 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Preservational Learning Improves Self-supervised Medical Image Models by Reconstructing Diverse Contexts
Sep 09, 2021
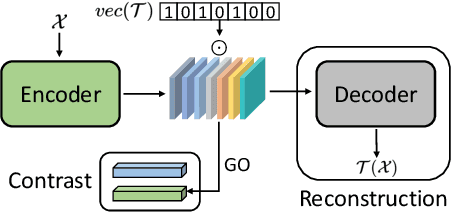
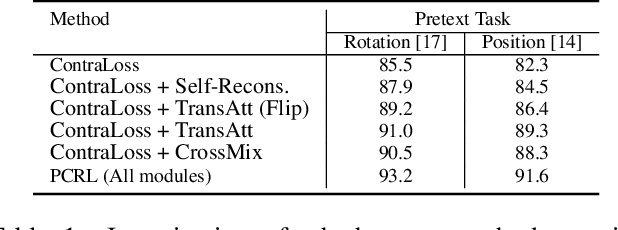
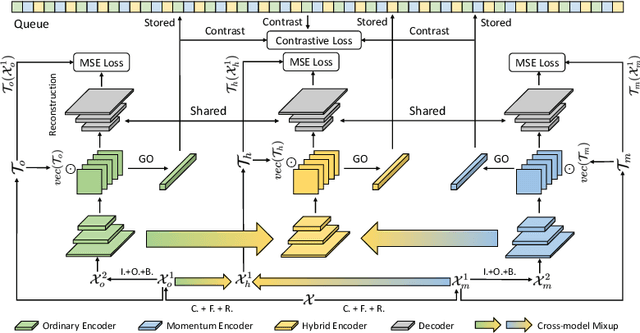
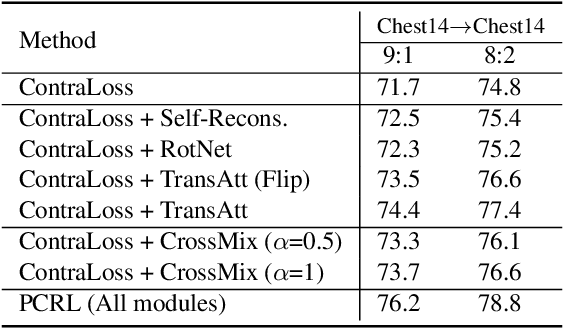
Preserving maximal information is one of principles of designing self-supervised learning methodologies. To reach this goal, contrastive learning adopts an implicit way which is contrasting image pairs. However, we believe it is not fully optimal to simply use the contrastive estimation for preservation. Moreover, it is necessary and complemental to introduce an explicit solution to preserve more information. From this perspective, we introduce Preservational Learning to reconstruct diverse image contexts in order to preserve more information in learned representations. Together with the contrastive loss, we present Preservational Contrastive Representation Learning (PCRL) for learning self-supervised medical representations. PCRL provides very competitive results under the pretraining-finetuning protocol, outperforming both self-supervised and supervised counterparts in 5 classification/segmentation tasks substantially.
Lesion detection in contrast enhanced spectral mammography
Jul 20, 2022Background \& purpose: The recent emergence of neural networks models for the analysis of breast images has been a breakthrough in computer aided diagnostic. This approach was not yet developed in Contrast Enhanced Spectral Mammography (CESM) where access to large databases is complex. This work proposes a deep-learning-based Computer Aided Diagnostic development for CESM recombined images able to detect lesions and classify cases. Material \& methods: A large CESM diagnostic dataset with biopsy-proven lesions was collected from various hospitals and different acquisition systems. The annotated data were split on a patient level for the training (55%), validation (15%) and test (30%) of a deep neural network with a state-of-the-art detection architecture. Free Receiver Operating Characteristic (FROC) was used to evaluate the model for the detection of 1) all lesions, 2) biopsied lesions and 3) malignant lesions. ROC curve was used to evaluate breast cancer classification. The metrics were finally compared to clinical results. Results: For the evaluation of the malignant lesion detection, at high sensitivity (Se>0.95), the false positive rate was at 0.61 per image. For the classification of malignant cases, the model reached an Area Under the Curve (AUC) in the range of clinical CESM diagnostic results. Conclusion: This CAD is the first development of a lesion detection and classification model for CESM images. Trained on a large dataset, it has the potential to be used for helping the management of biopsy decision and for helping the radiologist detecting complex lesions that could modify the clinical treatment.
