 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Can Push-forward Generative Models Fit Multimodal Distributions?
Jun 29, 2022
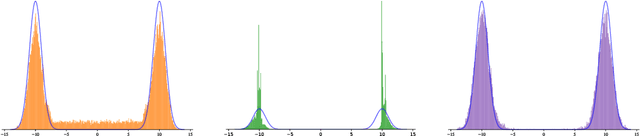
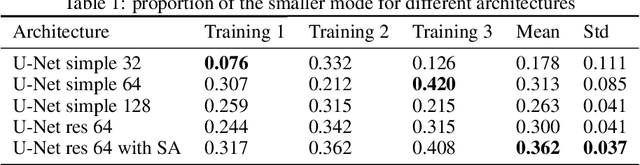
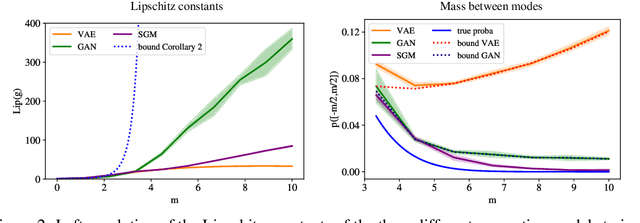

Many generative models synthesize data by transforming a standard Gaussian random variable using a deterministic neural network. Among these models are the Variational Autoencoders and the Generative Adversarial Networks. In this work, we call them "push-forward" models and study their expressivity. We show that the Lipschitz constant of these generative networks has to be large in order to fit multimodal distributions. More precisely, we show that the total variation distance and the Kullback-Leibler divergence between the generated and the data distribution are bounded from below by a constant depending on the mode separation and the Lipschitz constant. Since constraining the Lipschitz constants of neural networks is a common way to stabilize generative models, there is a provable trade-off between the ability of push-forward models to approximate multimodal distributions and the stability of their training. We validate our findings on one-dimensional and image datasets and empirically show that generative models consisting of stacked networks with stochastic input at each step, such as diffusion models do not suffer of such limitations.
Alternating direction method of multipliers applied to medical image restoration
Jul 04, 2021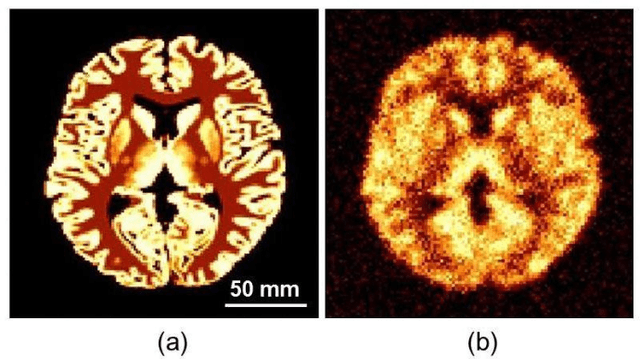
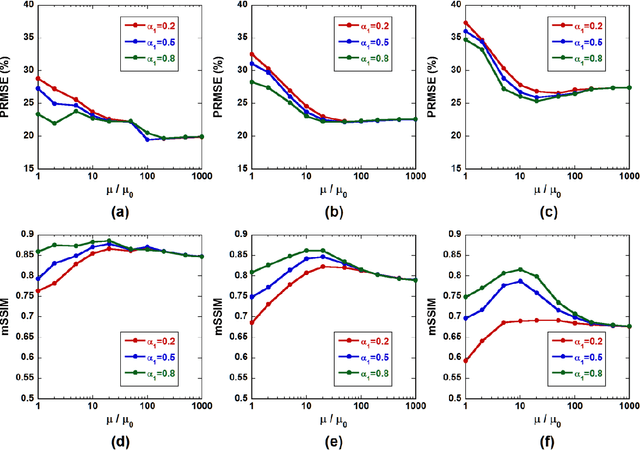
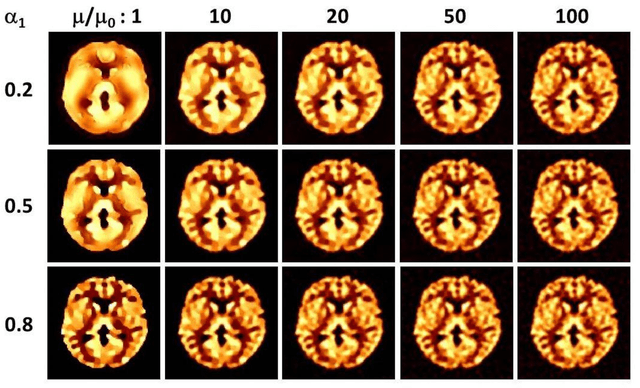
We investigate the effects of the regularization parameter for the norm () and penalty parameter () in the alternating direction method of multipliers (ADMM) on the quality of restored medical images. Simulation studies are performed using images degraded by a point spread function (PSF) and Gaussian noise. The j-th column of the system matrix () is calculated by convolving the image with unity at pixel j and zero at all other pixels and the PSF. The simulation studies show that the mean structural similarity index is maximal when is approximately 10 to 20, where , with and being the transpose of A and the observed data, respectively. The restored image became blurred with a decrease in . This study will be useful for identifying optimal parameter values in the ADMM when applied to medical image restoration.
