 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LANTERN-RD: Enabling Deep Learning for Mitigation of the Invasive Spotted Lanternfly
May 12, 2022


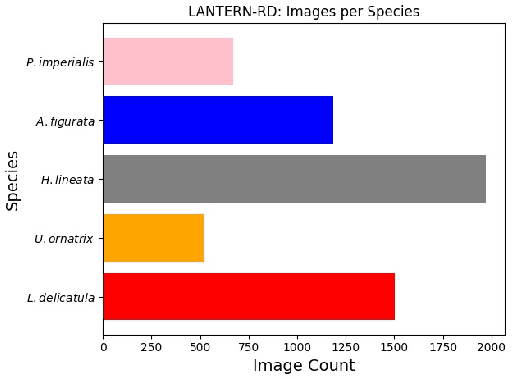
The Spotted Lanternfly (SLF) is an invasive planthopper that threatens the local biodiversity and agricultural economy of regions such as the Northeastern United States and Japan. As researchers scramble to study the insect, there is a great potential for computer vision tasks such as detection, pose estimation, and accurate identification to have important downstream implications in containing the SLF. However, there is currently no publicly available dataset for training such AI models. To enable computer vision applications and motivate advancements to challenge the invasive SLF problem, we propose LANTERN-RD, the first curated image dataset of the spotted lanternfly and its look-alikes, featuring images with varied lighting conditions, diverse backgrounds, and subjects in assorted poses. A VGG16-based baseline CNN validates the potential of this dataset for stimulating fresh computer vision applications to accelerate invasive SLF research. Additionally, we implement the trained model in a simple mobile classification application in order to directly empower responsible public mitigation efforts. The overarching mission of this work is to introduce a novel SLF image dataset and release a classification framework that enables computer vision applications, boosting studies surrounding the invasive SLF and assisting in minimizing its agricultural and economic damage.
Abandoning the Bayer-Filter to See in the Dark
Mar 22, 2022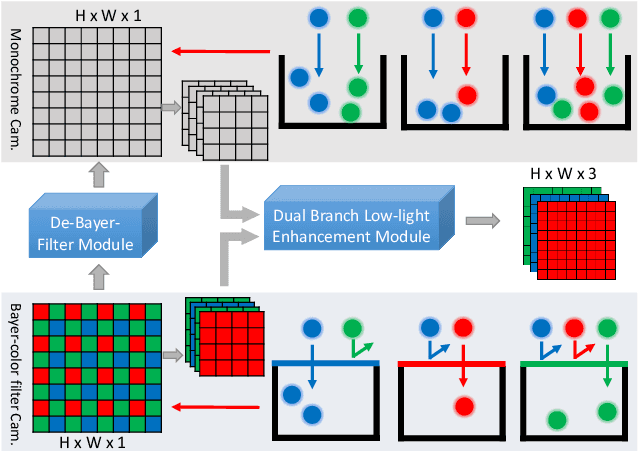


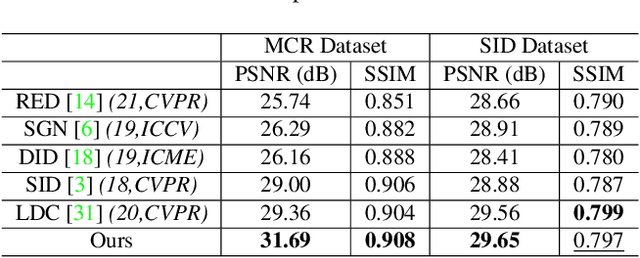
Low-light image enhancement - a pervasive but challenging problem, plays a central role in enhancing the visibility of an image captured in a poor illumination environment. Due to the fact that not all photons can pass the Bayer-Filter on the sensor of the color camera, in this work, we first present a De-Bayer-Filter simulator based on deep neural networks to generate a monochrome raw image from the colored raw image. Next, a fully convolutional network is proposed to achieve the low-light image enhancement by fusing colored raw data with synthesized monochrome raw data. Channel-wise attention is also introduced to the fusion process to establish a complementary interaction between features from colored and monochrome raw images. To train the convolutional networks, we propose a dataset with monochrome and color raw pairs named Mono-Colored Raw paired dataset (MCR) collected by using a monochrome camera without Bayer-Filter and a color camera with Bayer-Filter. The proposed pipeline take advantages of the fusion of the virtual monochrome and the color raw images and our extensive experiments indicate that significant improvement can be achieved by leveraging raw sensor data and data-driven learning.
