 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Supervised Depth Estimation with Isometric-Self-Sample-Based Learning
May 20, 2022
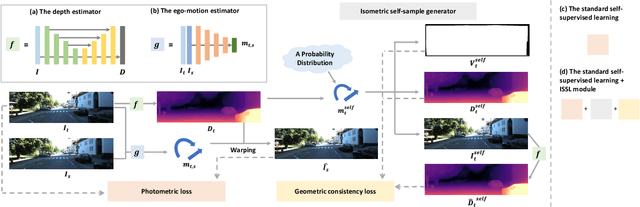
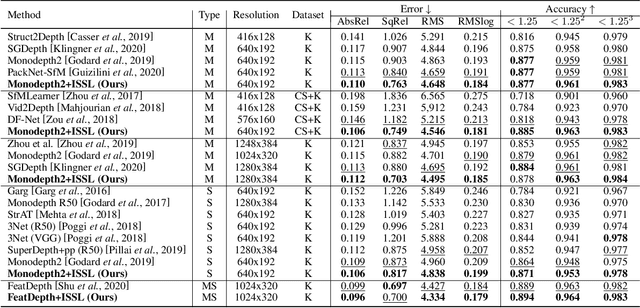
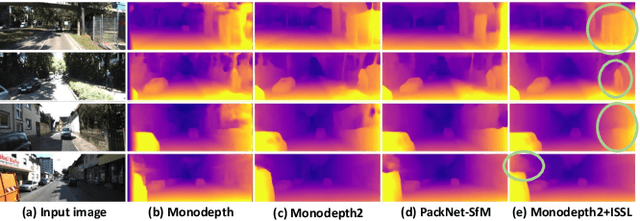
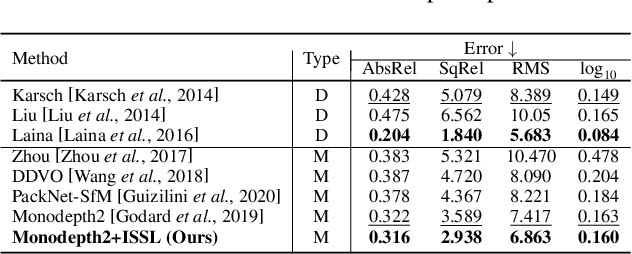
Managing the dynamic regions in the photometric loss formulation has been a main issue for handling the self-supervised depth estimation problem. Most previous methods have alleviated this issue by removing the dynamic regions in the photometric loss formulation based on the masks estimated from another module, making it difficult to fully utilize the training images. In this paper, to handle this problem, we propose an isometric self-sample-based learning (ISSL) method to fully utilize the training images in a simple yet effective way. The proposed method provides additional supervision during training using self-generated images that comply with pure static scene assumption. Specifically, the isometric self-sample generator synthesizes self-samples for each training image by applying random rigid transformations on the estimated depth. Thus both the generated self-samples and the corresponding training image always follow the static scene assumption. We show that plugging our ISSL module into several existing models consistently improves the performance by a large margin. In addition, it also boosts the depth accuracy over different types of scene, i.e., outdoor scenes (KITTI and Make3D) and indoor scene (NYUv2), validating its high effectiveness.
