
The spatio-angular resolution of a light field (LF) display is a crucial factor for delivering adequate spatial image quality and eliciting an accommodation response. Previous studies have modelled retinal image formation with an LF display and evaluated whether accommodation would be evoked correctly. The models were mostly based on ray-tracing and a schematic eye model, which pose computational complexity and inaccurately represent the human eye population's behaviour. We propose an efficient wave-optics-based framework to model the human eye and a general LF display. With the model, we simulated the retinal point spread function (PSF) of a point rendered by an LF display at various depths to characterise the retinal image quality. Additionally, accommodation responses to rendered LF images were estimated by computing the visual Strehl ratio based on the optical transfer function (VSOTF) from the PSFs. We assumed an ideal LF display that had an infinite spatial resolution and was free from optical aberrations in the simulation. We tested images rendered at 0--4 dioptres of depths having angular resolutions of up to 4x4 viewpoints within a pupil. The simulation predicted small and constant accommodation errors, which contradict the findings of previous studies. An evaluation of the optical resolution of the rendered retinal image suggested a trade-off between the maximum resolution achievable and the depth range of a rendered image where in-focus resolution is kept high. The proposed framework can be used to evaluate the upper bound of the optical performance of an LF display for realistically aberrated eyes, which may help to find an optimal spatio-angular resolution required to render a high quality 3D scene.
Recovering Private Text in Federated Learning of Language Models
May 17, 2022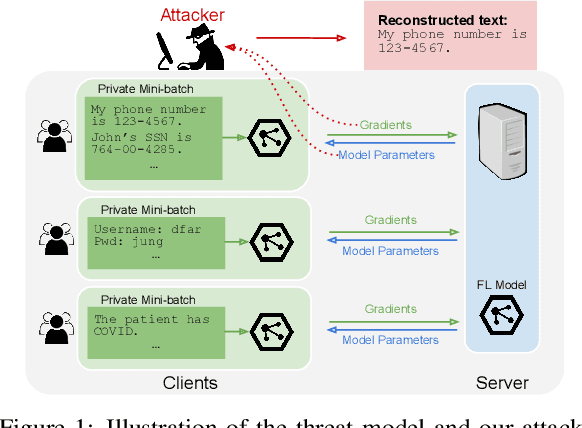
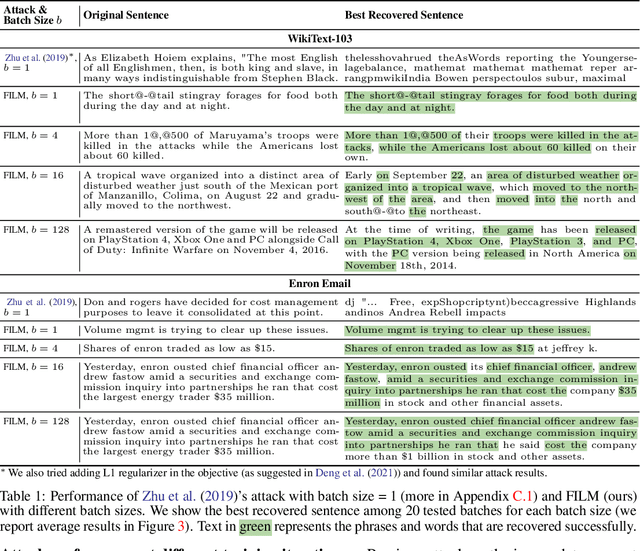
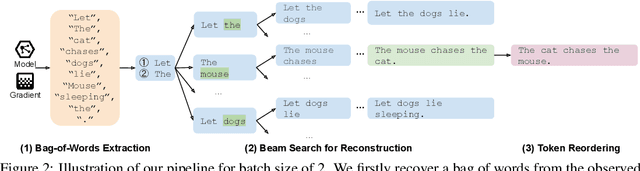

Federated learning allows distributed users to collaboratively train a model while keeping each user's data private. Recently, a growing body of work has demonstrated that an eavesdropping attacker can effectively recover image data from gradients transmitted during federated learning. However, little progress has been made in recovering text data. In this paper, we present a novel attack method FILM for federated learning of language models -- for the first time, we show the feasibility of recovering text from large batch sizes of up to 128 sentences. Different from image-recovery methods which are optimized to match gradients, we take a distinct approach that first identifies a set of words from gradients and then directly reconstructs sentences based on beam search and a prior-based reordering strategy. The key insight of our attack is to leverage either prior knowledge in pre-trained language models or memorization during training. Despite its simplicity, we demonstrate that FILM can work well with several large-scale datasets -- it can extract single sentences with high fidelity even for large batch sizes and recover multiple sentences from the batch successfully if the attack is applied iteratively. We hope our results can motivate future work in developing stronger attacks as well as new defense methods for training language models in federated learning. Our code is publicly available at https://github.com/Princeton-SysML/FILM.
