 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End AI-based MRI Reconstruction and Lesion Detection Pipeline for Evaluation of Deep Learning Image Reconstruction
Sep 23, 2021
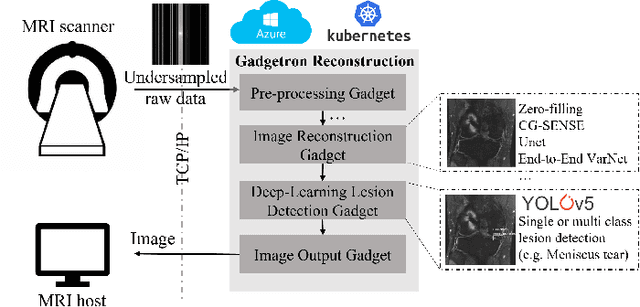
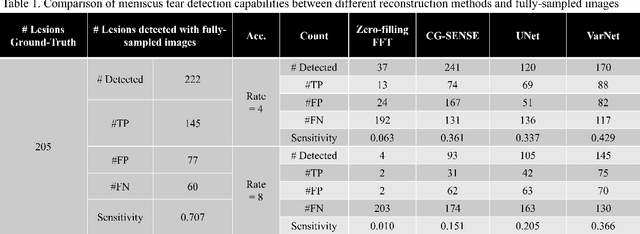
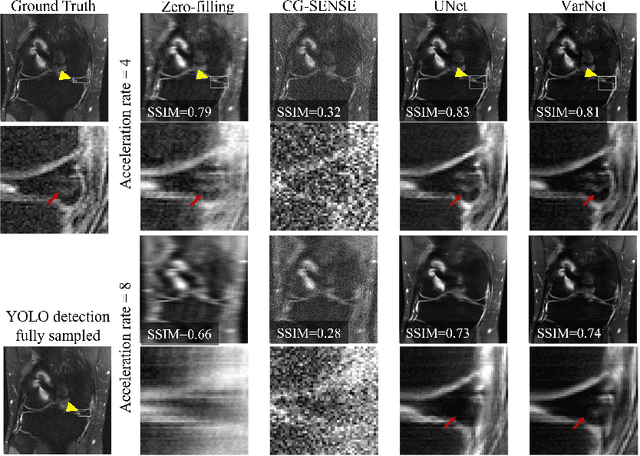

Deep learning techniques have emerged as a promising approach to highly accelerated MRI. However, recent reconstruction challenges have shown several drawbacks in current deep learning approaches, including the loss of fine image details even using models that perform well in terms of global quality metrics. In this study, we propose an end-to-end deep learning framework for image reconstruction and pathology detection, which enables a clinically aware evaluation of deep learning reconstruction quality. The solution is demonstrated for a use case in detecting meniscal tears on knee MRI studies, ultimately finding a loss of fine image details with common reconstruction methods expressed as a reduced ability to detect important pathology like meniscal tears. Despite the common practice of quantitative reconstruction methodology evaluation with metrics such as SSIM, impaired pathology detection as an automated pathology-based reconstruction evaluation approach suggests existing quantitative methods do not capture clinically important reconstruction outcomes.
