 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Distilling effective supervision for robust medical image segmentation with noisy labels
Jun 21, 2021
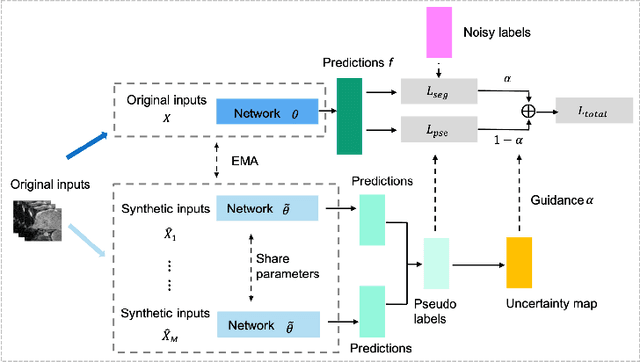
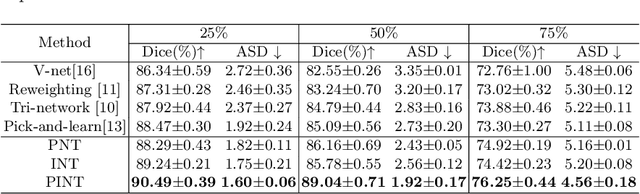
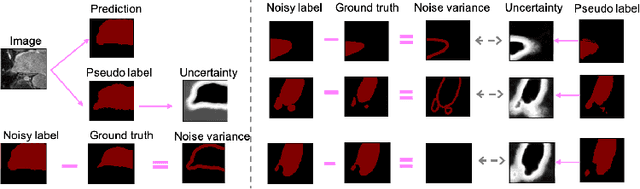
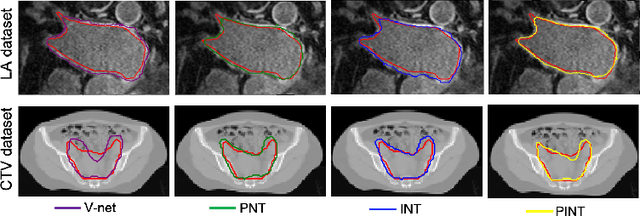
Despite the success of deep learning methods in medical image segmentation tasks, the human-level performance relies on massive training data with high-quality annotations, which are expensive and time-consuming to collect. The fact is that there exist low-quality annotations with label noise, which leads to suboptimal performance of learned models. Two prominent directions for segmentation learning with noisy labels include pixel-wise noise robust training and image-level noise robust training. In this work, we propose a novel framework to address segmenting with noisy labels by distilling effective supervision information from both pixel and image levels. In particular, we explicitly estimate the uncertainty of every pixel as pixel-wise noise estimation, and propose pixel-wise robust learning by using both the original labels and pseudo labels. Furthermore, we present an image-level robust learning method to accommodate more information as the complements to pixel-level learning. We conduct extensive experiments on both simulated and real-world noisy datasets. The results demonstrate the advantageous performance of our method compared to state-of-the-art baselines for medical image segmentation with noisy labels.
Shadows Shed Light on 3D Objects
Jun 17, 2022
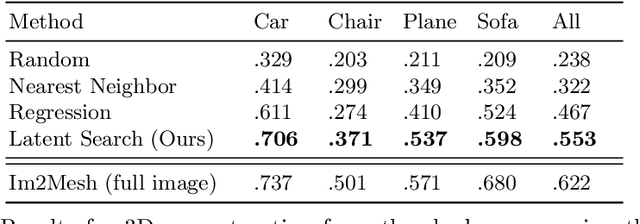
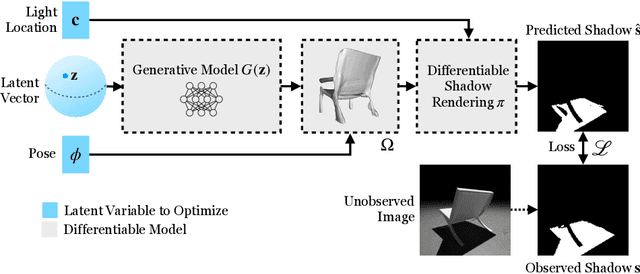
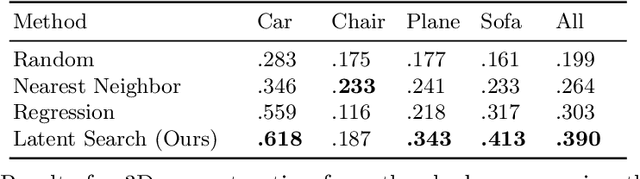
3D reconstruction is a fundamental problem in computer vision, and the task is especially challenging when the object to reconstruct is partially or fully occluded. We introduce a method that uses the shadows cast by an unobserved object in order to infer the possible 3D volumes behind the occlusion. We create a differentiable image formation model that allows us to jointly infer the 3D shape of an object, its pose, and the position of a light source. Since the approach is end-to-end differentiable, we are able to integrate learned priors of object geometry in order to generate realistic 3D shapes of different object categories. Experiments and visualizations show that the method is able to generate multiple possible solutions that are consistent with the observation of the shadow. Our approach works even when the position of the light source and object pose are both unknown. Our approach is also robust to real-world images where ground-truth shadow mask is unknown.
