 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Contrastive Hashing for Cross-Modal Retrieval in Remote Sensing
Apr 19, 2022
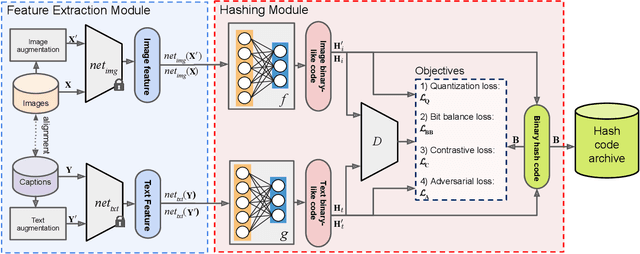
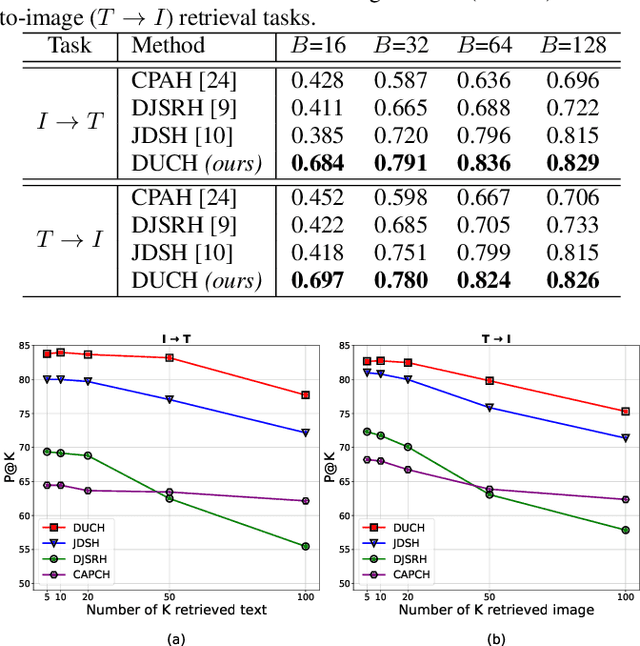

The development of cross-modal retrieval systems that can search and retrieve semantically relevant data across different modalities based on a query in any modality has attracted great attention in remote sensing (RS). In this paper, we focus our attention on cross-modal text-image retrieval, where queries from one modality (e.g., text) can be matched to archive entries from another (e.g., image). Most of the existing cross-modal text-image retrieval systems in RS require a high number of labeled training samples and also do not allow fast and memory-efficient retrieval. These issues limit the applicability of the existing cross-modal retrieval systems for large-scale applications in RS. To address this problem, in this paper we introduce a novel unsupervised cross-modal contrastive hashing (DUCH) method for text-image retrieval in RS. To this end, the proposed DUCH is made up of two main modules: 1) feature extraction module, which extracts deep representations of two modalities; 2) hashing module that learns to generate cross-modal binary hash codes from the extracted representations. We introduce a novel multi-objective loss function including: i) contrastive objectives that enable similarity preservation in intra- and inter-modal similarities; ii) an adversarial objective that is enforced across two modalities for cross-modal representation consistency; and iii) binarization objectives for generating hash codes. Experimental results show that the proposed DUCH outperforms state-of-the-art methods. Our code is publicly available at https://git.tu-berlin.de/rsim/duch.
