 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Drive&Segment: Unsupervised Semantic Segmentation of Urban Scenes via Cross-modal Distillation
Mar 21, 2022
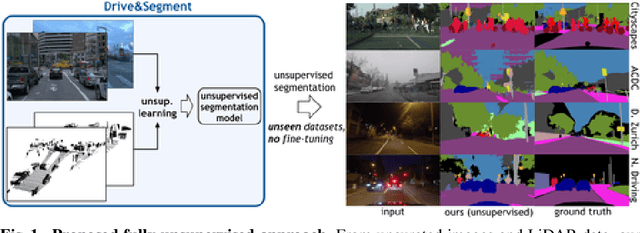
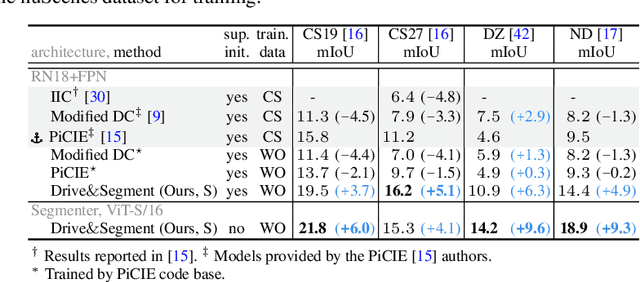
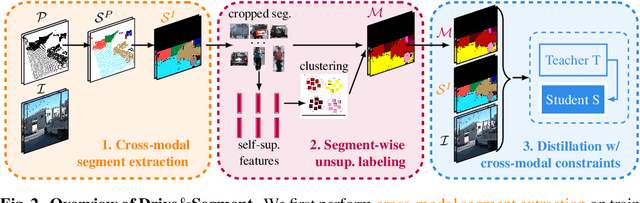
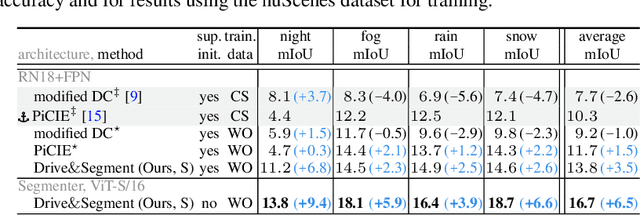
This work investigates learning pixel-wise semantic image segmentation in urban scenes without any manual annotation, just from the raw non-curated data collected by cars which, equipped with cameras and LiDAR sensors, drive around a city. Our contributions are threefold. First, we propose a novel method for cross-modal unsupervised learning of semantic image segmentation by leveraging synchronized LiDAR and image data. The key ingredient of our method is the use of an object proposal module that analyzes the LiDAR point cloud to obtain proposals for spatially consistent objects. Second, we show that these 3D object proposals can be aligned with the input images and reliably clustered into semantically meaningful pseudo-classes. Finally, we develop a cross-modal distillation approach that leverages image data partially annotated with the resulting pseudo-classes to train a transformer-based model for image semantic segmentation. We show the generalization capabilities of our method by testing on four different testing datasets (Cityscapes, Dark Zurich, Nighttime Driving and ACDC) without any finetuning, and demonstrate significant improvements compared to the current state of the art on this problem. See project webpage https://vobecant.github.io/DriveAndSegment/ for the code and more.
