 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Modal Image Captioning for the Visually Impaired
May 17, 2021

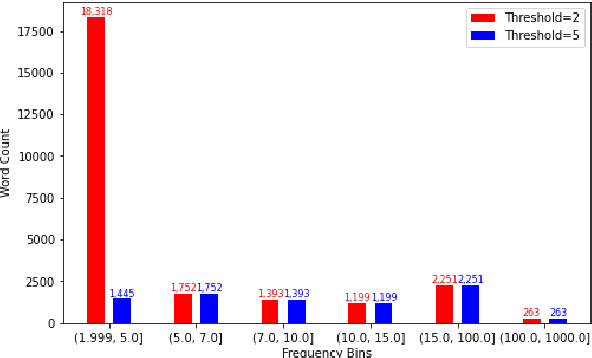

One of the ways blind people understand their surroundings is by clicking images and relying on descriptions generated by image captioning systems. Current work on captioning images for the visually impaired do not use the textual data present in the image when generating captions. This problem is critical as many visual scenes contain text. Moreover, up to 21% of the questions asked by blind people about the images they click pertain to the text present in them. In this work, we propose altering AoANet, a state-of-the-art image captioning model, to leverage the text detected in the image as an input feature. In addition, we use a pointer-generator mechanism to copy the detected text to the caption when tokens need to be reproduced accurately. Our model outperforms AoANet on the benchmark dataset VizWiz, giving a 35% and 16.2% performance improvement on CIDEr and SPICE scores, respectively.
Mask-guided Spectral-wise Transformer for Efficient Hyperspectral Image Reconstruction
Nov 15, 2021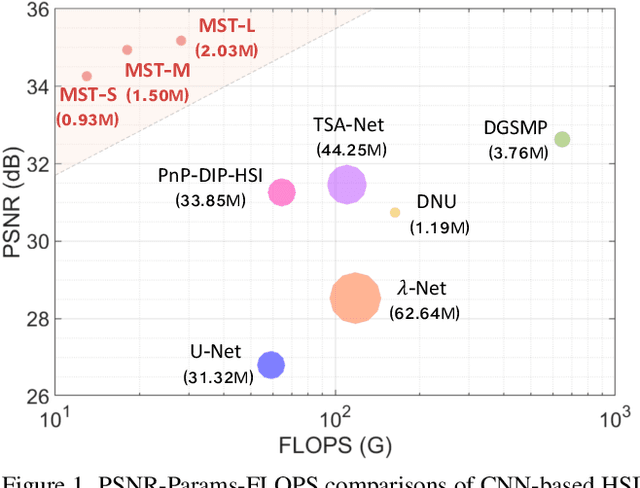
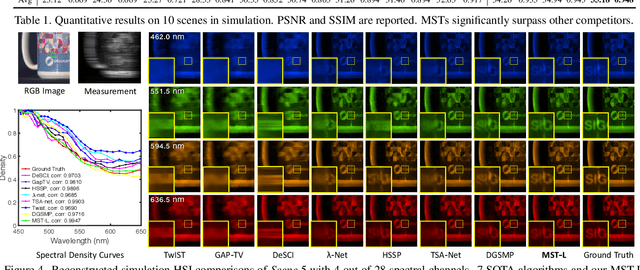
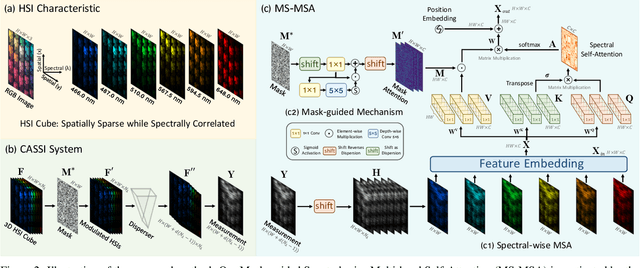
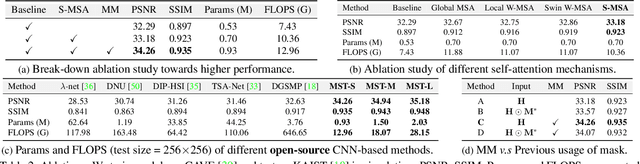
Hyperspectral image (HSI) reconstruction aims to recover the 3D spatial-spectral signal from a 2D measurement in the coded aperture snapshot spectral imaging (CASSI) system. The HSI representations are highly similar and correlated across the spectral dimension. Modeling the inter-spectra interactions is beneficial for HSI reconstruction. However, existing CNN-based methods show limitations in capturing spectral-wise similarity and long-range dependencies. Besides, the HSI information is modulated by a coded aperture (physical mask) in CASSI. Nonetheless, current algorithms have not fully explored the guidance effect of the mask for HSI restoration. In this paper, we propose a novel framework, Mask-guided Spectral-wise Transformer (MST), for HSI reconstruction. Specifically, we present a Spectral-wise Multi-head Self-Attention (S-MSA) that treats each spectral feature as a token and calculates self-attention along the spectral dimension. In addition, we