 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Prior-Induced Information Alignment for Image Matting
Jun 28, 2021


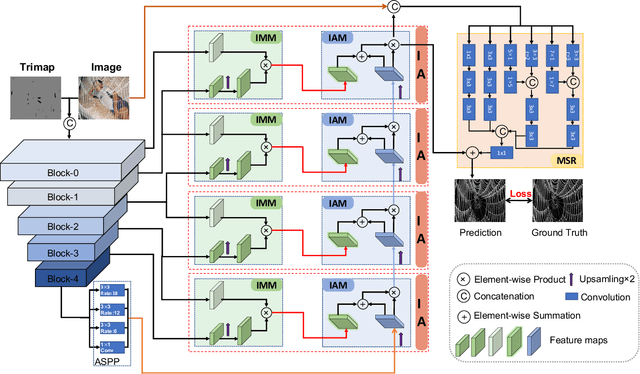
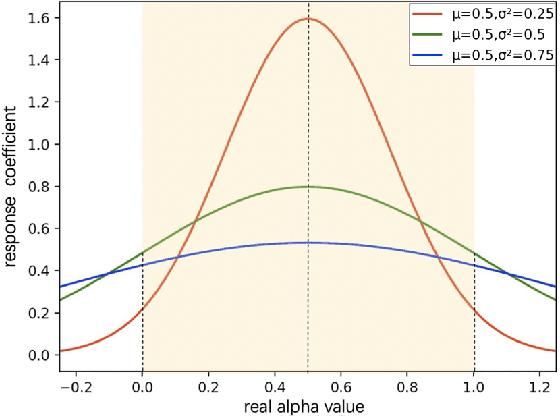
Image matting is an ill-posed problem that aims to estimate the opacity of foreground pixels in an image. However, most existing deep learning-based methods still suffer from the coarse-grained details. In general, these algorithms are incapable of felicitously distinguishing the degree of exploration between deterministic domains (certain FG and BG pixels) and undetermined domains (uncertain in-between pixels), or inevitably lose information in the continuous sampling process, leading to a sub-optimal result. In this paper, we propose a novel network named Prior-Induced Information Alignment Matting Network (PIIAMatting), which can efficiently model the distinction of pixel-wise response maps and the correlation of layer-wise feature maps. It mainly consists of a Dynamic Gaussian Modulation mechanism (DGM) and an Information Alignment strategy (IA). Specifically, the DGM can dynamically acquire a pixel-wise domain response map learned from the prior distribution. The response map can present the relationship between the opacity variation and the convergence process during training. On the other hand, the IA comprises an Information Match Module (IMM) and an Information Aggregation Module (IAM), jointly scheduled to match and aggregate the adjacent layer-wise features adaptively. Besides, we also develop a Multi-Scale Refinement (MSR) module to integrate multi-scale receptive field information at the refinement stage to recover the fluctuating appearance details. Extensive quantitative and qualitative evaluations demonstrate that the proposed PIIAMatting performs favourably against state-of-the-art image matting methods on the Alphamatting.com, Composition-1K and Distinctions-646 dataset.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 07, 2021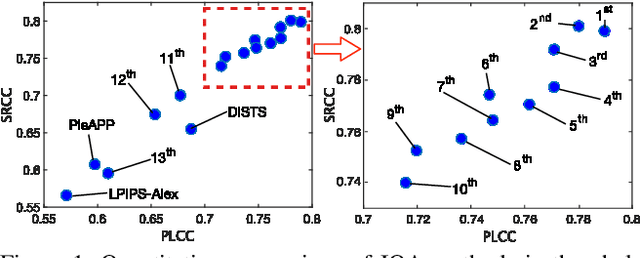
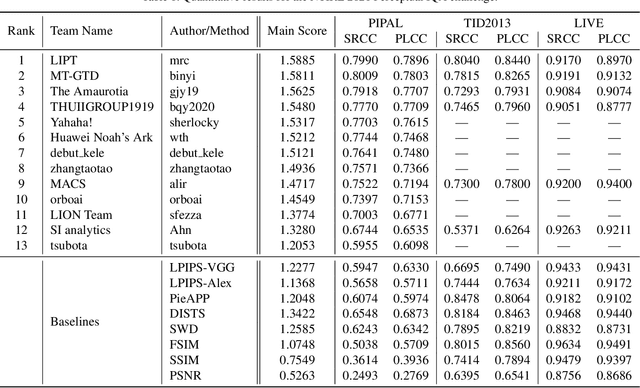

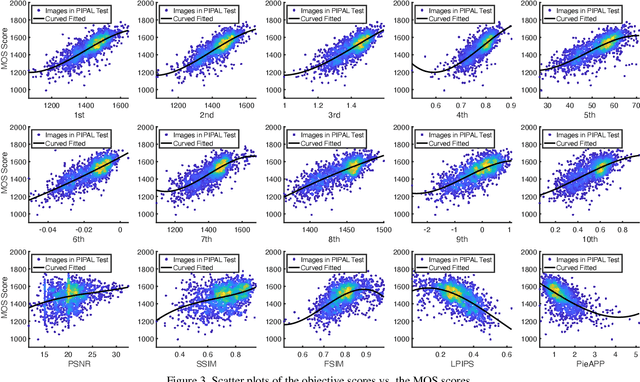
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
Fluorescent wavefront shaping using incoherent iterative phase conjugation
May 15, 2022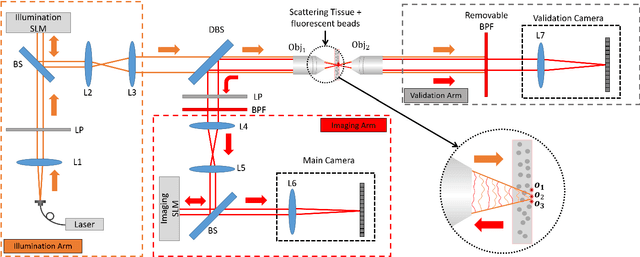
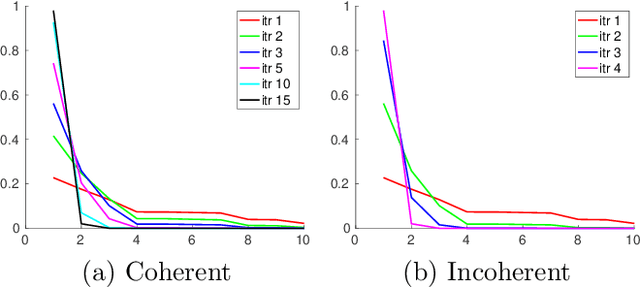