Consistency-preserving Visual Question Answering in Medical Imaging
Jun 27, 2022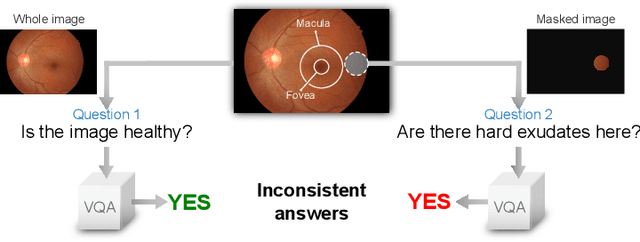
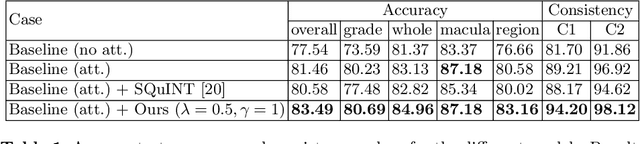
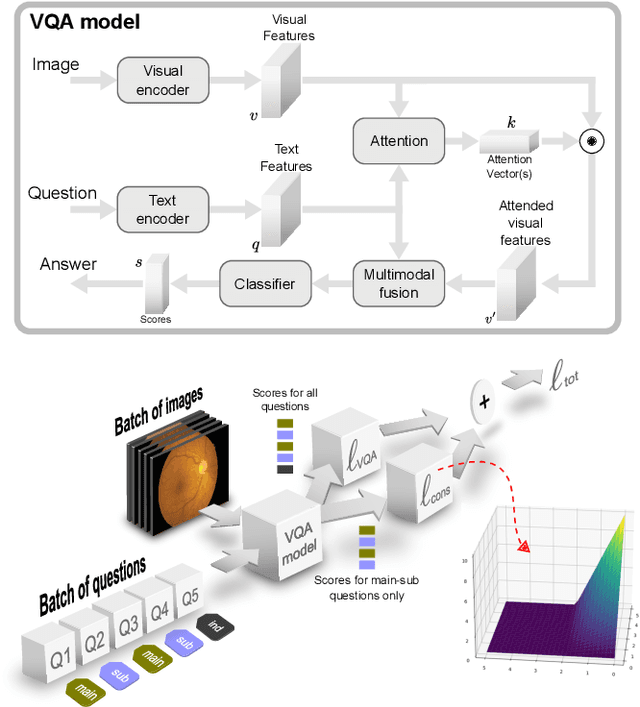
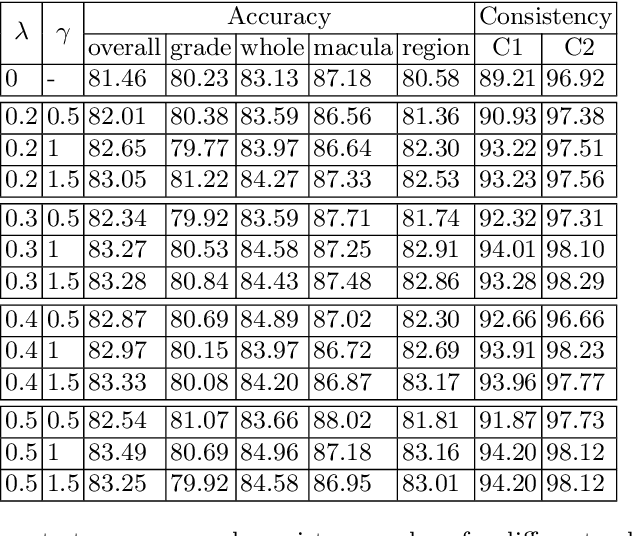
Visual Question Answering (VQA) models take an image and a natural-language question as input and infer the answer to the question. Recently, VQA systems in medical imaging have gained popularity thanks to potential advantages such as patient engagement and second opinions for clinicians. While most research efforts have been focused on improving architectures and overcoming data-related limitations, answer consistency has been overlooked even though it plays a critical role in establishing trustworthy models. In this work, we propose a novel loss function and corresponding training procedure that allows the inclusion of relations between questions into the training process. Specifically, we consider the case where implications between perception and reasoning questions are known a-priori. To show the benefits of our approach, we evaluate it on the clinically relevant task of Diabetic Macular Edema (DME) staging from fundus imaging. Our experiments show that our method outperforms state-of-the-art baselines, not only by improving model consistency, but also in terms of overall model accuracy. Our code and data are available at https://github.com/sergiotasconmorales/consistency_vqa.
