 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Semantic Image Segmentation via Label Fusion in Semantically Textured Meshes
Nov 22, 2021
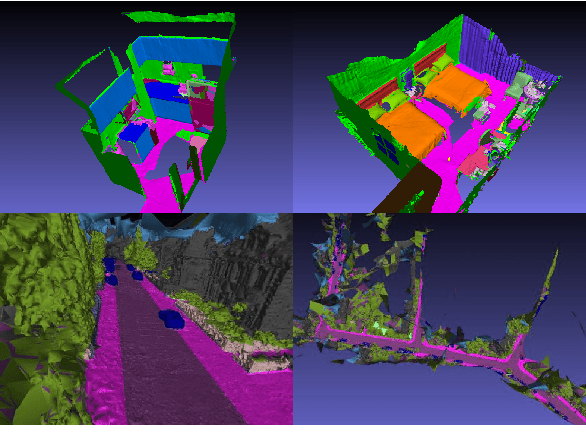

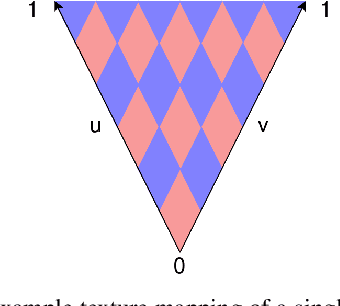
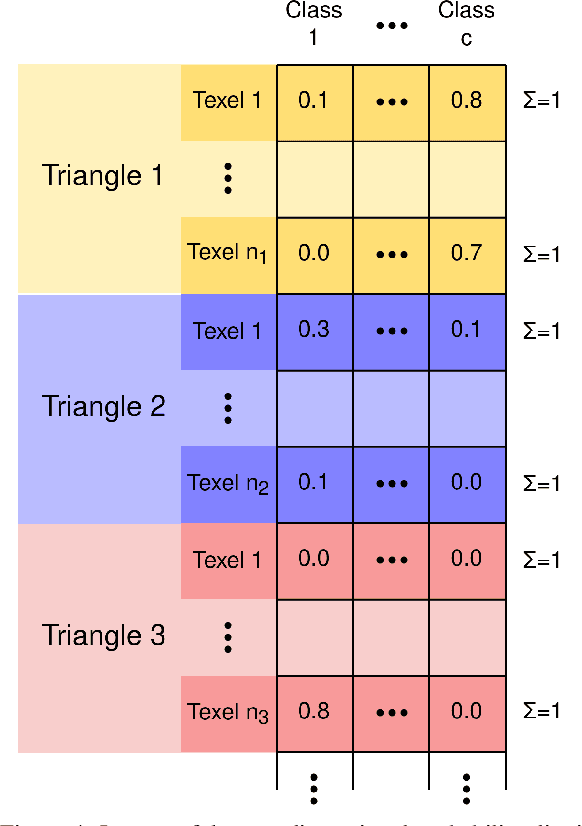
Models for semantic segmentation require a large amount of hand-labeled training data which is costly and time-consuming to produce. For this purpose, we present a label fusion framework that is capable of improving semantic pixel labels of video sequences in an unsupervised manner. We make use of a 3D mesh representation of the environment and fuse the predictions of different frames into a consistent representation using semantic mesh textures. Rendering the semantic mesh using the original intrinsic and extrinsic camera parameters yields a set of improved semantic segmentation images. Due to our optimized CUDA implementation, we are able to exploit the entire $c$-dimensional probability distribution of annotations over $c$ classes in an uncertainty-aware manner. We evaluate our method on the Scannet dataset where we improve annotations produced by the state-of-the-art segmentation network ESANet from $52.05 \%$ to $58.25 \%$ pixel accuracy. We publish the source code of our framework online to foster future research in this area (\url{https://github.com/fferflo/semantic-meshes}). To the best of our knowledge, this is the first publicly available label fusion framework for semantic image segmentation based on meshes with semantic textures.
