 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Visible-light Images Guided Cross-Spectrum Depth Estimation from Dual-Modality Cameras
Apr 30, 2022

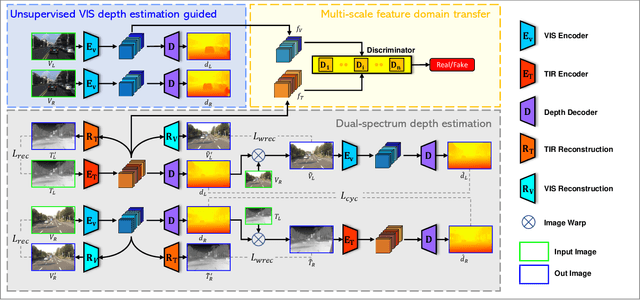


Cross-spectrum depth estimation aims to provide a depth map in all illumination conditions with a pair of dual-spectrum images. It is valuable for autonomous vehicle applications when the vehicle is equipped with two cameras of different modalities. However, images captured by different-modality cameras can be photometrically quite different. Therefore, cross-spectrum depth estimation is a very challenging problem. Moreover, the shortage of large-scale open-source datasets also retards further research in this field. In this paper, we propose an unsupervised visible-light image guided cross-spectrum (i.e., thermal and visible-light, TIR-VIS in short) depth estimation framework given a pair of RGB and thermal images captured from a visible-light camera and a thermal one. We first adopt a base depth estimation network using RGB-image pairs. Then we propose a multi-scale feature transfer network to transfer features from the TIR-VIS domain to the VIS domain at the feature level to fit the trained depth estimation network. At last, we propose a cross-spectrum depth cycle consistency to improve the depth result of dual-spectrum image pairs. Meanwhile, we release a large dual-spectrum depth estimation dataset with visible-light and far-infrared stereo images captured in different scenes to the society. The experiment result shows that our method achieves better performance than the compared existing methods. Our datasets is available at https://github.com/whitecrow1027/VIS-TIR-Datasets.
A robust and lightweight deep attention multiple instance learning algorithm for predicting genetic alterations
May 31, 2022Deep-learning models based on whole-slide digital pathology images (WSIs) become increasingly popular for predicting molecular biomarkers. Instance-based models has been the mainstream strategy for predicting genetic alterations using WSIs although bag-based models along with self-attention mechanism-based algorithms have been proposed for other digital pathology applications. In this paper, we proposed a novel Attention-based Multiple Instance Mutation Learning (AMIML) model for predicting gene mutations. AMIML was comprised of successive 1-D convolutional layers, a decoder, and a residual weight connection to facilitate further integration of a lightweight attention mechanism to detect the most predictive image patches. Using data for 24 clinically relevant genes from four cancer cohorts in The Cancer Genome Atlas (TCGA) studies (UCEC, BRCA, GBM and KIRC), we compared AMIML with one popular instance-based model and four recently published bag-based models (e.g., CHOWDER, HE2RNA, etc.). AMIML demonstrated excellent robustness, not only outperforming all the five baseline algorithms in the vast majority of the tested genes (17 out of 24), but also providing near-best-performance for the other seven genes. Conversely, the performance of the baseline published algorithms varied across different cancers/genes. In addition, compared to the published models for genetic alterations, AMIML provided a significant improvement for predicting a wide range of genes (e.g., KMT2C, TP53, and SETD2 for KIRC; ERBB2, BRCA1, and BRCA2 for BRCA; JAK1, POLE, and MTOR for UCEC) as well as produced outstanding predictive models for other clinically relevant gene mutations, which have not been reported in the current literature. Furthermore, with the flexible and interpretable attention-based MIL pooling mechanism, AMIML could further zero-in and detect predictive image patches.