Monocular Depth Estimation for Semi-Transparent Volume Renderings
Jun 27, 2022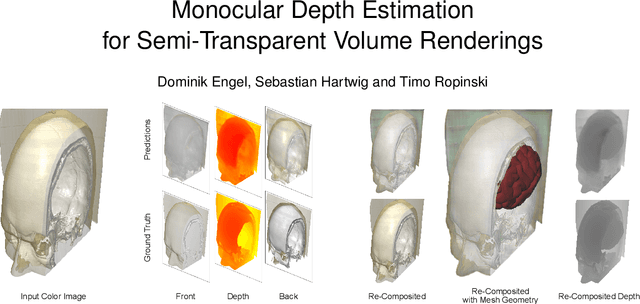
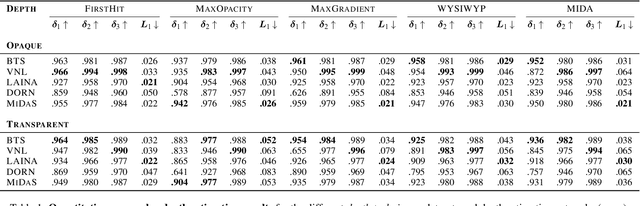
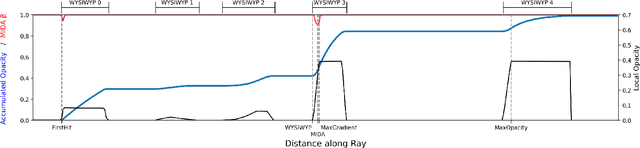
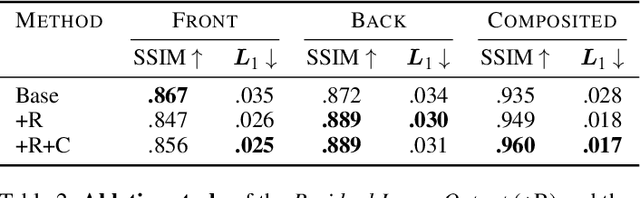
Neural networks have shown great success in extracting geometric information from color images. Especially, monocular depth estimation networks are increasingly reliable in real-world scenes. In this work we investigate the applicability of such monocular depth estimation networks to semi-transparent volume rendered images. As depth is notoriously difficult to define in a volumetric scene without clearly defined surfaces, we consider different depth computations that have emerged in practice, and compare state-of-the-art monocular depth estimation approaches for these different interpretations during an evaluation considering different degrees of opacity in the renderings. Additionally, we investigate how these networks can be extended to further obtain color and opacity information, in order to create a layered representation of the scene based on a single color image. This layered representation consists of spatially separated semi-transparent intervals that composite to the original input rendering. In our experiments we show that adaptions of existing approaches to monocular depth estimation perform well on semi-transparent volume renderings, which has several applications in the area of scientific visualization.
Confident Sinkhorn Allocation for Pseudo-Labeling
Jun 13, 2022
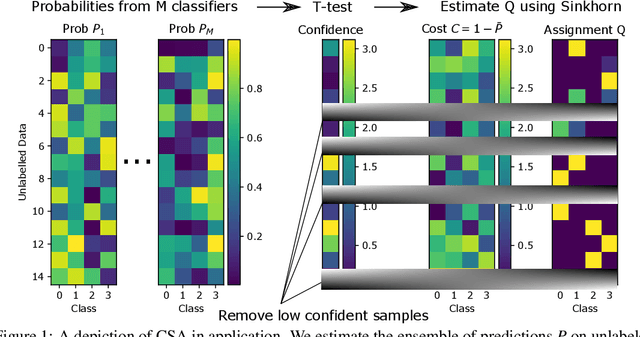
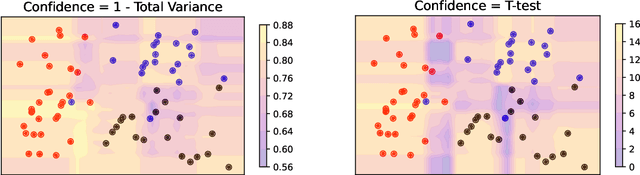
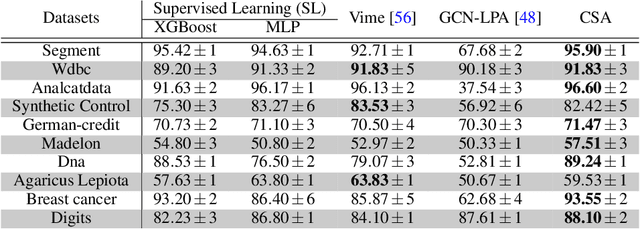
Semi-supervised learning is a critical tool in reducing machine learning's dependence on labeled data. It has, however, been applied primarily to image and language data, by exploiting the inherent spatial and semantic structure therein. These methods do not apply to tabular data because these domain structures are not available. Existing pseudo-labeling (PL) methods can be effective for tabular data but are vulnerable to noise samples and to greedy assignments given a predefined threshold which is unknown. This paper addresses this problem by proposing a Confident Sinkhorn Allocation (CSA), which assigns labels to only samples with high confidence scores and learns the best label allocation via optimal transport. CSA outperforms the current state-of-the-art in this practically important area.