Copy-Move Image Forgery Detection Based on Evolving Circular Domains Coverage
Sep 09, 2021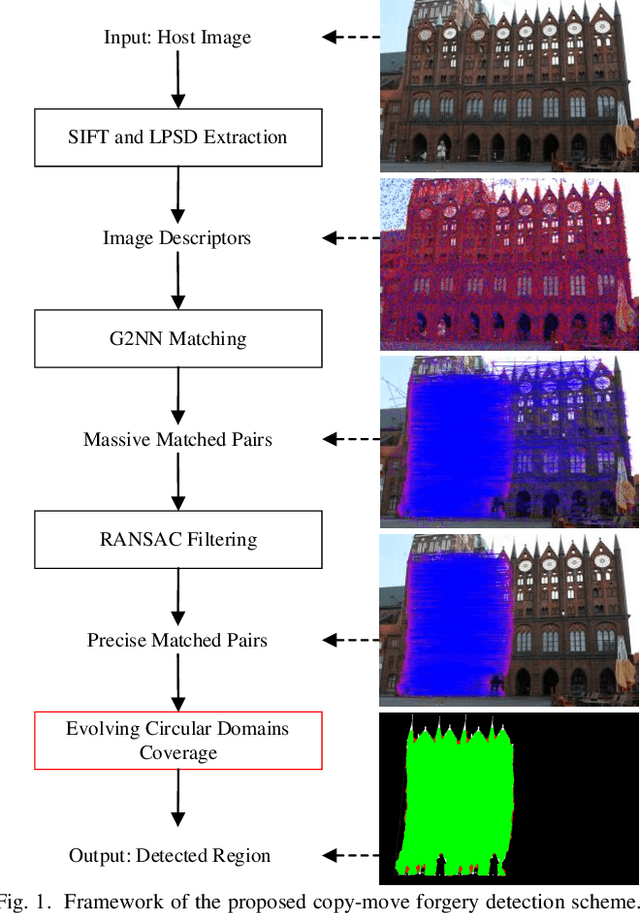
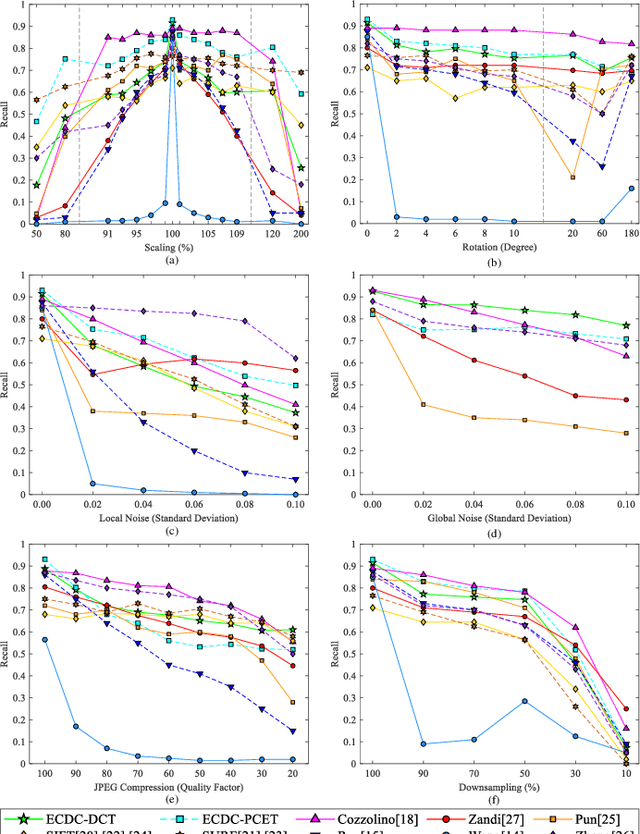
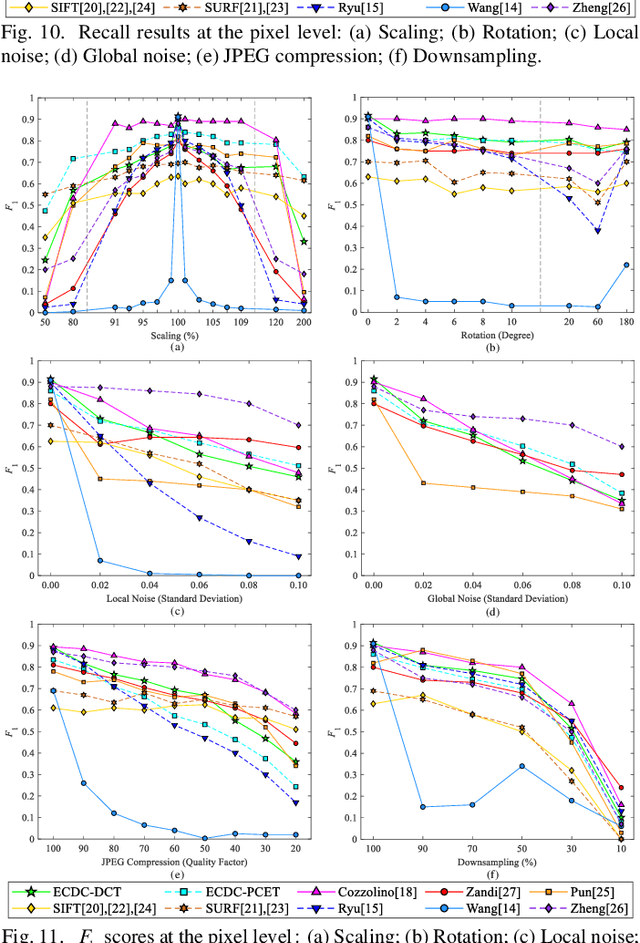

The aim of this paper is to improve the accuracy of copy-move forgery detection (CMFD) in image forensics by proposing a novel scheme. The proposed scheme integrates both block-based and keypoint-based forgery detection methods. Firstly, speed-up robust feature (SURF) descriptor in log-polar space and scale invariant feature transform (SIFT) descriptor are extracted from an entire forged image. Secondly, generalized 2 nearest neighbor (g2NN) is employed to get massive matched pairs. Then, random sample consensus (RANSAC) algorithm is employed to filter out mismatched pairs, thus allowing rough localization of the counterfeit areas. To present more accurately these forgery areas more accurately, we propose an efficient and accurate algorithm, evolving circular domains coverage (ECDC), to cover present them. This algorithm aims to find satisfactory threshold areas by extracting block features from jointly evolving circular domains, which are centered on the matched pairs. Finally, morphological operation is applied to refine the detected forgery areas. The experimental results indicate that the proposed CMFD scheme can achieve better detection performance under various attacks compared with other state-of-the-art CMFD schemes.