Wavefront shaping correction makes it possible to image fluorescent particles deep inside scattering tissue. This requires determining a correction mask to be placed in both excitation and emission paths. Standard approaches select correction masks by optimizing various image metrics, a process that requires capturing a prohibitively large number of images. To reduce acquisition cost, iterative phase conjugation techniques use the observation that the desired correction mask is an eigenvector of the tissue transmission operator. They then determine this eigenvector via optical implementations of the power iteration method, which require capturing orders of magnitude fewer images. Existing iterative phase conjugation techniques assume a linear model for the transmission of light through tissue, and thus only apply to fully-coherent imaging systems. We extend such techniques to the incoherent case for the first time. The fact that light emitted from different sources sums incoherently violates the linear model and makes linear transmission operators inapplicable. We show that, surprisingly, the non-linearity due to incoherent summation results in an order-of-magnitude acceleration in the convergence of the phase conjugation iteration.
Learned Gradient of a Regularizer for Plug-and-Play Gradient Descent
Apr 29, 2022



The Plug-and-Play (PnP) framework allows integrating advanced image denoising priors into optimization algorithms, to efficiently solve a variety of image restoration tasks. The Plug-and-Play alternating direction method of multipliers (ADMM) and the Regularization by Denoising (RED) algorithms are two examples of such methods that made a breakthrough in image restoration. However, while the former method only applies to proximal algorithms, it has recently been shown that there exists no regularization that explains the RED algorithm when the denoisers lack Jacobian symmetry, which happen to be the case of most practical denoisers. To the best of our knowledge, there exists no method for training a network that directly represents the gradient of a regularizer, which can be directly used in Plug-and-Play gradient-based algorithms. We show that it is possible to train a denoiser along with a network that corresponds to the gradient of its regularizer. We use this gradient of the regularizer in gradient-based optimization methods and obtain better results comparing to other generic Plug-and-Play approaches. We also show that the regularizer can be used as a pre-trained network for unrolled gradient descent. Lastly, we show that the resulting denoiser allows for a quick convergence of the Plug-and-Play ADMM.
