 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Simplified Un-Supervised Learning Based Approach for Ink Mismatch Detection in Handwritten Hyper-Spectral Document Images
Jun 11, 2022
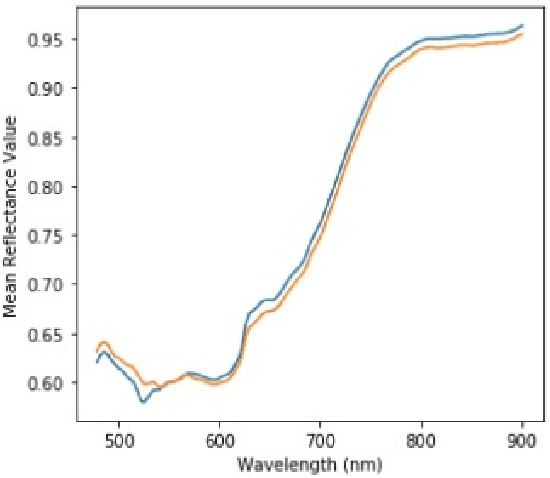
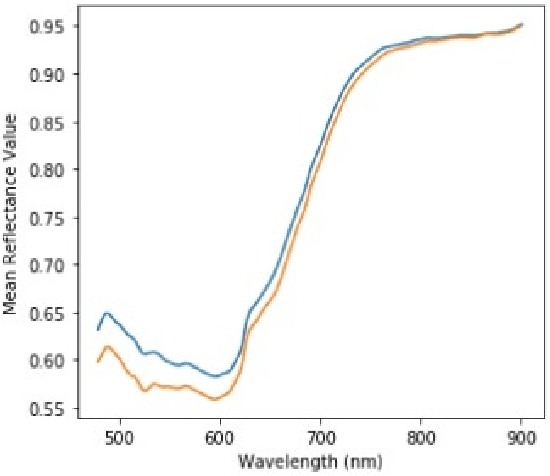
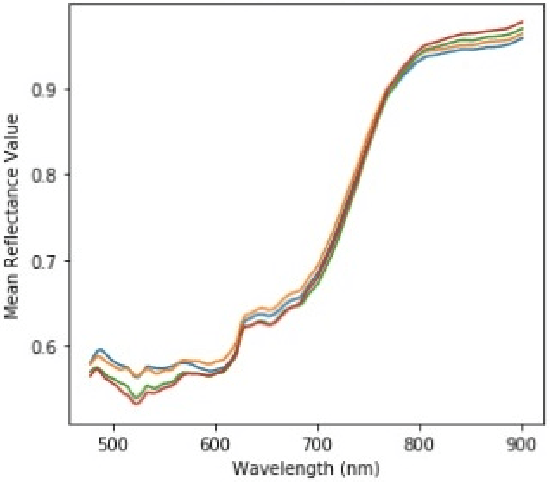
Hyper-spectral imaging has become the latest trend in the field of optical imaging systems. Among various other applications, hyper-spectral imaging has been widely used for analysis of printed and handwritten documents. This paper proposes an efficient technique for estimating the number of different but visibly similar inks present in a Hyper spectral Document Image. Our approach is based on un-supervised learning and does not require any prior knowledge of the dataset. The algorithm was tested on the iVision HHID dataset and has achieved comparable results with the state of the algorithms present in the literature. This work can prove to be effective when employed during the early stages of forgery detection in Hyper-spectral Document Images.
