 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Vision-Language Pre-Training with Triple Contrastive Learning
Mar 28, 2022
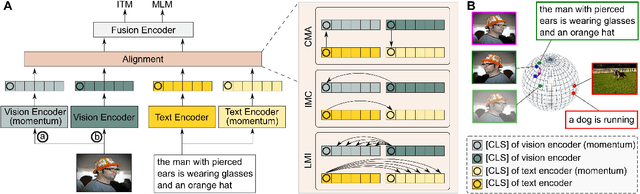

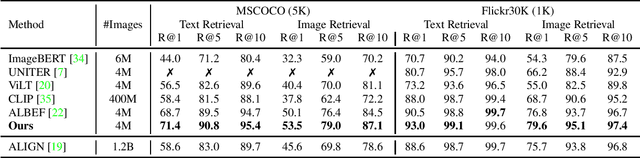
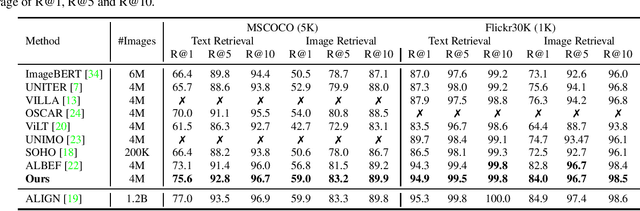
Vision-language representation learning largely benefits from image-text alignment through contrastive losses (e.g., InfoNCE loss). The success of this alignment strategy is attributed to its capability in maximizing the mutual information (MI) between an image and its matched text. However, simply performing cross-modal alignment (CMA) ignores data potential within each modality, which may result in degraded representations. For instance, although CMA-based models are able to map image-text pairs close together in the embedding space, they fail to ensure that similar inputs from the same modality stay close by. This problem can get even worse when the pre-training data is noisy. In this paper, we propose triple contrastive learning (TCL) for vision-language pre-training by leveraging both cross-modal and intra-modal self-supervision. Besides CMA, TCL introduces an intra-modal contrastive objective to provide complementary benefits in representation learning. To take advantage of localized and structural information from image and text input, TCL further maximizes the average MI between local regions of image/text and their global summary. To the best of our knowledge, ours is the first work that takes into account local structure information for multi-modality representation learning. Experimental evaluations show that our approach is competitive and achieves the new state of the art on various common down-stream vision-language tasks such as image-text retrieval and visual question answering.
Medical image segmentation with imperfect 3D bounding boxes
Aug 06, 2021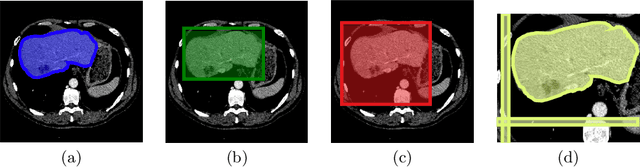

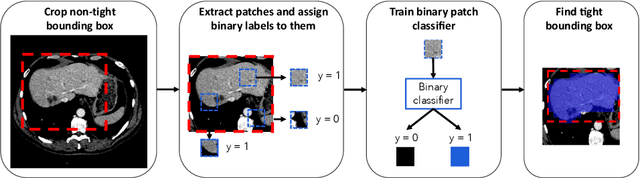

The development of high quality medical image segmentation algorithms depends on the availability of large datasets with pixel-level labels. The challenges of collecting such datasets, especially in case of 3D volumes, motivate to develop approaches that can learn from other types of labels that are cheap to obtain, e.g. bounding boxes. We focus on 3D medical images with their corresponding 3D bounding boxes which are considered as series of per-slice non-tight 2D bounding boxes. While current weakly-supervised approaches that use 2D bounding boxes as weak labels can be applied to medical image segmentation, we show that their success is limited in cases when the assumption about the tightness of the bounding boxes breaks. We propose a new bounding box correction framework which is trained on a small set of pixel-level annotations to improve the tightness of a larger set of non-tight bounding box annotations. The effectiveness of our solution is demonstrated by evaluating a known weakly-supervised segmentation approach with and without the proposed bounding box correction algorithm. When the tightness is improved by our solution, the results of the weakly-supervised segmentation become much closer to those of the fully-supervised one.
