 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
InvNorm: Domain Generalization for Object Detection in Gastrointestinal Endoscopy
May 05, 2022
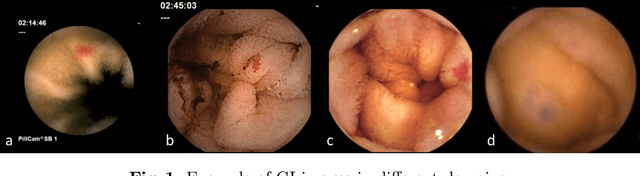
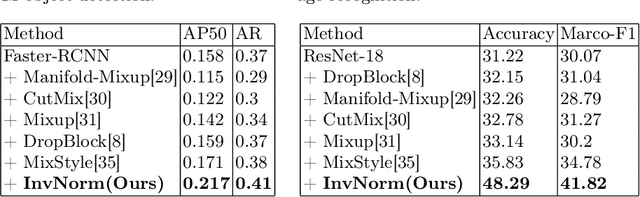
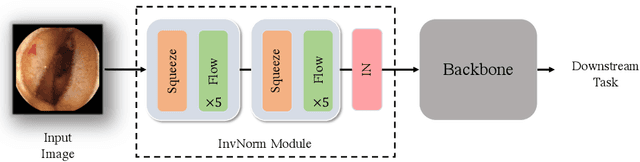
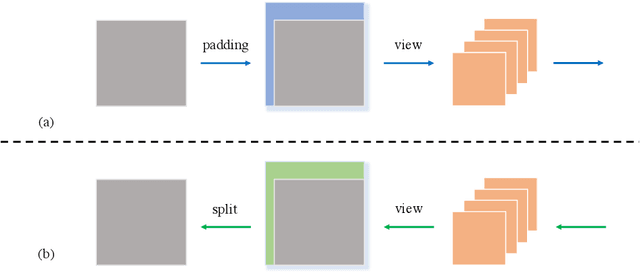
Domain Generalization is a challenging topic in computer vision, especially in Gastrointestinal Endoscopy image analysis. Due to several device limitations and ethical reasons, current open-source datasets are typically collected on a limited number of patients using the same brand of sensors. Different brands of devices and individual differences will significantly affect the model's generalizability. Therefore, to address the generalization problem in GI(Gastrointestinal) endoscopy, we propose a multi-domain GI dataset and a light, plug-in block called InvNorm(Invertible Normalization), which could achieve a better generalization performance in any structure. Previous DG(Domain Generalization) methods fail to achieve invertible transformation, which would lead to some misleading augmentation. Moreover, these models would be more likely to lead to medical ethics issues. Our method utilizes normalizing flow to achieve invertible and explainable style normalization to address the problem. The effectiveness of InvNorm is demonstrated on a wide range of tasks, including GI recognition, GI object detection, and natural image recognition.
Domain Adaptive 3D Pose Augmentation for In-the-wild Human Mesh Recovery
Jun 21, 2022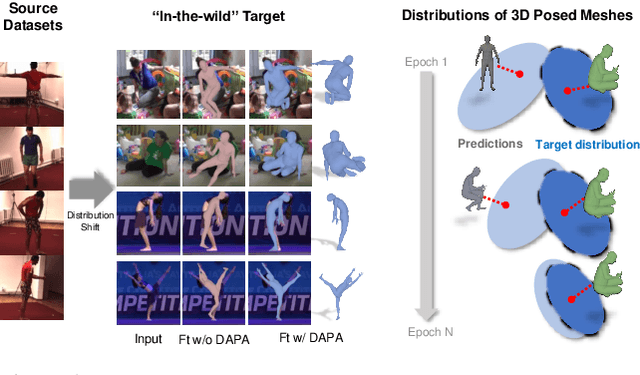
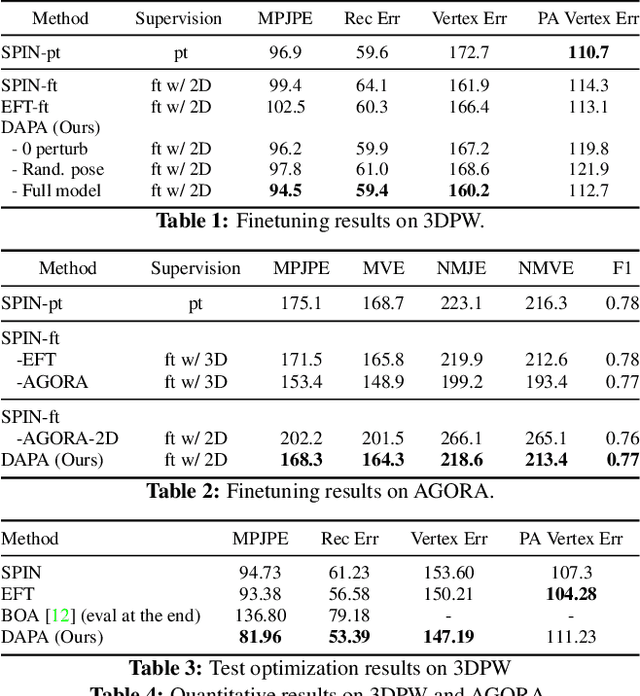
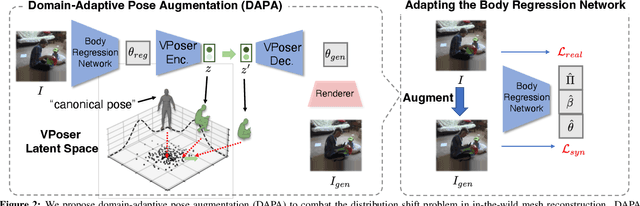

The ability to perceive 3D human bodies from a single image has a multitude of applications ranging from entertainment and robotics to neuroscience and healthcare. A fundamental challenge in human mesh recovery is in collecting the ground truth 3D mesh targets required for training, which requires burdensome motion capturing systems and is often limited to indoor laboratories. As a result, while progress is made on benchmark datasets collected in