SurfaceNet: Adversarial SVBRDF Estimation from a Single Image
Jul 23, 2021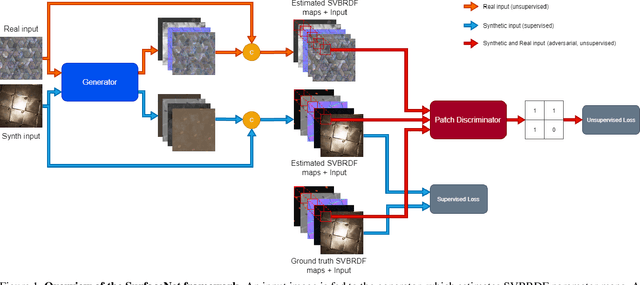
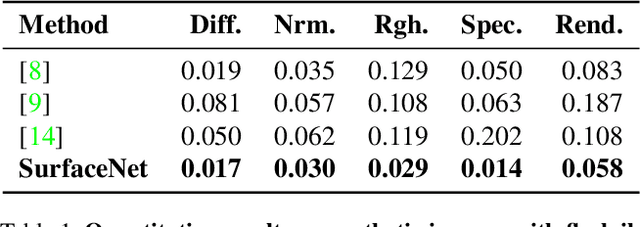
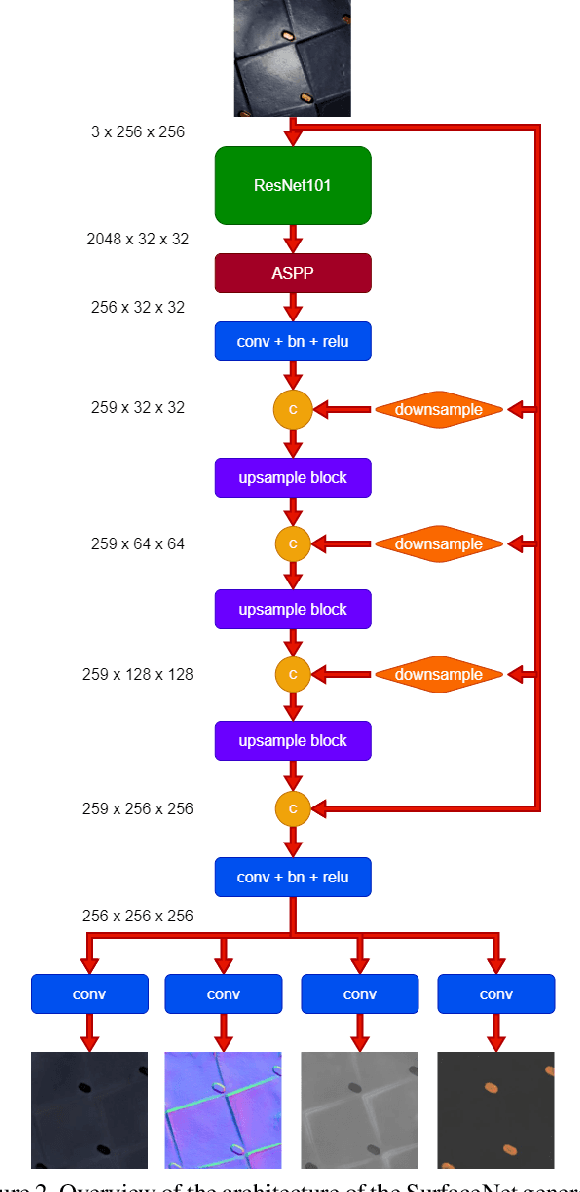
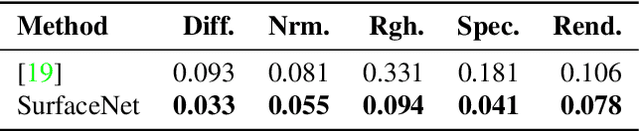
In this paper we present SurfaceNet, an approach for estimating spatially-varying bidirectional reflectance distribution function (SVBRDF) material properties from a single image. We pose the problem as an image translation task and propose a novel patch-based generative adversarial network (GAN) that is able to produce high-quality, high-resolution surface reflectance maps. The employment of the GAN paradigm has a twofold objective: 1) allowing the model to recover finer details than standard translation models; 2) reducing the domain shift between synthetic and real data distributions in an unsupervised way. An extensive evaluation, carried out on a public benchmark of synthetic and real images under different illumination conditions, shows that SurfaceNet largely outperforms existing SVBRDF reconstruction methods, both quantitatively and qualitatively. Furthermore, SurfaceNet exhibits a remarkable ability in generating high-quality maps from real samples without any supervision at training time.
