 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ARTEMIS: Attention-based Retrieval with Text-Explicit Matching and Implicit Similarity
Mar 15, 2022

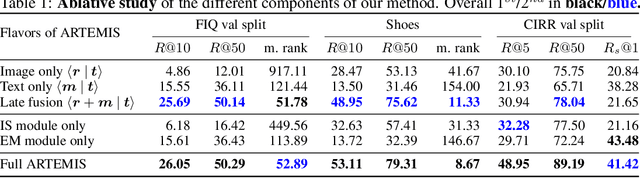
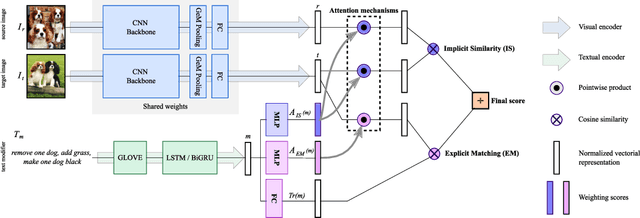
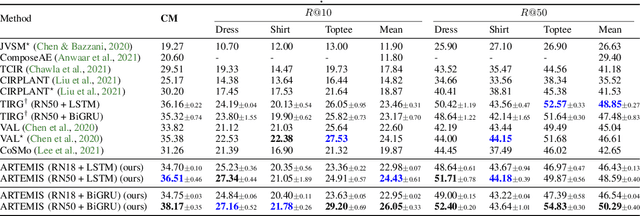
An intuitive way to search for images is to use queries composed of an example image and a complementary text. While the first provides rich and implicit context for the search, the latter explicitly calls for new traits, or specifies how some elements of the example image should be changed to retrieve the desired target image. Current approaches typically combine the features of each of the two elements of the query into a single representation, which can then be compared to the ones of the potential target images. Our work aims at shedding new light on the task by looking at it through the prism of two familiar and related frameworks: text-to-image and image-to-image retrieval. Taking inspiration from them, we exploit the specific relation of each query element with the targeted image and derive light-weight attention mechanisms which enable to mediate between the two complementary modalities. We validate our approach on several retrieval benchmarks, querying with images and their associated free-form text modifiers. Our method obtains state-of-the-art results without resorting to side information, multi-level features, heavy pre-training nor large architectures as in previous works.
Reuse your features: unifying retrieval and feature-metric alignment
Apr 13, 2022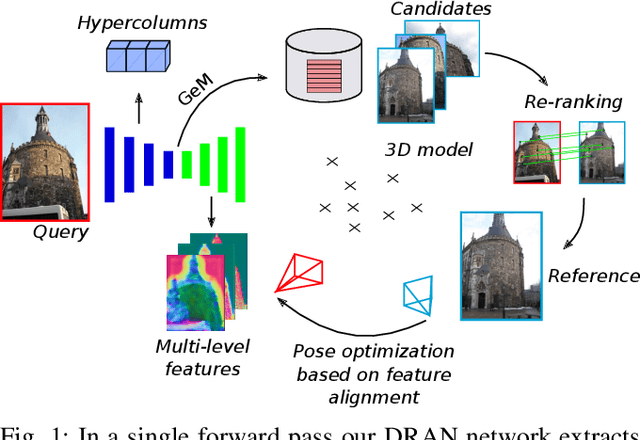
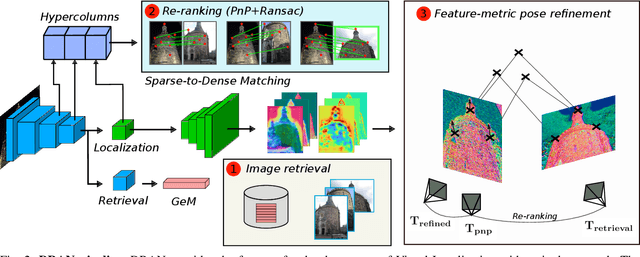
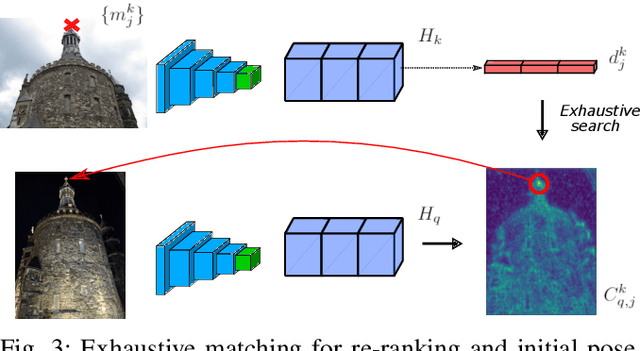
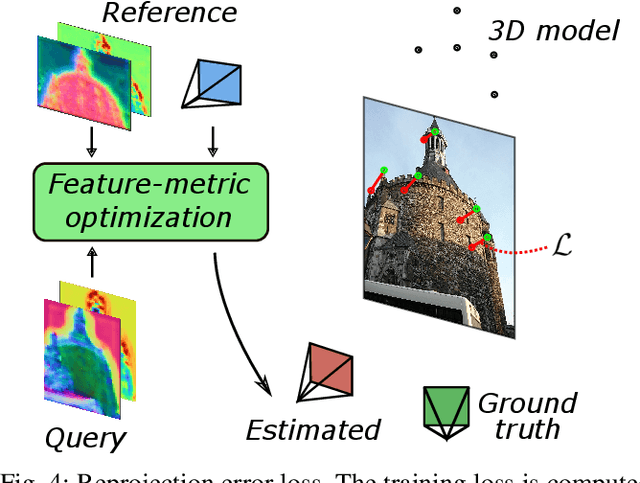