Sub-cluster-aware Network for Few-shot Skin Disease Classification
Jul 03, 2022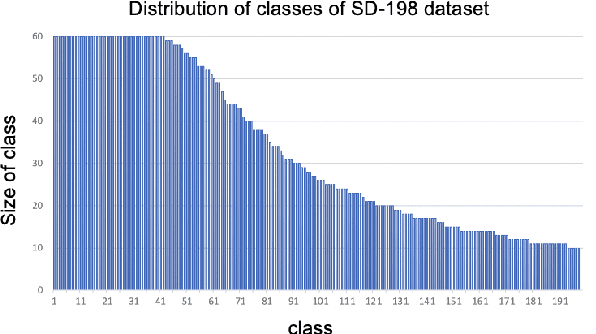
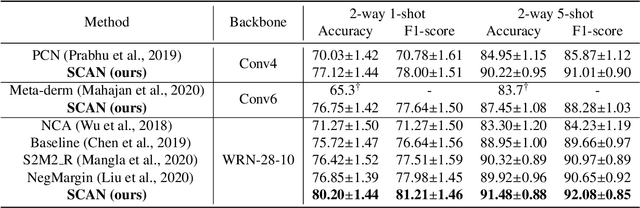
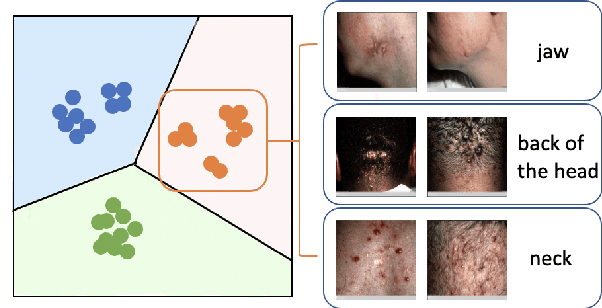
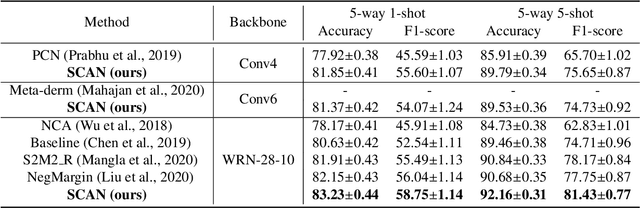
This paper studies the few-shot skin disease classification problem. Based on a crucial observation that skin disease images often exist multiple sub-clusters within a class (i.e., the appearances of images within one class of disease vary and form multiple distinct sub-groups), we design a novel Sub-Cluster-Aware Network, namely SCAN, for rare skin disease diagnosis with enhanced accuracy. As the performance of few-shot learning highly depends on the quality of the learned feature encoder, the main principle guiding the design of SCAN is the intrinsic sub-clustered representation learning for each class so as to better describe feature distributions. Specifically, SCAN follows a dual-branch framework, where the first branch is to learn class-wise features to distinguish different skin diseases, and the second one aims to learn features which can effectively partition each class into several groups so as to preserve the sub-clustered structure within each class. To achieve the objective of the second branch, we present a cluster loss to learn image similarities via unsupervised clustering. To ensure that the samples in each sub-cluster are from the same class, we further design a purity loss to refine the unsupervised clustering results. We evaluate the proposed approach on two public datasets for few-shot skin disease classification. The experimental results validate that our framework outperforms the other state-of-the-art methods by around 2% to 4% on the SD-198 and Derm7pt datasets.