Rotation Equivariant 3D Hand Mesh Generation from a Single RGB Image
Nov 25, 2021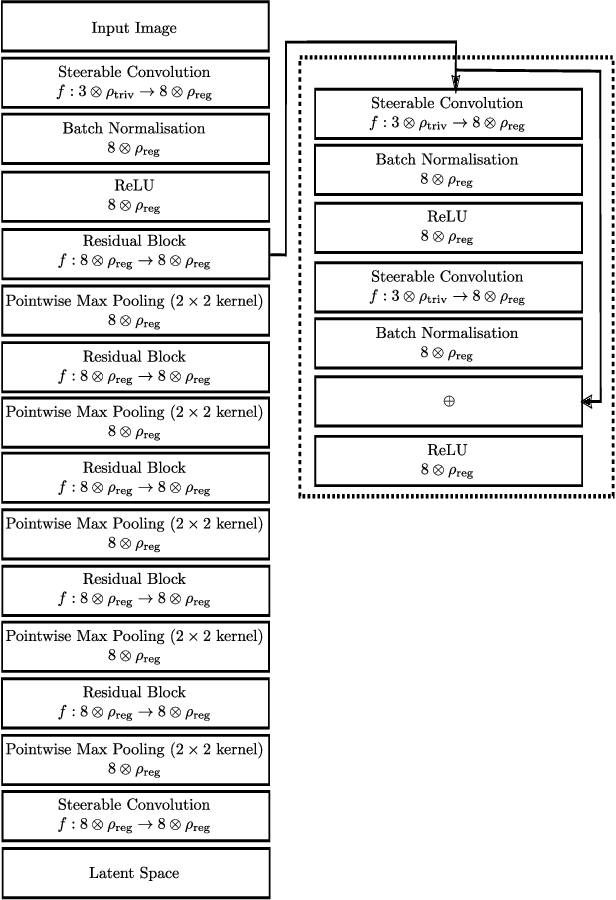
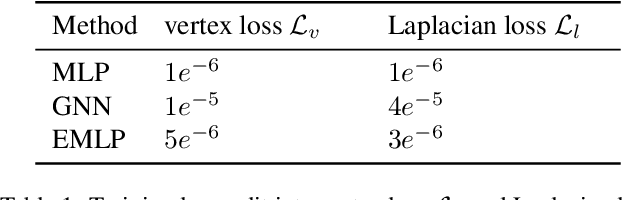
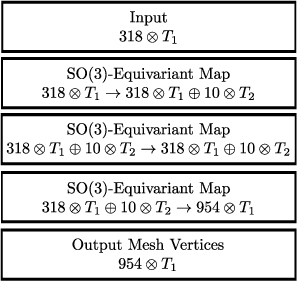
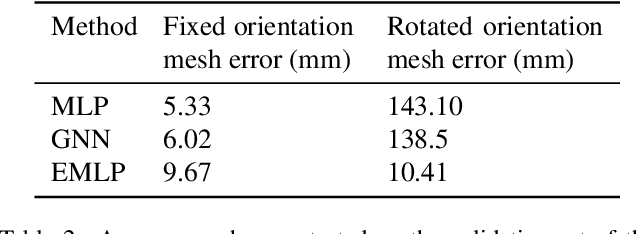
We develop a rotation equivariant model for generating 3D hand meshes from 2D RGB images. This guarantees that as the input image of a hand is rotated the generated mesh undergoes a corresponding rotation. Furthermore, this removes undesirable deformations in the meshes often generated by methods without rotation equivariance. By building a rotation equivariant model, through considering symmetries in the problem, we reduce the need for training on very large datasets to achieve good mesh reconstruction. The encoder takes images defined on $\mathbb{Z}^{2}$ and maps these to latent functions defined on the group $C_{8}$. We introduce a novel vector mapping function to map the function defined on $C_{8}$ to a latent point cloud space defined on the group $\mathrm{SO}(2)$. Further, we introduce a 3D projection function that learns a 3D function from the $\mathrm{SO}(2)$ latent space. Finally, we use an $\mathrm{SO}(3)$ equivariant decoder to ensure rotation equivariance. Our rotation equivariant model outperforms state-of-the-art methods on a real-world dataset and we demonstrate that it accurately captures the shape and pose in the generated meshes under rotation of the input hand.