Seeing Around Obstacles with Terahertz Waves
May 10, 2022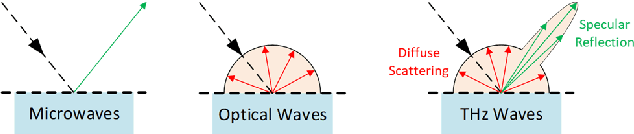
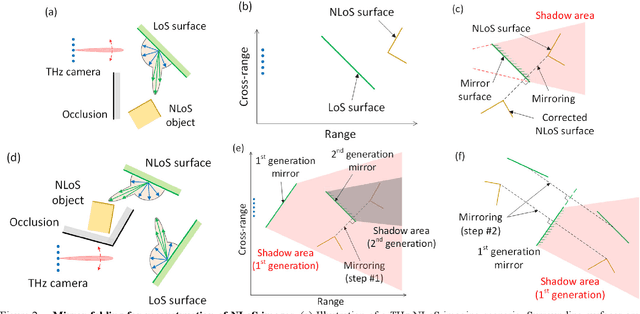
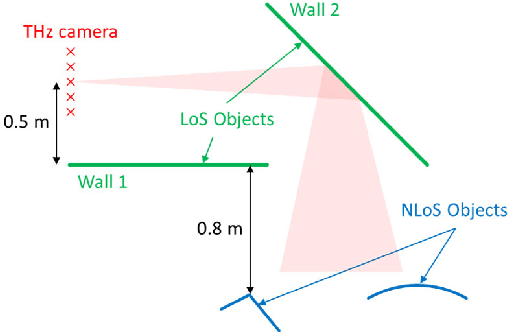
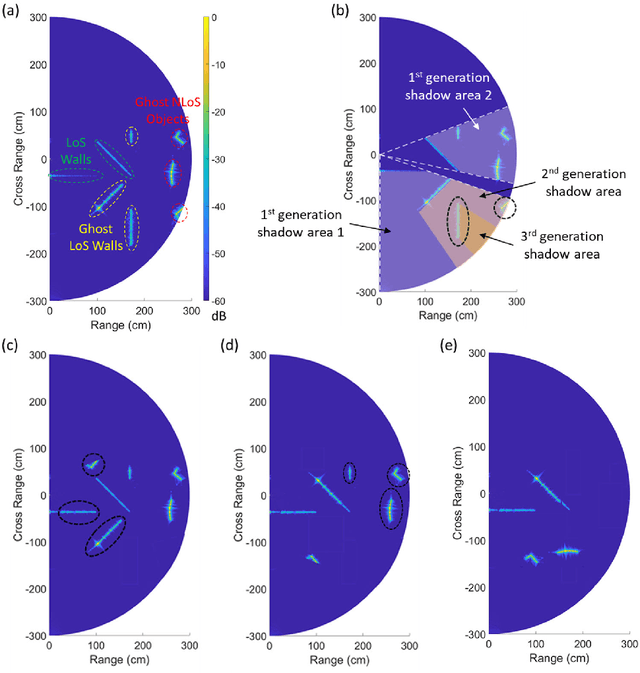
Traditional imaging systems, such as the eye or cameras, image scenes that lie in the direct line-of-sight (LoS). Most objects are opaque in the optical and infrared regimes and can limit dramatically the field of view (FoV). Current approaches to see around occlusions exploit the multireflection propagation of signals from neighboring surfaces either in the microwave or the optical bands. Using lower frequency signals anatomical information is limited and images suffer from clutter while optical systems encounter diffuse scattering from most surfaces and suffer from path loss, thus limiting the imaging distance. In this work, we show that terahertz (THz) waves can be used to extend visibility to non-line-of-sight (NLoS) while combining the advantages of both spectra. The material properties and roughness of most building surfaces allow for a unique combination of both diffuse and strong specular scattering. As a result, most building surfaces behave as lossy mirrors that enable propagation paths between a THz camera and the NLoS scenes. We propose a mirror folding algorithm that tracks the multireflection propagation of THz waves to 1) correct the image from cluttering and 2) see around occlusions without a priori knowledge of the scene geometry and material properties. To validate the feasibility of the proposed NLoS imaging approach, we carried out a numerical analysis and developed two THz imaging systems to demonstrate real-world NLoS imaging experiments in sub-THz bands (270-300 GHz). The results show the capability of THz radar imaging systems to recover both the geometry and pose of LoS and NLoS objects with centimeter-scale resolution in various multipath propagation scenarios. THz NLoS imaging can operate in low visibility conditions (e.g., night, strong ambient light, smoke) and uses computationally inexpensive image reconstruction algorithms.
