 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Quantification of Percent Emphysema on CT via Domain Attention: the Multi-Ethnic Study of Atherosclerosis (MESA) Lung Study
Mar 06, 2024
Robust quantification of pulmonary emphysema on computed tomography (CT) remains challenging for large-scale research studies that involve scans from different scanner types and for translation to clinical scans. Existing studies have explored several directions to tackle this challenge, including density correction, noise filtering, regression, hidden Markov measure field (HMMF) model-based segmentation, and volume-adjusted lung density. Despite some promising results, previous studies either required a tedious workflow or limited opportunities for downstream emphysema subtyping, limiting efficient adaptation on a large-scale study. To alleviate this dilemma, we developed an end-to-end deep learning framework based on an existing HMMF segmentation framework. We first demonstrate that a regular UNet cannot replicate the existing HMMF results because of the lack of scanner priors. We then design a novel domain attention block to fuse image feature with quantitative scanner priors which significantly improves the results.
Decoupling Degradations with Recurrent Network for Video Restoration in Under-Display Camera
Mar 08, 2024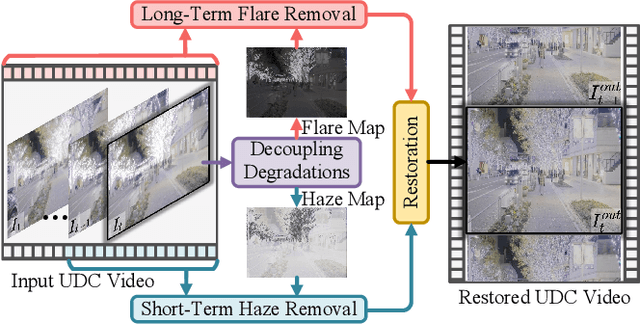
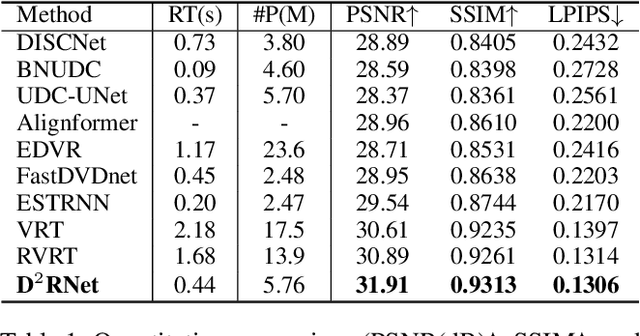
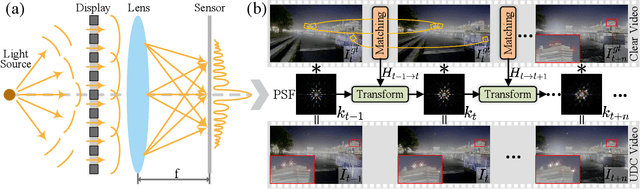

Under-display camera (UDC) systems are the foundation of full-screen display devices in which the lens mounts under the display. The pixel array of light-emitting diodes used for display diffracts and attenuates incident light, causing various degradations as the light intensity changes. Unlike general video restoration which recovers video by treating different degradation factors equally, video restoration for UDC systems is more challenging that concerns removing diverse degradation over time while preserving temporal consistency. In this paper, we introduce a novel video restoration network, called D$^2$RNet, specifically designed for UDC systems. It employs a set of Decoupling Attention Modules (DAM) that effectively separate the various video degradation factors. More specifically, a soft mask generation function is proposed to formulate each frame into flare and haze based on the diffraction arising from incident light of different intensities, followed by the proposed flare and haze removal components that leverage long- and short-term feature learning to handle the respective degradations. Such a design offers an targeted and effective solution to eliminating various types of degradation in UDC systems. We further extend our design into multi-scale to overcome the scale-changing of degradation that often occur in long-range videos. To demonstrate the superiority of D$^2$RNet, we propose a large-scale UDC video benchmark by gathering HDR videos and generating realistically degraded videos using the point spread function measured by a commercial UDC system. Extensive quantitative and qualitative evaluations demonstrate the superiority of D$^2$RNet compared to other state-of-the-art video restoration and UDC image restoration methods. Code is available at https://github.com/ChengxuLiu/DDRNet.git