these restrictive settings, models fail to generalize to real-world ``in-the-wild'' scenarios due to distribution shifts. We propose Domain Adaptive 3D Pose Augmentation (DAPA), a data augmentation method that enhances the model's generalization ability in in-the-wild scenarios. DAPA combines the strength of methods based on synthetic datasets by getting direct supervision from the synthesized meshes, and domain adaptation methods by using ground truth 2D keypoints from the target dataset. We show quantitatively that finetuning with DAPA effectively improves results on benchmarks 3DPW and AGORA. We further demonstrate the utility of DAPA on a challenging dataset curated from videos of real-world parent-child interaction.
Online Exemplar Fine-Tuning for Image-to-Image Translation
Nov 18, 2020
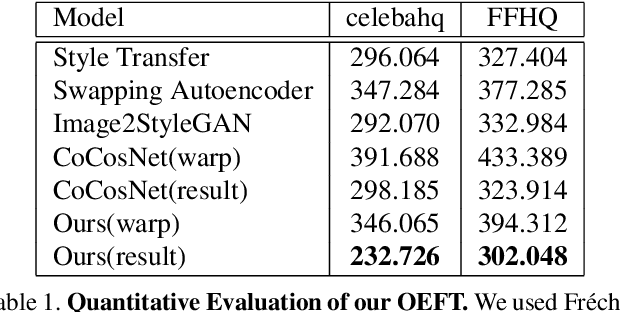
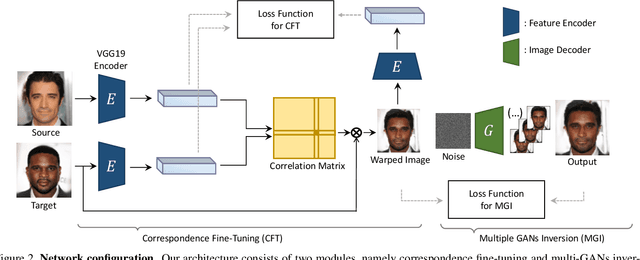
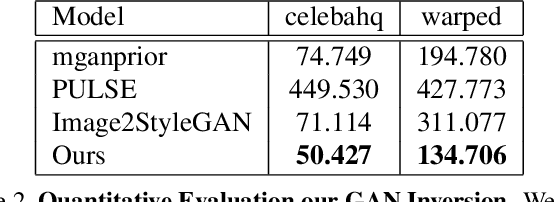
Existing techniques to solve exemplar-based image-to-image translation within deep convolutional neural networks (CNNs) generally require a training phase to optimize the network parameters on domain-specific and task-specific benchmarks, thus having limited applicability and generalization ability. In this paper, we propose a novel framework, for the first time, to solve exemplar-based translation through an online optimization given an input image pair, called online exemplar fine-tuning (OEFT), in which we fine-tune the off-the-shelf and general-purpose networks to the input image pair themselves. We design two sub-networks, namely correspondence fine-tuning and multiple GAN inversion, and optimize these network parameters and latent codes, starting from the pre-trained ones, with well-defined loss functions. Our framework does not require the off-line training phase, which has been the main challenge of existing methods, but the pre-trained networks to enable optimization in online. Experimental results prove that our framework is effective in having a generalization power to unseen image pairs and clearly even outperforms the state-of-the-arts needing the intensive training phase.
