 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
REVECA -- Rich Encoder-decoder framework for Video Event CAptioner
Jun 18, 2022
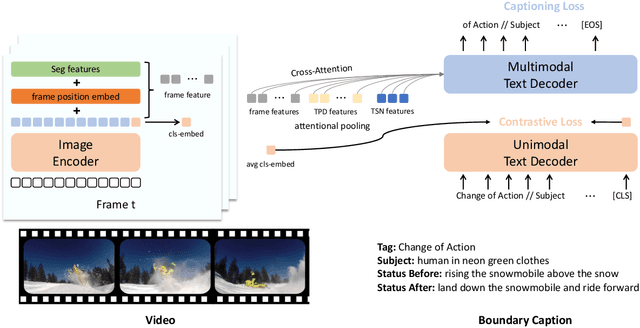
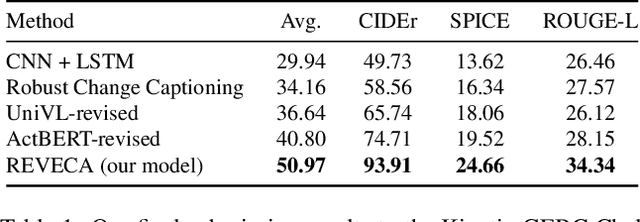
We describe an approach used in the Generic Boundary Event Captioning challenge at the Long-Form Video Understanding Workshop held at CVPR 2022. We designed a Rich Encoder-decoder framework for Video Event CAptioner (REVECA) that utilizes spatial and temporal information from the video to generate a caption for the corresponding the event boundary. REVECA uses frame position embedding to incorporate information before and after the event boundary. Furthermore, it employs features extracted using the temporal segment network and temporal-based pairwise difference method to learn temporal information. A semantic segmentation mask for the attentional pooling process is adopted to learn the subject of an event. Finally, LoRA is applied to fine-tune the image encoder to enhance the learning efficiency. REVECA yielded an average score of 50.97 on the Kinetics-GEBC test data, which is an improvement of 10.17 over the baseline method. Our code is available in https://github.com/TooTouch/REVECA.
Sonification as a Reliable Alternative to Conventional Visual Surgical Navigation
Jun 30, 2022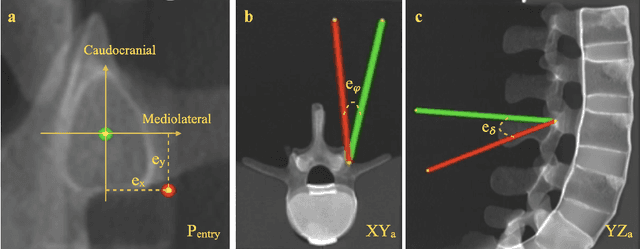
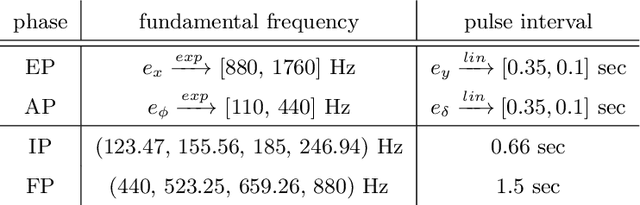
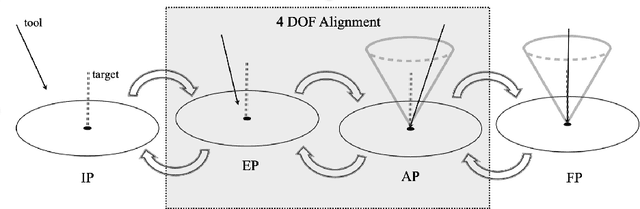
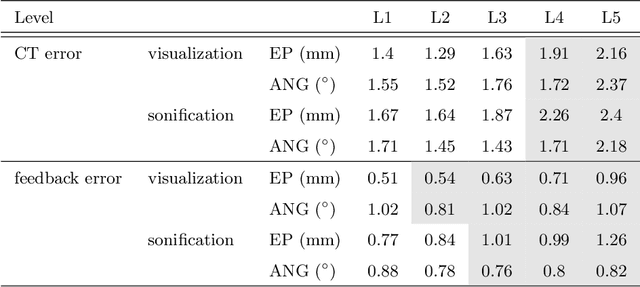
Despite the undeniable advantages of image-guided surgical assistance systems in terms of accuracy, such systems have not yet fully met surgeons' needs or expectations regarding usability, time efficiency, and their integration into the surgical workflow. On the other hand, perceptual studies have shown that presenting independent but causally correlated information via multimodal feedback involving different sensory modalities can improve task performance. This article investigates an alternative method for computer-assisted surgical navigation, introduces a novel sonification methodology for navigated pedicle screw placement, and discusses advanced solutions based on multisensory feedback. The proposed method comprises a novel sonification solution for alignment tasks in four