Self-Supervised Pre-Training of Swin Transformers for 3D Medical Image Analysis
Nov 29, 2021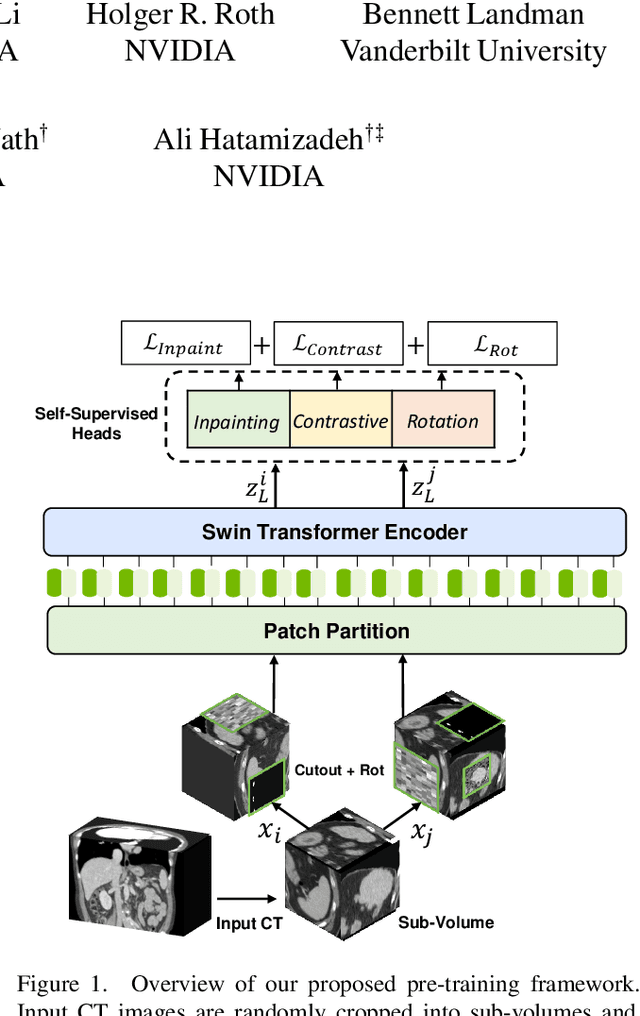
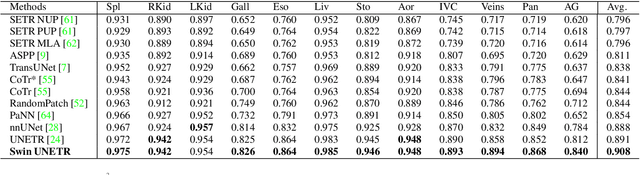
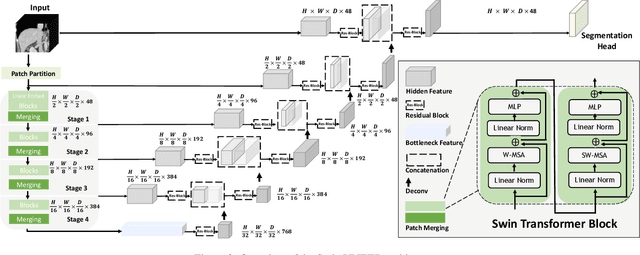
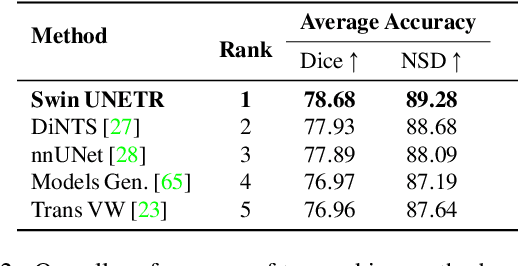
Vision Transformers (ViT)s have shown great performance in self-supervised learning of global and local representations that can be transferred to downstream applications. Inspired by these results, we introduce a novel self-supervised learning framework with tailored proxy tasks for medical image analysis. Specifically, we propose: (i) a new 3D transformer-based model, dubbed Swin UNEt TRansformers (Swin UNETR), with a hierarchical encoder for self-supervised pre-training; (ii) tailored proxy tasks for learning the underlying pattern of human anatomy. We demonstrate successful pre-training of the proposed model on 5,050 publicly available computed tomography (CT) images from various body organs. The effectiveness of our approach is validated by fine-tuning the pre-trained models on the Beyond the Cranial Vault (BTCV) Segmentation Challenge with 13 abdominal organs and segmentation tasks from the Medical Segmentation Decathlon (MSD) dataset. Our model is currently the state-of-the-art (i.e. ranked 1st) on the public test leaderboards of both MSD and BTCV datasets. Code: https://monai.io/research/swin-unetr
Efficient Document Image Classification Using Region-Based Graph Neural Network
Jun 25, 2021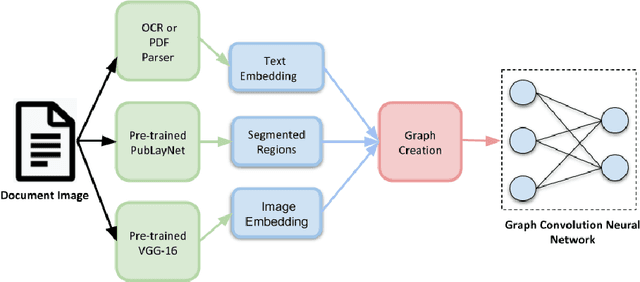
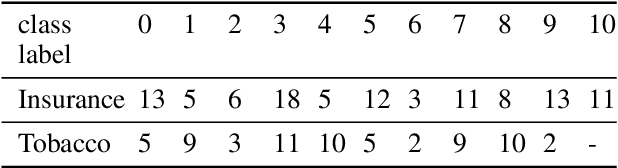

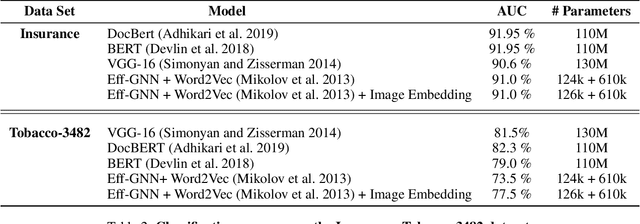
Document image classification remains a popular research area because it can be commercialized in many enterprise applications across different industries. Recent advancements in large pre-trained computer vision and language models and graph neural networks has lent document image classification many tools. However using large pre-trained models usually requires substantial computing resources which could defeat the cost-saving advantages of automatic document