Large-Margin Representation Learning for Texture Classification
Jun 17, 2022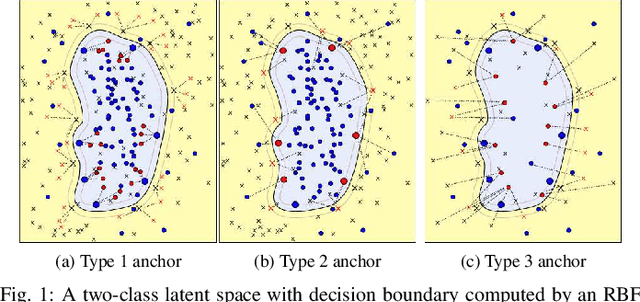

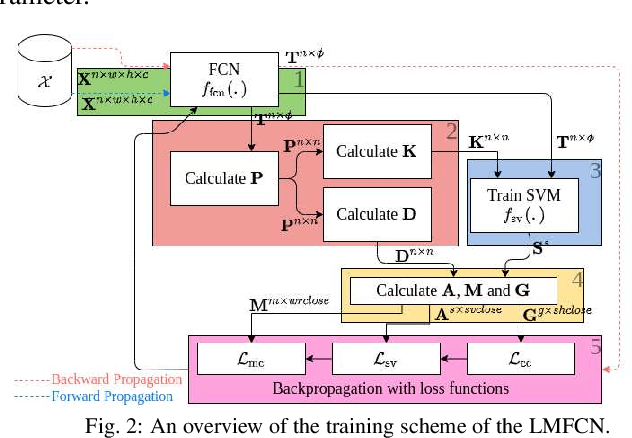
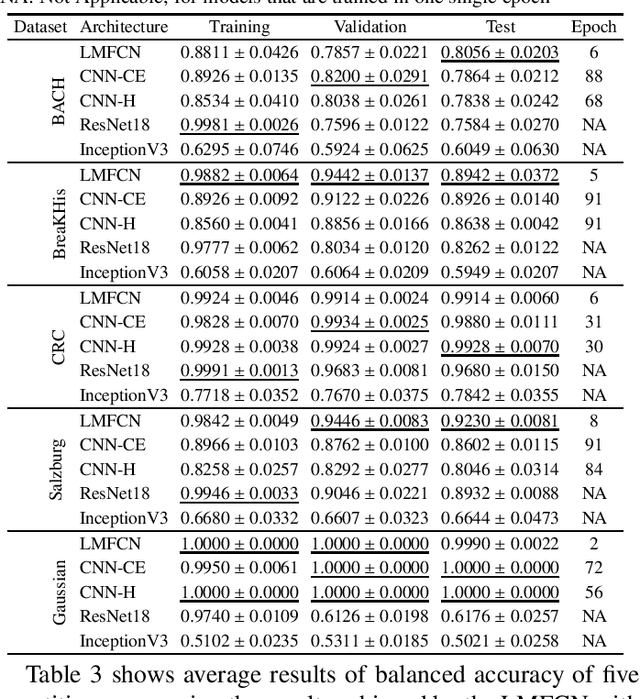
This paper presents a novel approach combining convolutional layers (CLs) and large-margin metric learning for training supervised models on small datasets for texture classification. The core of such an approach is a loss function that computes the distances between instances of interest and support vectors. The objective is to update the weights of CLs iteratively to learn a representation with a large margin between classes. Each iteration results in a large-margin discriminant model represented by support vectors based on such a representation. The advantage of the proposed approach w.r.t. convolutional neural networks (CNNs) is two-fold. First, it allows representation learning with a small amount of data due to the reduced number of parameters compared to an equivalent CNN. Second, it has a low training cost since the backpropagation considers only support vectors. The experimental results on texture and histopathologic image datasets have shown that the proposed approach achieves competitive accuracy with lower computational cost and faster convergence when compared to equivalent CNNs.