We propose a compact pipeline to unify all the steps of Visual Localization: image retrieval, candidate re-ranking and initial pose estimation, and camera pose refinement. Our key assumption is that the deep features used for these individual tasks share common characteristics, so we should reuse them in all the procedures of the pipeline. Our DRAN (Deep Retrieval and image Alignment Network) is able to extract global descriptors for efficient image retrieval, use intermediate hierarchical features to re-rank the retrieval list and produce an intial pose guess, which is finally refined by means of a feature-metric optimization based on learned deep multi-scale dense features. DRAN is the first single network able to produce the features for the three steps of visual localization. DRAN achieves a competitive performance in terms of robustness and accuracy specially in extreme day-night changes.
k-strip: A novel segmentation algorithm in k-space for the application of skull stripping
May 19, 2022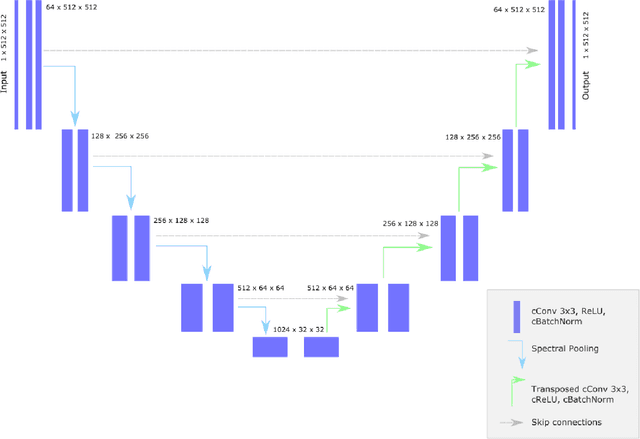
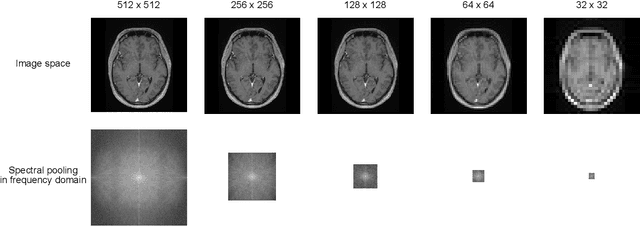
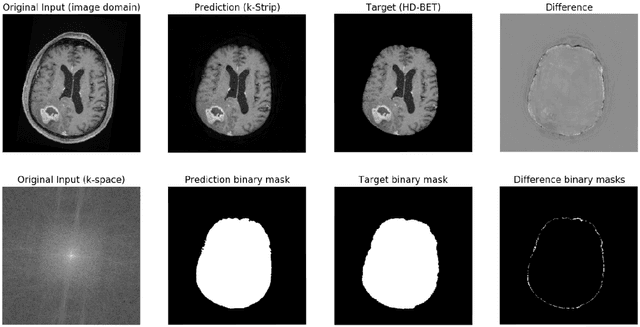
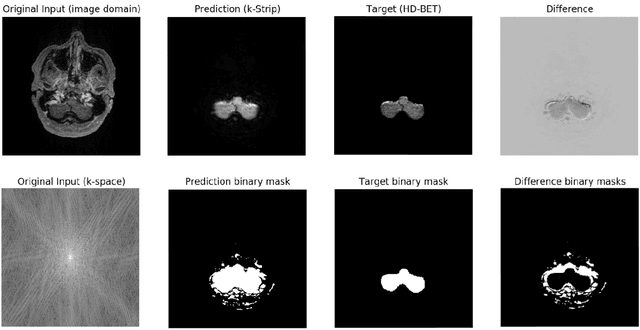
Objectives: Present a novel deep learning-based skull stripping algorithm for magnetic resonance imaging (MRI) that works directly in the information rich k-space. Materials and Methods: Using two datasets from different institutions with a total of 36,900 MRI slices, we trained a deep learning-based model to work directly with the complex raw k-space data. Skull stripping performed by HD-BET (Brain Extraction Tool) in the image domain were used as the ground truth. Results: Both datasets were very similar to the ground truth (DICE scores of 