 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On Leveraging Variational Graph Embeddings for Open World Compositional Zero-Shot Learning
Apr 23, 2022
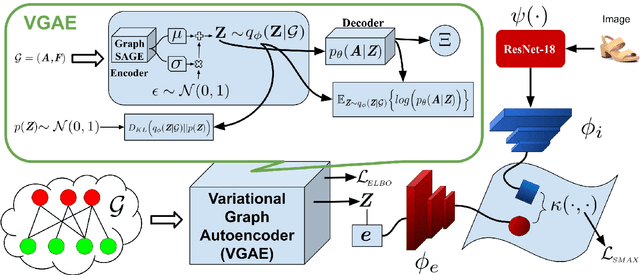
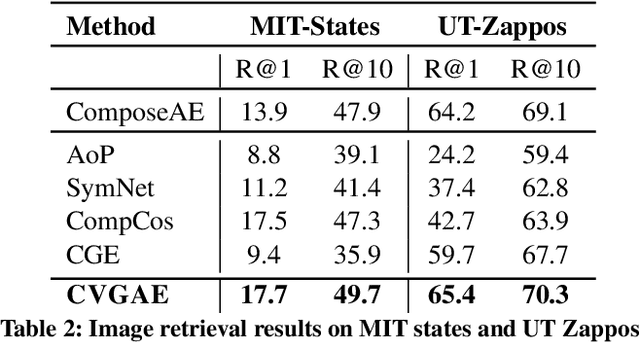
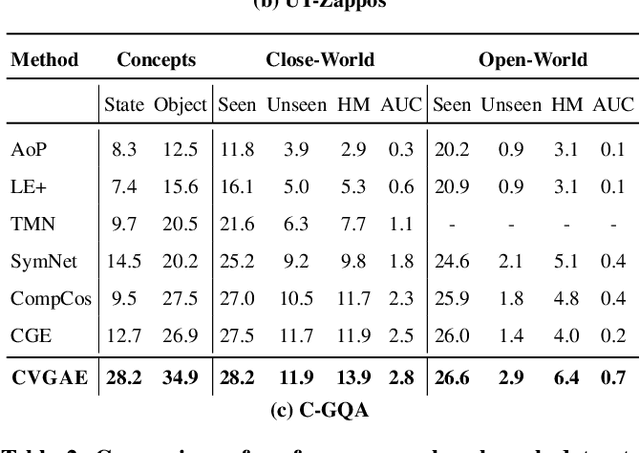
Humans are able to identify and categorize novel compositions of known concepts. The task in Compositional Zero-Shot learning (CZSL) is to learn composition of primitive concepts, i.e. objects and states, in such a way that even their novel compositions can be zero-shot classified. In this work, we do not assume any prior knowledge on the feasibility of novel compositions i.e.open-world setting, where infeasible compositions dominate the search space. We propose a Compositional Variational Graph Autoencoder (CVGAE) approach for learning the variational embeddings of the primitive concepts (nodes) as well as feasibility of their compositions (via edges). Such modelling makes CVGAE scalable to real-world application scenarios. This is in contrast to SOTA method, CGE, which is computationally very expensive. e.g.for benchmark C-GQA dataset, CGE requires 3.94 x 10^5 nodes, whereas CVGAE requires only 1323 nodes. We learn a mapping of the graph and image embeddings onto a common embedding space. CVGAE adopts a deep metric learning approach and learns a similarity metric in this space via bi-directional contrastive loss between projected graph and image embeddings. We validate the effectiveness of our approach on three benchmark datasets.We also demonstrate via an image retrieval task that the representations learnt by CVGAE are better suited for compositional generalization.