Vision Xformers: Efficient Attention for Image Classification
Aug 03, 2021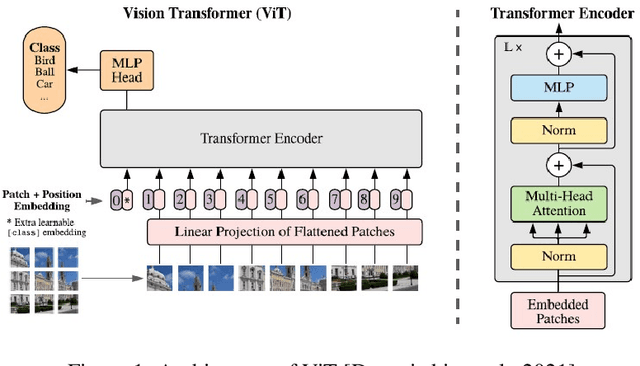

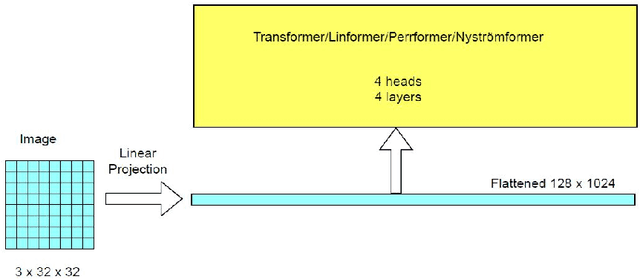

We propose three improvements to vision transformers (ViT) to reduce the number of trainable parameters without compromising classification accuracy. We address two shortcomings of the early ViT architectures -- quadratic bottleneck of the attention mechanism and the lack of an inductive bias in their architectures that rely on unrolling the two-dimensional image structure. Linear attention mechanisms overcome the bottleneck of quadratic complexity, which restricts application of transformer models in vision tasks. We modify the ViT architecture to work on longer sequence data by replacing the quadratic attention with efficient transformers, such as Performer, Linformer and Nystr\"omformer of linear complexity creating Vision X-formers (ViX). We show that all three versions of ViX may be more accurate than ViT for image classification while using far fewer parameters and computational resources. We also compare their performance with FNet and multi-layer perceptron (MLP) mixer. We further show that replacing the initial linear embedding layer by convolutional layers in ViX further increases their performance. Furthermore, our tests on recent vision transformer models, such as LeViT, Convolutional vision Transformer (CvT), Compact Convolutional Transformer (CCT) and Pooling-based Vision Transformer (PiT) show that replacing the attention with Nystr\"omformer or Performer saves GPU usage and memory without deteriorating the classification accuracy. We also show that replacing the standard learnable 1D position embeddings in ViT with Rotary Position Embedding (RoPE) give further improvements in accuracy. Incorporating these changes can democratize transformers by making them accessible to those with limited data and computing resources.