Utility of Equivariant Message Passing in Cortical Mesh Segmentation
Jun 15, 2022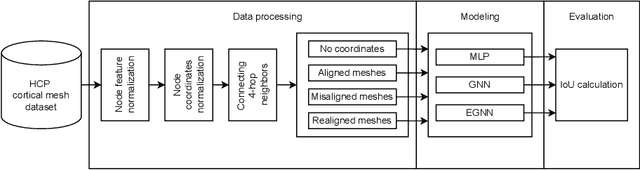
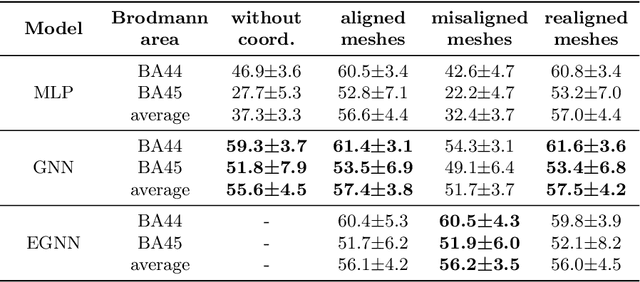
The automated segmentation of cortical areas has been a long-standing challenge in medical image analysis. The complex geometry of the cortex is commonly represented as a polygon mesh, whose segmentation can be addressed by graph-based learning methods. When cortical meshes are misaligned across subjects, current methods produce significantly worse segmentation results, limiting their ability to handle multi-domain data. In this paper, we investigate the utility of E(n)-equivariant graph neural networks (EGNNs), comparing their performance against plain graph neural networks (GNNs). Our evaluation shows that GNNs outperform EGNNs on aligned meshes, due to their ability to leverage the presence of a global coordinate system. On misaligned meshes, the performance of plain GNNs drop considerably, while E(n)-equivariant message passing maintains the same segmentation results. The best results can also be obtained by using plain GNNs on realigned data (co-registered meshes in a global coordinate system).
DCT2net: an interpretable shallow CNN for image denoising
Jul 31, 2021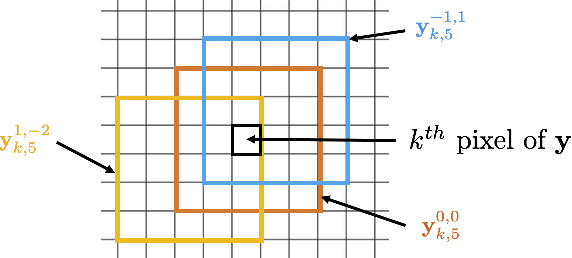


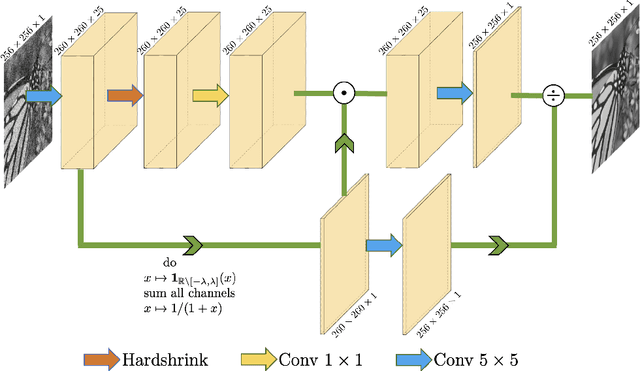
This work tackles the issue of noise removal from images, focusing on the well-known DCT image denoising algorithm. The latter, stemming from signal processing, has been well studied over the years. Though very simple, it is still used in crucial parts of state-of-the-art "traditional" denoising algorithms such as BM3D. Since a few years however, deep convolutional neural networks (CNN) have outperformed their traditional counterparts, making signal processing methods less attractive. In this paper, we demonstrate that a DCT denoiser can be seen as a shallow CNN and thereby its original linear transform can be tuned through gradient descent in a supervised manner, improving considerably its performance. This gives birth to a fully interpretable CNN called DCT2net. To deal with remaining artifacts induced by DCT2net, an original hybrid solution between DCT and DCT2net is proposed combining the best that these two methods can offer; DCT2net is selected to process non-stationary image patches while DCT is optimal for piecewise smooth patches. Experiments on artificially noisy images demonstrate that two-layer DCT2net provides comparable results to BM3D and is as fast as DnCNN algorithm composed of more than a dozen of layers.