Pseudo-Stereo for Monocular 3D Object Detection in Autonomous Driving
Mar 04, 2022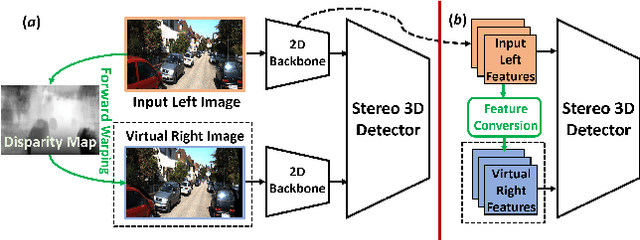
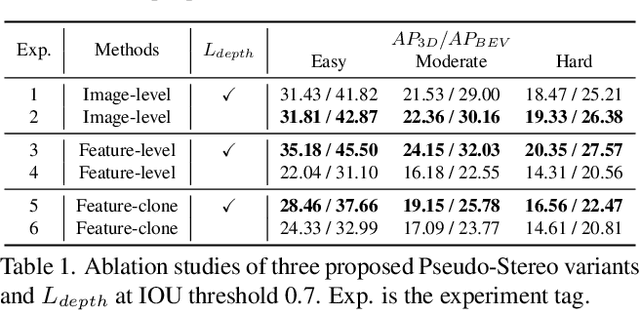
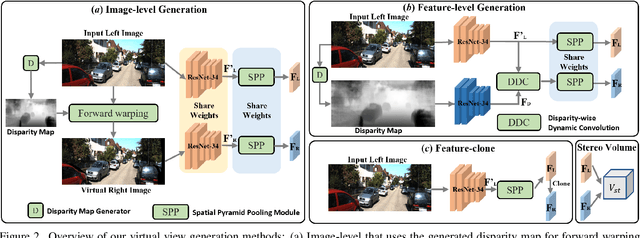
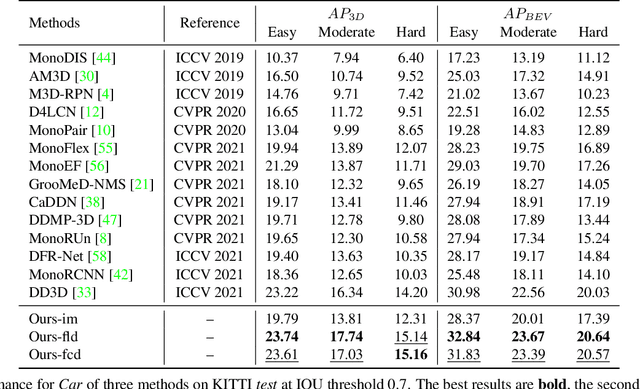
Pseudo-LiDAR 3D detectors have made remarkable progress in monocular 3D detection by enhancing the capability of perceiving depth with depth estimation networks, and using LiDAR-based 3D detection architectures. The advanced stereo 3D detectors can also accurately localize 3D objects. The gap in image-to-image generation for stereo views is much smaller than that in image-to-LiDAR generation. Motivated by this, we propose a Pseudo-Stereo 3D detection framework with three novel virtual view generation methods, including image-level generation, feature-level generation, and feature-clone, for detecting 3D objects from a single image. Our analysis of depth-aware learning shows that the depth loss is effective in only feature-level virtual view generation and the estimated depth map is effective in both image-level and feature-level in our framework. We propose a disparity-wise dynamic convolution with dynamic kernels sampled from the disparity feature map to filter the features adaptively from a single image for generating virtual image features, which eases the feature degradation caused by the depth estimation errors. Till submission (November 18, 2021), our Pseudo-Stereo 3D detection framework ranks 1st on car, pedestrian, and cyclist among the monocular 3D detectors with publications on the KITTI-3D benchmark. The code is released at https://github.com/revisitq/Pseudo-Stereo-3D.
