 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Personalized Showcases: Generating Multi-Modal Explanations for Recommendations
Jun 30, 2022
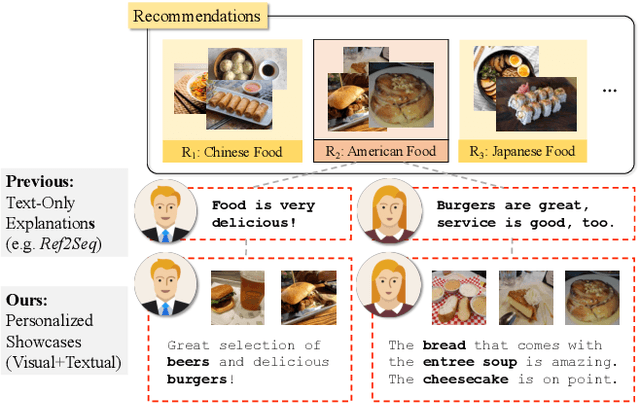
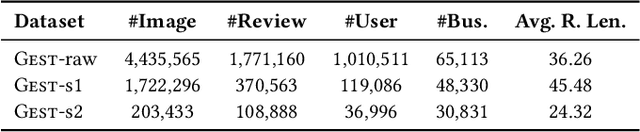

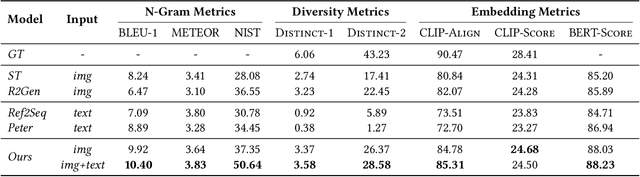
Existing explanation models generate only text for recommendations but still struggle to produce diverse contents. In this paper, to further enrich explanations, we propose a new task named personalized showcases, in which we provide both textual and visual information to explain our recommendations. Specifically, we first select a personalized image set that is the most relevant to a user's interest toward a recommended item. Then, natural language explanations are generated accordingly given our selected images. For this new task, we collect a large-scale dataset from Google Local (i.e.,~maps) and construct a high-quality subset for generating multi-modal explanations. We propose a personalized multi-modal framework which can generate diverse and visually-aligned explanations via contrastive learning. Experiments show that our framework benefits from different modalities as inputs, and is able to produce more diverse and expressive explanations compared to previous methods on a variety of evaluation metrics.
Perceptual Quality Assessment of Omnidirectional Images
Jul 06, 2022



Omnidirectional images and videos can provide immersive experience of real-world scenes in Virtual Reality (VR) environment. We present a perceptual omnidirectional image quality assessment (IQA) study in this paper since it is extremely important to provide a good quality of experience under the VR environment. We first establish an omnidirectional IQA (OIQA) database, which includes 16 source images and 320 distorted images degraded by 4 commonly encountered distortion types, namely JPEG compression, JPEG2000 compression, Gaussian blur and Gaussian noise. Then a subjective quality evaluation study is conducted on the OIQA database in the VR environment. Considering that humans can only see a part of the scene at one movement in the VR environment, visual attention becomes extremely important. Thus we also track head and eye movement data during the quality rating experiments. The original and distorted omnidirectional images, subjective quality ratings, and the head and eye movement data together constitute the OIQA database. State-of-the-art full-reference (FR) IQA measures are tested on the OIQA database, and some new observations different from traditional IQA are made.