Open High-Resolution Satellite Imagery: The WorldStrat Dataset -- With Application to Super-Resolution
Jul 13, 2022

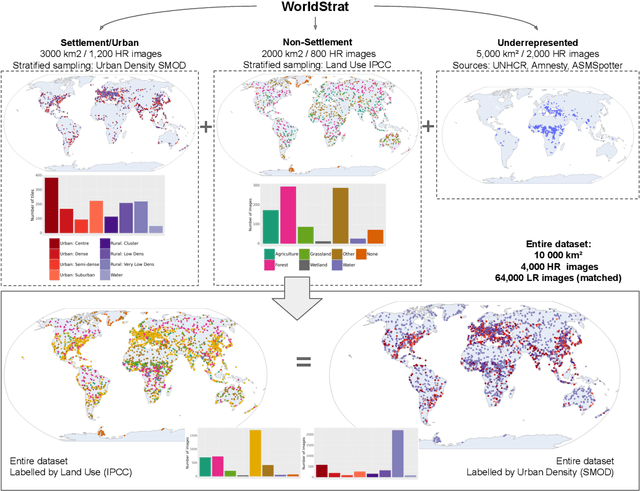
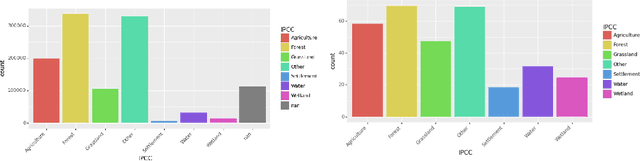
Analyzing the planet at scale with satellite imagery and machine learning is a dream that has been constantly hindered by the cost of difficult-to-access highly-representative high-resolution imagery. To remediate this, we introduce here the WorldStrat dataset. The largest and most varied such publicly available dataset, at Airbus SPOT 6/7 satellites' high resolution of up to 1.5 m/pixel, empowered by European Space Agency's Phi-Lab as part of the ESA-funded QueryPlanet project, we curate nearly 10,000 sqkm of unique locations to ensure stratified representation of all types of land-use across the world: from agriculture to ice caps, from forests to multiple urbanization densities. We also enrich those with locations typically under-represented in ML datasets: sites of humanitarian interest, illegal mining sites, and settlements of persons at risk. We temporally-match each high-resolution image with multiple low-resolution images from the freely accessible lower-resolution Sentinel-2 satellites at 10 m/pixel. We accompany this dataset with an open-source Python package to: rebuild or extend the WorldStrat dataset, train and infer baseline algorithms, and learn with abundant tutorials, all compatible with the popular EO-learn toolbox. We hereby hope to foster broad-spectrum applications of ML to satellite imagery, and possibly develop from free public low-resolution Sentinel2 imagery the same power of analysis allowed by costly private high-resolution imagery. We illustrate this specific point by training and releasing several highly compute-efficient baselines on the task of Multi-Frame Super-Resolution. High-resolution Airbus imagery is CC BY-NC, while the labels and Sentinel2 imagery are CC BY, and the source code and pre-trained models under BSD. The dataset is available at https://zenodo.org/record/6810792 and the software package at https://github.com/worldstrat/worldstrat .
Effect of the output activation function on the probabilities and errors in medical image segmentation
Sep 02, 2021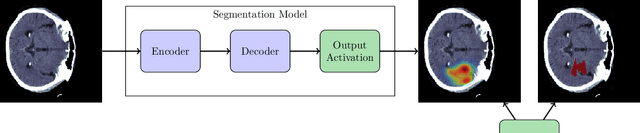

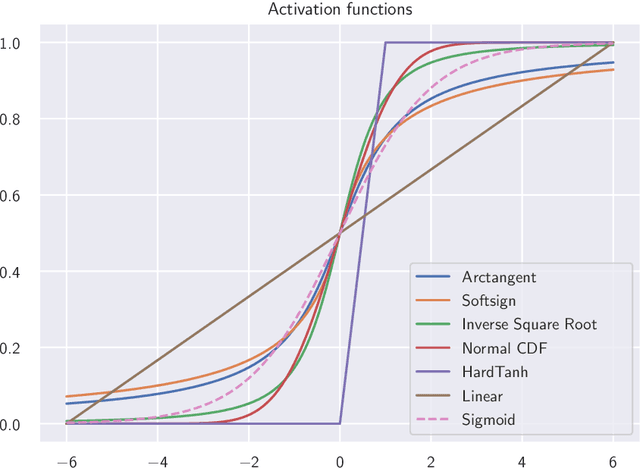
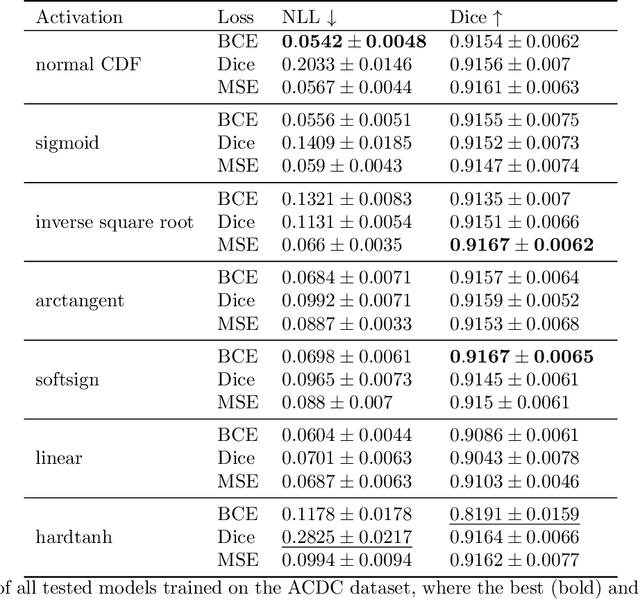