Colonoscopy Navigation using End-to-End Deep Visuomotor Control: A User Study
Jun 30, 2022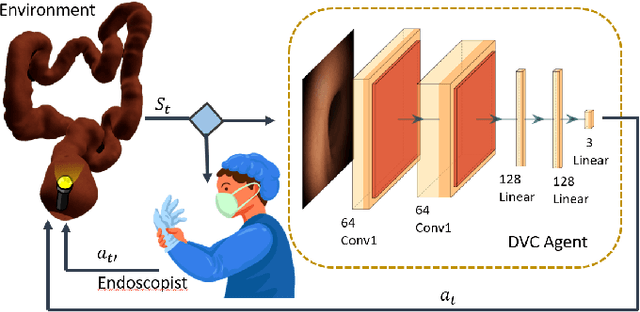
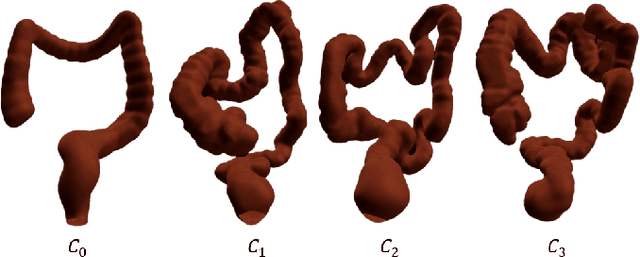
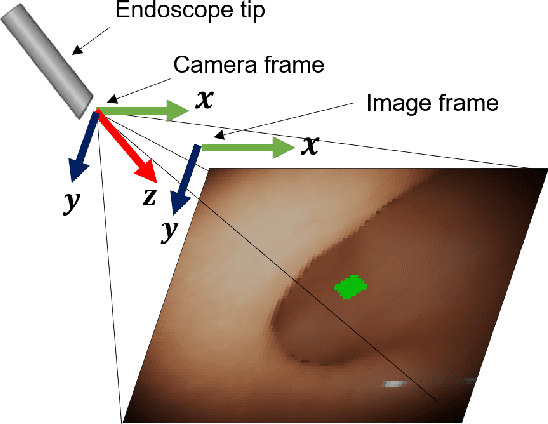
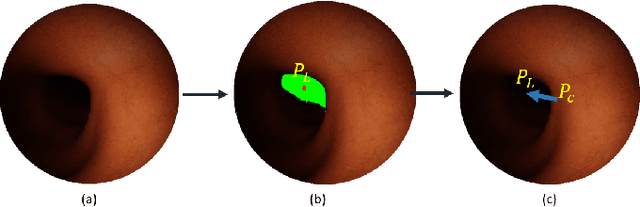
Flexible endoscopes for colonoscopy present several limitations due to their inherent complexity, resulting in patient discomfort and lack of intuitiveness for clinicians. Robotic devices together with autonomous control represent a viable solution to reduce the workload of endoscopists and the training time while improving the overall procedure outcome. Prior works on autonomous endoscope control use heuristic policies that limit their generalisation to the unstructured and highly deformable colon environment and require frequent human intervention. This work proposes an image-based control of the endoscope using Deep Reinforcement Learning, called Deep Visuomotor Control (DVC), to exhibit adaptive behaviour in convoluted sections of the colon tract. DVC learns a mapping between the endoscopic images and the control signal of the endoscope. A first user study of 20 expert gastrointestinal endoscopists was carried out to compare their navigation performance with DVC policies using a realistic virtual simulator. The results indicate that DVC shows equivalent performance on several assessment parameters, being more safer. Moreover, a second user study with 20 novice participants was performed to demonstrate easier human supervision compared to a state-of-the-art heuristic control policy. Seamless supervision of colonoscopy procedures would enable interventionists to focus on the medical decision rather than on the control problem of the endoscope.