ImPosIng: Implicit Pose Encoding for Efficient Camera Pose Estimation
May 05, 2022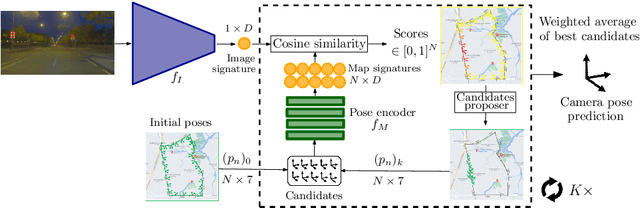
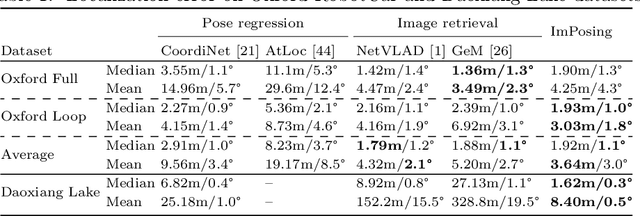


We propose a novel learning-based formulation for camera pose estimation that can perform relocalization accurately and in real-time in city-scale environments. Camera pose estimation algorithms determine the position and orientation from which an image has been captured, using a set of geo-referenced images or 3D scene representation. Our new localization paradigm, named Implicit Pose Encoding (ImPosing), embeds images and camera poses into a common latent representation with 2 separate neural networks, such that we can compute a similarity score for each image-pose pair. By evaluating candidates through the latent space in a hierarchical manner, the camera position and orientation are not directly regressed but incrementally refined. Compared to the representation used in structure-based relocalization methods, our implicit map is memory bounded and can be properly explored to improve localization performances against learning-based regression approaches. In this paper, we describe how to effectively optimize our learned modules, how to combine them to achieve real-time localization, and demonstrate results on diverse large scale scenarios that significantly outperform prior work in accuracy and computational efficiency.
RandStainNA: Learning Stain-Agnostic Features from Histology Slides by Bridging Stain Augmentation and Normalization
Jun 25, 2022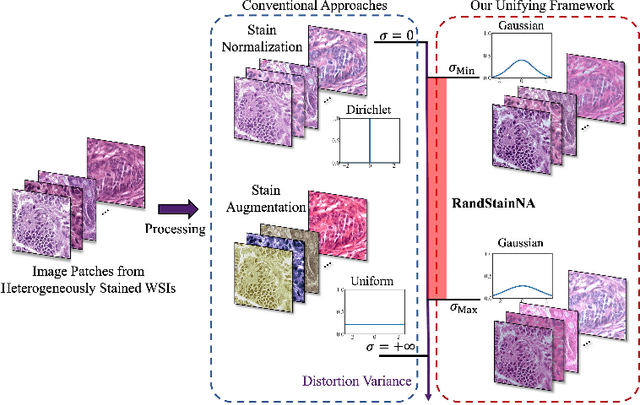
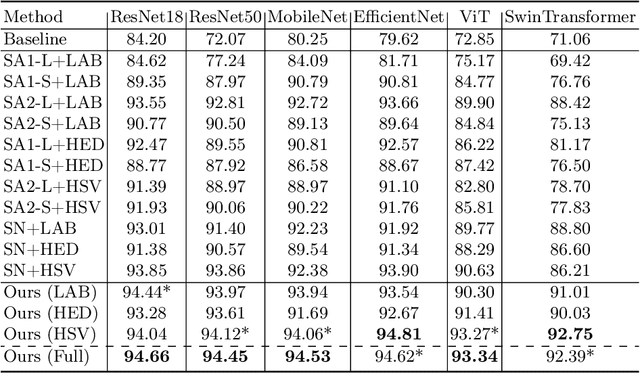
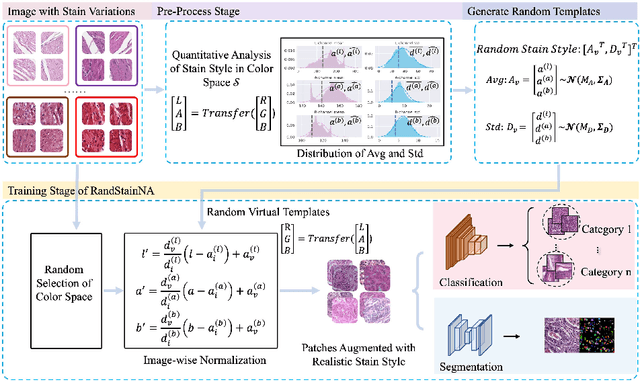

Stain variations often decrease the generalization ability of deep learning based approaches in digital histopathology analysis. Two separate proposals, namely stain normalization (SN) and stain augmentation (SA), have been spotlighted to reduce the generalization error, where the former alleviates the stain shift across different medical centers using template image and the latter enriches the accessible stain styles by the simulation of more stain variations. However, their applications are bounded by the selection of template images and the construction of unrealistic styles. To address the problems, we unify SN and SA with a novel RandStainNA scheme, which constrains variable stain styles in a practicable range to train a stain agnostic deep learning model. The RandStainNA is applicable to stain normalization in a collection of color spaces i.e. HED, HSV, LAB. Additionally, we propose a random color space selection scheme to gain extra performance improvement. We evaluate our method by two diagnostic tasks i.e. tissue subtype classification and nuclei segmentation, with various network backbones. The performance superiority over both SA and SN yields that the proposed RandStainNA can consistently improve the generalization ability, that our models can cope with more incoming clinical datasets with unpredicted stain styles. The codes is available at https://github.com/yiqings/RandStainNA.