Sequence-aware multimodal page classification of Brazilian legal documents
Jul 02, 2022
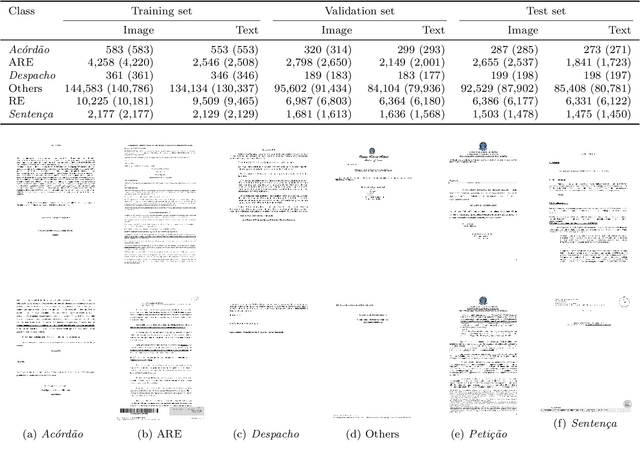
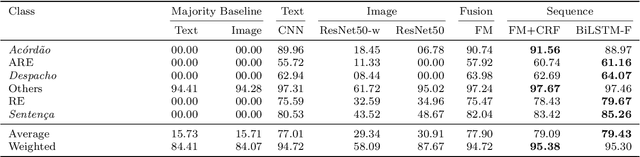
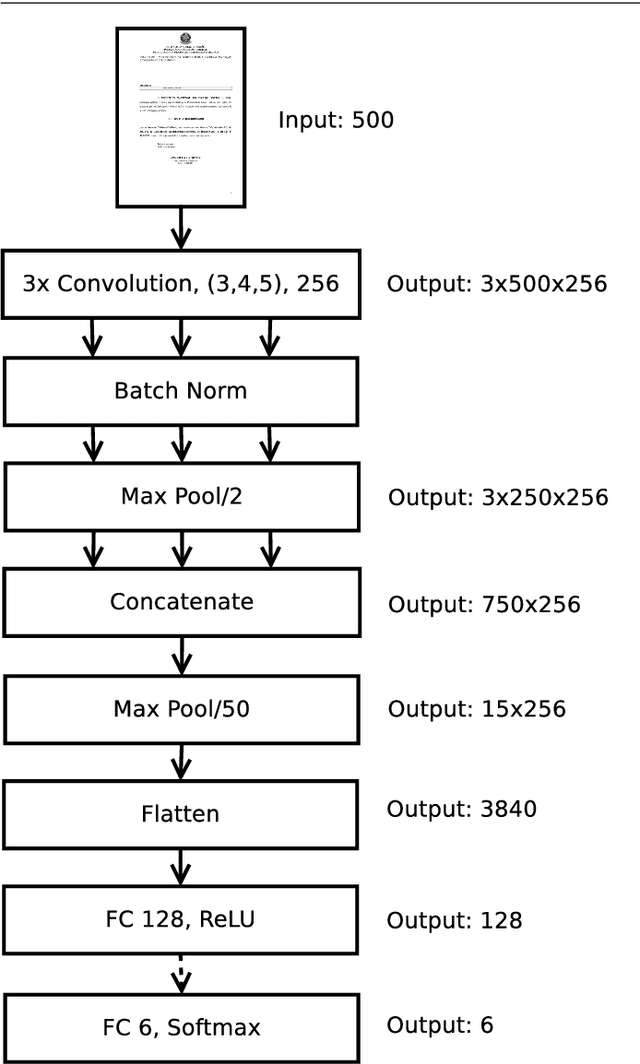
The Brazilian Supreme Court receives tens of thousands of cases each semester. Court employees spend thousands of hours to execute the initial analysis and classification of those cases -- which takes effort away from posterior, more complex stages of the case management workflow. In this paper, we explore multimodal classification of documents from Brazil's Supreme Court. We train and evaluate our methods on a novel multimodal dataset of 6,510 lawsuits (339,478 pages) with manual annotation assigning each page to one of six classes. Each lawsuit is an ordered sequence of pages, which are stored both as an image and as a corresponding text extracted through optical character recognition. We first train two unimodal classifiers: a ResNet pre-trained on ImageNet is fine-tuned on the images, and a convolutional network with filters of multiple kernel sizes is trained from scratch on document texts. We use them as extractors of visual and textual features, which are then combined through our proposed Fusion Module. Our Fusion Module can handle missing textual or visual input by using learned embeddings for missing data. Moreover, we experiment with bi-directional Long Short-Term Memory (biLSTM) networks and linear-chain conditional random fields to model the sequential nature of the pages. The multimodal approaches outperform both textual and visual classifiers, especially when leveraging the sequential nature of the pages.