customize a Mask-guided Mechanism (MM) that directs S-MSA to pay attention to spatial regions with high-fidelity spectral representations. Extensive experiments show that our MST significantly outperforms state-of-the-art (SOTA) methods on simulation and real HSI datasets while requiring dramatically cheaper computational and memory costs.
Structure-Preserving Image Super-Resolution
Sep 26, 2021
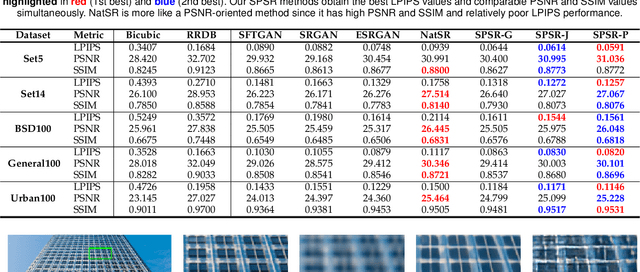
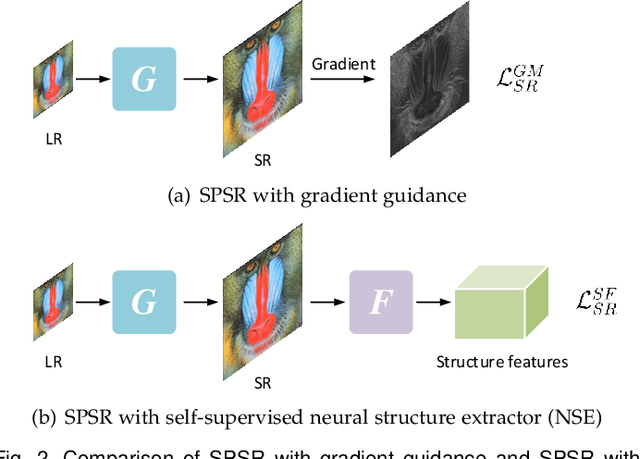

Structures matter in single image super-resolution (SISR). Benefiting from generative adversarial networks (GANs), recent studies have promoted the development of SISR by recovering photo-realistic images. However, there are still undesired structural distortions in the recovered images. In this paper, we propose a structure-preserving super-resolution (SPSR) method to alleviate the above issue while maintaining the merits of GAN-based methods to generate perceptual-pleasant details. Firstly, we propose SPSR with gradient guidance (SPSR-G) by exploiting gradient maps of images to guide the recovery in two aspects. On the one hand, we restore high-resolution gradient maps by a gradient branch to provide additional structure priors for the SR process. On the other hand, we propose a gradient loss to impose a second-order restriction on the super-resolved images, which helps generative networks concentrate more on geometric structures. Secondly, since the gradient maps are handcrafted and may only be able to capture limited aspects of structural information, we further extend SPSR-G by introducing a learnable neural structure extractor (NSE) to unearth richer local structures and provide stronger supervision for SR. We propose two self-supervised structure learning methods, contrastive prediction and solving jigsaw puzzles, to train the NSEs. Our methods are model-agnostic, which can be potentially used for off-the-shelf SR networks. Experimental results on five benchmark datasets show that the proposed methods outperform state-of-the-art perceptual-driven SR methods under LPIPS, PSNR, and SSIM metrics. Visual results demonstrate the superiority of our methods in restoring structures while generating natural SR images. Code is available at https://github.com/Maclory/SPSR.