Contrastive Semi-Supervised Learning for 2D Medical Image Segmentation
Jun 12, 2021



Contrastive Learning (CL) is a recent representation learning approach, which achieves promising results by encouraging inter-class separability and intra-class compactness in learned image representations. Because medical images often contain multiple classes of interest per image, a standard image-level CL for these images is not applicable. In this work, we present a novel semi-supervised 2D medical segmentation solution that applies CL on image patches, instead of full images. These patches are meaningfully constructed using the semantic information of different classes obtained via pseudo labeling. We also propose a novel consistency regularization scheme, which works in synergy with contrastive learning. It addresses the problem of confirmation bias often observed in semi-supervised settings, and encourages better clustering in the feature space. We evaluate our method on four public medical segmentation datasets along with a novel histopathology dataset that we introduce. Our method obtains consistent improvements over the state-of-the-art semi-supervised segmentation approaches for all datasets.
Contrastive Learning of Features between Images and LiDAR
Jun 24, 2022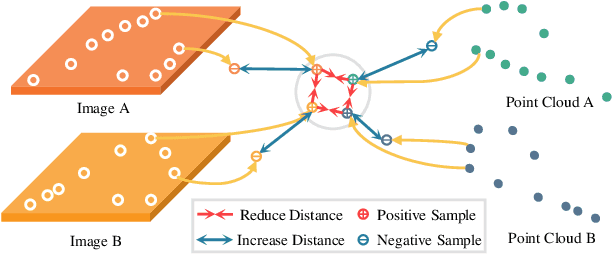
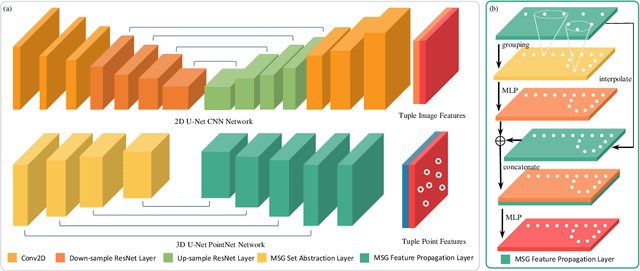


Image and Point Clouds provide different information for robots. Finding the correspondences between data from different sensors is crucial for various tasks such as localization, mapping, and navigation. Learning-based descriptors have been developed for single sensors; there is little work on cross-modal features. This work treats learning cross-modal features as a dense contrastive learning problem. We propose a Tuple-Circle loss function for cross-modality feature learning. Furthermore, to learn good features and not lose generality, we developed a variant of widely used PointNet++ architecture for point cloud and U-Net CNN architecture for images. Moreover, we conduct experiments on a real-world dataset to show the effectiveness of our loss function and network structure. We show that our models indeed learn information from both images as well as LiDAR by visualizing the features.