Residue-Based Natural Language Adversarial Attack Detection
Apr 17, 2022
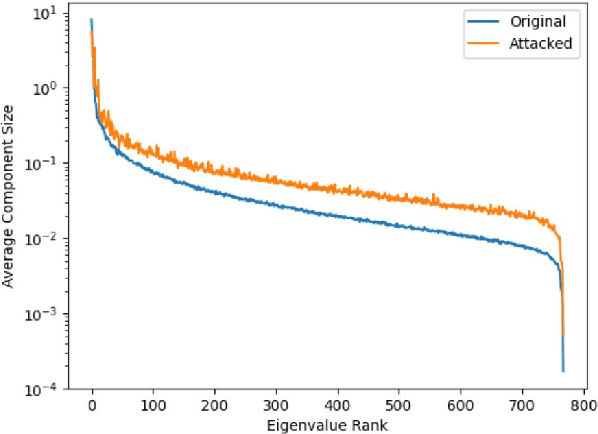
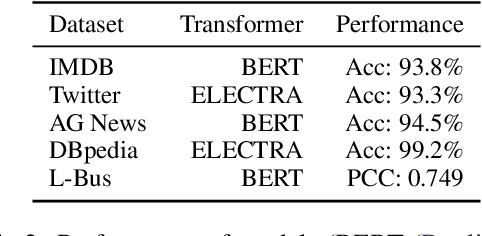
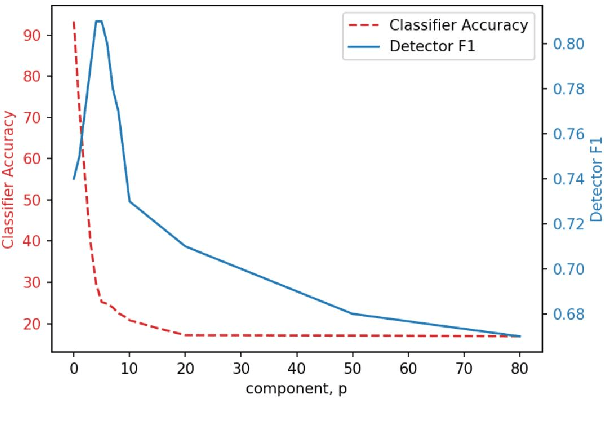
Deep learning based systems are susceptible to adversarial attacks, where a small, imperceptible change at the input alters the model prediction. However, to date the majority of the approaches to detect these attacks have been designed for image processing systems. Many popular image adversarial detection approaches are able to identify adversarial examples from embedding feature spaces, whilst in the NLP domain existing state of the art detection approaches solely focus on input text features, without consideration of model embedding spaces. This work examines what differences result when porting these image designed strategies to Natural Language Processing (NLP) tasks - these detectors are found to not port over well. This is expected as NLP systems have a very different form of input: discrete and sequential in nature, rather than the continuous and fixed size inputs for images. As an equivalent model-focused NLP detection approach, this work proposes a simple sentence-embedding "residue" based detector to identify adversarial examples. On many tasks, it out-performs ported image domain detectors and recent state of the art NLP specific detectors.
DeepSSM: A Blueprint for Image-to-Shape Deep Learning Models
Oct 14, 2021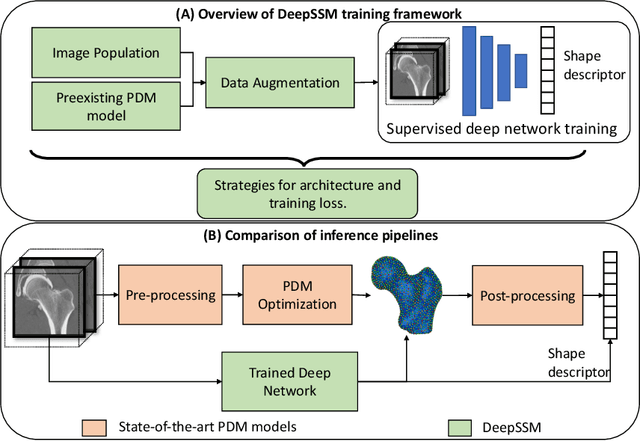

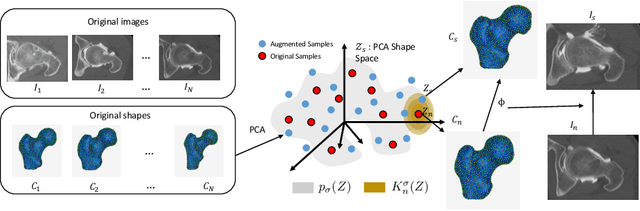
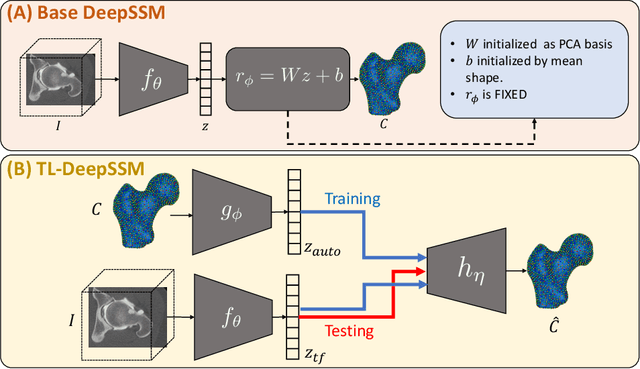
Statistical shape modeling (SSM) characterizes anatomical variations in a population of shapes generated from medical images. SSM requires consistent shape representation across samples in shape cohort. Establishing this representation entails a processing pipeline that includes anatomy segmentation, re-sampling, registration, and non-linear optimization. These shape representations are then used to extract low-dimensional shape descriptors that facilitate subsequent analyses in different applications. However, the current process of obtaining these shape descriptors from imaging data relies on human and computational resources, requiring domain expertise for segmenting anatomies of interest. Moreover, this same taxing pipeline needs to be repeated to infer shape descriptors for new image data using a pre-trained/existing shape model. Here, we propose DeepSSM, a deep learning-based framework for learning the functional mapping from images to low-dimensional shape