Effective Solid State LiDAR Odometry Using Continuous-time Filter Registration
Jun 17, 2022

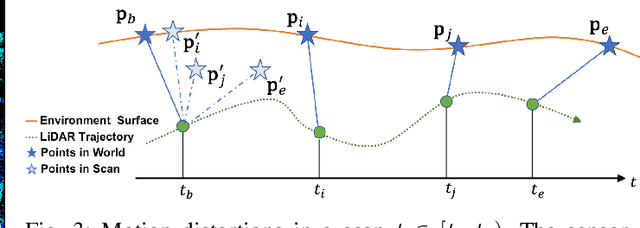
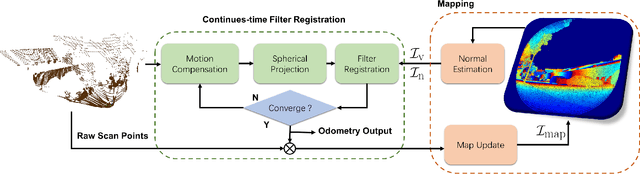
Solid-state LiDARs are more compact and cheaper than the conventional mechanical multi-line spinning LiDARs, which have become increasingly popular in autonomous driving recently. However, there are several challenges for these new LiDAR sensors, including severe motion distortions, small field of view and sparse point cloud, which hinder them from being widely used in LiDAR odometry. To tackle these problems, we present an effective continuous-time LiDAR odometry (ECTLO) method for the Risley prism-based LiDARs with non-repetitive scanning patterns. To account for the noisy data, a filter-based point-to-plane Gaussian Mixture Model is used for robust registration. Moreover, a LiDAR-only continuous-time motion model is employed to relieve the inevitable distortions. To facilitate the implicit data association in parallel, we maintain all map points within a single range image. Extensive experiments have been conducted on various testbeds using the solid-state LiDARs with different scanning patterns, whose promising results demonstrate the efficacy of our proposed approach.
Content-adaptive Representation Learning for Fast Image Super-resolution
May 20, 2021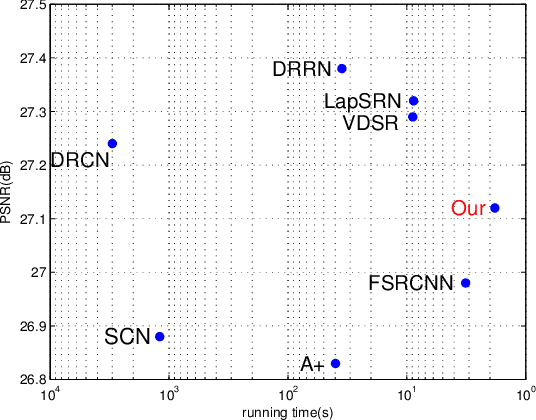
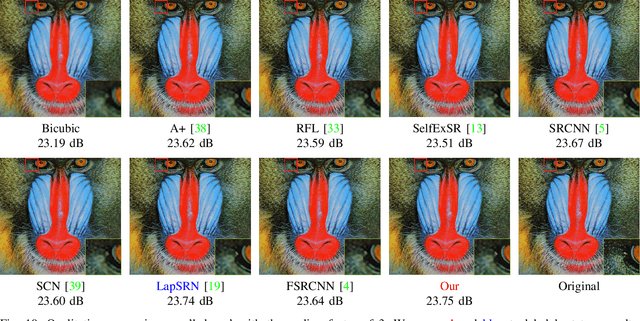


Deep convolutional networks have attracted great attention in image restoration and enhancement. Generally, restoration quality has been improved by building more and more convolutional block. However, these methods mostly learn a specific model to handle all images and ignore difficulty diversity. In other words, an area in the image with high frequency tend to lose more information during compressing while an area with low frequency tends to lose less. In this article, we adrress the efficiency issue in image SR by incorporating a patch-wise rolling network(PRN) to content-adaptively recover images according to difficulty levels. In contrast to existing studies that ignore difficulty diversity, we adopt different stage of a neural network to perform image restoration. In addition, we propose a rolling strategy that utilizes the parameters of each stage more flexible. Extensive experiments demonstrate that our model not only shows a significant acceleration but also maintain state-of-the-art performance.
