 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PNODE: A memory-efficient neural ODE framework based on high-level adjoint differentiation
Jun 02, 2022
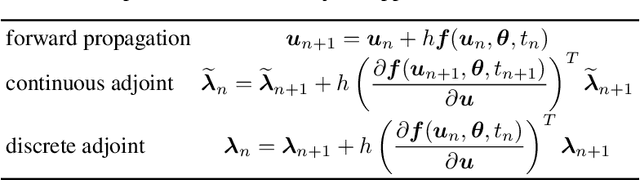


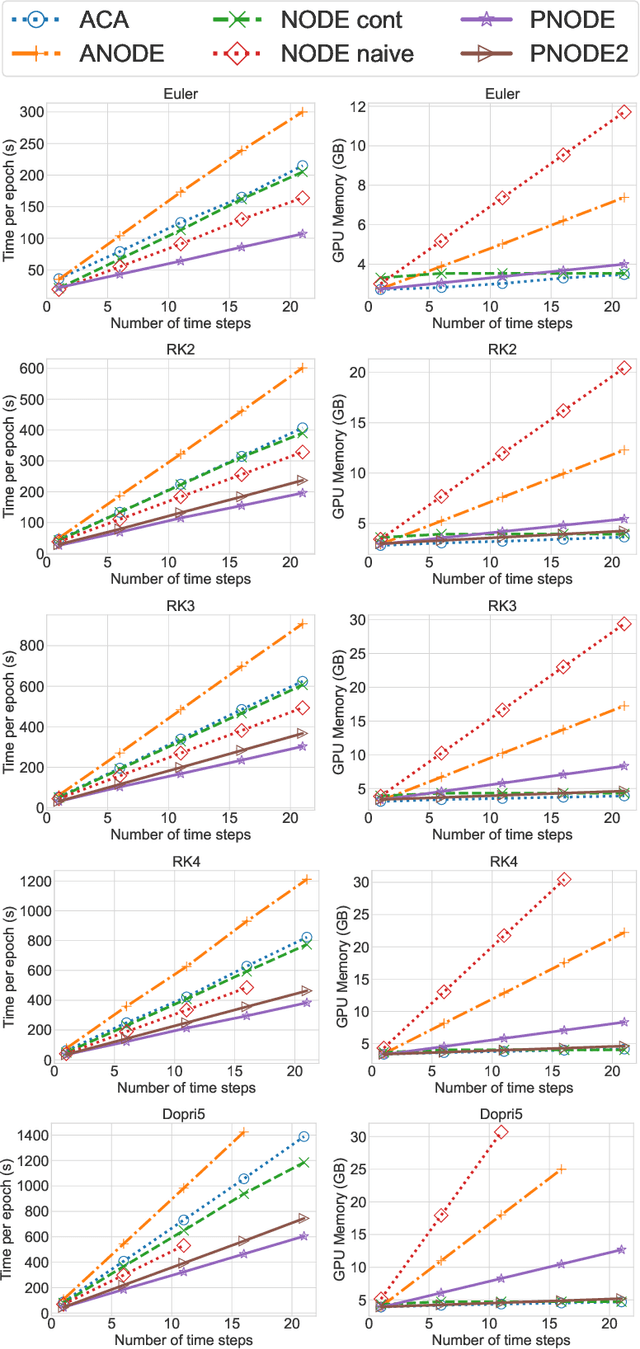
Neural ordinary differential equations (neural ODEs) have emerged as a novel network architecture that bridges dynamical systems and deep learning. However, the gradient obtained with the continuous adjoint method in the vanilla neural ODE is not reverse-accurate. Other approaches suffer either from excessive memory requirement due to deep computational graphs or from limited choices for the time integration scheme, hampering their application to large-scale complex dynamical systems. To achieve accurate gradients without compromising memory efficiency and flexibility, we present a new neural ODE framework, PNODE, based on high-level discrete adjoint algorithmic differentiation. By leveraging discrete adjoint time integrators and advanced checkpointing strategies tailored for these integrators, PNODE can provide a balance between memory and computational costs, while computing the gradients consistently and accurately. We provide an open-source implementation based on PyTorch and PETSc, one of the most commonly used portable, scalable scientific computing libraries. We demonstrate the performance through extensive numerical experiments on image classification and continuous normalizing flow problems. We show that PNODE achieves the highest memory efficiency when compared with other reverse-accurate methods. On the image classification problems, PNODE is up to two times faster than the vanilla neural ODE and up to 2.3 times faster than the best existing reverse-accurate method. We also show that PNODE enables the use of the implicit time integration methods that are needed for stiff dynamical systems.
