 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LaRa: Latents and Rays for Multi-Camera Bird's-Eye-View Semantic Segmentation
Jun 27, 2022
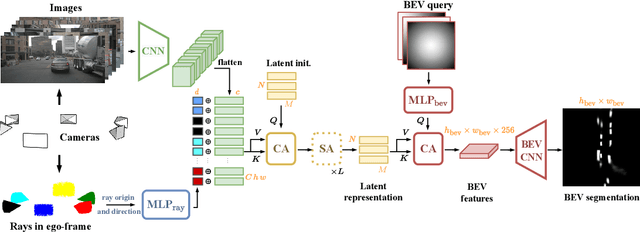
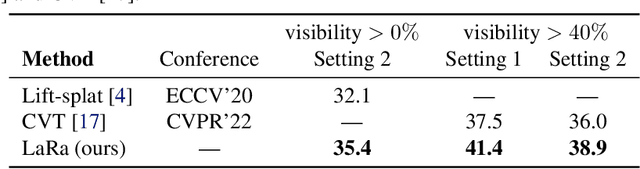

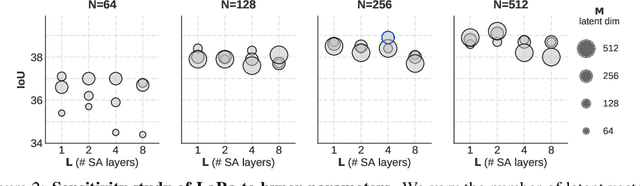
Recent works in autonomous driving have widely adopted the bird's-eye-view (BEV) semantic map as an intermediate representation of the world. Online prediction of these BEV maps involves non-trivial operations such as multi-camera data extraction as well as fusion and projection into a common top-view grid. This is usually done with error-prone geometric operations (e.g., homography or back-projection from monocular depth estimation) or expensive direct dense mapping between image pixels and pixels in BEV (e.g., with MLP or attention). In this work, we present 'LaRa', an efficient encoder-decoder, transformer-based model for vehicle semantic segmentation from multiple cameras. Our approach uses a system of cross-attention to aggregate information over multiple sensors into a compact, yet rich, collection of latent representations. These latent representations, after being processed by a series of self-attention blocks, are then reprojected with a second cross-attention in the BEV space. We demonstrate that our model outperforms on nuScenes the best previous works using transformers.
CV4Code: Sourcecode Understanding via Visual Code Representations
May 11, 2022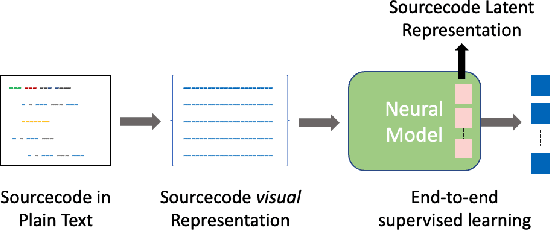
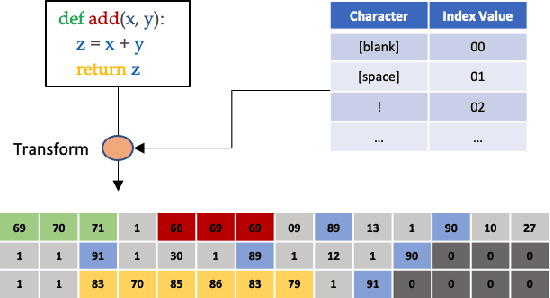

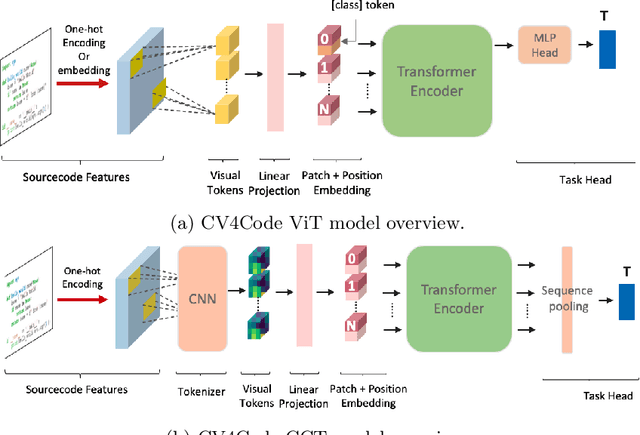
We present CV4Code, a compact and effective computer vision method for sourcecode understanding. Our method leverages the contextual and the structural information available from the code snippet by treating each snippet as a two-dimensional image, which naturally encodes the context and retains the underlying structural information through an explicit spatial representation. To codify snippets as images, we propose an ASCII codepoint-based image representation that facilitates fast generation of sourcecode images and eliminates redundancy in the encoding that would arise from an RGB pixel representation. Furthermore, as sourcecode is treated as images, neither lexical analysis (tokenisation) nor syntax tree parsing is required, which makes the proposed method agnostic to any particular programming language and lightweight from the application pipeline point of view. CV4Code can even featurise syntactically incorrect code which is not possible from methods that depend on the Abstract Syntax Tree (AST). We demonstrate the effectiveness of CV4Code by learning Convolutional and Transformer networks to predict the functional task, i.e. the problem it solves, of the source code directly from its two-dimensional representation, and using an embedding from its latent space to derive a similarity score of two code snippets in a retrieval setup. Experimental results show that our approach achieves state-of-the-art performance in comparison to other methods with the same task and data configurations. For the first time we show the benefits of treating sourcecode understanding as a form of image processing task.