Student Collaboration Improves Self-Supervised Learning: Dual-Loss Adaptive Masked Autoencoder for Brain Cell Image Analysis
May 10, 2022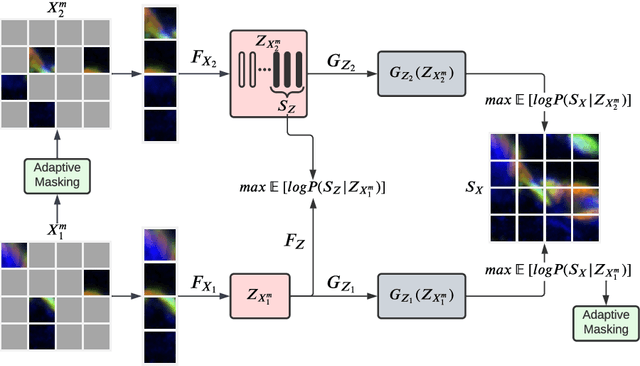
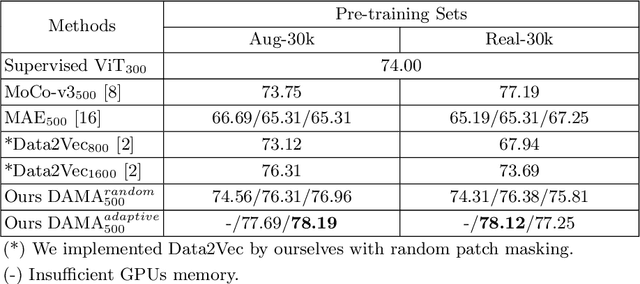
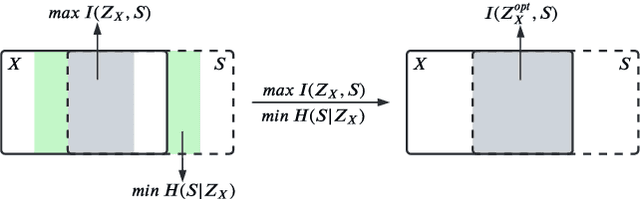
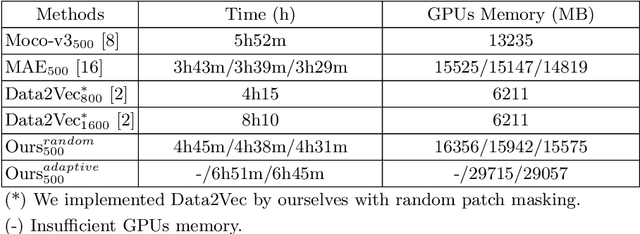
Self-supervised learning leverages the underlying data structure as the source of the supervisory signal without the need for human annotation effort. This approach offers a practical solution to learning with a large amount of biomedical data and limited annotation. Unlike other studies exploiting data via multi-view (e.g., augmented images), this study presents a self-supervised Dual-Loss Adaptive Masked Autoencoder (DAMA) algorithm established from the viewpoint of the information theory. Specifically, our objective function maximizes the mutual information by minimizing the conditional entropy in pixel-level reconstruction and feature-level regression. We further introduce an adaptive mask sampling strategy to maximize mutual information. We conduct extensive experiments on brain cell images to validate the proposed method. DAMA significantly outperforms both state-of-the-art self-supervised and supervised methods on brain cells data and demonstrates competitive result on ImageNet-1k. Code: https://github.com/hula-ai/DAMA
EMOCA: Emotion Driven Monocular Face Capture and Animation
Apr 24, 2022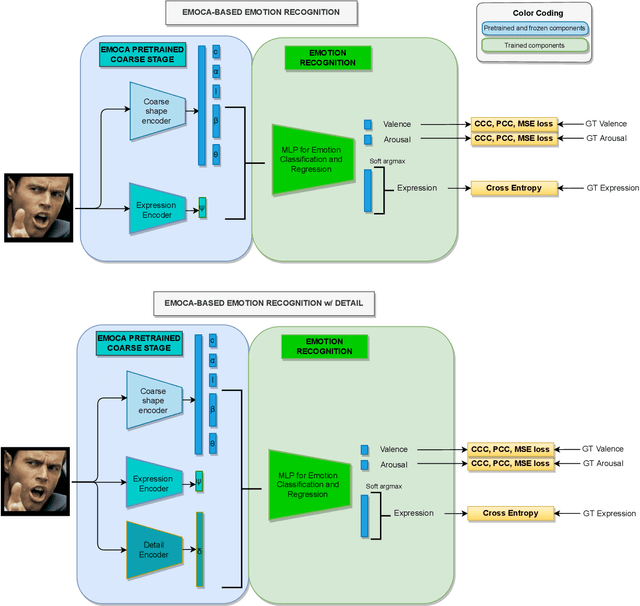
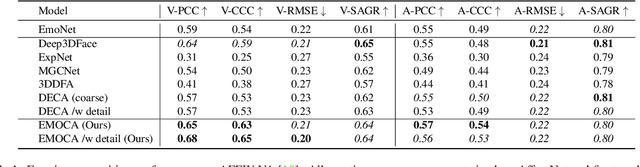
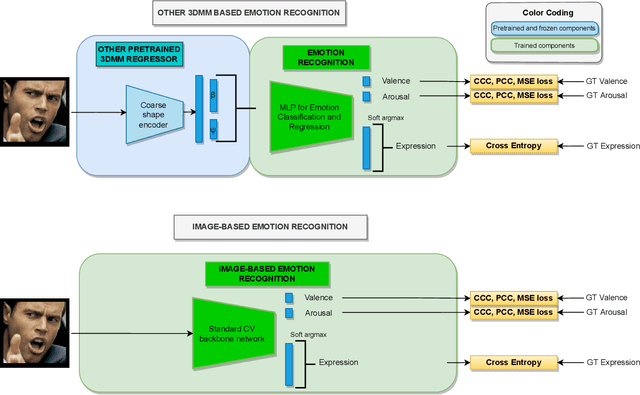