The sigmoid activation is the standard output activation function in binary classification and segmentation with neural networks. Still, there exist a variety of other potential output activation functions, which may lead to improved results in medical image segmentation. In this work, we consider how the asymptotic behavior of different output activation and loss functions affects the prediction probabilities and the corresponding segmentation errors. For cross entropy, we show that a faster rate of change of the activation function correlates with better predictions, while a slower rate of change can improve the calibration of probabilities. For dice loss, we found that the arctangent activation function is superior to the sigmoid function. Furthermore, we provide a test space for arbitrary output activation functions in the area of medical image segmentation. We tested seven activation functions in combination with three loss functions on four different medical image segmentation tasks to provide a classification of which function is best suited in this application scenario.
Unsupervised Remote Sensing Super-Resolution via Migration Image Prior
May 23, 2021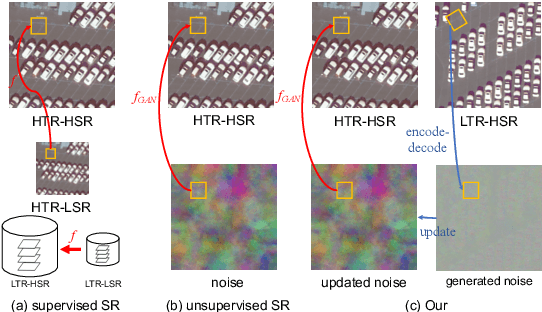
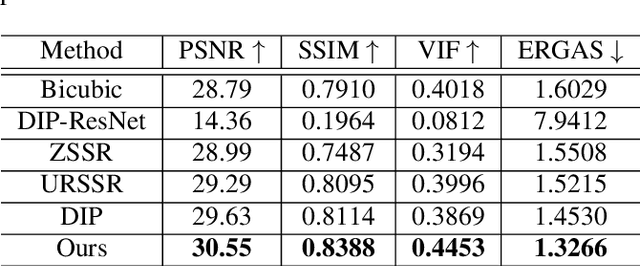
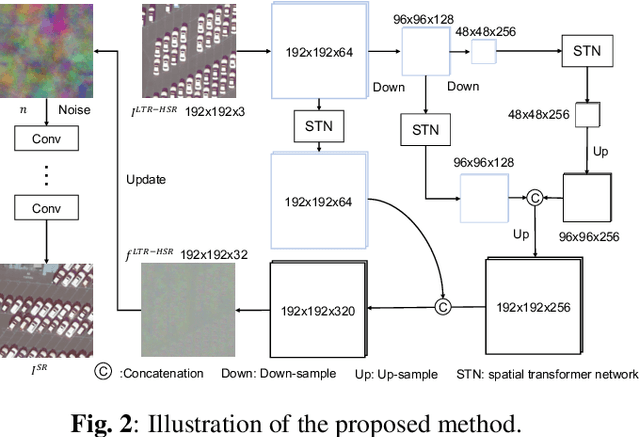
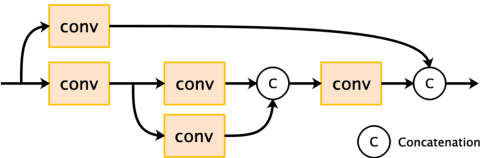
Recently, satellites with high temporal resolution have fostered wide attention in various practical applications. Due to limitations of bandwidth and hardware cost, however, the spatial resolution of such satellites is considerably low, largely limiting their potentials in scenarios that require spatially explicit information. To improve image resolution, numerous approaches based on training low-high resolution pairs have been proposed to address the super-resolution (SR) task. Despite their success, however, low/high spatial resolution pairs are usually difficult to obtain in satellites with a high temporal resolution, making such approaches in SR impractical to use. In this paper, we proposed a new unsupervised learning framework, called "MIP", which achieves SR tasks without low/high resolution image pairs. First, random noise maps are fed into a designed generative adversarial network (GAN) for reconstruction. Then, the proposed method converts the reference image to latent space as the migration image prior. Finally, we update the input noise via an implicit method, and further transfer the texture and structured information from the reference image. Extensive experimental results on the Draper dataset show that MIP achieves significant improvements over state-of-the-art methods both quantitatively and qualitatively. The proposed MIP is open-sourced at http://github.com/jiaming-wang/MIP.