JPGNet: Joint Predictive Filtering and Generative Network for Image Inpainting
Jul 09, 2021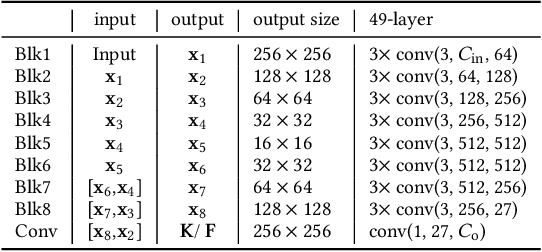

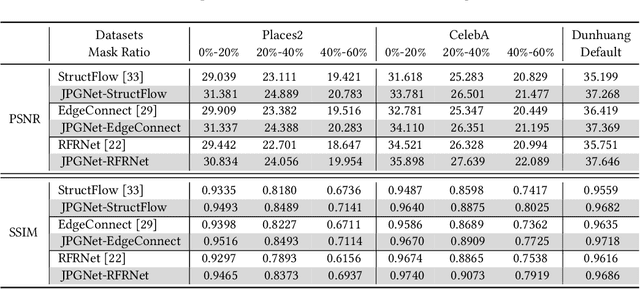
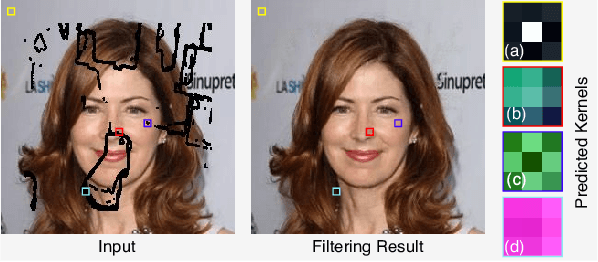
Image inpainting aims to restore the missing regions and make the recovery results identical to the originally complete image, which is different from the common generative task emphasizing the naturalness of generated images. Nevertheless, existing works usually regard it as a pure generation problem and employ cutting-edge generative techniques to address it. The generative networks fill the main missing parts with realistic contents but usually distort the local structures. In this paper, we formulate image inpainting as a mix of two problems, i.e., predictive filtering and deep generation. Predictive filtering is good at preserving local structures and removing artifacts but falls short to complete the large missing regions. The deep generative network can fill the numerous missing pixels based on the understanding of the whole scene but hardly restores the details identical to the original ones. To make use of their respective advantages, we propose the joint predictive filtering and generative network (JPGNet) that contains three branches: predictive filtering & uncertainty network (PFUNet), deep generative network, and uncertainty-aware fusion network (UAFNet). The PFUNet can adaptively predict pixel-wise kernels for filtering-based inpainting according to the input image and output an uncertainty map. This map indicates the pixels should be processed by filtering or generative networks, which is further fed to the UAFNet for a smart combination between filtering and generative results. Note that, our method as a novel framework for the image inpainting problem can benefit any existing generation-based methods. We validate our method on three public datasets, i.e., Dunhuang, Places2, and CelebA, and demonstrate that our method can enhance three state-of-the-art generative methods (i.e., StructFlow, EdgeConnect, and RFRNet) significantly with the slightly extra time cost.