Masked Siamese ConvNets
Jun 15, 2022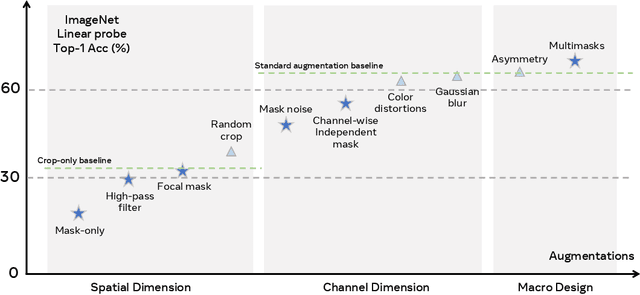
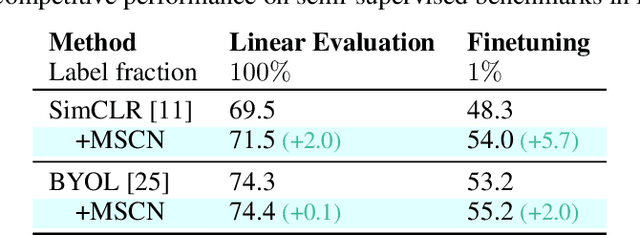

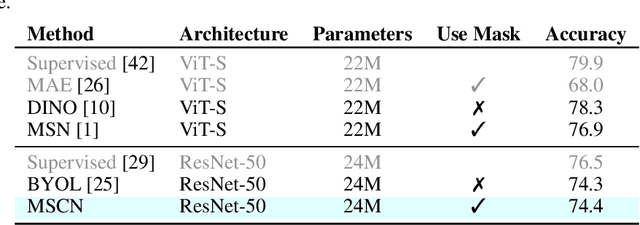
Self-supervised learning has shown superior performances over supervised methods on various vision benchmarks. The siamese network, which encourages embeddings to be invariant to distortions, is one of the most successful self-supervised visual representation learning approaches. Among all the augmentation methods, masking is the most general and straightforward method that has the potential to be applied to all kinds of input and requires the least amount of domain knowledge. However, masked siamese networks require particular inductive bias and practically only work well with Vision Transformers. This work empirically studies the problems behind masked siamese networks with ConvNets. We propose several empirical designs to overcome these problems gradually. Our method performs competitively on low-shot image classification and outperforms previous methods on object detection benchmarks. We discuss several remaining issues and hope this work can provide useful data points for future general-purpose self-supervised learning.
Automated Wheat Disease Detection using a ROS-based Autonomous Guided UAV
Jun 30, 2022
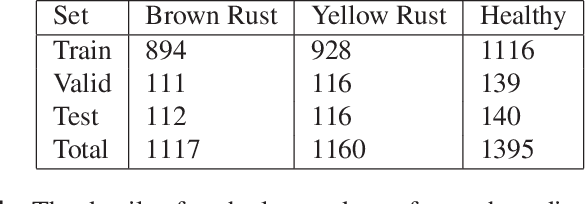
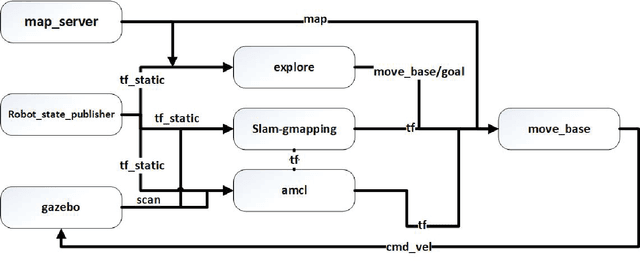
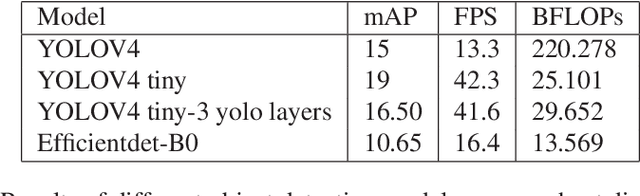
With the increase in world population, food resources have to be modified to be more productive, resistive, and reliable. Wheat is one of the most important food resources in the world, mainly because of the variety of wheat-based products. Wheat crops are threatened by three main types of diseases which cause large amounts of annual damage in crop yield. These diseases can be eliminated by using pesticides at the right time. While the task of manually spraying pesticides is burdensome and expensive, agricultural robotics can aid farmers by increasing the speed and decreasing the amount of chemicals. In this work, a smart autonomous system has been implemented on an unmanned aerial vehicle to automate the task of monitoring wheat fields. First, an image-based deep learning approach is used to detect and classify disease-infected wheat plants. To find the most optimal method, different approaches have been studied. Because of the lack of a public wheat-disease dataset, a custom dataset has been created and labeled. Second, an efficient mapping and navigation system is presented using a simulation in the robot operating system and Gazebo environments. A 2D simultaneous localization and mapping algorithm is used for mapping the workspace autonomously with the help of a frontier-based exploration method.
