 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ExSinGAN: Learning an Explainable Generative Model from a Single Image
May 16, 2021

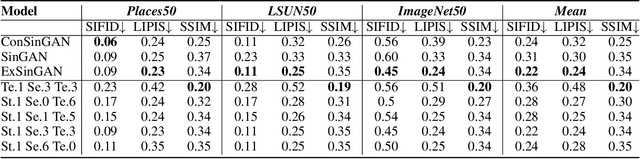
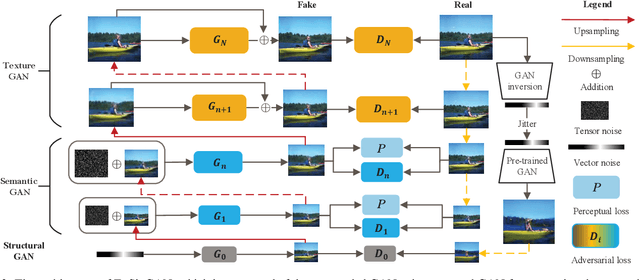
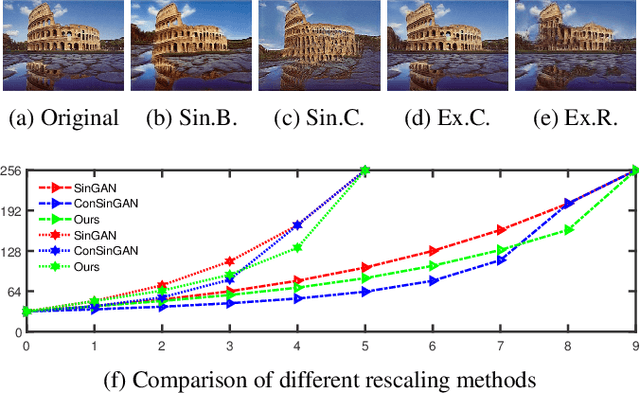
Generating images from a single sample, as a newly developing branch of image synthesis, has attracted extensive attention. In this paper, we formulate this problem as sampling from the conditional distribution of a single image, and propose a hierarchical framework that simplifies the learning of the intricate conditional distributions through the successive learning of the distributions about structure, semantics and texture, making the process of learning and generation comprehensible. On this basis, we design ExSinGAN composed of three cascaded GANs for learning an explainable generative model from a given image, where the cascaded GANs model the distributions about structure, semantics and texture successively. ExSinGAN is learned not only from the internal patches of the given image as the previous works did, but also from the external prior obtained by the GAN inversion technique. Benefiting from the appropriate combination of internal and external information, ExSinGAN has a more powerful capability of generation and competitive generalization ability for the image manipulation tasks compared with prior works.
Neural Transformers for Intraductal Papillary Mucosal Neoplasms (IPMN) Classification in MRI images
Jun 21, 2022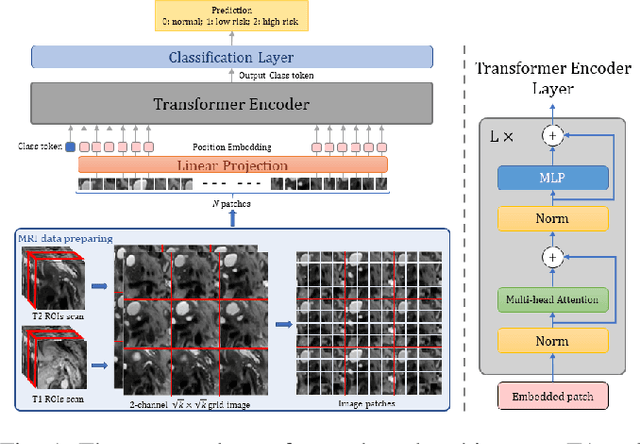
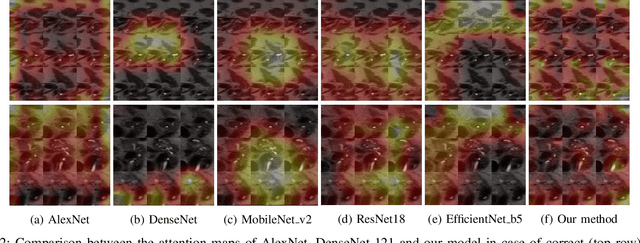
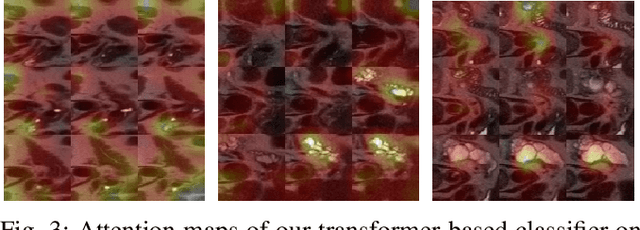
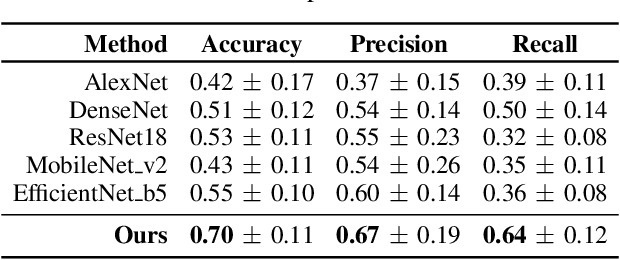
Early detection of precancerous cysts or neoplasms, i.e., Intraductal Papillary Mucosal Neoplasms (IPMN), in pancreas is a challenging and complex task, and it may lead to a more favourable outcome. Once detected, grading IPMNs accurately is also necessary, since low-risk IPMNs can be under surveillance