GLANCE: Global to Local Architecture-Neutral Concept-based Explanations
Jul 05, 2022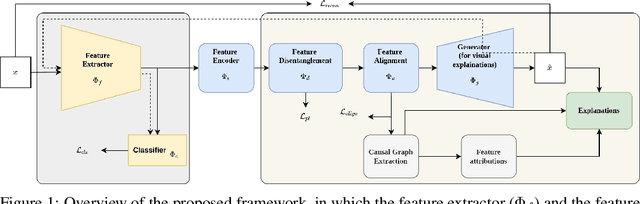

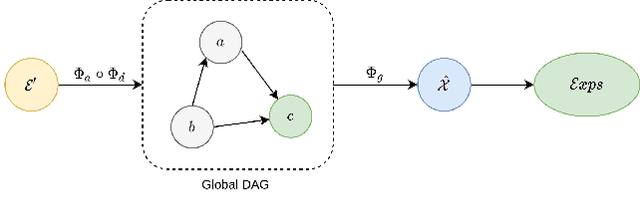
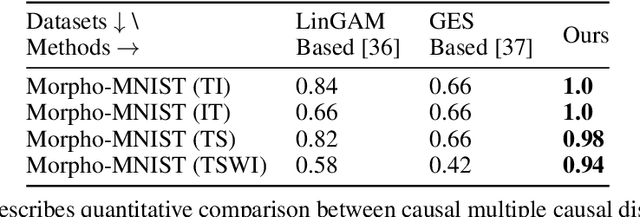
Most of the current explainability techniques focus on capturing the importance of features in input space. However, given the complexity of models and data-generating processes, the resulting explanations are far from being `complete', in that they lack an indication of feature interactions and visualization of their `effect'. In this work, we propose a novel twin-surrogate explainability framework to explain the decisions made by any CNN-based image classifier (irrespective of the architecture). For this, we first disentangle latent features from the classifier, followed by aligning these features to observed/human-defined `context' features. These aligned features form semantically meaningful concepts that are used for extracting a causal graph depicting the `perceived' data-generating process, describing the inter- and intra-feature interactions between unobserved latent features and observed `context' features. This causal graph serves as a global model from which local explanations of different forms can be extracted. Specifically, we provide a generator to visualize the `effect' of interactions among features in latent space and draw feature importance therefrom as local explanations. Our framework utilizes adversarial knowledge distillation to faithfully learn a representation from the classifiers' latent space and use it for extracting visual explanations. We use the styleGAN-v2 architecture with an additional regularization term to enforce disentanglement and alignment. We demonstrate and evaluate explanations obtained with our framework on Morpho-MNIST and on the FFHQ human faces dataset. Our framework is available at \url{https://github.com/koriavinash1/GLANCE-Explanations}.
Open High-Resolution Satellite Imagery: The WorldStrat Dataset -- With Application to Super-Resolution
Jul 13, 2022

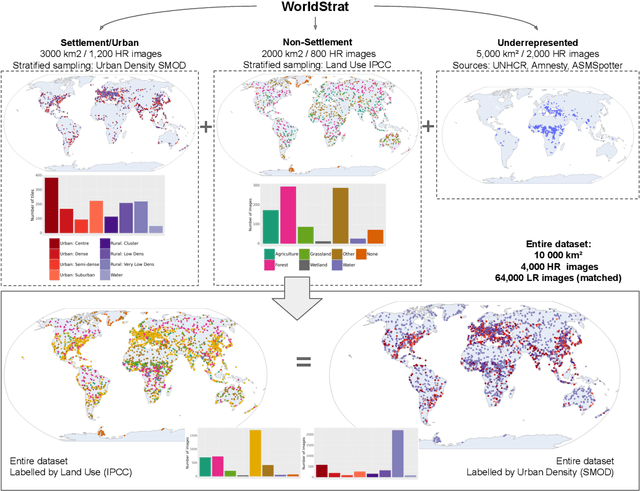
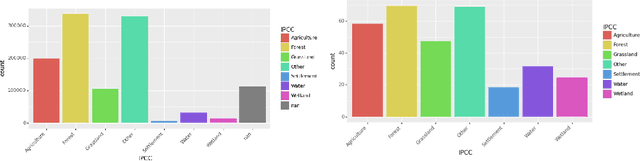