Multitask vocal burst modeling with ResNets and pre-trained paralinguistic Conformers
Jun 24, 2022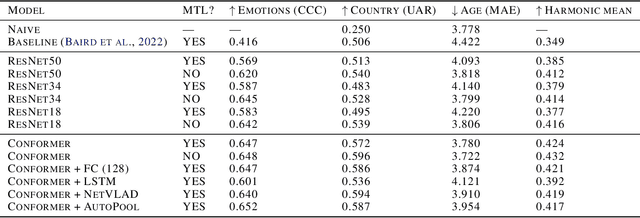
This technical report presents the modeling approaches used in our submission to the ICML Expressive Vocalizations Workshop & Competition multitask track (ExVo-MultiTask). We first applied image classification models of various sizes on mel-spectrogram representations of the vocal bursts, as is standard in sound event detection literature. Results from these models show an increase of 21.24% over the baseline system with respect to the harmonic mean of the task metrics, and comprise our team's main submission to the MultiTask track. We then sought to characterize the headroom in the MultiTask track by applying a large pre-trained Conformer model that previously achieved state-of-the-art results on paralinguistic tasks like speech emotion recognition and mask detection. We additionally investigated the relationship between the sub-tasks of emotional expression, country of origin, and age prediction, and discovered that the best performing models are trained as single-task models, questioning whether the problem truly benefits from a multitask setting.
Data variation-aware medical image segmentation
Feb 24, 2022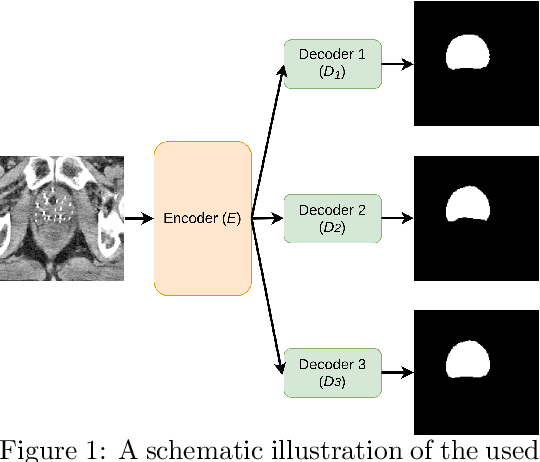
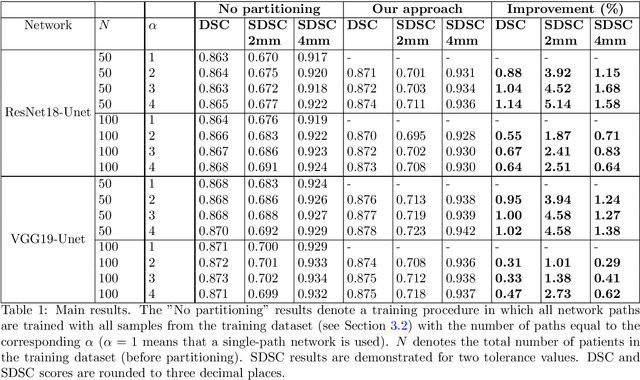
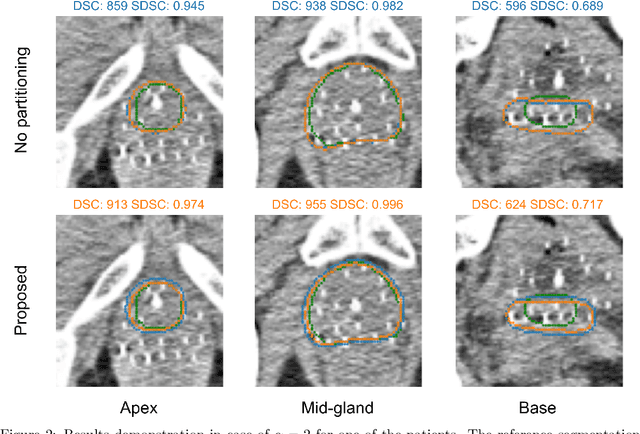
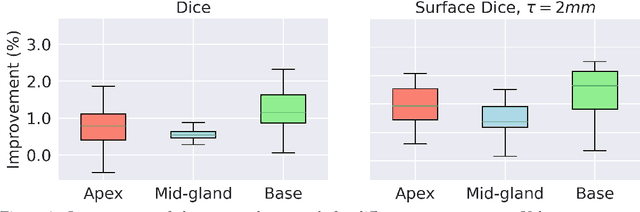
Deep learning algorithms have become the golden standard for segmentation of medical imaging data. In most works, the variability and heterogeneity of real clinical data is acknowledged to still be a problem. One way to automatically overcome this is to capture and exploit this variation explicitly. Here, we propose an approach that