Predicting Out-of-Domain Generalization with Local Manifold Smoothness
Jul 05, 2022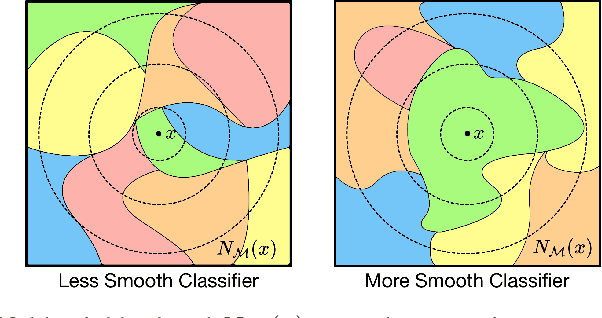

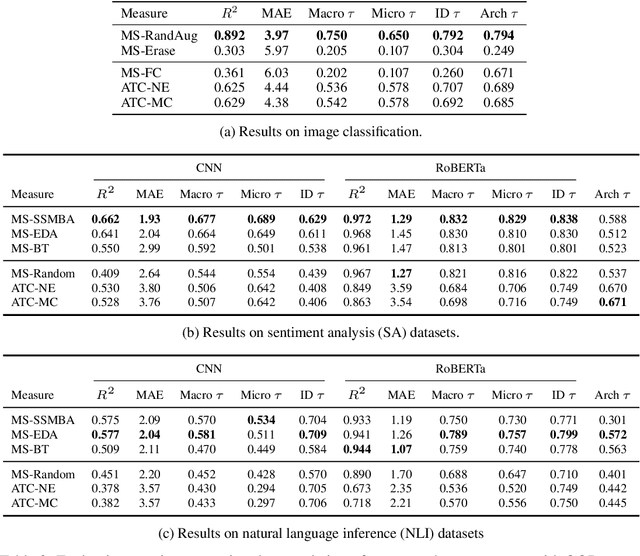
Understanding how machine learning models generalize to new environments is a critical part of their safe deployment. Recent work has proposed a variety of complexity measures that directly predict or theoretically bound the generalization capacity of a model. However, these methods rely on a strong set of assumptions that in practice are not always satisfied. Motivated by the limited settings in which existing measures can be applied, we propose a novel complexity measure based on the local manifold smoothness of a classifier. We define local manifold smoothness as a classifier's output sensitivity to perturbations in the manifold neighborhood around a given test point. Intuitively, a classifier that is less sensitive to these perturbations should generalize better. To estimate smoothness we sample points using data augmentation and measure the fraction of these points classified into the majority class. Our method only requires selecting a data augmentation method and makes no other assumptions about the model or data distributions, meaning it can be applied even in out-of-domain (OOD) settings where existing methods cannot. In experiments on robustness benchmarks in image classification, sentiment analysis, and natural language inference, we demonstrate a strong and robust correlation between our manifold smoothness measure and actual OOD generalization on over 3,000 models evaluated on over 100 train/test domain pairs.
CASHformer: Cognition Aware SHape Transformer for Longitudinal Analysis
Jul 05, 2022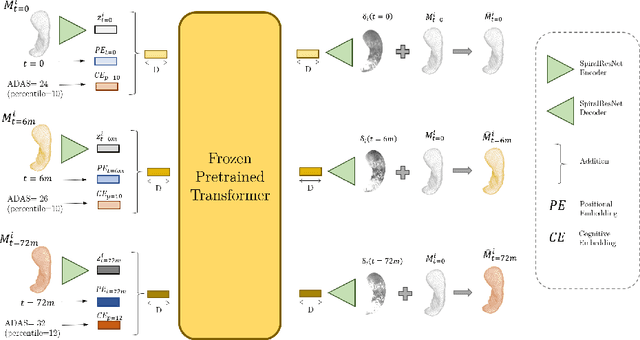
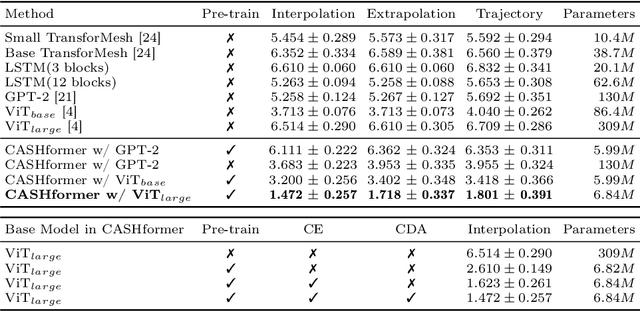
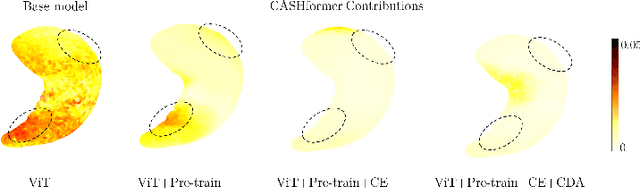
Modeling temporal changes in subcortical structures is crucial for a better understanding of the progression of Alzheimer's disease (AD). Given their flexibility to adapt to heterogeneous sequence lengths, mesh-based transformer architectures have been proposed in the past for predicting hippocampus deformations across time. However, one of the main limitations of transformers is the large amount of trainable parameters, which makes the application on small datasets very challenging. In addition, current methods do not include relevant non-image information that can help to identify AD-related patterns in