92\%-98\% and Hausdorff distances of under 5.5 mm). Results on slices above the eye-region reach DICE scores of up to 99\%, while the accuracy drops in regions around the eyes and below, with partially blurred output. The output of k-strip often smoothed edges at the demarcation to the skull. Binary masks are created with an appropriate threshold. Conclusion: With this proof-of-concept study, we were able to show the feasibility of working in the k-space frequency domain, preserving phase information, with consistent results. Future research should be dedicated to discovering additional ways the k-space can be used for innovative image analysis and further workflows.
Progressive Class-based Expansion Learning For Image Classification
Jun 28, 2021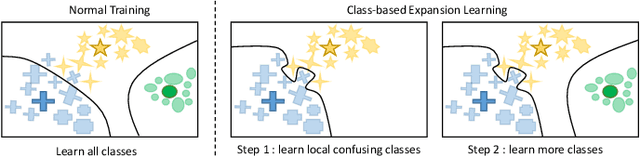
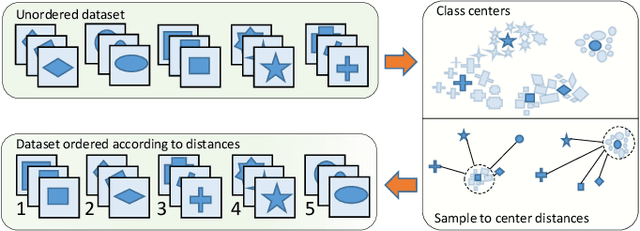
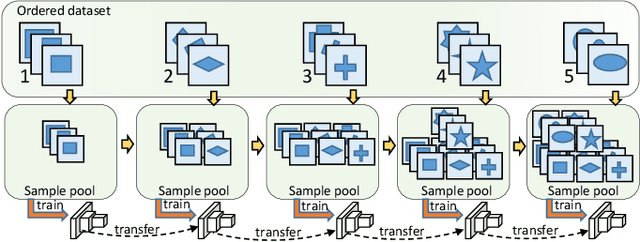
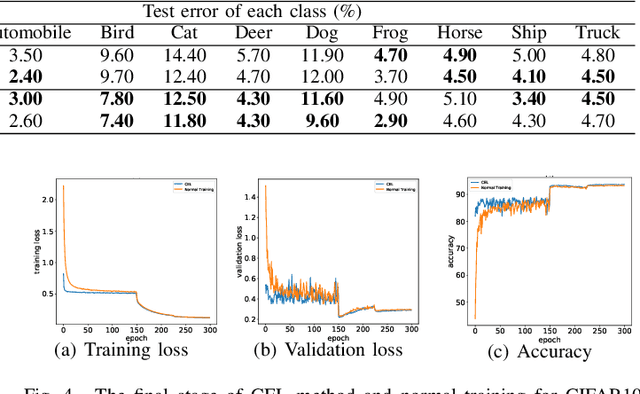
In this paper, we propose a novel image process scheme called class-based expansion learning for image classification, which aims at improving the supervision-stimulation frequency for the samples of the confusing classes. Class-based expansion learning takes a bottom-up growing strategy in a class-based expansion optimization fashion, which pays more attention to the quality of learning the fine-grained classification boundaries for the preferentially selected classes. Besides, we develop a class confusion criterion to select the confusing class preferentially for training. In this way, the classification boundaries of the confusing classes are frequently stimulated, resulting in a fine-grained form. Experimental results demonstrate the effectiveness of the proposed scheme on several benchmarks.
