 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Training Discrete Deep Generative Models via Gapped Straight-Through Estimator
Jun 15, 2022
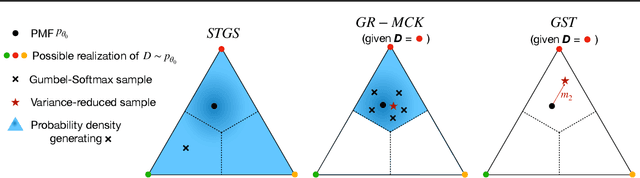
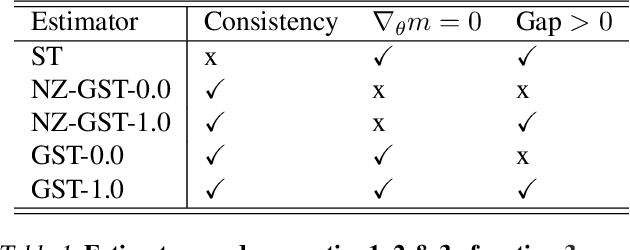
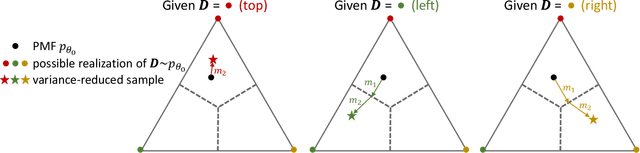
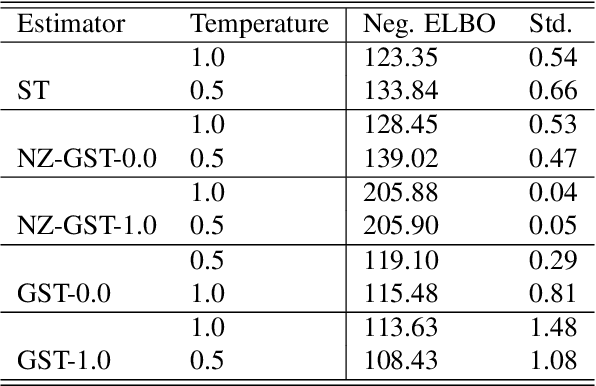
While deep generative models have succeeded in image processing, natural language processing, and reinforcement learning, training that involves discrete random variables remains challenging due to the high variance of its gradient estimation process. Monte Carlo is a common solution used in most variance reduction approaches. However, this involves time-consuming resampling and multiple function evaluations. We propose a Gapped Straight-Through (GST) estimator to reduce the variance without incurring resampling overhead. This estimator is inspired by the essential properties of Straight-Through Gumbel-Softmax. We determine these properties and show via an ablation study that they are essential. Experiments demonstrate that the proposed GST estimator enjoys better performance compared to strong baselines on two discrete deep generative modeling tasks, MNIST-VAE and ListOps.