Instance Segmentation of Unlabeled Modalities via Cyclic Segmentation GAN
Apr 06, 2022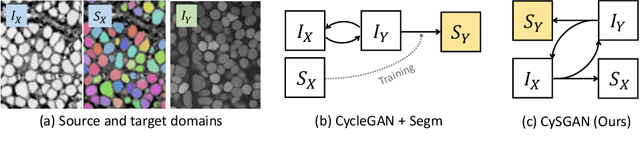

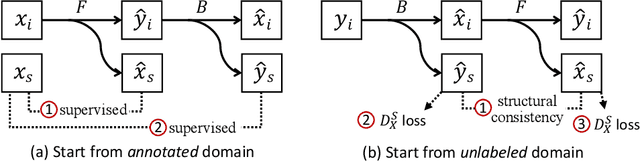
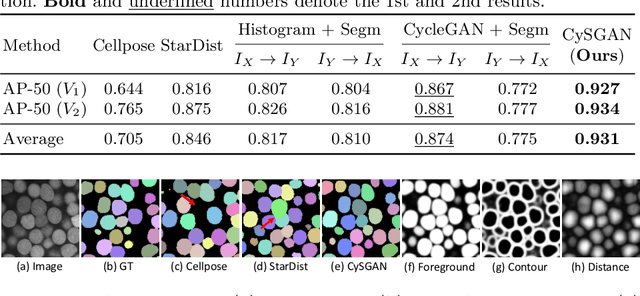
Instance segmentation for unlabeled imaging modalities is a challenging but essential task as collecting expert annotation can be expensive and time-consuming. Existing works segment a new modality by either deploying a pre-trained model optimized on diverse training data or conducting domain translation and image segmentation as two independent steps. In this work, we propose a novel Cyclic Segmentation Generative Adversarial Network (CySGAN) that conducts image translation and instance segmentation jointly using a unified framework. Besides the CycleGAN losses for image translation and supervised losses for the annotated source domain, we introduce additional self-supervised and segmentation-based adversarial objectives to improve the model performance by leveraging unlabeled target domain images. We benchmark our approach on the task of 3D neuronal nuclei segmentation with annotated electron microscopy (EM) images and unlabeled expansion microscopy (ExM) data. Our CySGAN outperforms both pretrained generalist models and the baselines that sequentially conduct image translation and segmentation. Our implementation and the newly collected, densely annotated ExM nuclei dataset, named NucExM, are available at https://connectomics-bazaar.github.io/proj/CySGAN/index.html.
Cross-Sim-NGF: FFT-Based Global Rigid Multimodal Alignment of Image Volumes using Normalized Gradient Fields
Oct 19, 2021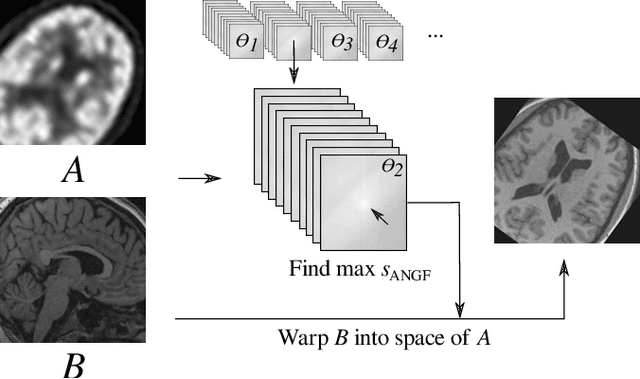
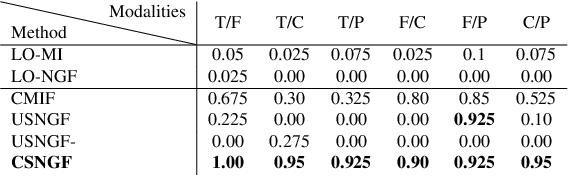

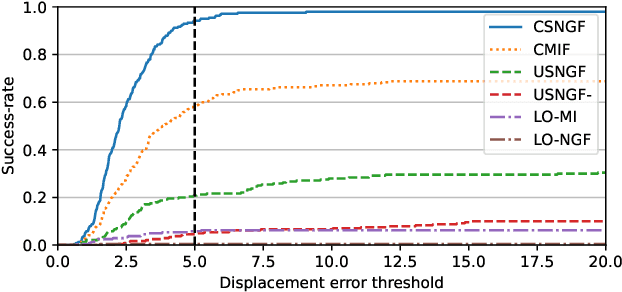
Multimodal image alignment involves finding spatial correspondences between volumes varying in appearance and structure. Automated alignment methods are often based on local optimization that can be highly sensitive to their initialization. We propose a global optimization method for rigid multimodal 3D image alignment, based on a novel efficient algorithm for computing similarity of normalized gradient fields (NGF) in the frequency domain. We validate the method experimentally on a dataset comprised of 20 brain volumes acquired in four modalities (T1w, Flair, CT, [18F] FDG PET), synthetically displaced with known transformations. The proposed method exhibits excellent performance on all six possible modality combinations, and outperforms all four reference methods by a large margin. The method is fast; a 3.4Mvoxel global rigid alignment requires approximately 40 seconds of computation, and the proposed algorithm outperforms a direct algorithm for the same task by more than three orders of magnitude. Open-source implementation is provided.