Pythae: Unifying Generative Autoencoders in Python -- A Benchmarking Use Case
Jun 16, 2022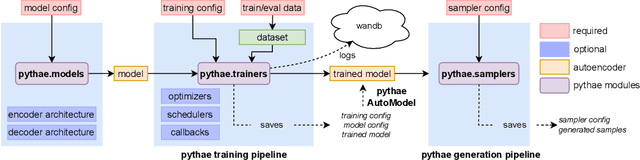
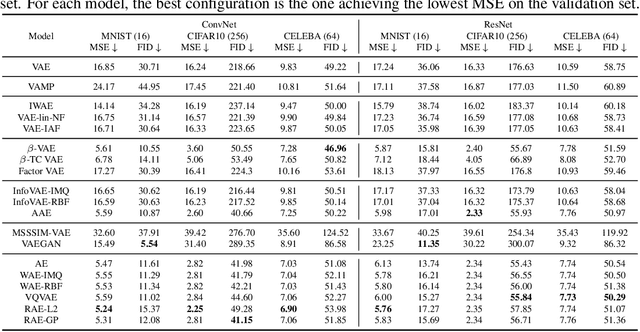
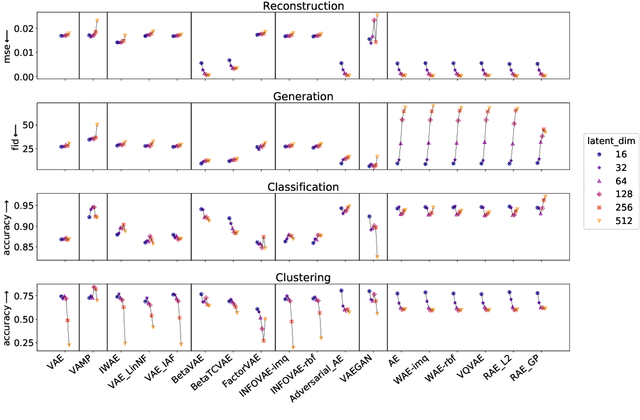
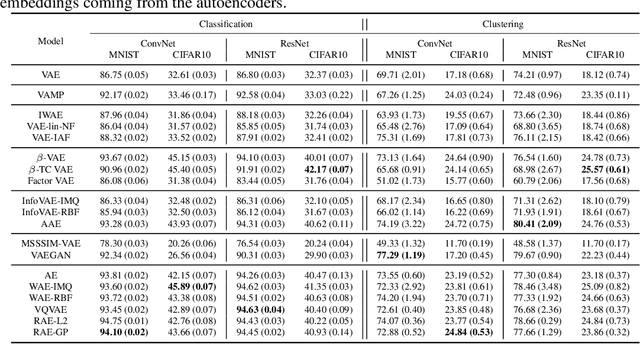
In recent years, deep generative models have attracted increasing interest due to their capacity to model complex distributions. Among those models, variational autoencoders have gained popularity as they have proven both to be computationally efficient and yield impressive results in multiple fields. Following this breakthrough, extensive research has been done in order to improve the original publication, resulting in a variety of different VAE models in response to different tasks. In this paper we present Pythae, a versatile open-source Python library providing both a unified implementation and a dedicated framework allowing straightforward, reproducible and reliable use of generative autoencoder models. We then propose to use this library to perform a case study benchmark where we present and compare 19 generative autoencoder models representative of some of the main improvements on downstream tasks such as image reconstruction, generation, classification, clustering and interpolation. The open-source library can be found at https://github.com/clementchadebec/benchmark_VAE.