Image2Gif: Generating Continuous Realistic Animations with Warping NODEs
May 09, 2022
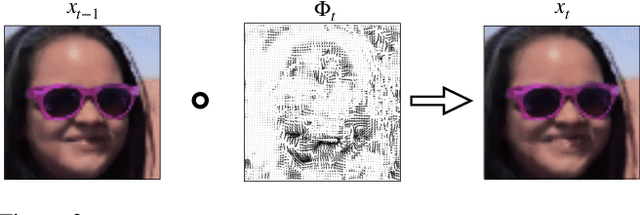
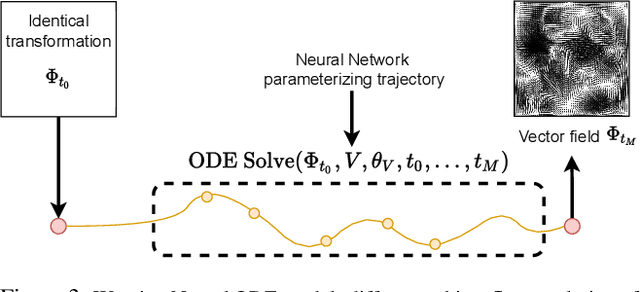
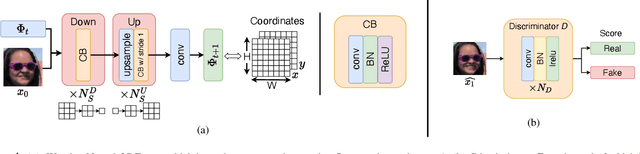
Generating smooth animations from a limited number of sequential observations has a number of applications in vision. For example, it can be used to increase number of frames per second, or generating a new trajectory only based on first and last frames, e.g. a motion of face emotions. Despite the discrete observed data (frames), the problem of generating a new trajectory is a continues problem. In addition, to be perceptually realistic, the domain of an image should not alter drastically through the trajectory of changes. In this paper, we propose a new framework, Warping Neural ODE, for generating a smooth animation (video frame interpolation) in a continuous manner, given two ("farther apart") frames, denoting the start and the end of the animation. The key feature of our framework is utilizing the continuous spatial transformation of the image based on the vector field, derived from a system of differential equations. This allows us to achieve the smoothness and the realism of an animation with infinitely small time steps between the frames. We show the application of our work in generating an animation given two frames, in different training settings, including Generative Adversarial Network (GAN) and with $L_2$ loss.