improves on our previous work in this area and explain how it potentially can improve clinical acceptance of (semi-)automatic segmentation methods. In contrast to a standard neural network that produces one segmentation, we propose to use a multi-pathUnet network that produces multiple segmentation variants, presumably corresponding to the variations that reside in the dataset. Different paths of the network are trained on disjoint data subsets. Because a priori it may be unclear what variations exist in the data, the subsets should be automatically determined. This is achieved by searching for the best data partitioning with an evolutionary optimization algorithm. Because each network path can become more specialized when trained on a more homogeneous data subset, better segmentation quality can be achieved. In practical usage, various automatically produced segmentations can be presented to a medical expert, from which the preferred segmentation can be selected. In experiments with a real clinical dataset of CT scans with prostate segmentations, our approach provides an improvement of several percentage points in terms of Dice and surface Dice coefficients compared to when all network paths are trained on all training data. Noticeably, the largest improvement occurs in the upper part of the prostate that is known to be most prone to inter-observer segmentation variation.
Magnification-independent Histopathological Image Classification with Similarity-based Multi-scale Embeddings
Jul 02, 2021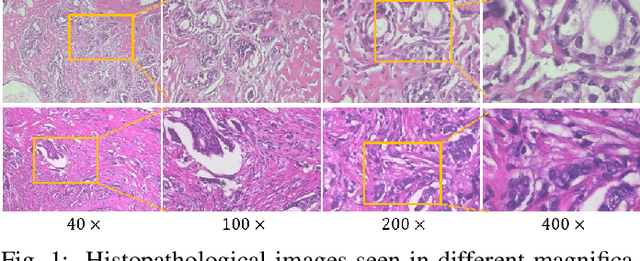
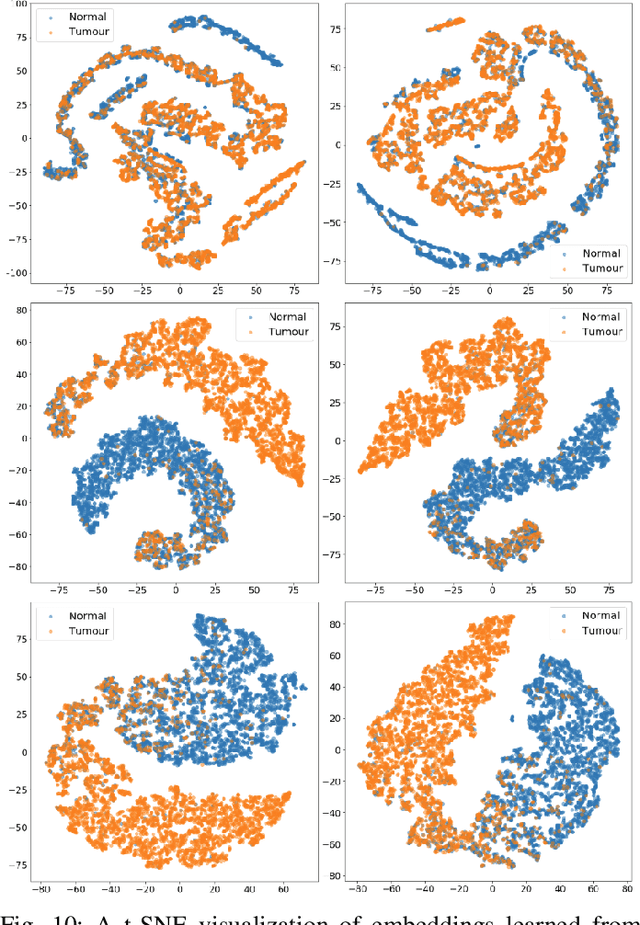
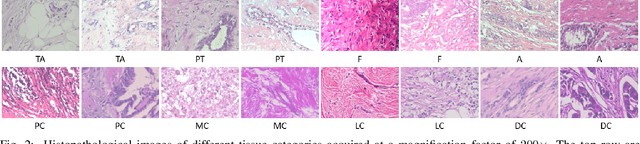
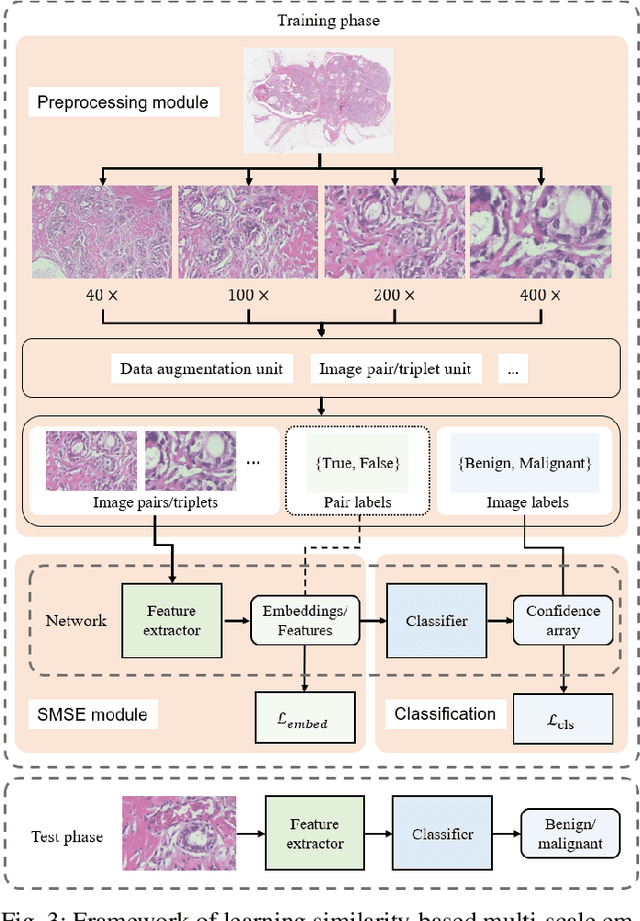