PD-GAN: Probabilistic Diverse GAN for Image Inpainting
May 05, 2021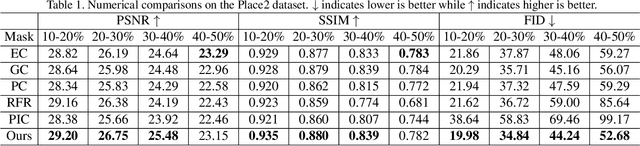
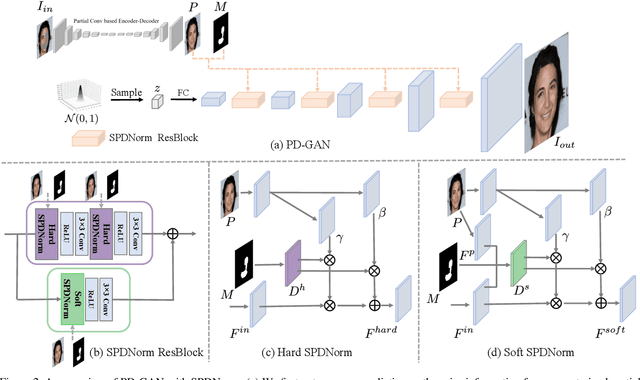
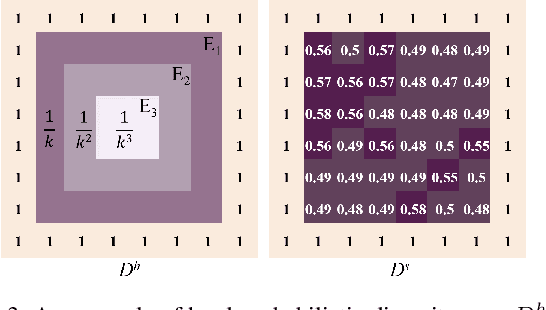
We propose PD-GAN, a probabilistic diverse GAN for image inpainting. Given an input image with arbitrary hole regions, PD-GAN produces multiple inpainting results with diverse and visually realistic content. Our PD-GAN is built upon a vanilla GAN which generates images based on random noise. During image generation, we modulate deep features of input random noise from coarse-to-fine by injecting an initially restored image and the hole regions in multiple scales. We argue that during hole filling, the pixels near the hole boundary should be more deterministic (i.e., with higher probability trusting the context and initially restored image to create natural inpainting boundary), while those pixels lie in the center of the hole should enjoy more degrees of freedom (i.e., more likely to depend on the random noise for enhancing diversity). To this end, we propose spatially probabilistic diversity normalization (SPDNorm) inside the modulation to model the probability of generating a pixel conditioned on the context information. SPDNorm dynamically balances the realism and diversity inside the hole region, making the generated content more diverse towards the hole center and resemble neighboring image content more towards the hole boundary. Meanwhile, we propose a perceptual diversity loss to further empower PD-GAN for diverse content generation. Experiments on benchmark datasets including CelebA-HQ, Places2 and Paris Street View indicate that PD-GAN is effective for diverse and visually realistic image restoration.