Learning Bellman Complete Representations for Offline Policy Evaluation
Jul 12, 2022
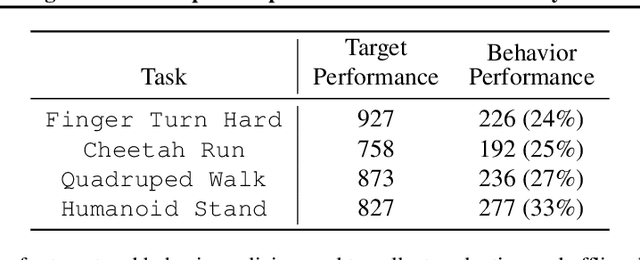

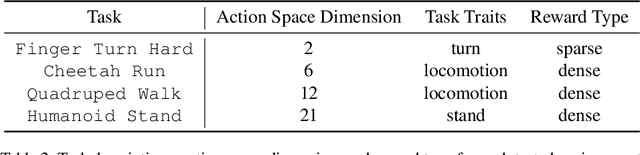
We study representation learning for Offline Reinforcement Learning (RL), focusing on the important task of Offline Policy Evaluation (OPE). Recent work shows that, in contrast to supervised learning, realizability of the Q-function is not enough for learning it. Two sufficient conditions for sample-efficient OPE are Bellman completeness and coverage. Prior work often assumes that representations satisfying these conditions are given, with results being mostly theoretical in nature. In this work, we propose BCRL, which directly learns from data an approximately linear Bellman complete representation with good coverage. With this learned representation, we perform OPE using Least Square Policy Evaluation (LSPE) with linear functions in our learned representation. We present an end-to-end theoretical analysis, showing that our two-stage algorithm enjoys polynomial sample complexity provided some representation in the rich class considered is linear Bellman complete. Empirically, we extensively evaluate our algorithm on challenging, image-based continuous control tasks from the Deepmind Control Suite. We show our representation enables better OPE compared to previous representation learning methods developed for off-policy RL (e.g., CURL, SPR). BCRL achieve competitive OPE error with the state-of-the-art method Fitted Q-Evaluation (FQE), and beats FQE when evaluating beyond the initial state distribution. Our ablations show that both linear Bellman complete and coverage components of our method are crucial.