The classification of histopathological images is of great value in both cancer diagnosis and pathological studies. However, multiple reasons, such as variations caused by magnification factors and class imbalance, make it a challenging task where conventional methods that learn from image-label datasets perform unsatisfactorily in many cases. We observe that tumours of the same class often share common morphological patterns. To exploit this fact, we propose an approach that learns similarity-based multi-scale embeddings (SMSE) for magnification-independent histopathological image classification. In particular, a pair loss and a triplet loss are leveraged to learn similarity-based embeddings from image pairs or image triplets. The learned embeddings provide accurate measurements of similarities between images, which are regarded as a more effective form of representation for histopathological morphology than normal image features. Furthermore, in order to ensure the generated models are magnification-independent, images acquired at different magnification factors are simultaneously fed to networks during training for learning multi-scale embeddings. In addition to the SMSE, to eliminate the impact of class imbalance, instead of using the hard sample mining strategy that intuitively discards some easy samples, we introduce a new reinforced focal loss to simultaneously punish hard misclassified samples while suppressing easy well-classified samples. Experimental results show that the SMSE improves the performance for histopathological image classification tasks for both breast and liver cancers by a large margin compared to previous methods. In particular, the SMSE achieves the best performance on the BreakHis benchmark with an improvement ranging from 5% to 18% compared to previous methods using traditional features.