Abs-CAM: A Gradient Optimization Interpretable Approach for Explanation of Convolutional Neural Networks
Jul 08, 2022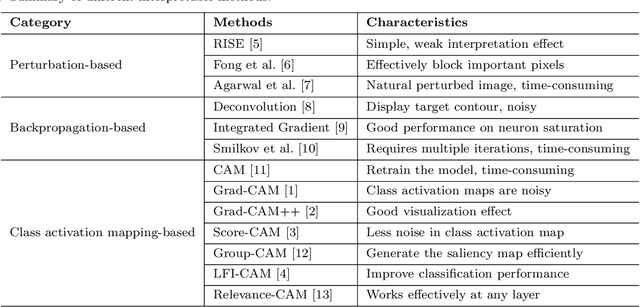
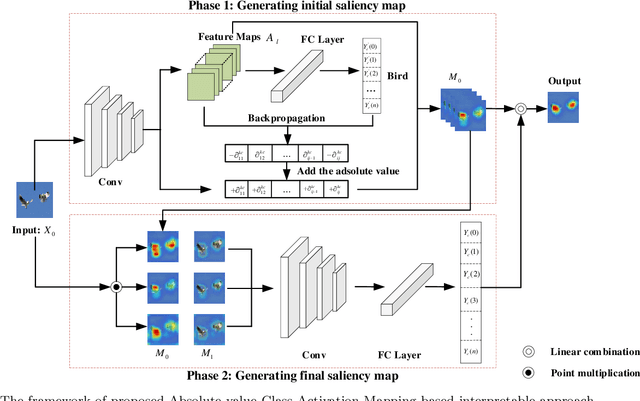
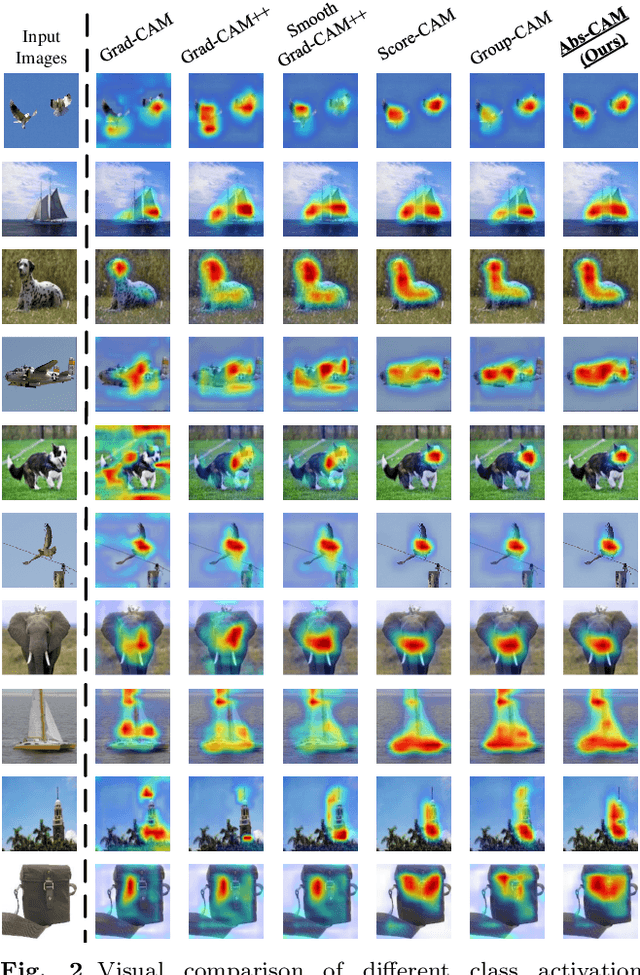
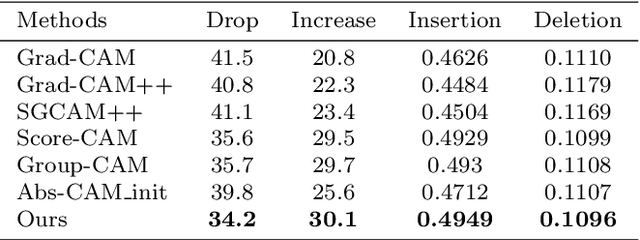
The black-box nature of Deep Neural Networks (DNNs) severely hinders its performance improvement and application in specific scenes. In recent years, class activation mapping-based method has been widely used to interpret the internal decisions of models in computer vision tasks. However, when this method uses backpropagation to obtain gradients, it will cause noise in the saliency map, and even locate features that are irrelevant to decisions. In this paper, we propose an Absolute value Class Activation Mapping-based (Abs-CAM) method, which optimizes the gradients derived from the backpropagation and turns all of them into positive gradients to enhance the visual features of output neurons' activation, and improve the localization ability of the saliency map. The framework of Abs-CAM is divided into two phases: generating initial saliency map and generating final saliency map. The first phase improves the localization ability of the saliency map by optimizing the gradient, and the second phase linearly combines the initial saliency map with the original image to enhance the semantic information of the saliency map. We conduct qualitative and quantitative evaluation of the proposed method, including Deletion, Insertion, and Pointing Game. The experimental results show that the Abs-CAM can obviously eliminate the noise in the saliency map, and can better locate the features related to decisions, and is superior to the previous methods in recognition and localization tasks.
Fused Deep Neural Network based Transfer Learning in Occluded Face Classification and Person re-Identification
May 15, 2022