Structure-Preserving Image Super-Resolution
Sep 26, 2021
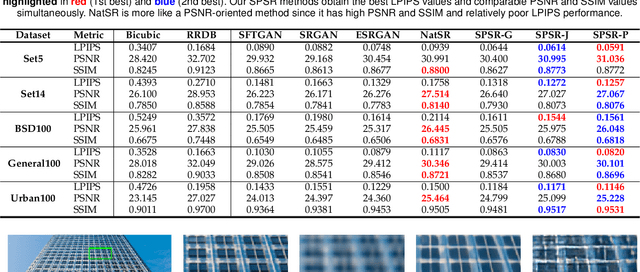
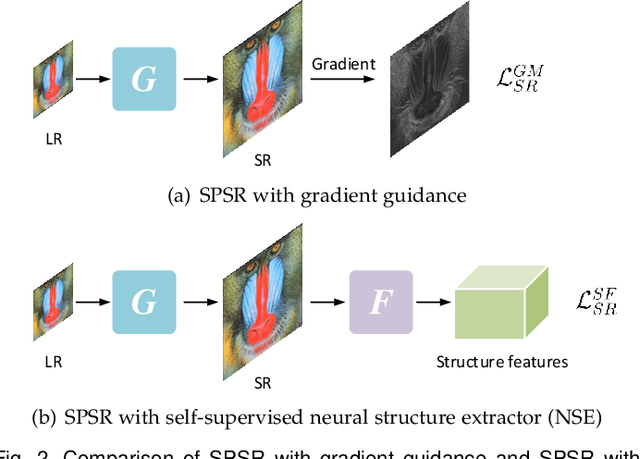

Structures matter in single image super-resolution (SISR). Benefiting from generative adversarial networks (GANs), recent studies have promoted the development of SISR by recovering photo-realistic images. However, there are still undesired structural distortions in the recovered images. In this paper, we propose a structure-preserving super-resolution (SPSR) method to alleviate the above issue while maintaining the merits of GAN-based methods to generate perceptual-pleasant details. Firstly, we propose SPSR with gradient guidance (SPSR-G) by exploiting gradient maps of images to guide the recovery in two aspects. On the one hand, we restore high-resolution gradient maps by a gradient branch to provide additional structure priors for the SR process. On the other hand, we propose a gradient loss to impose a second-order restriction on the super-resolved images, which helps generative networks concentrate more on geometric structures. Secondly, since the gradient maps are handcrafted and may only be able to capture limited aspects of structural information, we further extend SPSR-G by introducing a learnable neural structure extractor (NSE) to unearth richer local structures and provide stronger supervision for SR. We propose two self-supervised structure learning methods, contrastive prediction and solving jigsaw puzzles, to train the NSEs. Our methods are model-agnostic, which can be potentially used for off-the-shelf SR networks. Experimental results on five benchmark datasets show that the proposed methods outperform state-of-the-art perceptual-driven SR methods under LPIPS, PSNR, and SSIM metrics. Visual results demonstrate the superiority of our methods in restoring structures while generating natural SR images. Code is available at https://github.com/Maclory/SPSR.
Can Push-forward Generative Models Fit Multimodal Distributions?
Jun 29, 2022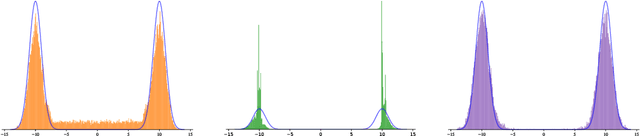
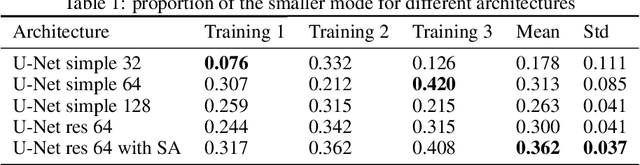
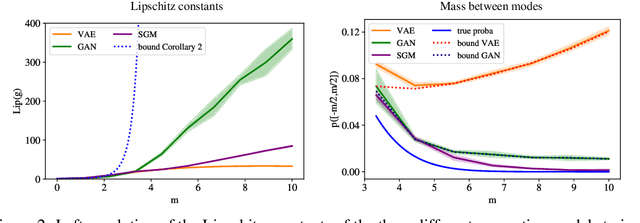

Many generative models synthesize data by transforming a standard Gaussian random variable using a deterministic neural network. Among these models are the Variational Autoencoders and the Generative Adversarial Networks. In this work, we call them "push-forward" models and study their expressivity. We show that the Lipschitz constant of these generative networks has to be large in order to fit multimodal distributions. More precisely, we show that the total variation distance and the Kullback-Leibler divergence between the generated and the data distribution are bounded from below by a constant depending on the mode separation and the Lipschitz constant. Since constraining the Lipschitz constants of neural networks is a common way to stabilize generative models, there is a provable trade-off between the ability of push-forward models to approximate multimodal distributions and the stability of their training. We validate our findings on one-dimensional and image datasets and empirically show that generative models consisting of stacked networks with stochastic input at each step, such as diffusion models do not suffer of such limitations.