GLiT: Neural Architecture Search for Global and Local Image Transformer
Jul 07, 2021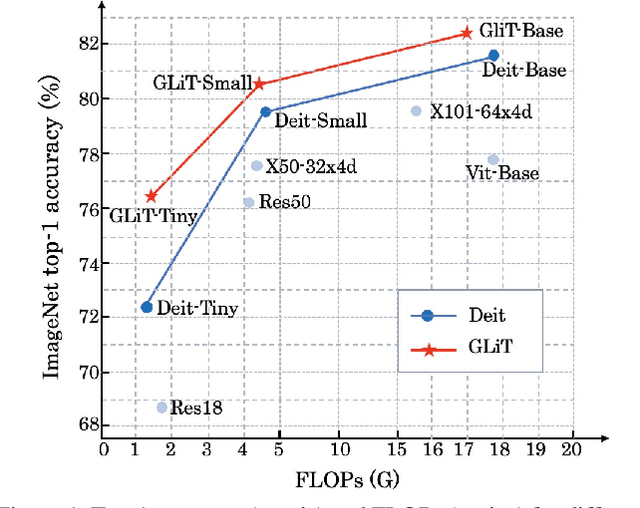
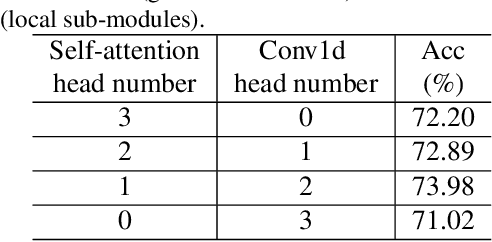
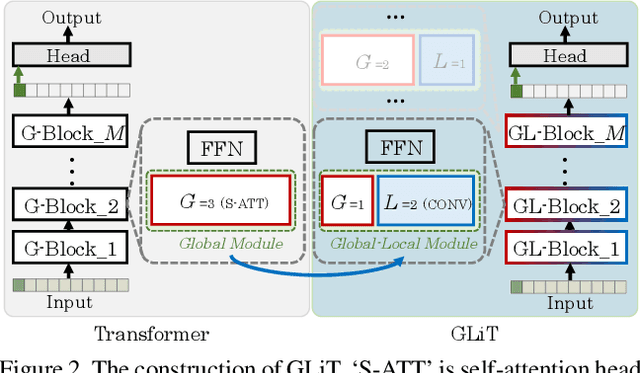

We introduce the first Neural Architecture Search (NAS) method to find a better transformer architecture for image recognition. Recently, transformers without CNN-based backbones are found to achieve impressive performance for image recognition. However, the transformer is designed for NLP tasks and thus could be sub-optimal when directly used for image recognition. In order to improve the visual representation ability for transformers, we propose a new search space and searching algorithm. Specifically, we introduce a locality module that models the local correlations in images explicitly with fewer computational cost. With the locality module, our search space is defined to let the search algorithm freely trade off between global and local information as well as optimizing the low-level design choice in each module. To tackle the problem caused by huge search space, a hierarchical neural architecture search method is proposed to search the optimal vision transformer from two levels separately with the evolutionary algorithm. Extensive experiments on the ImageNet dataset demonstrate that our method can find more discriminative and efficient transformer variants than the ResNet family (e.g., ResNet101) and the baseline ViT for image classification.
Self-Supervised Learning for Real-World Super-Resolution from Dual Zoomed Observations
Mar 02, 2022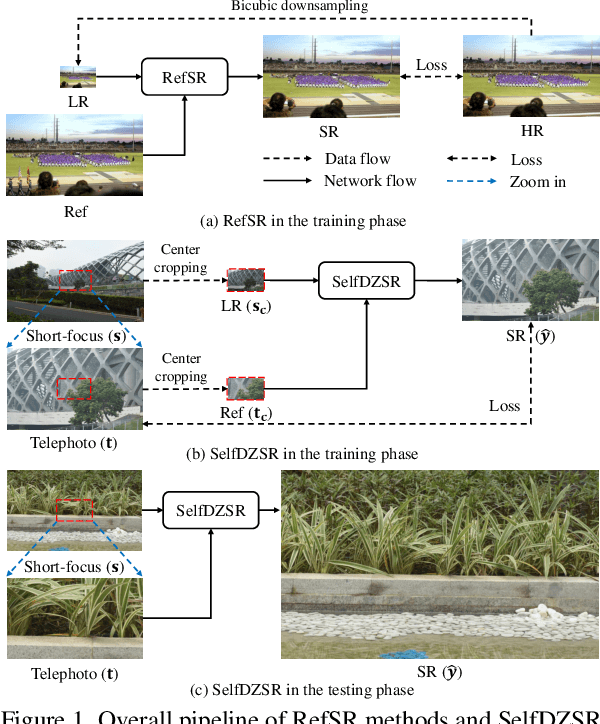
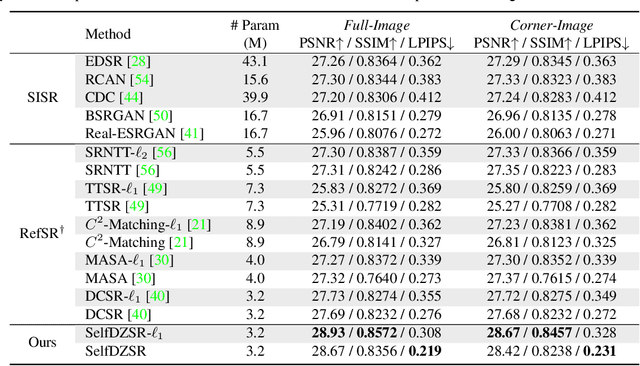

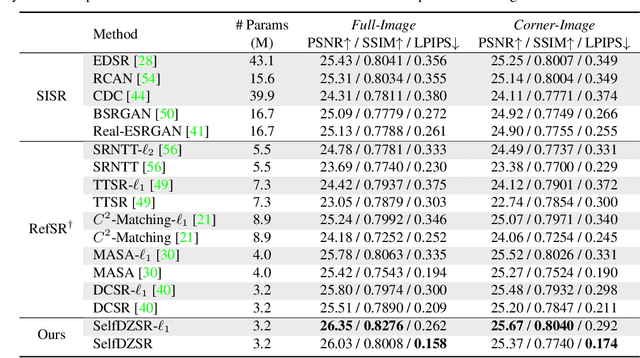