degrees of freedom based on frequency modulation (FM) synthesis. We compared the resulting accuracy and execution time of the proposed sonification method with visual navigation, which is currently considered the state of the art. We conducted a phantom study in which 17 surgeons executed the pedicle screw placement task in the lumbar spine, guided by either the proposed sonification-based or the traditional visual navigation method. The results demonstrated that the proposed method is as accurate as the state of the art while decreasing the surgeon's need to focus on visual navigation displays instead of the natural focus on surgical tools and targeted anatomy during task execution.
GM-MLIC: Graph Matching based Multi-Label Image Classification
May 07, 2021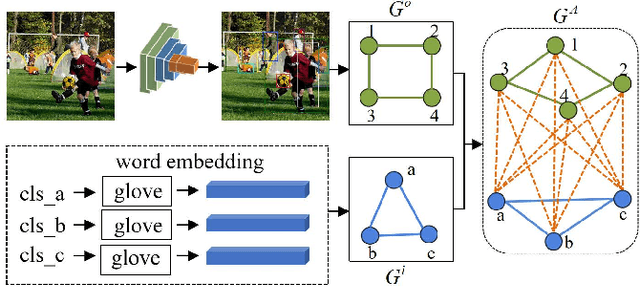
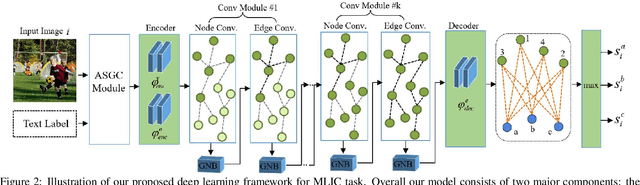
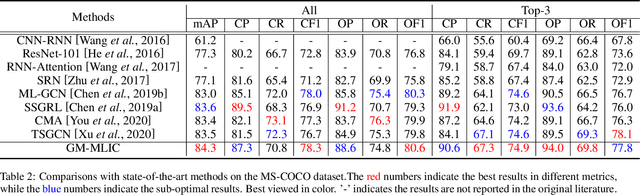
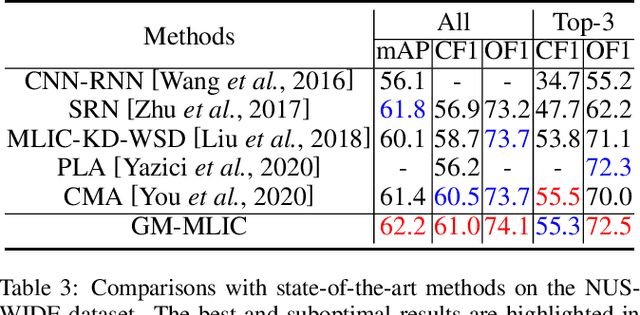
Multi-Label Image Classification (MLIC) aims to predict a set of labels that present in an image. The key to deal with such problem is to mine the associations between image contents and labels, and further obtain the correct assignments between images and their labels. In this paper, we treat each image as a bag of instances, and reformulate the task of MLIC as an instance-label matching selection problem. To model such problem, we propose a novel deep learning framework named Graph Matching based Multi-Label Image Classification (GM-MLIC), where Graph Matching (GM) scheme is introduced owing to its excellent capability of excavating the instance and label relationship. Specifically, we first construct an instance spatial graph and a label semantic graph respectively, and then incorporate them into a constructed assignment graph by connecting each instance to all labels. Subsequently, the graph network block is adopted to aggregate and update all nodes and edges state on the assignment graph to form structured representations for each instance and label. Our network finally derives a prediction score for each instance-label correspondence and optimizes such correspondence with a weighted cross-entropy loss. Extensive experiments conducted on various image datasets demonstrate the superiority of our proposed method.