Representational Multiplicity Should Be Exposed, Not Eliminated
Jun 17, 2022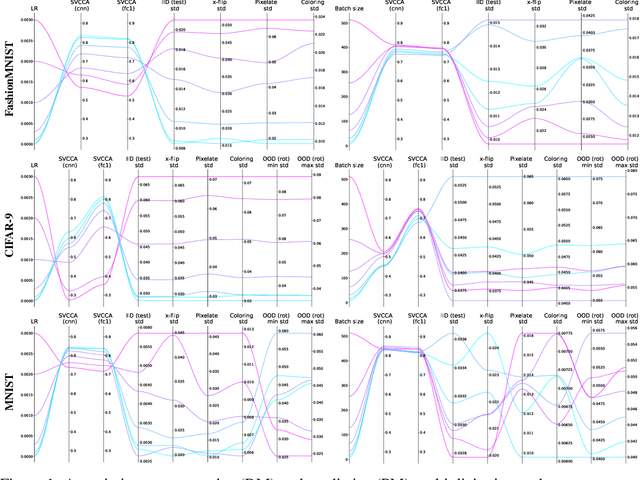
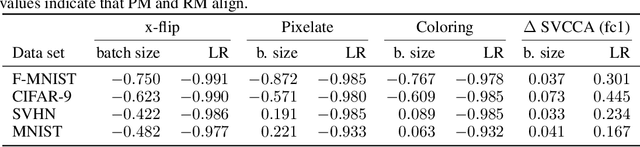
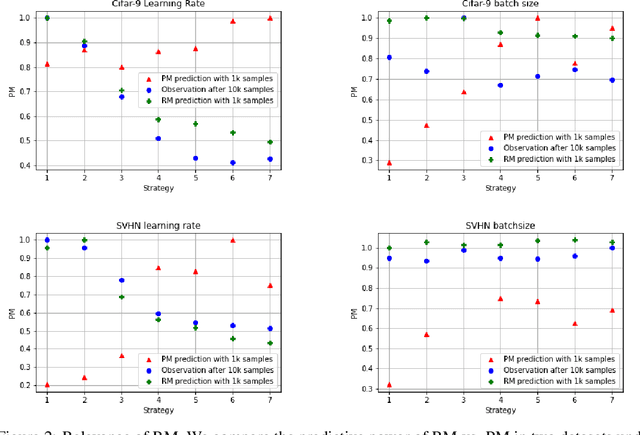
It is prevalent and well-observed, but poorly understood, that two machine learning models with similar performance during training can have very different real-world performance characteristics. This implies elusive differences in the internals of the models, manifesting as representational multiplicity (RM). We introduce a conceptual and experimental setup for analyzing RM and show that certain training methods systematically result in greater RM than others, measured by activation similarity via singular vector canonical correlation analysis (SVCCA). We further correlate it with predictive multiplicity measured by the variance in i.i.d. and out-of-distribution test set predictions, in four common image data sets. We call for systematic measurement and maximal exposure, not elimination, of RM in models. Qualitative tools such as our confabulator analysis can facilitate understanding and communication of RM effects to stakeholders.