descriptors and their associated shape representations, thereby inferring statistical representation of anatomy directly from 3D images. Once trained using an existing shape model, DeepSSM circumvents the heavy and manual pre-processing and segmentation and significantly improves the computational time, making it a viable solution for fully end-to-end SSM applications. In addition, we introduce a model-based data-augmentation strategy to address data scarcity. Finally, this paper presents and analyzes two different architectural variants of DeepSSM with different loss functions using three medical datasets and their downstream clinical application. Experiments showcase that DeepSSM performs comparably or better to the state-of-the-art SSM both quantitatively and on application-driven downstream tasks. Therefore, DeepSSM aims to provide a comprehensive blueprint for deep learning-based image-to-shape models.
PixelSynth: Generating a 3D-Consistent Experience from a Single Image
Aug 12, 2021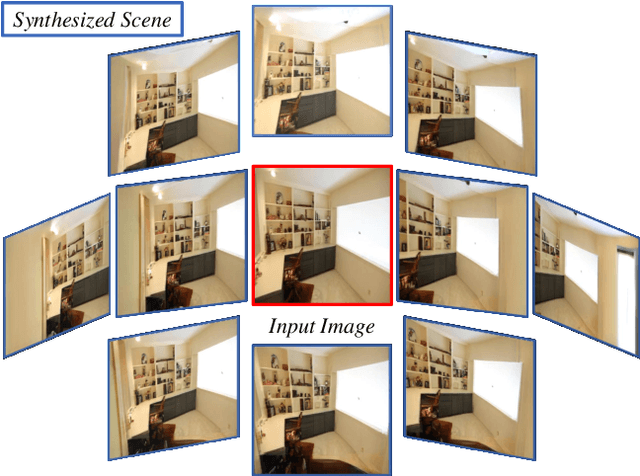
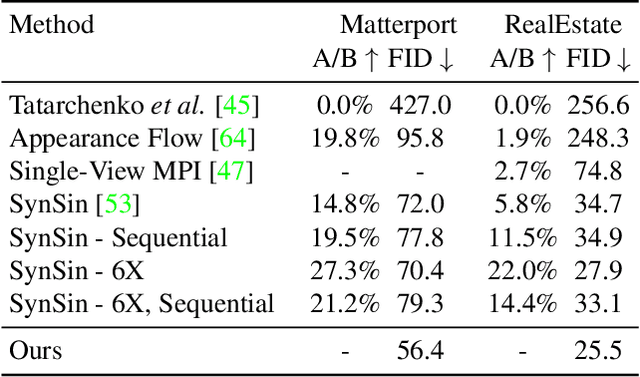


Recent advancements in differentiable rendering and 3D reasoning have driven exciting results in novel view synthesis from a single image. Despite realistic results, methods are limited to relatively small view change. In order to synthesize immersive scenes, models must also be able to extrapolate. We present an approach that fuses 3D reasoning with autoregressive modeling to outpaint large view changes in a 3D-consistent manner, enabling scene synthesis. We demonstrate considerable improvement in single image large-angle view synthesis results compared to a variety of methods and possible variants across simulated and real datasets. In addition, we show increased 3D consistency compared to alternative accumulation methods. Project website: https://crockwell.github.io/pixelsynth/
Online Deep Equilibrium Learning for Regularization by Denoising
May 25, 2022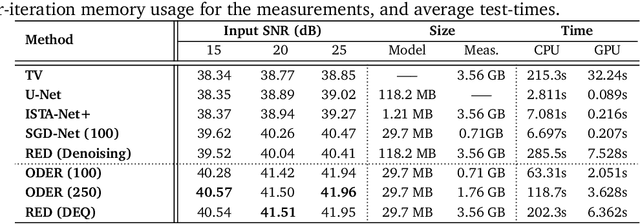
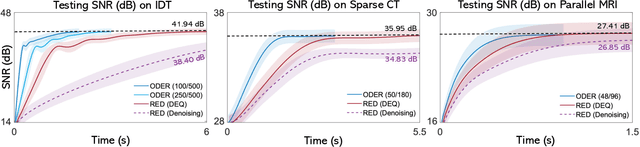
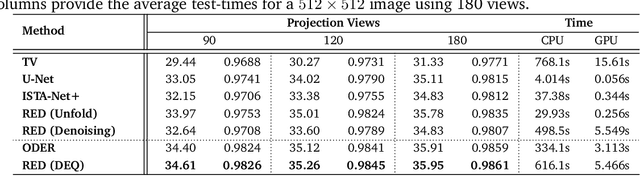
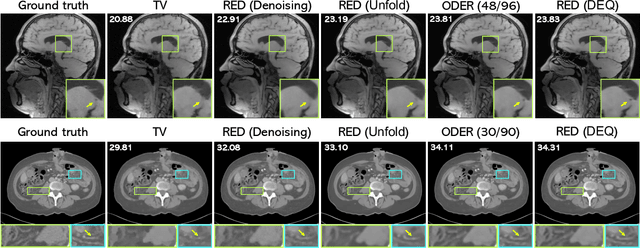
Plug-and-Play Priors (PnP) and Regularization by Denoising (RED) are widely-used frameworks for solving imaging inverse problems by computing fixed-points of operators combining physical measurement models and learned image priors. While traditional PnP/RED formulations have focused on priors specified using image denoisers, there is a growing interest in learning PnP/RED priors that are end-to-end optimal. The recent