the progression. To this end, we introduce CASHformer, a transformer-based framework to model longitudinal shape trajectories in AD. CASHformer incorporates the idea of pre-trained transformers as universal compute engines that generalize across a wide range of tasks by freezing most layers during fine-tuning. This reduces the number of parameters by over 90% with respect to the original model and therefore enables the application of large models on small datasets without overfitting. In addition, CASHformer models cognitive decline to reveal AD atrophy patterns in the temporal sequence. Our results show that CASHformer reduces the reconstruction error by 73% compared to previously proposed methods. Moreover, the accuracy of detecting patients progressing to AD increases by 3% with imputing missing longitudinal shape data.
Structured Multi-modal Feature Embedding and Alignment for Image-Sentence Retrieval
Aug 05, 2021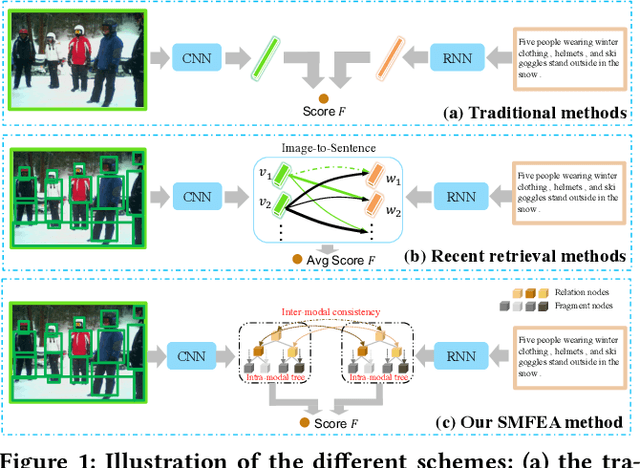
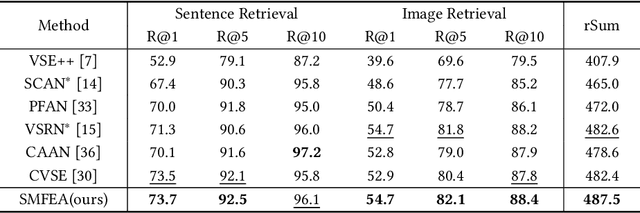
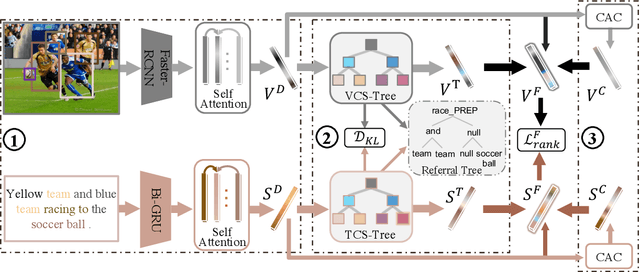
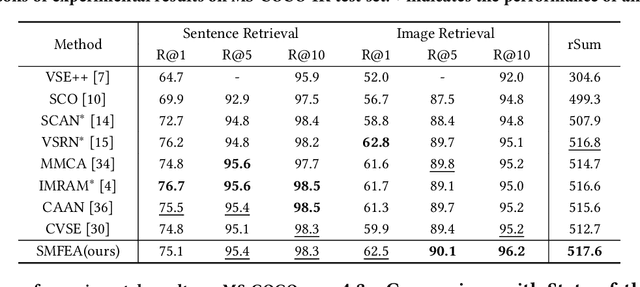
The current state-of-the-art image-sentence retrieval methods implicitly align the visual-textual fragments, like regions in images and words in sentences, and adopt attention modules to highlight the relevance of cross-modal semantic correspondences. However, the retrieval performance remains unsatisfactory due to a lack of consistent representation in both semantics and structural spaces. In this work, we propose to address the above issue from two aspects: (i) constructing intrinsic structure (along with relations) among the fragments of respective modalities, e.g., "dog $\to$ play $\to$ ball" in semantic structure for an image, and (ii) seeking explicit inter-modal structural and semantic correspondence between the visual and textual modalities. In this paper, we propose a novel Structured Multi-modal Feature Embedding and Alignment (SMFEA) model for image-sentence retrieval. In order to jointly and explicitly learn the visual-textual embedding and the cross-modal alignment, SMFEA creates a novel multi-modal structured module with a shared context-aware referral tree. In particular, the relations of the visual and textual fragments are modeled by constructing Visual Context-aware Structured Tree encoder (VCS-Tree) and Textual Context-aware Structured Tree encoder (TCS-Tree) with shared labels, from which visual