Unsupervised Knowledge-Transfer for Learned Image Reconstruction
Jul 06, 2021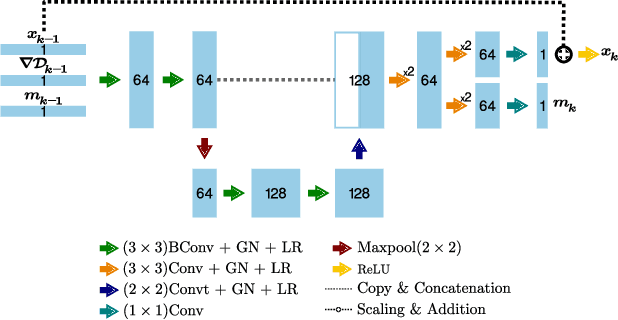
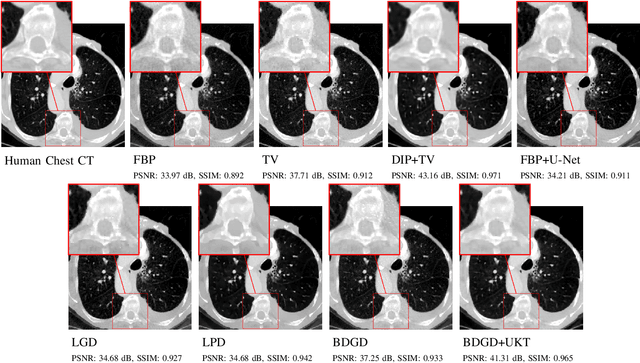
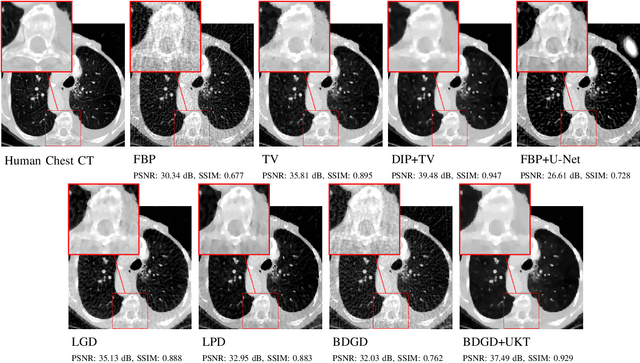
Deep learning-based image reconstruction approaches have demonstrated impressive empirical performance in many imaging modalities. These approaches generally require a large amount of high-quality training data, which is often not available. To circumvent this issue, we develop a novel unsupervised knowledge-transfer paradigm for learned iterative reconstruction within a Bayesian framework. The proposed approach learns an iterative reconstruction network in two phases. The first phase trains a reconstruction network with a set of ordered pairs comprising of ground truth images and measurement data. The second phase fine-tunes the pretrained network to the measurement data without supervision. Furthermore, the framework delivers uncertainty information over the reconstructed image. We present extensive experimental results on low-dose and sparse-view computed tomography, showing that the proposed framework significantly improves reconstruction quality not only visually, but also quantitatively in terms of PSNR and SSIM, and is competitive with several state-of-the-art supervised and unsupervised reconstruction techniques.
FS-NCSR: Increasing Diversity of the Super-Resolution Space via Frequency Separation and Noise-Conditioned Normalizing Flow
Apr 20, 2022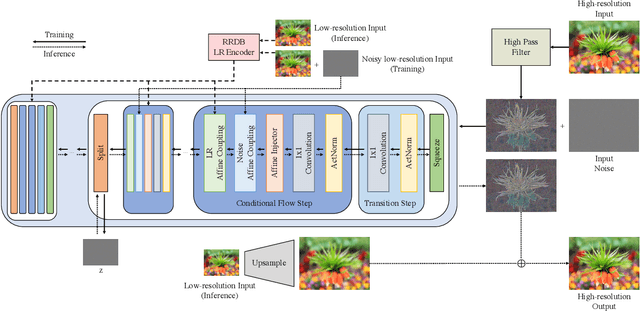
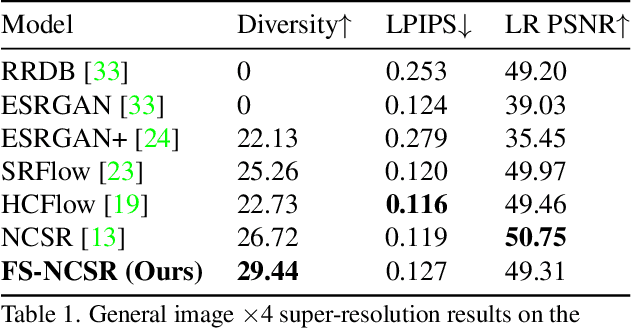

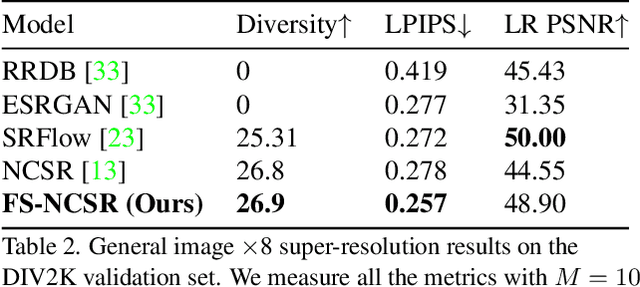
Super-resolution suffers from an innate ill-posed problem that a single low-resolution (LR) image can be from multiple high-resolution (HR) images. Recent studies on the flow-based algorithm solve this ill-posedness by learning the super-resolution space and predicting diverse HR outputs. Unfortunately, the diversity of the super-resolution outputs is still unsatisfactory, and