In this paper, we consider two challenging issues in reference-based super-resolution (RefSR), (i) how to choose a proper reference image, and (ii) how to learn real-world RefSR in a self-supervised manner. Particularly, we present a novel self-supervised learning approach for real-world image SR from observations at dual camera zooms (SelfDZSR). For the first issue, the more zoomed (telephoto) image can be naturally leveraged as the reference to guide the SR of the lesser zoomed (short-focus) image. For the second issue, SelfDZSR learns a deep network to obtain the SR result of short-focal image and with the same resolution as the telephoto image. For this purpose, we take the telephoto image instead of an additional high-resolution image as the supervision information and select a patch from it as the reference to super-resolve the corresponding short-focus image patch. To mitigate the effect of various misalignment between the short-focus low-resolution (LR) image and telephoto ground-truth (GT) image, we design a degradation model and map the GT to a pseudo-LR image aligned with GT. Then the pseudo-LR and LR image can be fed into the proposed adaptive spatial transformer networks (AdaSTN) to deform the LR features. During testing, SelfDZSR can be directly deployed to super-solve the whole short-focus image with the reference of telephoto image. Experiments show that our method achieves better quantitative and qualitative performance against state-of-the-arts. The code and pre-trained models will be publicly available.
Adversarial Robustness Assessment of NeuroEvolution Approaches
Jul 12, 2022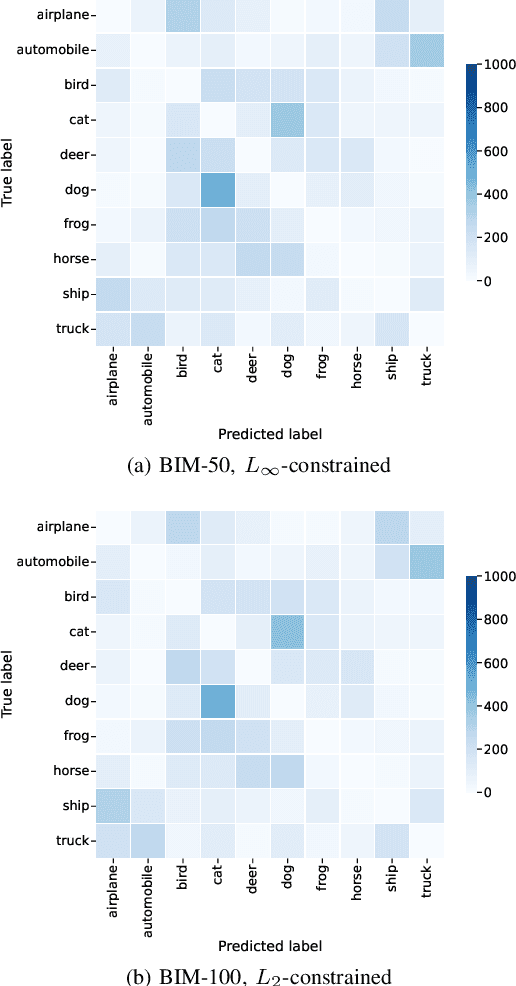
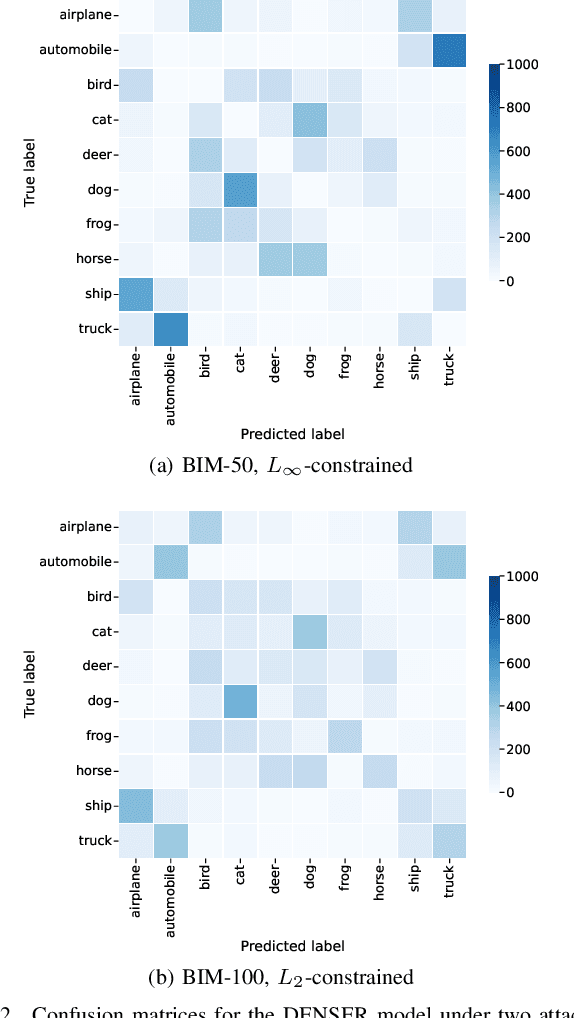