Neural Rendering for Stereo 3D Reconstruction of Deformable Tissues in Robotic Surgery
Jun 30, 2022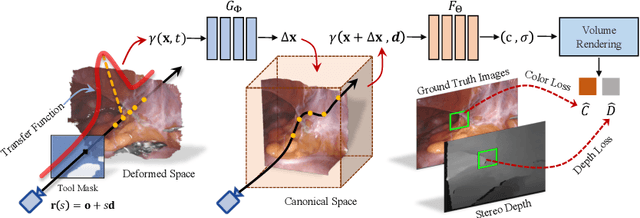

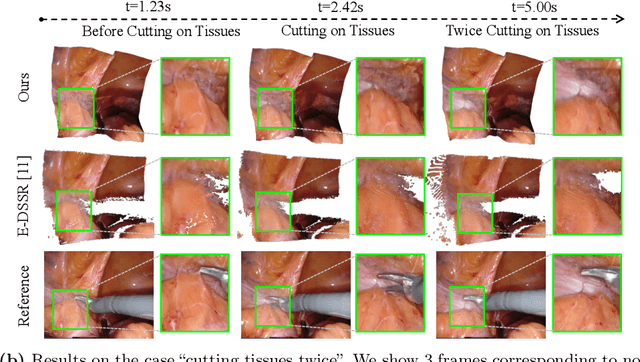
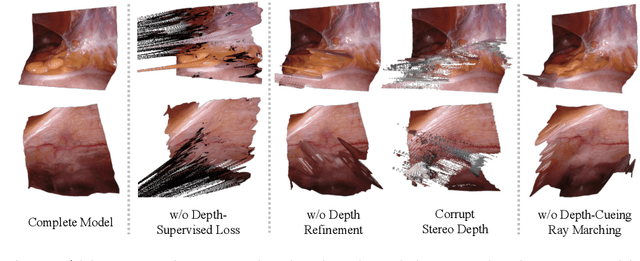
Reconstruction of the soft tissues in robotic surgery from endoscopic stereo videos is important for many applications such as intra-operative navigation and image-guided robotic surgery automation. Previous works on this task mainly rely on SLAM-based approaches, which struggle to handle complex surgical scenes. Inspired by recent progress in neural rendering, we present a novel framework for deformable tissue reconstruction from binocular captures in robotic surgery under the single-viewpoint setting. Our framework adopts dynamic neural radiance fields to represent deformable surgical scenes in MLPs and optimize shapes and deformations in a learning-based manner. In addition to non-rigid deformations, tool occlusion and poor 3D clues from a single viewpoint are also particular challenges in soft tissue reconstruction. To overcome these difficulties, we present a series of strategies of tool mask-guided ray casting, stereo depth-cueing ray marching and stereo depth-supervised optimization. With experiments on DaVinci robotic surgery videos, our method significantly outperforms the current state-of-the-art reconstruction method for handling various complex non-rigid deformations. To our best knowledge, this is the first work leveraging neural rendering for surgical scene 3D reconstruction with remarkable potential demonstrated. Code is available at: https://github.com/med-air/EndoNeRF.