and textual features can be jointly learned and optimized. We utilize the multi-modal tree structure to explicitly align the heterogeneous image-sentence data by maximizing the semantic and structural similarity between corresponding inter-modal tree nodes. Extensive experiments on Microsoft COCO and Flickr30K benchmarks demonstrate the superiority of the proposed model in comparison to the state-of-the-art methods.
On the Sins of Image Synthesis Loss for Self-supervised Depth Estimation
Sep 13, 2021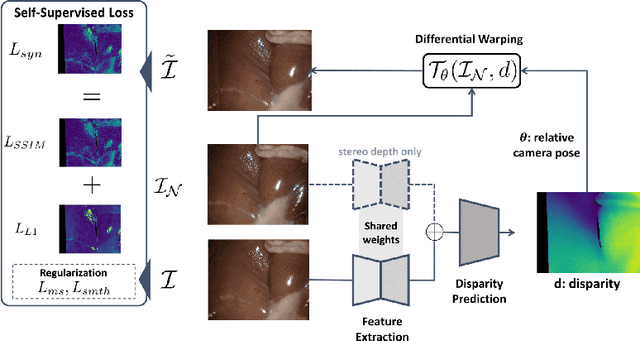
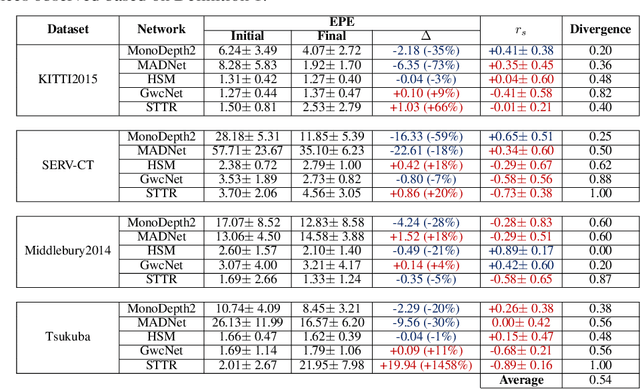
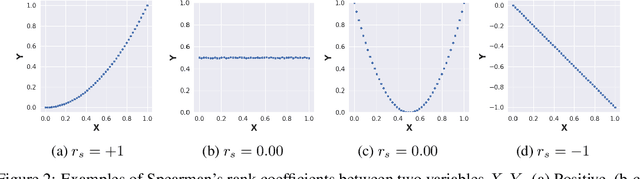
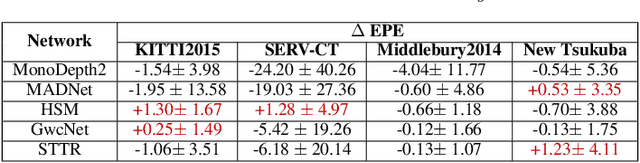
Scene depth estimation from stereo and monocular imagery is critical for extracting 3D information for downstream tasks such as scene understanding. Recently, learning-based methods for depth estimation have received much attention due to their high performance and flexibility in hardware choice. However, collecting ground truth data for supervised training of these algorithms is costly or outright impossible. This circumstance suggests a need for alternative learning approaches that do not require corresponding depth measurements. Indeed, self-supervised learning of depth estimation provides an increasingly popular alternative. It is based on the idea that observed frames can be synthesized from neighboring frames if accurate depth of the scene is known - or in this case, estimated. We show empirically that - contrary to common belief - improvements in image synthesis do not necessitate improvement in depth estimation. Rather, optimizing for image synthesis can result in diverging performance with respect to the main prediction objective - depth. We attribute this diverging phenomenon to aleatoric uncertainties, which originate from data. Based on our experiments on four datasets (spanning street, indoor, and medical) and five architectures (monocular and stereo), we conclude that this diverging phenomenon is independent of the dataset domain and not mitigated by commonly used regularization techniques. To underscore the importance of this finding, we include a survey of methods which use image synthesis, totaling 127 papers over the last six years. This observed divergence has not been previously reported or studied in depth, suggesting room for future improvement of self-supervised approaches which might be impacted the finding.
