 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fingerprint Template Invertibility: Minutiae vs. Deep Templates
May 08, 2022
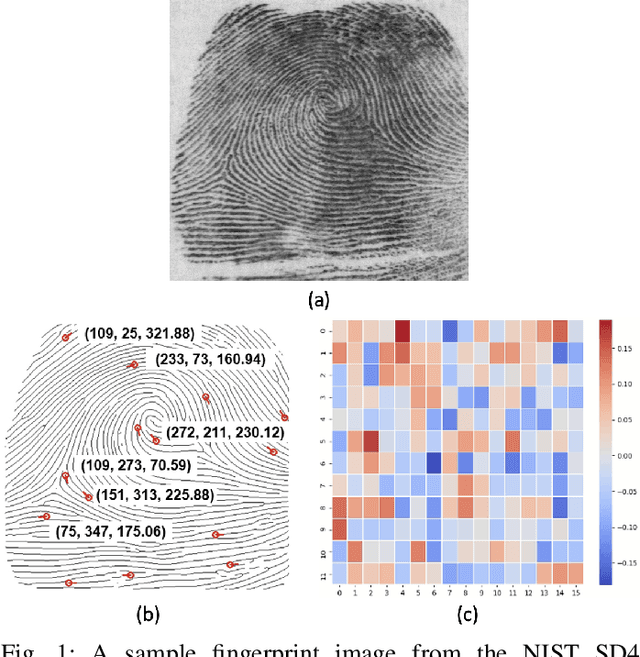

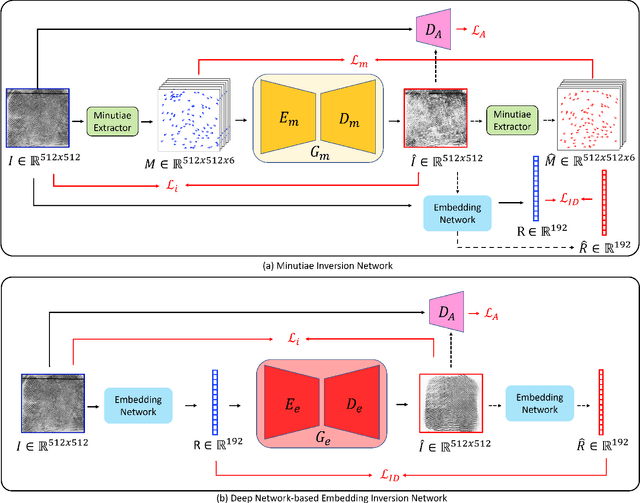

Much of the success of fingerprint recognition is attributed to minutiae-based fingerprint representation. It was believed that minutiae templates could not be inverted to obtain a high fidelity fingerprint image, but this assumption has been shown to be false. The success of deep learning has resulted in alternative fingerprint representations (embeddings), in the hope that they might offer better recognition accuracy as well as non-invertibility of deep network-based templates. We evaluate whether deep fingerprint templates suffer from the same reconstruction attacks as the minutiae templates. We show that while a deep template can be inverted to produce a fingerprint image that could be matched to its source image, deep templates are more resistant to reconstruction attacks than minutiae templates. In particular, reconstructed fingerprint images from minutiae templates yield a TAR of about 100.0% (98.3%) @ FAR of 0.01% for type-I (type-II) attacks using a state-of-the-art commercial fingerprint matcher, when tested on NIST SD4. The corresponding attack performance for reconstructed fingerprint images from deep templates using the same commercial matcher yields a TAR of less than 1% for both type-I and type-II attacks; however, when the reconstructed images are matched using the same deep network, they achieve a TAR of 85.95% (68.10%) for type-I (type-II) attacks. Furthermore, what is missing from previous fingerprint template inversion studies is an evaluation of the black-box attack performance, which we perform using 3 different state-of-the-art fingerprint matchers. We conclude that fingerprint images generated by inverting minutiae templates are highly susceptible to both white-box and black-box attack evaluations, while fingerprint images generated by deep templates are resistant to black-box evaluations and comparatively less susceptible to white-box evaluations.