Boosting Multi-Modal E-commerce Attribute Value Extraction via Unified Learning Scheme and Dynamic Range Minimization
Jul 15, 2022
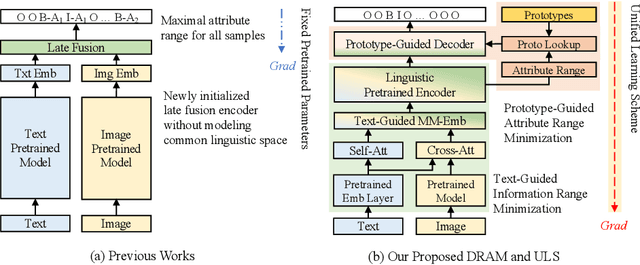
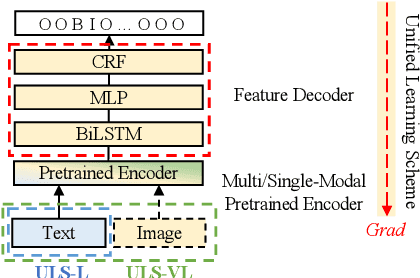

With the prosperity of e-commerce industry, various modalities, e.g., vision and language, are utilized to describe product items. It is an enormous challenge to understand such diversified data, especially via extracting the attribute-value pairs in text sequences with the aid of helpful image regions. Although a series of previous works have been dedicated to this task, there remain seldomly investigated obstacles that hinder further improvements: 1) Parameters from up-stream single-modal pretraining are inadequately applied, without proper jointly fine-tuning in a down-stream multi-modal task. 2) To select descriptive parts of images, a simple late fusion is widely applied, regardless of priori knowledge that language-related information should be encoded into a common linguistic embedding space by stronger encoders. 3) Due to diversity across products, their attribute sets tend to vary greatly, but current approaches predict with an unnecessary maximal range and lead to more potential false positives. To address these issues, we propose in this paper a novel approach to boost multi-modal e-commerce attribute value extraction via unified learning scheme and dynamic range minimization: 1) Firstly, a unified scheme is designed to jointly train a multi-modal task with pretrained single-modal parameters. 2) Secondly, a text-guided information range minimization method is proposed to adaptively encode descriptive parts of each modality into an identical space with a powerful pretrained linguistic model. 3) Moreover, a prototype-guided attribute range minimization method is proposed to first determine the proper attribute set of the current product, and then select prototypes to guide the prediction of the chosen attributes. Experiments on the popular multi-modal e-commerce benchmarks show that our approach achieves superior performance over the other state-of-the-art techniques.