Self-Supervision on Images and Text Reduces Reliance on Visual Shortcut Features
Jun 14, 2022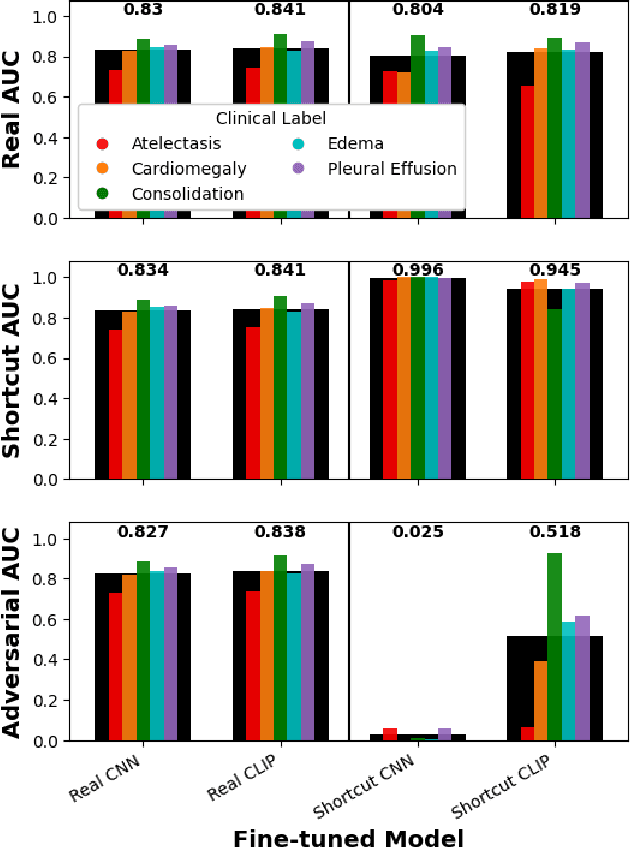
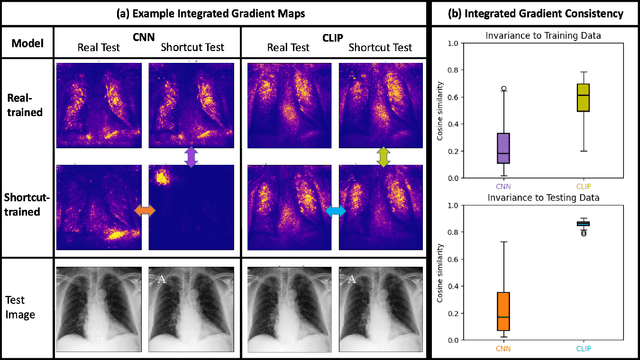
Deep learning models trained in a fully supervised manner have been shown to rely on so-called "shortcut" features. Shortcut features are inputs that are associated with the outcome of interest in the training data, but are either no longer associated or not present in testing or deployment settings. Here we provide experiments that show recent self-supervised models trained on images and text provide more robust image representations and reduce the model's reliance on visual shortcut features on a realistic medical imaging example. Additionally, we find that these self-supervised models "forget" shortcut features more quickly than fully supervised ones when fine-tuned on labeled data. Though not a complete solution, our experiments provide compelling evidence that self-supervised models trained on images and text provide some resilience to visual shortcut features.
Progressive Class-based Expansion Learning For Image Classification
Jun 28, 2021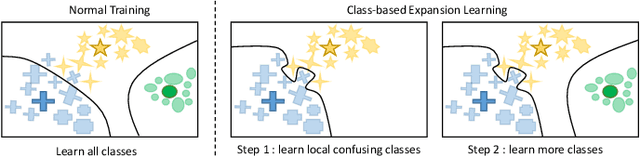
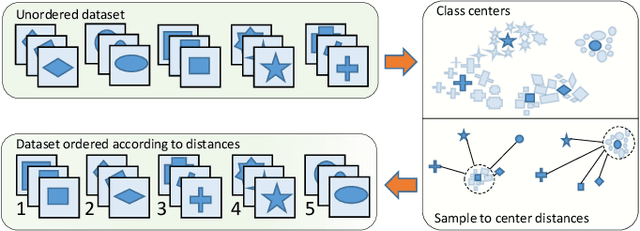
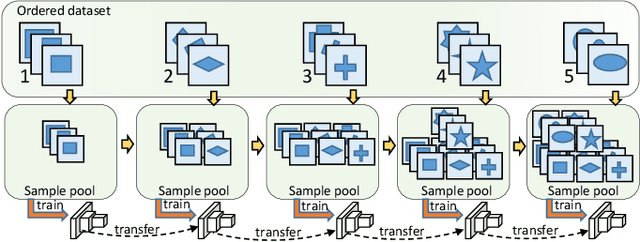
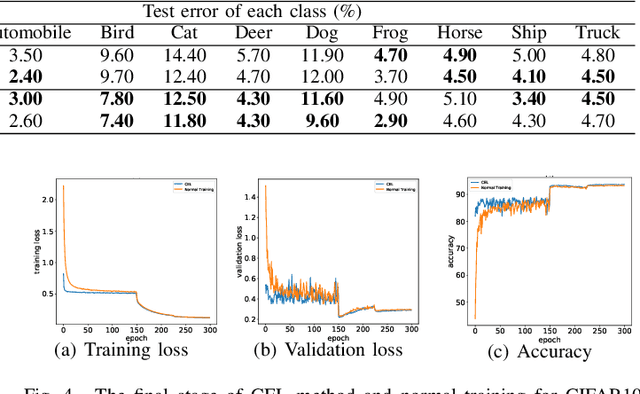
In this paper, we propose a novel image process scheme called class-based expansion learning for image classification, which aims at improving the supervision-stimulation frequency for the samples of the confusing classes. Class-based expansion learning takes a bottom-up growing strategy in a class-based expansion optimization fashion, which pays more attention to the quality of learning the fine-grained classification boundaries for the preferentially selected classes. Besides, we develop a class confusion criterion to select the confusing class preferentially for training. In this way, the classification boundaries of the confusing classes are frequently stimulated, resulting in a fine-grained form. Experimental results demonstrate the effectiveness of the proposed scheme on several benchmarks.
