 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Gaussian Fourier Pyramid for Local Laplacian Filter
Jun 08, 2022
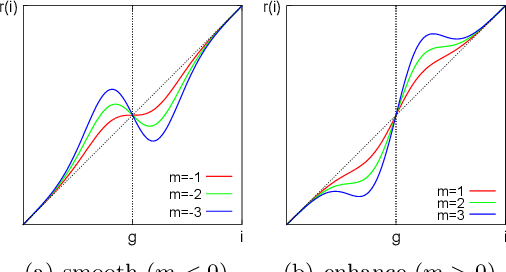
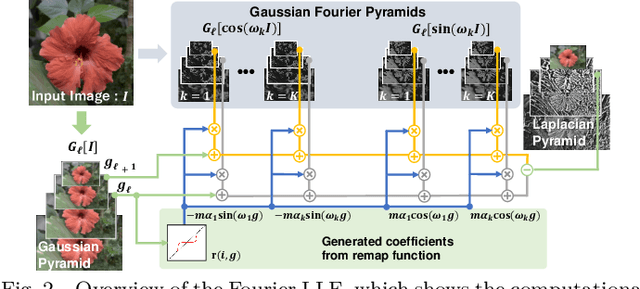

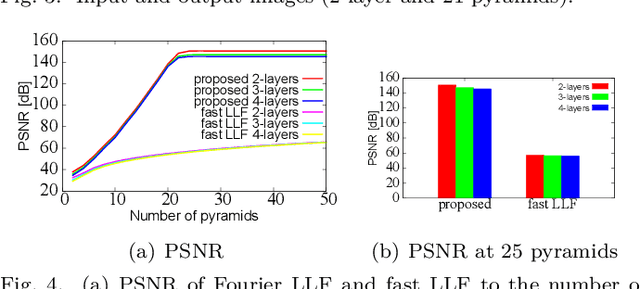
Multi-scale processing is essential in image processing and computer graphics. Halos are a central issue in multi-scale processing. Several edge-preserving decompositions resolve halos, e.g., local Laplacian filtering (LLF), by extending the Laplacian pyramid to have an edge-preserving property. Its processing is costly; thus, an approximated acceleration of fast LLF was proposed to linearly interpolate multiple Laplacian pyramids. This paper further improves the accuracy by Fourier series expansion, named Fourier LLF. Our results showed that Fourier LLF has a higher accuracy for the same number of pyramids. Moreover, Fourier LLF exhibits parameter-adaptive property for content-adaptive filtering. The code is available at: https://norishigefukushima.github.io/GaussianFourierPyramid/.
Segmenting white matter hyperintensities on isotropic three-dimensional Fluid Attenuated Inversion Recovery magnetic resonance images: A comparison of Deep learning tools on a Norwegian national imaging database
Jul 18, 2022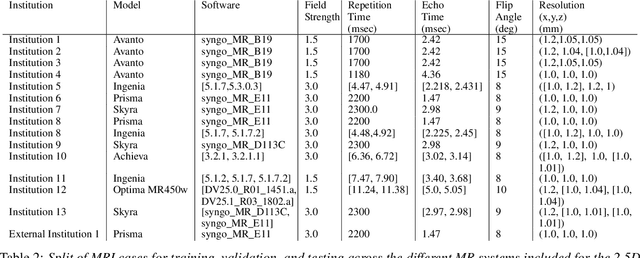
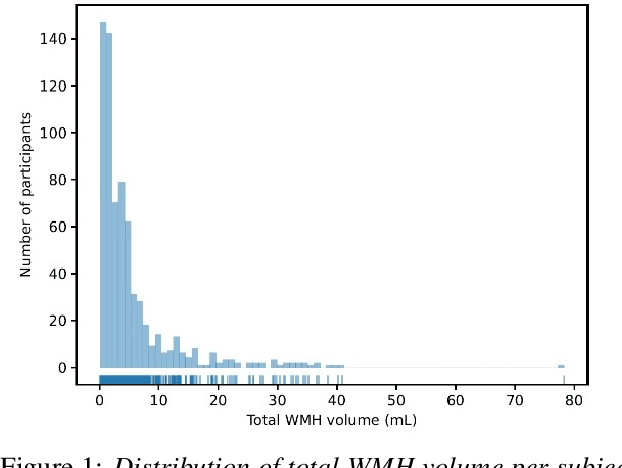

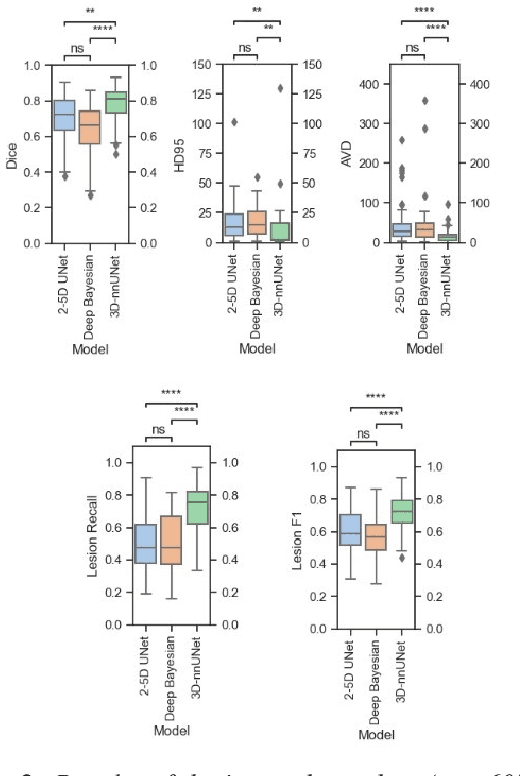
Introduction Automated segmentation of white matter hyperintensities (WMHs) is an essential step in neuroimaging analysis of Magnetic Resonance Imaging (MRI). Fluid Attenuated Inversion Recovery (FLAIR-weighted) is an MRI contrast that is particularly useful to visualize and quantify WMHs, a hallmark of cerebral small vessel disease and Alzheimer's disease (AD). Clinical MRI protocols migrate to a three-dimensional (3D) FLAIR-weighted acquisition to enable high spatial resolution in all three voxel dimensions. The current study details the deployment of deep learning tools to enable automated WMH segmentation and characterization from 3D FLAIR-weighted images acquired as part of a national AD imaging initiative. Materials and methods Among 642 participants (283 male, mean age: (65.18 +/- 9.33) years) from the DDI study, two in-house networks were