Trimap-guided Feature Mining and Fusion Network for Natural Image Matting
Dec 03, 2021
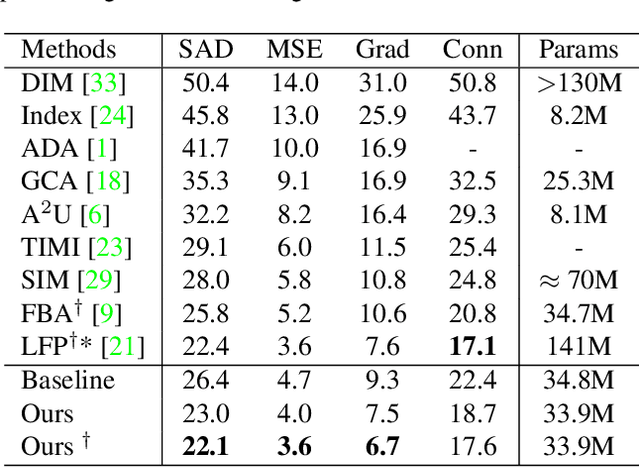
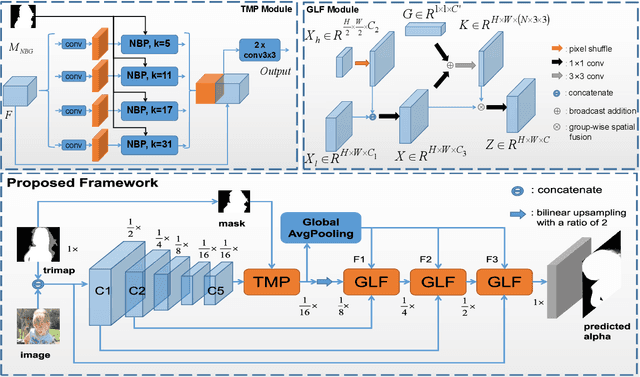
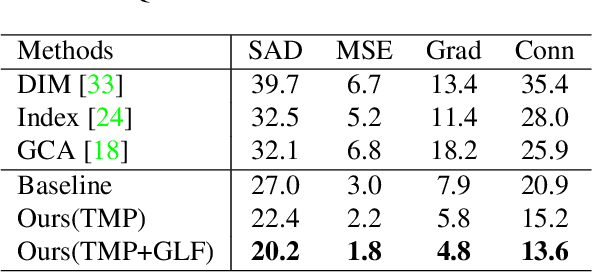
Utilizing trimap guidance and fusing multi-level features are two important issues for trimap-based matting with pixel-level prediction. To utilize trimap guidance, most existing approaches simply concatenate trimaps and images together to feed a deep network or apply an extra network to extract more trimap guidance, which meets the conflict between efficiency and effectiveness. For emerging content-based feature fusion, most existing matting methods only focus on local features which lack the guidance of a global feature with strong semantic information related to the interesting object. In this paper, we propose a trimap-guided feature mining and fusion network consisting of our trimap-guided non-background multi-scale pooling (TMP) module and global-local context-aware fusion (GLF) modules. Considering that trimap provides strong semantic guidance, our TMP module focuses effective feature mining on interesting objects under the guidance of trimap without extra parameters. Furthermore, our GLF modules use global semantic information of interesting objects mined by our TMP module to guide an effective global-local context-aware multi-level feature fusion. In addition, we build a common interesting object matting (CIOM) dataset to advance high-quality image matting. Experimental results on the Composition-1k test set, Alphamatting benchmark, and our CIOM test set demonstrate that our method outperforms state-of-the-art approaches. Code and models will be publicly available soon.
MaskRange: A Mask-classification Model for Range-view based LiDAR Segmentation
Jun 24, 2022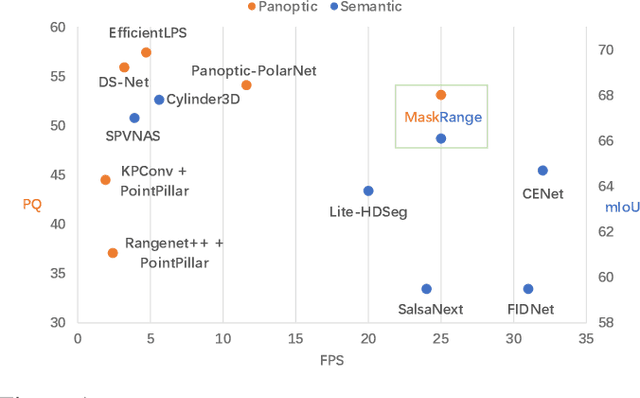
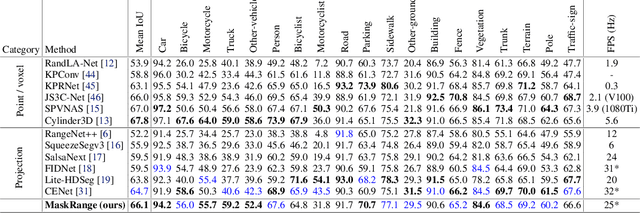
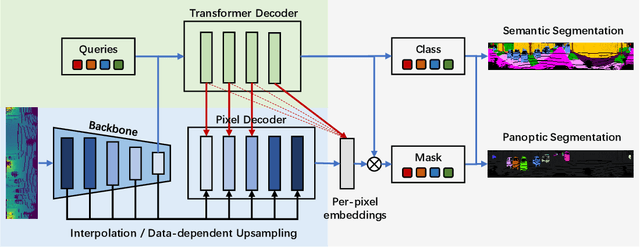
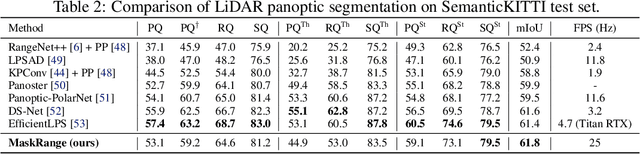
Range-view based LiDAR segmentation methods are attractive for practical applications due to their direct inheritance from efficient 2D CNN architectures. In literature, most range-view based methods follow the per-pixel classification paradigm. Recently, in the image segmentation domain, another paradigm formulates segmentation as a mask-classification problem and has achieved remarkable performance. This raises an interesting question: can the mask-classification paradigm benefit the range-view based LiDAR segmentation and achieve better performance than the counterpart per-pixel paradigm? To answer this question, we propose a unified mask-classification model, MaskRange, for the range-view based LiDAR semantic and panoptic segmentation. Along with the new paradigm, we also propose a novel data augmentation method to deal with overfitting, context-reliance, and class-imbalance problems. Extensive experiments are conducted on the SemanticKITTI benchmark. Among all published range-view based methods, our MaskRange achieves state-of-the-art performance with $66.10$ mIoU on semantic segmentation and promising results with $53.10$ PQ on panoptic segmentation with high efficiency. Our code will be released.