HANF: Hyperparameter And Neural Architecture Search in Federated Learning
Jun 24, 2022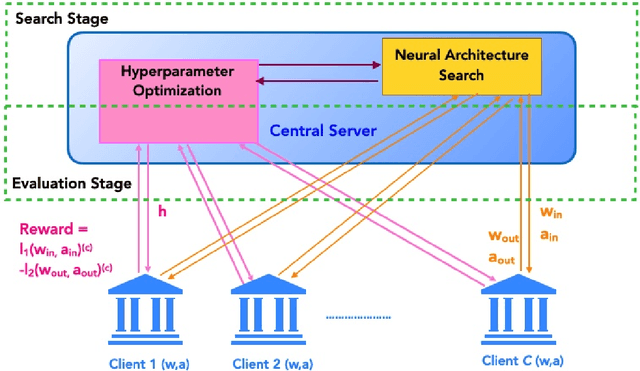

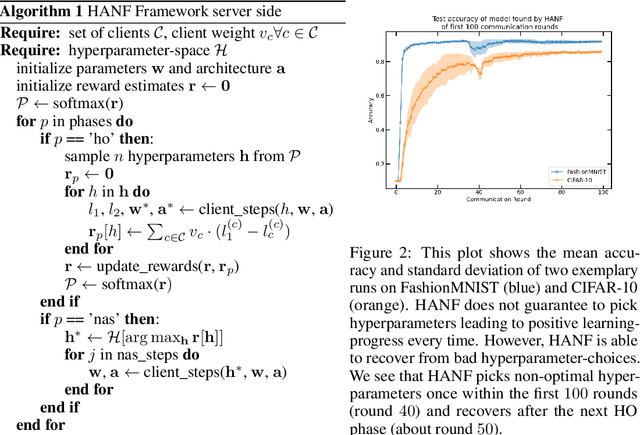
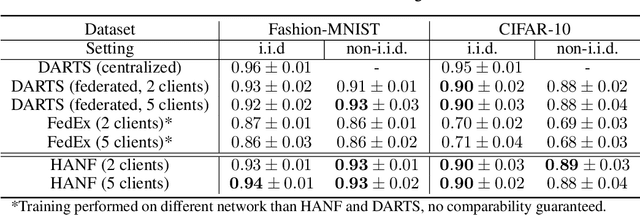
Automated machine learning (AutoML) is an important step to make machine learning models being widely applied to solve real world problems. Despite numerous research advancement, machine learning methods are not fully utilized by industries mainly due to their data privacy and security regulations, high cost involved in storing and computing increasing amount of data at central location and most importantly lack of expertise. Hence, we introduce a novel framework, HANF - $\textbf{H}$yperparameter $\textbf{A}$nd $\textbf{N}$eural architecture search in $\textbf{F}$ederated learning as a step towards building an AutoML framework for data distributed across several data owner servers without any need for bringing the data to a central location. HANF jointly optimizes a neural architecture and non-architectural hyperparameters of a learning algorithm using gradient-based neural architecture search and $n$-armed bandit approach respectively in data distributed setting. We show that HANF efficiently finds the optimized neural architecture and also tunes the hyperparameters on data owner servers. Additionally, HANF can be applied in both, federated and non-federated settings. Empirically, we show that HANF converges towards well-suited architectures and non-architectural hyperparameter-sets using image-classification tasks.