trained and validated across five national collection sites. Three models were tested on a held-out subset of the internal data from the 642 participants and an external dataset with 29 cases from an international collaborator. These test sets were evaluated independently. Five established WMH performance metrics were used for comparison against ground truth human-in-the-loop segmentation. Results Of the three networks tested, the 3D nnU-Net had the best performance with an average dice similarity coefficient score of 0.78 +/- 0.10, performing better than both the in-house developed 2.5D model and the SOTA Deep Bayesian network. Conclusion With the increasing use of 3D FLAIR-weighted images in MRI protocols, our results suggest that WMH segmentation models can be trained on 3D data and yield WMH segmentation performance that is comparable to or better than state-of-the-art without the need for including T1-weighted image series.
FLVoogd: Robust And Privacy Preserving Federated Learning
Jun 24, 2022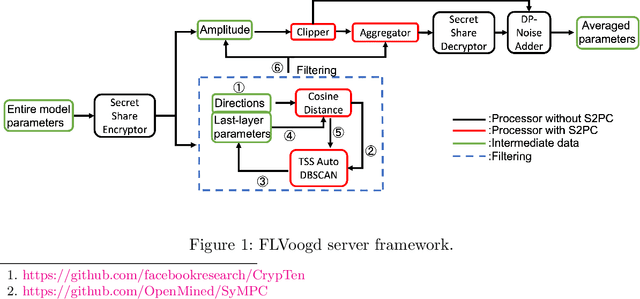

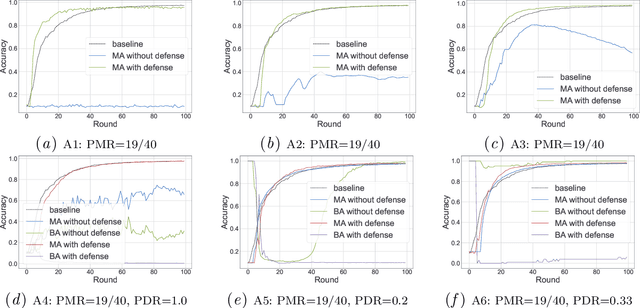
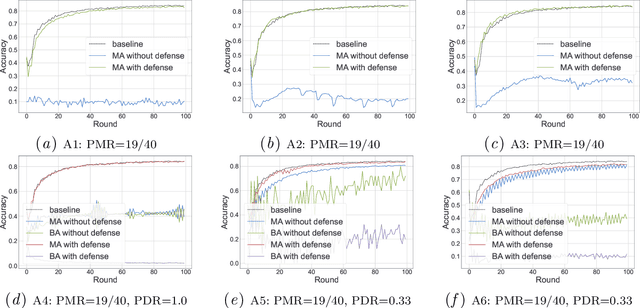
In this work, we propose FLVoogd, an updated federated learning method in which servers and clients collaboratively eliminate Byzantine attacks while preserving privacy. In particular, servers use automatic Density-based Spatial Clustering of Applications with Noise (DBSCAN) combined with S2PC to cluster the benign majority without acquiring sensitive personal information. Meanwhile, clients build dual models and perform test-based distance controlling to adjust their local models toward the global one to achieve personalizing. Our framework is automatic and adaptive that servers/clients don't need to tune the parameters during the training. In addition, our framework leverages Secure Multi-party Computation (SMPC) operations, including multiplications, additions, and comparison, where costly operations, like division and square root, are not required. Evaluations are carried out on some conventional datasets from the image classification field. The result shows that FLVoogd can effectively reject malicious uploads in most scenarios; meanwhile, it avoids data leakage from the server-side.