image classification. In the paper we propose an efficient document image classification framework that uses graph convolution neural networks and incorporates textual, visual and layout information of the document. We have rigorously benchmarked our proposed algorithm against several state-of-art vision and language models on both publicly available dataset and a real-life insurance document classification dataset. Empirical results on both publicly available and real-world data show that our methods achieve near SOTA performance yet require much less computing resources and time for model training and inference. This results in solutions than offer better cost advantages, especially in scalable deployment for enterprise applications. The results showed that our algorithm can achieve classification performance quite close to SOTA. We also provide comprehensive comparisons of computing resources, model sizes, train and inference time between our proposed methods and baselines. In addition we delineate the cost per image using our method and other baselines.
Cardiomegaly Detection using Deep Convolutional Neural Network with U-Net
May 23, 2022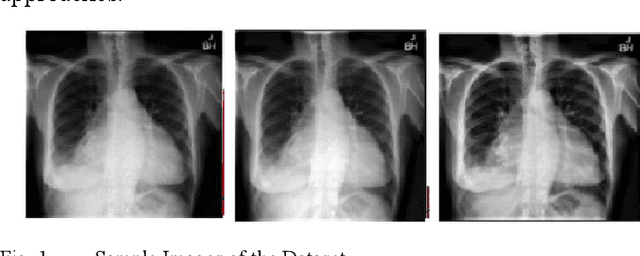
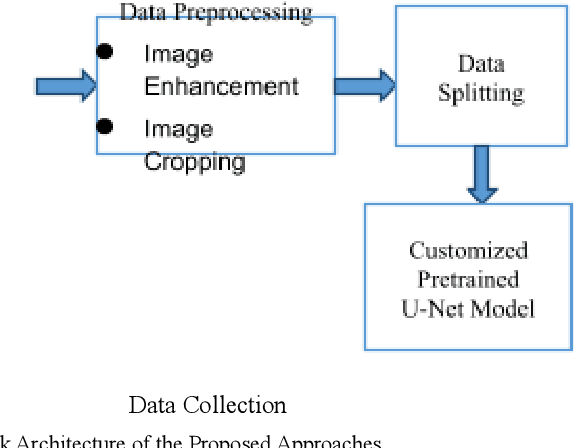
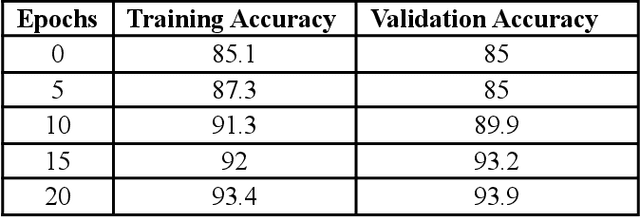
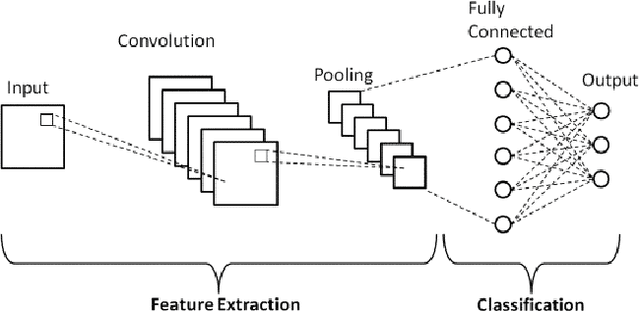
Cardiomegaly is indeed a medical disease in which the heart is enlarged. Cardiomegaly is better to handle if caught early, so early detection is critical. The chest X-ray, being one of the most often used radiography examinations, has been used to detect and visualize abnormalities of human organs for decades. X-ray is also a significant medical diagnosis tool for cardiomegaly. Even for domain experts, distinguishing the many types of diseases from the X-ray is a difficult and time-consuming task. Deep learning models are also most effective when used on huge data sets, yet due to privacy concerns, large datasets are rarely available inside the medical industry. A Deep learning-based customized retrained U-Net model for detecting