Benchopt: Reproducible, efficient and collaborative optimization benchmarks
Jun 28, 2022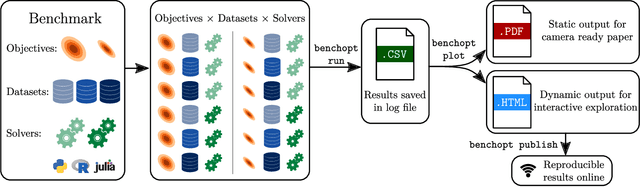
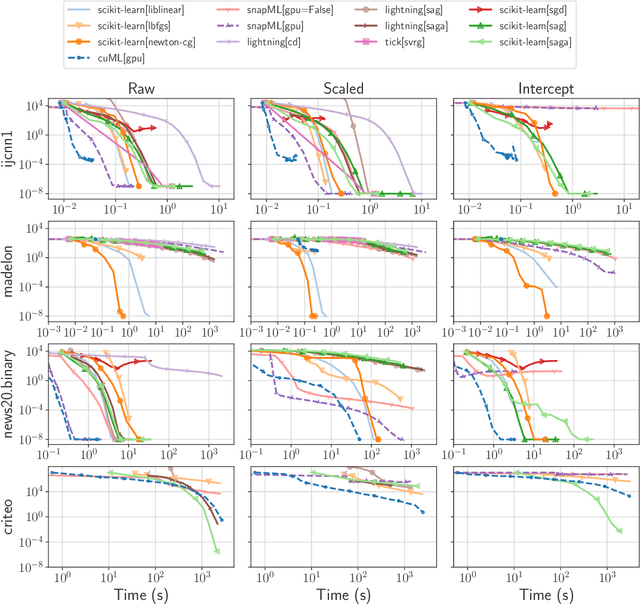
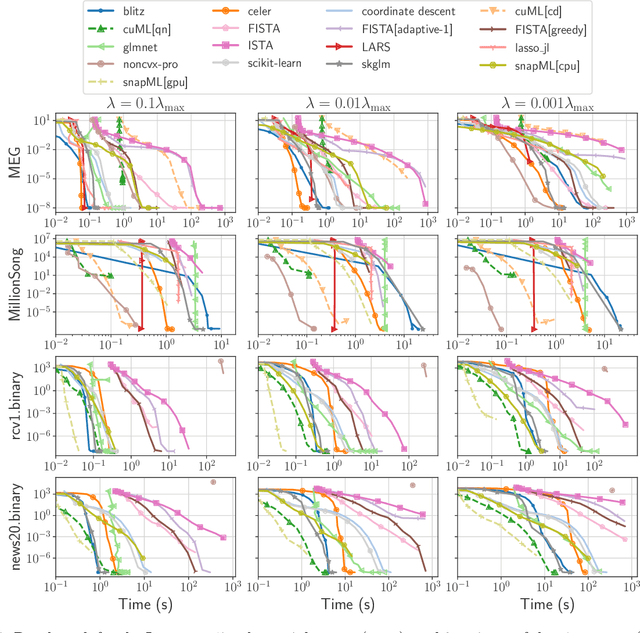
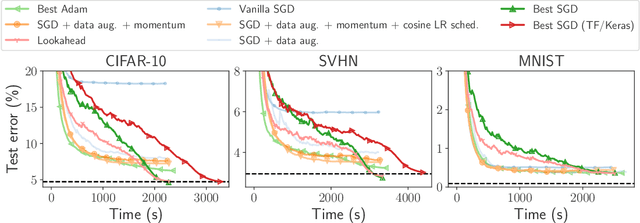
Numerical validation is at the core of machine learning research as it allows to assess the actual impact of new methods, and to confirm the agreement between theory and practice. Yet, the rapid development of the field poses several challenges: researchers are confronted with a profusion of methods to compare, limited transparency and consensus on best practices, as well as tedious re-implementation work. As a result, validation is often very partial, which can lead to wrong conclusions that slow down the progress of research. We propose Benchopt, a collaborative framework to automate, reproduce and publish optimization benchmarks in machine learning across programming languages and hardware architectures. Benchopt simplifies benchmarking for the community by providing an off-the-shelf tool for running, sharing and extending experiments. To demonstrate its broad usability, we showcase benchmarks on three standard learning tasks: $\ell_2$-regularized logistic regression, Lasso, and ResNet18 training for image classification. These benchmarks highlight key practical findings that give a more nuanced view of the state-of-the-art for these problems, showing that for practical evaluation, the devil is in the details. We hope that Benchopt will foster collaborative work in the community hence improving the reproducibility of research findings.