An Efficient Architecture and High-Throughput Implementation of CCSDS-123.0-B-2 Hybrid Entropy Coder Targeting Space-Grade SRAM FPGA Technology
May 09, 2022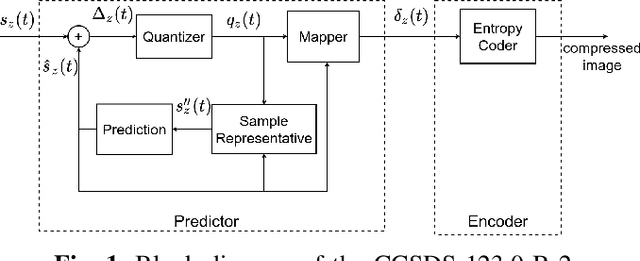
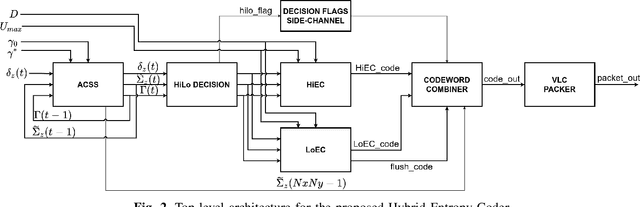
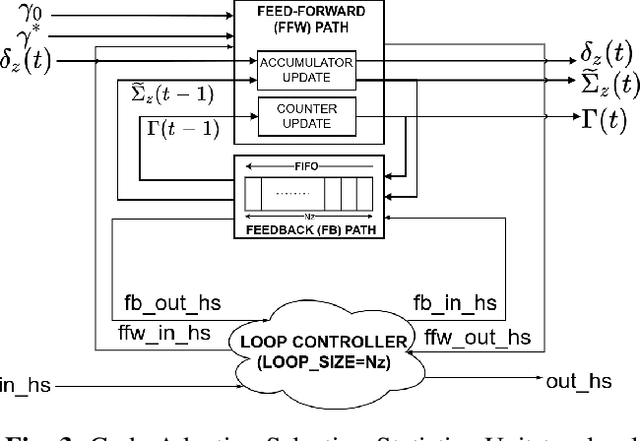
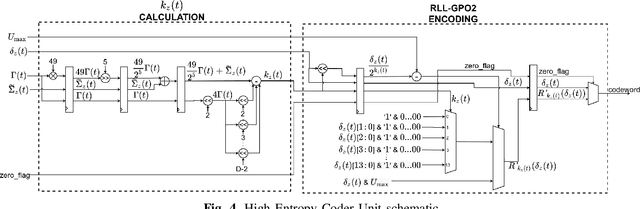
Nowadays, hyperspectral imaging is recognized as cornerstone remote sensing technology. The explosive growth in image data volume and instrument data rates, compete with limited on-board storage resources and downlink bandwidth, making hyperspectral image data compression a mission critical on-board processing task. The Consultative Committee for Space Data Systems (CCSDS) extended the previous issue of the CCSDS-123.0 Recommended Standard for multi- and hyperspectral image compression to provide with Near-Lossless compression functionality. A key feature of the CCSDS-123.0-B-2 is the improved Hybrid Entropy Coder, which at low bit rates, provides substantially better compression performance than the Issue 1 entropy coders. In this paper, we introduce a high-throughput hardware implementation of the CCSDS-123.0-B-2 Hybrid Entropy Coder. The introduced architecture exploits the systolic design pattern to provide modularity and latency insensitivity in a deep and elastic pipeline achieving a constant throughput of 1 sample/cycle with a small FPGA resource footprint. This architecture is described in portable VHDL RTL and is implemented, validated and demonstrated on a commercially available Xilinx KCU105 development board hosting a Xilinx Kintex Ultrascale XCKU040 SRAM FPGA, and thus, is directly transferable to Xilinx Radiation Tolerant Kintex UltraScale XQRKU060 space-grade devices for space deployments. Moreover, state-of-the-art SpaceFibre (ECSS-E-ST-50-11C) serial link interface and test equipment were used in the validation platform to emulate an on-board deployment. The introduced CCSDS-123.0-B-2 Hybrid Entropy Encoder achieves a constant throughput performance of 305 MSamples/s. To the best of our knowledge, this is the first published fully-compliant architecture and high-throughput implementation of the CCSDS-123.0-B-2 Hybrid Entropy Coder, targeting space-grade FPGA technology.
