 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enhancing Satellite Imagery using Deep Learning for the Sensor To Shooter Timeline
Mar 30, 2022

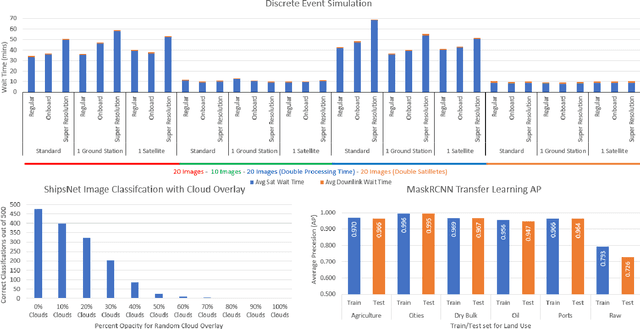

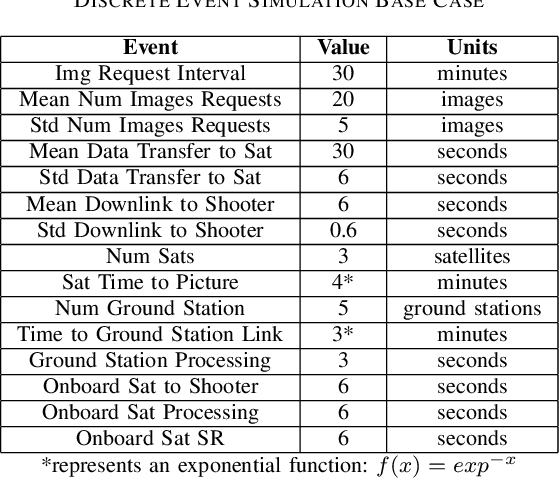
The sensor to shooter timeline is affected by two main variables: satellite positioning and asset positioning. Speeding up satellite positioning by adding more sensors or by decreasing processing time is important only if there is a prepared shooter, otherwise the main source of time is getting the shooter into position. However, the intelligence community should work towards the exploitation of sensors to the highest speed and effectiveness possible. Achieving a high effectiveness while keeping speed high is a tradeoff that must be considered in the sensor to shooter timeline. In this paper we investigate two main ideas, increasing the effectiveness of satellite imagery through image manipulation and how on-board image manipulation would affect the sensor to shooter timeline. We cover these ideas in four scenarios: Discrete Event Simulation of onboard processing versus ground station processing, quality of information with cloud cover removal, information improvement with super resolution, and data reduction with image to caption. This paper will show how image manipulation techniques such as Super Resolution, Cloud Removal, and Image to Caption will improve the quality of delivered information in addition to showing how those processes effect the sensor to shooter timeline.
Predicting Out-of-Domain Generalization with Local Manifold Smoothness
Jul 05, 2022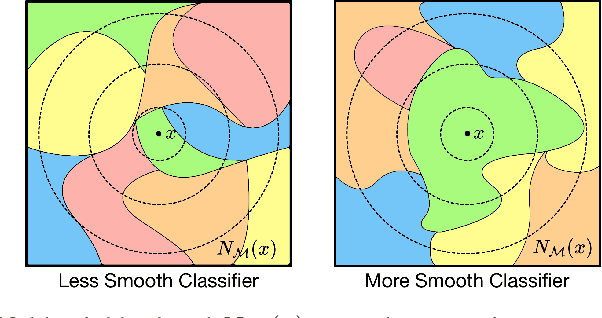

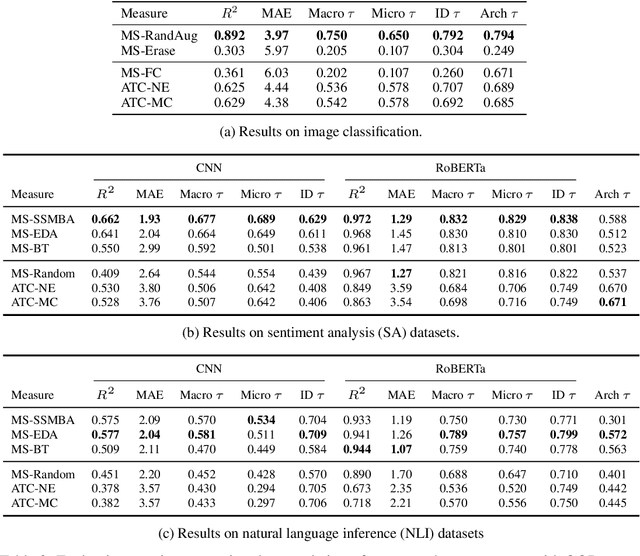
Understanding how machine learning models generalize to new environments is a critical part of their safe deployment. Recent work has proposed a variety of complexity measures that directly predict or theoretically bound the generalization capacity of a model. However, these methods rely on a strong set of assumptions that in practice are not always satisfied. Motivated by the limited settings in which existing measures can be applied, we propose a novel complexity measure based on the local manifold smoothness of a classifier. We define local manifold smoothness as a classifier's output sensitivity to perturbations in the manifold neighborhood around a given test point. Intuitively, a classifier