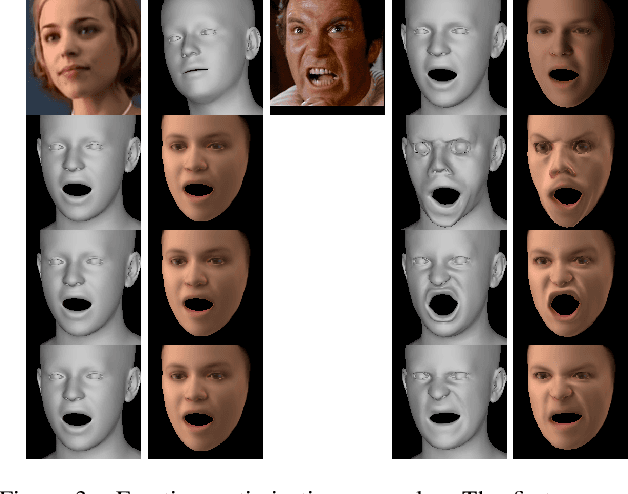
As 3D facial avatars become more widely used for communication, it is critical that they faithfully convey emotion. Unfortunately, the best recent methods that regress parametric 3D face models from monocular images are unable to capture the full spectrum of facial expression, such as subtle or extreme emotions. We find the standard reconstruction metrics used for training (landmark reprojection error, photometric error, and face recognition loss) are insufficient to capture high-fidelity expressions. The result is facial geometries that do not match the emotional content of the input image. We address this with EMOCA (EMOtion Capture and Animation), by introducing a novel deep perceptual emotion consistency loss during training, which helps ensure that the reconstructed 3D expression matches the expression depicted in the input image. While EMOCA achieves 3D reconstruction errors that are on par with the current best methods, it significantly outperforms them in terms of the quality of the reconstructed expression and the perceived emotional content. We also directly regress levels of valence and arousal and classify basic expressions from the estimated 3D face parameters. On the task of in-the-wild emotion recognition, our purely geometric approach is on par with the best image-based methods, highlighting the value of 3D geometry in analyzing human behavior. The model and code are publicly available at https://emoca.is.tue.mpg.de.