Deep Equilibrium Models (DEQ) framework has enabled memory-efficient end-to-end learning of PnP/RED priors by implicitly differentiating through the fixed-point equations without storing intermediate activation values. However, the dependence of the computational/memory complexity of the measurement models in PnP/RED on the total number of measurements leaves DEQ impractical for many imaging applications. We propose ODER as a new strategy for improving the efficiency of DEQ through stochastic approximations of the measurement models. We theoretically analyze ODER giving insights into its convergence and ability to approximate the traditional DEQ approach. Our numerical results suggest the potential improvements in training/testing complexity due to ODER on three distinct imaging applications.
MEDUSA: Multi-scale Encoder-Decoder Self-Attention Deep Neural Network Architecture for Medical Image Analysis
Oct 12, 2021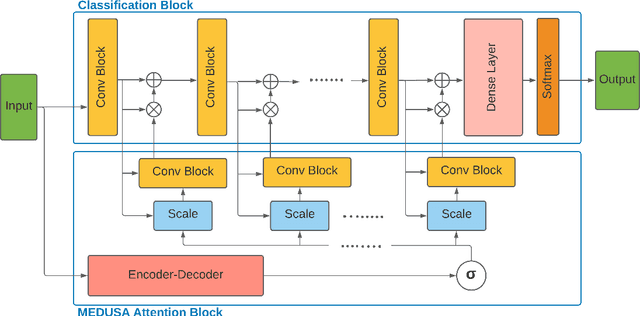
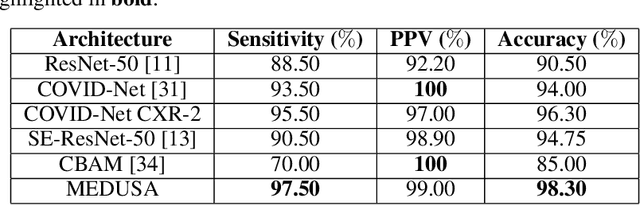
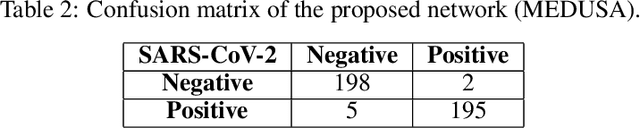
Medical image analysis continues to hold interesting challenges given the subtle characteristics of certain diseases and the significant overlap in appearance between diseases. In this work, we explore the concept of self-attention for tackling such subtleties in and between diseases. To this end, we introduce MEDUSA, a multi-scale encoder-decoder self-attention mechanism tailored for medical image analysis. While self-attention deep convolutional neural network architectures in existing literature center around the notion of multiple isolated lightweight attention mechanisms with limited individual capacities being incorporated at different points in the network architecture, MEDUSA takes a significant departure from this notion by possessing a single, unified self-attention mechanism with significantly higher capacity with multiple attention heads feeding into different scales in the network architecture. To the best of the authors' knowledge, this is the first "single body, multi-scale heads" realization of self-attention and enables explicit global context amongst selective attention at different levels of representational abstractions while still enabling differing local attention context at individual levels of abstractions. With MEDUSA, we obtain state-of-the-art performance on multiple challenging medical image analysis benchmarks including COVIDx, RSNA RICORD, and RSNA Pneumonia Challenge when compared to previous work. Our MEDUSA model is publicly available.