Can Audio Captions Be Evaluated with Image Caption Metrics?
Oct 10, 2021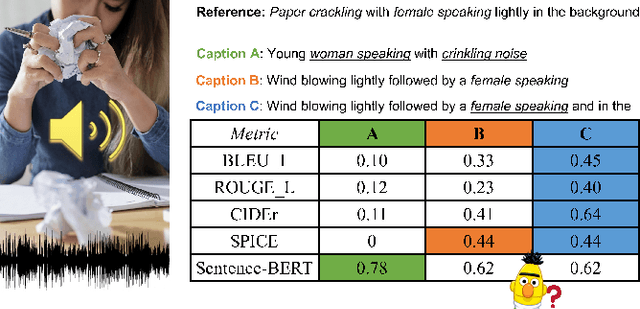

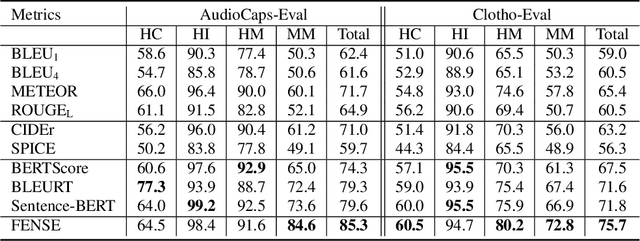
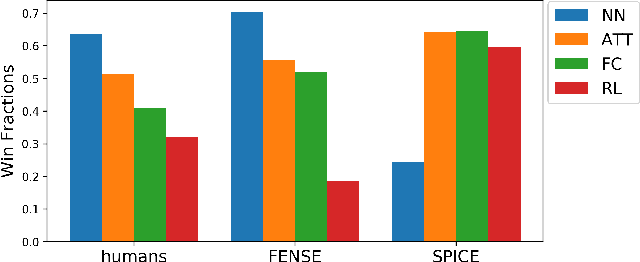
Automated audio captioning aims at generating textual descriptions for an audio clip. To evaluate the quality of generated audio captions, previous works directly adopt image captioning metrics like SPICE and CIDEr, without justifying their suitability in this new domain, which may mislead the development of advanced models. This problem is still unstudied due to the lack of human judgment datasets on caption quality. Therefore, we firstly construct two evaluation benchmarks, AudioCaps-Eval and Clotho-Eval. They are established with pairwise comparison instead of absolute rating to achieve better inter-annotator agreement. Current metrics are found in poor correlation with human annotations on these datasets. To overcome their limitations, we propose a metric named FENSE, where we combine the strength of Sentence-BERT in capturing similarity, and a novel Error Detector to penalize erroneous sentences for robustness. On the newly established benchmarks, FENSE outperforms current metrics by 14-25% accuracy. Code, data and web demo available at: https://github.com/blmoistawinde/fense
Making Heads or Tails: Towards Semantically Consistent Visual Counterfactuals
Mar 24, 2022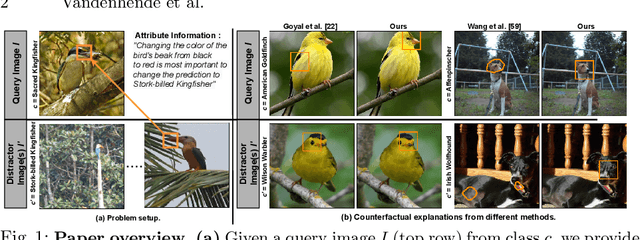
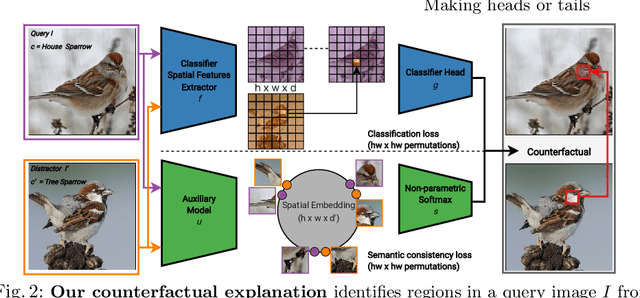
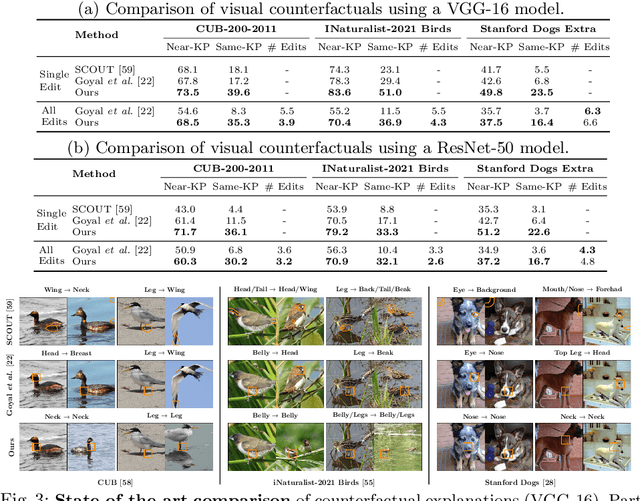

A visual counterfactual explanation replaces image regions in a query image with regions from a distractor image such that the system's decision on the transformed image changes to the distractor class. In this work, we present a novel framework for computing visual counterfactual explanations based on two key ideas. First, we enforce that the \textit{replaced} and \textit{replacer} regions contain