Semantic Segmentation for Thermal Images: A Comparative Survey
May 26, 2022
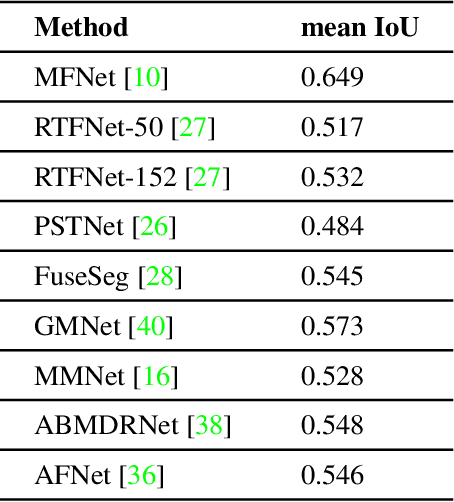


Semantic segmentation is a challenging task since it requires excessively more low-level spatial information of the image compared to other computer vision problems. The accuracy of pixel-level classification can be affected by many factors, such as imaging limitations and the ambiguity of object boundaries in an image. Conventional methods exploit three-channel RGB images captured in the visible spectrum with deep neural networks (DNN). Thermal images can significantly contribute during the segmentation since thermal imaging cameras are capable of capturing details despite the weather and illumination conditions. Using infrared spectrum in semantic segmentation has many real-world use cases, such as autonomous driving, medical imaging, agriculture, defense industry, etc. Due to this wide range of use cases, designing accurate semantic segmentation algorithms with the help of infrared spectrum is an important challenge. One approach is to use both visible and infrared spectrum images as inputs. These methods can accomplish higher accuracy due to enriched input information, with the cost of extra effort for the alignment and processing of multiple inputs. Another approach is to use only thermal images, enabling less hardware cost for smaller use cases. Even though there are multiple surveys on semantic segmentation methods, the literature lacks a comprehensive survey centered explicitly around semantic segmentation using infrared spectrum. This work aims to fill this gap by presenting algorithms in the literature and categorizing them by their input images.
Details Preserving Deep Collaborative Filtering-Based Method for Image Denoising
Jul 11, 2021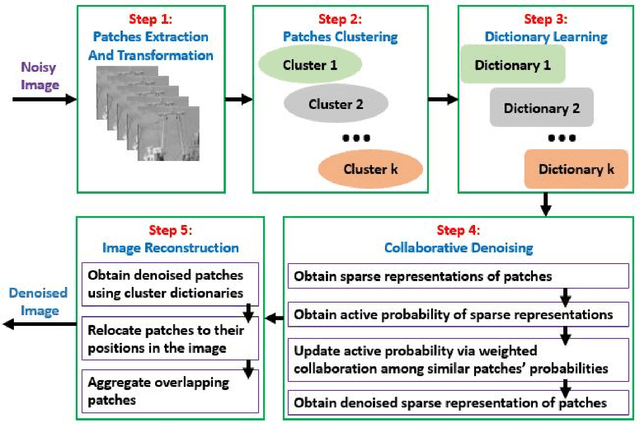
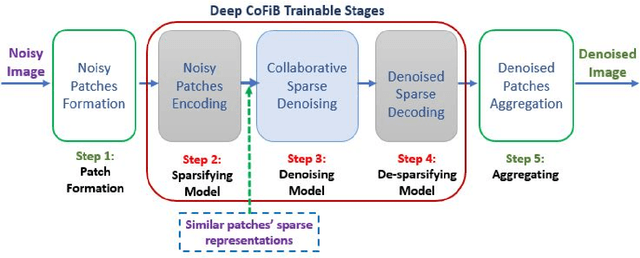

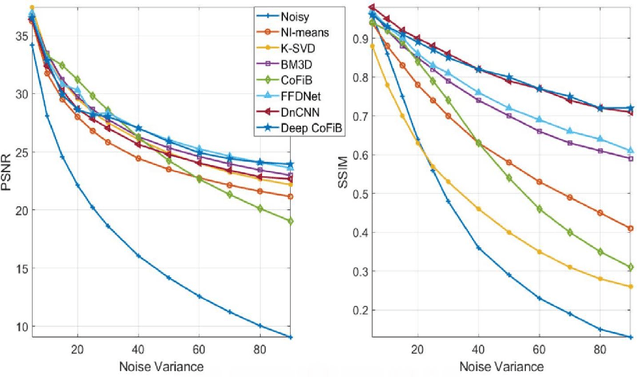
In spite of the improvements achieved by the several denoising algorithms over the years, many of them still fail at preserving the fine details of the image after denoising. This is as a result of the smooth-out effect they have on the images. Most neural network-based algorithms have achieved better quantitative performance than the classical denoising algorithms. However, they also suffer from qualitative (visual) performance as a result of the smooth-out effect. In this paper, we propose an algorithm to address this shortcoming. We propose a deep collaborative filtering-based (Deep-CoFiB) algorithm for image denoising. This algorithm performs collaborative denoising of image patches in the sparse domain using a set of optimized neural network models. This results in a fast algorithm that is able to excellently obtain a trade-off between noise removal and details preservation. Extensive experiments show that the DeepCoFiB performed quantitatively (in terms of PSNR and SSIM) and qualitatively (visually) better than many of the state-of-the-art denoising algorithms.
Dam reservoir extraction from remote sensing imagery using tailored metric learning strategies
Jul 12, 2022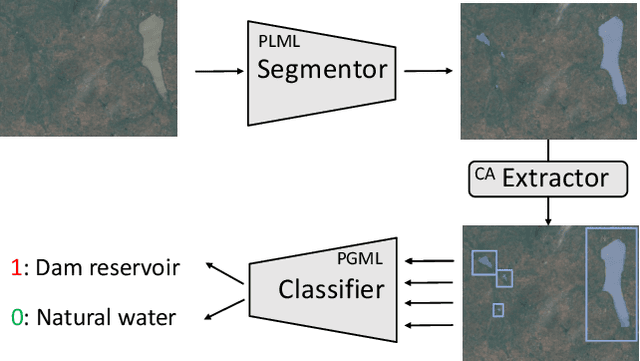

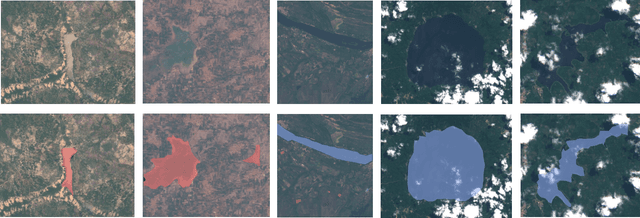
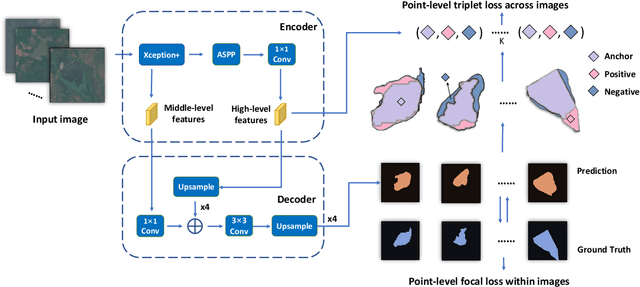
Dam reservoirs play an important role in meeting sustainable development goals and global climate targets. However, particularly for small dam reservoirs, there is a lack of consistent data on their geographical location. To address this data gap, a promising approach is to perform automated dam reservoir extraction based on globally available remote sensing imagery. It can be considered as a fine-grained task of water body extraction, which involves extracting water areas in images and then separating dam reservoirs from natural water bodies. We propose a novel deep neural network (DNN) based pipeline that decomposes dam reservoir extraction into water body segmentation and dam reservoir recognition. Water bodies are firstly separated from background lands in a segmentation model and each individual water body is then predicted as either dam reservoir or natural water body in a classification model. For the former step, point-level metric learning with triplets across images is injected into the segmentation model to address contour ambiguities between water areas and land regions. For the latter step, prior-guided metric learning with triplets from clusters is injected into the classification model to optimize the image embedding space in a fine-grained level based on reservoir clusters. To facilitate future research, we establish a benchmark dataset with earth imagery data and human labelled reservoirs from river basins in West Africa and India. Extensive experiments were conducted on this benchmark in the water body segmentation task, dam reservoir recognition task, and the joint dam reservoir extraction task. Superior performance has been observed in the respective tasks when comparing our method with state of the art approaches.