AdaFace: Quality Adaptive Margin for Face Recognition
Apr 03, 2022
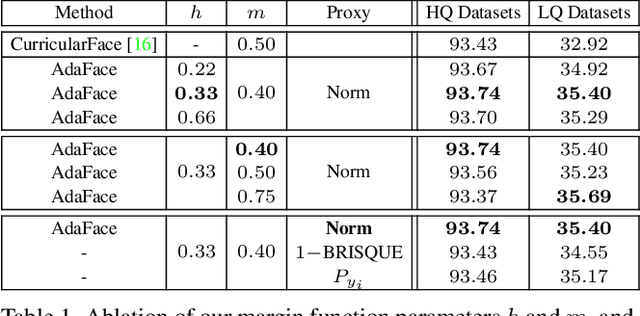


Recognition in low quality face datasets is challenging because facial attributes are obscured and degraded. Advances in margin-based loss functions have resulted in enhanced discriminability of faces in the embedding space. Further, previous studies have studied the effect of adaptive losses to assign more importance to misclassified (hard) examples. In this work, we introduce another aspect of adaptiveness in the loss function, namely the image quality. We argue that the strategy to emphasize misclassified samples should be adjusted according to their image quality. Specifically, the relative importance of easy or hard samples should be based on the sample's image quality. We propose a new loss function that emphasizes samples of different difficulties based on their image quality. Our method achieves this in the form of an adaptive margin function by approximating the image quality with feature norms. Extensive experiments show that our method, AdaFace, improves the face recognition performance over the state-of-the-art (SoTA) on four datasets (IJB-B, IJB-C, IJB-S and TinyFace). Code and models are released in https://github.com/mk-minchul/AdaFace.
Deep Active Latent Surfaces for Medical Geometries
Jun 21, 2022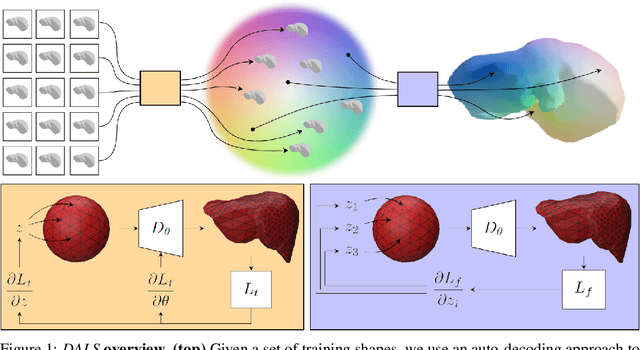

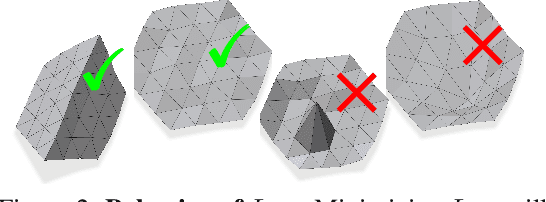
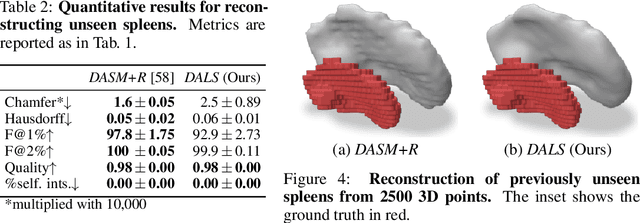
Shape priors have long been known to be effective when reconstructing 3D shapes from noisy or incomplete data. When using a deep-learning based shape representation, this often involves learning a latent representation, which can be either in the form of a single global vector or of multiple local ones. The latter allows more flexibility but is prone to overfitting. In this paper, we advocate a hybrid approach representing shapes in terms of 3D meshes with a separate latent vector at each vertex. During training the latent vectors are constrained to have the same value, which avoids overfitting. For inference, the latent vectors are updated independently while imposing spatial regularization constraints. We show that this gives us both flexibility and generalization capabilities, which we demonstrate on several medical image processing tasks.