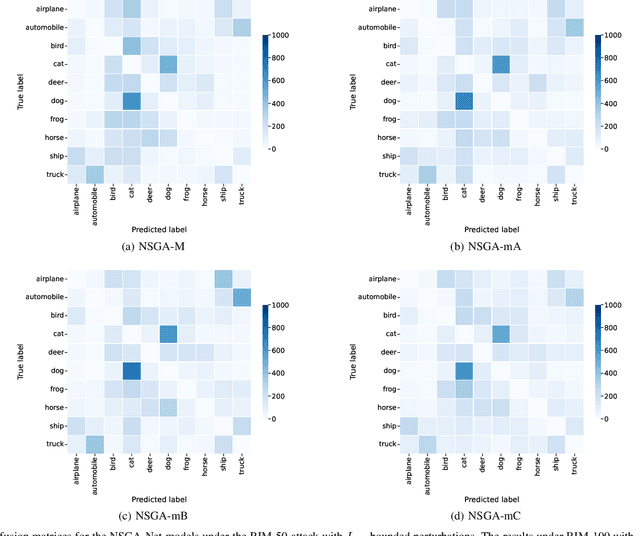
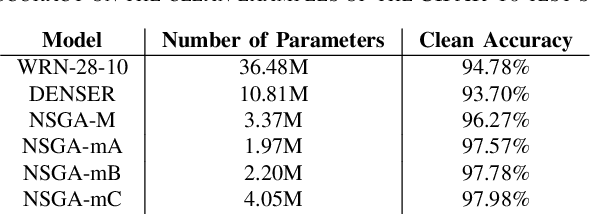
NeuroEvolution automates the generation of Artificial Neural Networks through the application of techniques from Evolutionary Computation. The main goal of these approaches is to build models that maximize predictive performance, sometimes with an additional objective of minimizing computational complexity. Although the evolved models achieve competitive results performance-wise, their robustness to adversarial examples, which becomes a concern in security-critical scenarios, has received limited attention. In this paper, we evaluate the adversarial robustness of models found by two prominent NeuroEvolution approaches on the CIFAR-10 image classification task: DENSER and NSGA-Net. Since the models are publicly available, we consider white-box untargeted attacks, where the perturbations are bounded by either the L2 or the Linfinity-norm. Similarly to manually-designed networks, our results show that when the evolved models are attacked with iterative methods, their accuracy usually drops to, or close to, zero under both distance metrics. The DENSER model is an exception to this trend, showing some resistance under the L2 threat model, where its accuracy only drops from 93.70% to 18.10% even with iterative attacks. Additionally, we analyzed the impact of pre-processing applied to the data before the first layer of the network. Our observations suggest that some of these techniques can exacerbate the perturbations added to the original inputs, potentially harming robustness. Thus, this choice should not be neglected when automatically designing networks for applications where adversarial attacks are prone to occur.