SynthTIGER: Synthetic Text Image GEneratoR Towards Better Text Recognition Models
Jul 20, 2021

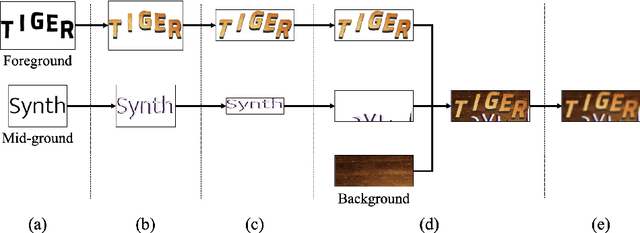
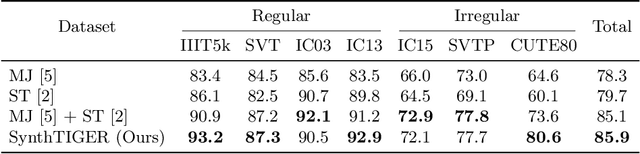
For successful scene text recognition (STR) models, synthetic text image generators have alleviated the lack of annotated text images from the real world. Specifically, they generate multiple text images with diverse backgrounds, font styles, and text shapes and enable STR models to learn visual patterns that might not be accessible from manually annotated data. In this paper, we introduce a new synthetic text image generator, SynthTIGER, by analyzing techniques used for text image synthesis and integrating effective ones under a single algorithm. Moreover, we propose two techniques that alleviate the long-tail problem in length and character distributions of training data. In our experiments, SynthTIGER achieves better STR performance than the combination of synthetic datasets, MJSynth (MJ) and SynthText (ST). Our ablation study demonstrates the benefits of using sub-components of SynthTIGER and the guideline on generating synthetic text images for STR models. Our implementation is publicly available at https://github.com/clovaai/synthtiger.
Lessons learned from the NeurIPS 2021 MetaDL challenge: Backbone fine-tuning without episodic meta-learning dominates for few-shot learning image classification
Jun 15, 2022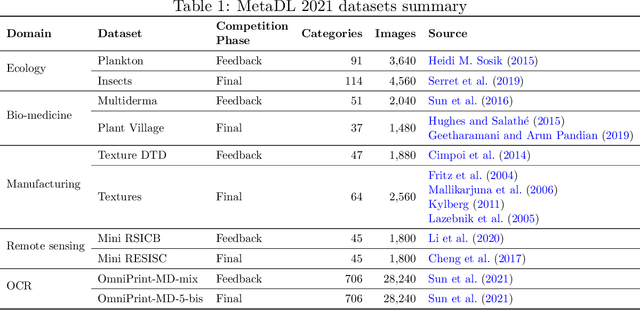

Although deep neural networks are capable of achieving performance superior to humans on various tasks, they are notorious for requiring large amounts of data and computing resources, restricting their success to domains where such resources are available. Metalearning methods can address this problem by transferring knowledge from related tasks, thus reducing the amount of data and computing resources needed to learn new tasks. We organize the MetaDL competition series, which provide opportunities for research groups all over the world to create and experimentally assess new meta-(deep)learning solutions for real problems. In this paper, authored collaboratively between the competition organizers and the top-ranked participants, we describe the design of the competition, the datasets, the best experimental results, as well as the top-ranked methods in the NeurIPS 2021 challenge, which attracted 15 active teams who made it to the final phase (by outperforming the baseline), making over 100 code submissions during the feedback phase. The solutions of the top participants have been open-sourced. The lessons learned include that learning good representations is essential for effective transfer learning.