the outputs from the flow-based model usually suffer from undesired artifacts which causes low-quality outputs. In this paper, we propose FS-NCSR which produces diverse and high-quality super-resolution outputs using frequency separation and noise conditioning compared to the existing flow-based approaches. As the sharpness and high-quality detail of the image rely on its high-frequency information, FS-NCSR only estimates the high-frequency information of the high-resolution outputs without redundant low-frequency components. Through this, FS-NCSR significantly improves the diversity score without significant image quality degradation compared to the NCSR, the winner of the previous NTIRE 2021 challenge.
Multitask vocal burst modeling with ResNets and pre-trained paralinguistic Conformers
Jun 24, 2022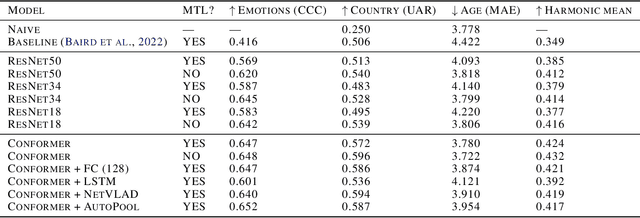
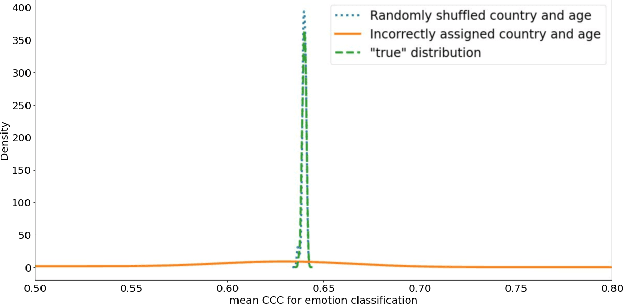
This technical report presents the modeling approaches used in our submission to the ICML Expressive Vocalizations Workshop & Competition multitask track (ExVo-MultiTask). We first applied image classification models of various sizes on mel-spectrogram representations of the vocal bursts, as is standard in sound event detection literature. Results from these models show an increase of 21.24% over the baseline system with respect to the harmonic mean of the task metrics, and comprise our team's main submission to the MultiTask track. We then sought to characterize the headroom in the MultiTask track by applying a large pre-trained Conformer model that previously achieved state-of-the-art results on paralinguistic tasks like speech emotion recognition and mask detection. We additionally investigated the relationship between the sub-tasks of emotional expression, country of origin, and age prediction, and discovered that the best performing models are trained as single-task models, questioning whether the problem truly benefits from a multitask setting.