Calibrating the Dice loss to handle neural network overconfidence for biomedical image segmentation
Oct 31, 2021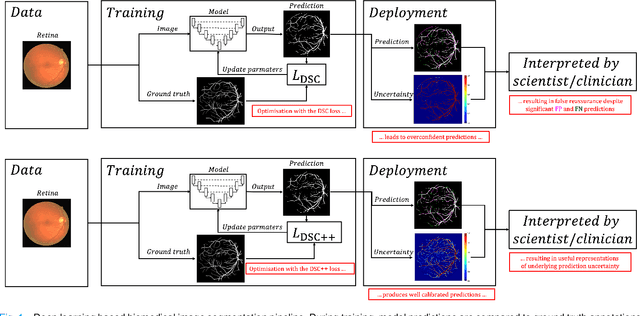
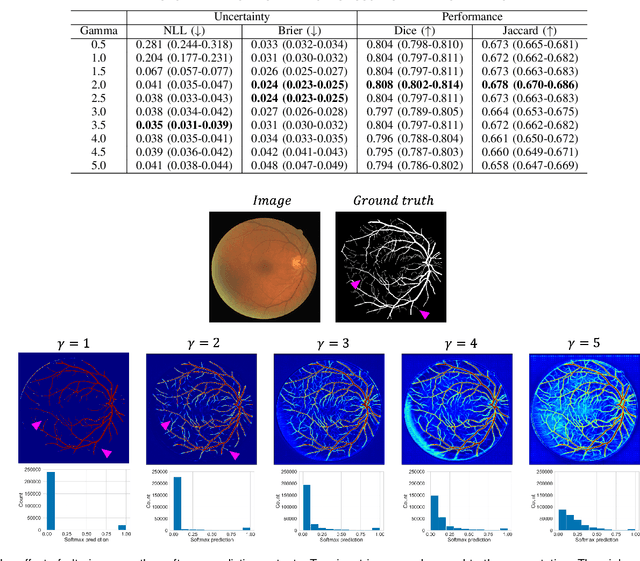
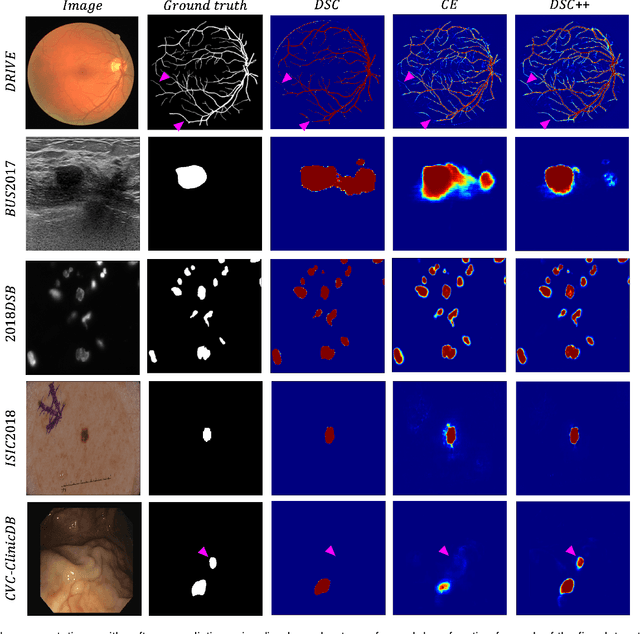
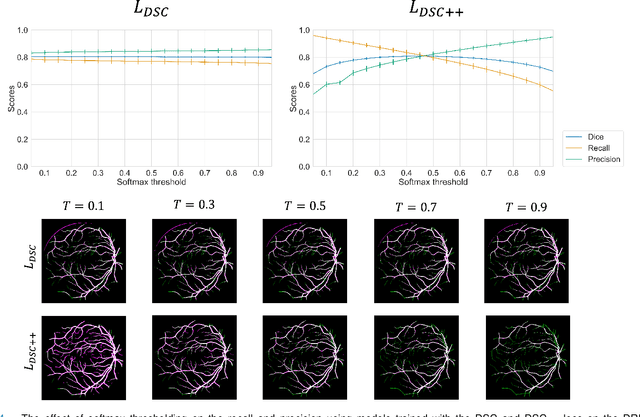
The Dice similarity coefficient (DSC) is both a widely used metric and loss function for biomedical image segmentation due to its robustness to class imbalance. However, it is well known that the DSC loss is poorly calibrated, resulting in overconfident predictions that cannot be usefully interpreted in biomedical and clinical practice. Performance is often the only metric used to evaluate segmentations produced by deep neural networks, and calibration is often neglected. However, calibration is important for translation into biomedical and clinical practice, providing crucial contextual information to model predictions for interpretation by scientists and clinicians. In this study, we identify poor calibration as an emerging challenge of deep learning based biomedical image segmentation. We provide a simple yet effective extension of the DSC loss, named the DSC++ loss, that selectively modulates the penalty associated with overconfident, incorrect predictions. As a standalone loss function, the DSC++ loss achieves significantly improved calibration over the conventional DSC loss across five well-validated open-source biomedical imaging datasets. Similarly, we observe significantly improved when integrating the DSC++ loss into four DSC-based loss functions. Finally, we use softmax thresholding to illustrate that well calibrated outputs enable tailoring of precision-recall bias, an important post-processing technique to adapt the model predictions to suit the biomedical or clinical task. The DSC++ loss overcomes the major limitation of the DSC, providing a suitable loss function for training deep learning segmentation models for use in biomedical and clinical practice.