Natural Image Reconstruction from fMRI using Deep Learning: A Survey
Oct 18, 2021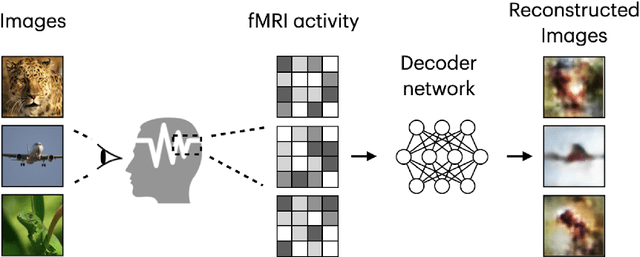


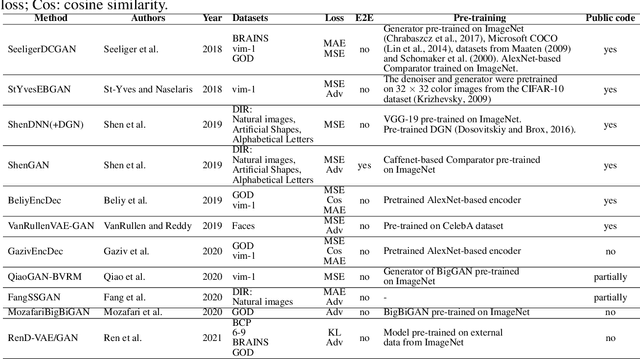
With the advent of brain imaging techniques and machine learning tools, much effort has been devoted to building computational models to capture the encoding of visual information in the human brain. One of the most challenging brain decoding tasks is the accurate reconstruction of the perceived natural images from brain activities measured by functional magnetic resonance imaging (fMRI). In this work, we survey the most recent deep learning methods for natural image reconstruction from fMRI. We examine these methods in terms of architectural design, benchmark datasets, and evaluation metrics and present a fair performance evaluation across standardized evaluation metrics. Finally, we discuss the strengths and limitations of existing studies and present potential future directions.
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents
Jul 17, 2022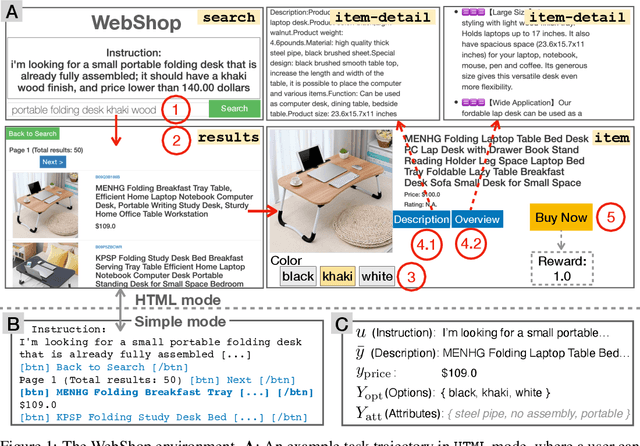
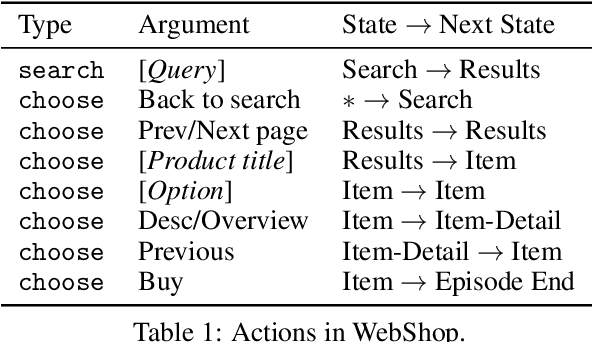
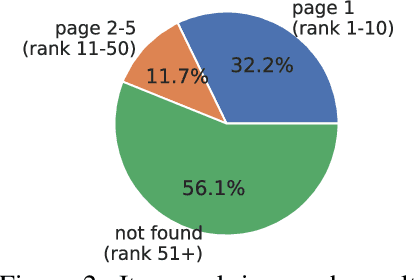
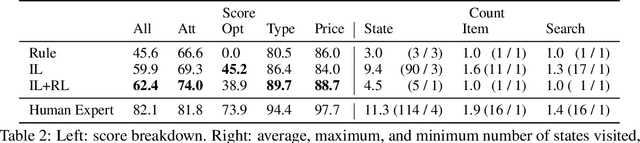
Existing benchmarks for grounding language in interactive environments either lack real-world linguistic elements, or prove difficult to scale up due to substantial human involvement in the collection of data or feedback signals. To bridge this gap, we develop WebShop -- a simulated e-commerce website environment with $1.18$ million real-world products and $12,087$ crowd-sourced text instructions. Given a text instruction specifying a product requirement, an agent needs to navigate multiple types of webpages and issue diverse actions to find, customize, and purchase an item. WebShop provides several challenges for language grounding including understanding compositional instructions, query (re-)formulation, comprehending and acting on noisy text in webpages, and performing strategic exploration. We collect over $1,600$ human demonstrations for the task, and train and evaluate a diverse range of agents using reinforcement learning, imitation learning, and pre-trained image and language models. Our best model achieves a task success rate of $29\%$, which outperforms rule-based heuristics ($9.6\%$) but is far lower than human expert performance ($59\%$). We also analyze agent and human trajectories and ablate various model components to provide insights for developing future agents with stronger language understanding and decision making abilities. Finally, we show that agents trained on WebShop exhibit non-trivial sim-to-real transfer when evaluated on amazon.com and ebay.com, indicating the potential value of WebShop in developing practical web-based agents that can operate in the wild.