* Accepted for Long Talk at ICML 2022
BDIS: Bayesian Dense Inverse Searching Method for Real-Time Stereo Surgical Image Matching
May 06, 2022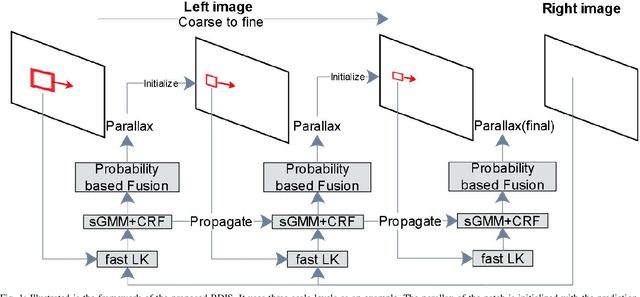
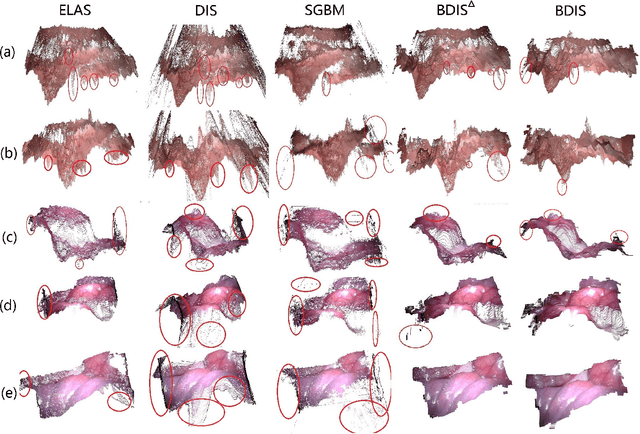
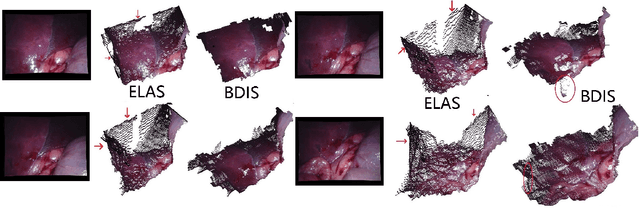
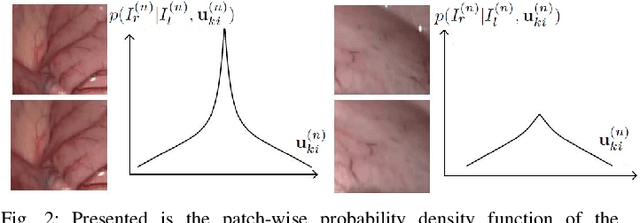
In stereoscope-based Minimally Invasive Surgeries (MIS), dense stereo matching plays an indispensable role in 3D shape recovery, AR, VR, and navigation tasks. Although numerous Deep Neural Network (DNN) approaches are proposed, the conventional prior-free approaches are still popular in the industry because of the lack of open-source annotated data set and the limitation of the task-specific pre-trained DNNs. Among the prior-free stereo matching algorithms, there is no successful real-time algorithm in none GPU environment for MIS. This paper proposes the first CPU-level real-time prior-free stereo matching algorithm for general MIS tasks. We achieve an average 17 Hz on 640*480 images with a single-core CPU (i5-9400) for surgical images. Meanwhile, it achieves slightly better accuracy than the popular ELAS. The patch-based fast disparity searching algorithm is adopted for the rectified stereo images. A coarse-to-fine Bayesian probability and a spatial Gaussian mixed model were proposed to evaluate the patch probability at different scales. An optional probability density function estimation algorithm was adopted to quantify the prediction variance. Extensive experiments demonstrated the proposed method's capability to handle ambiguities introduced by the textureless surfaces and the photometric inconsistency from the non-Lambertian reflectance and dark illumination. The estimated probability managed to balance the confidences of the patches for stereo images at different scales. It has similar or higher accuracy and fewer outliers than the baseline ELAS in MIS, while it is 4-5 times faster. The code and the synthetic data sets are available at https://github.com/JingweiSong/BDIS-v2.