program, while high-risk IPMNs have to be surgically resected before they turn into cancer. Current standards (Fukuoka and others) for IPMN classification show significant intra- and inter-operator variability, beside being error-prone, making a proper diagnosis unreliable. The established progress in artificial intelligence, through the deep learning paradigm, may provide a key tool for an effective support to medical decision for pancreatic cancer. In this work, we follow this trend, by proposing a novel AI-based IPMN classifier that leverages the recent success of transformer networks in generalizing across a wide variety of tasks, including vision ones. We specifically show that our transformer-based model exploits pre-training better than standard convolutional neural networks, thus supporting the sought architectural universalism of transformers in vision, including the medical image domain and it allows for a better interpretation of the obtained results.
Recovering Private Text in Federated Learning of Language Models
May 17, 2022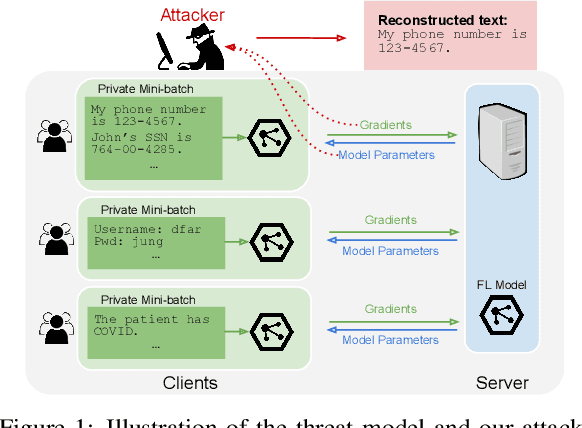
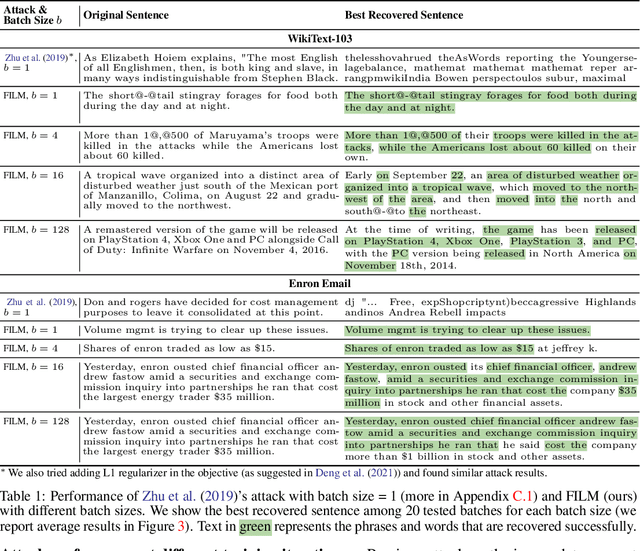
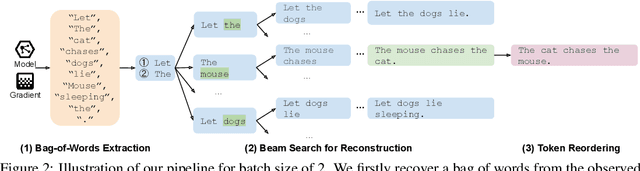

Federated learning allows distributed users to collaboratively train a model while keeping each user's data private. Recently, a growing body of work has demonstrated that an eavesdropping attacker can effectively recover image data from gradients transmitted during federated learning. However, little progress has been made in recovering text data. In this paper, we present a novel attack method FILM for federated learning of language models -- for the first time, we show the feasibility of recovering text from large batch sizes of up to 128 sentences. Different from image-recovery methods which are optimized to match gradients, we take a distinct approach that first identifies a set of words from gradients and then directly reconstructs sentences based on beam search and a prior-based