Competence-based Multimodal Curriculum Learning for Medical Report Generation
Jun 24, 2022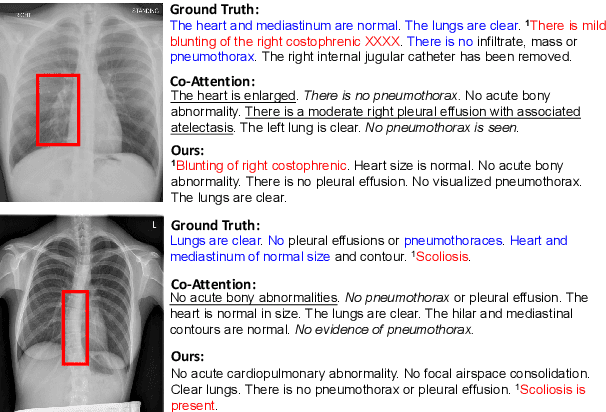
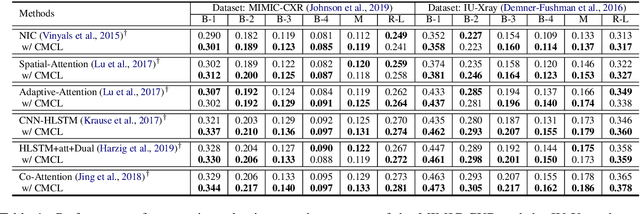
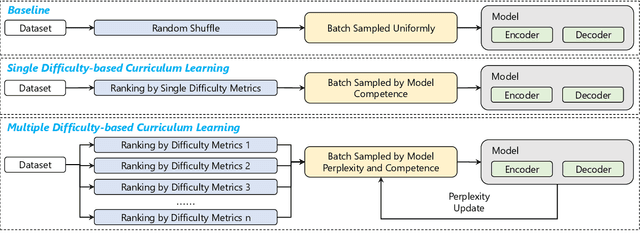
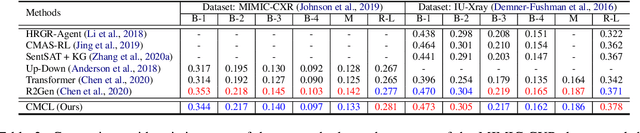
Medical report generation task, which targets to produce long and coherent descriptions of medical images, has attracted growing research interests recently. Different from the general image captioning tasks, medical report generation is more challenging for data-driven neural models. This is mainly due to 1) the serious data bias and 2) the limited medical data. To alleviate the data bias and make best use of available data, we propose a Competence-based Multimodal Curriculum Learning framework (CMCL). Specifically, CMCL simulates the learning process of radiologists and optimizes the model in a step by step manner. Firstly, CMCL estimates the difficulty of each training instance and evaluates the competence of current