Analyzing the planet at scale with satellite imagery and machine learning is a dream that has been constantly hindered by the cost of difficult-to-access highly-representative high-resolution imagery. To remediate this, we introduce here the WorldStrat dataset. The largest and most varied such publicly available dataset, at Airbus SPOT 6/7 satellites' high resolution of up to 1.5 m/pixel, empowered by European Space Agency's Phi-Lab as part of the ESA-funded QueryPlanet project, we curate nearly 10,000 sqkm of unique locations to ensure stratified representation of all types of land-use across the world: from agriculture to ice caps, from forests to multiple urbanization densities. We also enrich those with locations typically under-represented in ML datasets: sites of humanitarian interest, illegal mining sites, and settlements of persons at risk. We temporally-match each high-resolution image with multiple low-resolution images from the freely accessible lower-resolution Sentinel-2 satellites at 10 m/pixel. We accompany this dataset with an open-source Python package to: rebuild or extend the WorldStrat dataset, train and infer baseline algorithms, and learn with abundant tutorials, all compatible with the popular EO-learn toolbox. We hereby hope to foster broad-spectrum applications of ML to satellite imagery, and possibly develop from free public low-resolution Sentinel2 imagery the same power of analysis allowed by costly private high-resolution imagery. We illustrate this specific point by training and releasing several highly compute-efficient baselines on the task of Multi-Frame Super-Resolution. High-resolution Airbus imagery is CC BY-NC, while the labels and Sentinel2 imagery are CC BY, and the source code and pre-trained models under BSD. The dataset is available at https://zenodo.org/record/6810792 and the software package at https://github.com/worldstrat/worldstrat .
Semi-supervised learning for medical image classification using imbalanced training data
Aug 20, 2021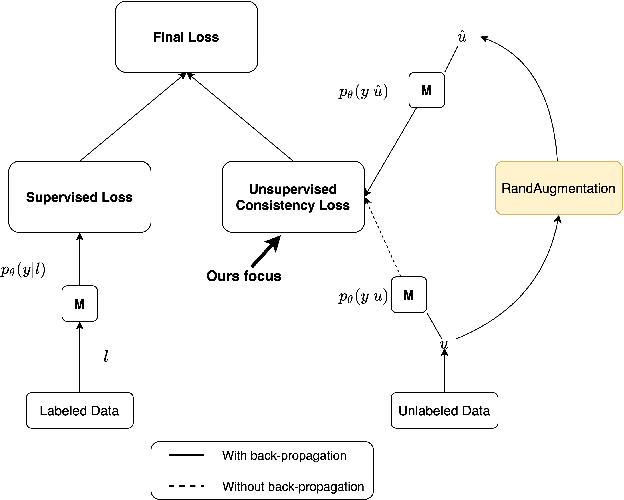
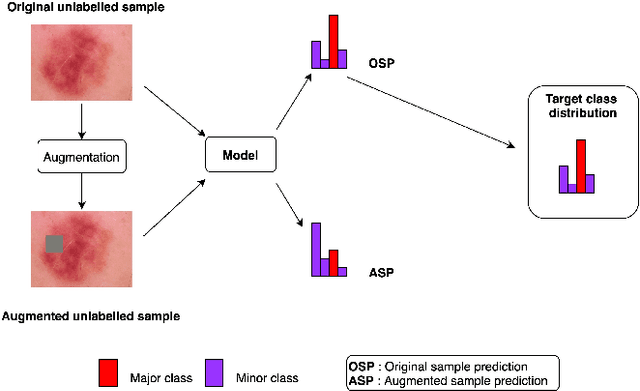