Unsupervised Deraining: Where Contrastive Learning Meets Self-similarity
Mar 22, 2022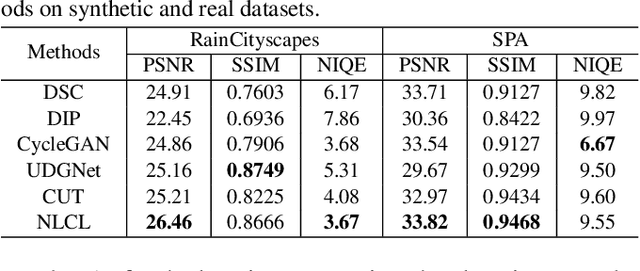
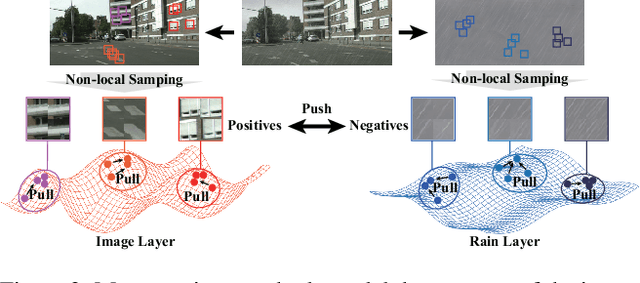
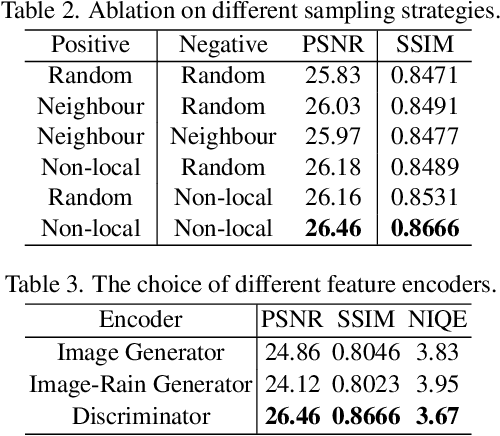
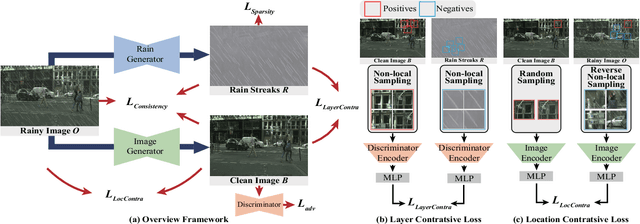
Image deraining is a typical low-level image restoration task, which aims at decomposing the rainy image into two distinguishable layers: the clean image layer and the rain layer. Most of the existing learning-based deraining methods are supervisedly trained on synthetic rainy-clean pairs. The domain gap between the synthetic and real rains makes them less generalized to different real rainy scenes. Moreover, the existing methods mainly utilize the property of the two layers independently, while few of them have considered the mutually exclusive relationship between the two layers. In this work, we propose a novel non-local contrastive learning (NLCL) method for unsupervised image deraining. Consequently, we not only utilize the intrinsic self-similarity property within samples but also the mutually exclusive property between the two layers, so as to better differ the rain layer from the clean image. Specifically, the non-local self-similarity image layer patches as the positives are pulled together and similar rain layer patches as the negatives are pushed away. Thus the similar positive/negative samples that are close in the original space benefit us to enrich more discriminative representation. Apart from the self-similarity sampling strategy, we analyze how to choose an appropriate feature encoder in NLCL. Extensive experiments on different real rainy datasets demonstrate that the proposed method obtains state-of-the-art performance in real deraining.