model; Secondly, CMCL selects the most suitable batch of training instances considering current model competence. By iterating above two steps, CMCL can gradually improve the model's performance. The experiments on the public IU-Xray and MIMIC-CXR datasets show that CMCL can be incorporated into existing models to improve their performance.
The General sampling theorem, Compressed sensing and a method of image sampling and reconstruction with sampling rates close to the theoretical limit
Oct 17, 2021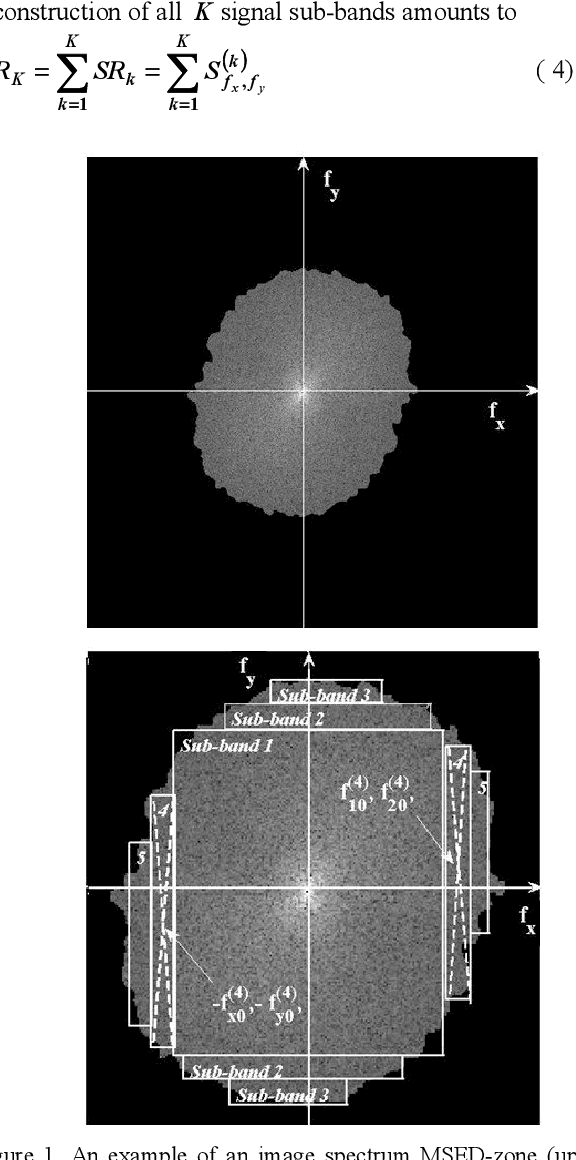

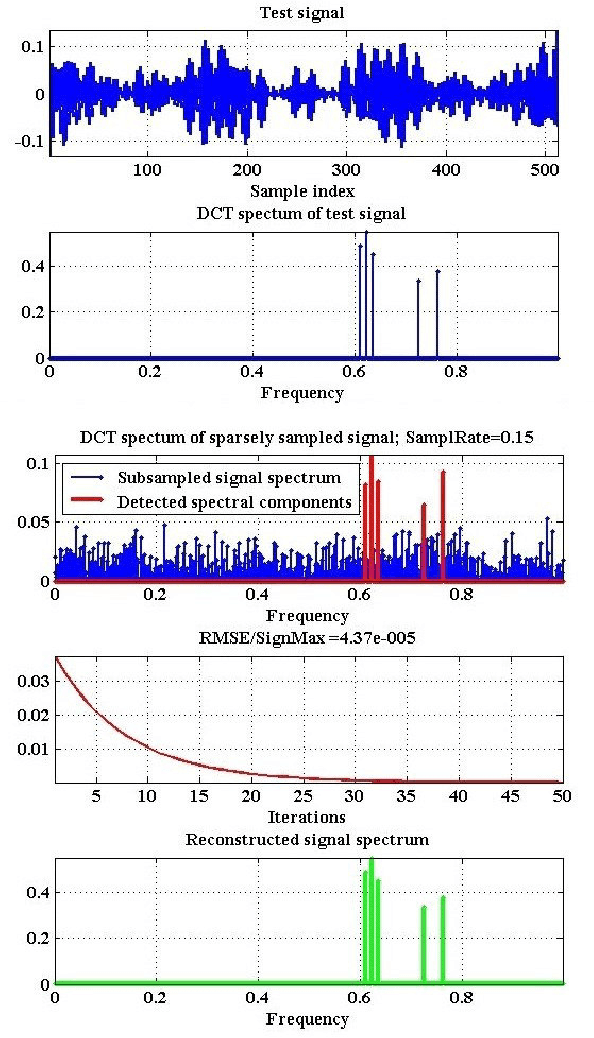
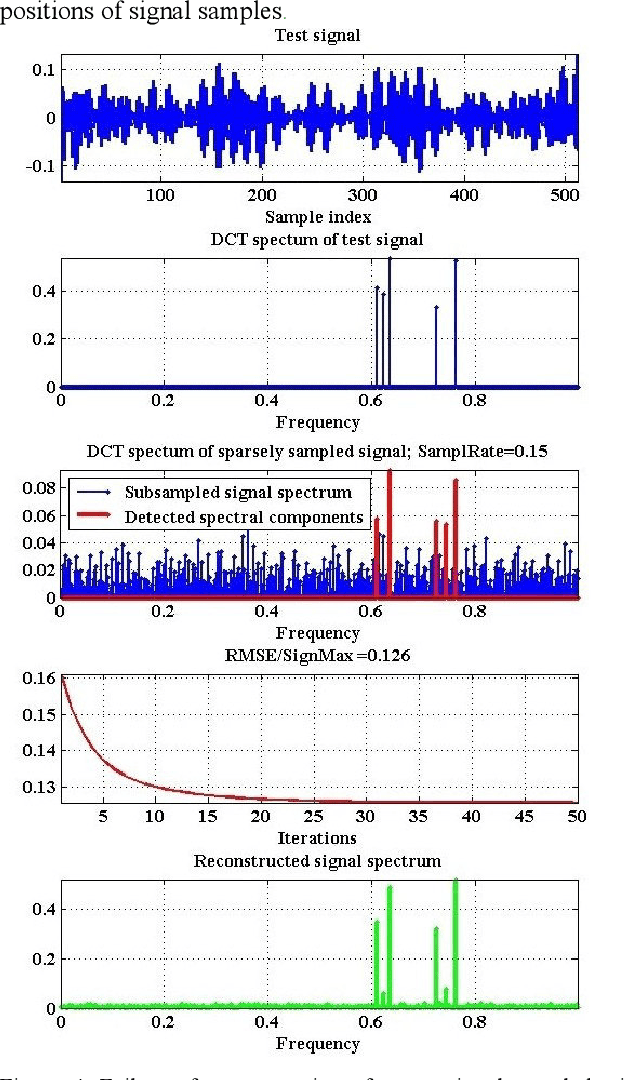
The article addresses the problem of image sampling with minimal possible sampling rates and reviews the recent advances in sampling theory and methods: modern formulations of the sampling theorems, potentials and limitations of Compressed sensing methods and a practical method of image sampling and reconstruction with sampling rates close to the theoretical minimum.