reordering strategy. The key insight of our attack is to leverage either prior knowledge in pre-trained language models or memorization during training. Despite its simplicity, we demonstrate that FILM can work well with several large-scale datasets -- it can extract single sentences with high fidelity even for large batch sizes and recover multiple sentences from the batch successfully if the attack is applied iteratively. We hope our results can motivate future work in developing stronger attacks as well as new defense methods for training language models in federated learning. Our code is publicly available at https://github.com/Princeton-SysML/FILM.
Adapting CLIP For Phrase Localization Without Further Training
Apr 07, 2022
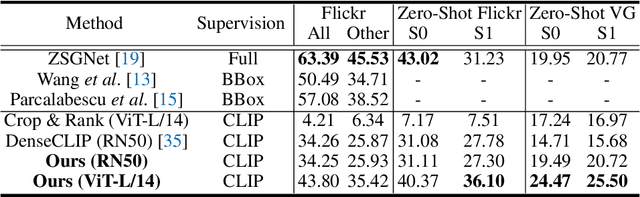
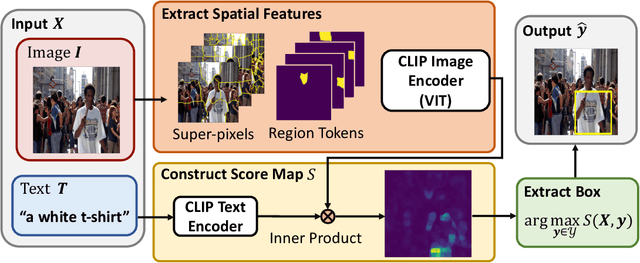
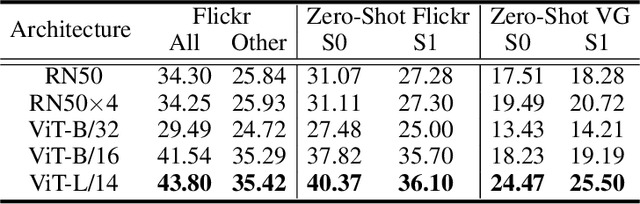
Supervised or weakly supervised methods for phrase localization (textual grounding) either rely on human annotations or some other supervised models, e.g., object detectors. Obtaining these annotations is labor-intensive and may be difficult to scale in practice. We propose to leverage recent advances in contrastive language-vision models, CLIP, pre-trained on image and caption pairs collected from the internet. In its original form, CLIP only outputs an image-level embedding without any spatial resolution. We adapt CLIP to generate high-resolution spatial feature maps. Importantly, we can extract feature maps from both ViT and ResNet CLIP model while maintaining the semantic properties of an image embedding. This provides a natural framework for phrase localization. Our method for phrase localization requires no human annotations or additional training. Extensive experiments show that our method outperforms existing no-training methods in zero-shot phrase localization, and in some cases, it even outperforms supervised methods. Code is available at https://github.com/pals-ttic/adapting-CLIP .