Deformable One-shot Face Stylization via DINO Semantic Guidance
Mar 04, 2024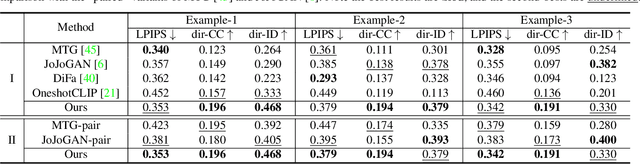


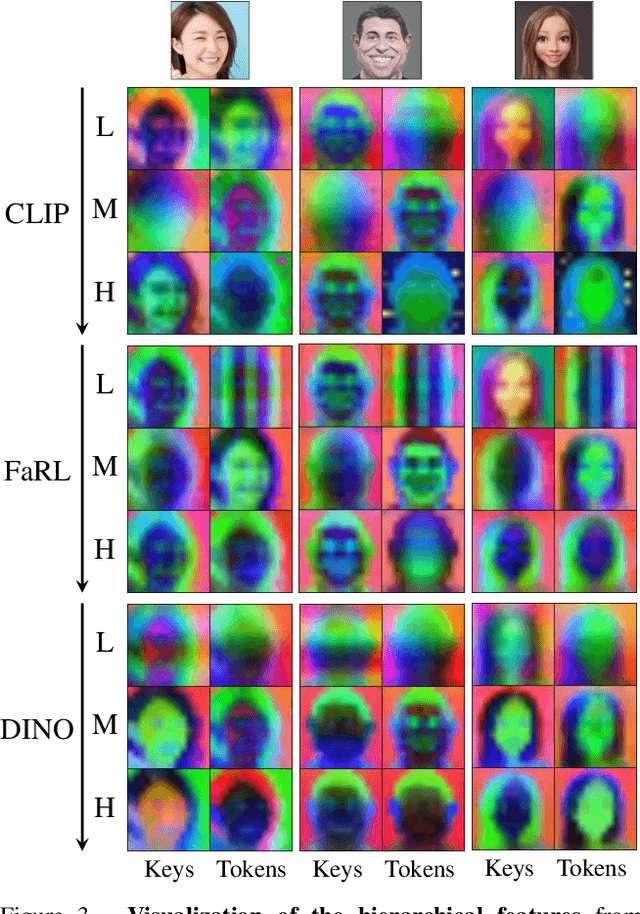
This paper addresses the complex issue of one-shot face stylization, focusing on the simultaneous consideration of appearance and structure, where previous methods have fallen short. We explore deformation-aware face stylization that diverges from traditional single-image style reference, opting for a real-style image pair instead. The cornerstone of our method is the utilization of a self-supervised vision transformer, specifically DINO-ViT, to establish a robust and consistent facial structure representation across both real and style domains. Our stylization process begins by adapting the StyleGAN generator to be deformation-aware through the integration of spatial transformers (STN). We then introduce two innovative constraints for generator fine-tuning under the guidance of DINO semantics: i) a directional deformation loss that regulates directional vectors in DINO space, and ii) a relative structural consistency constraint based on DINO token self-similarities, ensuring diverse generation. Additionally, style-mixing is employed to align the color generation with the reference, minimizing inconsistent correspondences. This framework delivers enhanced deformability for general one-shot face stylization, achieving notable efficiency with a fine-tuning duration of approximately 10 minutes. Extensive qualitative and quantitative comparisons demonstrate our superiority over state-of-the-art one-shot face stylization methods. Code is available at https://github.com/zichongc/DoesFS
Multimodal Learned Sparse Retrieval for Image Suggestion
Feb 12, 2024Learned Sparse Retrieval (LSR) is a group of neural methods designed to encode queries and documents into sparse lexical vectors. These vectors can be efficiently indexed and retrieved using an inverted index. While LSR has shown promise in text retrieval, its potential in multi-modal retrieval remains largely unexplored. Motivated by this, in this work, we explore the application of LSR in the multi-modal domain, i.e., we focus on Multi-Modal Learned Sparse Retrieval (MLSR). We conduct experiments using several MLSR model configurations and evaluate the performance on the image suggestion task. We find that solving the task solely based on the image content is challenging. Enriching the image content with its caption improves the model performance significantly, implying the importance of image captions to provide fine-grained concepts and context information of images. Our approach presents a practical and effective solution for training LSR retrieval models in multi-modal settings.