TriHorn-Net: A Model for Accurate Depth-Based 3D Hand Pose Estimation
Jun 14, 2022

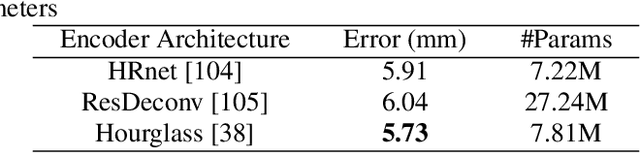
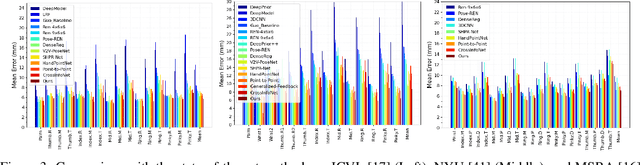
3D hand pose estimation methods have made significant progress recently. However, estimation accuracy is often far from sufficient for specific real-world applications, and thus there is significant room for improvement. This paper proposes TriHorn-Net, a novel model that uses specific innovations to improve hand pose estimation accuracy on depth images. The first innovation is the decomposition of the 3D hand pose estimation into the estimation of 2D joint locations in the depth image space (UV), and the estimation of their corresponding depths aided by two complementary attention maps. This decomposition prevents depth estimation, which is a more difficult task, from interfering with the UV estimations at both the prediction and feature levels. The second innovation is PixDropout, which is, to the best of our knowledge, the first appearance-based data augmentation method for hand depth images. Experimental results demonstrate that the proposed model outperforms the state-of-the-art methods on three public benchmark datasets.
Content-adaptive Representation Learning for Fast Image Super-resolution
May 20, 2021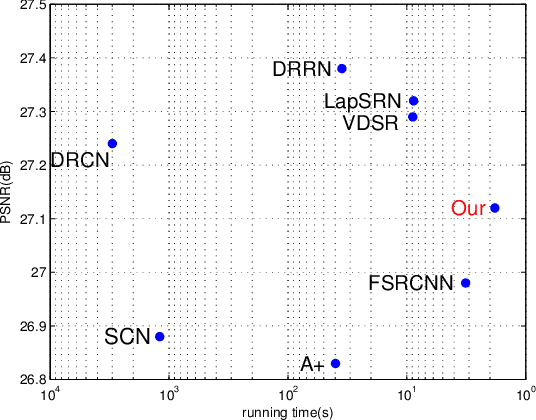
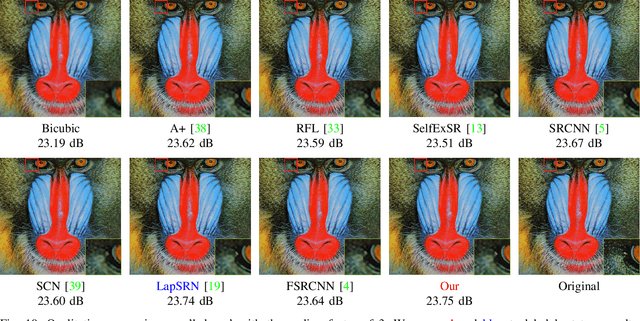


Deep convolutional networks have attracted great attention in image restoration and enhancement. Generally, restoration quality has been improved by building more and more convolutional block. However, these methods mostly learn a specific model to handle all images and ignore difficulty diversity. In other words, an area in the image with high frequency tend to lose more information during compressing while an area with low frequency tends to lose less. In this article, we adrress the efficiency issue in image SR by incorporating a patch-wise rolling network(PRN) to content-adaptively recover images according to difficulty levels. In contrast to existing studies that ignore difficulty diversity, we adopt different stage of a neural network to perform image restoration. In addition, we propose a rolling strategy that utilizes the parameters of each stage more flexible. Extensive experiments demonstrate that our model not only shows a significant acceleration but also maintain state-of-the-art performance.