FS-NCSR: Increasing Diversity of the Super-Resolution Space via Frequency Separation and Noise-Conditioned Normalizing Flow
Apr 20, 2022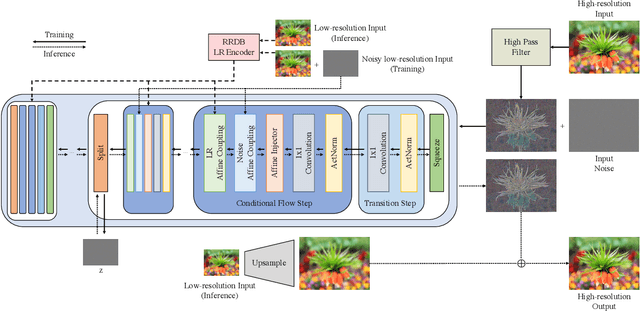
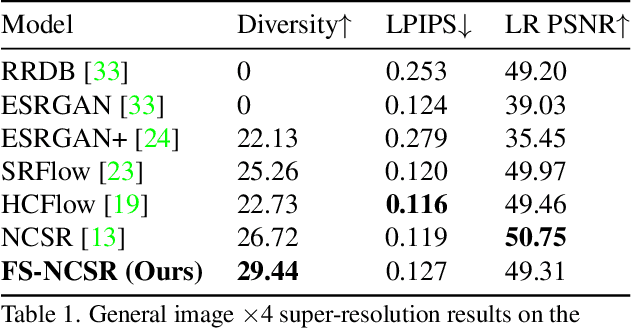

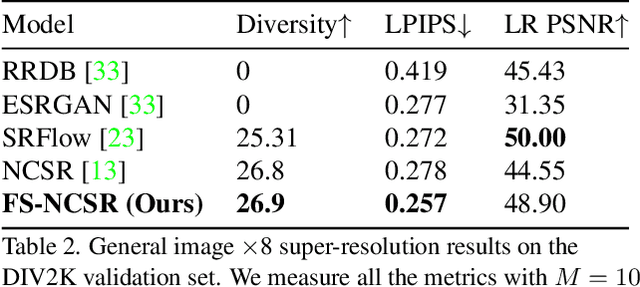
Super-resolution suffers from an innate ill-posed problem that a single low-resolution (LR) image can be from multiple high-resolution (HR) images. Recent studies on the flow-based algorithm solve this ill-posedness by learning the super-resolution space and predicting diverse HR outputs. Unfortunately, the diversity of the super-resolution outputs is still unsatisfactory, and the outputs from the flow-based model usually suffer from undesired artifacts which causes low-quality outputs. In this paper, we propose FS-NCSR which produces diverse and high-quality super-resolution outputs using frequency separation and noise conditioning compared to the existing flow-based approaches. As the sharpness and high-quality detail of the image rely on its high-frequency information, FS-NCSR only estimates the high-frequency information of the high-resolution outputs without redundant low-frequency components. Through this, FS-NCSR significantly improves the diversity score without significant image quality degradation compared to the NCSR, the winner of the previous NTIRE 2021 challenge.
Data variation-aware medical image segmentation
Feb 24, 2022
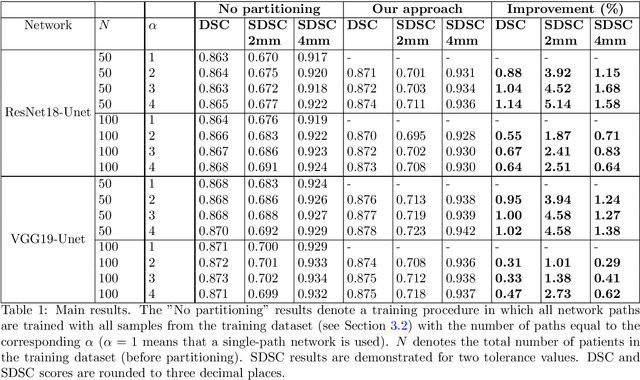
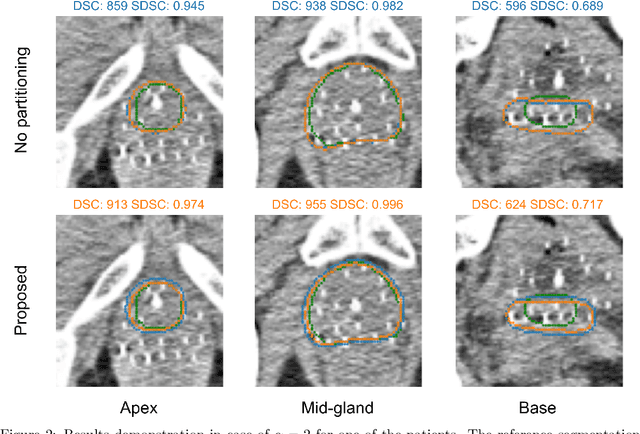
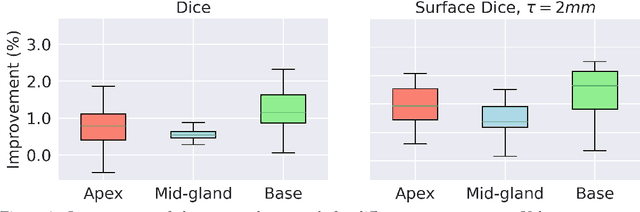
Deep learning algorithms have become the golden standard for segmentation of medical imaging data. In most works, the variability and heterogeneity of real clinical data is acknowledged to still be a problem. One way to automatically overcome this is to capture and exploit this variation explicitly. Here, we propose an approach that improves on our previous work in this area and explain how it potentially can improve clinical acceptance of (semi-)automatic segmentation methods. In contrast to a standard neural network that produces one segmentation, we propose to use a multi-pathUnet network that produces multiple segmentation variants, presumably corresponding to the variations that reside in the dataset. Different paths of the network are trained on disjoint data subsets. Because a priori it may be unclear what variations exist in the data, the subsets should be automatically determined. This is achieved by searching for the best data partitioning with an evolutionary optimization algorithm. Because each network path can become more specialized when trained on a more homogeneous data subset, better segmentation quality can be achieved. In practical usage, various automatically produced segmentations can be presented to a medical expert, from which the preferred segmentation can be selected. In experiments with a real clinical dataset of CT scans with prostate segmentations, our approach provides an improvement of several percentage points in terms of Dice and surface Dice coefficients compared to when all network paths are trained on all training data. Noticeably, the largest improvement occurs in the upper part of the prostate that is known to be most prone to inter-observer segmentation variation.