Transform your Smartphone into a DSLR Camera: Learning the ISP in the Wild
Mar 22, 2022

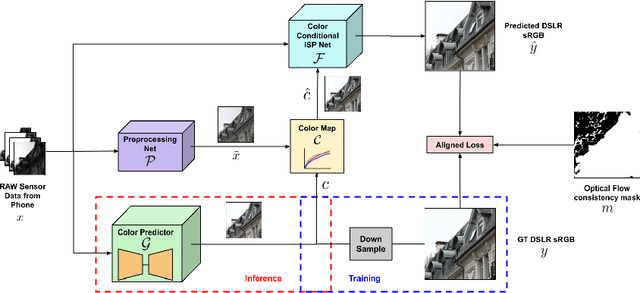

We propose a trainable Image Signal Processing (ISP) framework that produces DSLR quality images given RAW images captured by a smartphone. To address the color misalignments between training image pairs, we employ a color-conditional ISP network and optimize a novel parametric color mapping between each input RAW and reference DSLR image. During inference, we predict the target color image by designing a color prediction network with efficient Global Context Transformer modules. The latter effectively leverage global information to learn consistent color and tone mappings. We further propose a robust masked aligned loss to identify and discard regions with inaccurate motion estimation during training. Lastly, we introduce the ISP in the Wild (ISPW) dataset, consisting of weakly paired phone RAW and DSLR sRGB images. We extensively evaluate our method, setting a new state-of-the-art on two datasets.
A Hierarchical Multi-Task Approach to Gastrointestinal Image Analysis
Nov 16, 2021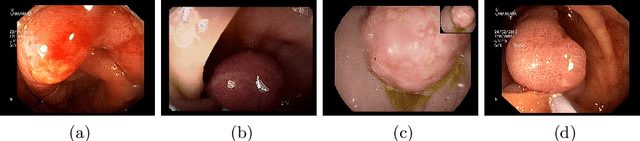
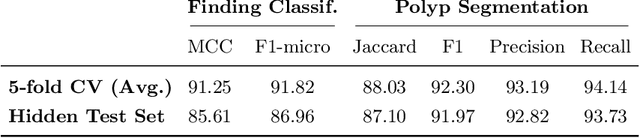
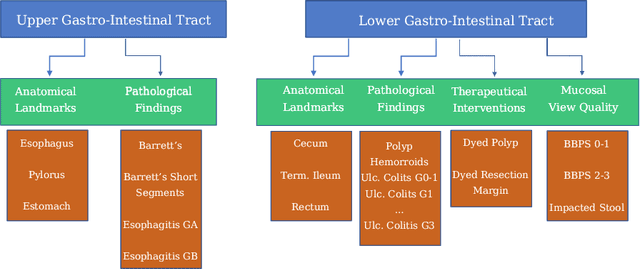
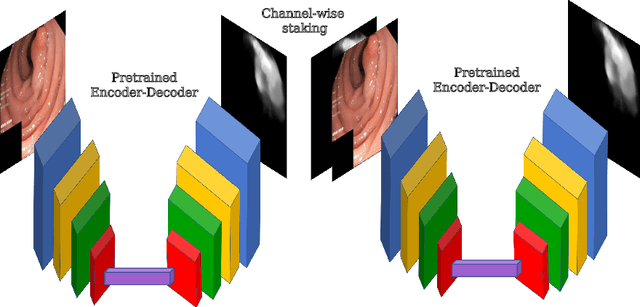
A large number of different lesions and pathologies can affect the human digestive system, resulting in life-threatening situations. Early detection plays a relevant role in the successful treatment and the increase of current survival rates to, e.g., colorectal cancer. The standard procedure enabling detection, endoscopic video analysis, generates large quantities of visual data that need to be carefully analyzed by an specialist. Due to the wide range of color, shape, and general visual appearance of pathologies, as well as highly varying image quality, such process is greatly dependent on the human operator experience and skill. In this work, we detail our solution to the task of multi-category classification of images from the gastrointestinal (GI) human tract within the 2020 Endotect Challenge. Our approach is based on a Convolutional Neural Network minimizing a hierarchical error function that takes into account not only the finding category, but also its location within the GI tract (lower/upper tract), and the type of finding (pathological finding/therapeutic intervention/anatomical landmark/mucosal views' quality). We also describe in this paper our solution for the challenge task of polyp segmentation in colonoscopies, which was addressed with a pretrained double encoder-decoder network. Our internal cross-validation results show an average performance of 91.25 Mathews Correlation Coefficient (MCC) and 91.82 Micro-F1 score for the classification task, and a 92.30 F1 score for the polyp segmentation task. The organization provided feedback on the performance in a hidden test set for both tasks, which resulted in 85.61 MCC and 86.96 F1 score for classification, and 91.97 F1 score for polyp segmentation. At the time of writing no public ranking for this challenge had been released.