Image Super-Resolution via Iterative Refinement
Apr 15, 2021
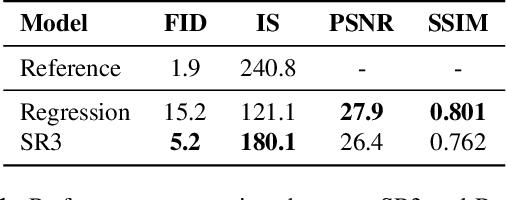
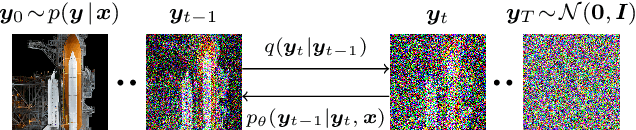

We present SR3, an approach to image Super-Resolution via Repeated Refinement. SR3 adapts denoising diffusion probabilistic models to conditional image generation and performs super-resolution through a stochastic denoising process. Inference starts with pure Gaussian noise and iteratively refines the noisy output using a U-Net model trained on denoising at various noise levels. SR3 exhibits strong performance on super-resolution tasks at different magnification factors, on faces and natural images. We conduct human evaluation on a standard 8X face super-resolution task on CelebA-HQ, comparing with SOTA GAN methods. SR3 achieves a fool rate close to 50%, suggesting photo-realistic outputs, while GANs do not exceed a fool rate of 34%. We further show the effectiveness of SR3 in cascaded image generation, where generative models are chained with super-resolution models, yielding a competitive FID score of 11.3 on ImageNet.
SSMI: How to Make Objects of Interest Disappear without Accessing Object Detectors?
Jun 22, 2022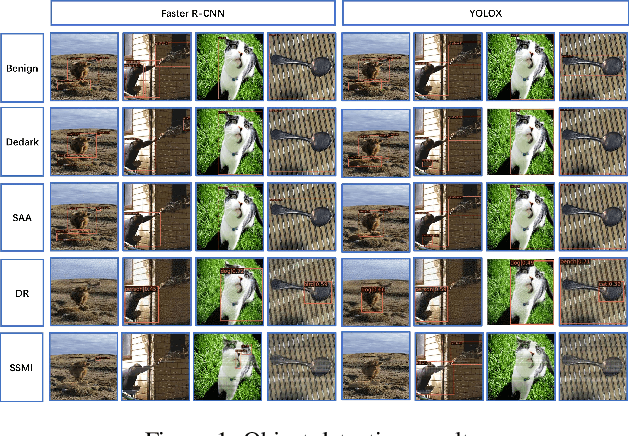


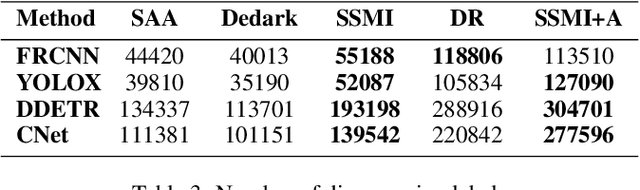
Most black-box adversarial attack schemes for object detectors mainly face two shortcomings: requiring access to the target model and generating inefficient adversarial examples (failing to make objects disappear in large numbers). To overcome these shortcomings, we propose a black-box adversarial attack scheme based on semantic segmentation and model inversion (SSMI). We first locate the position of the target object using semantic segmentation techniques. Next, we design a neighborhood background pixel replacement to replace the target region pixels with background pixels to ensure that the pixel modifications are not easily detected by human vision. Finally, we reconstruct a machine-recognizable example and use the mask matrix to select pixels in the reconstructed example to modify the benign image to generate an adversarial example. Detailed experimental results show that SSMI can generate efficient adversarial examples to evade human-eye perception and make objects of interest disappear. And more importantly, SSMI outperforms existing same kinds of attacks. The maximum increase in new and disappearing labels is 16%, and the maximum decrease in mAP metrics for object detection is 36%.