the same semantic part, resulting in more semantically consistent explanations. Second, we use multiple distractor images in a computationally efficient way and obtain more discriminative explanations with fewer region replacements. Our approach is $\mathbf{27\%}$ more semantically consistent and an order of magnitude faster than a competing method on three fine-grained image recognition datasets. We highlight the utility of our counterfactuals over existing works through machine teaching experiments where we teach humans to classify different bird species. We also complement our explanations with the vocabulary of parts and attributes that contributed the most to the system's decision. In this task as well, we obtain state-of-the-art results when using our counterfactual explanations relative to existing works, reinforcing the importance of semantically consistent explanations.
Spatial-temporal Concept based Explanation of 3D ConvNets
Jun 09, 2022
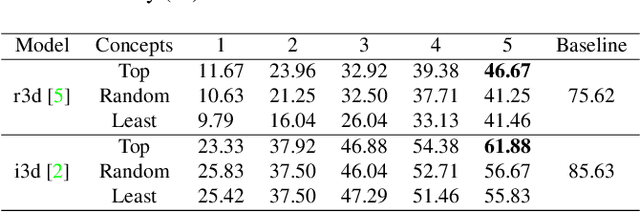
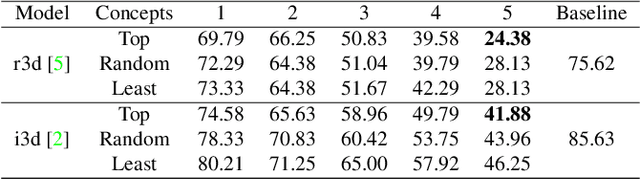
Recent studies have achieved outstanding success in explaining 2D image recognition ConvNets. On the other hand, due to the computation cost and complexity of video data, the explanation of 3D video recognition ConvNets is relatively less studied. In this paper, we present a 3D ACE (Automatic Concept-based Explanation) framework for interpreting 3D ConvNets. In our approach: (1) videos are represented using high-level supervoxels, which is straightforward for human to understand; and (2) the interpreting framework estimates a score for each voxel, which reflects its importance in the decision procedure. Experiments show that our method can discover spatial-temporal concepts of different importance-levels, and thus can explore the influence of the concepts on a target task, such as action classification, in-depth. The codes are publicly available.