Biologically inspired deep residual networks for computer vision applications
May 05, 2022
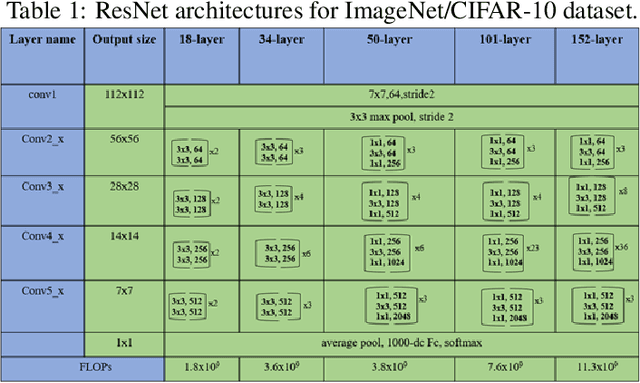

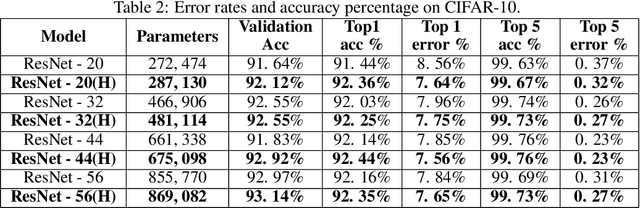
Deep neural network has been ensured as a key technology in the field of many challenging and vigorously researched computer vision tasks. Furthermore, classical ResNet is thought to be a state-of-the-art convolutional neural network (CNN) and was observed to capture features which can have good generalization ability. In this work, we propose a biologically inspired deep residual neural network where the hexagonal convolutions are introduced along the skip connections. The performance of different ResNet variants using square and hexagonal convolution are evaluated with the competitive training strategy mentioned by [1]. We show that the proposed approach advances the baseline image classification accuracy of vanilla ResNet architectures on CIFAR-10 and the same was observed over multiple subsets of the ImageNet 2012 dataset. We observed an average improvement by 1.35% and 0.48% on baseline top-1 accuracies for ImageNet 2012 and CIFAR-10, respectively. The proposed biologically inspired deep residual networks were observed to have improved generalized performance and this could be a potential research direction to improve the discriminative ability of state-of-the-art image classification networks.
Linear Revolution-Invariance: Modeling and Deblurring Spatially-Varying Imaging Systems
Jun 17, 2022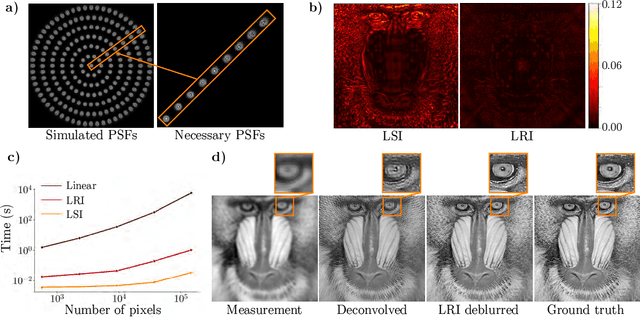
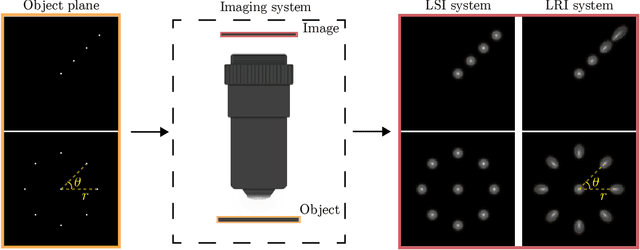
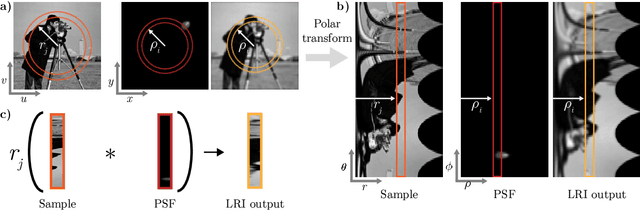
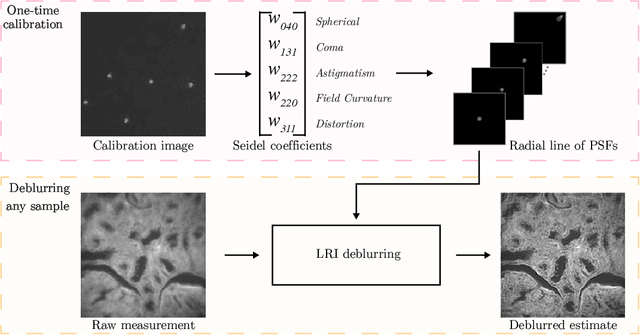
We develop theory and algorithms for modeling and deblurring imaging systems that are composed of rotationally-symmetric optics. Such systems have point spread functions (PSFs) which are spatially-varying, but only vary radially, a property we call linear revolution-invariance (LRI). From the LRI property we develop an exact theory for linear imaging with radially-varying optics, including an analog of the Fourier Convolution Theorem. This theory, in tandem with a calibration procedure using Seidel aberration coefficients, yields an efficient forward model and deblurring algorithm which requires only a single calibration image -- one that is easier to measure than a single PSF. We test these methods in simulation and experimentally on images of resolution targets, rabbit liver tissue, and live tardigrades obtained using the UCLA Miniscope v3. We find that the LRI forward model generates accurate radially-varying blur, and LRI deblurring improves resolution, especially near the edges of the field-of-view. These methods are available for use as a Python package at https://github.com/apsk14/lri.