Multi-Prior Learning via Neural Architecture Search for Blind Face Restoration
Jun 28, 2022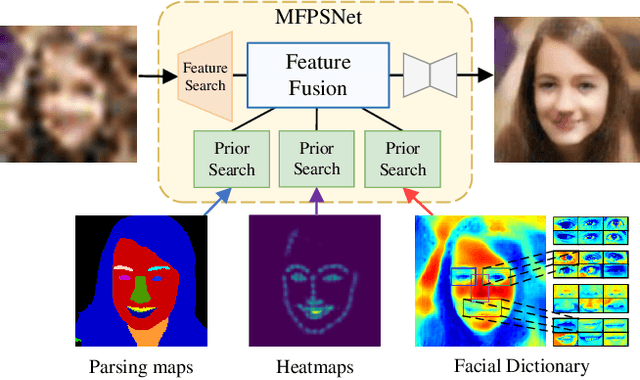
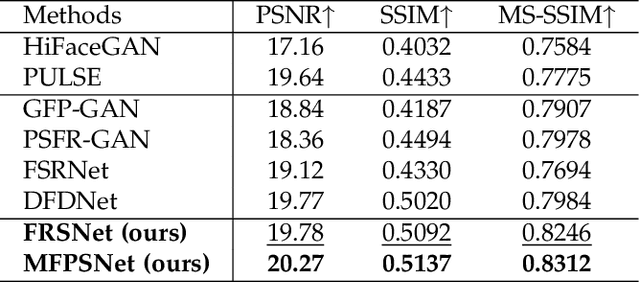
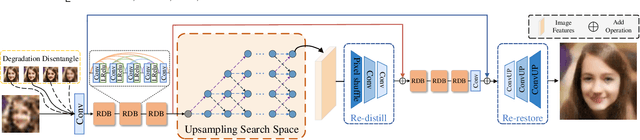
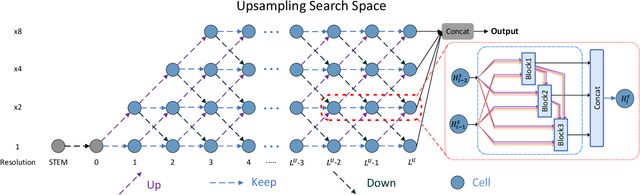
Blind Face Restoration (BFR) aims to recover high-quality face images from low-quality ones and usually resorts to facial priors for improving restoration performance. However, current methods still suffer from two major difficulties: 1) how to derive a powerful network architecture without extensive hand tuning; 2) how to capture complementary information from multiple facial priors in one network to improve restoration performance. To this end, we propose a Face Restoration Searching Network (FRSNet) to adaptively search the suitable feature extraction architecture within our specified search space, which can directly contribute to the restoration quality. On the basis of FRSNet, we further design our Multiple Facial Prior Searching Network (MFPSNet) with a multi-prior learning scheme. MFPSNet optimally extracts information from diverse facial priors and fuses the information into image features, ensuring that both external guidance and internal features are reserved. In this way, MFPSNet takes full advantage of semantic-level (parsing maps), geometric-level (facial heatmaps), reference-level (facial dictionaries) and pixel-level (degraded images) information and thus generates faithful and realistic images. Quantitative and qualitative experiments show that MFPSNet performs favorably on both synthetic and real-world datasets against the state-of-the-art BFR methods. The codes are publicly available at: https://github.com/YYJ1anG/MFPSNet.