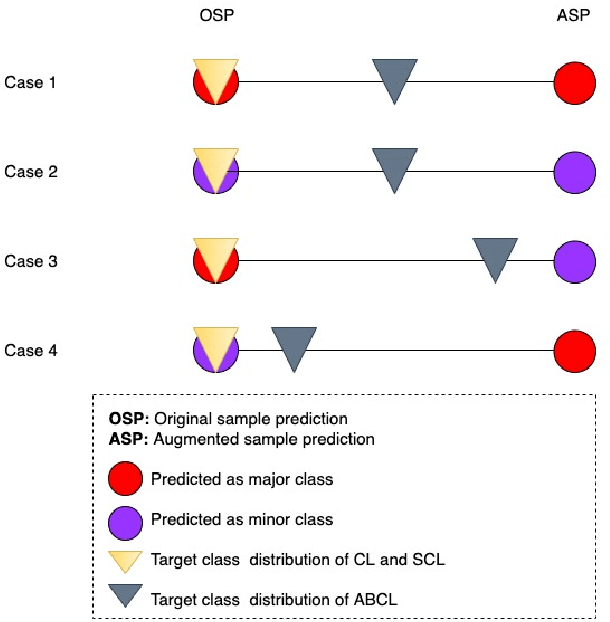
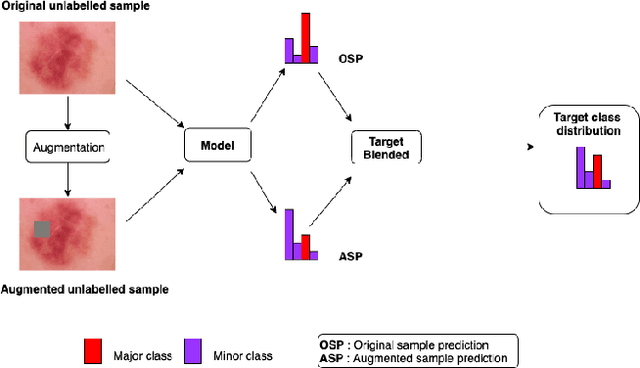
Medical image classification is often challenging for two reasons: a lack of labelled examples due to expensive and time-consuming annotation protocols, and imbalanced class labels due to the relative scarcity of disease-positive individuals in the wider population. Semi-supervised learning (SSL) methods exist for dealing with a lack of labels, but they generally do not address the problem of class imbalance. In this study we propose Adaptive Blended Consistency Loss (ABCL), a drop-in replacement for consistency loss in perturbation-based SSL methods. ABCL counteracts data skew by adaptively mixing the target class distribution of the consistency loss in accordance with class frequency. Our experiments with ABCL reveal improvements to unweighted average recall on two different imbalanced medical image classification datasets when compared with existing consistency losses that are not designed to counteract class imbalance.
Diverse Image Inpainting with Bidirectional and Autoregressive Transformers
Apr 30, 2021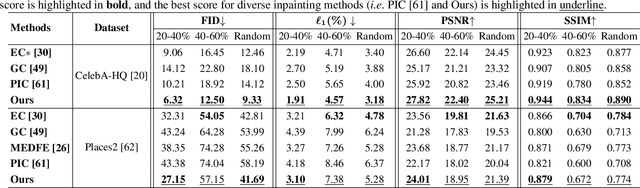
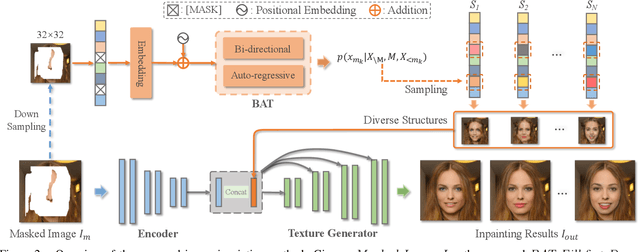
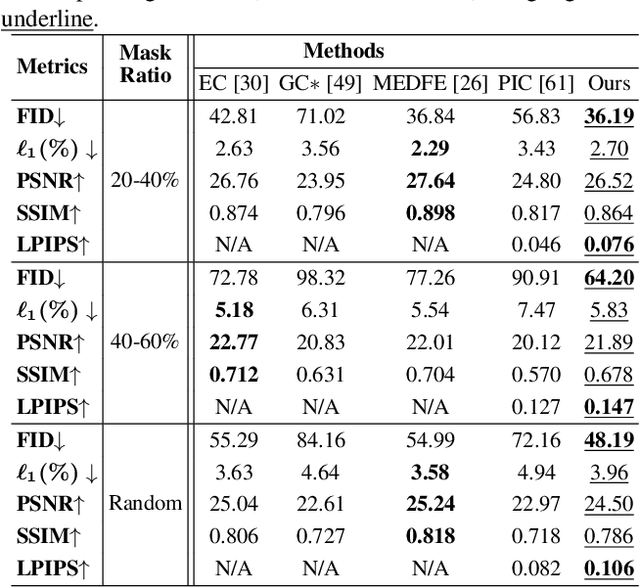
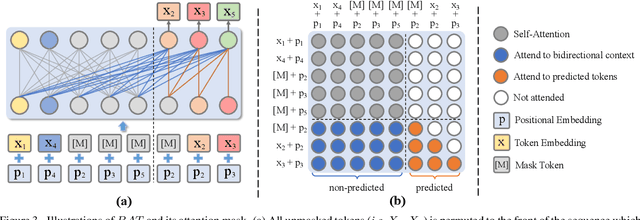
Image inpainting is an underdetermined inverse problem, it naturally allows diverse contents that fill up the missing or corrupted regions reasonably and realistically. Prevalent approaches using convolutional neural networks (CNNs) can synthesize visually pleasant contents, but CNNs suffer from limited perception fields for capturing global features. With image-level attention, transformers enable to model long-range dependencies and generate diverse contents with autoregressive modeling of pixel-sequence distributions. However, the unidirectional attention in transformers is suboptimal as corrupted regions can have arbitrary shapes with contexts from arbitrary directions. We propose BAT-Fill, an image inpainting framework with a novel bidirectional autoregressive transformer (BAT) that models deep bidirectional contexts for autoregressive