Seeing Around Obstacles with Terahertz Waves
May 10, 2022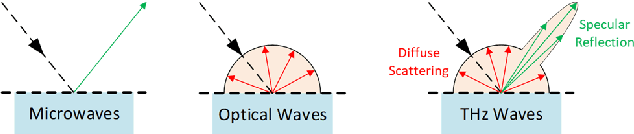
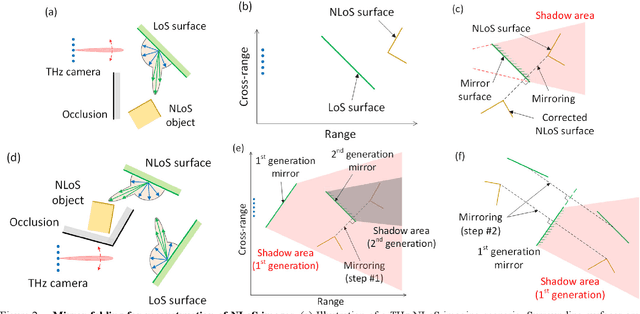
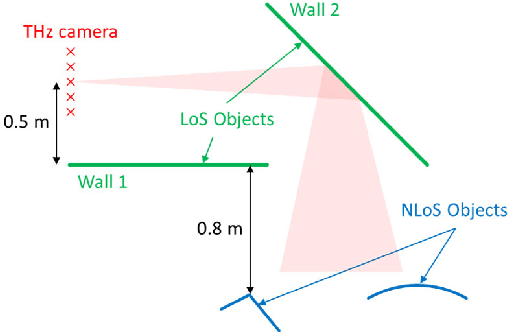
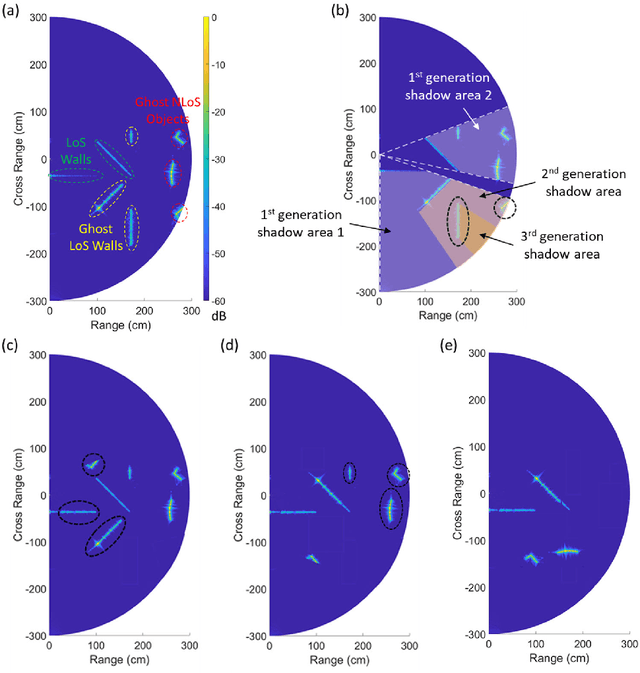
Traditional imaging systems, such as the eye or cameras, image scenes that lie in the direct line-of-sight (LoS). Most objects are opaque in the optical and infrared regimes and can limit dramatically the field of view (FoV). Current approaches to see around occlusions exploit the multireflection propagation of signals from neighboring surfaces either in the microwave or the optical bands. Using lower frequency signals anatomical information is limited and images suffer from clutter while optical systems encounter diffuse scattering from most surfaces and suffer from path loss, thus limiting the imaging distance. In this work, we show that terahertz (THz) waves can be used to extend visibility to non-line-of-sight (NLoS) while combining the advantages of both spectra. The material properties and roughness of most building surfaces allow for a unique combination of both diffuse and strong specular scattering. As a result, most building surfaces behave as lossy mirrors that enable propagation paths between a THz camera and the NLoS scenes. We propose a mirror folding algorithm that tracks the multireflection propagation of THz waves to 1) correct the image from cluttering and 2) see around occlusions without a priori knowledge of the scene geometry and material properties. To validate the feasibility of the proposed NLoS imaging approach, we carried out a numerical analysis and developed two THz imaging systems to demonstrate real-world NLoS imaging experiments in sub-THz bands (270-300 GHz). The results show the capability of THz radar imaging systems to recover both the geometry and pose of LoS and NLoS objects with centimeter-scale resolution in various multipath propagation scenarios. THz NLoS imaging can operate in low visibility conditions (e.g., night, strong ambient light, smoke) and uses computationally inexpensive image reconstruction algorithms.