Towards Self-Supervised Gaze Estimation
Mar 21, 2022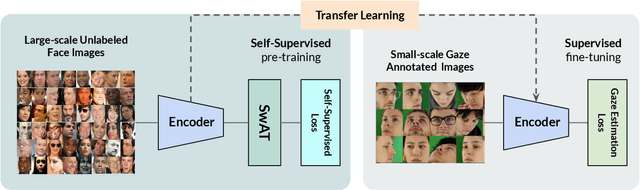

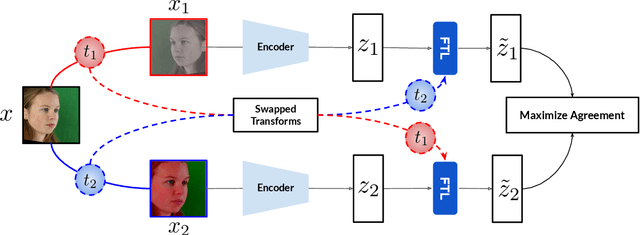
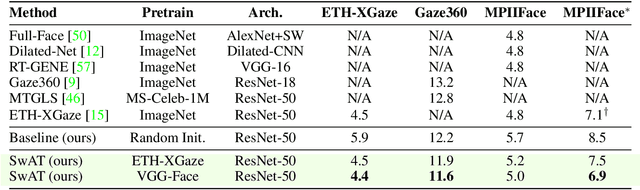
Recent joint embedding-based self-supervised methods have surpassed standard supervised approaches on various image recognition tasks such as image classification. These self-supervised methods aim at maximizing agreement between features extracted from two differently transformed views of the same image, which results in learning an invariant representation with respect to appearance and geometric image transformations. However, the effectiveness of these approaches remains unclear in the context of gaze estimation, a structured regression task that requires equivariance under geometric transformations (e.g., rotations, horizontal flip). In this work, we propose SwAT, an equivariant version of the online clustering-based self-supervised approach SwAV, to learn more informative representations for gaze estimation. We identify the most effective image transformations for self-supervised pretraining and demonstrate that SwAT, with ResNet-50 and supported with uncurated unlabeled face images, outperforms state-of-the-art gaze estimation methods and supervised baselines in various experiments. In particular, we achieve up to 57% and 25% improvements in cross-dataset and within-dataset evaluation tasks on existing benchmarks (ETH-XGaze, Gaze360, and MPIIFaceGaze).
Spatial Likelihood Voting with Self-Knowledge Distillation for Weakly Supervised Object Detection
Apr 14, 2022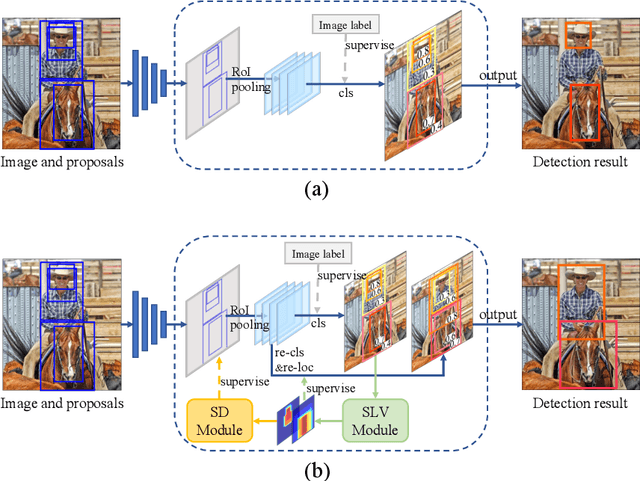
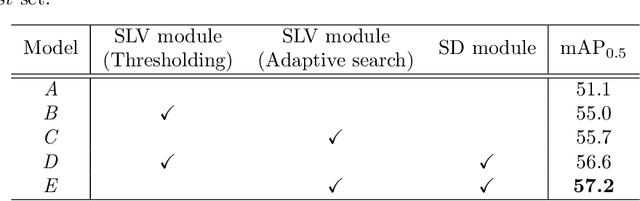
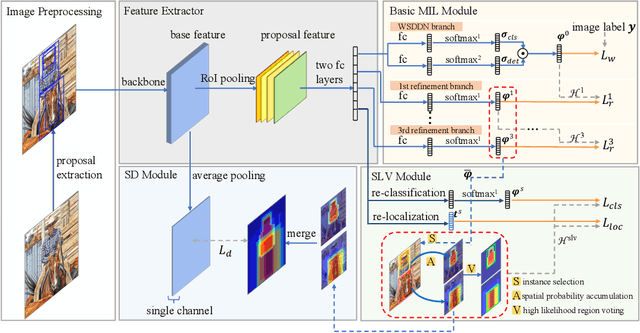

Weakly supervised object detection (WSOD), which is an effective way to train an object detection model using only image-level annotations, has attracted considerable attention from researchers. However, most of the existing methods, which are based on multiple instance learning (MIL), tend to localize instances to the discriminative parts of salient objects instead of the entire content of all objects. In this paper, we propose a WSOD framework called the Spatial Likelihood Voting with Self-knowledge Distillation Network (SLV-SD Net). In this framework, we introduce a spatial likelihood voting (SLV) module to converge region proposal localization without bounding box annotations. Specifically, in every iteration during training, all the region proposals in a given image act as voters voting for the likelihood of each category in the spatial dimensions. After dilating the alignment on the area with large likelihood values, the voting results are regularized as bounding boxes, which are then used for the final classification and localization. Based on SLV, we further propose a self-knowledge distillation (SD) module to refine the feature representations of the given image. The likelihood maps generated by the SLV module are used to supervise the feature learning of the backbone network, encouraging the network to attend to wider and more diverse areas of the image. Extensive experiments on the PASCAL VOC 2007/2012 and MS-COCO datasets demonstrate the excellent performance of SLV-SD Net. In addition, SLV-SD Net produces new state-of-the-art results on these benchmarks.