Multi-label Iterated Learning for Image Classification with Label Ambiguity
Nov 23, 2021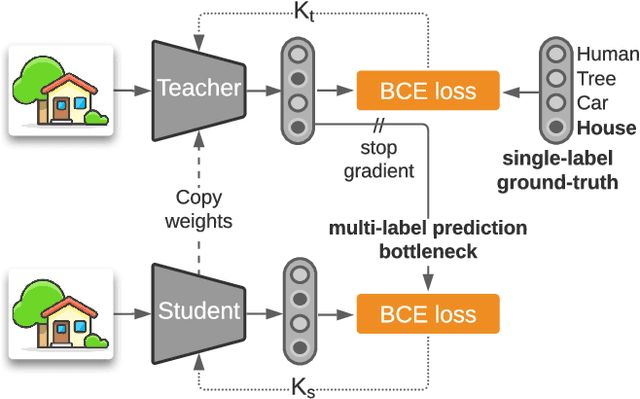
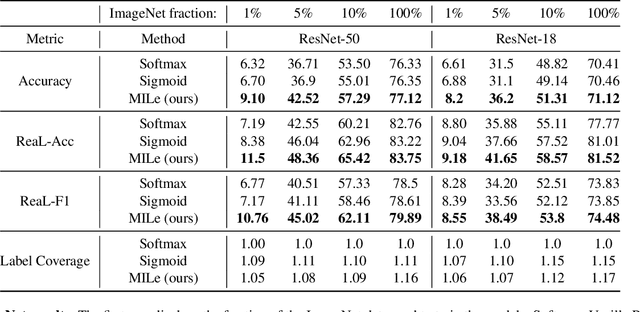

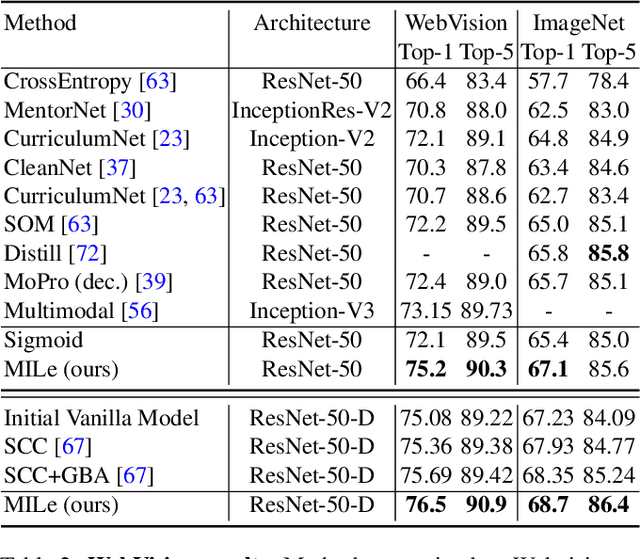
Transfer learning from large-scale pre-trained models has become essential for many computer vision tasks. Recent studies have shown that datasets like ImageNet are weakly labeled since images with multiple object classes present are assigned a single label. This ambiguity biases models towards a single prediction, which could result in the suppression of classes that tend to co-occur in the data. Inspired by language emergence literature, we propose multi-label iterated learning (MILe) to incorporate the inductive biases of multi-label learning from single labels using the framework of iterated learning. MILe is a simple yet effective procedure that builds a multi-label description of the image by propagating binary predictions through successive generations of teacher and student networks with a learning bottleneck. Experiments show that our approach exhibits systematic benefits on ImageNet accuracy as well as ReaL F1 score, which indicates that MILe deals better with label ambiguity than the standard training procedure, even when fine-tuning from self-supervised weights. We also show that MILe is effective