Learning Fair Representation via Distributional Contrastive Disentanglement
Jun 17, 2022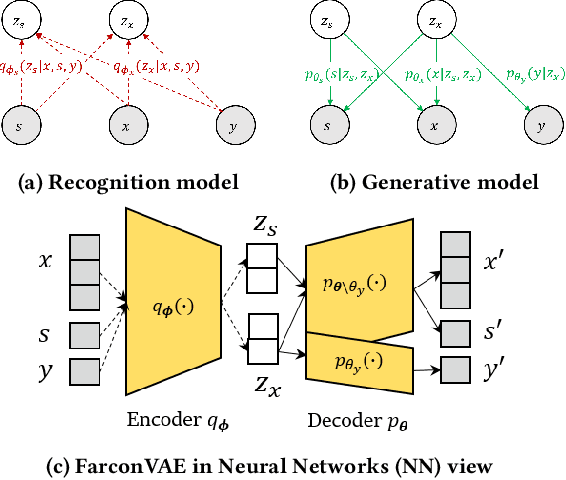
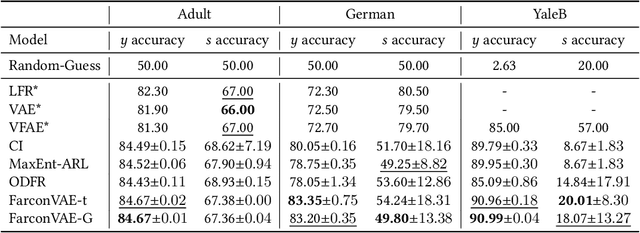
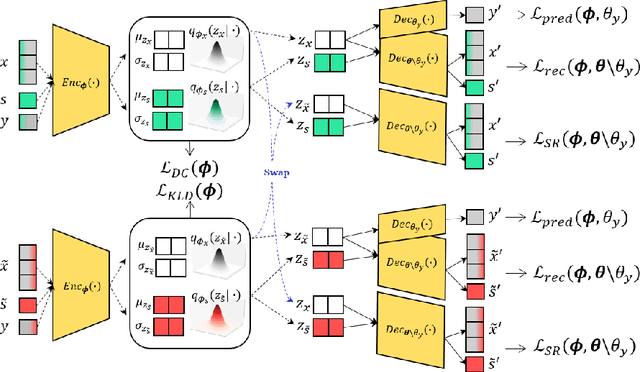
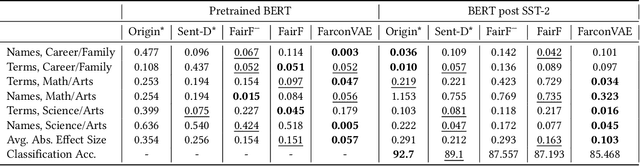
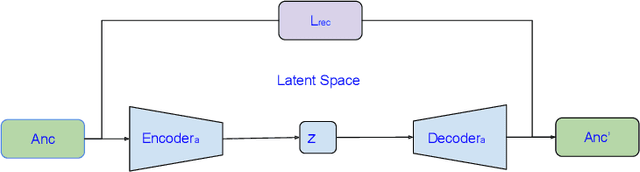
Learning fair representation is crucial for achieving fairness or debiasing sensitive information. Most existing works rely on adversarial representation learning to inject some invariance into representation. However, adversarial learning methods are known to suffer from relatively unstable training, and this might harm the balance between fairness and predictiveness of representation. We propose a new approach, learning FAir Representation via distributional CONtrastive Variational AutoEncoder (FarconVAE), which induces the latent space to be disentangled into sensitive and nonsensitive parts. We first construct the pair of observations with different sensitive attributes but with the same labels. Then, FarconVAE enforces each non-sensitive latent to be closer, while sensitive latents to be far from each other and also far from the non-sensitive latent by contrasting their distributions. We provide a new type of contrastive loss motivated by Gaussian and Student-t kernels for distributional contrastive learning with theoretical analysis. Besides, we adopt a new swap-reconstruction loss to boost the disentanglement further. FarconVAE shows superior performance on fairness, pretrained model debiasing, and domain generalization tasks from various modalities, including tabular, image, and text.