Deep Camera Obscura: An Image Restoration Pipeline for Lensless Pinhole Photography
Aug 12, 2021The lensless pinhole camera is perhaps the earliest and simplest form of an imaging system using only a pinhole-sized aperture in place of a lens. They can capture an infinite depth-of-field and offer greater freedom from optical distortion over their lens-based counterparts. However, the inherent limitations of a pinhole system result in lower sharpness from blur caused by optical diffraction and higher noise levels due to low light throughput of the small aperture, requiring very long exposure times to capture well-exposed images. In this paper, we explore an image restoration pipeline using deep learning and domain-knowledge of the pinhole system to enhance the pinhole image quality through a joint denoise and deblur approach. Our approach allows for more practical exposure times for hand-held photography and provides higher image quality, making it more suitable for daily photography compared to other lensless cameras while keeping size and cost low. This opens up the potential of pinhole cameras to be used in smaller devices, such as smartphones.
Step-Wise Hierarchical Alignment Network for Image-Text Matching
Jun 11, 2021
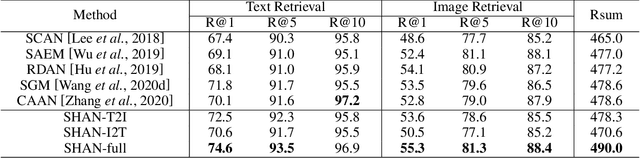
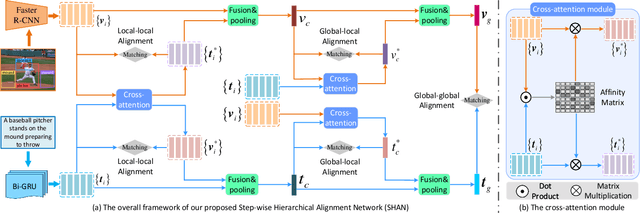
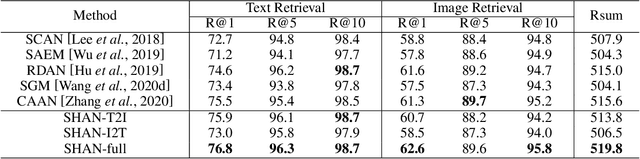
Image-text matching plays a central role in bridging the semantic gap between vision and language. The key point to achieve precise visual-semantic alignment lies in capturing the fine-grained cross-modal correspondence between image and text. Most previous methods rely on single-step reasoning to discover the visual-semantic interactions, which lacks the ability of exploiting the multi-level information to locate the hierarchical fine-grained relevance. Different from them, in this work, we propose a step-wise hierarchical alignment network (SHAN) that decomposes image-text matching into multi-step cross-modal reasoning process. Specifically, we first achieve local-to-local alignment at fragment level, following by performing global-to-local and global-to-global alignment at context level sequentially. This progressive alignment strategy supplies our model with more complementary and sufficient semantic clues to understand the hierarchical correlations between image and text. The experimental results on two benchmark datasets demonstrate the superiority of our proposed method.