A Transfer-Learning Based Ensemble Architecture for ECG Signal Classification
Jun 21, 2022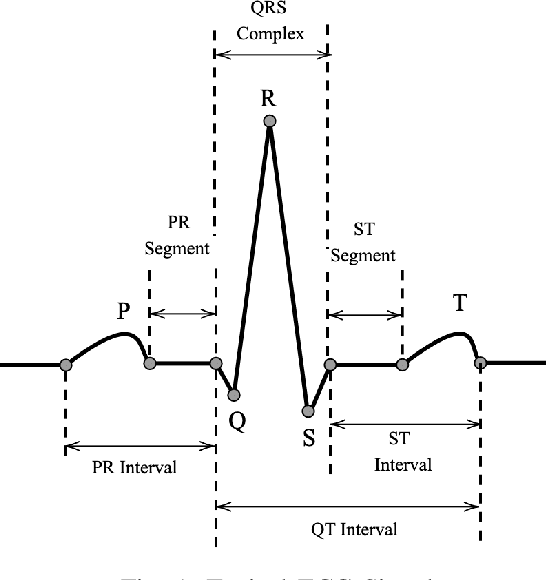
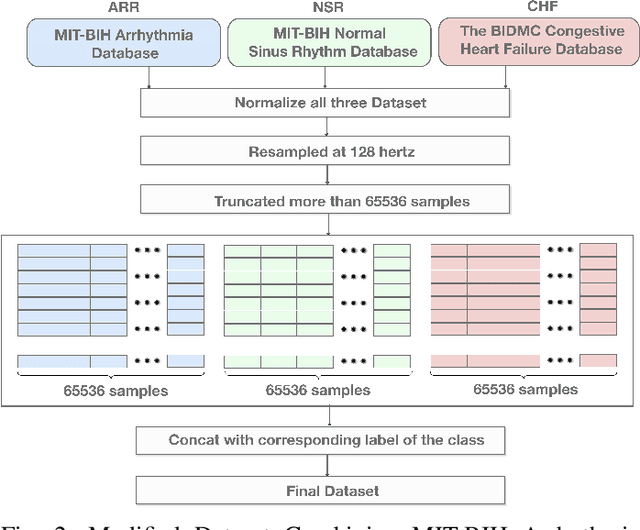
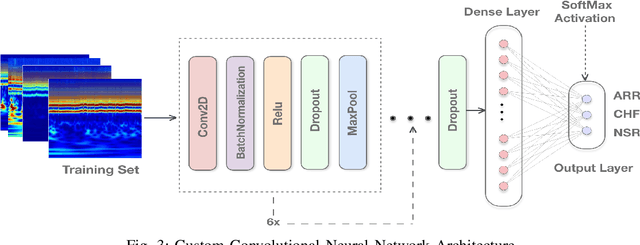
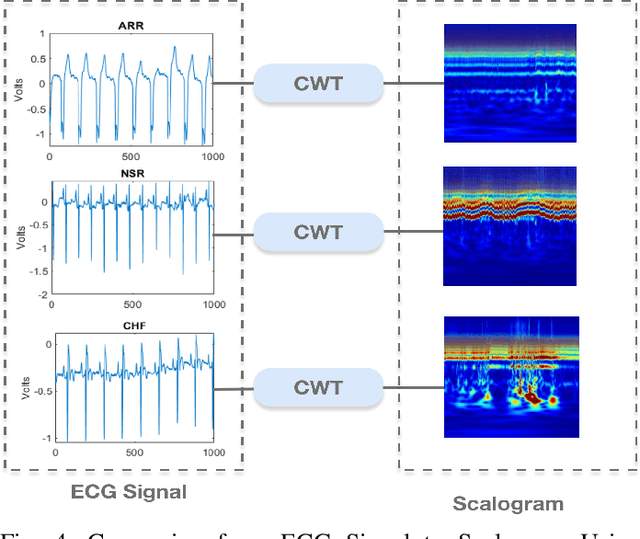
Manual interpretation and classification of ECG signals lack both accuracy and reliability. These continuous time-series signals are more effective when represented as an image for CNN-based classification. A continuous Wavelet transform filter is used here to get corresponding images. In achieving the best result generic CNN architectures lack sufficient accuracy and also have a higher run-time. To address this issue, we propose an ensemble method of transfer learning-based models to classify ECG signals. In our work, two modified VGG-16 models and one InceptionResNetV2 model with added feature extracting layers and ImageNet weights are working as the backbone. After ensemble, we report an increase of 6.36% accuracy than previous MLP-based algorithms. After 5-fold cross-validation with the Physionet dataset, our model reaches an accuracy of 99.98%.