Contrastive Semantic Similarity Learning for Image Captioning Evaluation with Intrinsic Auto-encoder
Jun 29, 2021
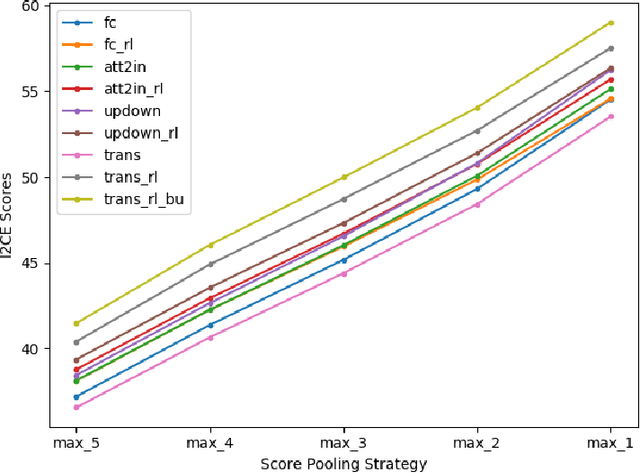
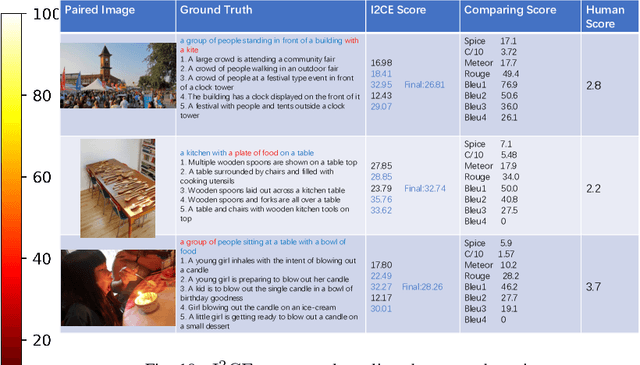
Automatically evaluating the quality of image captions can be very challenging since human language is quite flexible that there can be various expressions for the same meaning. Most of the current captioning metrics rely on token level matching between candidate caption and the ground truth label sentences. It usually neglects the sentence-level information. Motivated by the auto-encoder mechanism and contrastive representation learning advances, we propose a learning-based metric for image captioning, which we call Intrinsic Image Captioning Evaluation($I^2CE$). We develop three progressive model structures to learn the sentence level representations--single branch model, dual branches model, and triple branches model. Our empirical tests show that $I^2CE$ trained with dual branches structure achieves better consistency with human judgments to contemporary image captioning evaluation metrics. Furthermore, We select several state-of-the-art image captioning models and test their performances on the MS COCO dataset concerning both contemporary metrics and the proposed $I^2CE$. Experiment results show that our proposed method can align well with the scores generated from other contemporary metrics. On this concern, the proposed metric could serve as a novel indicator of the intrinsic information between captions, which may be complementary to the existing ones.