Predicting Out-of-Domain Generalization with Local Manifold Smoothness
Jul 05, 2022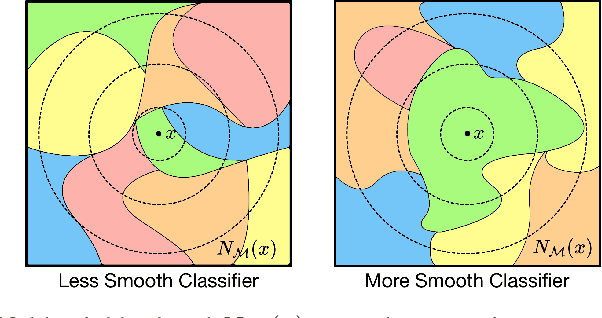

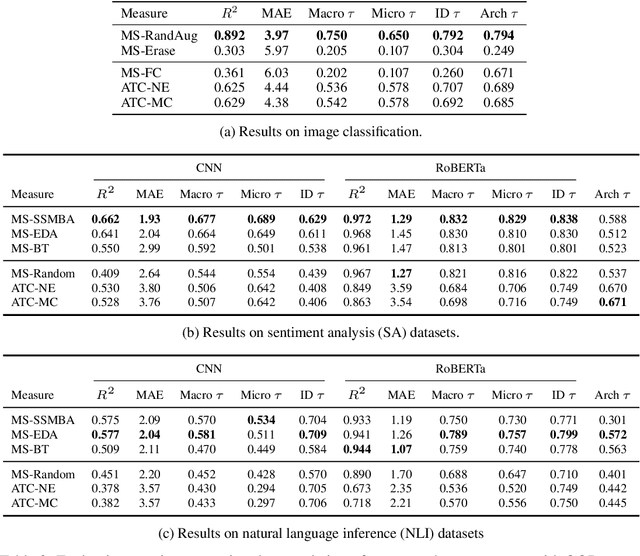
Understanding how machine learning models generalize to new environments is a critical part of their safe deployment. Recent work has proposed a variety of complexity measures that directly predict or theoretically bound the generalization capacity of a model. However, these methods rely on a strong set of assumptions that in practice are not always satisfied. Motivated by the limited settings in which existing measures can be applied, we propose a novel complexity measure based on the local manifold smoothness of a classifier. We define local manifold smoothness as a classifier's output sensitivity to perturbations in the manifold neighborhood around a given test point. Intuitively, a classifier that is less sensitive to these perturbations should generalize better. To estimate smoothness we sample points using data augmentation and measure the fraction of these points classified into the majority class. Our method only requires selecting a data augmentation method and makes no other assumptions about the model or data distributions, meaning it can be applied even in out-of-domain (OOD) settings where existing methods cannot. In experiments on robustness benchmarks in image classification, sentiment analysis, and natural language inference, we demonstrate a strong and robust correlation between our manifold smoothness measure and actual OOD generalization on over 3,000 models evaluated on over 100 train/test domain pairs.