that is less sensitive to these perturbations should generalize better. To estimate smoothness we sample points using data augmentation and measure the fraction of these points classified into the majority class. Our method only requires selecting a data augmentation method and makes no other assumptions about the model or data distributions, meaning it can be applied even in out-of-domain (OOD) settings where existing methods cannot. In experiments on robustness benchmarks in image classification, sentiment analysis, and natural language inference, we demonstrate a strong and robust correlation between our manifold smoothness measure and actual OOD generalization on over 3,000 models evaluated on over 100 train/test domain pairs.
CASHformer: Cognition Aware SHape Transformer for Longitudinal Analysis
Jul 05, 2022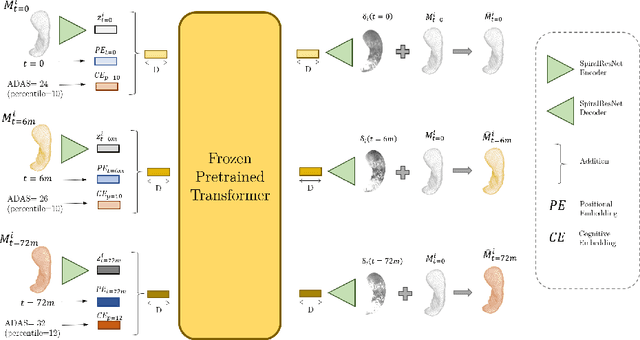
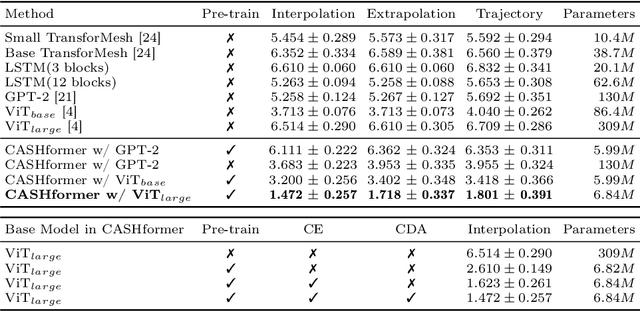
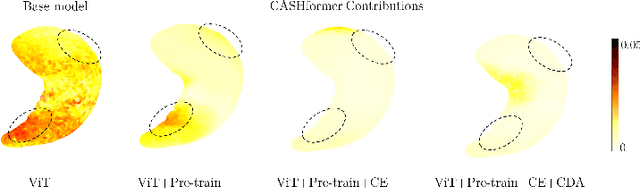
Modeling temporal changes in subcortical structures is crucial for a better understanding of the progression of Alzheimer's disease (AD). Given their flexibility to adapt to heterogeneous sequence lengths, mesh-based transformer architectures have been proposed in the past for predicting hippocampus deformations across time. However, one of the main limitations of transformers is the large amount of trainable parameters, which makes the application on small datasets very challenging. In addition, current methods do not include relevant non-image information that can help to identify AD-related patterns in the progression. To this end, we introduce CASHformer, a transformer-based framework to model longitudinal shape trajectories in AD. CASHformer incorporates the idea of pre-trained transformers as universal compute engines that generalize across a wide range of tasks by freezing most layers during fine-tuning. This reduces the number of parameters by over 90% with respect to the original model and therefore enables the application of large models on small datasets without overfitting. In addition, CASHformer models cognitive decline to reveal AD atrophy patterns in the temporal sequence. Our results show that CASHformer reduces the reconstruction error by 73% compared to previously proposed methods. Moreover, the accuracy of detecting patients progressing to AD increases by 3% with imputing missing longitudinal shape data.