Lesion classification by model-based feature extraction: A differential affine invariant model of soft tissue elasticity
May 27, 2022
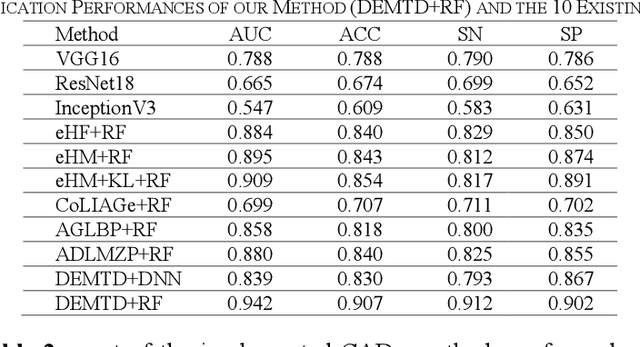
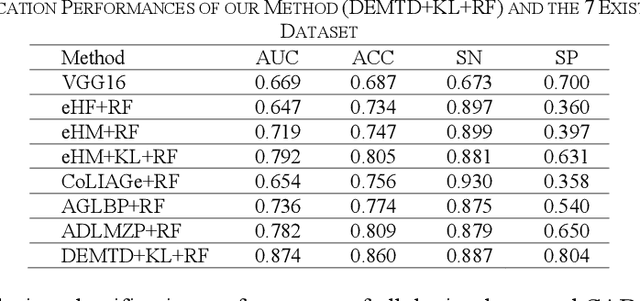
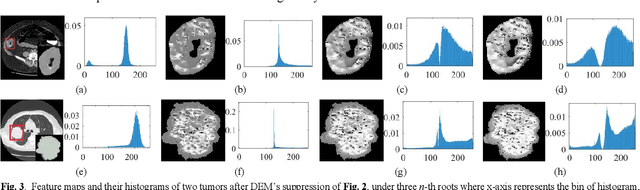
The elasticity of soft tissues has been widely considered as a characteristic property to differentiate between healthy and vicious tissues and, therefore, motivated several elasticity imaging modalities, such as Ultrasound Elastography, Magnetic Resonance Elastography, and Optical Coherence Elastography. This paper proposes an alternative approach of modeling the elasticity using Computed Tomography (CT) imaging modality for model-based feature extraction machine learning (ML) differentiation of lesions. The model describes a dynamic non-rigid (or elastic) deformation in differential manifold to mimic the soft tissues elasticity under wave fluctuation in vivo. Based on the model, three local deformation invariants are constructed by two tensors defined by the first and second order derivatives from the CT images and used to generate elastic feature maps after normalization via a novel signal suppression method. The model-based elastic image features are extracted from the feature maps and fed to machine learning to perform lesion classifications. Two pathologically proven image datasets of colon polyps (44 malignant and 43 benign) and lung nodules (46 malignant and 20 benign) were used to evaluate the proposed model-based lesion classification. The outcomes of this modeling approach reached the score of area under the curve of the receiver operating characteristics of 94.2 % for the polyps and 87.4 % for the nodules, resulting in an average gain of 5 % to 30 % over ten existing state-of-the-art lesion classification methods. The gains by modeling tissue elasticity for ML differentiation of lesions are striking, indicating the great potential of exploring the modeling strategy to other tissue properties for ML differentiation of lesions.
Efficient Training of 3D Seismic Image Fault Segmentation Network under Sparse Labels by Weakening Anomaly Annotation
Oct 19, 2021
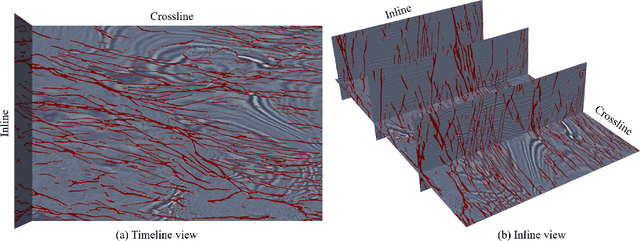


Seismic data fault detection has recently been regarded as a 3D image segmentation task. The nature of fault structures in seismic image makes it difficult to manually label faults. Manual labeling often has many false negative labels (abnormal annotations), which will seriously jeopardize the training process. In this work, we find that region-based loss significantly outperforms distribution-based loss when dealing with false negative labels, therefore we proposed Mask Dice loss (MD loss), which is the first reported region-based loss function for training 3D image segmentation networks using sparse 2D slice labels. In addition, fault is an edge feature, and the current network widely used for fault segmentation downsamples the features multiple times, which is not conducive to edge representation and thus requires many parameters and computational effort to preserve the features. We proposed Fault-Net, which uses a high-resolution and shallow structure to propagate multi-scale features in parallel, fully preserving edge features. Meanwhile, in order to efficiently fuse multiscale features, we decouple the convolution process into feature selection and channel fusion, and proposed a lightweight feature fusion block, Multi-Scale Compression Fusion (MCF). Because the Fault-Net always keeps the edge features during propagation, only few parameters and computation are required. Experimental results show that MD loss can clearly weaken the effect of false negative labels. The Fault-Net parameter is only 0.42MB, support up to 528^3(1.5x10^8, Float32) size cuboid inference on 16GB video ram, its inference speed on CPU and GPU is significantly faster than other networks. It works well on most of the open data seismic images, and the result of our approach is state-ofthe-art in FORCE fault identification competition.