A Comprehensive Review of Image Analysis Methods for Microorganism Counting: From Classical Image Processing to Deep Learning Approaches
Mar 25, 2021
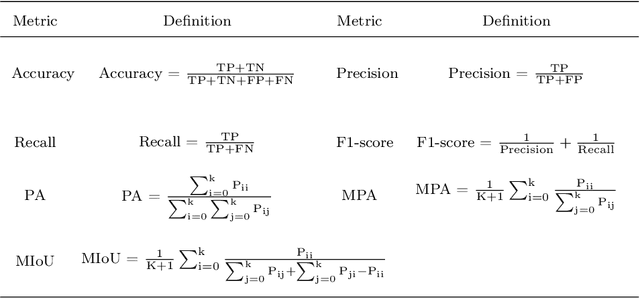
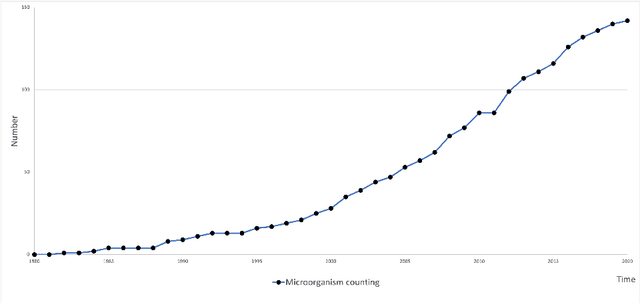
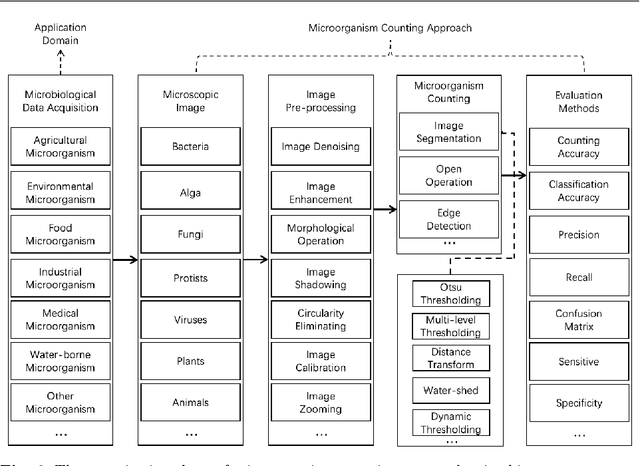
Microorganisms such as bacteria and fungi play essential roles in many application fields, like biotechnique, medical technique and industrial domain. Microorganism counting techniques are crucial in microorganism analysis, helping biologists and related researchers quantitatively analyze the microorganisms and calculate their characteristics, such as biomass concentration and biological activity. However, traditional microorganism manual counting methods are time consuming and subjective, which cannot be applied in large-scale applications. In order to improve this situation, image analysis-based microorganism counting systems are developed since 1980s, which consists of digital image processing, image segmentation, image classification and so on. Moreover, image analysis-based microorganism counting methods are efficient comparing with traditional plate counting methods. In this article, we have studied the development of microorganism counting methods using digital image analysis. Firstly, the microorganisms are grouped as bacteria and other microorganisms. Then, the related articles are summarized based on image segmentation methods. Each part of articles are reviewed by time periods. Moreover, commonly used image processing methods for microorganism counting are summarized and analyzed to find technological common points. More than 142 papers are summarized in this article. In conclusion, this article can be referred to researchers to determine the development trend in microorganism counting field and further analyze the potential applications