REPLICA: Enhanced Feature Pyramid Network by Local Image Translation and Conjunct Attention for High-Resolution Breast Tumor Detection
Nov 22, 2021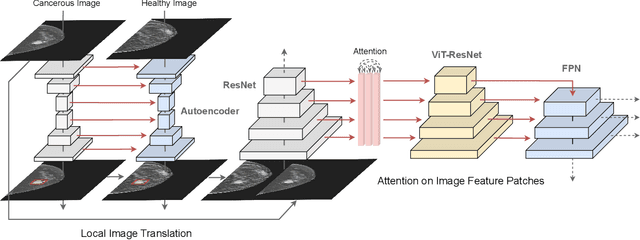
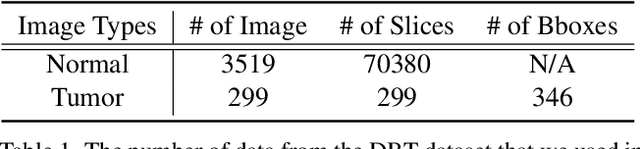
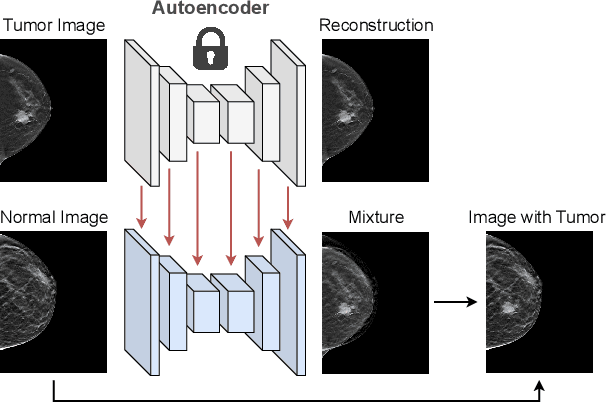
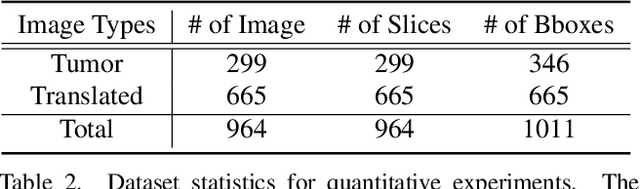
We introduce an improvement to the feature pyramid network of standard object detection models. We call our method enhanced featuRE Pyramid network by Local Image translation and Conjunct Attention, or REPLICA. REPLICA improves object detection performance by simultaneously (1) generating realistic but fake images with simulated objects to mitigate the data-hungry problem of the attention mechanism, and (2) advancing the detection model architecture through a novel modification of attention on image feature patches. Specifically, we use a convolutional autoencoder as a generator to create new images by injecting objects into images via local interpolation and reconstruction of their features extracted in hidden layers. Then due to the larger number of simulated images, we use a visual transformer to enhance outputs of each ResNet layer that serve as inputs to a feature pyramid network. We apply our methodology to the problem of detecting lesions in Digital Breast Tomosynthesis scans (DBT), a high-resolution medical imaging modality crucial in breast cancer screening. We demonstrate qualitatively and quantitatively that REPLICA can improve the accuracy of tumor detection using our enhanced standard object detection framework via experimental results.