CASHformer: Cognition Aware SHape Transformer for Longitudinal Analysis
Jul 05, 2022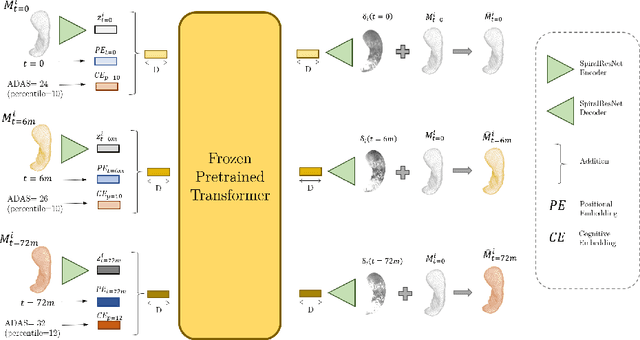
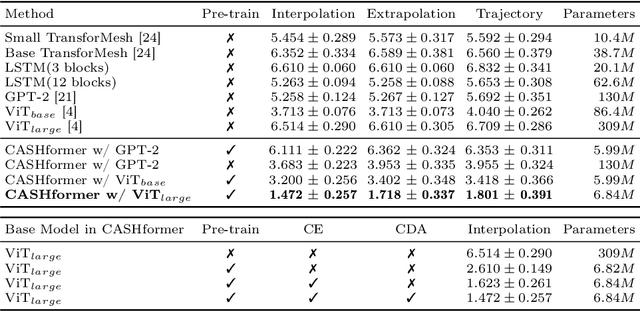
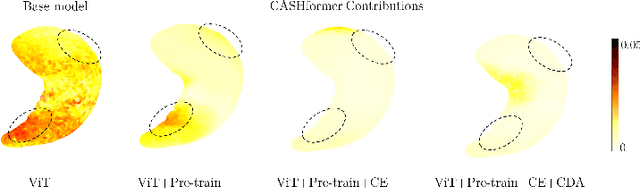
Modeling temporal changes in subcortical structures is crucial for a better understanding of the progression of Alzheimer's disease (AD). Given their flexibility to adapt to heterogeneous sequence lengths, mesh-based transformer architectures have been proposed in the past for predicting hippocampus deformations across time. However, one of the main limitations of transformers is the large amount of trainable parameters, which makes the application on small datasets very challenging. In addition, current methods do not include relevant non-image information that can help to identify AD-related patterns in the progression. To this end, we introduce CASHformer, a transformer-based framework to model longitudinal shape trajectories in AD. CASHformer incorporates the idea of pre-trained transformers as universal compute engines that generalize across a wide range of tasks by freezing most layers during fine-tuning. This reduces the number of parameters by over 90% with respect to the original model and therefore enables the application of large models on small datasets without overfitting. In addition, CASHformer models cognitive decline to reveal AD atrophy patterns in the temporal sequence. Our results show that CASHformer reduces the reconstruction error by 73% compared to previously proposed methods. Moreover, the accuracy of detecting patients progressing to AD increases by 3% with imputing missing longitudinal shape data.
Deep Dense Local Feature Matching and Vehicle Removal for Indoor Visual Localization
May 25, 2022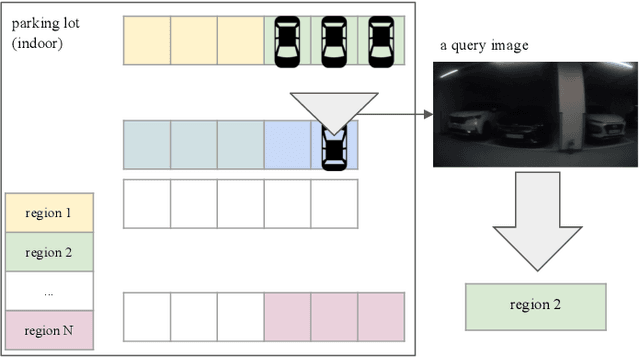


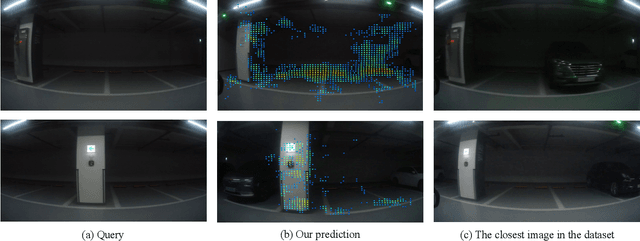
Visual localization is an essential component of intelligent transportation systems, enabling broad applications that require understanding one's self location when other sensors are not available. It is mostly tackled by image retrieval such that the location of a query image is determined by its closest match in the previously collected images. Existing approaches focus on large scale localization where landmarks are helpful in finding the location. However, visual localization becomes challenging in small scale environments where objects are hardly recognizable. In this paper, we propose a visual localization framework that robustly finds the match for a query among the images collected from indoor parking lots. It is a challenging problem when the vehicles in the images share similar appearances and are frequently replaced such as parking lots. We propose to employ a deep dense local feature matching that resembles human perception to find correspondences and eliminating matches from vehicles automatically with a vehicle detector. The proposed solution is robust to the scenes with low textures and invariant to false matches caused by vehicles. We compare our framework with alternatives to validate our superiority on a benchmark dataset containing 267 pre-collected images and 99 query images taken from 34 sections of a parking lot. Our method achieves 86.9 percent accuracy, outperforming the alternatives.