Differential real-time single-pixel imaging with Fourier domain regularization -- applications to VIS-IR imaging and polarization imaging
May 24, 2022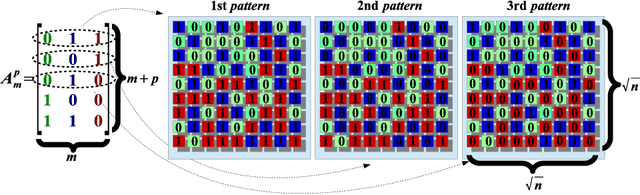
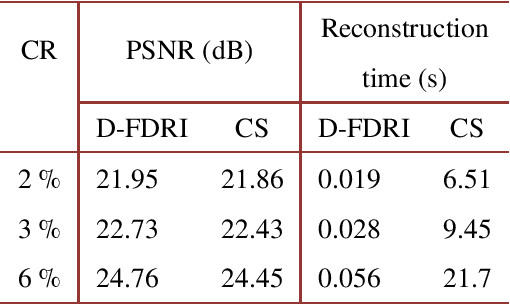
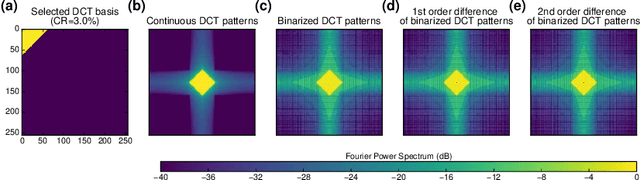
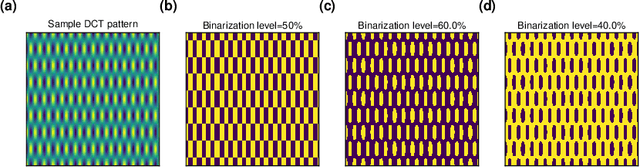
The speed and quality of single-pixel imaging (SPI) are fundamentally limited by image modulation frequency and by the levels of optical noise and compression noise. In an approach to come close to these limits, we introduce a SPI technique, which is inherently differential, and comprises a novel way of measuring the zeroth spatial frequency of images and makes use of varied thresholding of sampling patterns. With the proposed sampling, the entropy of the detection signal is increased in comparison to standard SPI protocols. Image reconstruction is obtained with a single matrix-vector product so the cost of the reconstruction method scales proportionally with the number of measured samples. A differential operator is included in the reconstruction and following the method is based on finding the generalized inversion of the modified measurement matrix with regularization in the Fourier domain. We demonstrate $256 \times 256$ SPI at up to $17~$Hz at visible and near-infrared wavelength ranges using two polarization or spectral channels. A low bit-resolution data acquisition device with alternating-current-coupling can be used in the measurement indicating that the proposed method combines improved noise robustness with a differential removal of the direct current component of the signal.