UNIT-DDPM: UNpaired Image Translation with Denoising Diffusion Probabilistic Models
Apr 12, 2021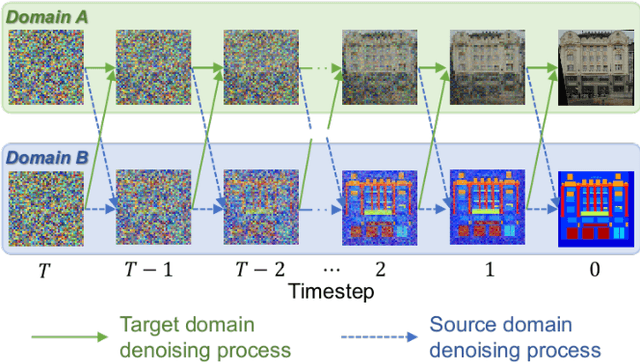
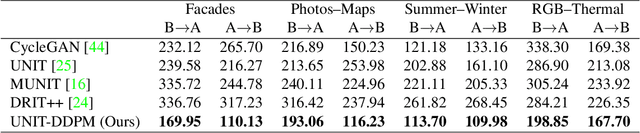
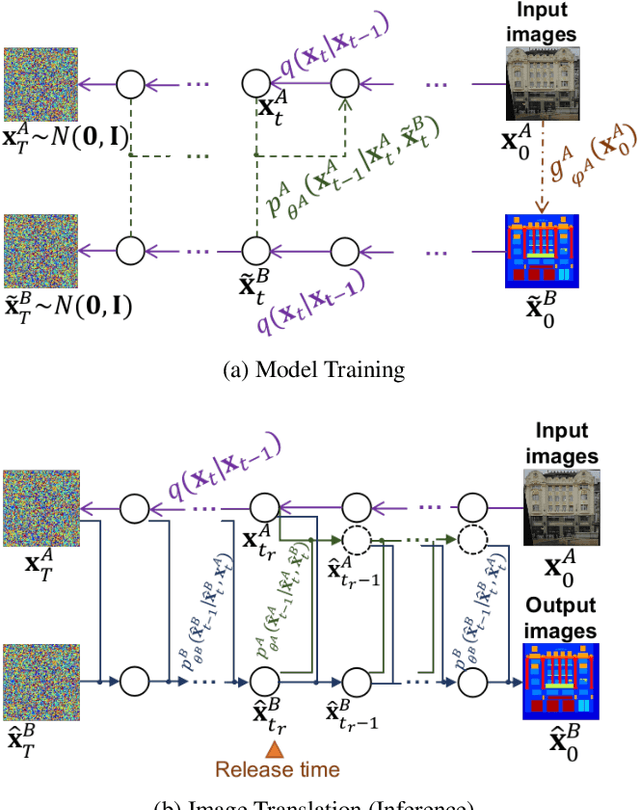

We propose a novel unpaired image-to-image translation method that uses denoising diffusion probabilistic models without requiring adversarial training. Our method, UNpaired Image Translation with Denoising Diffusion Probabilistic Models (UNIT-DDPM), trains a generative model to infer the joint distribution of images over both domains as a Markov chain by minimising a denoising score matching objective conditioned on the other domain. In particular, we update both domain translation models simultaneously, and we generate target domain images by a denoising Markov Chain Monte Carlo approach that is conditioned on the input source domain images, based on Langevin dynamics. Our approach provides stable model training for image-to-image translation and generates high-quality image outputs. This enables state-of-the-art Fr\'echet Inception Distance (FID) performance on several public datasets, including both colour and multispectral imagery, significantly outperforming the contemporary adversarial image-to-image translation methods.