Detection of Furigana Text in Images
Jul 08, 2022
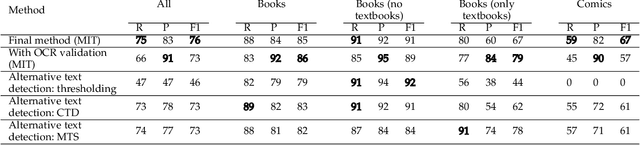
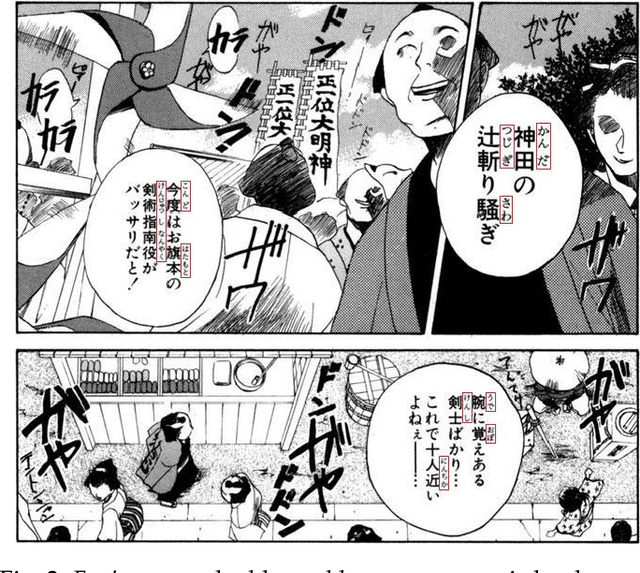
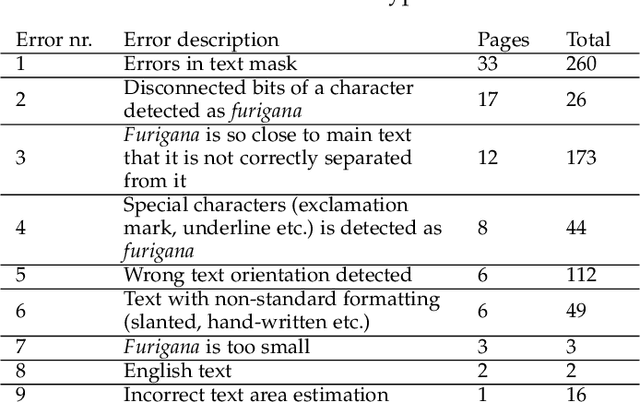
Furigana are pronunciation notes used in Japanese writing. Being able to detect these can help improve optical character recognition (OCR) performance or make more accurate digital copies of Japanese written media by correctly displaying furigana. This project focuses on detecting furigana in Japanese books and comics. While there has been research into the detection of Japanese text in general, there are currently no proposed methods for detecting furigana. We construct a new dataset containing Japanese written media and annotations of furigana. We propose an evaluation metric for such data which is similar to the evaluation protocols used in object detection except that it allows groups of objects to be labeled by one annotation. We propose a method for detection of furigana that is based on mathematical morphology and connected component analysis. We evaluate the detections of the dataset and compare different methods for text extraction. We also evaluate different types of images such as books and comics individually and discuss the challenges of each type of image. The proposed method reaches an F1-score of 76\% on the dataset. The method performs well on regular books, but less so on comics, and books of irregular format. Finally, we show that the proposed method can improve the performance of OCR by 5\% on the manga109 dataset. Source code is available via \texttt{\url{https://github.com/nikolajkb/FuriganaDetection}}
Progressive Class-based Expansion Learning For Image Classification
Jun 28, 2021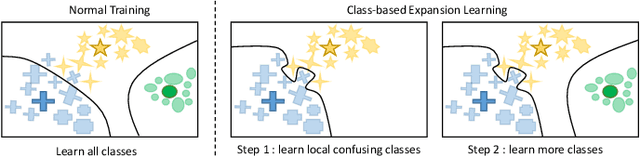
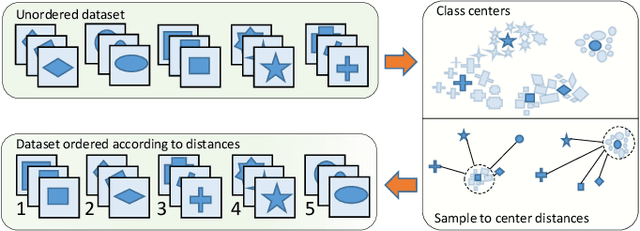
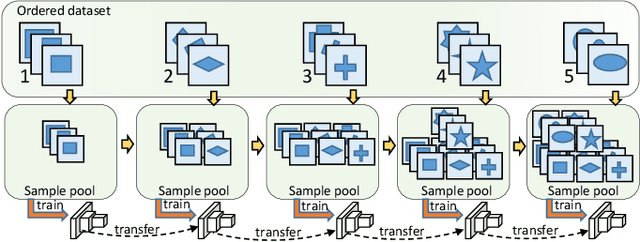