Towards Racially Unbiased Skin Tone Estimation via Scene Disambiguation
May 08, 2022Virtual facial avatars will play an increasingly important role in immersive communication, games and the metaverse, and it is therefore critical that they be inclusive. This requires accurate recovery of the appearance, represented by albedo, regardless of age, sex, or ethnicity. While significant progress has been made on estimating 3D facial geometry, albedo estimation has received less attention. The task is fundamentally ambiguous because the observed color is a function of albedo and lighting, both of which are unknown. We find that current methods are biased towards light skin tones due to (1) strongly biased priors that prefer lighter pigmentation and (2) algorithmic solutions that disregard the light/albedo ambiguity. To address this, we propose a new evaluation dataset (FAIR) and an algorithm (TRUST) to improve albedo estimation and, hence, fairness. Specifically, we create the first facial albedo evaluation benchmark where subjects are balanced in terms of skin color, and measure accuracy using the Individual Typology Angle (ITA) metric. We then address the light/albedo ambiguity by building on a key observation: the image of the full scene -- as opposed to a cropped image of the face -- contains important information about lighting that can be used for disambiguation. TRUST regresses facial albedo by conditioning both on the face region and a global illumination signal obtained from the scene image. Our experimental results show significant improvement compared to state-of-the-art methods on albedo estimation, both in terms of accuracy and fairness. The evaluation benchmark and code will be made available for research purposes at https://trust.is.tue.mpg.de.
Cardiomegaly Detection using Deep Convolutional Neural Network with U-Net
May 23, 2022
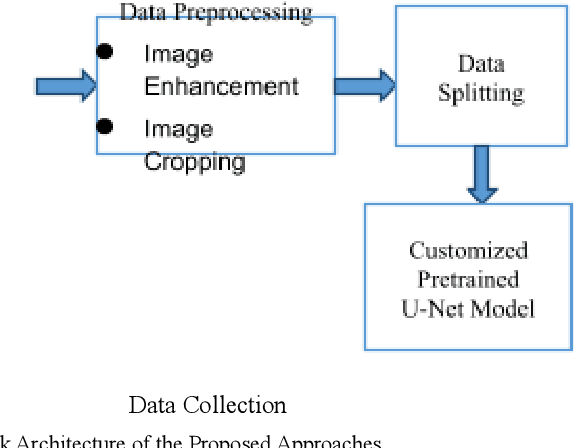
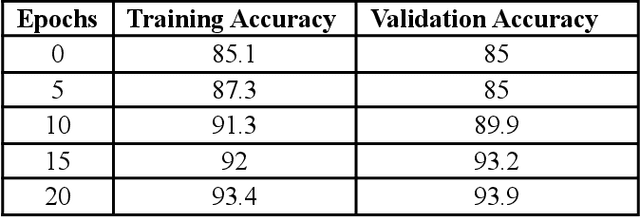
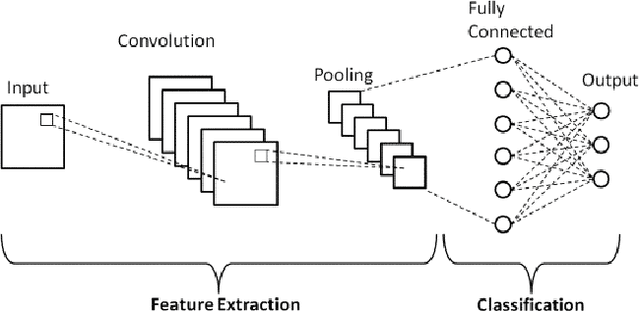
Cardiomegaly is indeed a medical disease in which the heart is enlarged. Cardiomegaly is better to handle if caught early, so early detection is critical. The chest X-ray, being one of the most often used radiography examinations, has been used to detect and visualize abnormalities of human organs for decades. X-ray is also a significant medical diagnosis tool for