Advancing 3D Medical Image Analysis with Variable Dimension Transform based Supervised 3D Pre-training
Jan 05, 2022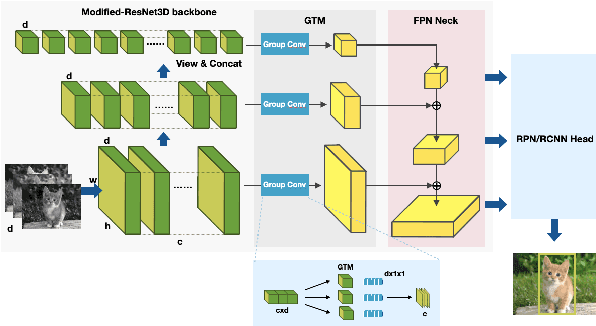
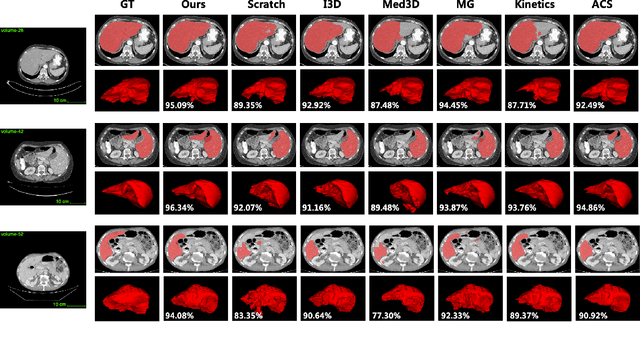
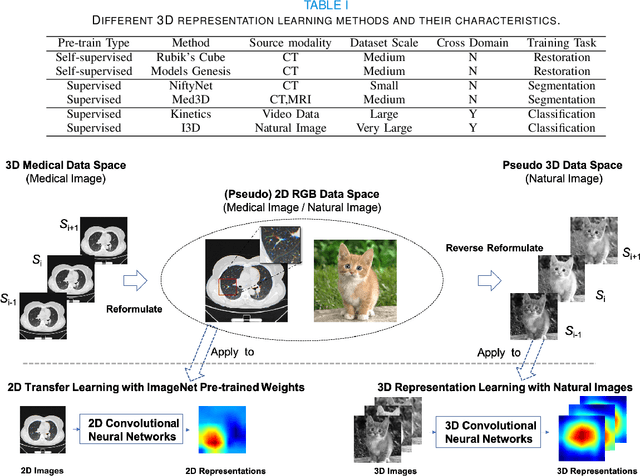
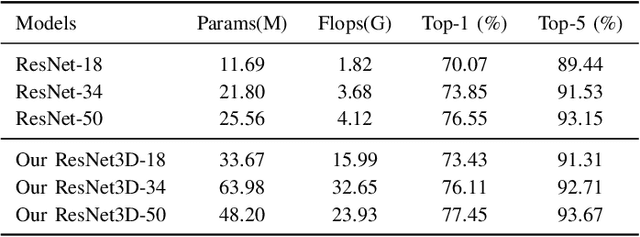
The difficulties in both data acquisition and annotation substantially restrict the sample sizes of training datasets for 3D medical imaging applications. As a result, constructing high-performance 3D convolutional neural networks from scratch remains a difficult task in the absence of a sufficient pre-training parameter. Previous efforts on 3D pre-training have frequently relied on self-supervised approaches, which use either predictive or contrastive learning on unlabeled data to build invariant 3D representations. However, because of the unavailability of large-scale supervision information, obtaining semantically invariant and discriminative representations from these learning frameworks remains problematic. In this paper, we revisit an innovative yet simple fully-supervised 3D network pre-training framework to take advantage of semantic supervisions from large-scale 2D natural image datasets. With a redesigned 3D network architecture, reformulated natural images are used to address the problem of data scarcity and develop powerful 3D representations. Comprehensive experiments on four benchmark datasets demonstrate that the proposed pre-trained models can effectively accelerate convergence while also improving accuracy for a variety of 3D medical imaging tasks such as classification, segmentation and detection. In addition, as compared to training from scratch, it can save up to 60% of annotation efforts. On the NIH DeepLesion dataset, it likewise achieves state-of-the-art