In-N-Out Generative Learning for Dense Unsupervised Video Segmentation
Apr 11, 2022
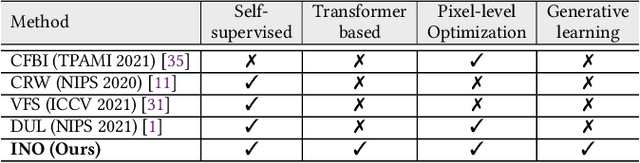
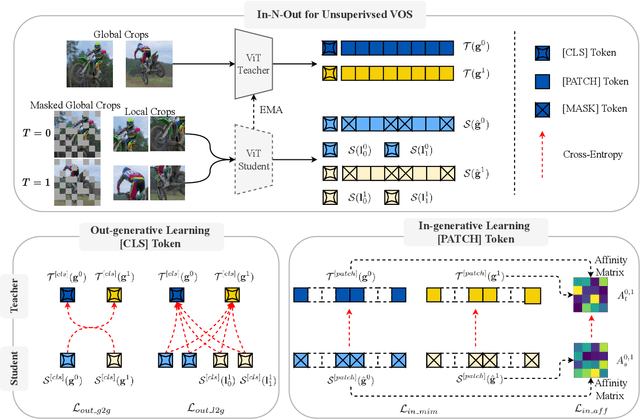
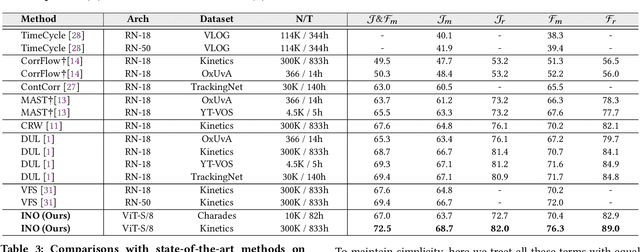
In this paper, we focus on the unsupervised learning for Video Object Segmentation (VOS) which learns visual correspondence (i.e., similarity between pixel-level features) from unlabeled videos. Previous methods are mainly based on the contrastive learning paradigm, which optimize either in image level or pixel level. Image-level optimization (e.g., the spatially pooled feature of ResNet) learns robust high-level semantics but is sub-optimal since the pixel-level features are optimized implicitly. By contrast, pixel-level optimization is more explicit, however, it is sensitive to the visual quality of training data and is not robust to object deformation. To complementarily perform these two levels of optimization in a unified framework, we propose the In-aNd-Out (INO) generative learning from a purely generative perspective with the help of naturally designed class tokens and patch tokens in Vision Transformer (ViT). Specifically, for image-level optimization, we force the out-view imagination from local to global views on class tokens, which helps capturing high-level semantics, and we name it as out-generative learning. As to pixel-level optimization, we perform in-view masked image modeling on patch tokens, which recovers the corrupted parts of an image via inferring its fine-grained structure, and we term it as in-generative learning. To better discover the temporal information, we additionally force the inter-frame consistency from both feature level and affinity matrix level. Extensive experiments on DAVIS-2017 val and YouTube-VOS 2018 val show that our INO outperforms previous state-of-the-art methods by significant margins.