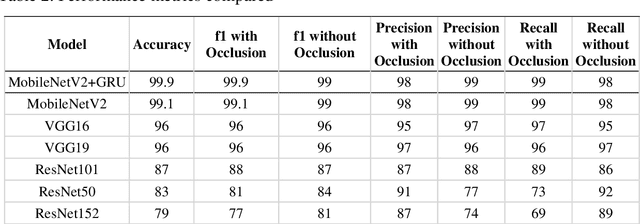
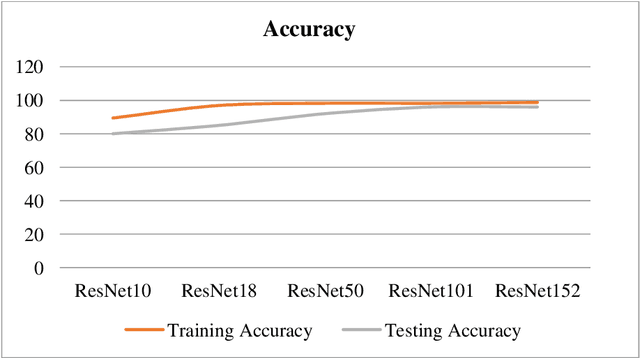
Recent period of pandemic has brought person identification even with occluded face image a great importance with increased number of mask usage. This paper aims to recognize the occlusion of one of four types in face images. Various transfer learning methods were tested, and the results show that MobileNet V2 with Gated Recurrent Unit(GRU) performs better than any other Transfer Learning methods, with a perfect accuracy of 99% in classification of images as with or without occlusion and if with occlusion, then the type of occlusion. In parallel, identifying the Region of interest from the device captured image is done. This extracted Region of interest is utilised in face identification. Such a face identification process is done using the ResNet model with its Caffe implementation. To reduce the execution time, after the face occlusion type was recognized the person was searched to confirm their face image in the registered database. The face label of the person obtained from both simultaneous processes was verified for their matching score. If the matching score was above 90, the recognized label of the person was logged into a file with their name, type of mask, date, and time of recognition. MobileNetV2 is a lightweight framework which can also be used in embedded or IoT devices to perform real time detection and identification in suspicious areas of investigations using CCTV footages. When MobileNetV2 was combined with GRU, a reliable accuracy was obtained. The data provided in the paper belong to two categories, being either collected from Google Images for occlusion classification, face recognition, and facial landmarks, or collected in fieldwork. The motive behind this research is to identify and log person details which could serve surveillance activities in society-based e-governance.