MACSA: A Multimodal Aspect-Category Sentiment Analysis Dataset with Multimodal Fine-grained Aligned Annotations
Jun 28, 2022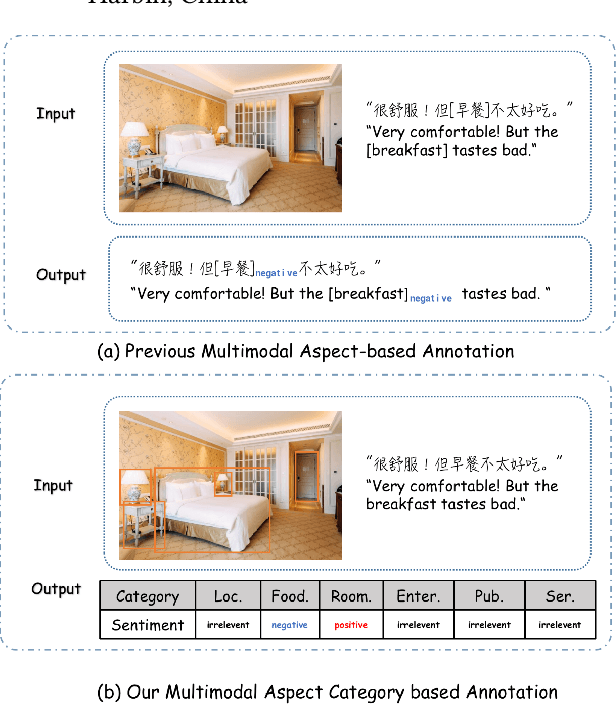
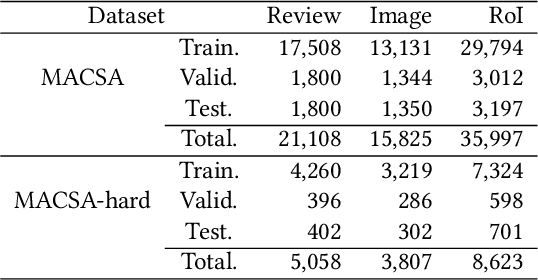
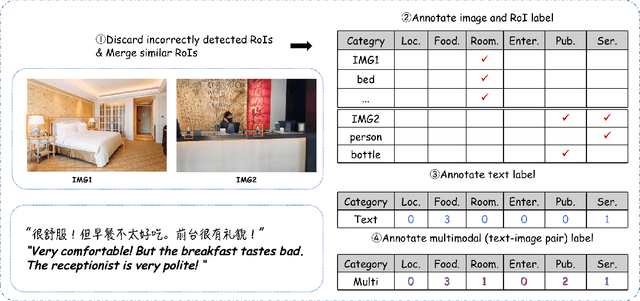
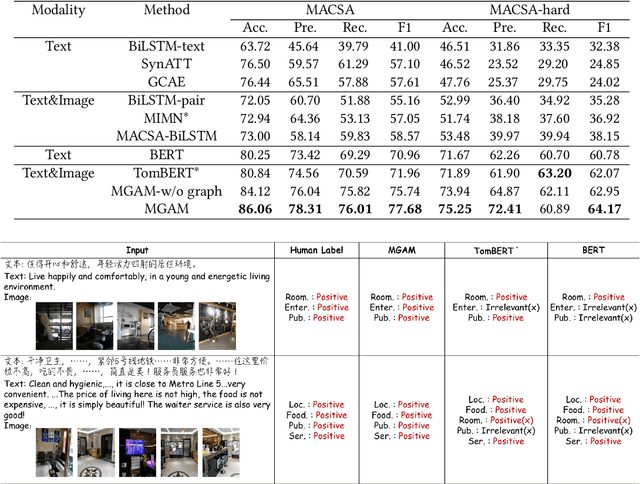
Multimodal fine-grained sentiment analysis has recently attracted increasing attention due to its broad applications. However, the existing multimodal fine-grained sentiment datasets most focus on annotating the fine-grained elements in text but ignore those in images, which leads to the fine-grained elements in visual content not receiving the full attention they deserve. In this paper, we propose a new dataset, the Multimodal Aspect-Category Sentiment Analysis (MACSA) dataset, which contains more than 21K text-image pairs. The dataset provides fine-grained annotations for both textual and visual content and firstly uses the aspect category as the pivot to align the fine-grained elements between the two modalities. Based on our dataset, we propose the Multimodal ACSA task and a multimodal graph-based aligned model (MGAM), which adopts a fine-grained cross-modal fusion method. Experimental results show that our method can facilitate the baseline comparison for future research on this corpus. We will make the dataset and code publicly available.