Convolutional Layers Are Not Translation Equivariant
Jun 10, 2022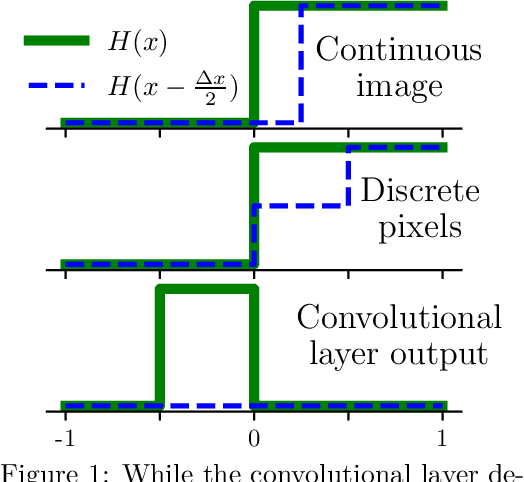
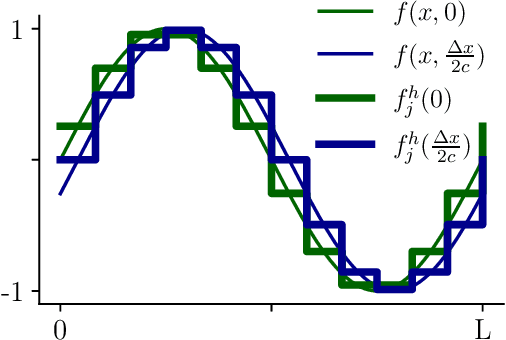
The purpose of this paper is to correct a misconception about convolutional neural networks (CNNs). CNNs are made up of convolutional layers which are shift equivariant due to weight sharing. However, contrary to popular belief, convolutional layers are not translation equivariant, even when boundary effects are ignored and when pooling and subsampling are absent. This is because shift equivariance is a discrete symmetry while translation equivariance is a continuous symmetry. That discrete systems do not in general inherit continuous equivariances is a fundamental limitation of equivariant deep learning. We discuss two implications of this fact. First, CNNs have achieved success in image processing despite not inheriting the translation equivariance of the physical systems they model. Second, using CNNs to solve partial differential equations (PDEs) will not result in translation equivariant solvers.
Fusformer: A Transformer-based Fusion Approach for Hyperspectral Image Super-resolution
Sep 05, 2021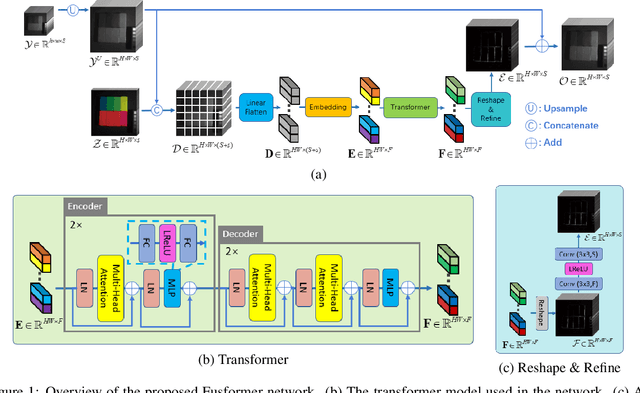
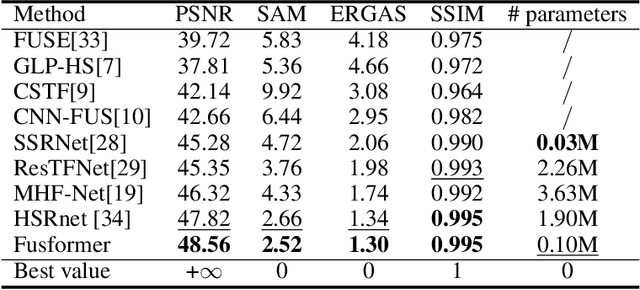

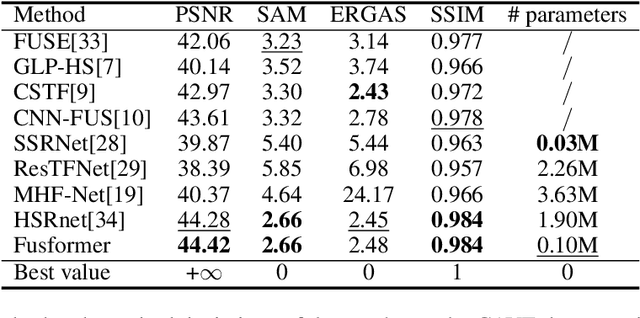
Hyperspectral image has become increasingly crucial due to its abundant spectral information. However, It has poor spatial resolution with the limitation of the current imaging mechanism. Nowadays, many convolutional neural networks have been proposed for the hyperspectral image super-resolution problem. However, convolutional neural network (CNN) based methods only consider the local information instead of the global one with the limited kernel size of receptive field in the convolution operation. In this paper, we design a network based on the transformer for fusing the low-resolution