ARM: Any-Time Super-Resolution Method
Mar 21, 2022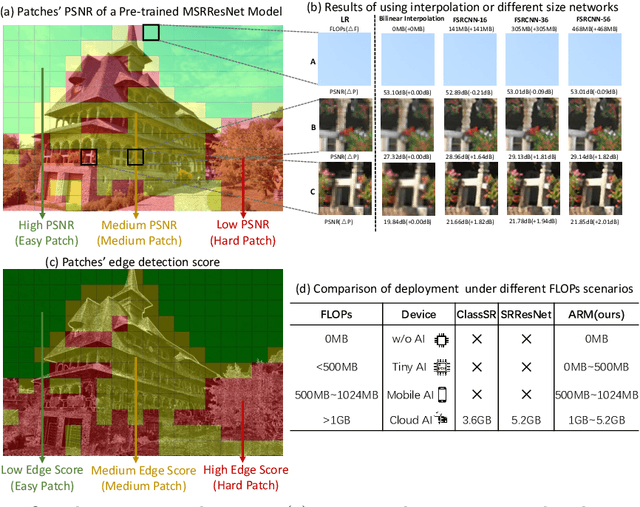
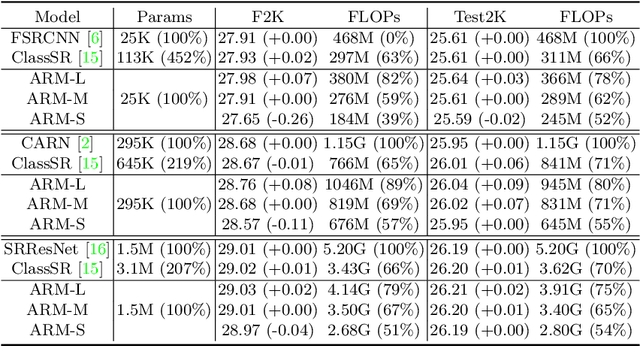

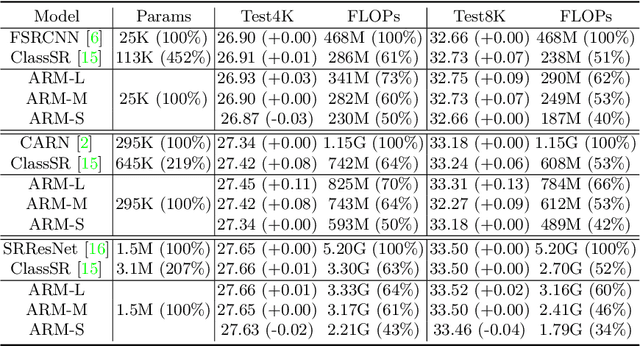
This paper proposes an Any-time super-Resolution Method (ARM) to tackle the over-parameterized single image super-resolution (SISR) models. Our ARM is motivated by three observations: (1) The performance of different image patches varies with SISR networks of different sizes. (2) There is a tradeoff between computation overhead and performance of the reconstructed image. (3) Given an input image, its edge information can be an effective option to estimate its PSNR. Subsequently, we train an ARM supernet containing SISR subnets of different sizes to deal with image patches of various complexity. To that effect, we construct an Edge-to-PSNR lookup table that maps the edge score of an image patch to the PSNR performance for each subnet, together with a set of computation costs for the subnets. In the inference, the image patches are individually distributed to different subnets for a better computation-performance tradeoff. Moreover, each SISR subnet shares weights of the ARM supernet, thus no extra parameters are introduced. The setting of multiple subnets can well adapt the computational cost of SISR model to the dynamically available hardware resources, allowing the SISR task to be in service at any time. Extensive experiments on resolution datasets of different sizes with popular SISR networks as backbones verify the effectiveness and the versatility of our ARM. The source code is available at \url{https://github.com/chenbong/ARM-Net}.