Graph-DETR3D: Rethinking Overlapping Regions for Multi-View 3D Object Detection
Apr 26, 2022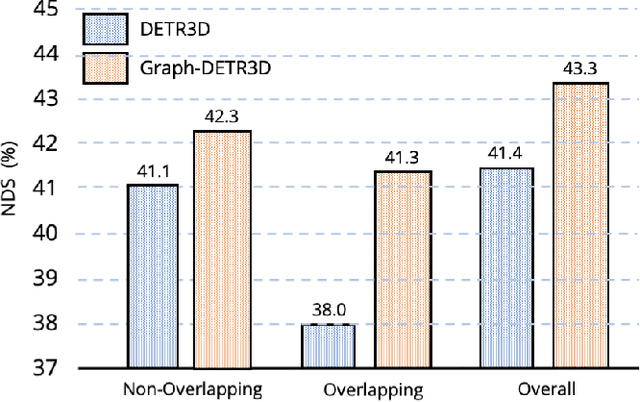
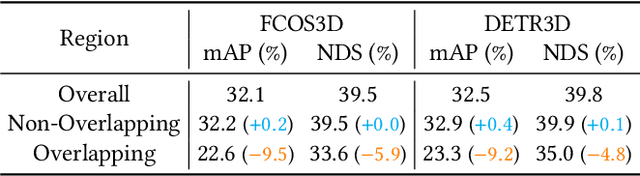

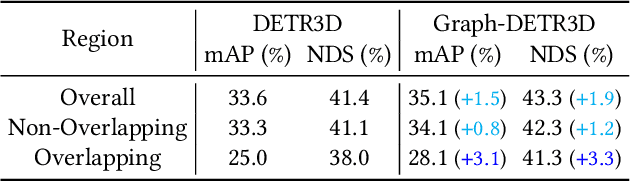
3D object detection from multiple image views is a fundamental and challenging task for visual scene understanding. Due to its low cost and high efficiency, multi-view 3D object detection has demonstrated promising application prospects. However, accurately detecting objects through perspective views in the 3D space is extremely difficult due to the lack of depth information. Recently, DETR3D introduces a novel 3D-2D query paradigm in aggregating multi-view images for 3D object detection and achieves state-of-the-art performance. In this paper, with intensive pilot experiments, we quantify the objects located at different regions and find that the "truncated instances" (i.e., at the border regions of each image) are the main bottleneck hindering the performance of DETR3D. Although it merges multiple features from two adjacent views in the overlapping regions, DETR3D still suffers from insufficient feature aggregation, thus missing the chance to fully boost the detection performance. In an effort to tackle the problem, we propose Graph-DETR3D to automatically aggregate multi-view imagery information through graph structure learning (GSL). It constructs a dynamic 3D graph between each object query and 2D feature maps to enhance the object representations, especially at the border regions. Besides, Graph-DETR3D benefits from a novel depth-invariant multi-scale training strategy, which maintains the visual depth consistency by simultaneously scaling the image size and the object depth. Extensive experiments on the nuScenes dataset demonstrate the effectiveness and efficiency of our Graph-DETR3D. Notably, our best model achieves 49.5 NDS on the nuScenes test leaderboard, achieving new state-of-the-art in comparison with various published image-view 3D object detectors.
SpecSinGAN: Sound Effect Variation Synthesis Using Single-Image GANs
Oct 14, 2021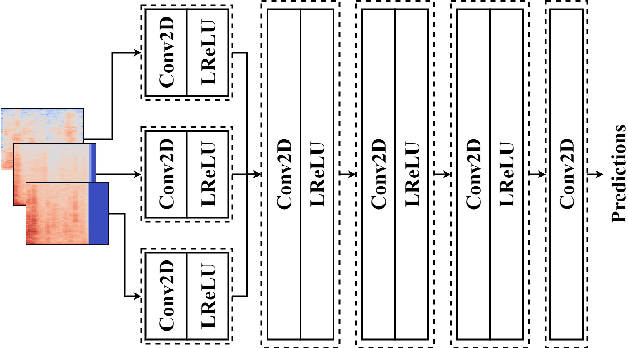
Single-image generative adversarial networks learn from the internal distribution of a single training example to generate variations of it, removing the need of a large dataset. In this paper we introduce SpecSinGAN, an unconditional generative architecture that takes a single one-shot sound effect (e.g., a footstep; a character jump) and produces novel variations of it, as if they were different takes from the same recording session. We explore the use of multi-channel spectrograms to train the model on the various layers that comprise a single sound effect. A listening study comparing our model to real recordings and to digital signal processing procedural audio models in terms of sound plausibility and variation revealed that SpecSinGAN is more plausible and varied than the procedural audio models considered, when using multi-channel spectrograms. Sound examples can be found at the project website: https://www.adrianbarahonarios.com/specsingan/