generation of diverse inpainting contents. BAT-Fill inherits the merits of transformers and CNNs in a two-stage manner, which allows to generate high-resolution contents without being constrained by the quadratic complexity of attention in transformers. Specifically, it first generates pluralistic image structures of low resolution by adapting transformers and then synthesizes realistic texture details of high resolutions with a CNN-based up-sampling network. Extensive experiments over multiple datasets show that BAT-Fill achieves superior diversity and fidelity in image inpainting qualitatively and quantitatively.
Anti-aliasing Deep Image Classifiers using Novel Depth Adaptive Blurring and Activation Function
Oct 03, 2021
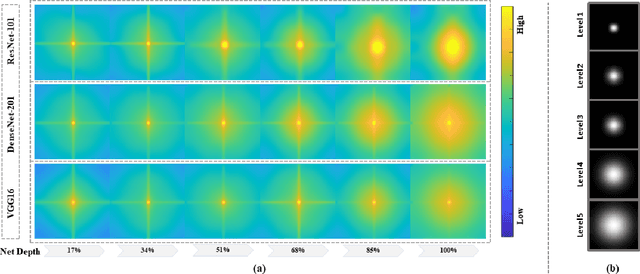

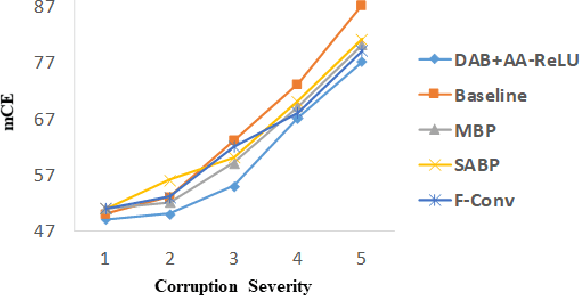
Deep convolutional networks are vulnerable to image translation or shift, partly due to common down-sampling layers, e.g., max-pooling and strided convolution. These operations violate the Nyquist sampling rate and cause aliasing. The textbook solution is low-pass filtering (blurring) before down-sampling, which can benefit deep networks as well. Even so, non-linearity units, such as ReLU, often re-introduce the problem, suggesting that blurring alone may not suffice. In this work, first, we analyse deep features with Fourier transform and show that Depth Adaptive Blurring is more effective, as opposed to monotonic blurring. To this end, we outline how this can replace existing down-sampling methods. Second, we introduce a novel activation function -- with a built-in low pass filter, to keep the problem from reappearing. From experiments, we observe generalisation on other forms of transformations and corruptions as well, e.g., rotation, scale, and noise. We evaluate our method under three challenging settings: (1) a variety of image translations; (2) adversarial attacks -- both $\ell_{p}$ bounded and unbounded; and (3) data corruptions and perturbations. In each setting, our method achieves state-of-the-art results and improves clean accuracy on various benchmark datasets.