cardiomegaly. Even for domain experts, distinguishing the many types of diseases from the X-ray is a difficult and time-consuming task. Deep learning models are also most effective when used on huge data sets, yet due to privacy concerns, large datasets are rarely available inside the medical industry. A Deep learning-based customized retrained U-Net model for detecting Cardiomegaly disease is presented in this research. In the training phase, chest X-ray images from the "ChestX-ray8" open source real dataset are used. To reduce computing time, this model performs data preprocessing, picture improvement, image compression, and classification before moving on to the training step. The work used a chest x-ray image dataset to simulate and produced a diagnostic accuracy of 94%, a sensitivity of 96.2 percent, and a specificity of 92.5 percent, which beats prior pre-trained model findings for identifying Cardiomegaly disease.
Uformer: A General U-Shaped Transformer for Image Restoration
Jun 06, 2021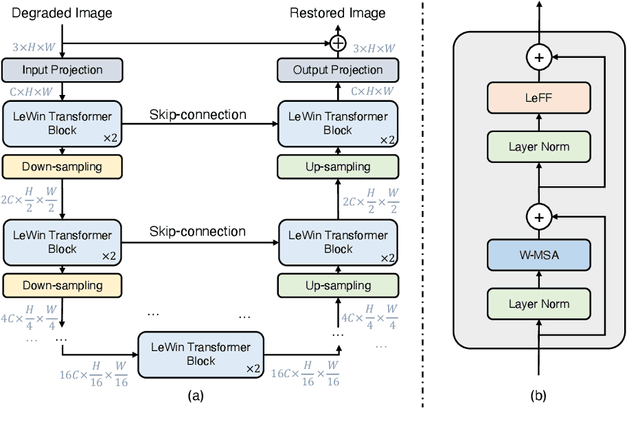
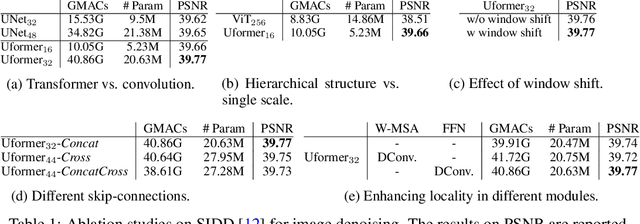
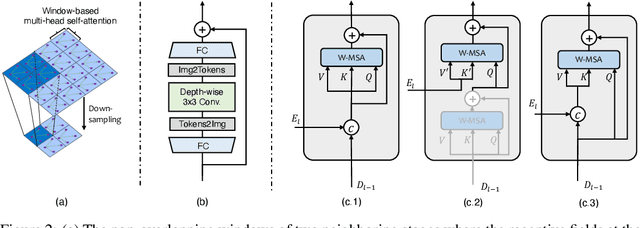
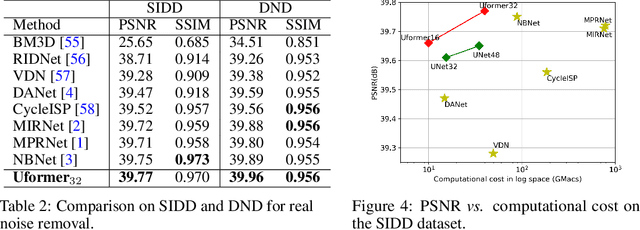
In this paper, we present Uformer, an effective and efficient Transformer-based architecture, in which we build a hierarchical encoder-decoder network using the Transformer block for image restoration. Uformer has two core designs to make it suitable for this task. The first key element is a local-enhanced window Transformer block, where we use non-overlapping window-based self-attention to reduce the computational requirement and employ the depth-wise convolution in the feed-forward network to further improve its potential for capturing local context. The second key element is that we explore three skip-connection schemes to effectively deliver information from the encoder to the decoder. Powered by these two designs, Uformer enjoys a high capability for capturing useful dependencies for image restoration. Extensive experiments on several image restoration tasks demonstrate the superiority of Uformer, including image denoising, deraining, deblurring and demoireing. We expect that our work will encourage further research to explore Transformer-based architectures for low-level vision tasks. The code and models will be available at https://github.com/ZhendongWang6/Uformer.