Realistic Ultrasound Image Synthesis for Improved Classification of Liver Disease
Jul 27, 2021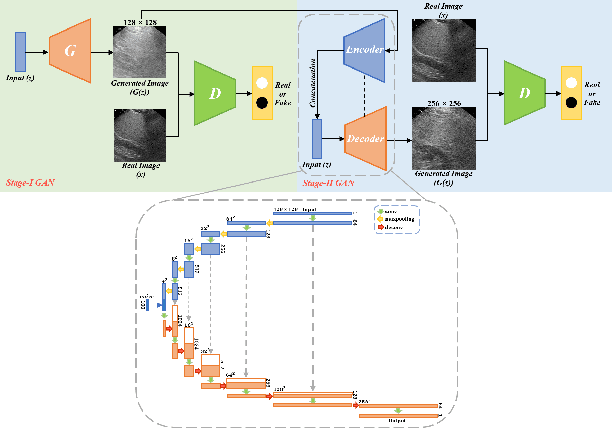

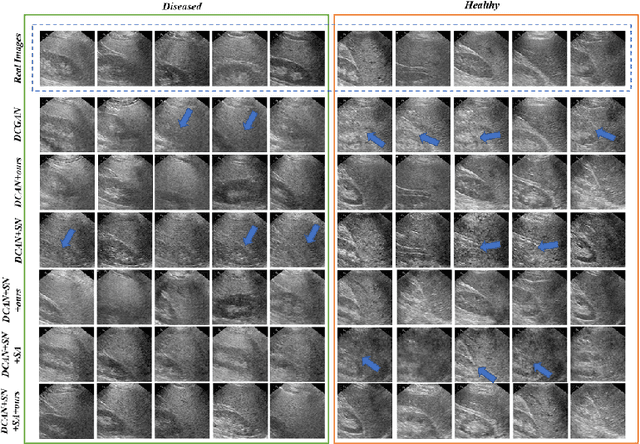
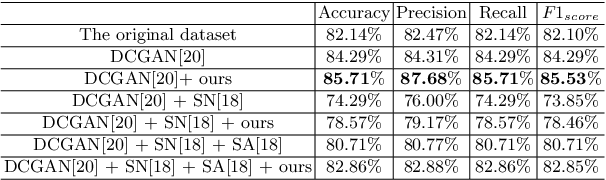
With the success of deep learning-based methods applied in medical image analysis, convolutional neural networks (CNNs) have been investigated for classifying liver disease from ultrasound (US) data. However, the scarcity of available large-scale labeled US data has hindered the success of CNNs for classifying liver disease from US data. In this work, we propose a novel generative adversarial network (GAN) architecture for realistic diseased and healthy liver US image synthesis. We adopt the concept of stacking to synthesize realistic liver US data. Quantitative and qualitative evaluation is performed on 550 in-vivo B-mode liver US images collected from 55 subjects. We also show that the synthesized images, together with real in vivo data, can be used to significantly improve the performance of traditional CNN architectures for Nonalcoholic fatty liver disease (NAFLD) classification.
PoCaP Corpus: A Multimodal Dataset for Smart Operating Room Speech Assistant using Interventional Radiology Workflow Analysis
Jun 24, 2022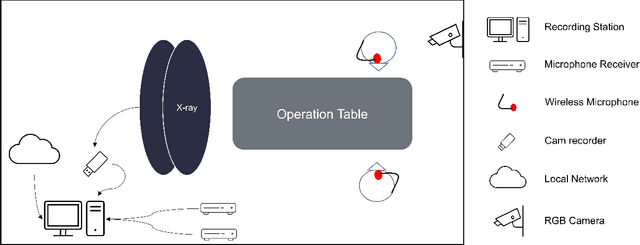
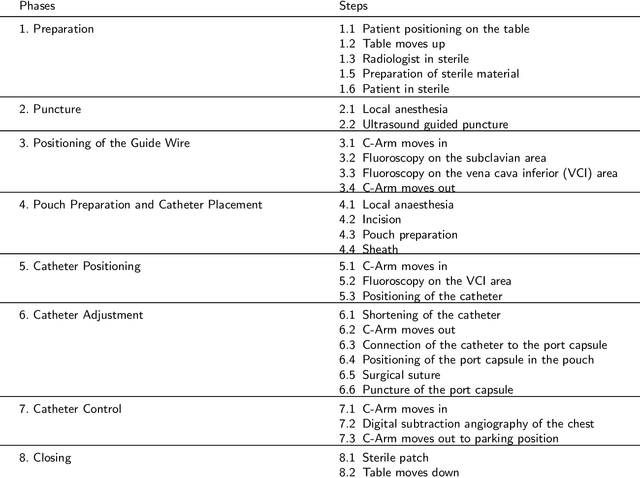
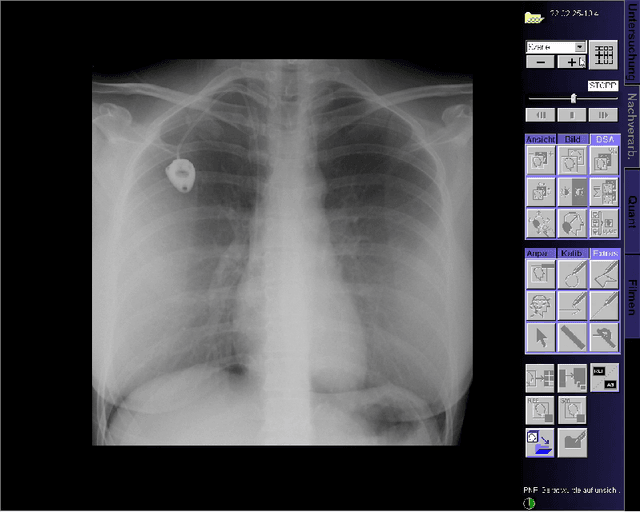