JPGNet: Joint Predictive Filtering and Generative Network for Image Inpainting
Jul 09, 2021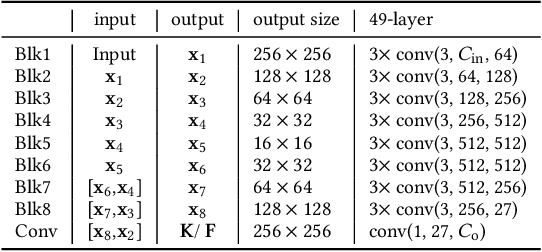

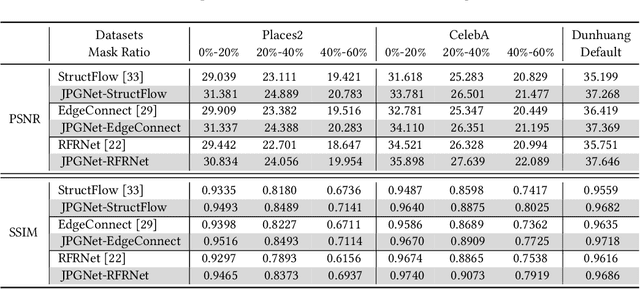
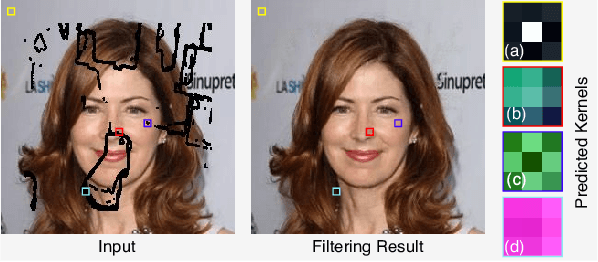
Image inpainting aims to restore the missing regions and make the recovery results identical to the originally complete image, which is different from the common generative task emphasizing the naturalness of generated images. Nevertheless, existing works usually regard it as a pure generation problem and employ cutting-edge generative techniques to address it. The generative networks fill the main missing parts with realistic contents but usually distort the local structures. In this paper, we formulate image inpainting as a mix of two problems, i.e., predictive filtering and deep generation. Predictive filtering is good at preserving local structures and removing artifacts but falls short to complete the large missing regions. The deep generative network can fill the numerous missing pixels based on the understanding of the whole scene but hardly restores the details identical to the original ones. To make use of their respective advantages, we propose the joint predictive filtering and generative network (JPGNet) that contains three branches: predictive filtering & uncertainty network (PFUNet), deep generative network, and uncertainty-aware fusion network (UAFNet). The PFUNet can adaptively predict pixel-wise kernels for filtering-based inpainting according to the input image and output an uncertainty map. This map indicates the pixels should be processed by filtering or generative networks, which is further fed to the UAFNet for a smart combination between filtering and generative results. Note that, our method as a novel framework for the image inpainting problem can benefit any existing generation-based methods. We validate our method on three public datasets, i.e., Dunhuang, Places2, and CelebA, and demonstrate that our method can enhance three state-of-the-art generative methods (i.e., StructFlow, EdgeConnect, and RFRNet) significantly with the slightly extra time cost.