Self-Supervised Training with Autoencoders for Visual Anomaly Detection
Jun 28, 2022


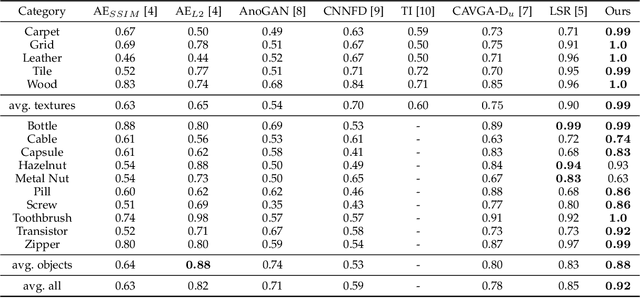
Deep convolutional autoencoders provide an effective tool for learning non-linear dimensionality reduction in an unsupervised way. Recently, they have been used for the task of anomaly detection in the visual domain. By optimising for the reconstruction error using anomaly-free examples, the common belief is that a trained network will have difficulties to reconstruct anomalous parts during the test phase. This is usually done by controlling the capacity of the network by either reducing the size of the bottleneck layer or enforcing sparsity constraints on its activations. However, neither of these techniques does explicitly penalise reconstruction of anomalous signals often resulting in a poor detection. We tackle this problem by adapting a self-supervised learning regime which allows to use discriminative information during training while regularising the model to focus on the data manifold by means of a modified reconstruction error resulting in an accurate detection. Unlike related approaches, the inference of the proposed method during training and prediction is very efficient processing the whole input image in one single step. Our experiments on the MVTec Anomaly Detection dataset demonstrate high recognition and localisation performance of the proposed method. On the texture-subset, in particular, our approach consistently outperforms a bunch of recent anomaly detection methods by a big margin.
Single Image Depth Estimation: An Overview
Apr 13, 2021
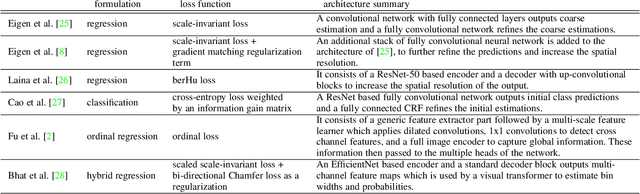

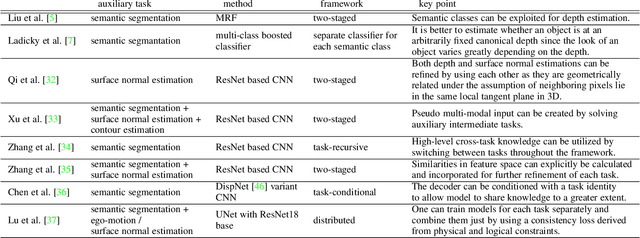
We review solutions to the problem of depth estimation, arguably the most important subtask in scene understanding. We focus on the single image depth estimation problem. Due to its properties, the single image depth estimation problem is currently best tackled with machine learning methods, most successfully with convolutional neural networks. We provide an overview of the field by examining key works. We examine non-deep learning approaches that mostly predate deep learning and utilize hand-crafted features and assumptions, and more recent works that mostly use deep learning techniques. The single image depth estimation problem is tackled first in a supervised fashion with absolute or relative depth information acquired from human or sensor-labeled data, or in an unsupervised way using unlabelled stereo images or video datasets. We also study multitask approaches that combine the depth estimation problem with related tasks such as semantic segmentation and surface normal estimation. Finally, we discuss investigations into the mechanisms, principles, and failure cases of contemporary solutions.