A Hybrid Convolutional Neural Network with Meta Feature Learning for Abnormality Detection in Wireless Capsule Endoscopy Images
Jul 20, 2022
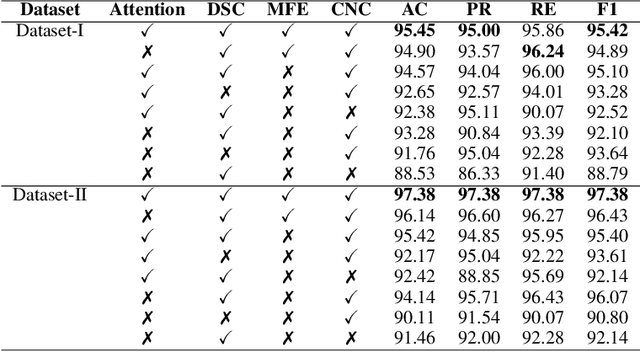
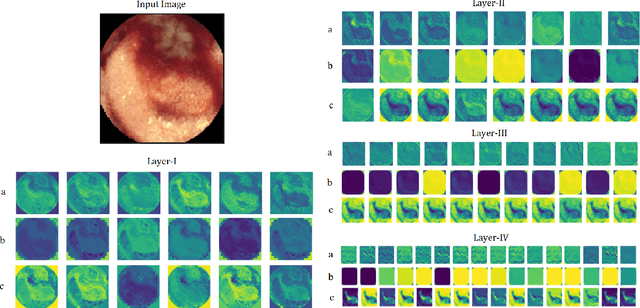
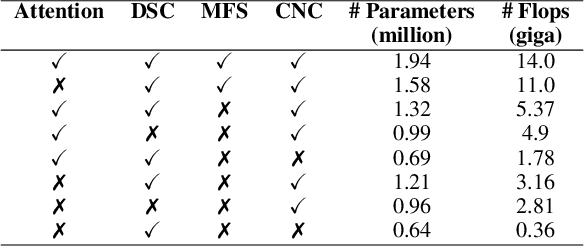
Wireless Capsule Endoscopy is one of the most advanced non-invasive methods for the examination of gastrointestinal tracts. An intelligent computer-aided diagnostic system for detecting gastrointestinal abnormalities like polyp, bleeding, inflammation, etc. is highly exigent in wireless capsule endoscopy image analysis. Abnormalities greatly differ in their shape, size, color, and texture, and some appear to be visually similar to normal regions. This poses a challenge in designing a binary classifier due to intra-class variations. In this study, a hybrid convolutional neural network is proposed for abnormality detection that extracts a rich pool of meaningful features from wireless capsule endoscopy images using a variety of convolution operations. It consists of three parallel convolutional neural networks, each with a distinctive feature learning capability. The first network utilizes depthwise separable convolution, while the second employs cosine normalized convolution operation. A novel meta-feature extraction mechanism is introduced in the third network, to extract patterns from the statistical information drawn over the features generated from the first and second networks and its own previous layer. The network trio effectively handles intra-class variance and efficiently detects gastrointestinal abnormalities. The proposed hybrid convolutional neural network model is trained and tested on two widely used publicly available datasets. The test results demonstrate that the proposed model outperforms six state-of-the-art methods with 97\% and 98\% classification accuracy on KID and Kvasir-Capsule datasets respectively. Cross dataset evaluation results also demonstrate the generalization performance of the proposed model.