Automated Detection of Label Errors in Semantic Segmentation Datasets via Deep Learning and Uncertainty Quantification
Jul 13, 2022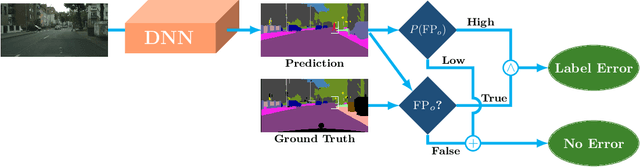
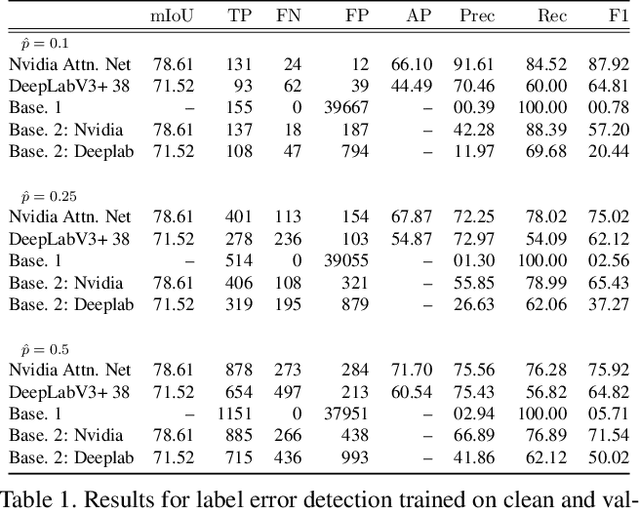
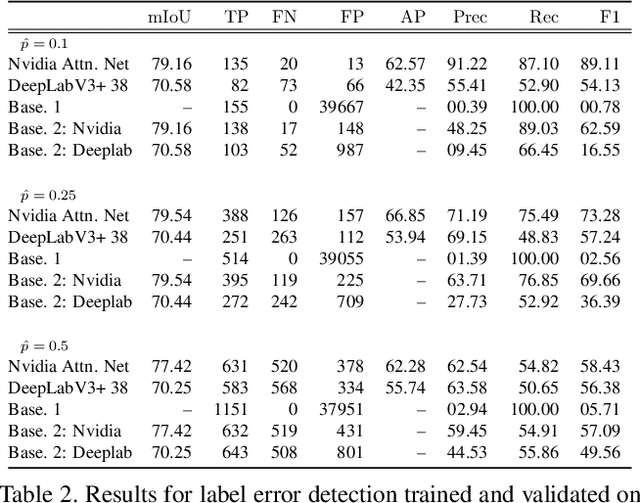
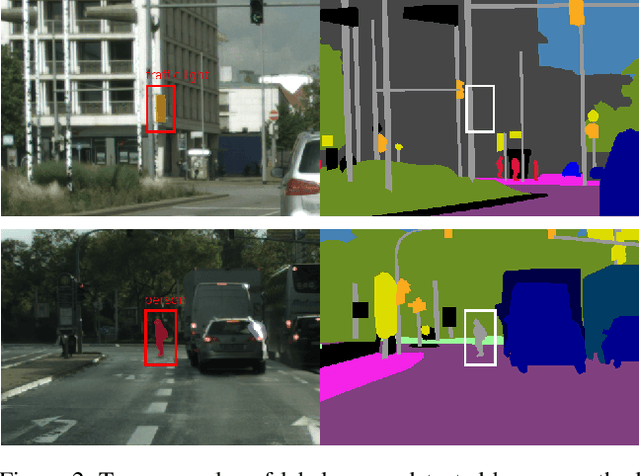
In this work, we for the first time present a method for detecting label errors in image datasets with semantic segmentation, i.e., pixel-wise class labels. Annotation acquisition for semantic segmentation datasets is time-consuming and requires plenty of human labor. In particular, review processes are time consuming and label errors can easily be overlooked by humans. The consequences are biased benchmarks and in extreme cases also performance degradation of deep neural networks (DNNs) trained on such datasets. DNNs for semantic segmentation yield pixel-wise predictions, which makes detection of label errors via uncertainty quantification a complex task. Uncertainty is particularly pronounced at the transitions between connected components of the prediction. By lifting the consideration of uncertainty to the level of predicted components, we enable the usage of DNNs together with component-level uncertainty quantification for the detection of label errors. We present a principled approach to benchmarking the task of label error detection by dropping labels from the Cityscapes dataset as well from a dataset extracted from the CARLA driving simulator, where in the latter case we have the labels under control. Our experiments show that our approach is able to detect the vast majority of label errors while controlling the number of false label error detections. Furthermore, we apply our method to semantic segmentation datasets frequently used by the computer vision community and present a collection of label errors along with sample statistics.