This paper presents a new multimodal interventional radiology dataset, called PoCaP (Port Catheter Placement) Corpus. This corpus consists of speech and audio signals in German, X-ray images, and system commands collected from 31 PoCaP interventions by six surgeons with average duration of 81.4 $\pm$ 41.0 minutes. The corpus aims to provide a resource for developing a smart speech assistant in operating rooms. In particular, it may be used to develop a speech controlled system that enables surgeons to control the operation parameters such as C-arm movements and table positions. In order to record the dataset, we acquired consent by the institutional review board and workers council in the University Hospital Erlangen and by the patients for data privacy. We describe the recording set-up, data structure, workflow and preprocessing steps, and report the first PoCaP Corpus speech recognition analysis results with 11.52 $\%$ word error rate using pretrained models. The findings suggest that the data has the potential to build a robust command recognition system and will allow the development of a novel intervention support systems using speech and image processing in the medical domain.
Data-Driven Interpolation for Super-Scarce X-Ray Computed Tomography
May 16, 2022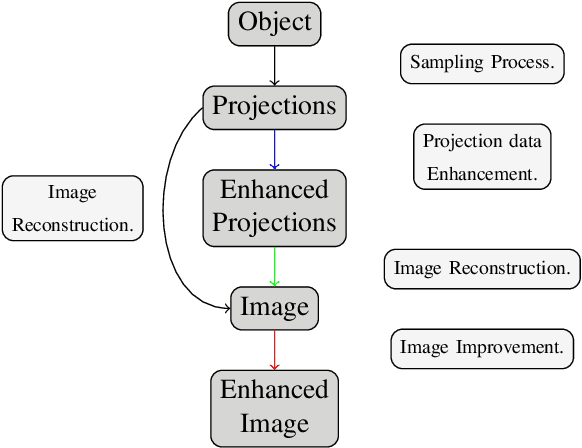
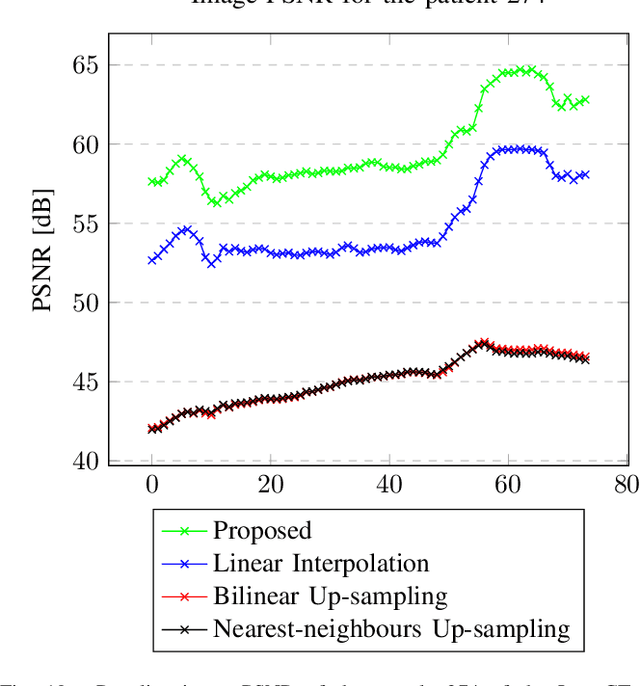
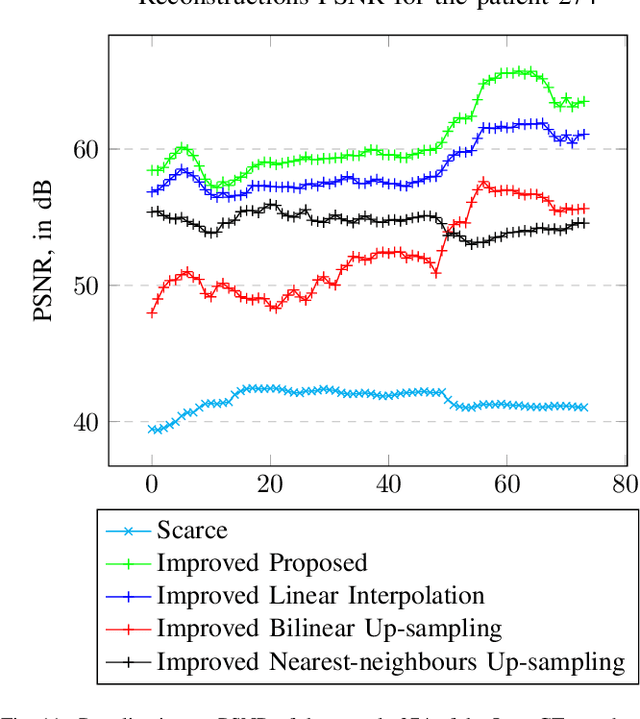
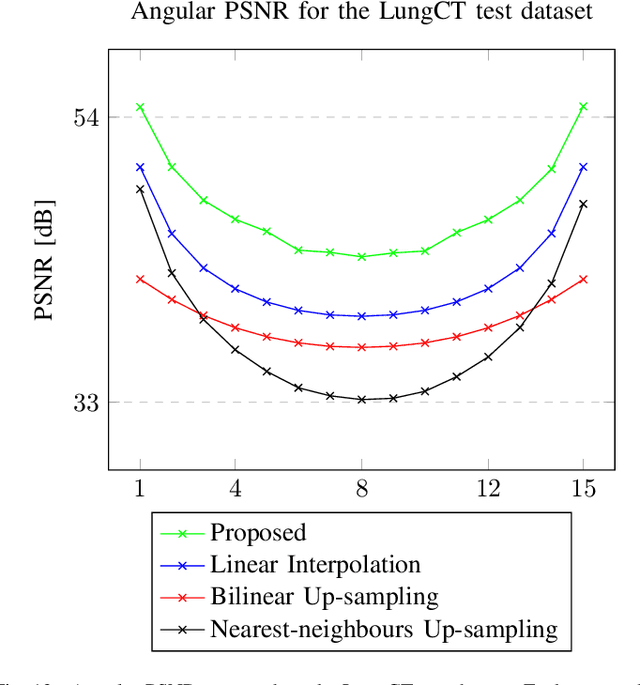
We address the problem of reconstructing X-Ray tomographic images from scarce measurements by interpolating missing acquisitions using a self-supervised approach. To do so, we train shallow neural networks to combine two neighbouring acquisitions into an estimated measurement at an intermediate angle. This procedure yields an enhanced sequence of measurements that can be reconstructed using standard methods, or further enhanced using regularisation approaches. Unlike methods that improve the sequence of acquisitions using an initial deterministic interpolation followed by machine-learning enhancement, we focus on inferring one measurement at once. This allows the method to scale to 3D, the computation to be faster and crucially, the interpolation to be significantly better than the current methods, when they exist. We also establish that a sequence of measurements must be processed as such, rather than as an image or a volume. We do so by comparing interpolation and up-sampling methods, and find that the latter significantly under-perform. We compare the performance of the proposed method against deterministic interpolation and up-sampling procedures and find that it outperforms them, even when used jointly with a state-of-the-art projection-data enhancement approach using machine-learning. These results are obtained for 2D and 3D imaging, on large biomedical datasets, in both projection space and image space.