Copy-Move Image Forgery Detection Based on Evolving Circular Domains Coverage
Sep 09, 2021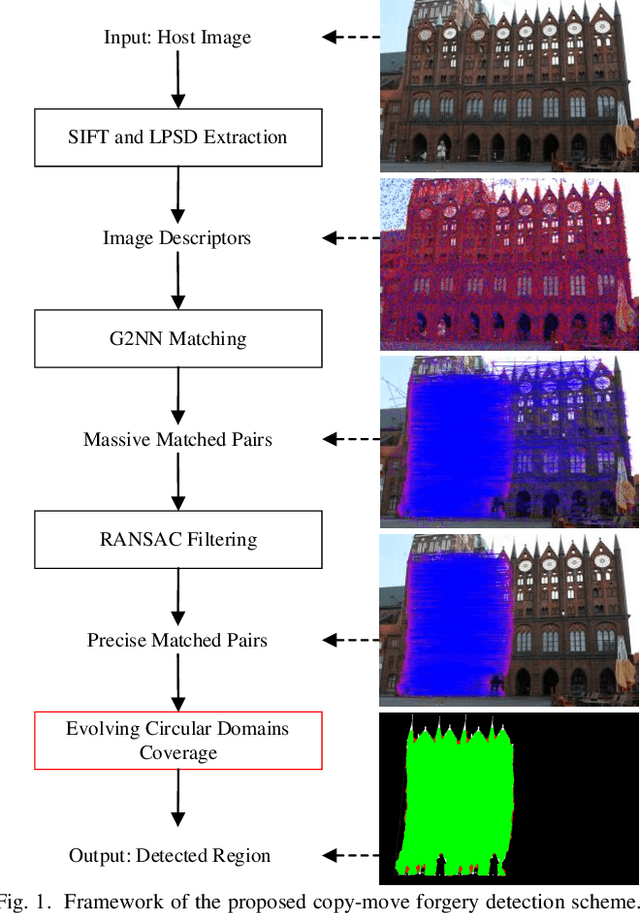
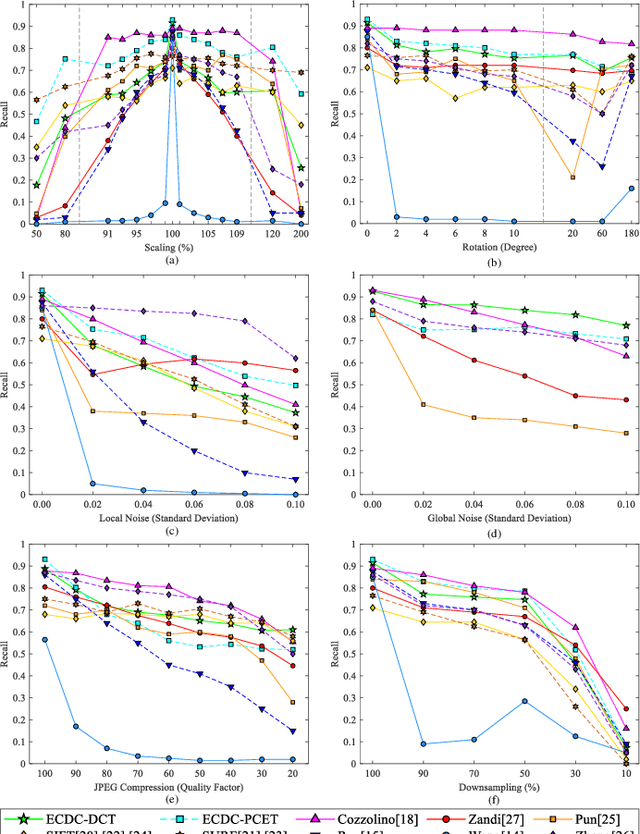
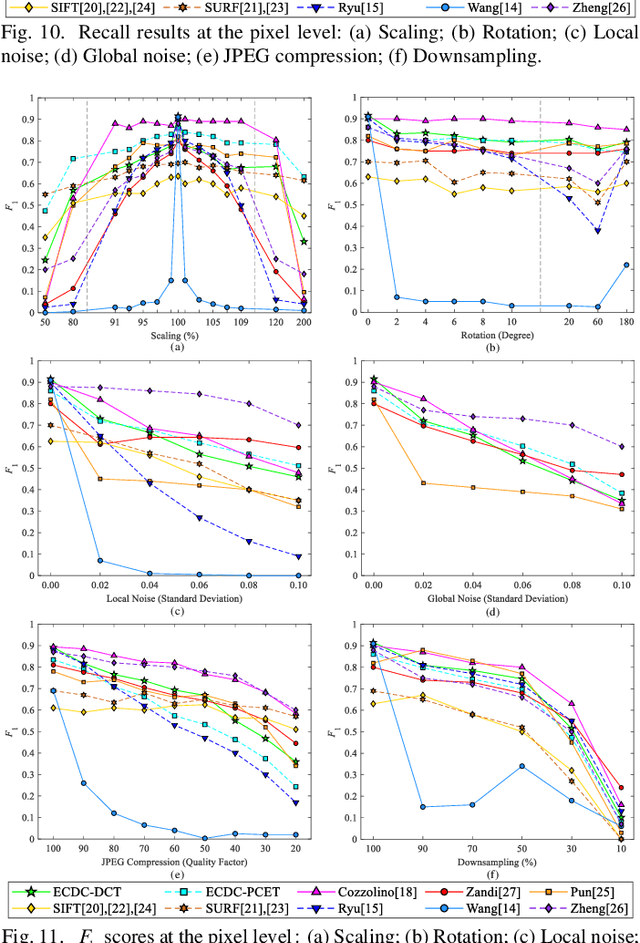

The aim of this paper is to improve the accuracy of copy-move forgery detection (CMFD) in image forensics by proposing a novel scheme. The proposed scheme integrates both block-based and keypoint-based forgery detection methods. Firstly, speed-up robust feature (SURF) descriptor in log-polar space and scale invariant feature transform (SIFT) descriptor are extracted from an entire forged image. Secondly, generalized 2 nearest neighbor (g2NN) is employed to get massive matched pairs. Then, random sample consensus (RANSAC) algorithm is employed to filter out mismatched pairs, thus allowing rough localization of the counterfeit areas. To present more accurately these forgery areas more accurately, we propose an efficient and accurate algorithm, evolving circular domains coverage (ECDC), to cover present them. This algorithm aims to find satisfactory threshold areas by extracting block features from jointly evolving circular domains, which are centered on the matched pairs. Finally, morphological operation is applied to refine the detected forgery areas. The experimental results indicate that the proposed CMFD scheme can achieve better detection performance under various attacks compared with other state-of-the-art CMFD schemes.