JPerceiver: Joint Perception Network for Depth, Pose and Layout Estimation in Driving Scenes
Jul 16, 2022
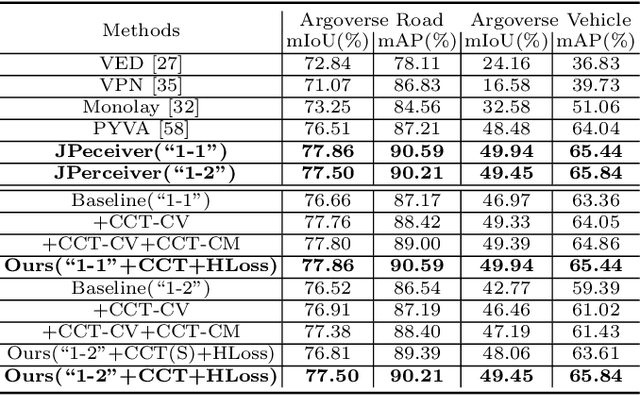
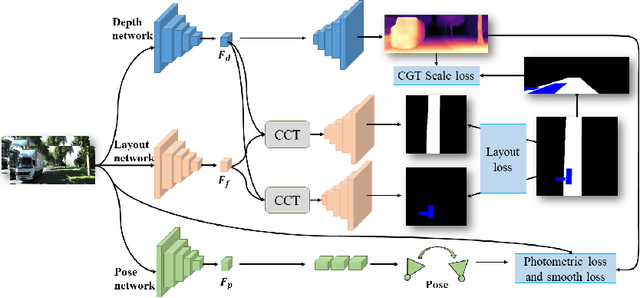
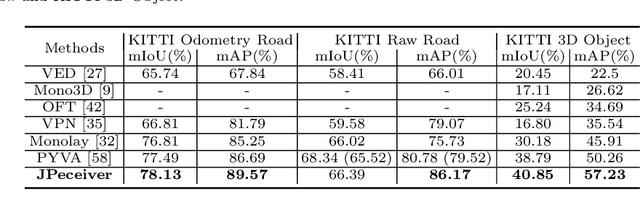
Depth estimation, visual odometry (VO), and bird's-eye-view (BEV) scene layout estimation present three critical tasks for driving scene perception, which is fundamental for motion planning and navigation in autonomous driving. Though they are complementary to each other, prior works usually focus on each individual task and rarely deal with all three tasks together. A naive way is to accomplish them independently in a sequential or parallel manner, but there are many drawbacks, i.e., 1) the depth and VO results suffer from the inherent scale ambiguity issue; 2) the BEV layout is directly predicted from the front-view image without using any depth-related information, although the depth map contains useful geometry clues for inferring scene layouts. In this paper, we address these issues by proposing a novel joint perception framework named JPerceiver, which can simultaneously estimate scale-aware depth and VO as well as BEV layout from a monocular video sequence. It exploits the cross-view geometric transformation (CGT) to propagate the absolute scale from the road layout to depth and VO based on a carefully-designed scale loss. Meanwhile, a cross-view and cross-modal transfer (CCT) module is devised to leverage the depth clues for reasoning road and vehicle layout through an attention mechanism. JPerceiver can be trained in an end-to-end multi-task learning way, where the CGT scale loss and CCT module promote inter-task knowledge transfer to benefit feature learning of each task. Experiments on Argoverse, Nuscenes and KITTI show the superiority of JPerceiver over existing methods on all the above three tasks in terms of accuracy, model size, and inference speed. The code and models are available at~\href{https://github.com/sunnyHelen/JPerceiver}{https://github.com/sunnyHelen/JPerceiver}.