Automated Detection of Label Errors in Semantic Segmentation Datasets via Deep Learning and Uncertainty Quantification
Jul 13, 2022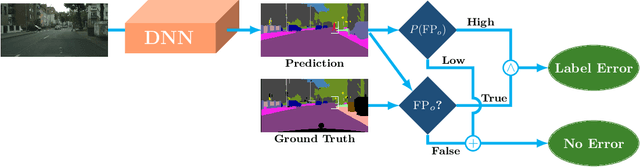
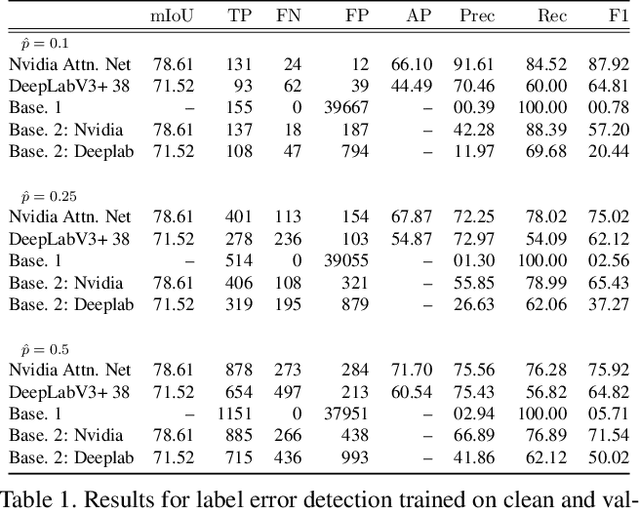
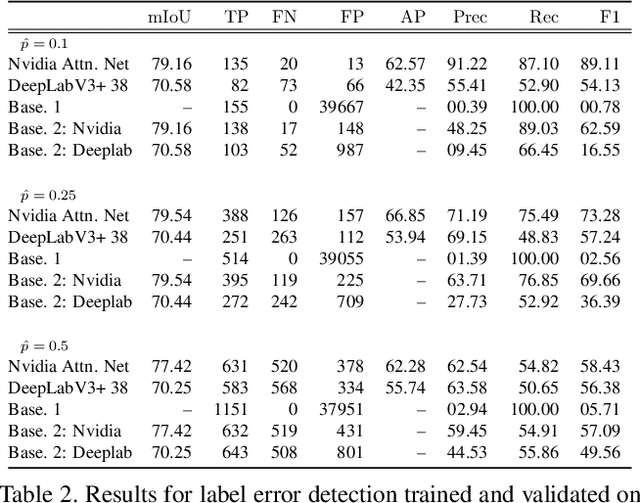
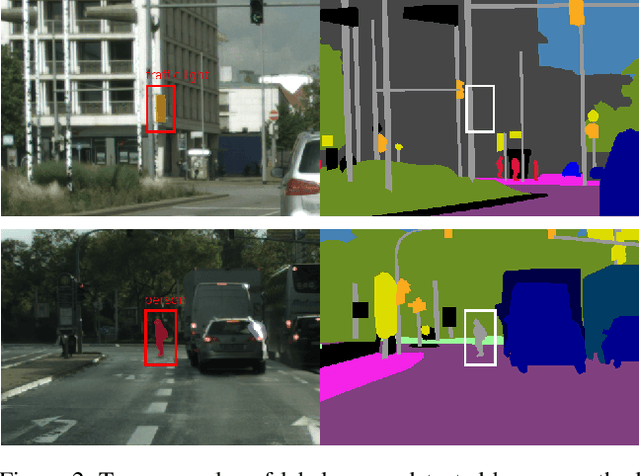
In this work, we for the first time present a method for detecting label errors in image datasets with semantic segmentation, i.e., pixel-wise class labels. Annotation acquisition for semantic segmentation datasets is time-consuming and requires plenty of human labor. In particular, review processes are time consuming and label errors can easily be overlooked by humans. The consequences are biased benchmarks and in extreme cases also performance degradation of deep neural networks (DNNs) trained on such datasets. DNNs for semantic segmentation yield pixel-wise predictions, which makes detection of label errors via uncertainty quantification a complex task. Uncertainty is particularly pronounced at the transitions between connected components of the prediction. By lifting the consideration of uncertainty to the level of predicted components, we enable the usage of DNNs together with component-level uncertainty quantification for the detection of label errors. We present a principled approach to benchmarking the task of label error detection by dropping labels from the Cityscapes dataset as well from a dataset extracted from the CARLA driving simulator, where in the latter case we have the labels under control. Our experiments show that our approach is able to detect the vast majority of label errors while controlling the number of false label error detections. Furthermore, we apply our method to semantic segmentation datasets frequently used by the computer vision community and present a collection of label errors along with sample statistics.