Robust Deep Neural Object Detection and Segmentation for Automotive Driving Scenario with Compressed Image Data
May 13, 2022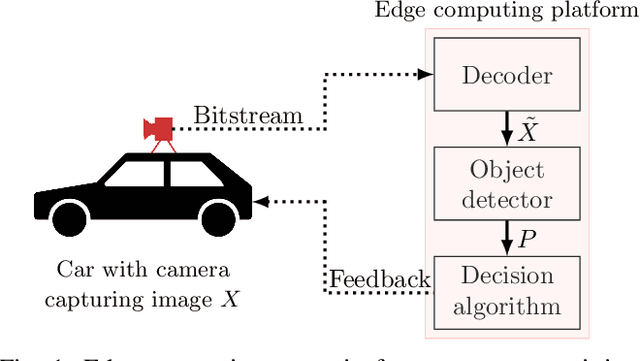
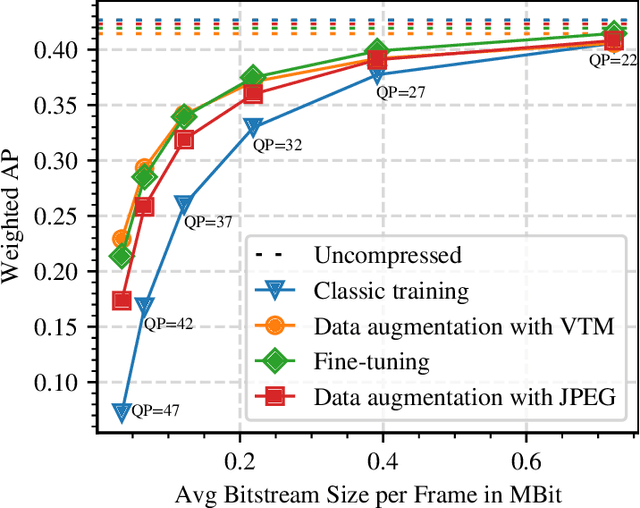


Deep neural object detection or segmentation networks are commonly trained with pristine, uncompressed data. However, in practical applications the input images are usually deteriorated by compression that is applied to efficiently transmit the data. Thus, we propose to add deteriorated images to the training process in order to increase the robustness of the two state-of-the-art networks Faster and Mask R-CNN. Throughout our paper, we investigate an autonomous driving scenario by evaluating the newly trained models on the Cityscapes dataset that has been compressed with the upcoming video coding standard Versatile Video Coding (VVC). When employing the models that have been trained with the proposed method, the weighted average precision of the R-CNNs can be increased by up to 3.68 percentage points for compressed input images, which corresponds to bitrate savings of nearly 48 %.
* Originally submitted at IEEE ISCAS 2021
Hierarchical Latent Structure for Multi-Modal Vehicle Trajectory Forecasting
Jul 11, 2022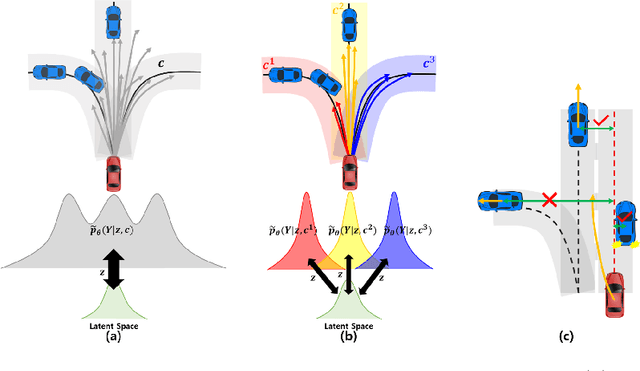

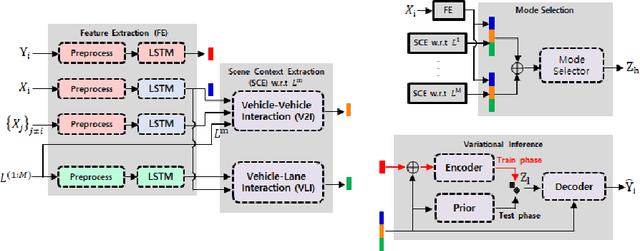
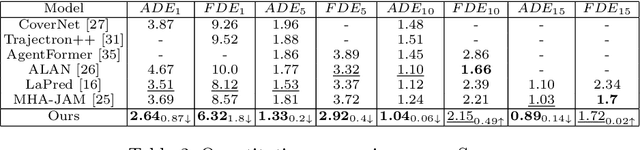
Variational autoencoder (VAE) has widely been utilized for modeling data distributions because it is theoretically elegant, easy to train, and has nice manifold representations. However, when applied to image reconstruction and synthesis tasks, VAE shows the limitation that the generated sample tends to be blurry. We observe that a similar problem, in which the generated trajectory is located between adjacent lanes, often arises in VAE-based trajectory forecasting models. To mitigate this problem, we introduce a hierarchical latent structure into the VAE-based forecasting model. Based on the assumption that the trajectory distribution can be approximated as a mixture of simple distributions (or modes), the low-level latent variable is employed to model each mode of the mixture and the high-level latent