Multi-granularity Association Learning Framework for on-the-fly Fine-Grained Sketch-based Image Retrieval
Jan 13, 2022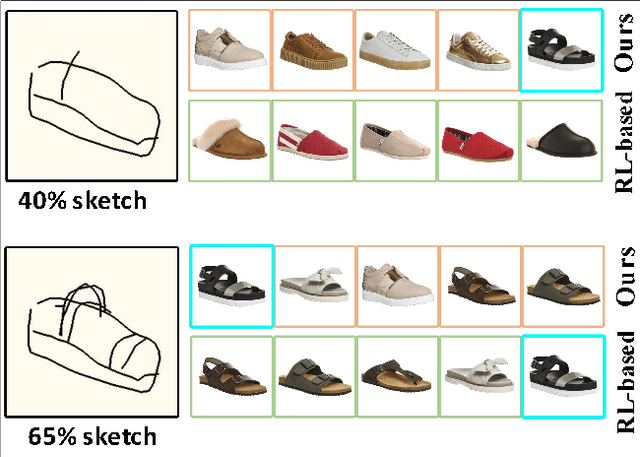
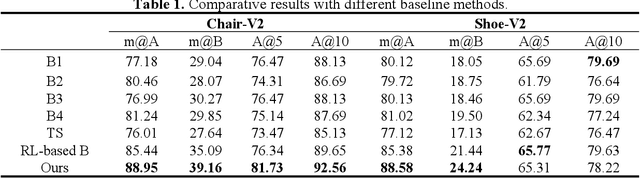
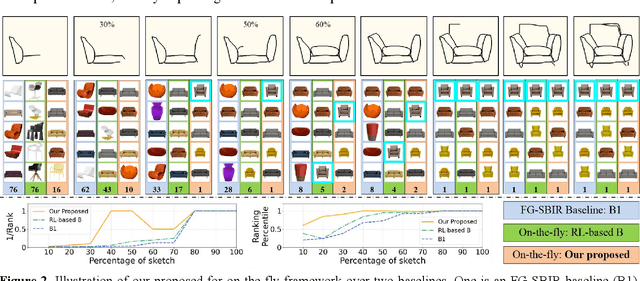
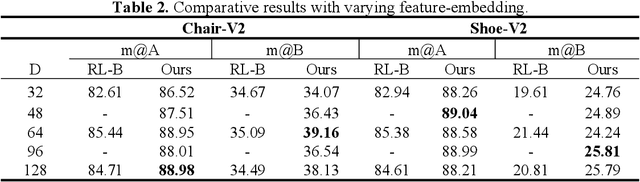
Fine-grained sketch-based image retrieval (FG-SBIR) addresses the problem of retrieving a particular photo in a given query sketch. However, its widespread applicability is limited by the fact that it is difficult to draw a complete sketch for most people, and the drawing process often takes time. In this study, we aim to retrieve the target photo with the least number of strokes possible (incomplete sketch), named on-the-fly FG-SBIR (Bhunia et al. 2020), which starts retrieving at each stroke as soon as the drawing begins. We consider that there is a significant correlation among these incomplete sketches in the sketch drawing episode of each photo. To learn more efficient joint embedding space shared between the photo and its incomplete sketches, we propose a multi-granularity association learning framework that further optimizes the embedding space of all incomplete sketches. Specifically, based on the integrity of the sketch, we can divide a complete sketch episode into several stages, each of which corresponds to a simple linear mapping layer. Moreover, our framework guides the vector space representation of the current sketch to approximate that of its later sketches to realize the retrieval performance of the sketch with fewer strokes to approach that of the sketch with more strokes. In the experiments, we proposed more realistic challenges, and our method achieved superior early retrieval efficiency over the state-of-the-art methods and alternative baselines on two publicly available fine-grained sketch retrieval datasets.
AnyFace: Free-style Text-to-Face Synthesis and Manipulation
Mar 29, 2022
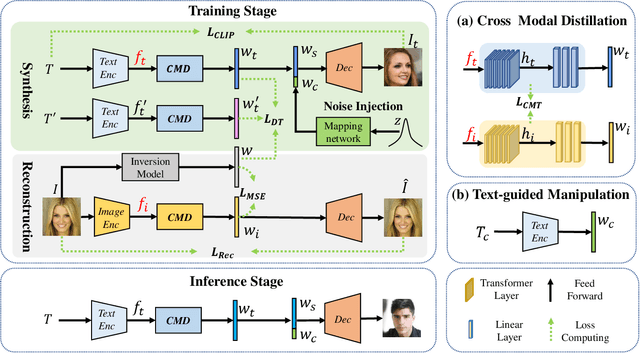
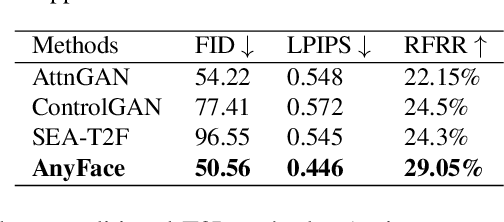
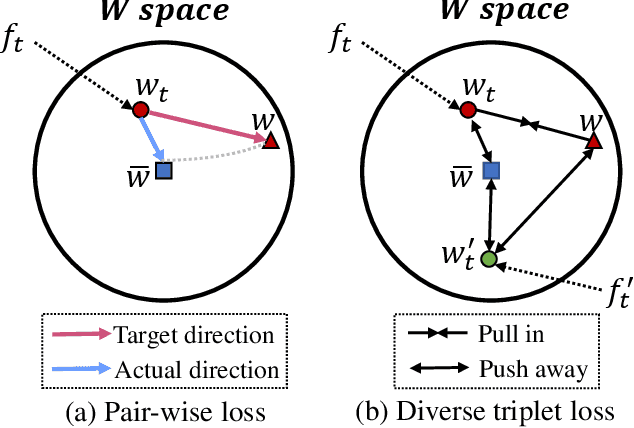
Existing text-to-image synthesis methods generally are only applicable to words in the training dataset. However, human faces are so variable to be described with limited words. So this paper proposes the first free-style text-to-face method namely AnyFace enabling much wider open world applications such as metaverse, social media, cosmetics, forensics, etc. AnyFace has a novel