Cardiomegaly disease is presented in this research. In the training phase, chest X-ray images from the "ChestX-ray8" open source real dataset are used. To reduce computing time, this model performs data preprocessing, picture improvement, image compression, and classification before moving on to the training step. The work used a chest x-ray image dataset to simulate and produced a diagnostic accuracy of 94%, a sensitivity of 96.2 percent, and a specificity of 92.5 percent, which beats prior pre-trained model findings for identifying Cardiomegaly disease.
Instance Segmentation of Unlabeled Modalities via Cyclic Segmentation GAN
Apr 06, 2022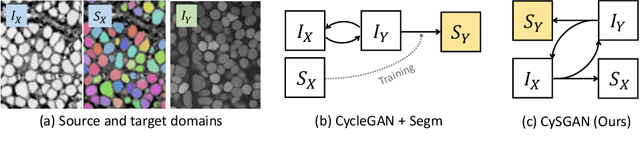

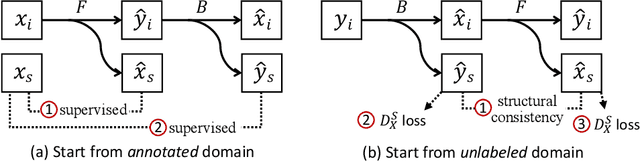
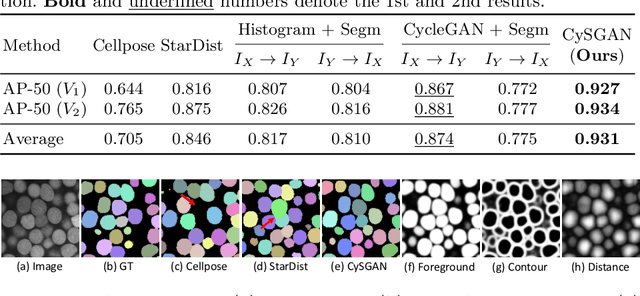
Instance segmentation for unlabeled imaging modalities is a challenging but essential task as collecting expert annotation can be expensive and time-consuming. Existing works segment a new modality by either deploying a pre-trained model optimized on diverse training data or conducting domain translation and image segmentation as two independent steps. In this work, we propose a novel Cyclic Segmentation Generative Adversarial Network (CySGAN) that conducts image translation and instance segmentation jointly using a unified framework. Besides the CycleGAN losses for image translation and supervised losses for the annotated source domain, we introduce additional self-supervised and segmentation-based adversarial objectives to improve the model performance by leveraging unlabeled target domain images. We benchmark our approach on the task of 3D neuronal nuclei segmentation with annotated electron microscopy (EM) images and unlabeled expansion microscopy (ExM) data. Our CySGAN outperforms both pretrained generalist models and the baselines that sequentially conduct image translation and segmentation. Our implementation and the newly collected, densely annotated ExM nuclei dataset, named NucExM, are available at https://connectomics-bazaar.github.io/proj/CySGAN/index.html.