A Hierarchical Multi-Task Approach to Gastrointestinal Image Analysis
Nov 16, 2021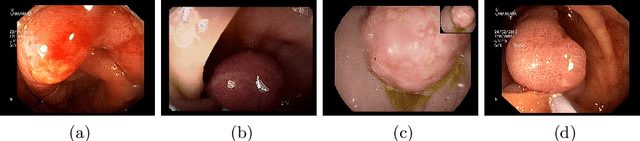
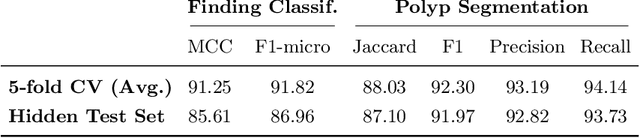
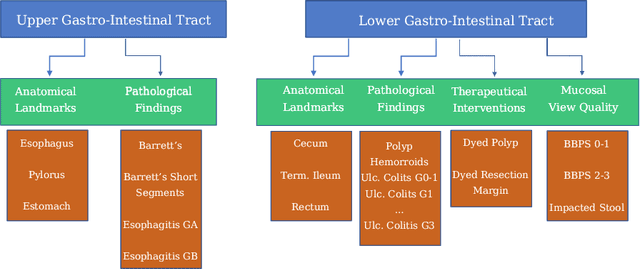
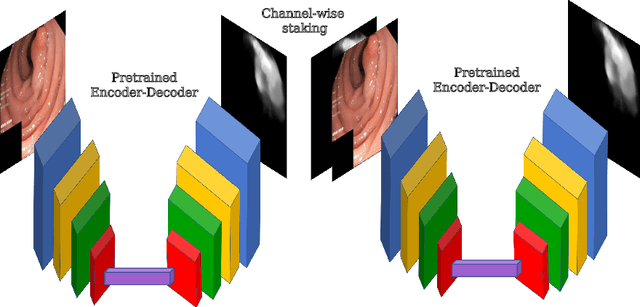
A large number of different lesions and pathologies can affect the human digestive system, resulting in life-threatening situations. Early detection plays a relevant role in the successful treatment and the increase of current survival rates to, e.g., colorectal cancer. The standard procedure enabling detection, endoscopic video analysis, generates large quantities of visual data that need to be carefully analyzed by an specialist. Due to the wide range of color, shape, and general visual appearance of pathologies, as well as highly varying image quality, such process is greatly dependent on the human operator experience and skill. In this work, we detail our solution to the task of multi-category classification of images from the gastrointestinal (GI) human tract within the 2020 Endotect Challenge. Our approach is based on a Convolutional Neural Network minimizing a hierarchical error function that takes into account not only the finding category, but also its location within the GI tract (lower/upper tract), and the type of finding (pathological finding/therapeutic intervention/anatomical landmark/mucosal views' quality). We also describe in this paper our solution for the challenge task of polyp segmentation in colonoscopies, which was addressed with a pretrained double encoder-decoder network. Our internal cross-validation results show an average performance of 91.25 Mathews Correlation Coefficient (MCC) and 91.82 Micro-F1 score for the classification task, and a 92.30 F1 score for the polyp segmentation task. The organization provided feedback on the performance in a hidden test set for both tasks, which resulted in 85.61 MCC and 86.96 F1 score for classification, and 91.97 F1 score for polyp segmentation. At the time of writing no public ranking for this challenge had been released.