Fingerprint Template Invertibility: Minutiae vs. Deep Templates
May 08, 2022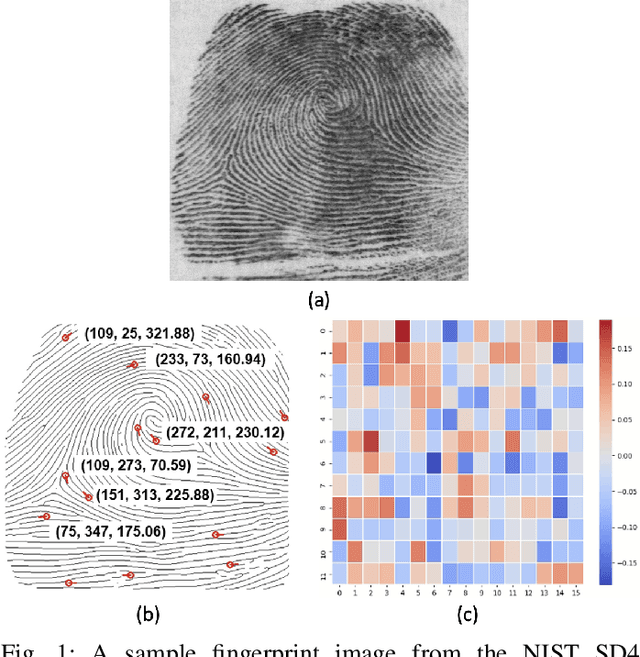

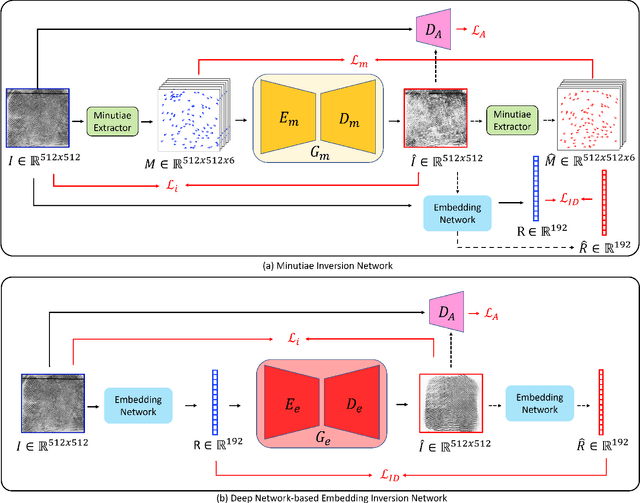

Much of the success of fingerprint recognition is attributed to minutiae-based fingerprint representation. It was believed that minutiae templates could not be inverted to obtain a high fidelity fingerprint image, but this assumption has been shown to be false. The success of deep learning has resulted in alternative fingerprint representations (embeddings), in the hope that they might offer better recognition accuracy as well as non-invertibility of deep network-based templates. We evaluate whether deep fingerprint templates suffer from the same reconstruction attacks as the minutiae templates. We show that while a deep template can be inverted to produce a fingerprint image that could be matched to its source image, deep templates are more resistant to reconstruction attacks than minutiae templates. In particular, reconstructed fingerprint images from minutiae templates yield a TAR of about 100.0% (98.3%) @ FAR of 0.01% for type-I (type-II) attacks using a state-of-the-art commercial fingerprint matcher, when tested on NIST SD4. The corresponding attack performance for reconstructed fingerprint images from deep templates using the same commercial matcher yields a TAR of less than 1% for both type-I and type-II attacks; however, when the reconstructed images are matched using the same deep network, they achieve a TAR of 85.95% (68.10%) for type-I (type-II) attacks. Furthermore, what is missing from previous fingerprint template inversion studies is an evaluation of the black-box attack performance, which we perform using 3 different state-of-the-art fingerprint matchers. We conclude that fingerprint images generated by inverting minutiae templates are highly susceptible to both white-box and black-box attack evaluations, while fingerprint images generated by deep templates are resistant to black-box evaluations and comparatively less susceptible to white-box evaluations.