ARM: Any-Time Super-Resolution Method
Mar 21, 2022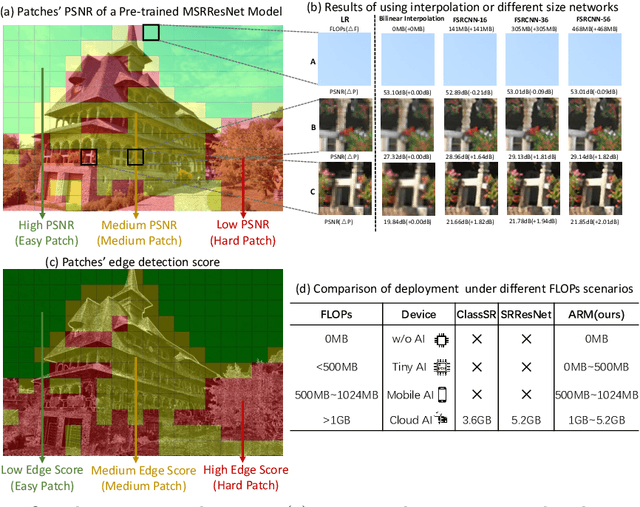
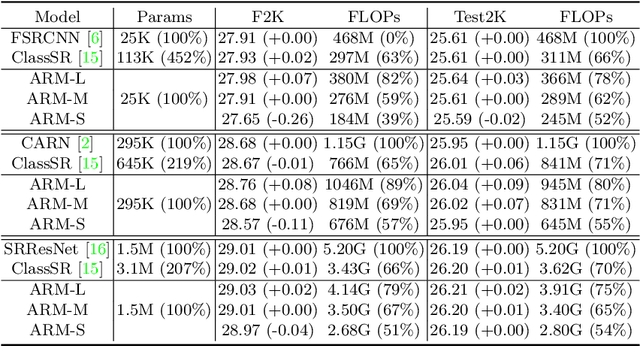

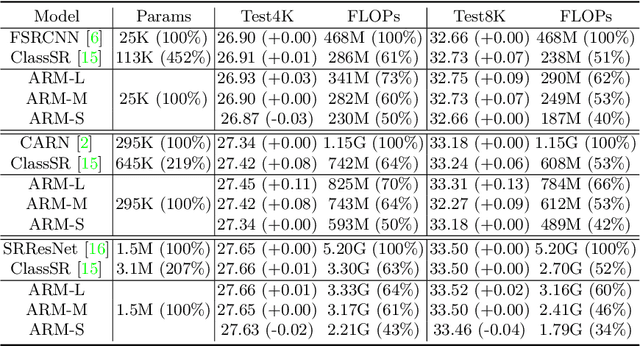
This paper proposes an Any-time super-Resolution Method (ARM) to tackle the over-parameterized single image super-resolution (SISR) models. Our ARM is motivated by three observations: (1) The performance of different image patches varies with SISR networks of different sizes. (2) There is a tradeoff between computation overhead and performance of the reconstructed image. (3) Given an input image, its edge information can be an effective option to estimate its PSNR. Subsequently, we train an ARM supernet containing SISR subnets of different sizes to deal with image patches of various complexity. To that effect, we construct an Edge-to-PSNR lookup table that maps the edge score of an image patch to the PSNR performance for each subnet, together with a set of computation costs for the subnets. In the inference, the image patches are individually distributed to different subnets for a better computation-performance tradeoff. Moreover, each SISR subnet shares weights of the ARM supernet, thus no extra parameters are introduced. The setting of multiple subnets can well adapt the computational cost of SISR model to the dynamically available hardware resources, allowing the SISR task to be in service at any time. Extensive experiments on resolution datasets of different sizes with popular SISR networks as backbones verify the effectiveness and the versatility of our ARM. The source code is available at \url{https://github.com/chenbong/ARM-Net}.