Learning Discriminative Representations for Multi-Label Image Recognition
Jul 23, 2021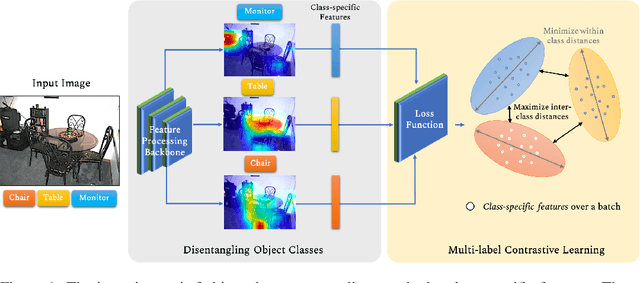
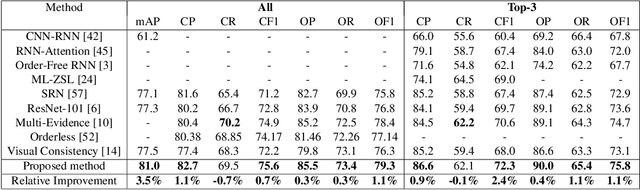
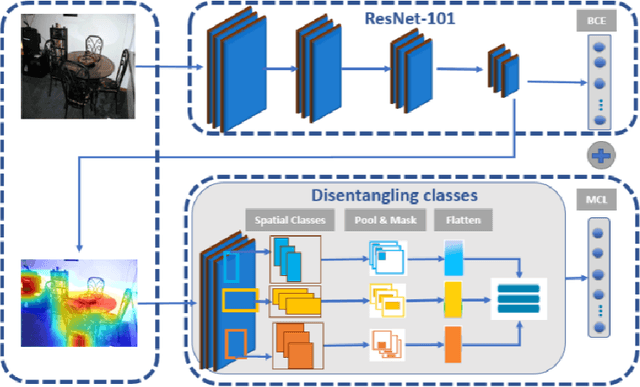
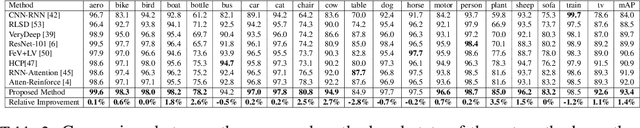
Multi-label recognition is a fundamental, and yet is a challenging task in computer vision. Recently, deep learning models have achieved great progress towards learning discriminative features from input images. However, conventional approaches are unable to model the inter-class discrepancies among features in multi-label images, since they are designed to work for image-level feature discrimination. In this paper, we propose a unified deep network to learn discriminative features for the multi-label task. Given a multi-label image, the proposed method first disentangles features corresponding to different classes. Then, it discriminates between these classes via increasing the inter-class distance while decreasing the intra-class differences in the output space. By regularizing the whole network with the proposed loss, the performance of applying the wellknown ResNet-101 is improved significantly. Extensive experiments have been performed on COCO-2014, VOC2007 and VOC2012 datasets, which demonstrate that the proposed method outperforms state-of-the-art approaches by a significant margin of 3:5% on large-scale COCO dataset. Moreover, analysis of the discriminative feature learning approach shows that it can be plugged into various types of multi-label methods as a general module.