reducing label noise, achieving state-of-the-art performance on real-world large-scale noisy data such as WebVision. Furthermore, MILe improves performance in class incremental settings such as IIRC and it is robust to distribution shifts. Code: https://github.com/rajeswar18/MILe
A Simplified Un-Supervised Learning Based Approach for Ink Mismatch Detection in Handwritten Hyper-Spectral Document Images
Jun 11, 2022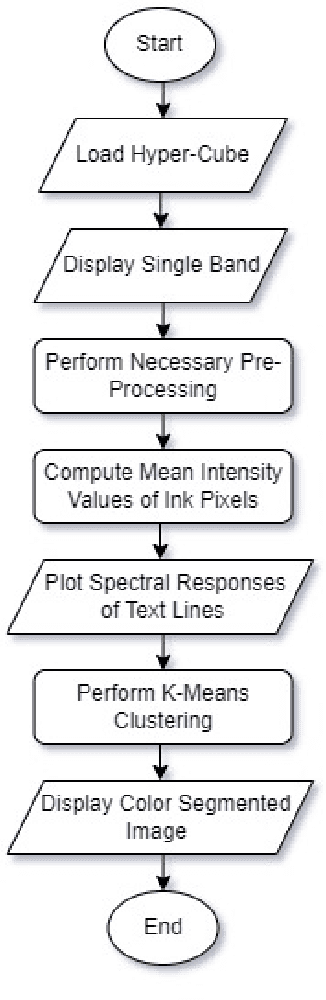
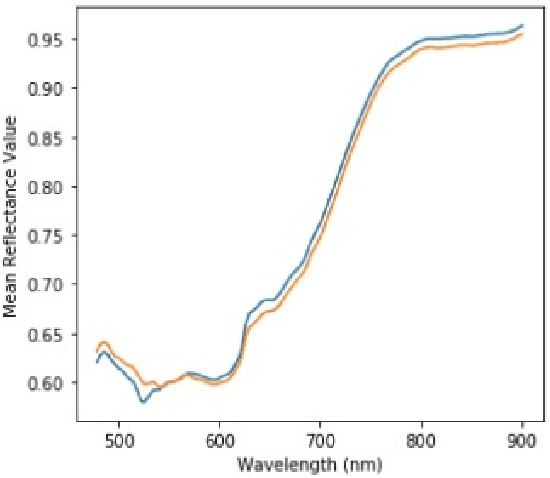
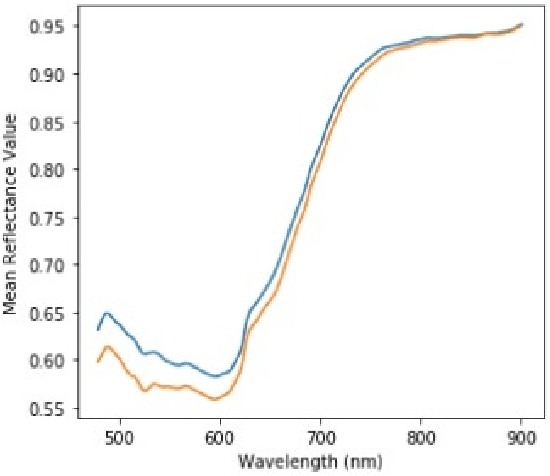
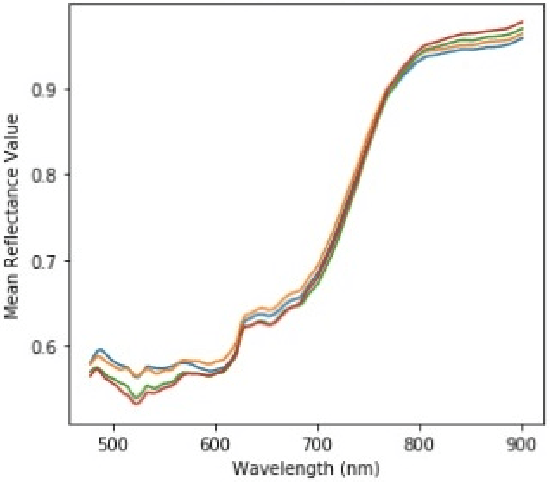
Hyper-spectral imaging has become the latest trend in the field of optical imaging systems. Among various other applications, hyper-spectral imaging has been widely used for analysis of printed and handwritten documents. This paper proposes an efficient technique for estimating the number of different but visibly similar inks present in a Hyper spectral Document Image. Our approach is based on un-supervised learning and does not require any prior knowledge of the dataset. The algorithm was tested on the iVision HHID dataset and has achieved comparable results with the state of the algorithms present in the literature. This work can prove to be effective when employed during the early stages of forgery detection in Hyper-spectral Document Images.