StyTr^2: Unbiased Image Style Transfer with Transformers
Jun 08, 2021
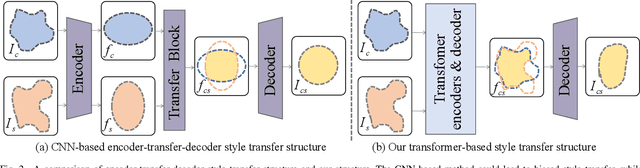
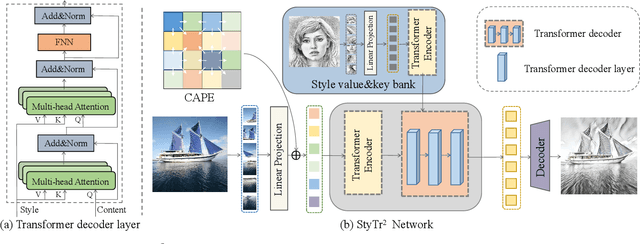
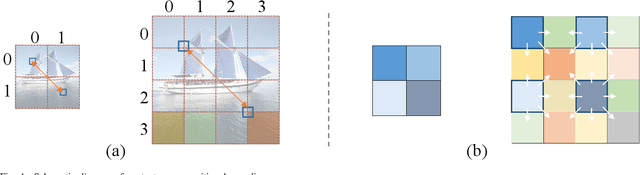
The goal of image style transfer is to render an image with artistic features guided by a style reference while maintaining the original content. Due to the locality and spatial invariance in CNNs, it is difficult to extract and maintain the global information of input images. Therefore, traditional neural style transfer methods are usually biased and content leak can be observed by running several times of the style transfer process with the same reference style image. To address this critical issue, we take long-range dependencies of input images into account for unbiased style transfer by proposing a transformer-based approach, namely StyTr^2. In contrast with visual transformers for other vision tasks, our StyTr^2 contains two different transformer encoders to generate domain-specific sequences for content and style, respectively. Following the encoders, a multi-layer transformer decoder is adopted to stylize the content sequence according to the style sequence. In addition, we analyze the deficiency of existing positional encoding methods and propose the content-aware positional encoding (CAPE) which is scale-invariant and more suitable for image style transfer task. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed StyTr^2 compared to state-of-the-art CNN-based and flow-based approaches.
ImUnity: a generalizable VAE-GAN solution for multicenter MR image harmonization
Sep 14, 2021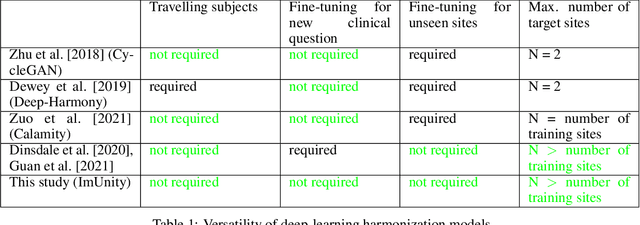
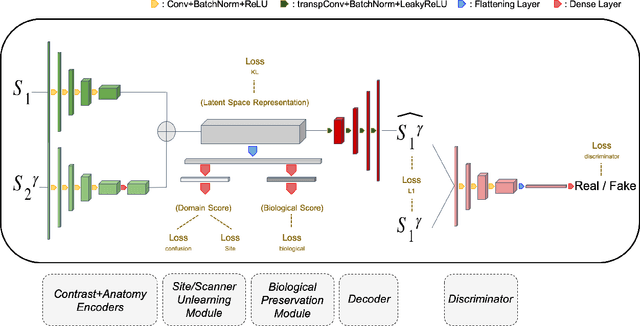
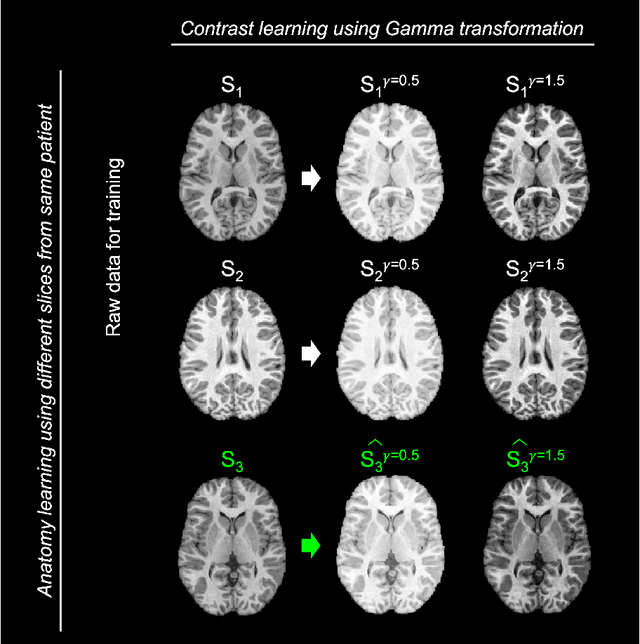
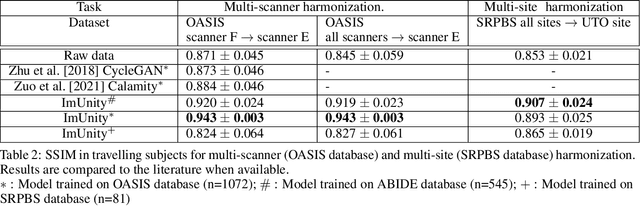