Image Steganography based on Iteratively Adversarial Samples of A Synchronized-directions Sub-image
Jan 13, 2021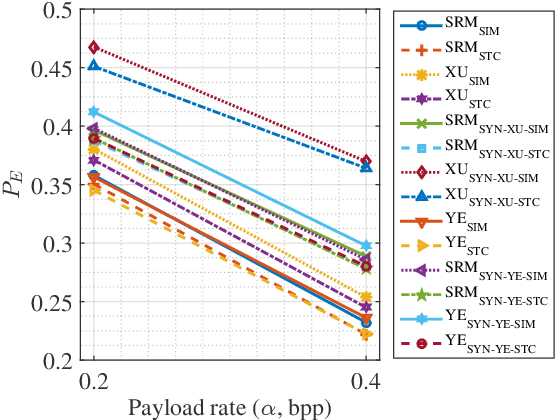
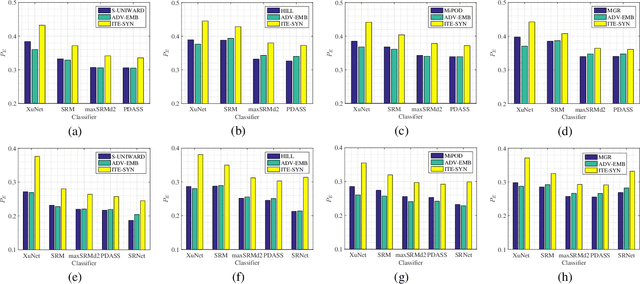
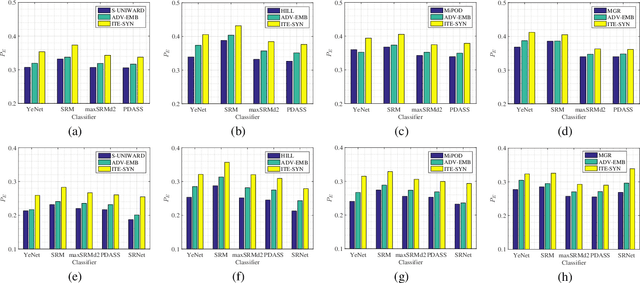
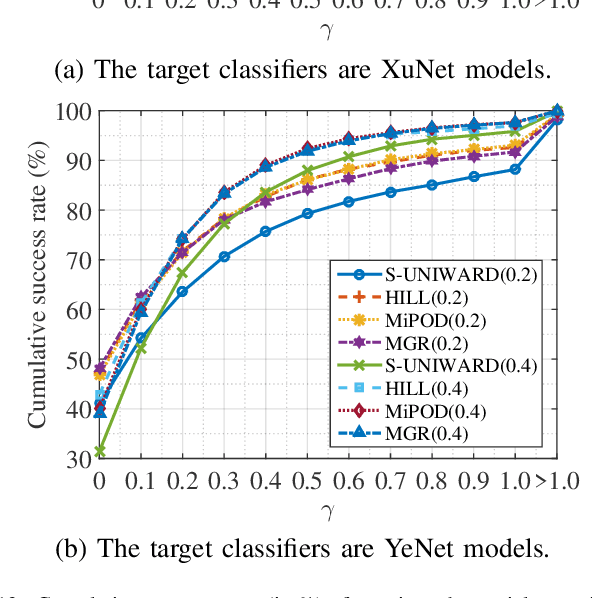
Nowadays a steganography has to face challenges of both feature based staganalysis and convolutional neural network (CNN) based steganalysis. In this paper, we present a novel steganography scheme denoted as ITE-SYN (based on ITEratively adversarial perturbations onto a SYNchronized-directions sub-image), by which security data is embedded with synchronizing modification directions to enhance security and then iteratively increased perturbations are added onto a sub-image to reduce loss with cover class label of the target CNN classifier. Firstly an exist steganographic function is employed to compute initial costs. Then the cover image is decomposed into some non-overlapped sub-images. After each sub-image is embedded, costs will be adjusted following clustering modification directions profile. And then the next sub-image will be embedded with adjusted costs until all secret data has been embedded. If the target CNN classifier does not discriminate the stego image as a cover image, based on adjusted costs, we change costs with adversarial manners according to signs of gradients back-propagated from the CNN classifier. And then a sub-image is chosen to be re-embedded with changed costs. Adversarial intensity will be iteratively increased until the adversarial stego image can fool the target CNN classifier. Experiments demonstrate that the proposed method effectively enhances security to counter both conventional feature-based classifiers and CNN classifiers, even other non-target CNN classifiers.