Peripheral Vision Transformer
Jun 14, 2022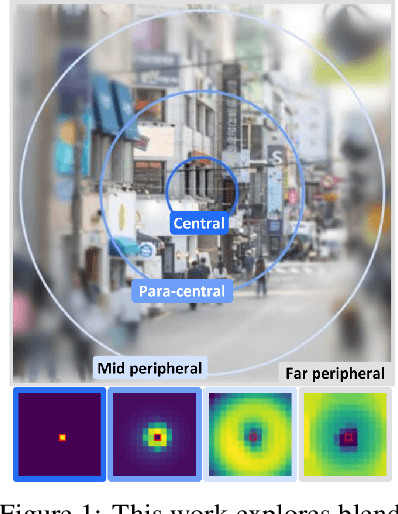
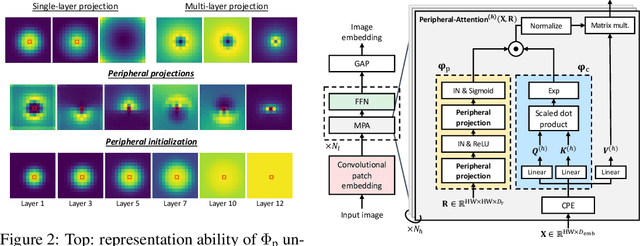
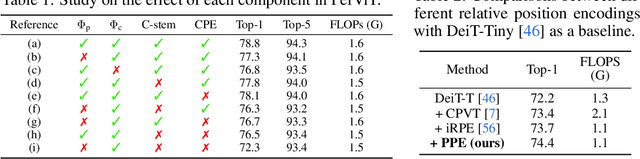

Human vision possesses a special type of visual processing systems called peripheral vision. Partitioning the entire visual field into multiple contour regions based on the distance to the center of our gaze, the peripheral vision provides us the ability to perceive various visual features at different regions. In this work, we take a biologically inspired approach and explore to model peripheral vision in deep neural networks for visual recognition. We propose to incorporate peripheral position encoding to the multi-head self-attention layers to let the network learn to partition the visual field into diverse peripheral regions given training data. We evaluate the proposed network, dubbed PerViT, on the large-scale ImageNet dataset and systematically investigate the inner workings of the model for machine perception, showing that the network learns to perceive visual data similarly to the way that human vision does. The state-of-the-art performance in image classification task across various model sizes demonstrates the efficacy of the proposed method.
SRDiff: Single Image Super-Resolution with Diffusion Probabilistic Models
May 18, 2021
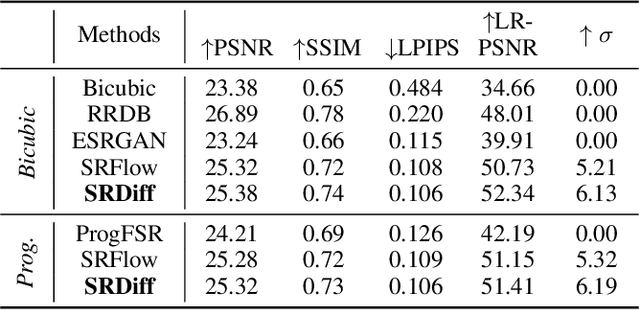
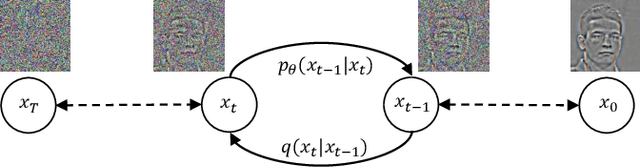
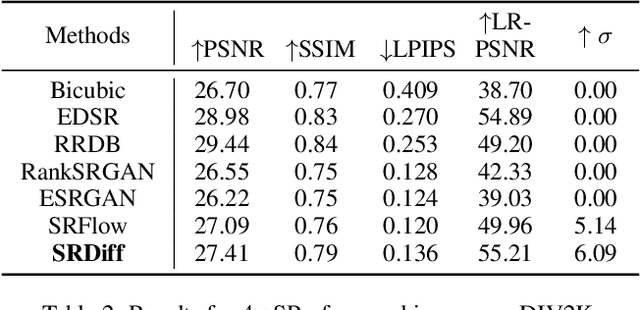
Single image super-resolution (SISR) aims to reconstruct high-resolution (HR) images from the given low-resolution (LR) ones, which is an ill-posed problem because one LR image corresponds to multiple HR images. Recently, learning-based SISR methods have greatly outperformed traditional ones, while suffering from over-smoothing, mode collapse or large model footprint issues for PSNR-oriented, GAN-driven and flow-based methods respectively. To solve these problems, we propose a novel single image super-resolution diffusion probabilistic model (SRDiff), which is the first diffusion-based model for SISR. SRDiff is optimized with a variant of the variational bound on the data likelihood and can provide diverse and realistic SR predictions by gradually transforming the Gaussian noise into a super-resolution (SR) image conditioned on an LR input through a Markov chain. In addition, we introduce residual prediction to the whole framework to speed up convergence. Our extensive experiments on facial and general benchmarks (CelebA and DIV2K datasets) show that 1) SRDiff can generate diverse SR results in rich details with state-of-the-art performance, given only one LR input; 2) SRDiff is easy to train with a small footprint; and 3) SRDiff can perform flexible image manipulation including latent space interpolation and content fusion.