LatentKeypointGAN: Controlling Images via Latent Keypoints -- Extended Abstract
May 17, 2022
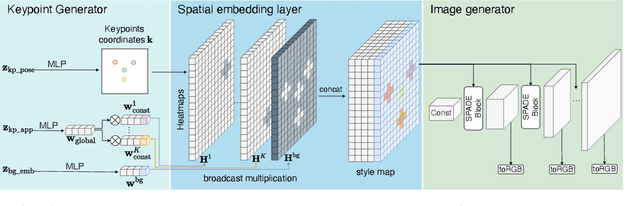
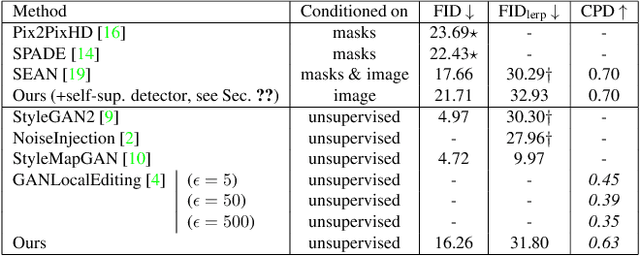
Generative adversarial networks (GANs) can now generate photo-realistic images. However, how to best control the image content remains an open challenge. We introduce LatentKeypointGAN, a two-stage GAN internally conditioned on a set of keypoints and associated appearance embeddings providing control of the position and style of the generated objects and their respective parts. A major difficulty that we address is disentangling the image into spatial and appearance factors with little domain knowledge and supervision signals. We demonstrate in a user study and quantitative experiments that LatentKeypointGAN provides an interpretable latent space that can be used to re-arrange the generated images by re-positioning and exchanging keypoint embeddings, such as generating portraits by combining the eyes, and mouth from different images. Notably, our method does not require labels as it is self-supervised and thereby applies to diverse application domains, such as editing portraits, indoor rooms, and full-body human poses.
PNODE: A memory-efficient neural ODE framework based on high-level adjoint differentiation
Jun 02, 2022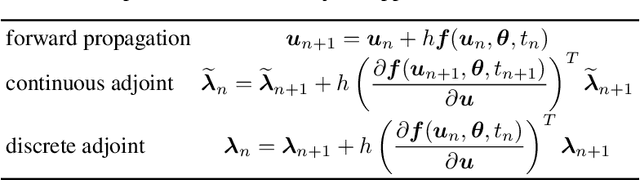


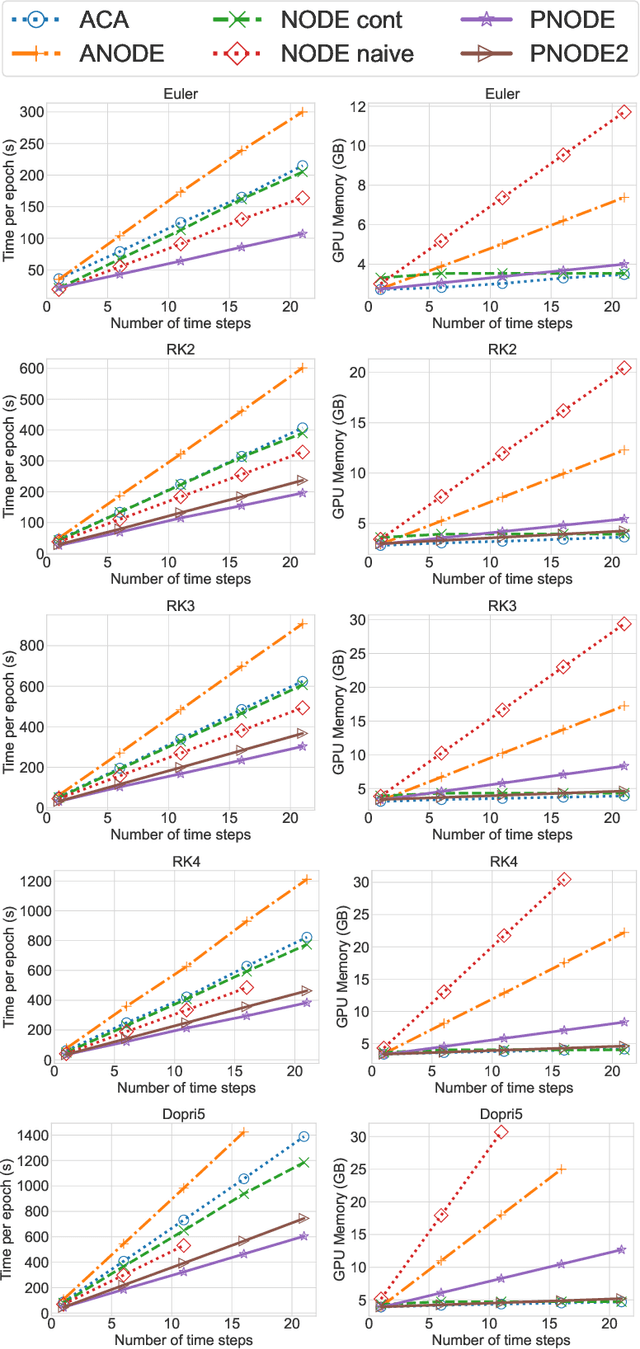
Neural ordinary differential equations (neural ODEs) have emerged as a novel network architecture that bridges dynamical systems and deep learning. However, the gradient obtained with the continuous adjoint method in the vanilla neural ODE is not reverse-accurate. Other approaches suffer either from excessive memory requirement due to deep computational graphs or from limited choices for the time integration scheme, hampering their application to large-scale complex dynamical systems. To achieve accurate gradients without compromising memory efficiency and