detection performance, outperforming earlier self-supervised and fully-supervised pre-training approaches, as well as methods that do training from scratch. To facilitate further development of 3D medical models, our code and pre-trained model weights are publicly available at https://github.com/urmagicsmine/CSPR.
Anomaly Detection with Adversarially Learned Perturbations of Latent Space
Jul 03, 2022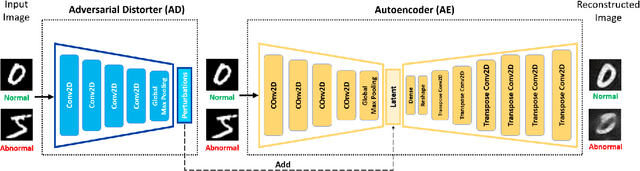



Anomaly detection is to identify samples that do not conform to the distribution of the normal data. Due to the unavailability of anomalous data, training a supervised deep neural network is a cumbersome task. As such, unsupervised methods are preferred as a common approach to solve this task. Deep autoencoders have been broadly adopted as a base of many unsupervised anomaly detection methods. However, a notable shortcoming of deep autoencoders is that they provide insufficient representations for anomaly detection by generalizing to reconstruct outliers. In this work, we have designed an adversarial framework consisting of two competing components, an Adversarial Distorter, and an Autoencoder. The Adversarial Distorter is a convolutional encoder that learns to produce effective perturbations and the autoencoder is a deep convolutional neural network that aims to reconstruct the images from the perturbed latent feature space. The networks are trained with opposing goals in which the Adversarial Distorter produces perturbations that are applied to the encoder's latent feature space to maximize the reconstruction error and the autoencoder tries to neutralize the effect of these perturbations to minimize it. When applied to anomaly detection, the proposed method learns semantically richer representations due to applying perturbations to the feature space. The proposed method outperforms the existing state-of-the-art methods in anomaly detection on image and video datasets.