Benefits of Overparameterized Convolutional Residual Networks: Function Approximation under Smoothness Constraint
Jun 09, 2022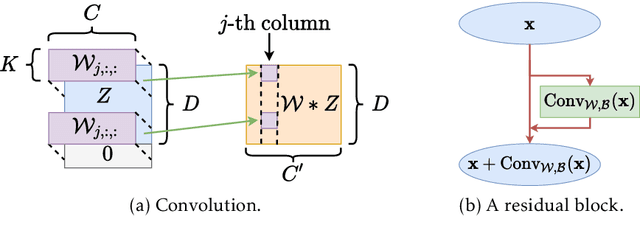
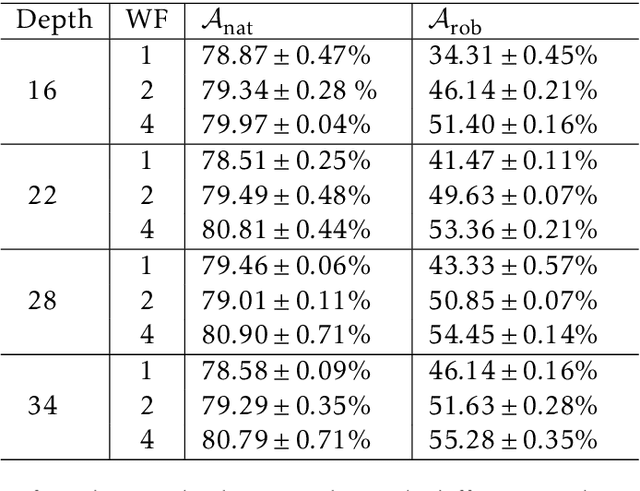
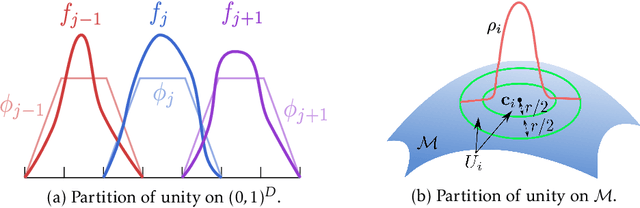
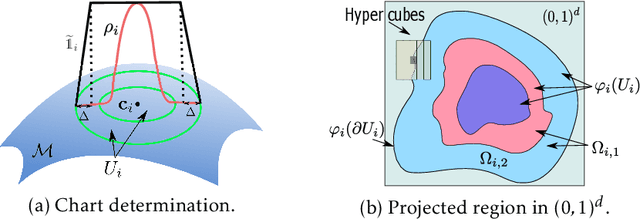
Overparameterized neural networks enjoy great representation power on complex data, and more importantly yield sufficiently smooth output, which is crucial to their generalization and robustness. Most existing function approximation theories suggest that with sufficiently many parameters, neural networks can well approximate certain classes of functions in terms of the function value. The neural network themselves, however, can be highly nonsmooth. To bridge this gap, we take convolutional residual networks (ConvResNets) as an example, and prove that large ConvResNets can not only approximate a target function in terms of function value, but also exhibit sufficient first-order smoothness. Moreover, we extend our theory to approximating functions supported on a low-dimensional manifold. Our theory partially justifies the benefits of using deep and wide networks in practice. Numerical experiments on adversarial robust image classification are provided to support our theory.