Semantic similarity metrics for learned image registration
Apr 20, 2021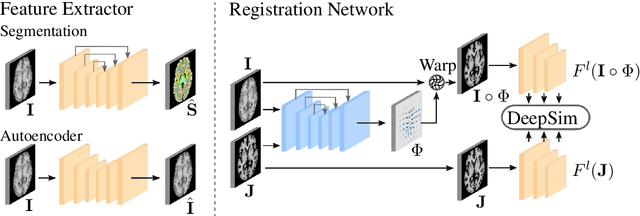
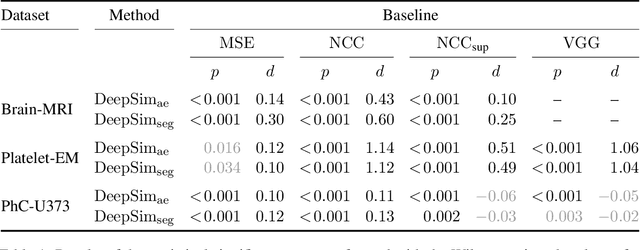
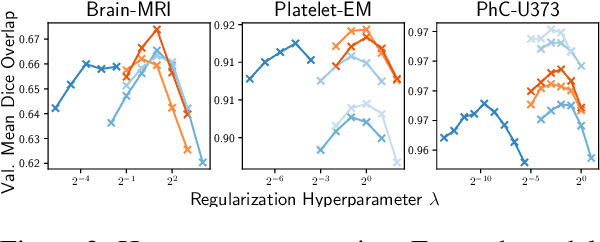
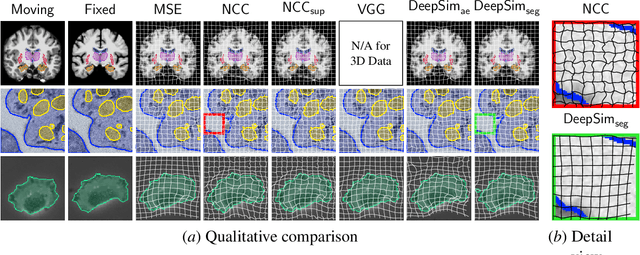
We propose a semantic similarity metric for image registration. Existing metrics like Euclidean Distance or Normalized Cross-Correlation focus on aligning intensity values, giving difficulties with low intensity contrast or noise. Our approach learns dataset-specific features that drive the optimization of a learning-based registration model. We train both an unsupervised approach using an auto-encoder, and a semi-supervised approach using supplemental segmentation data to extract semantic features for image registration. Comparing to existing methods across multiple image modalities and applications, we achieve consistently high registration accuracy. A learned invariance to noise gives smoother transformations on low-quality images.
Diffusion Models for Adversarial Purification
May 16, 2022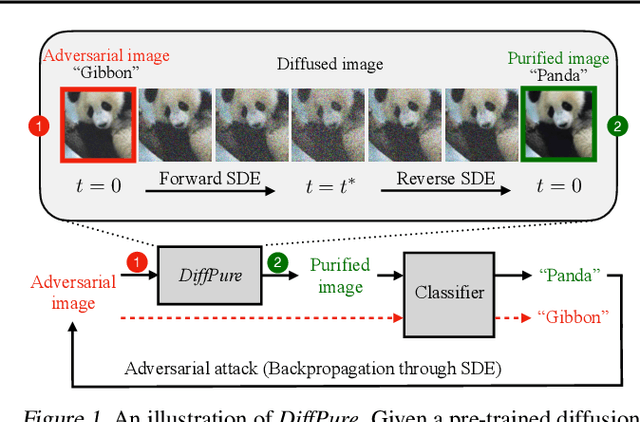
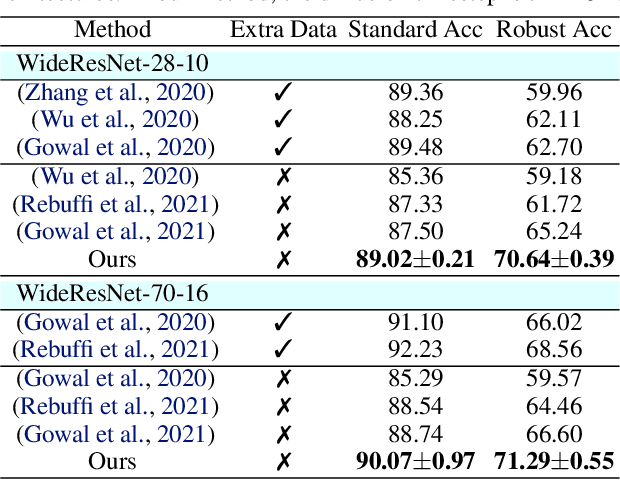

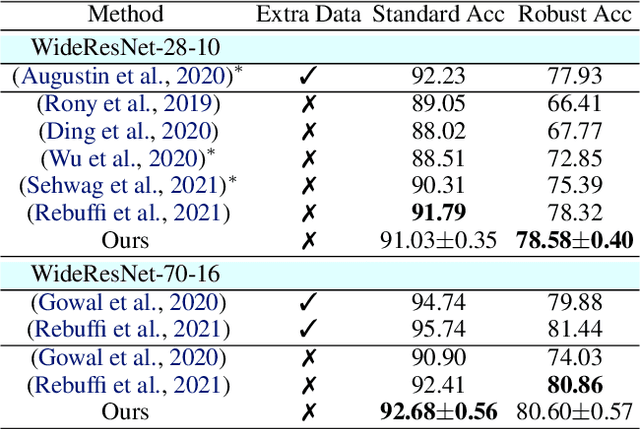
Adversarial purification refers to a class of defense methods that remove adversarial perturbations using a generative model. These methods do not make assumptions on the form of attack and the classification model, and thus can defend pre-existing classifiers against unseen threats. However, their performance currently falls behind adversarial training methods. In this work, we propose DiffPure that uses diffusion models for adversarial purification: Given an adversarial example, we first diffuse it with a small amount of noise following a forward diffusion process, and then recover the clean image through a reverse generative process. To evaluate our method against strong