ImUnity is an original deep-learning model designed for efficient and flexible MR image harmonization. A VAE-GAN network, coupled with a confusion module and an optional biological preservation module, uses multiple 2D-slices taken from different anatomical locations in each subject of the training database, as well as image contrast transformations for its self-supervised training. It eventually generates 'corrected' MR images that can be used for various multi-center population studies. Using 3 open source databases (ABIDE, OASIS and SRPBS), which contain MR images from multiple acquisition scanner types or vendors and a large range of subjects ages, we show that ImUnity: (1) outperforms state-of-the-art methods in terms of quality of images generated using traveling subjects; (2) removes sites or scanner biases while improving patients classification; (3) harmonizes data coming from new sites or scanners without the need for an additional fine-tuning and (4) allows the selection of multiple MR reconstructed images according to the desired applications. Tested here on T1-weighted images, ImUnity could be used to harmonize other types of medical images.
CoPE: Conditional image generation using Polynomial Expansions
Apr 11, 2021
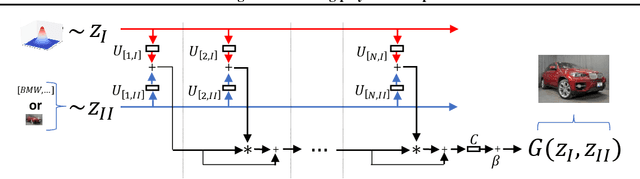


Generative modeling has evolved to a notable field of machine learning. Deep polynomial neural networks (PNNs) have demonstrated impressive results in unsupervised image generation, where the task is to map an input vector (i.e., noise) to a synthesized image. However, the success of PNNs has not been replicated in conditional generation tasks, such as super-resolution. Existing PNNs focus on single-variable polynomial expansions which do not fare well to two-variable inputs, i.e., the noise variable and the conditional variable. In this work, we introduce a general framework, called CoPE, that enables a polynomial expansion of two input variables and captures their auto- and cross-correlations. We exhibit how CoPE can be trivially augmented to accept an arbitrary number of input variables. CoPE is evaluated in five tasks (class-conditional generation, inverse problems, edges-to-image translation, image-to-image translation, attribute-guided generation) involving eight datasets. The thorough evaluation suggests that CoPE can be useful for tackling diverse conditional generation tasks.