Text2Pic Swift: Enhancing Long-Text to Image Retrieval for Large-Scale Libraries
Feb 23, 2024Text-to-image retrieval plays a crucial role across various applications, including digital libraries, e-commerce platforms, and multimedia databases, by enabling the search for images using text queries. Despite the advancements in Multimodal Large Language Models (MLLMs), which offer leading-edge performance, their applicability in large-scale, varied, and ambiguous retrieval scenarios is constrained by significant computational demands and the generation of injective embeddings. This paper introduces the Text2Pic Swift framework, tailored for efficient and robust retrieval of images corresponding to extensive textual descriptions in sizable datasets. The framework employs a two-tier approach: the initial Entity-based Ranking (ER) stage addresses the ambiguity inherent in lengthy text queries through a multiple-queries-to-multiple-targets strategy, effectively narrowing down potential candidates for subsequent analysis. Following this, the Summary-based Re-ranking (SR) stage further refines these selections based on concise query summaries. Additionally, we present a novel Decoupling-BEiT-3 encoder, specifically designed to tackle the challenges of ambiguous queries and to facilitate both stages of the retrieval process, thereby significantly improving computational efficiency via vector-based similarity assessments. Our evaluation, conducted on the AToMiC dataset, demonstrates that Text2Pic Swift outperforms current MLLMs by achieving up to an 11.06% increase in Recall@1000, alongside reductions in training and retrieval durations by 68.75% and 99.79%, respectively.
Learning Continuous 3D Words for Text-to-Image Generation
Feb 13, 2024Current controls over diffusion models (e.g., through text or ControlNet) for image generation fall short in recognizing abstract, continuous attributes like illumination direction or non-rigid shape change. In this paper, we present an approach for allowing users of text-to-image models to have fine-grained control of several attributes in an image. We do this by engineering special sets of input tokens that can be transformed in a continuous manner -- we call them Continuous 3D Words. These attributes can, for example, be represented as sliders and applied jointly with text prompts for fine-grained control over image generation. Given only a single mesh and a rendering engine, we show that our approach can be adopted to provide continuous user control over several 3D-aware attributes, including time-of-day illumination, bird wing orientation, dollyzoom effect, and object poses. Our method is capable of conditioning image creation with multiple Continuous 3D Words and text descriptions simultaneously while adding no overhead to the generative process. Project Page: https://ttchengab.github.io/continuous_3d_words
EMIFF: Enhanced Multi-scale Image Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
Feb 23, 2024In autonomous driving, cooperative perception makes use of multi-view cameras from both vehicles and infrastructure, providing a global vantage point with rich semantic context of road conditions beyond a single vehicle viewpoint. Currently, two major challenges persist in vehicle-infrastructure cooperative 3D (VIC3D) object detection: $1)$ inherent pose errors when fusing multi-view images, caused by time asynchrony across cameras; $2)$ information loss in transmission process resulted from limited communication bandwidth. To address these issues, we propose a novel camera-based 3D detection framework for VIC3D task, Enhanced Multi-scale Image Feature Fusion (EMIFF). To fully exploit holistic perspectives from both vehicles and infrastructure, we propose Multi-scale Cross Attention (MCA) and Camera-aware Channel Masking (CCM) modules to enhance infrastructure and vehicle features at scale, spatial, and channel levels to correct the pose error introduced by camera asynchrony. We also introduce a Feature Compression (FC) module with channel and spatial compression blocks for transmission efficiency. Experiments show that EMIFF achieves SOTA on DAIR-V2X-C datasets, significantly outperforming previous early-fusion and late-fusion methods with comparable transmission costs.