Dual Cross-Attention Learning for Fine-Grained Visual Categorization and Object Re-Identification
May 04, 2022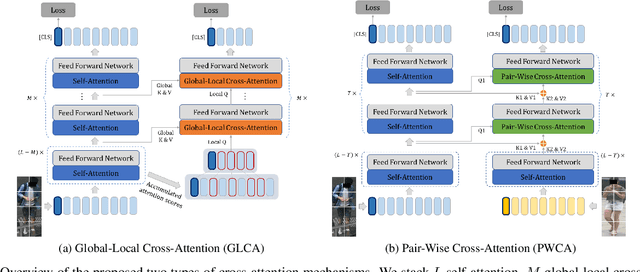
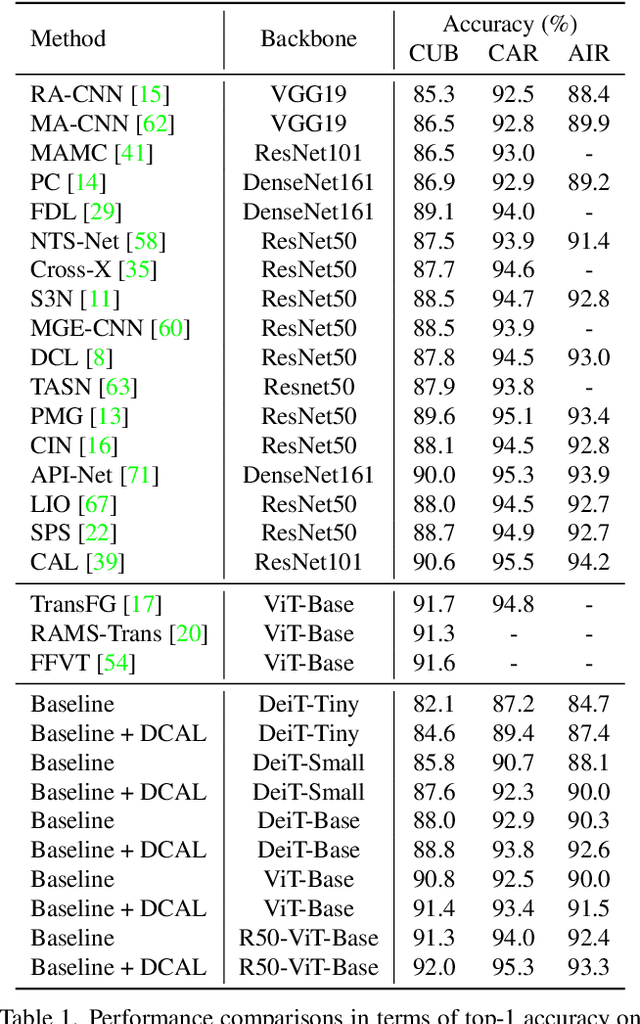
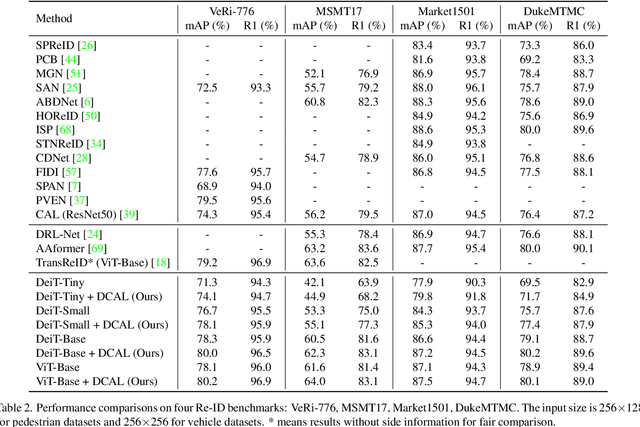
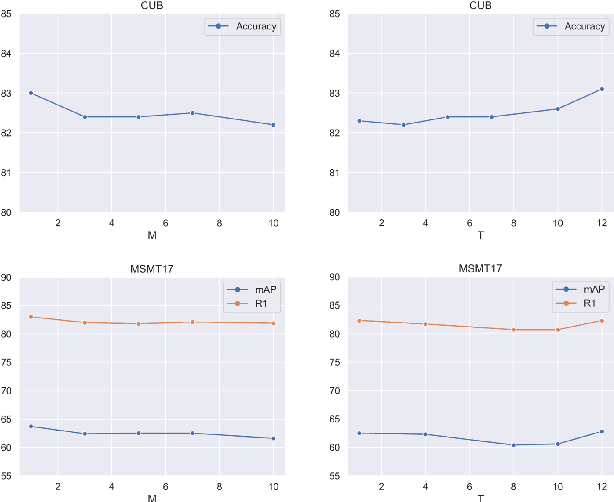
Recently, self-attention mechanisms have shown impressive performance in various NLP and CV tasks, which can help capture sequential characteristics and derive global information. In this work, we explore how to extend self-attention modules to better learn subtle feature embeddings for recognizing fine-grained objects, e.g., different bird species or person identities. To this end, we propose a dual cross-attention learning (DCAL) algorithm to coordinate with self-attention learning. First, we propose global-local cross-attention (GLCA) to enhance the interactions between global images and local high-response regions, which can help reinforce the spatial-wise discriminative clues for recognition. Second, we propose pair-wise cross-attention (PWCA) to establish the interactions between image pairs. PWCA can regularize the attention learning of an image by treating another image as distractor and will be removed during inference. We observe that DCAL can reduce misleading attentions and diffuse the attention response to discover more complementary parts for recognition. We conduct extensive evaluations on fine-grained visual categorization and object re-identification. Experiments demonstrate that DCAL performs on par with state-of-the-art methods and consistently improves multiple self-attention baselines, e.g., surpassing DeiT-Tiny and ViT-Base by 2.8% and 2.4% mAP on MSMT17, respectively.