hyperspectral images and high-resolution multispectral images to obtain the high-resolution hyperspectral images. Thanks to the representing ability of the transformer, our approach is able to explore the intrinsic relationships of features globally. Furthermore, considering the LR-HSIs hold the main spectral structure, the network focuses on the spatial detail estimation releasing from the burden of reconstructing the whole data. It reduces the mapping space of the proposed network, which enhances the final performance. Various experiments and quality indexes show our approach's superiority compared with other state-of-the-art methods.
Lattice Convolutional Networks for Learning Ground States of Quantum Many-Body Systems
Jun 15, 2022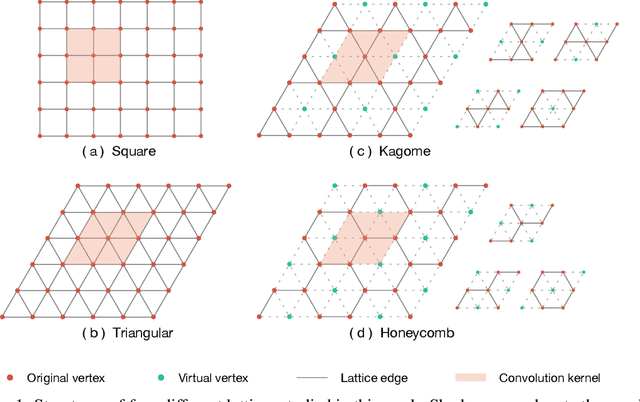
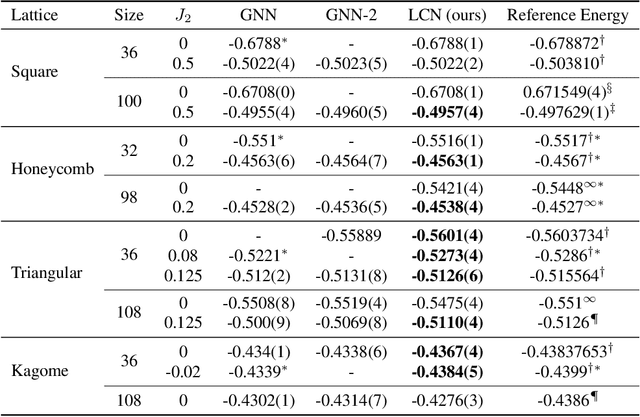
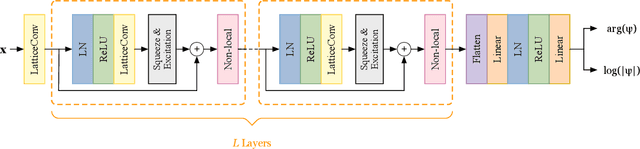
Deep learning methods have been shown to be effective in representing ground-state wave functions of quantum many-body systems. Existing methods use convolutional neural networks (CNNs) for square lattices due to their image-like structures. For non-square lattices, existing method uses graph neural network (GNN) in which structure information is not precisely captured, thereby requiring additional hand-crafted sublattice encoding. In this work, we propose lattice convolutions in which a set of proposed operations are used to convert non-square lattices into grid-like augmented lattices on which regular convolution can be applied. Based on the proposed lattice convolutions, we design lattice convolutional networks (LCN) that use self-gating and attention mechanisms. Experimental results show that our method achieves performance on par or better than existing methods on spin 1/2 $J_1$-$J_2$ Heisenberg model over the square, honeycomb, triangular, and kagome lattices while without using hand-crafted encoding.