flexibility, we present a new neural ODE framework, PNODE, based on high-level discrete adjoint algorithmic differentiation. By leveraging discrete adjoint time integrators and advanced checkpointing strategies tailored for these integrators, PNODE can provide a balance between memory and computational costs, while computing the gradients consistently and accurately. We provide an open-source implementation based on PyTorch and PETSc, one of the most commonly used portable, scalable scientific computing libraries. We demonstrate the performance through extensive numerical experiments on image classification and continuous normalizing flow problems. We show that PNODE achieves the highest memory efficiency when compared with other reverse-accurate methods. On the image classification problems, PNODE is up to two times faster than the vanilla neural ODE and up to 2.3 times faster than the best existing reverse-accurate method. We also show that PNODE enables the use of the implicit time integration methods that are needed for stiff dynamical systems.
High-Frequency aware Perceptual Image Enhancement
May 25, 2021
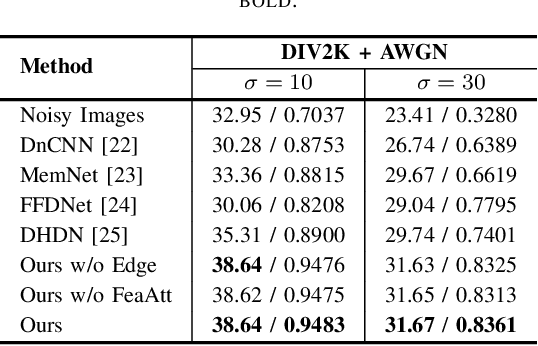
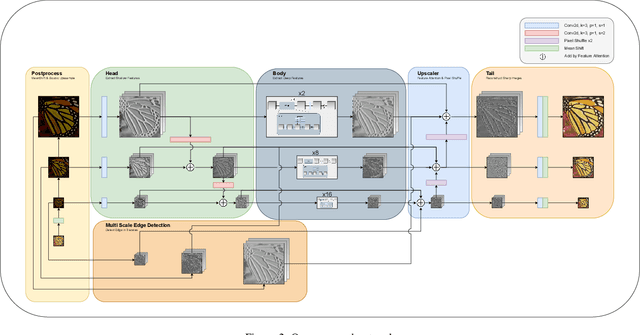
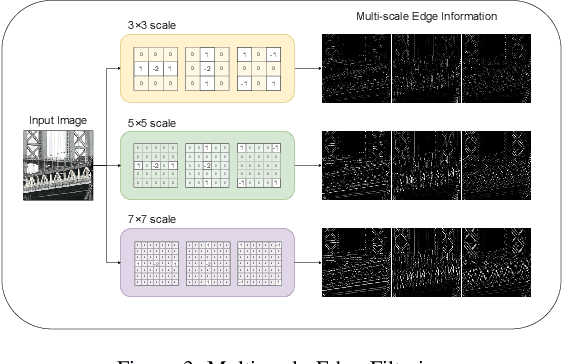
In this paper, we introduce a novel deep neural network suitable for multi-scale analysis and propose efficient model-agnostic methods that help the network extract information from high-frequency domains to reconstruct clearer images. Our model can be applied to multi-scale image enhancement problems including denoising, deblurring and single image super-resolution. Experiments on SIDD, Flickr2K, DIV2K, and REDS datasets show that our method achieves state-of-the-art performance on each task. Furthermore, we show that our model can overcome the over-smoothing problem commonly observed in existing PSNR-oriented methods and generate more natural high-resolution images by applying adversarial training.