Multi-Semantic Image Recognition Model and Evaluating Index for explaining the deep learning models
Sep 28, 2021
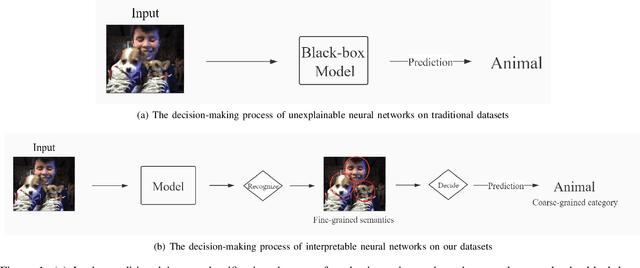
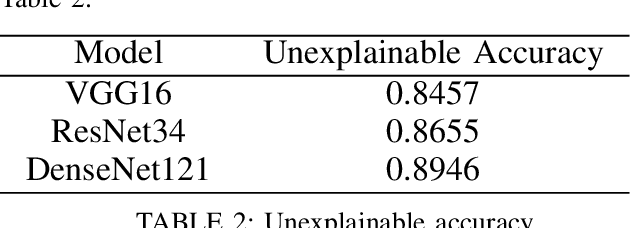
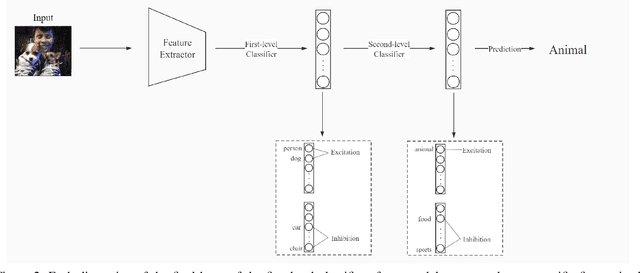
Although deep learning models are powerful among various applications, most deep learning models are still a black box, lacking verifiability and interpretability, which means the decision-making process that human beings cannot understand. Therefore, how to evaluate deep neural networks with explanations is still an urgent task. In this paper, we first propose a multi-semantic image recognition model, which enables human beings to understand the decision-making process of the neural network. Then, we presents a new evaluation index, which can quantitatively assess the model interpretability. We also comprehensively summarize the semantic information that affects the image classification results in the judgment process of neural networks. Finally, this paper also exhibits the relevant baseline performance with current state-of-the-art deep learning models.