two-stream framework for face image synthesis and manipulation given arbitrary descriptions of the human face. Specifically, one stream performs text-to-face generation and the other conducts face image reconstruction. Facial text and image features are extracted using the CLIP (Contrastive Language-Image Pre-training) encoders. And a collaborative Cross Modal Distillation (CMD) module is designed to align the linguistic and visual features across these two streams. Furthermore, a Diverse Triplet Loss (DT loss) is developed to model fine-grained features and improve facial diversity. Extensive experiments on Multi-modal CelebA-HQ and CelebAText-HQ demonstrate significant advantages of AnyFace over state-of-the-art methods. AnyFace can achieve high-quality, high-resolution, and high-diversity face synthesis and manipulation results without any constraints on the number and content of input captions.
Interpretable Mammographic Image Classification using Cased-Based Reasoning and Deep Learning
Jul 12, 2021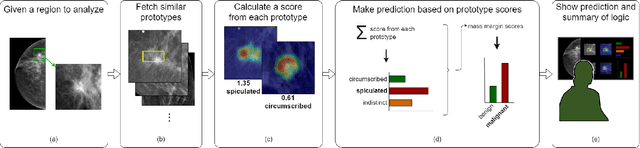
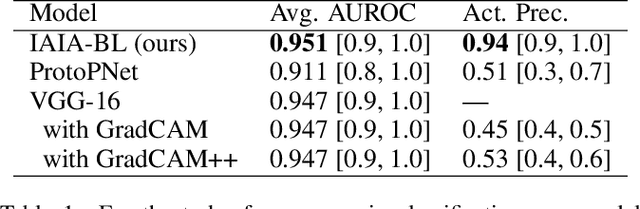
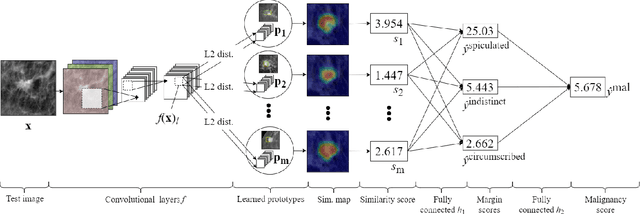
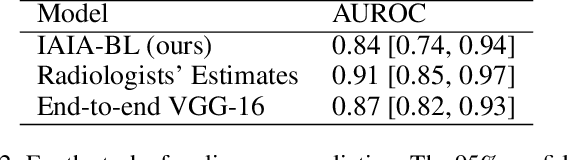
When we deploy machine learning models in high-stakes medical settings, we must ensure these models make accurate predictions that are consistent with known medical science. Inherently interpretable networks address this need by explaining the rationale behind each decision while maintaining equal or higher accuracy compared to black-box models. In this work, we present a novel interpretable neural network algorithm that uses case-based reasoning for mammography. Designed to aid a radiologist in their decisions, our network presents both a prediction of malignancy and an explanation of that prediction using known medical features. In order to yield helpful explanations, the network is designed to mimic the reasoning processes of a radiologist: our network first detects the clinically relevant semantic features of each image by comparing each new image with a learned set of prototypical image parts from the training images, then uses those clinical features to predict malignancy. Compared to other methods, our model detects clinical features (mass margins) with equal or higher accuracy, provides a more detailed explanation of its prediction, and is better able to differentiate the classification-relevant parts of the image.