Transformer-Based Deep Image Matching for Generalizable Person Re-identification
May 30, 2021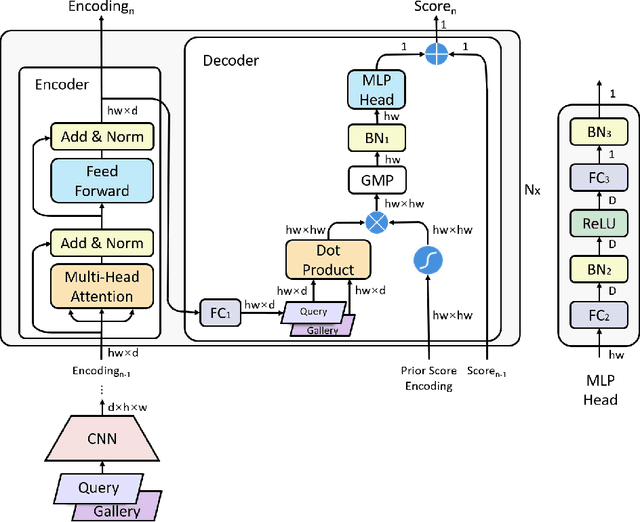
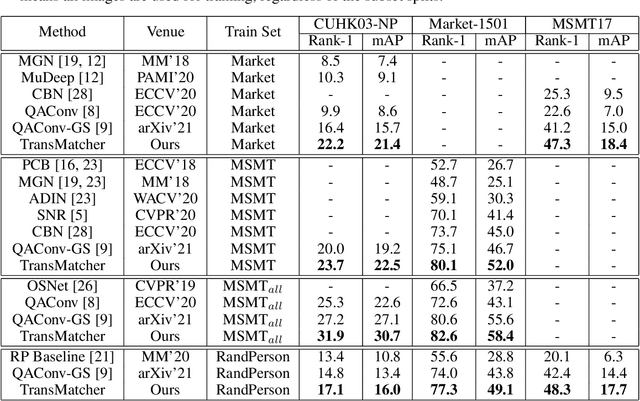
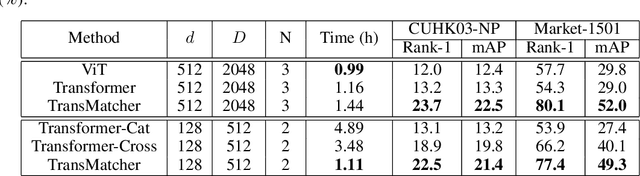
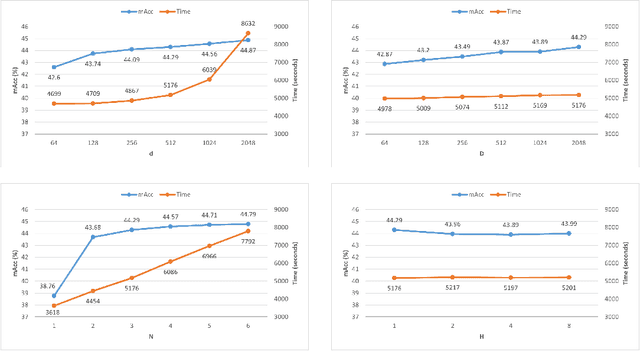
Transformers have recently gained increasing attention in computer vision. However, existing studies mostly use Transformers for feature representation learning, e.g. for image classification and dense predictions. In this work, we further investigate the possibility of applying Transformers for image matching and metric learning given pairs of images. We find that the Vision Transformer (ViT) and the vanilla Transformer with decoders are not adequate for image matching due to their lack of image-to-image attention. Thus, we further design two naive solutions, i.e. query-gallery concatenation in ViT, and query-gallery cross-attention in the vanilla Transformer. The latter improves the performance, but it is still limited. This implies that the attention mechanism in Transformers is primarily designed for global feature aggregation, which is not naturally suitable for image matching. Accordingly, we propose a new simplified decoder, which drops the full attention implementation with the softmax weighting, keeping only the query-key similarity computation. Additionally, global max pooling and a multilayer perceptron (MLP) head are applied to decode the matching result. This way, the simplified decoder is computationally more efficient, while at the same time more effective for image matching. The proposed method, called TransMatcher, achieves state-of-the-art performance in generalizable person re-identification, with up to 6.1% and 5.7% performance gains in Rank-1 and mAP, respectively, on several popular datasets. The source code of this study will be made publicly available.