Assessing Visually-Continuous Corruption Robustness of Neural Networks Relative to Human Performance
Feb 29, 2024While Neural Networks (NNs) have surpassed human accuracy in image classification on ImageNet, they often lack robustness against image corruption, i.e., corruption robustness. Yet such robustness is seemingly effortless for human perception. In this paper, we propose visually-continuous corruption robustness (VCR) -- an extension of corruption robustness to allow assessing it over the wide and continuous range of changes that correspond to the human perceptive quality (i.e., from the original image to the full distortion of all perceived visual information), along with two novel human-aware metrics for NN evaluation. To compare VCR of NNs with human perception, we conducted extensive experiments on 14 commonly used image corruptions with 7,718 human participants and state-of-the-art robust NN models with different training objectives (e.g., standard, adversarial, corruption robustness), different architectures (e.g., convolution NNs, vision transformers), and different amounts of training data augmentation. Our study showed that: 1) assessing robustness against continuous corruption can reveal insufficient robustness undetected by existing benchmarks; as a result, 2) the gap between NN and human robustness is larger than previously known; and finally, 3) some image corruptions have a similar impact on human perception, offering opportunities for more cost-effective robustness assessments. Our validation set with 14 image corruptions, human robustness data, and the evaluation code is provided as a toolbox and a benchmark.
Analysis of Deep Image Prior and Exploiting Self-Guidance for Image Reconstruction
Feb 08, 2024The ability of deep image prior (DIP) to recover high-quality images from incomplete or corrupted measurements has made it popular in inverse problems in image restoration and medical imaging including magnetic resonance imaging (MRI). However, conventional DIP suffers from severe overfitting and spectral bias effects. In this work, we first provide an analysis of how DIP recovers information from undersampled imaging measurements by analyzing the training dynamics of the underlying networks in the kernel regime for different architectures. This study sheds light on important underlying properties for DIP-based recovery. Current research suggests that incorporating a reference image as network input can enhance DIP's performance in image reconstruction compared to using random inputs. However, obtaining suitable reference images requires supervision, and raises practical difficulties. In an attempt to overcome this obstacle, we further introduce a self-driven reconstruction process that concurrently optimizes both the network weights and the input while eliminating the need for training data. Our method incorporates a novel denoiser regularization term which enables robust and stable joint estimation of both the network input and reconstructed image. We demonstrate that our self-guided method surpasses both the original DIP and modern supervised methods in terms of MR image reconstruction performance and outperforms previous DIP-based schemes for image inpainting.
A Density-Guided Temporal Attention Transformer for Indiscernible Object Counting in Underwater Video
Mar 06, 2024
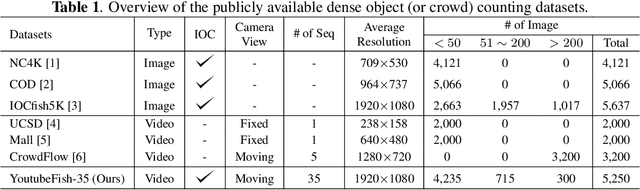
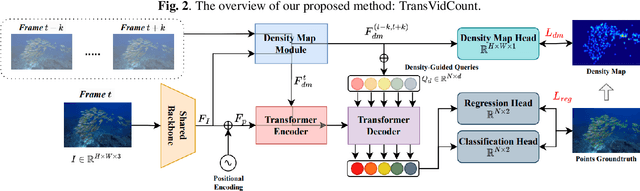

Dense object counting or crowd counting has come a long way thanks to the recent development in the vision community. However, indiscernible object counting, which aims to count the number of targets that are blended with respect to their surroundings, has been a challenge. Image-based object counting datasets have been the mainstream of the current publicly available datasets. Therefore, we propose a large-scale dataset called YoutubeFish-35, which contains a total of 35 sequences of high-definition videos with high frame-per-second and more than 150,000 annotated center points across a selected variety of scenes. For benchmarking purposes, we select three mainstream methods for dense object counting and carefully evaluate them on the newly collected dataset. We propose TransVidCount, a new strong baseline that combines density and regression branches along the temporal domain in a unified framework and can effectively tackle indiscernible object counting with state-of-the-art performance on YoutubeFish-35 dataset.