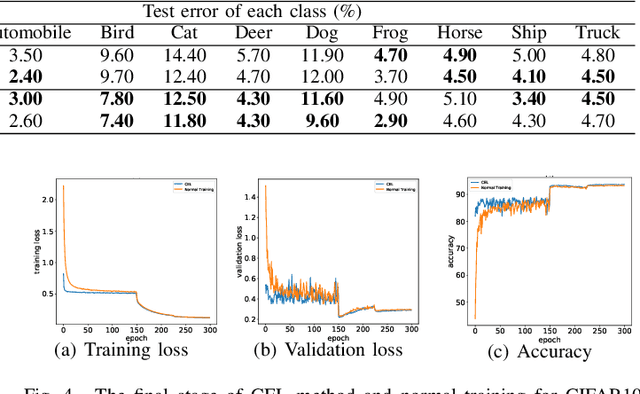
In this paper, we propose a novel image process scheme called class-based expansion learning for image classification, which aims at improving the supervision-stimulation frequency for the samples of the confusing classes. Class-based expansion learning takes a bottom-up growing strategy in a class-based expansion optimization fashion, which pays more attention to the quality of learning the fine-grained classification boundaries for the preferentially selected classes. Besides, we develop a class confusion criterion to select the confusing class preferentially for training. In this way, the classification boundaries of the confusing classes are frequently stimulated, resulting in a fine-grained form. Experimental results demonstrate the effectiveness of the proposed scheme on several benchmarks.
Uformer: A General U-Shaped Transformer for Image Restoration
Jun 06, 2021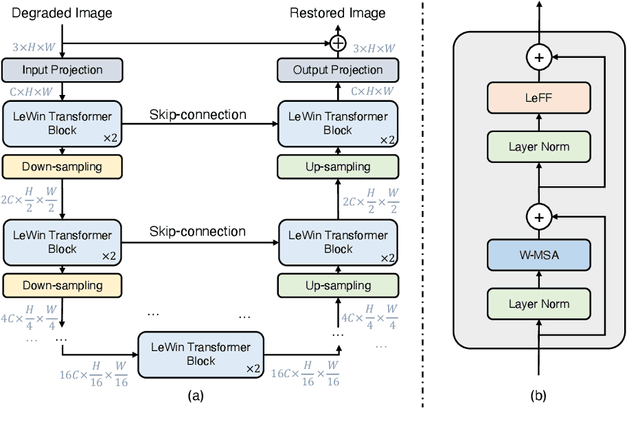
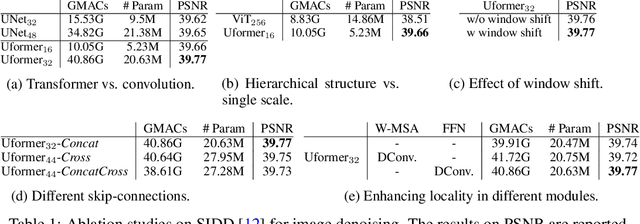
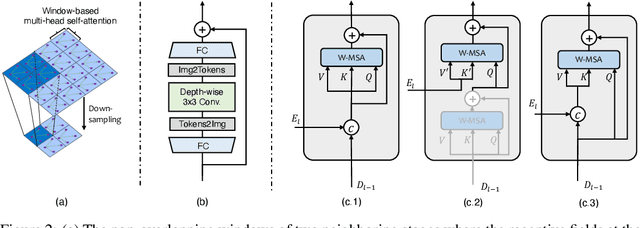
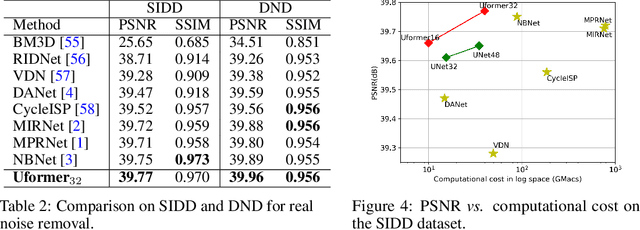
In this paper, we present Uformer, an effective and efficient Transformer-based architecture, in which we build a hierarchical encoder-decoder network using the Transformer block for image restoration. Uformer has two core designs to make it suitable for this task. The first key element is a local-enhanced window Transformer block, where we use non-overlapping window-based self-attention to reduce the computational requirement and employ the depth-wise convolution in the feed-forward network to further improve its potential for capturing local context. The second key element is that we explore three skip-connection schemes to effectively deliver information from the encoder to the decoder. Powered by these two designs, Uformer enjoys a high capability for capturing