A Unified Meta-Learning Framework for Dynamic Transfer Learning
Jul 05, 2022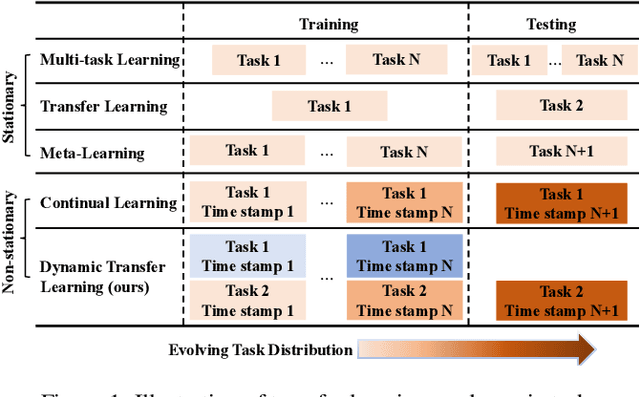

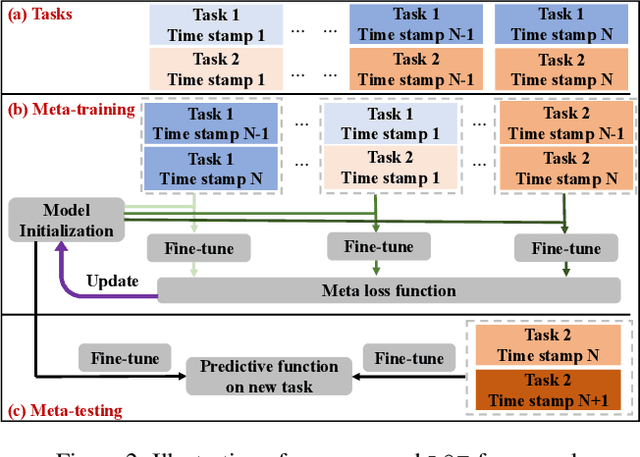
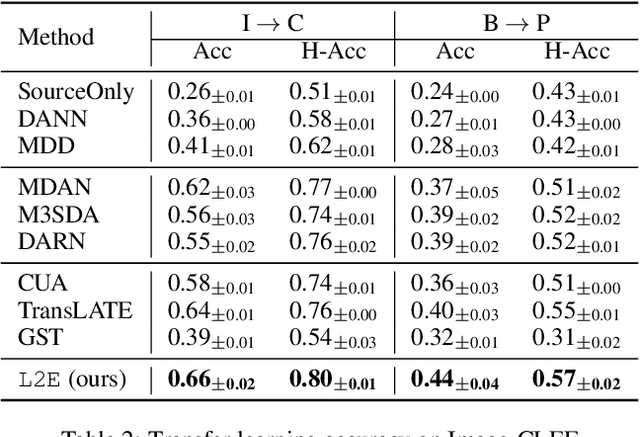
Transfer learning refers to the transfer of knowledge or information from a relevant source task to a target task. However, most existing works assume both tasks are sampled from a stationary task distribution, thereby leading to the sub-optimal performance for dynamic tasks drawn from a non-stationary task distribution in real scenarios. To bridge this gap, in this paper, we study a more realistic and challenging transfer learning setting with dynamic tasks, i.e., source and target tasks are continuously evolving over time. We theoretically show that the expected error on the dynamic target task can be tightly bounded in terms of source knowledge and consecutive distribution discrepancy across tasks. This result motivates us to propose a generic meta-learning framework L2E for modeling the knowledge transferability on dynamic tasks. It is centered around a task-guided meta-learning problem with a group of meta-pairs of tasks, based on which we are able to learn the prior model initialization for fast adaptation on the newest target task. L2E enjoys the following properties: (1) effective knowledge transferability across dynamic tasks; (2) fast adaptation to the new target task; (3) mitigation of catastrophic forgetting on historical target tasks; and (4) flexibility in incorporating any existing static transfer learning algorithms. Extensive experiments on various image data sets demonstrate the effectiveness of the proposed L2E framework.
ReplaceBlock: An improved regularization method based on background information
Mar 30, 2022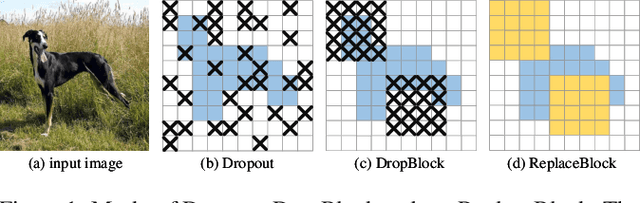
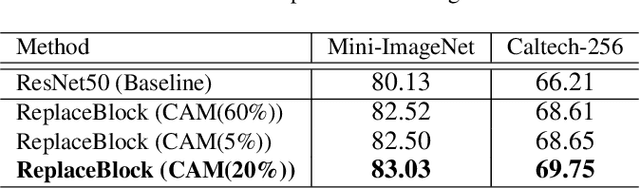
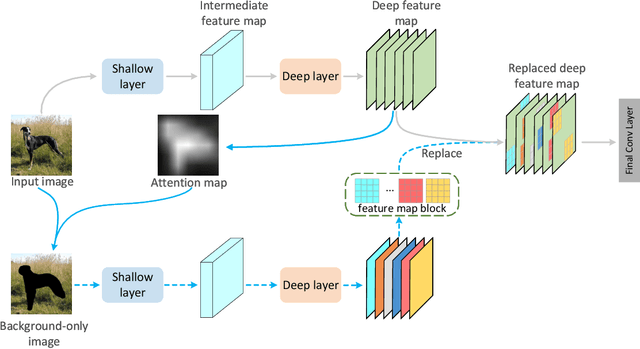
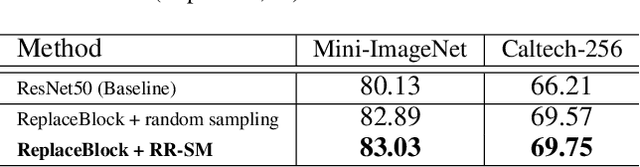
Attention mechanism, being frequently used to train networks for better feature representations, can effectively disentangle the target object from irrelevant objects in the background. Given an arbitrary image, we find that the background's irrelevant objects are most likely to occlude/block the target object. We propose, based on this finding, a ReplaceBlock to simulate the situations when the target object is partially occluded by the objects that are deemed as background. Specifically, ReplaceBlock erases the target object in the image, and then generates a feature map with only irrelevant objects and background by the model. Finally, some regions in the background feature map are used to replace some regions of the target object in the original image feature map. In this way, ReplaceBlock can effectively simulate the feature map of the occluded image. The experimental results show that ReplaceBlock works better than DropBlock in regularizing convolutional networks.