Raw Bayer Pattern Image Synthesis with Conditional GAN
Oct 25, 2021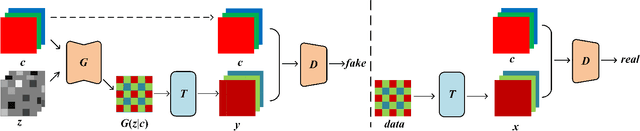
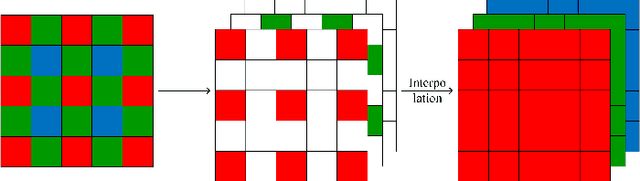

In this paper, we propose a method to generate Bayer pattern images by Generative adversarial network (GANs). It is shown theoretically that using the transformed data in GANs training is able to improve the generator learning of the original data distribution, owing to the invariant of Jensen Shannon(JS) divergence between two distributions under invertible and differentiable transformation. The Bayer pattern images can be generated by configuring the transformation as demosaicing, by converting the existing standard color datasets to Bayer domain, the proposed method is promising in the applications such as to find the optimal ISP configuration for computer vision tasks, in the in sensor or near sensor computing, even in photography. Experiments show that the images generated by our proposed method outperform the original Pix2PixHD model in FID score, PSNR, and SSIM, and the training process is more stable. For the situation similar to in sensor or near sensor computing for object detection, by using our proposed method, the model performance can be improved without the modification to the image sensor.
Reverse image filtering using total derivative approximation and accelerated gradient descent
Dec 08, 2021
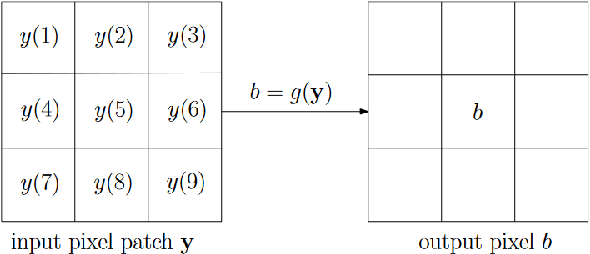
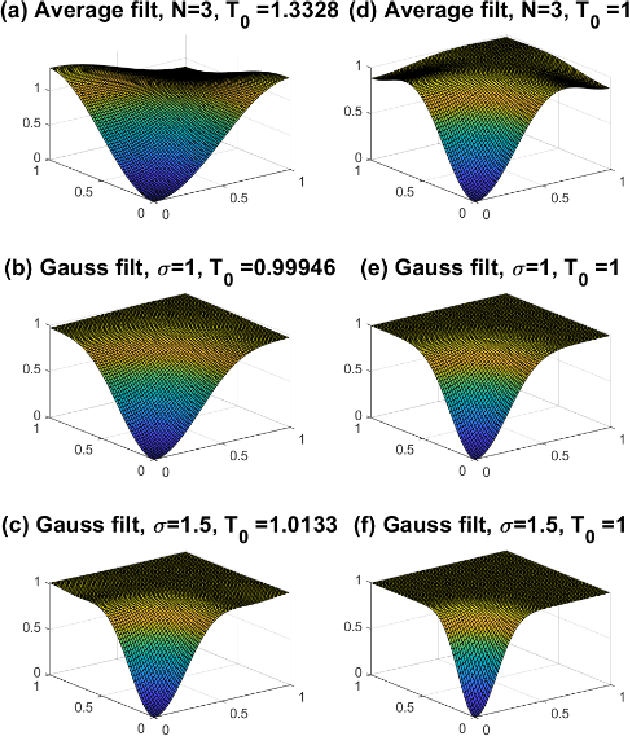

In this paper, we address a new problem of reversing the effect of an image filter, which can be linear or nonlinear. The assumption is that the algorithm of the filter is unknown and the filter is available as a black box. We formulate this inverse problem as minimizing a local patch-based cost function and use total derivative to approximate the gradient which is used in gradient descent to solve the problem. We analyze factors affecting the convergence and quality of the output in the Fourier domain. We also study the application of accelerated gradient descent algorithms in three gradient-free reverse filters, including the one proposed in this paper. We present results from extensive experiments to evaluate the complexity and effectiveness of the proposed algorithm. Results demonstrate that the proposed algorithm outperforms the state-of-the-art in that (1) it is at the same level of complexity as that of the fastest reverse filter, but it can reverse a larger number of filters, and (2) it can reverse the same list of filters as that of the very complex reverse filter, but its complexity is much smaller.