PS$^2$F: Polarized Spiral Point Spread Function for Single-Shot 3D Sensing
Jul 03, 2022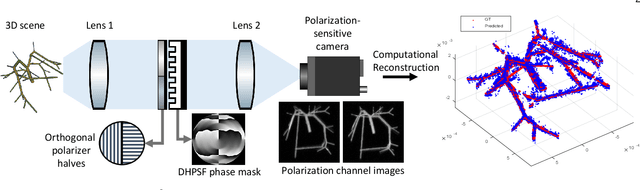
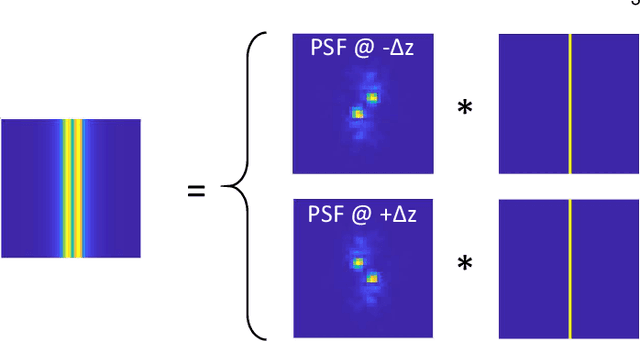
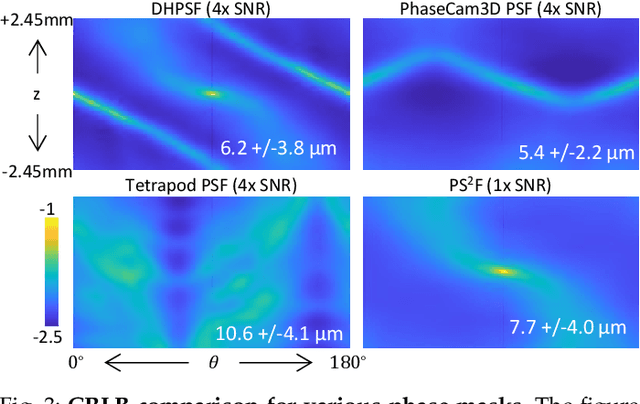
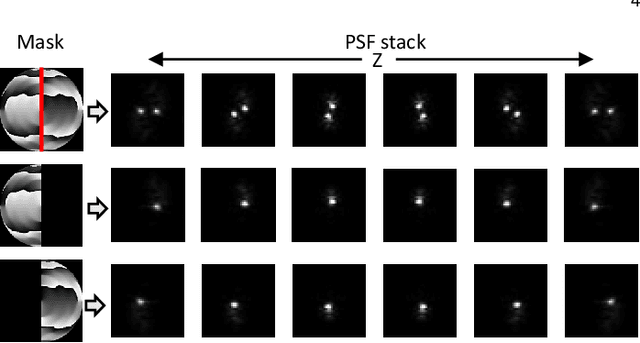
We propose a compact snapshot monocular depth estimation technique that relies on an engineered point spread function (PSF). Traditional approaches used in microscopic super-resolution imaging, such as the Double-Helix PSF (DHPSF), are ill-suited for scenes that are more complex than a sparse set of point light sources. We show, using the Cram\'er-Rao lower bound (CRLB), that separating the two lobes of the DHPSF and thereby capturing two separate images leads to a dramatic increase in depth accuracy. A unique property of the phase mask used for generating the DHPSF is that a separation of the phase mask into two halves leads to a spatial separation of the two lobes. We leverage this property to build a compact polarization-based optical setup, where we place two orthogonal linear polarizers on each half of the DHPSF phase mask and then capture the resulting image with a polarization sensitive camera. Results from simulations and a lab prototype demonstrate that our technique achieves up to $50\%$ lower depth error compared to state-of-the-art designs including the DHPSF, and the Tetrapod PSF, with little to no loss in spatial resolution.