Rotation Equivariant 3D Hand Mesh Generation from a Single RGB Image
Nov 25, 2021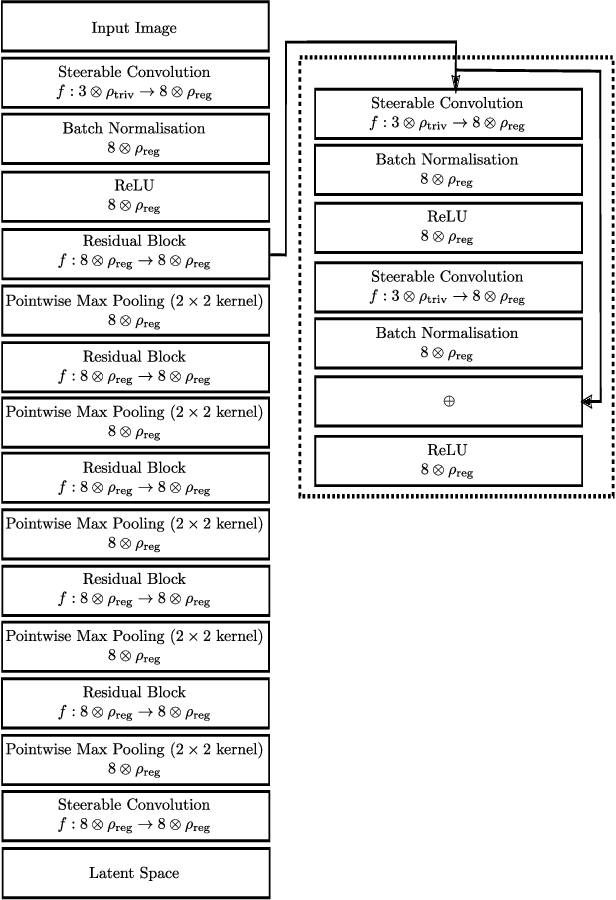
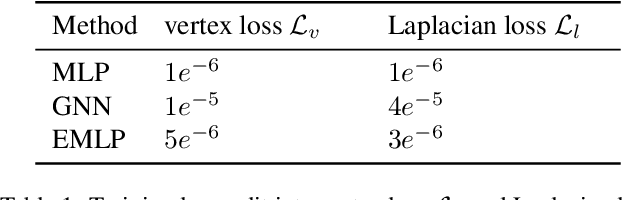
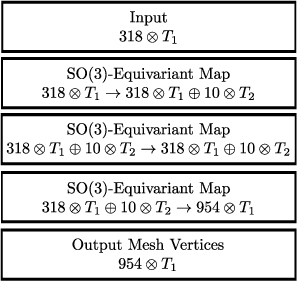
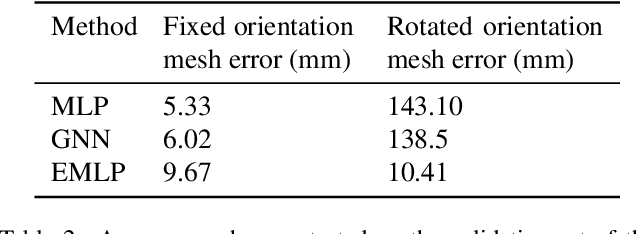
We develop a rotation equivariant model for generating 3D hand meshes from 2D RGB images. This guarantees that as the input image of a hand is rotated the generated mesh undergoes a corresponding rotation. Furthermore, this removes undesirable deformations in the meshes often generated by methods without rotation equivariance. By building a rotation equivariant model, through considering symmetries in the problem, we reduce the need for training on very large datasets to achieve good mesh reconstruction. The encoder takes images defined on $\mathbb{Z}^{2}$ and maps these to latent functions defined on the group $C_{8}$. We introduce a novel vector mapping function to map the function defined on $C_{8}$ to a latent point cloud space defined on the group $\mathrm{SO}(2)$. Further, we introduce a 3D projection function that learns a 3D function from the $\mathrm{SO}(2)$ latent space. Finally, we use an $\mathrm{SO}(3)$ equivariant decoder to ensure rotation equivariance. Our rotation equivariant model outperforms state-of-the-art methods on a real-world dataset and we demonstrate that it accurately captures the shape and pose in the generated meshes under rotation of the input hand.