adaptive attacks in an efficient and scalable way, we propose to use the adjoint method to compute full gradients of the reverse generative process. Extensive experiments on three image datasets including CIFAR-10, ImageNet and CelebA-HQ with three classifier architectures including ResNet, WideResNet and ViT demonstrate that our method achieves the state-of-the-art results, outperforming current adversarial training and adversarial purification methods, often by a large margin. Project page: https://diffpure.github.io.
DECAL: DEployable Clinical Active Learning
Jun 27, 2022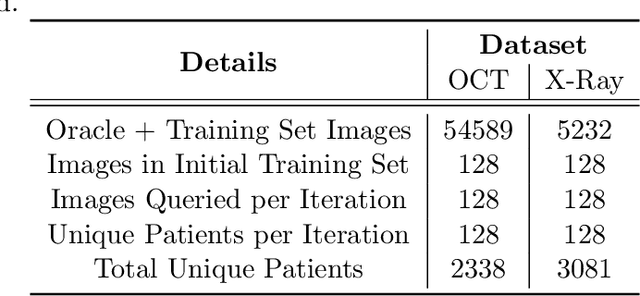
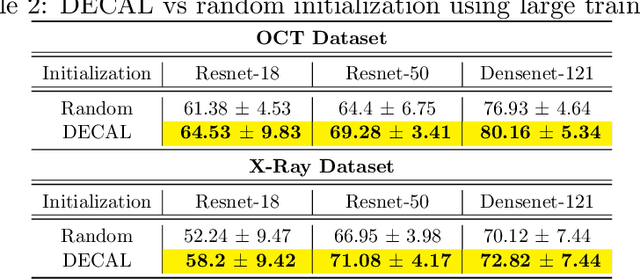
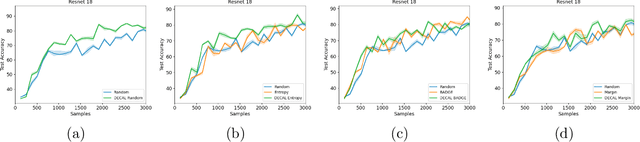
Conventional machine learning systems that operate on natural images assume the presence of attributes within the images that lead to some decision. However, decisions in medical domain are a resultant of attributes within medical diagnostic scans and electronic medical records (EMR). Hence, active learning techniques that are developed for natural images are insufficient for handling medical data. We focus on reducing this insufficiency by designing a deployable clinical active learning (DECAL) framework within a bi-modal interface so as to add practicality to the paradigm. Our approach is a "plug-in" method that makes natural image based active learning algorithms generalize better and faster. We find that on two medical datasets on three architectures and five learning strategies, DECAL increases generalization across 20 rounds by approximately 4.81%. DECAL leads to a 5.59% and 7.02% increase in average accuracy as an initialization strategy for optical coherence tomography (OCT) and X-Ray respectively. Our active learning results were achieved using 3000 (5%) and 2000 (38%) samples of OCT and X-Ray data respectively.