MSHT: Multi-stage Hybrid Transformer for the ROSE Image Analysis of Pancreatic Cancer
Dec 27, 2021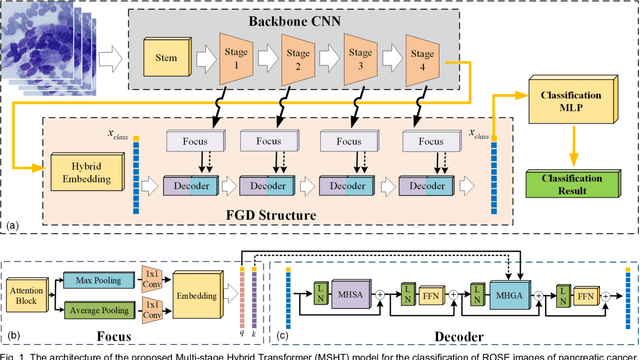
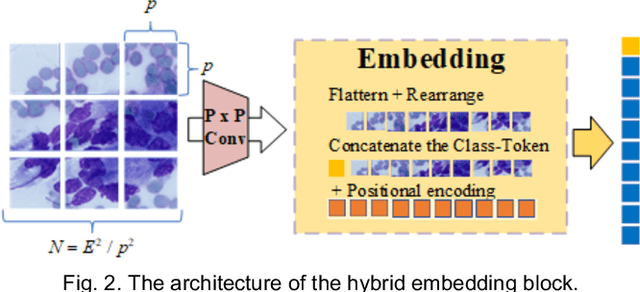

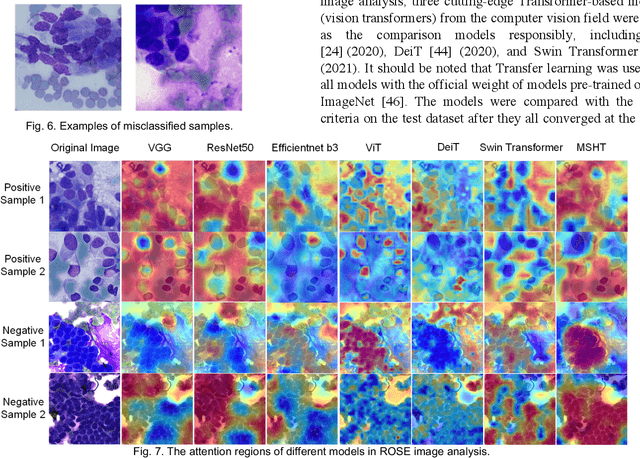
Pancreatic cancer is one of the most malignant cancers in the world, which deteriorates rapidly with very high mortality. The rapid on-site evaluation (ROSE) technique innovates the workflow by immediately analyzing the fast stained cytopathological images with on-site pathologists, which enables faster diagnosis in this time-pressured process. However, the wider expansion of ROSE diagnosis has been hindered by the lack of experienced pathologists. To overcome this problem, we propose a hybrid high-performance deep learning model to enable the automated workflow, thus freeing the occupation of the valuable time of pathologists. By firstly introducing the Transformer block into this field with our particular multi-stage hybrid design, the spatial features generated by the convolutional neural network (CNN) significantly enhance the Transformer global modeling. Turning multi-stage spatial features as global attention guidance, this design combines the robustness from the inductive bias of CNN with the sophisticated global modeling power of Transformer. A dataset of 4240 ROSE images is collected to evaluate the method in this unexplored field. The proposed multi-stage hybrid Transformer (MSHT) achieves 95.68% in classification accuracy, which is distinctively higher than the state-of-the-art models. Facing the need for interpretability, MSHT outperforms its counterparts with more accurate attention regions. The results demonstrate that the MSHT can distinguish cancer samples accurately at an unprecedented image scale, laying the foundation for deploying automatic decision systems and enabling the expansion of ROSE in clinical practice. The code and records are available at: https://github.com/sagizty/Multi-Stage-Hybrid-Transformer.