A robust and lightweight deep attention multiple instance learning algorithm for predicting genetic alterations
May 31, 2022Deep-learning models based on whole-slide digital pathology images (WSIs) become increasingly popular for predicting molecular biomarkers. Instance-based models has been the mainstream strategy for predicting genetic alterations using WSIs although bag-based models along with self-attention mechanism-based algorithms have been proposed for other digital pathology applications. In this paper, we proposed a novel Attention-based Multiple Instance Mutation Learning (AMIML) model for predicting gene mutations. AMIML was comprised of successive 1-D convolutional layers, a decoder, and a residual weight connection to facilitate further integration of a lightweight attention mechanism to detect the most predictive image patches. Using data for 24 clinically relevant genes from four cancer cohorts in The Cancer Genome Atlas (TCGA) studies (UCEC, BRCA, GBM and KIRC), we compared AMIML with one popular instance-based model and four recently published bag-based models (e.g., CHOWDER, HE2RNA, etc.). AMIML demonstrated excellent robustness, not only outperforming all the five baseline algorithms in the vast majority of the tested genes (17 out of 24), but also providing near-best-performance for the other seven genes. Conversely, the performance of the baseline published algorithms varied across different cancers/genes. In addition, compared to the published models for genetic alterations, AMIML provided a significant improvement for predicting a wide range of genes (e.g., KMT2C, TP53, and SETD2 for KIRC; ERBB2, BRCA1, and BRCA2 for BRCA; JAK1, POLE, and MTOR for UCEC) as well as produced outstanding predictive models for other clinically relevant gene mutations, which have not been reported in the current literature. Furthermore, with the flexible and interpretable attention-based MIL pooling mechanism, AMIML could further zero-in and detect predictive image patches.
8-bit Numerical Formats for Deep Neural Networks
Jun 06, 2022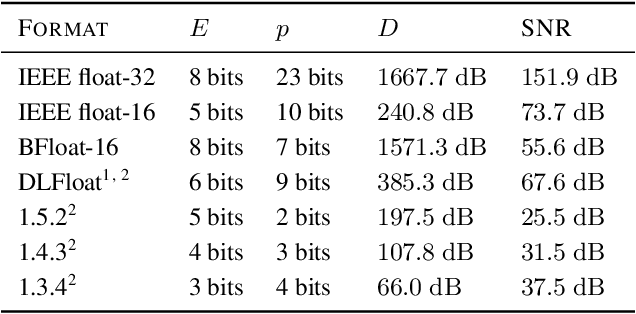
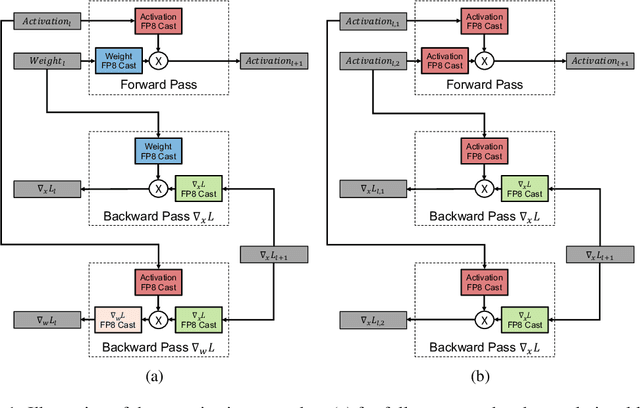
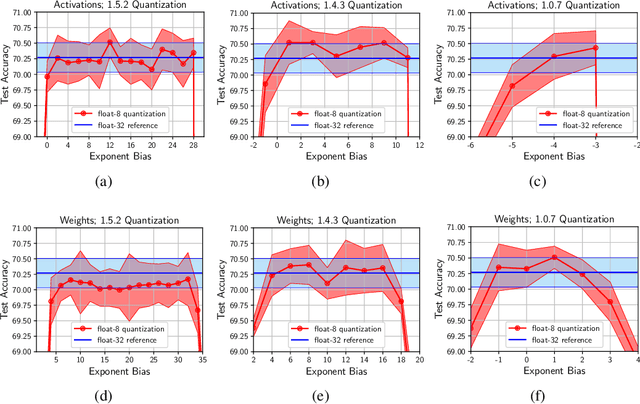
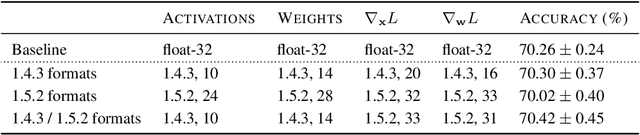
Given the current trend of increasing size and complexity of machine learning architectures, it has become of critical importance to identify new approaches to improve the computational efficiency of model training. In this context, we address the advantages of floating-point over fixed-point representation, and present an in-depth study on the use of 8-bit floating-point number formats for activations, weights, and gradients for both training and inference. We explore the effect of different bit-widths for exponents and significands and different exponent biases. The experimental results demonstrate that a suitable choice of these low-precision formats enables faster training and reduced power consumption without any degradation in accuracy for a range of deep learning models for image classification and language processing.