Incremental Learning Meets Transfer Learning: Application to Multi-site Prostate MRI Segmentation
Jun 03, 2022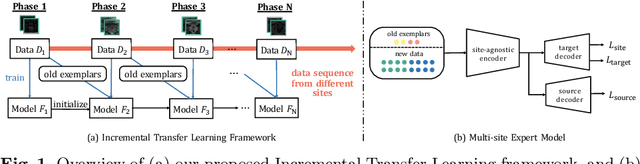

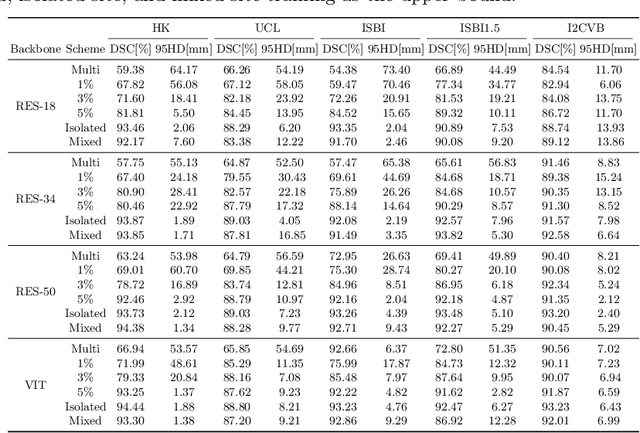
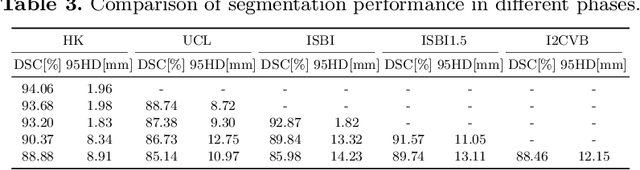
Many medical datasets have recently been created for medical image segmentation tasks, and it is natural to question whether we can use them to sequentially train a single model that (1) performs better on all these datasets, and (2) generalizes well and transfers better to the unknown target site domain. Prior works have achieved this goal by jointly training one model on multi-site datasets, which achieve competitive performance on average but such methods rely on the assumption about the availability of all training data, thus limiting its effectiveness in practical deployment. In this paper, we propose a novel multi-site segmentation framework called incremental-transfer learning (ITL), which learns a model from multi-site datasets in an end-to-end sequential fashion. Specifically, "incremental" refers to training sequentially constructed datasets, and "transfer" is achieved by leveraging useful information from the linear combination of embedding features on each dataset. In addition, we introduce our ITL framework, where we train the network including a site-agnostic encoder with pre-trained weights and at most two segmentation decoder heads. We also design a novel site-level incremental loss in order to generalize well on the target domain. Second, we show for the first time that leveraging our ITL training scheme is able to alleviate challenging catastrophic forgetting problems in incremental learning. We conduct experiments using five challenging benchmark datasets to validate the effectiveness of our incremental-transfer learning approach. Our approach makes minimal assumptions on computation resources and domain-specific expertise, and hence constitutes a strong starting point in multi-site medical image segmentation.
Vision-Language Pre-Training with Triple Contrastive Learning
Mar 28, 2022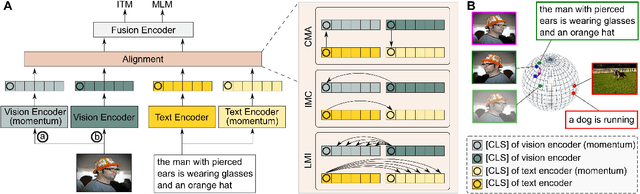

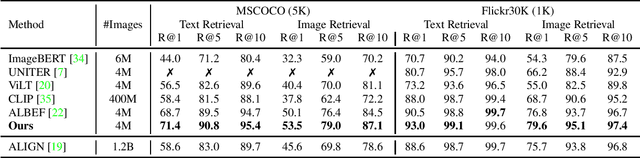
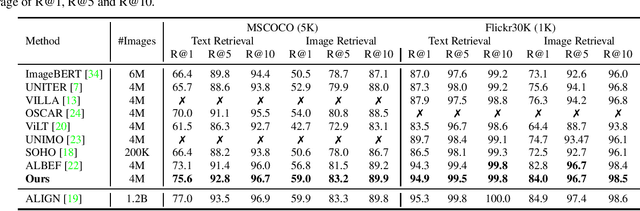
Vision-language representation learning largely benefits from image-text alignment through contrastive losses (e.g., InfoNCE loss). The success of this alignment strategy is attributed to its capability in maximizing the mutual information (MI) between an image and its matched text. However, simply performing cross-modal alignment (CMA) ignores data potential within each modality, which may result in degraded representations. For instance, although CMA-based models are able to map image-text pairs close together in the embedding space, they fail to ensure that similar inputs from the same modality stay close by. This problem can get even worse when the pre-training data is noisy. In this paper, we propose triple contrastive learning (TCL) for vision-language pre-training by leveraging both cross-modal and intra-modal self-supervision. Besides CMA, TCL introduces an intra-modal contrastive objective to provide complementary benefits in representation learning. To take advantage of localized and structural information from image and text input, TCL further maximizes the average MI between local regions of image/text and their global summary. To the best of our knowledge, ours is the first work that takes into account local structure information for multi-modality representation learning. Experimental evaluations show that our approach is competitive and achieves the new state of the art on various common down-stream vision-language tasks such as image-text retrieval and visual question answering.