Scalable Image Coding for Humans and Machines
Jul 18, 2021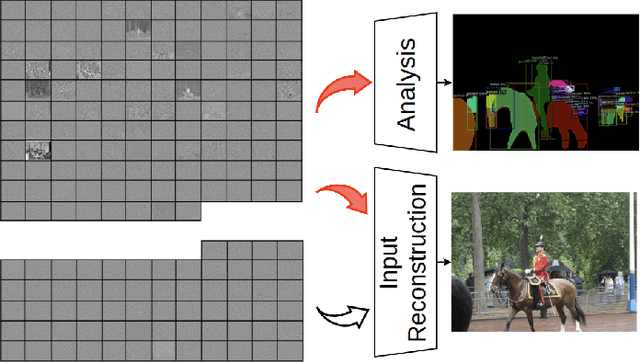
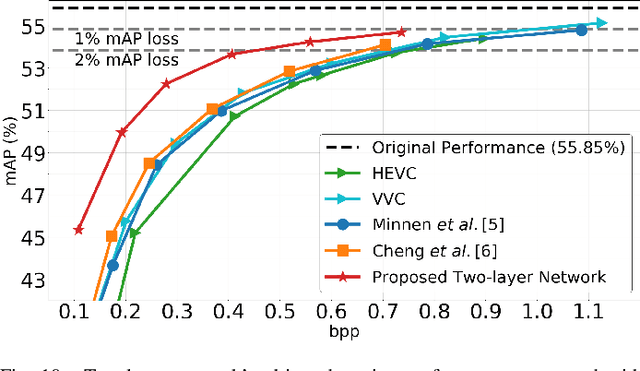
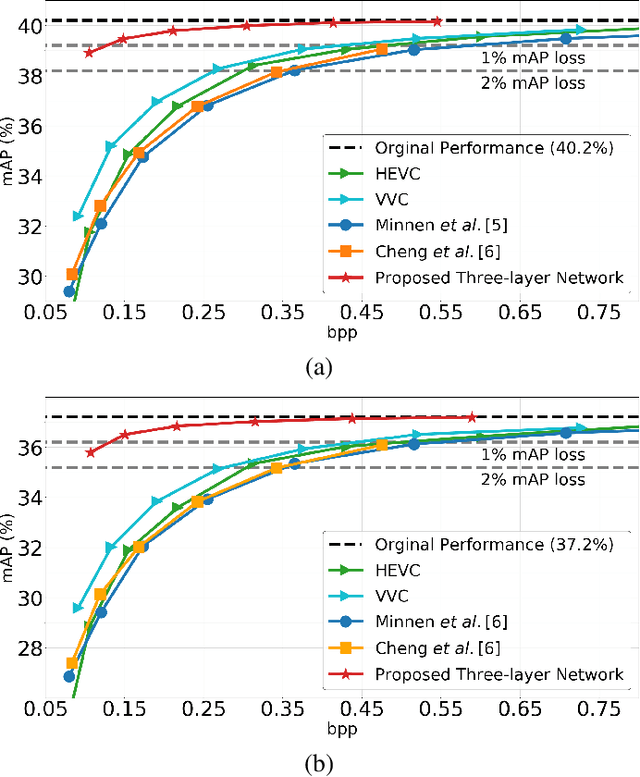
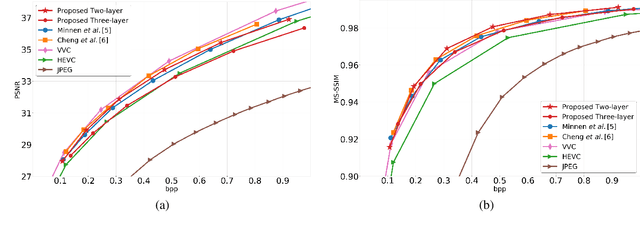
At present, and increasingly so in the future, much of the captured visual content will not be seen by humans. Instead, it will be used for automated machine vision analytics and may require occasional human viewing. Examples of such applications include traffic monitoring, visual surveillance, autonomous navigation, and industrial machine vision. To address such requirements, we develop an end-to-end learned image codec whose latent space is designed to support scalability from simpler to more complicated tasks. The simplest task is assigned to a subset of the latent space (the base layer), while more complicated tasks make use of additional subsets of the latent space, i.e., both the base and enhancement layer(s). For the experiments, we establish a 2-layer and a 3-layer model, each of which offers input reconstruction for human vision, plus machine vision task(s), and compare them with relevant benchmarks. The experiments show that our scalable codecs offer 37%-80% bitrate savings on machine vision tasks compared to best alternatives, while being comparable to state-of-the-art image codecs in terms of input reconstruction.