PoisonedEncoder: Poisoning the Unlabeled Pre-training Data in Contrastive Learning
May 17, 2022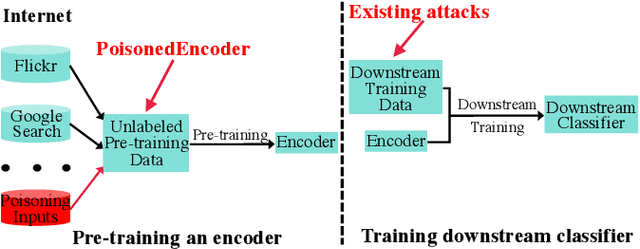
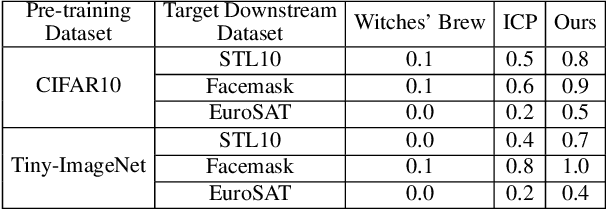
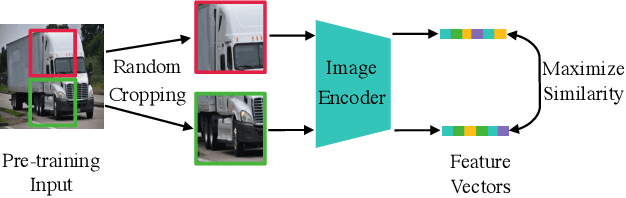

Contrastive learning pre-trains an image encoder using a large amount of unlabeled data such that the image encoder can be used as a general-purpose feature extractor for various downstream tasks. In this work, we propose PoisonedEncoder, a data poisoning attack to contrastive learning. In particular, an attacker injects carefully crafted poisoning inputs into the unlabeled pre-training data, such that the downstream classifiers built based on the poisoned encoder for multiple target downstream tasks simultaneously classify attacker-chosen, arbitrary clean inputs as attacker-chosen, arbitrary classes. We formulate our data poisoning attack as a bilevel optimization problem, whose solution is the set of poisoning inputs; and we propose a contrastive-learning-tailored method to approximately solve it. Our evaluation on multiple datasets shows that PoisonedEncoder achieves high attack success rates while maintaining the testing accuracy of the downstream classifiers built upon the poisoned encoder for non-attacker-chosen inputs. We also evaluate five defenses against PoisonedEncoder, including one pre-processing, three in-processing, and one post-processing defenses. Our results show that these defenses can decrease the attack success rate of PoisonedEncoder, but they also sacrifice the utility of the encoder or require a large clean pre-training dataset.
InvNorm: Domain Generalization for Object Detection in Gastrointestinal Endoscopy
May 05, 2022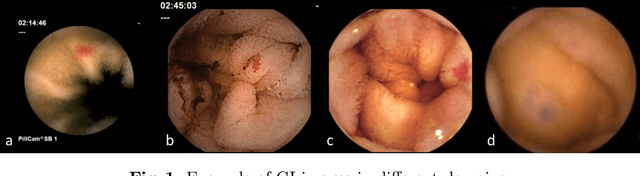
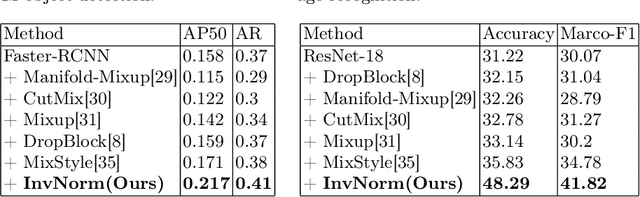
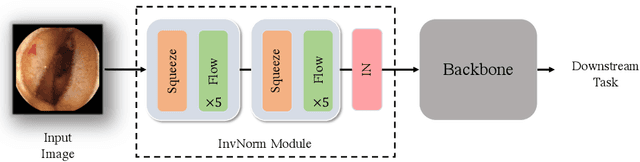
Domain Generalization is a challenging topic in computer vision, especially in Gastrointestinal Endoscopy image analysis. Due to several device limitations and ethical reasons, current open-source datasets are typically collected on a limited number of patients using the same brand of sensors. Different brands of devices and individual differences will significantly affect the model's generalizability. Therefore, to address the generalization problem in GI(Gastrointestinal) endoscopy, we propose a multi-domain GI dataset and a light, plug-in block called InvNorm(Invertible Normalization), which could achieve a better generalization performance in any structure. Previous DG(Domain Generalization) methods fail to achieve invertible transformation, which would lead to some misleading augmentation. Moreover, these models would be more likely to lead to medical ethics issues. Our method utilizes normalizing flow to achieve invertible and explainable style normalization to address the problem. The effectiveness of InvNorm is demonstrated on a wide range of tasks, including GI recognition, GI object detection, and natural image recognition.