EDPN: Enhanced Deep Pyramid Network for Blurry Image Restoration
May 11, 2021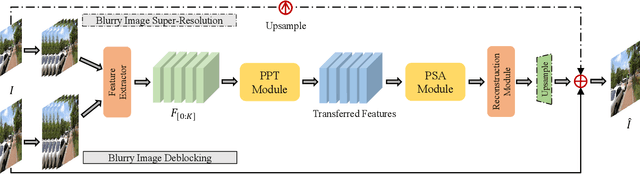
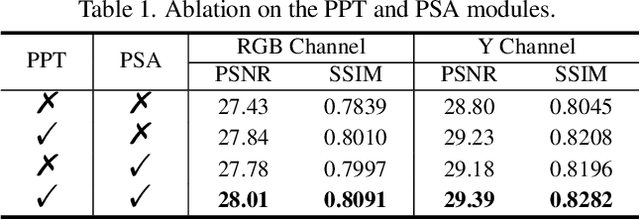
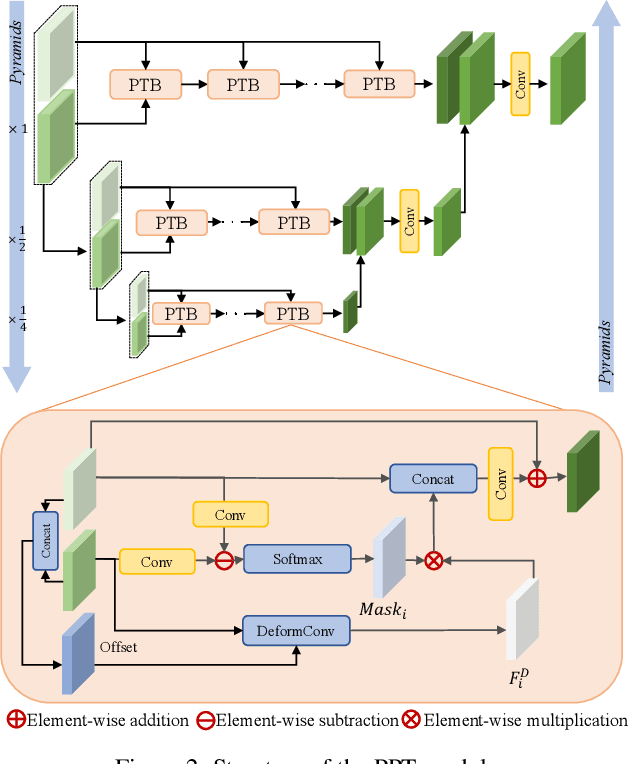
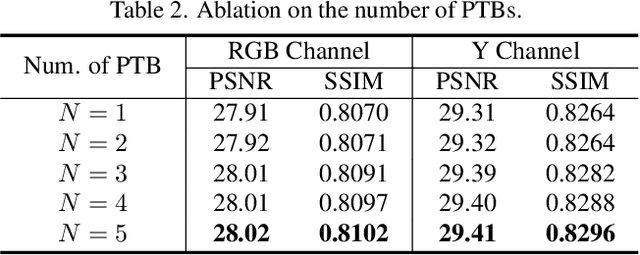
Image deblurring has seen a great improvement with the development of deep neural networks. In practice, however, blurry images often suffer from additional degradations such as downscaling and compression. To address these challenges, we propose an Enhanced Deep Pyramid Network (EDPN) for blurry image restoration from multiple degradations, by fully exploiting the self- and cross-scale similarities in the degraded image.Specifically, we design two pyramid-based modules, i.e., the pyramid progressive transfer (PPT) module and the pyramid self-attention (PSA) module, as the main components of the proposed network. By taking several replicated blurry images as inputs, the PPT module transfers both self- and cross-scale similarity information from the same degraded image in a progressive manner. Then, the PSA module fuses the above transferred features for subsequent restoration using self- and spatial-attention mechanisms. Experimental results demonstrate that our method significantly outperforms existing solutions for blurry image super-resolution and blurry image deblocking. In the NTIRE 2021 Image Deblurring Challenge, EDPN achieves the best PSNR/SSIM/LPIPS scores in Track 1 (Low Resolution) and the best SSIM/LPIPS scores in Track 2 (JPEG Artifacts).