useful dependencies for image restoration. Extensive experiments on several image restoration tasks demonstrate the superiority of Uformer, including image denoising, deraining, deblurring and demoireing. We expect that our work will encourage further research to explore Transformer-based architectures for low-level vision tasks. The code and models will be available at https://github.com/ZhendongWang6/Uformer.
ARTEMIS: Attention-based Retrieval with Text-Explicit Matching and Implicit Similarity
Mar 15, 2022
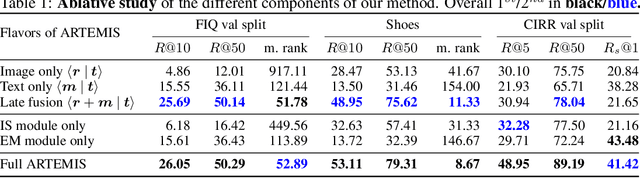
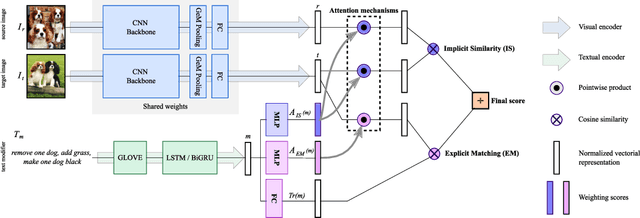
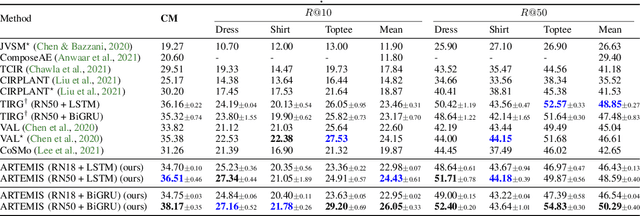
An intuitive way to search for images is to use queries composed of an example image and a complementary text. While the first provides rich and implicit context for the search, the latter explicitly calls for new traits, or specifies how some elements of the example image should be changed to retrieve the desired target image. Current approaches typically combine the features of each of the two elements of the query into a single representation, which can then be compared to the ones of the potential target images. Our work aims at shedding new light on the task by looking at it through the prism of two familiar and related frameworks: text-to-image and image-to-image retrieval. Taking inspiration from them, we exploit the specific relation of each query element with the targeted image and derive light-weight attention mechanisms which enable to mediate between the two complementary modalities. We validate our approach on several retrieval benchmarks, querying with images and their associated free-form text modifiers. Our method obtains state-of-the-art results without resorting to side information, multi-level features, heavy pre-training nor large architectures as in previous works.