SemAttNet: Towards Attention-based Semantic Aware Guided Depth Completion
Apr 28, 2022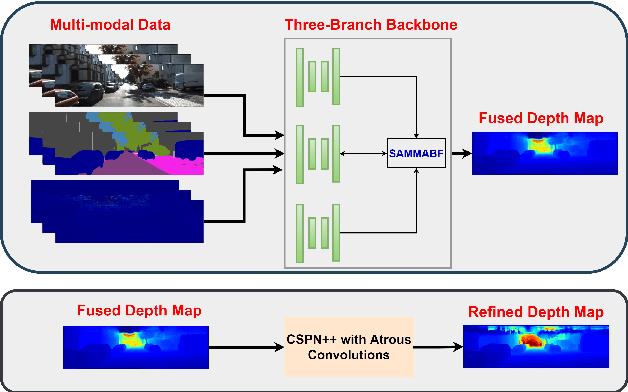
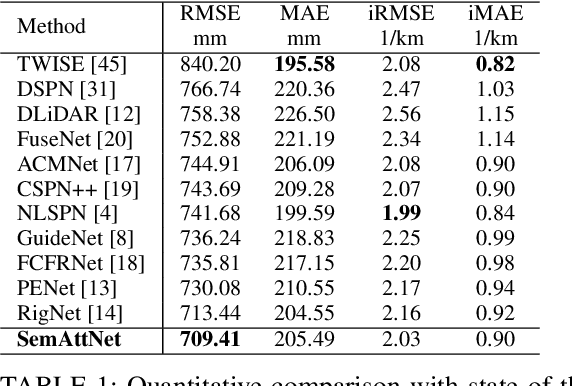

Depth completion involves recovering a dense depth map from a sparse map and an RGB image. Recent approaches focus on utilizing color images as guidance images to recover depth at invalid pixels. However, color images alone are not enough to provide the necessary semantic understanding of the scene. Consequently, the depth completion task suffers from sudden illumination changes in RGB images (e.g., shadows). In this paper, we propose a novel three-branch backbone comprising color-guided, semantic-guided, and depth-guided branches. Specifically, the color-guided branch takes a sparse depth map and RGB image as an input and generates color depth which includes color cues (e.g., object boundaries) of the scene. The predicted dense depth map of color-guided branch along-with semantic image and sparse depth map is passed as input to semantic-guided branch for estimating semantic depth. The depth-guided branch takes sparse, color, and semantic depths to generate the dense depth map. The color depth, semantic depth, and guided depth are adaptively fused to produce the output of our proposed three-branch backbone. In addition, we also propose to apply semantic-aware multi-modal attention-based fusion block (SAMMAFB) to fuse features between all three branches. We further use CSPN++ with Atrous convolutions to refine the dense depth map produced by our three-branch backbone. Extensive experiments show that our model achieves state-of-the-art performance in the KITTI depth completion benchmark at the time of submission.
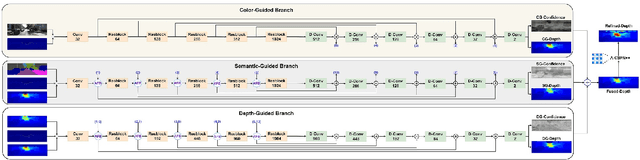
TraCon: A novel dataset for real-time traffic cones detection using deep learning
May 24, 2022



Substantial progress has been made in the field of object detection in road scenes. However, it is mainly focused on vehicles and pedestrians. To this end, we investigate traffic cone detection, an object category crucial for road effects and maintenance. In this work, the YOLOv5 algorithm is employed, in order to find a solution for the efficient and fast detection of traffic cones. The YOLOv5 can achieve a high detection accuracy with the score of IoU up to 91.31%. The proposed method is been applied to an RGB roadwork image dataset, collected from various sources.
Total Variation Optimization Layers for Computer Vision
Apr 07, 2022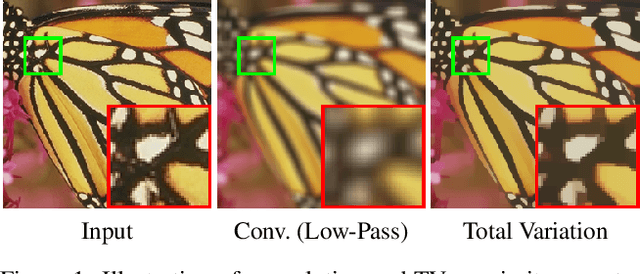



Optimization within a layer of a deep-net has emerged as a new direction for deep-net layer design. However, there are two main challenges when applying these layers to computer vision tasks: (a) which optimization problem within a layer is useful?; (b) how to ensure that computation within a layer remains efficient? To study question (a), in this work, we propose total variation (TV) minimization as a layer for computer vision. Motivated by the success of total variation in image processing, we hypothesize that TV as a layer provides useful inductive bias for deep-nets too. We study this hypothesis on five computer vision tasks: image classification, weakly supervised object localization, edge-preserving smoothing, edge detection, and image denoising, improving over existing baselines. To achieve these results we had to address question (b): we developed a GPU-based projected-Newton method which is $37\times$ faster than existing solutions.