Self-Supervision on Images and Text Reduces Reliance on Visual Shortcut Features
Jun 14, 2022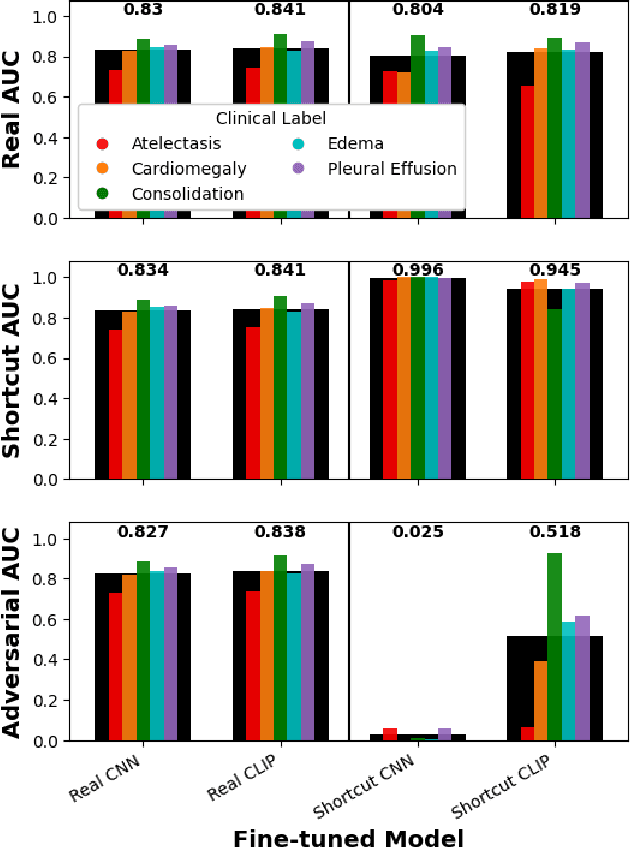
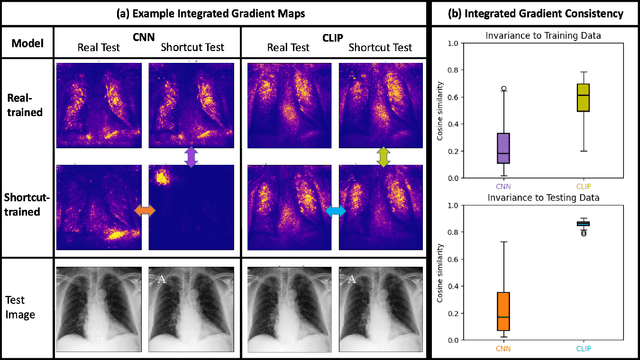
Deep learning models trained in a fully supervised manner have been shown to rely on so-called "shortcut" features. Shortcut features are inputs that are associated with the outcome of interest in the training data, but are either no longer associated or not present in testing or deployment settings. Here we provide experiments that show recent self-supervised models trained on images and text provide more robust image representations and reduce the model's reliance on visual shortcut features on a realistic medical imaging example. Additionally, we find that these self-supervised models "forget" shortcut features more quickly than fully supervised ones when fine-tuned on labeled data. Though not a complete solution, our experiments provide compelling evidence that self-supervised models trained on images and text provide some resilience to visual shortcut features.