PS$^2$F: Polarized Spiral Point Spread Function for Single-Shot 3D Sensing
Jul 03, 2022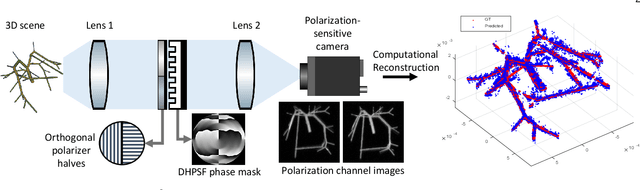
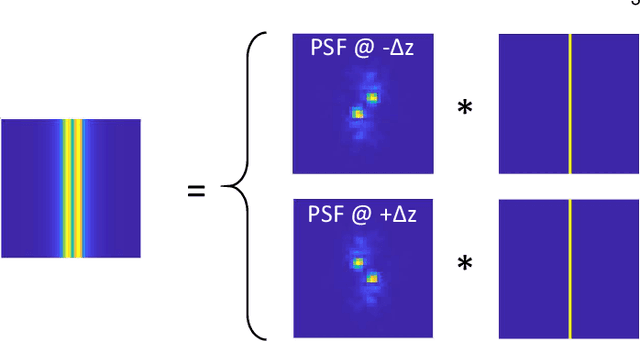
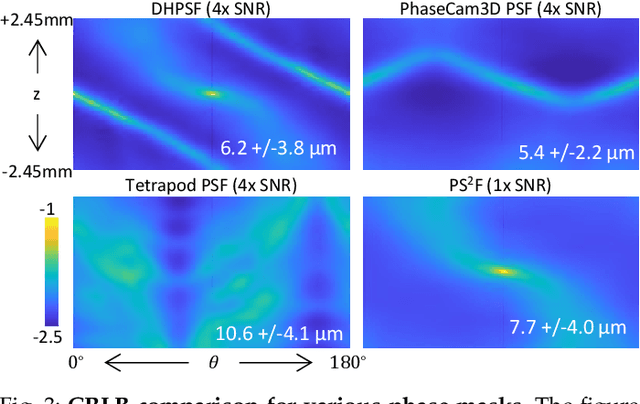
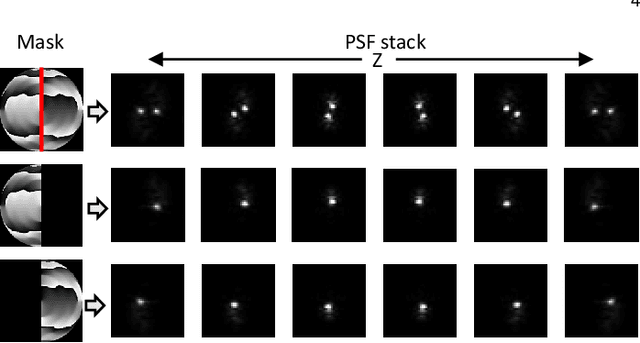
We propose a compact snapshot monocular depth estimation technique that relies on an engineered point spread function (PSF). Traditional approaches used in microscopic super-resolution imaging, such as the Double-Helix PSF (DHPSF), are ill-suited for scenes that are more complex than a sparse set of point light sources. We show, using the Cram\'er-Rao lower bound (CRLB), that separating the two lobes of the DHPSF and thereby capturing two separate images leads to a dramatic increase in depth accuracy. A unique property of the phase mask used for generating the DHPSF is that a separation of the phase mask into two halves leads to a spatial separation of the two lobes. We leverage this property to build a compact polarization-based optical setup, where we place two orthogonal linear polarizers on each half of the DHPSF phase mask and then capture the resulting image with a polarization sensitive camera. Results from simulations and a lab prototype demonstrate that our technique achieves up to $50\%$ lower depth error compared to state-of-the-art designs including the DHPSF, and the Tetrapod PSF, with little to no loss in spatial resolution.
MOST-GAN: 3D Morphable StyleGAN for Disentangled Face Image Manipulation
Nov 01, 2021

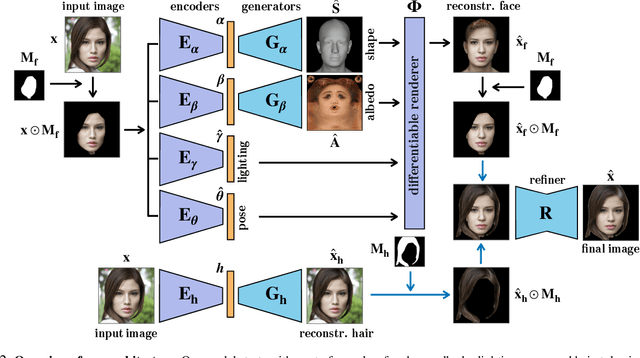

Recent advances in generative adversarial networks (GANs) have led to remarkable achievements in face image synthesis. While methods that use style-based GANs can generate strikingly photorealistic face images, it is often difficult to control the characteristics of the generated faces in a meaningful and disentangled way. Prior approaches aim to achieve such semantic control and disentanglement within the latent space of a previously trained GAN. In contrast, we propose a framework that a priori models physical attributes of the face such as 3D shape, albedo, pose, and lighting explicitly, thus providing disentanglement by design. Our method, MOST-GAN, integrates the expressive power and photorealism of style-based GANs with the physical disentanglement and flexibility of nonlinear 3D morphable models, which we couple with a state-of-the-art 2D hair manipulation network. MOST-GAN achieves photorealistic manipulation of portrait images with fully disentangled 3D control over their physical attributes, enabling extreme manipulation of lighting, facial expression, and pose variations up to full profile view.