AnoViT: Unsupervised Anomaly Detection and Localization with Vision Transformer-based Encoder-Decoder
Mar 21, 2022
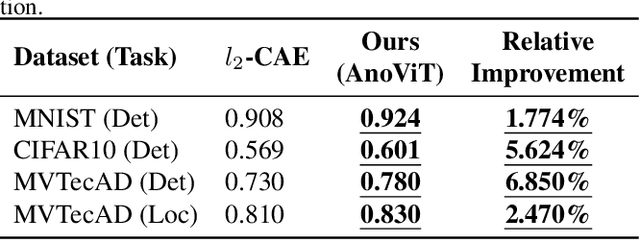
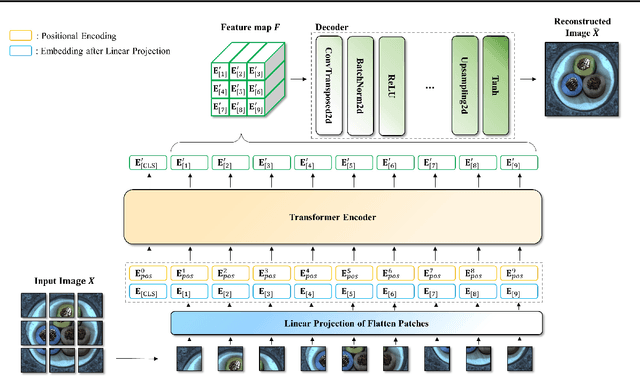
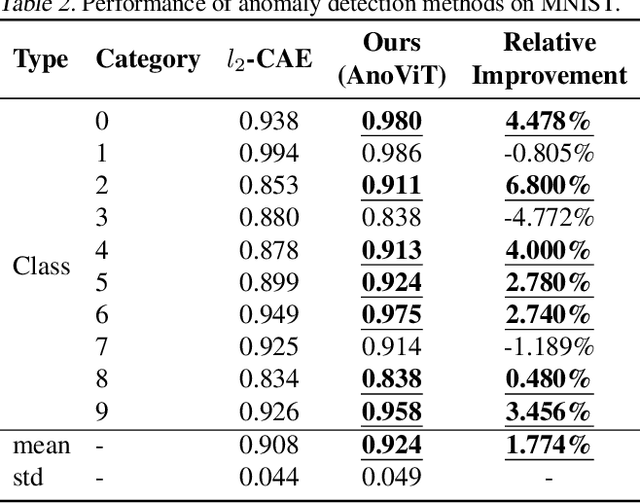
Image anomaly detection problems aim to determine whether an image is abnormal, and to detect anomalous areas. These methods are actively used in various fields such as manufacturing, medical care, and intelligent information. Encoder-decoder structures have been widely used in the field of anomaly detection because they can easily learn normal patterns in an unsupervised learning environment and calculate a score to identify abnormalities through a reconstruction error indicating the difference between input and reconstructed images. Therefore, current image anomaly detection methods have commonly used convolutional encoder-decoders to extract normal information through the local features of images. However, they are limited in that only local features of the image can be utilized when constructing a normal representation owing to the characteristics of convolution operations using a filter of fixed size. Therefore, we propose a vision transformer-based encoder-decoder model, named AnoViT, designed to reflect normal information by additionally learning the global relationship between image patches, which is capable of both image anomaly detection and localization. The proposed approach constructs a feature map that maintains the existing location information of individual patches by using the embeddings of all patches passed through multiple self-attention layers. The proposed AnoViT model performed better than the convolution-based model on three benchmark datasets. In MVTecAD, which is a representative benchmark dataset for anomaly localization, it showed improved results on 10 out of 15 classes compared with the baseline. Furthermore, the proposed method showed good performance regardless of the class and type of the anomalous area when localization results were evaluated qualitatively.