Self-Supervised Depth Estimation with Isometric-Self-Sample-Based Learning
May 20, 2022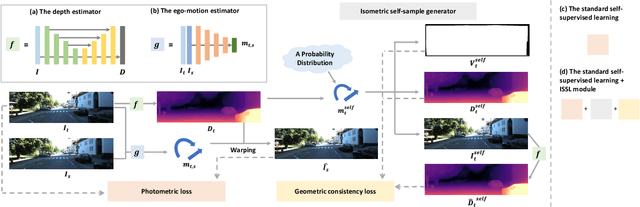
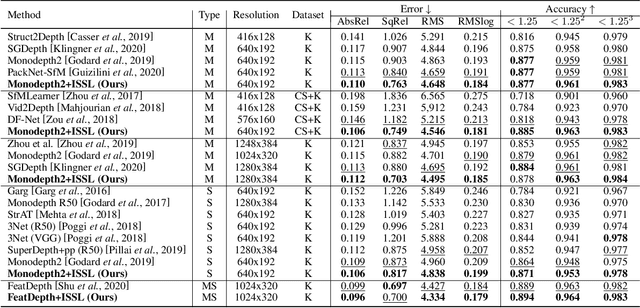
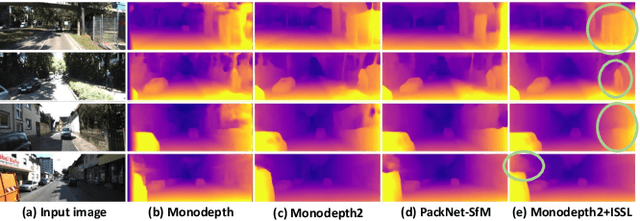
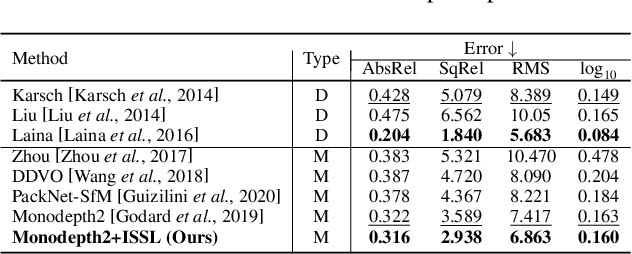
Managing the dynamic regions in the photometric loss formulation has been a main issue for handling the self-supervised depth estimation problem. Most previous methods have alleviated this issue by removing the dynamic regions in the photometric loss formulation based on the masks estimated from another module, making it difficult to fully utilize the training images. In this paper, to handle this problem, we propose an isometric self-sample-based learning (ISSL) method to fully utilize the training images in a simple yet effective way. The proposed method provides additional supervision during training using self-generated images that comply with pure static scene assumption. Specifically, the isometric self-sample generator synthesizes self-samples for each training image by applying random rigid transformations on the estimated depth. Thus both the generated self-samples and the corresponding training image always follow the static scene assumption. We show that plugging our ISSL module into several existing models consistently improves the performance by a large margin. In addition, it also boosts the depth accuracy over different types of scene, i.e., outdoor scenes (KITTI and Make3D) and indoor scene (NYUv2), validating its high effectiveness.