Monocular 3D Fingerprint Reconstruction and Unwarping
May 02, 2022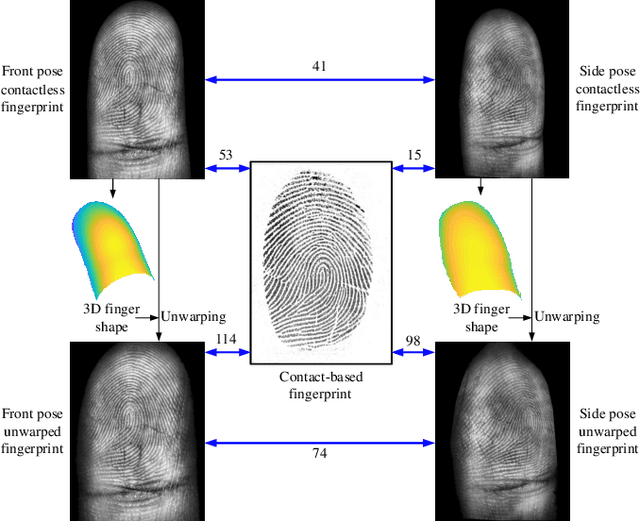
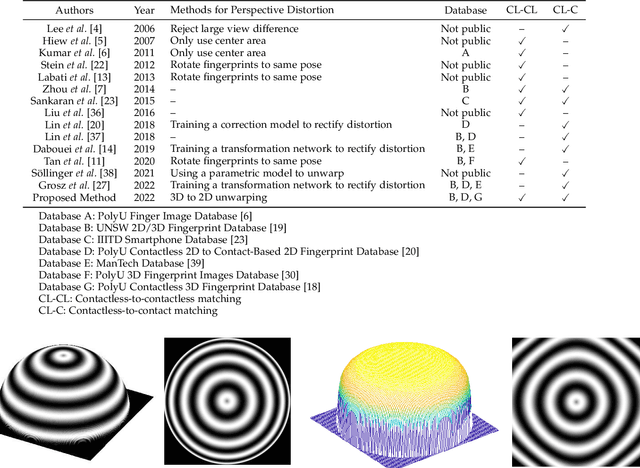
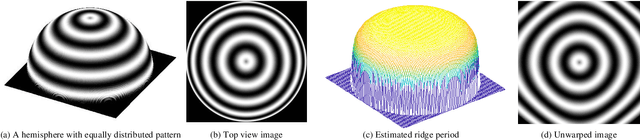
Compared with contact-based fingerprint acquisition techniques, contactless acquisition has the advantages of less skin distortion, larger fingerprint area, and hygienic acquisition. However, perspective distortion is a challenge in contactless fingerprint recognition, which changes ridge orientation, frequency, and minutiae location, and thus causes degraded recognition accuracy. We propose a learning based shape from texture algorithm to reconstruct a 3D finger shape from a single image and unwarp the raw image to suppress perspective distortion. Experimental results on contactless fingerprint databases show that the proposed method has high 3D reconstruction accuracy. Matching experiments on contactless-contact and contactless-contactless matching prove that the proposed method improves matching accuracy.