* arXiv admin note: text overlap with arXiv:2006.12884
Can Audio Captions Be Evaluated with Image Caption Metrics?
Oct 10, 2021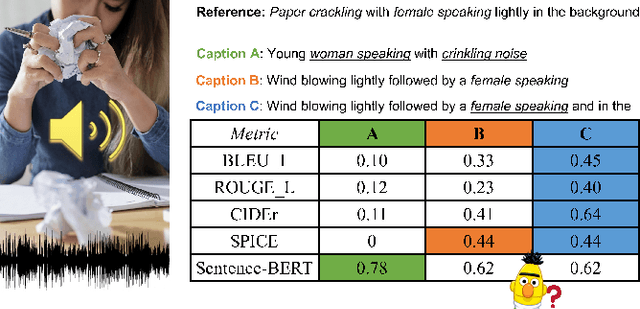

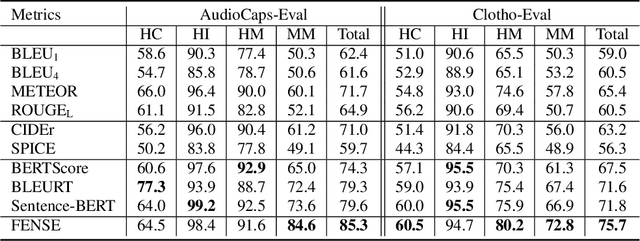
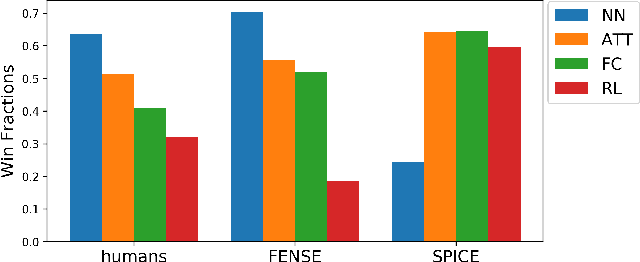
Automated audio captioning aims at generating textual descriptions for an audio clip. To evaluate the quality of generated audio captions, previous works directly adopt image captioning metrics like SPICE and CIDEr, without justifying their suitability in this new domain, which may mislead the development of advanced models. This problem is still unstudied due to the lack of human judgment datasets on caption quality. Therefore, we firstly construct two evaluation benchmarks, AudioCaps-Eval and Clotho-Eval. They are established with pairwise comparison instead of absolute rating to achieve better inter-annotator agreement. Current metrics are found in poor correlation with human annotations on these datasets. To overcome their limitations, we propose a metric named FENSE, where we combine the strength of Sentence-BERT in capturing similarity, and a novel Error Detector to penalize erroneous sentences for robustness. On the newly established benchmarks, FENSE outperforms current metrics by 14-25% accuracy. Code, data and web demo available at: https://github.com/blmoistawinde/fense