variable is employed to represent the weights for the modes. To model each mode accurately, we condition the low-level latent variable using two lane-level context vectors computed in novel ways, one corresponds to vehicle-lane interaction and the other to vehicle-vehicle interaction. The context vectors are also used to model the weights via the proposed mode selection network. To evaluate our forecasting model, we use two large-scale real-world datasets. Experimental results show that our model is not only capable of generating clear multi-modal trajectory distributions but also outperforms the state-of-the-art (SOTA) models in terms of prediction accuracy. Our code is available at https://github.com/d1024choi/HLSTrajForecast.
Uformer: A General U-Shaped Transformer for Image Restoration
Jun 06, 2021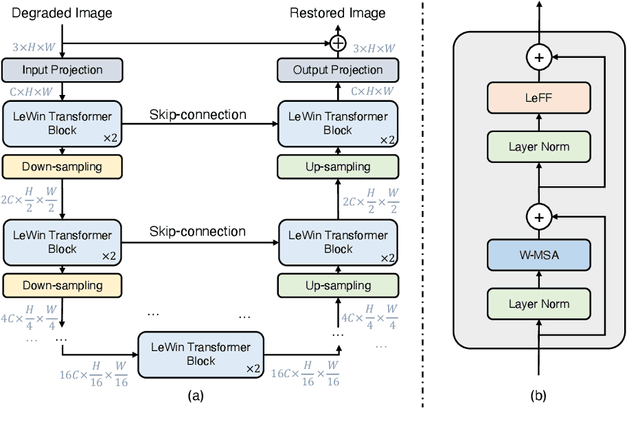
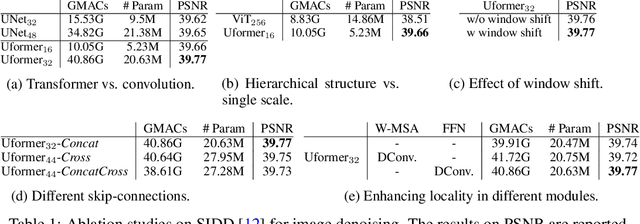
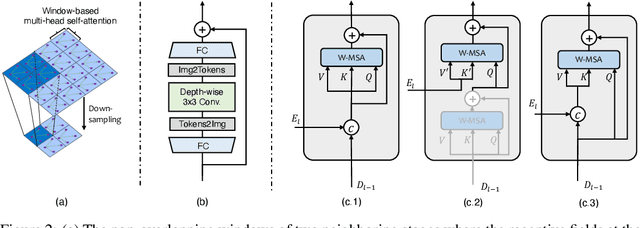
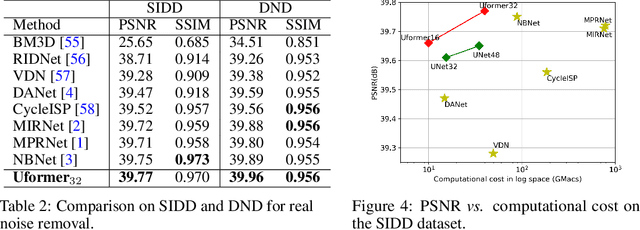
In this paper, we present Uformer, an effective and efficient Transformer-based architecture, in which we build a hierarchical encoder-decoder network using the Transformer block for image restoration. Uformer has two core designs to make it suitable for this task. The first key element is a local-enhanced window Transformer block, where we use non-overlapping window-based self-attention to reduce the computational requirement and employ the depth-wise convolution in the feed-forward network to further improve its potential for capturing local context. The second key element is that we explore three skip-connection schemes to effectively deliver information from the encoder to the decoder. Powered by these two designs, Uformer enjoys a high capability for capturing useful dependencies for image restoration. Extensive experiments on several image restoration tasks demonstrate the superiority of Uformer, including image denoising, deraining, deblurring and demoireing. We expect that our work will encourage further research to explore Transformer-based architectures for low-level vision tasks. The code and models will be available at https://github.com/ZhendongWang6/Uformer.