Exploring Separable Attention for Multi-Contrast MR Image Super-Resolution
Sep 03, 2021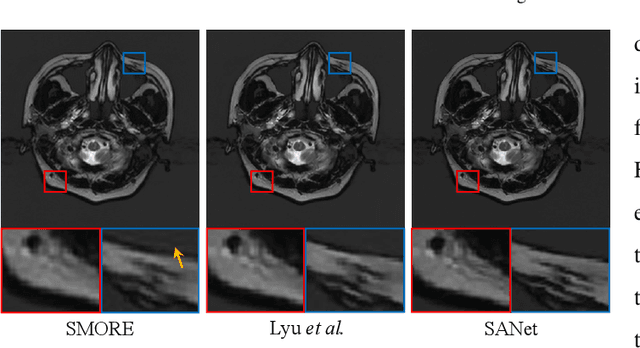
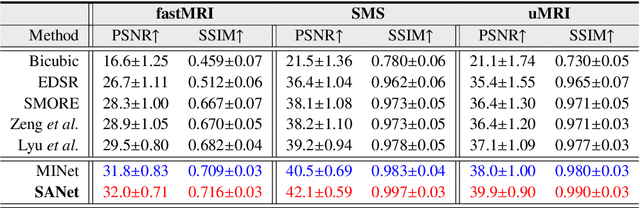
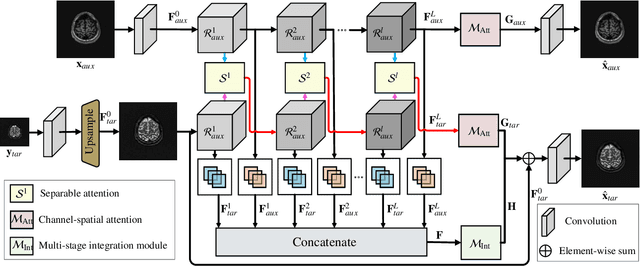
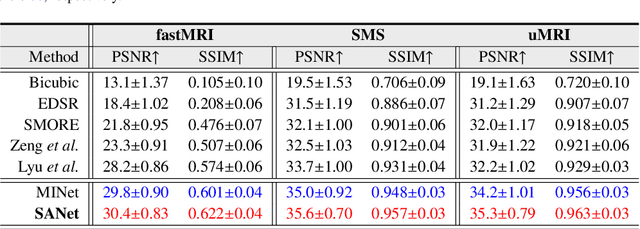
Super-resolving the Magnetic Resonance (MR) image of a target contrast under the guidance of the corresponding auxiliary contrast, which provides additional anatomical information, is a new and effective solution for fast MR imaging. However, current multi-contrast super-resolution (SR) methods tend to concatenate different contrasts directly, ignoring their relationships in different clues, \eg, in the foreground and background. In this paper, we propose a separable attention network (comprising a foreground priority attention and background separation attention), named SANet. Our method can explore the foreground and background areas in the forward and reverse directions with the help of the auxiliary contrast, enabling it to learn clearer anatomical structures and edge information for the SR of a target-contrast MR image. SANet provides three appealing benefits: (1) It is the first model to explore a separable attention mechanism that uses the auxiliary contrast to predict the foreground and background regions, diverting more attention to refining any uncertain details between these regions and correcting the fine areas in the reconstructed results. (2) A multi-stage integration module is proposed to learn the response of multi-contrast fusion at different stages, obtain the dependency between the fused features, and improve their representation ability. (3) Extensive experiments with various state-of-the-art multi-contrast SR methods on fastMRI and clinical \textit{in vivo} datasets demonstrate the superiority of our model.
Localized adversarial artifacts for compressed sensing MRI
Jun 10, 2022


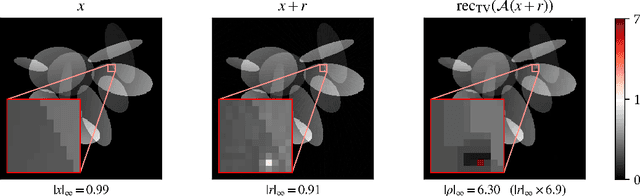
As interest in deep neural networks (DNNs) for image reconstruction tasks grows, their reliability has been called into question (Antun et al., 2020; Gottschling et al., 2020). However, recent work has shown that compared to total variation (TV) minimization, they show similar robustness to adversarial noise in terms of $\ell^2$-reconstruction error (Genzel et al., 2022). We consider a different notion of robustness, using the $\ell^\infty$-norm, and argue that localized reconstruction artifacts are a more relevant defect than the $\ell^2$-error. We create adversarial perturbations to undersampled MRI measurements which induce severe localized artifacts in the TV-regularized reconstruction. The same attack method is not as effective against DNN based reconstruction. Finally, we show that this phenomenon is inherent to reconstruction methods for which exact recovery can be guaranteed, as with compressed sensing reconstructions with $\ell^1$- or TV-minimization.