Rethink Transfer Learning in Medical Image Classification
Jun 10, 2021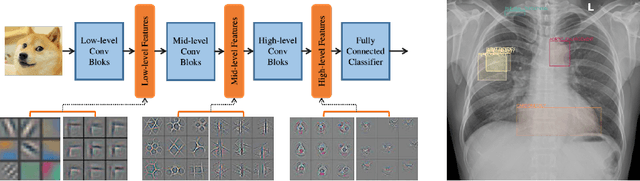
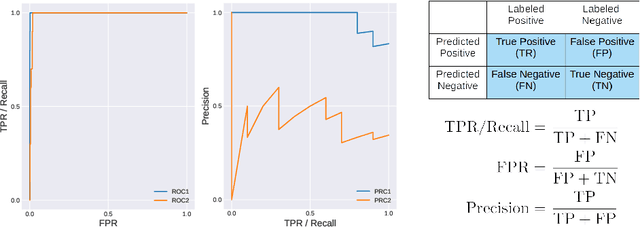
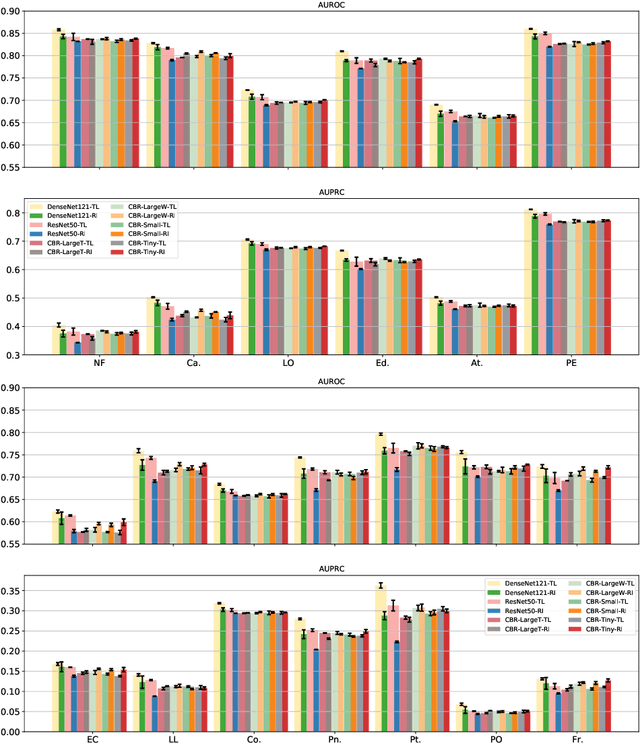
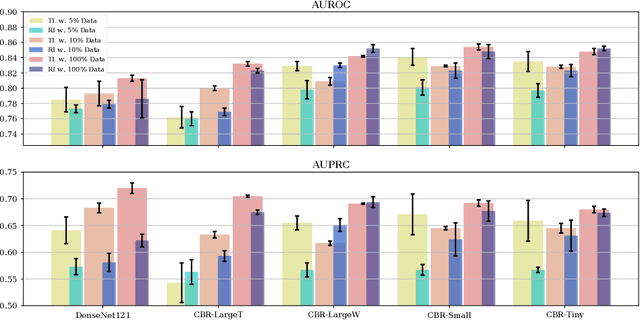
Transfer learning (TL) with deep convolutional neural networks (DCNNs) has proved successful in medical image classification (MIC). However, the current practice is puzzling, as MIC typically relies only on low- and/or mid-level features that are learned in the bottom layers of DCNNs. Following this intuition, we question the current strategies of TL in MIC. In this paper, we perform careful experimental comparisons between shallow and deep networks for classification on two chest x-ray datasets, using different TL strategies. We find that deep models are not always favorable, and finetuning truncated deep models almost always yields the best performance, especially in data-poor regimes. Project webpage: https://sun-umn.github.io/Transfer-Learning-in-Medical-Imaging/ Keywords: Transfer learning, Medical image classification, Feature hierarchy, Medical imaging, Evaluation metrics, Imbalanced data
Transformer-based Cross-Modal Recipe Embeddings with Large Batch Training
May 10, 2022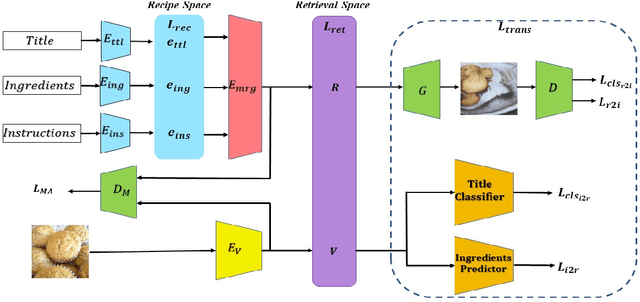