Weakly Supervised Medical Image Segmentation
Aug 12, 2021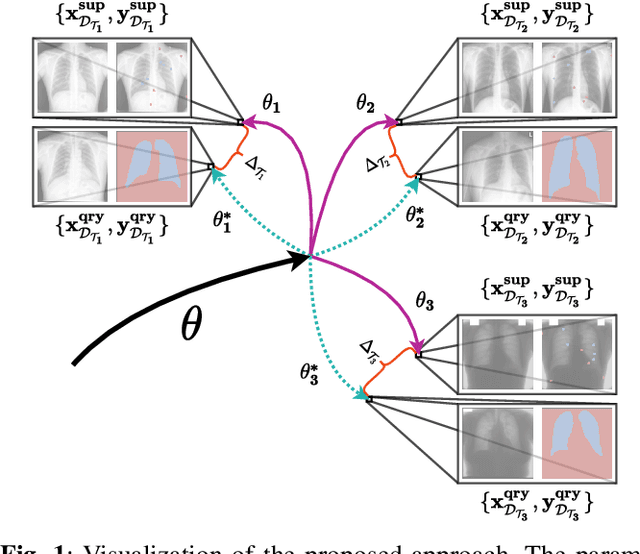
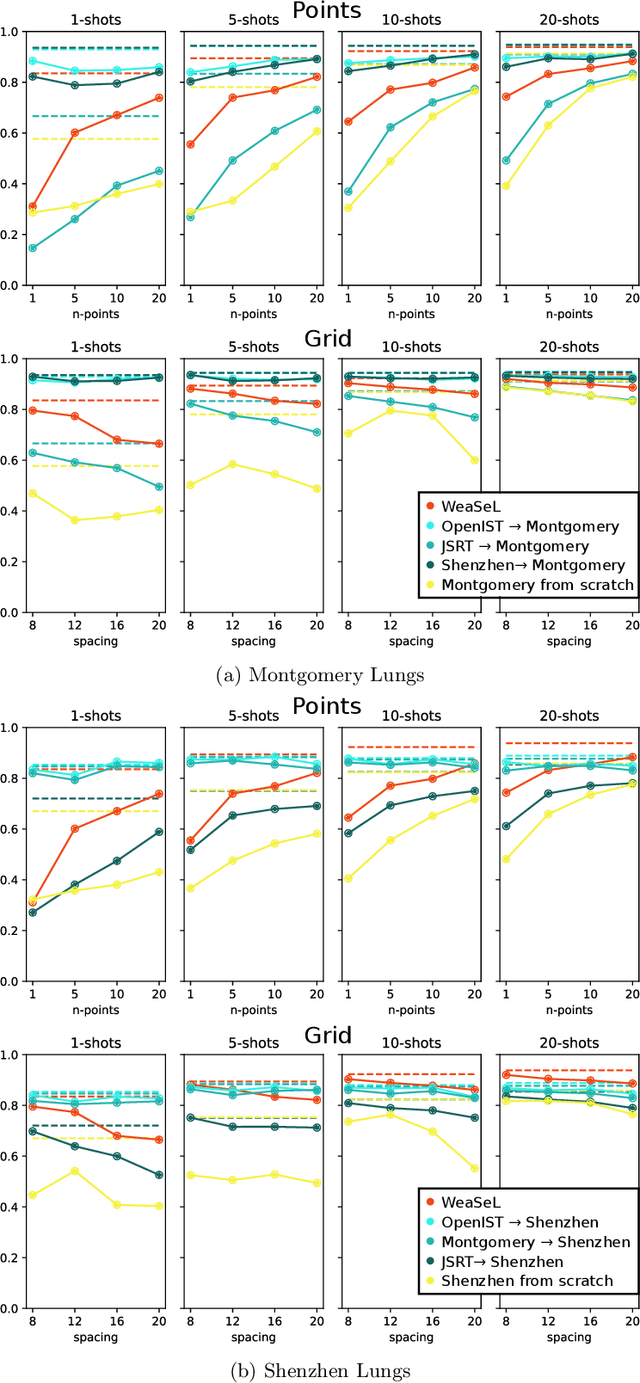
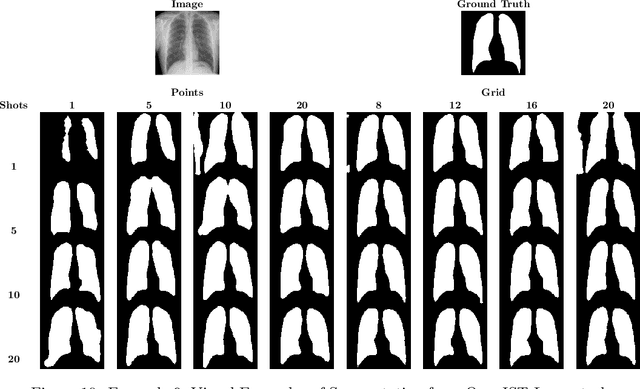
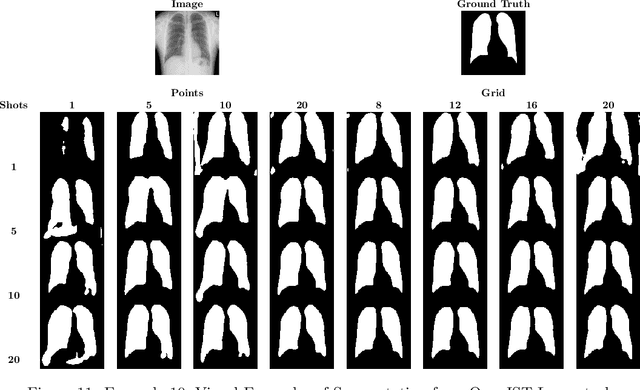
In this paper, we propose a novel approach for few-shot semantic segmentation with sparse labeled images. We investigate the effectiveness of our method, which is based on the Model-Agnostic Meta-Learning (MAML) algorithm, in the medical scenario, where the use of sparse labeling and few-shot can alleviate the cost of producing new annotated datasets. Our method uses sparse labels in the meta-training and dense labels in the meta-test, thus making the model learn to predict dense labels from sparse ones. We conducted experiments with four Chest X-Ray datasets to evaluate two types of annotations (grid and points). The results show that our method is the most suitable when the target domain highly differs from source domains, achieving Jaccard scores comparable to dense labels, using less than 2% of the pixels of an image with labels in few-shot scenarios.