Dynamic Spatial Sparsification for Efficient Vision Transformers and Convolutional Neural Networks
Jul 04, 2022
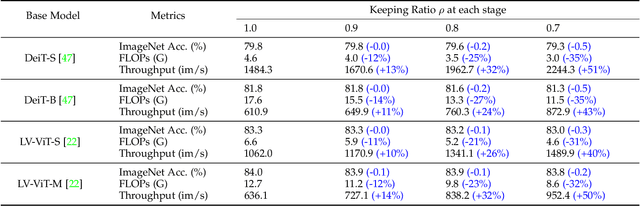
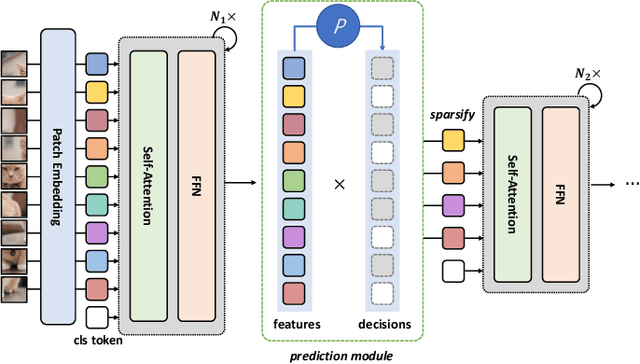
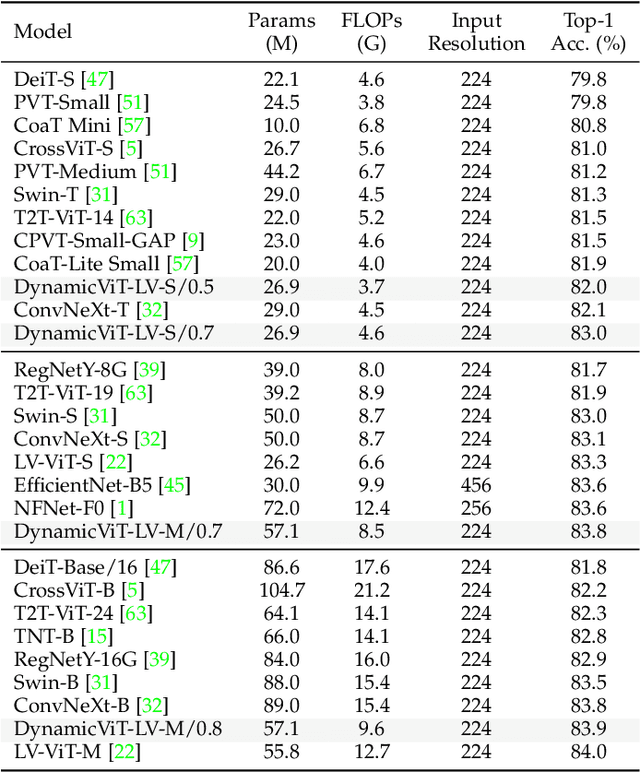
In this paper, we present a new approach for model acceleration by exploiting spatial sparsity in visual data. We observe that the final prediction in vision Transformers is only based on a subset of the most informative tokens, which is sufficient for accurate image recognition. Based on this observation, we propose a dynamic token sparsification framework to prune redundant tokens progressively and dynamically based on the input to accelerate vision Transformers. Specifically, we devise a lightweight prediction module to estimate the importance score of each token given the current features. The module is added to different layers to prune redundant tokens hierarchically. While the framework is inspired by our observation of the sparse attention in vision Transformers, we find the idea of adaptive and asymmetric computation can be a general solution for accelerating various architectures. We extend our method to hierarchical models including CNNs and hierarchical vision Transformers as well as more complex dense prediction tasks that require structured feature maps by formulating a more generic dynamic spatial sparsification framework with progressive sparsification and asymmetric computation for different spatial locations. By applying lightweight fast paths to less informative features and using more expressive slow paths to more important locations, we can maintain the structure of feature maps while significantly reducing the overall computations. Extensive experiments demonstrate the effectiveness of our framework on various modern architectures and different visual recognition tasks. Our results clearly demonstrate that dynamic spatial sparsification offers a new and more effective dimension for model acceleration. Code is available at https://github.com/raoyongming/DynamicViT