Rethinking Surgical Captioning: End-to-End Window-Based MLP Transformer Using Patches
Jun 30, 2022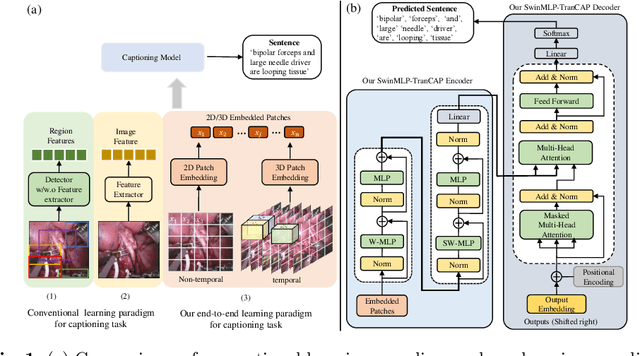
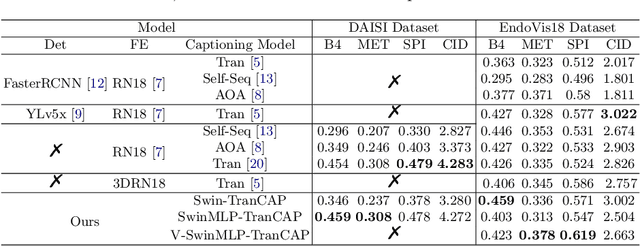
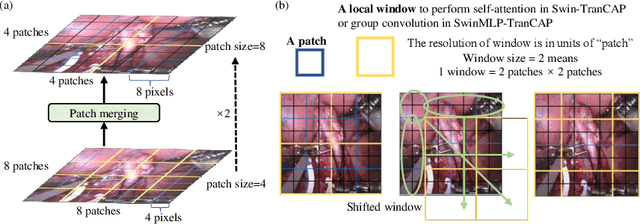
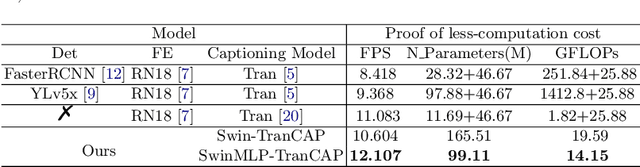
Surgical captioning plays an important role in surgical instruction prediction and report generation. However, the majority of captioning models still rely on the heavy computational object detector or feature extractor to extract regional features. In addition, the detection model requires additional bounding box annotation which is costly and needs skilled annotators. These lead to inference delay and limit the captioning model to deploy in real-time robotic surgery. For this purpose, we design an end-to-end detector and feature extractor-free captioning model by utilizing the patch-based shifted window technique. We propose Shifted Window-Based Multi-Layer Perceptrons Transformer Captioning model (SwinMLP-TranCAP) with faster inference speed and less computation. SwinMLP-TranCAP replaces the multi-head attention module with window-based multi-head MLP. Such deployments primarily focus on image understanding tasks, but very few works investigate the caption generation task. SwinMLP-TranCAP is also extended into a video version for video captioning tasks using 3D patches and windows. Compared with previous detector-based or feature extractor-based models, our models greatly simplify the architecture design while maintaining performance on two surgical datasets. The code is publicly available at https://github.com/XuMengyaAmy/SwinMLP_TranCAP.