FA-GAN: Fused Attentive Generative Adversarial Networks for MRI Image Super-Resolution
Aug 09, 2021


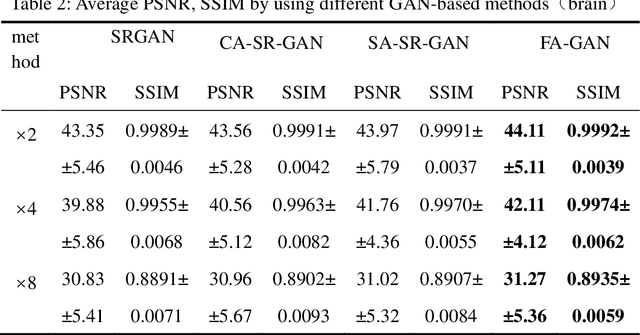
High-resolution magnetic resonance images can provide fine-grained anatomical information, but acquiring such data requires a long scanning time. In this paper, a framework called the Fused Attentive Generative Adversarial Networks(FA-GAN) is proposed to generate the super-resolution MR image from low-resolution magnetic resonance images, which can reduce the scanning time effectively but with high resolution MR images. In the framework of the FA-GAN, the local fusion feature block, consisting of different three-pass networks by using different convolution kernels, is proposed to extract image features at different scales. And the global feature fusion module, including the channel attention module, the self-attention module, and the fusion operation, is designed to enhance the important features of the MR image. Moreover, the spectral normalization process is introduced to make the discriminator network stable. 40 sets of 3D magnetic resonance images (each set of images contains 256 slices) are used to train the network, and 10 sets of images are used to test the proposed method. The experimental results show that the PSNR and SSIM values of the super-resolution magnetic resonance image generated by the proposed FA-GAN method are higher than the state-of-the-art reconstruction methods.
Data-driven Control of Agent-based Models: an Equation/Variable-free Machine Learning Approach
Jul 12, 2022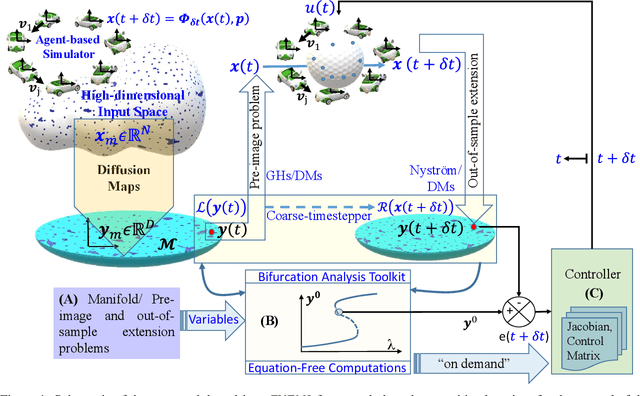
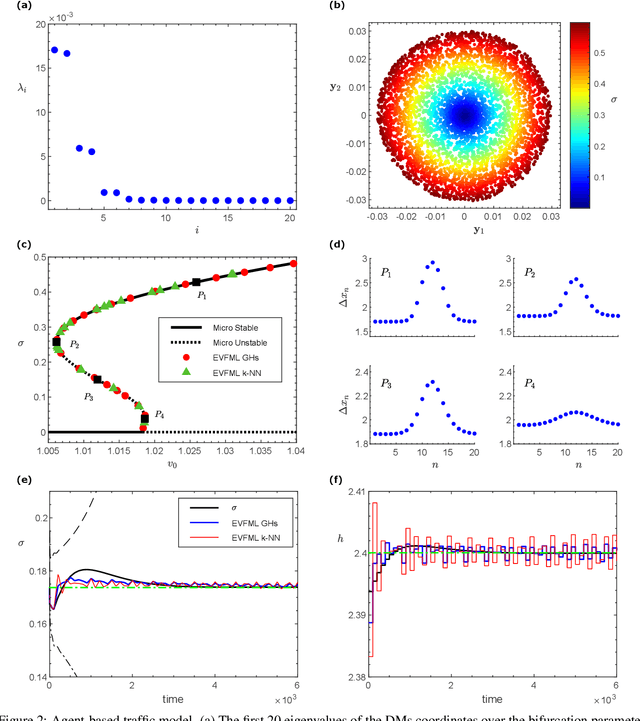
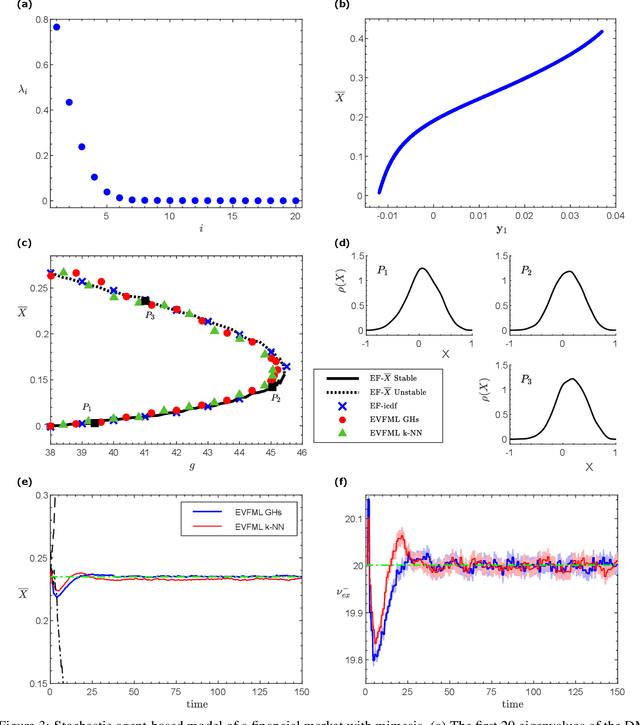
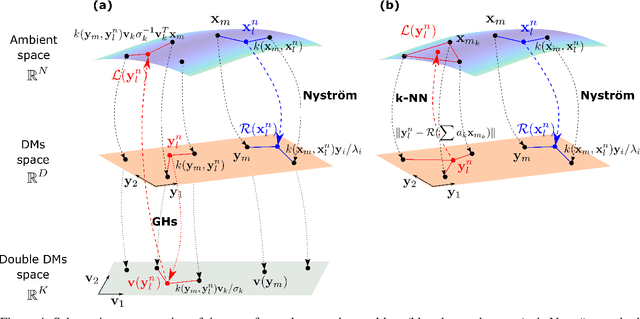
We present an Equation/Variable free machine learning (EVFML) framework for the control of the collective dynamics of complex/multiscale systems modelled via microscopic/agent-based simulators. The approach obviates the need for construction of surrogate, reduced-order models.