On Leveraging Variational Graph Embeddings for Open World Compositional Zero-Shot Learning
Apr 23, 2022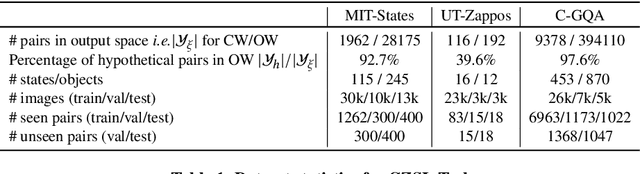
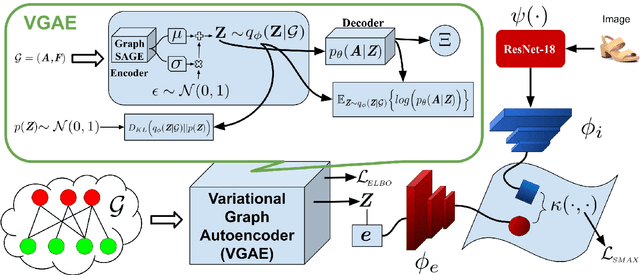
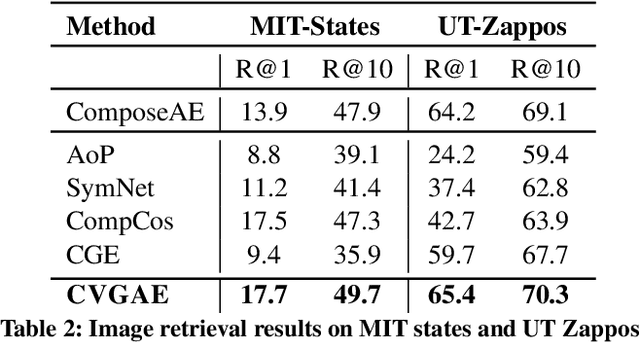
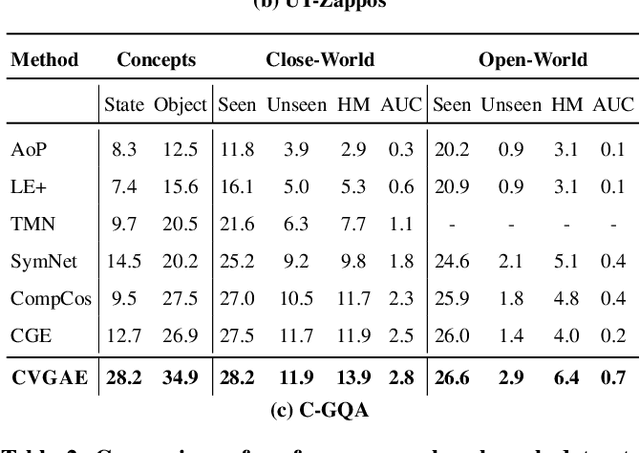
Humans are able to identify and categorize novel compositions of known concepts. The task in Compositional Zero-Shot learning (CZSL) is to learn composition of primitive concepts, i.e. objects and states, in such a way that even their novel compositions can be zero-shot classified. In this work, we do not assume any prior knowledge on the feasibility of novel compositions i.e.open-world setting, where infeasible compositions dominate the search space. We propose a Compositional Variational Graph Autoencoder (CVGAE) approach for learning the variational embeddings of the primitive concepts (nodes) as well as feasibility of their compositions (via edges). Such modelling makes CVGAE scalable to real-world application scenarios. This is in contrast to SOTA method, CGE, which is computationally very expensive. e.g.for benchmark C-GQA dataset, CGE requires 3.94 x 10^5 nodes, whereas CVGAE requires only 1323 nodes. We learn a mapping of the graph and image embeddings onto a common embedding space. CVGAE adopts a deep metric learning approach and learns a similarity metric in this space via bi-directional contrastive loss between projected graph and image embeddings. We validate the effectiveness of our approach on three benchmark datasets.We also demonstrate via an image retrieval task that the representations learnt by CVGAE are better suited for compositional generalization.