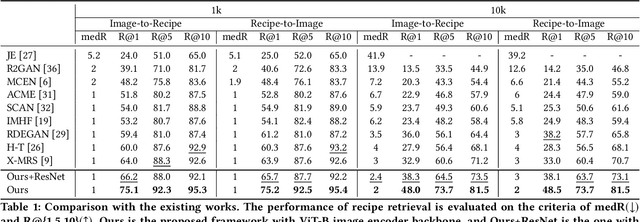
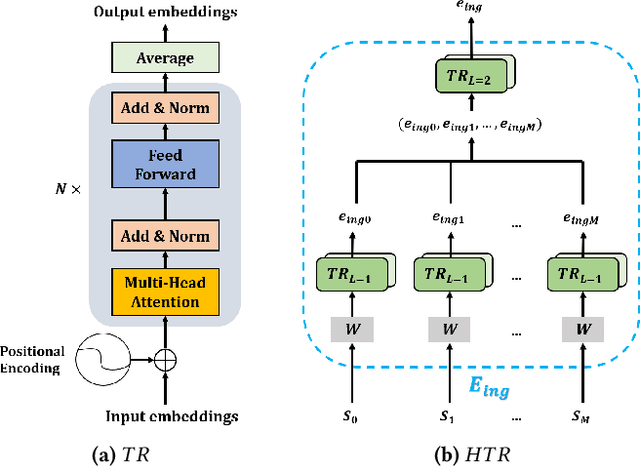
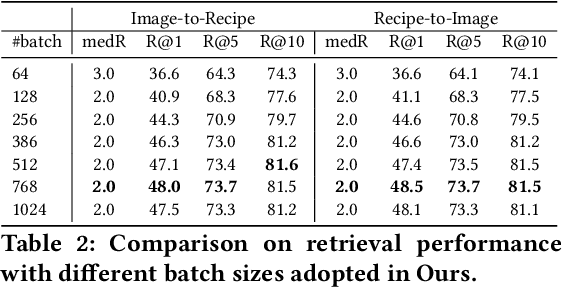
In this paper, we present a cross-modal recipe retrieval framework, Transformer-based Network for Large Batch Training (TNLBT), which is inspired by ACME~(Adversarial Cross-Modal Embedding) and H-T~(Hierarchical Transformer). TNLBT aims to accomplish retrieval tasks while generating images from recipe embeddings. We apply the Hierarchical Transformer-based recipe text encoder, the Vision Transformer~(ViT)-based recipe image encoder, and an adversarial network architecture to enable better cross-modal embedding learning for recipe texts and images. In addition, we use self-supervised learning to exploit the rich information in the recipe texts having no corresponding images. Since contrastive learning could benefit from a larger batch size according to the recent literature on self-supervised learning, we adopt a large batch size during training and have validated its effectiveness. In the experiments, the proposed framework significantly outperformed the current state-of-the-art frameworks in both cross-modal recipe retrieval and image generation tasks on the benchmark Recipe1M. This is the first work which confirmed the effectiveness of large batch training on cross-modal recipe embeddings.