~The proposed implementation consists of three steps: (A) from high-dimensional agent-based simulations, machine learning (in particular, non-linear manifold learning (Diffusion Maps (DMs)) helps identify a set of coarse-grained variables that parametrize the low-dimensional manifold on which the emergent/collective dynamics evolve. The out-of-sample extension and pre-image problems, i.e. the construction of non-linear mappings from the high-dimensional input space to the low-dimensional manifold and back, are solved by coupling DMs with the Nystrom extension and Geometric Harmonics, respectively; (B) having identified the manifold and its coordinates, we exploit the Equation-free approach to perform numerical bifurcation analysis of the emergent dynamics; then (C) based on the previous steps, we design data-driven embedded wash-out controllers that drive the agent-based simulators to their intrinsic, imprecisely known, emergent open-loop unstable steady-states, thus demonstrating that the scheme is robust against numerical approximation errors and modelling uncertainty.~The efficiency of the framework is illustrated by controlling emergent unstable (i) traveling waves of a deterministic agent-based model of traffic dynamics, and (ii) equilibria of a stochastic financial market agent model with mimesis.
Learning Convolutional Neural Networks in the Frequency Domain
Apr 15, 2022
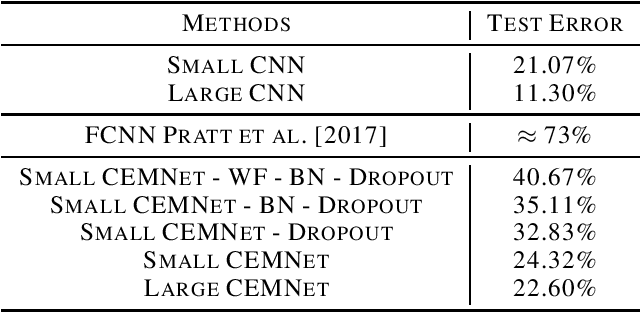
Convolutional neural network (CNN) achieves impressive success in the field of computer vision during the past few decades. As the core of CNNs, image convolution operation helps CNNs to achieve good performance on image-related tasks. However, image convolution is hard to be implemented and parallelized. In this paper, we propose a novel neural network model, namely CEMNet, that can be trained in frequency domain. The most important motivation of this research is that we can use the very simple element-wise multiplication operation to replace the image convolution in frequency domain based on Cross-Correlation Theorem. We further introduce Weight Fixation Mechanism to alleviate over-fitting, and analyze the working behavior of Batch Normalization, Leaky ReLU and Dropout in frequency domain to design their counterparts for CEMNet. Also, to deal with complex inputs brought by DFT, we design two branch network structure for CEMNet. Experimental results imply that CEMNet works well in frequency domain, and achieve good performance on MNIST and CIFAR-10 databases. To our knowledge, CEMNet is the first model trained in Fourier Domain that achieves more than 70\% validation accuracy on CIFAR-10 database.