Super-Resolution Image Reconstruction Based on Self-Calibrated Convolutional GAN
Jun 10, 2021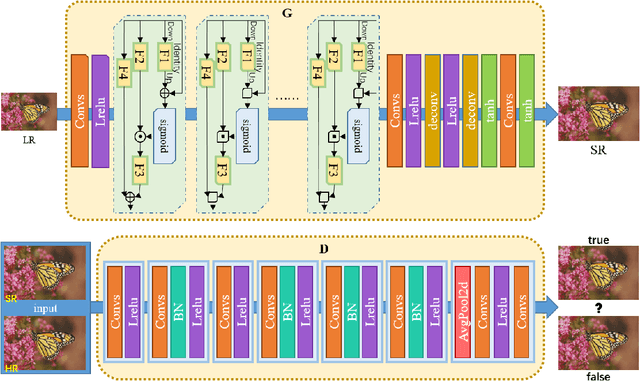
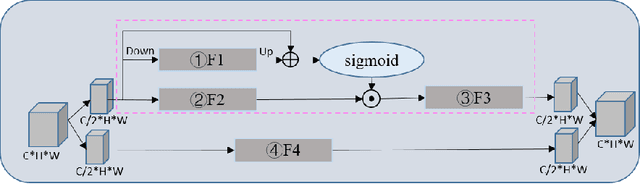

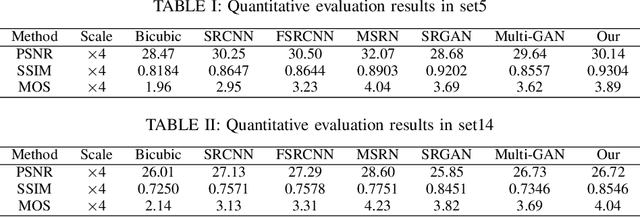
With the effective application of deep learning in computer vision, breakthroughs have been made in the research of super-resolution images reconstruction. However, many researches have pointed out that the insufficiency of the neural network extraction on image features may bring the deteriorating of newly reconstructed image. On the other hand, the generated pictures are sometimes too artificial because of over-smoothing. In order to solve the above problems, we propose a novel self-calibrated convolutional generative adversarial networks. The generator consists of feature extraction and image reconstruction. Feature extraction uses self-calibrated convolutions, which contains four portions, and each portion has specific functions. It can not only expand the range of receptive fields, but also obtain long-range spatial and inter-channel dependencies. Then image reconstruction is performed, and finally a super-resolution image is reconstructed. We have conducted thorough experiments on different datasets including set5, set14 and BSD100 under the SSIM evaluation method. The experimental results prove the effectiveness of the proposed network.