 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly Supervised Video Salient Object Detection via Point Supervision
Jul 15, 2022
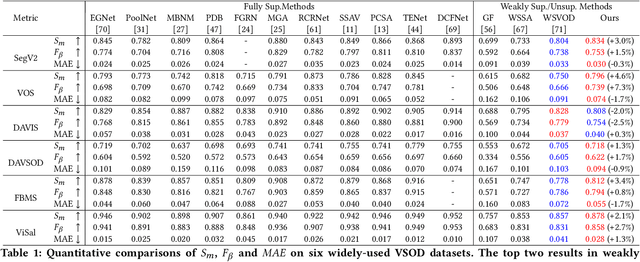
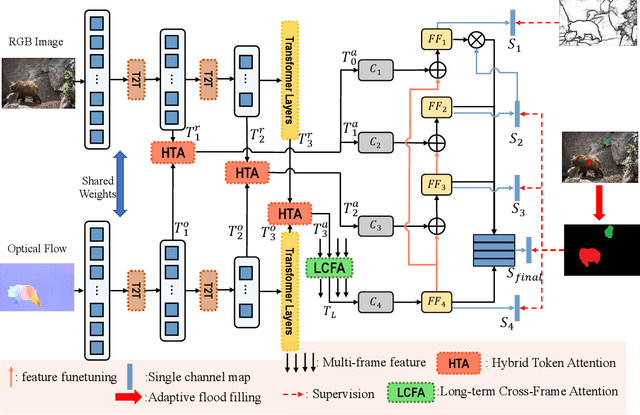
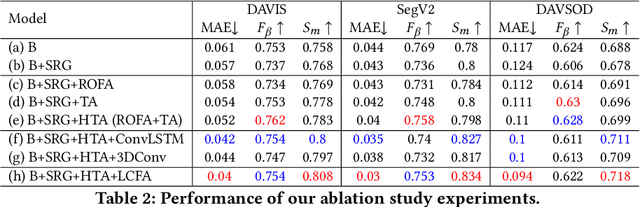
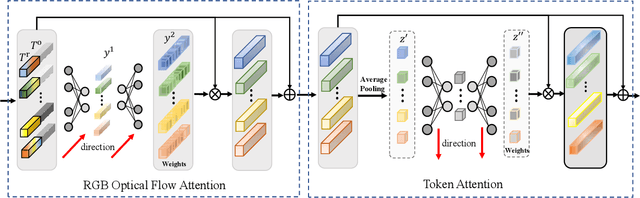
Video salient object detection models trained on pixel-wise dense annotation have achieved excellent performance, yet obtaining pixel-by-pixel annotated datasets is laborious. Several works attempt to use scribble annotations to mitigate this problem, but point supervision as a more labor-saving annotation method (even the most labor-saving method among manual annotation methods for dense prediction), has not been explored. In this paper, we propose a strong baseline model based on point supervision. To infer saliency maps with temporal information, we mine inter-frame complementary information from short-term and long-term perspectives, respectively. Specifically, we propose a hybrid token attention module, which mixes optical flow and image information from orthogonal directions, adaptively highlighting critical optical flow information (channel dimension) and critical token information (spatial dimension). To exploit long-term cues, we develop the Long-term Cross-Frame Attention module (LCFA), which assists the current frame in inferring salient objects based on multi-frame tokens. Furthermore, we label two point-supervised datasets, P-DAVIS and P-DAVSOD, by relabeling the DAVIS and the DAVSOD dataset. Experiments on the six benchmark datasets illustrate our method outperforms the previous state-of-the-art weakly supervised methods and even is comparable with some fully supervised approaches. Source code and datasets are available.
Weakly Supervised Object Localization via Transformer with Implicit Spatial Calibration
Jul 21, 2022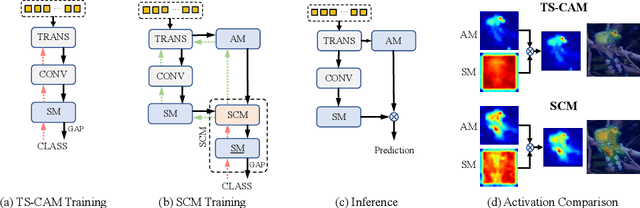
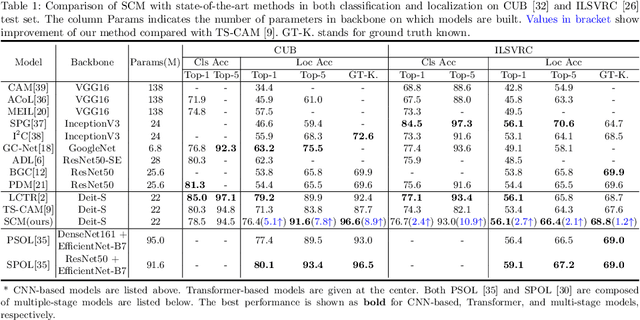
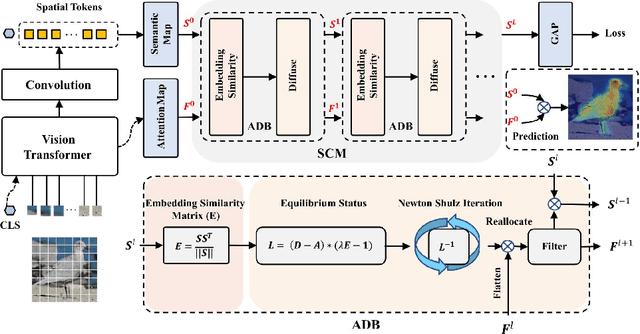
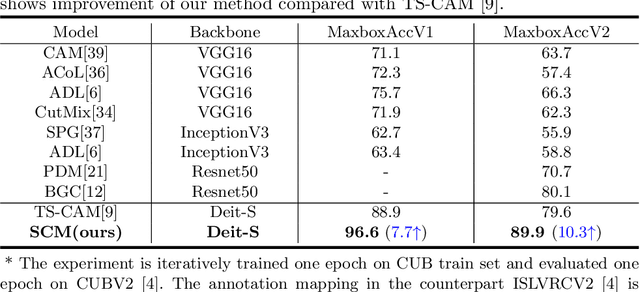
Weakly Supervised Object Localization (WSOL), which aims to localize objects by only using image-level labels, has attracted much attention because of its low annotation cost in real applications. Recent studies leverage the advantage of self-attention in visual Transformer for long-range dependency to re-active semantic regions, aiming to avoid partial activation in traditional class activation mapping (CAM). However, the long-range modeling in Transformer neglects the inherent spatial coherence of the object, and it usually diffuses the semantic-aware regions far from the object boundary, making localization results significantly larger or far smaller. To address such an issue, we introduce a simple yet effective Spatial Calibration Module (SCM) for accurate WSOL, incorporating semantic similarities of patch tokens and their spatial relationships into a unified diffusion model. Specifically, we introduce a learnable parameter to dynamically adjust the semantic correlations and spatial context intensities for effective information propagation. In practice, SCM is designed as an external module of Transformer, and can be removed during inference to reduce the computation cost. The object-sensitive localization ability is implicitly embedded into the Transformer encoder through optimization in the training phase. It enables the generated attention maps to capture the sharper object boundaries and filter the object-irrelevant background area. Extensive experimental results demonstrate the effectiveness of the proposed method, which significantly outperforms its counterpart TS-CAM on both CUB-200 and ImageNet-1K benchmarks. The code is available at https://github.com/164140757/SCM.
Self-Supervised Equivariant Learning for Oriented Keypoint Detection
Apr 19, 2022
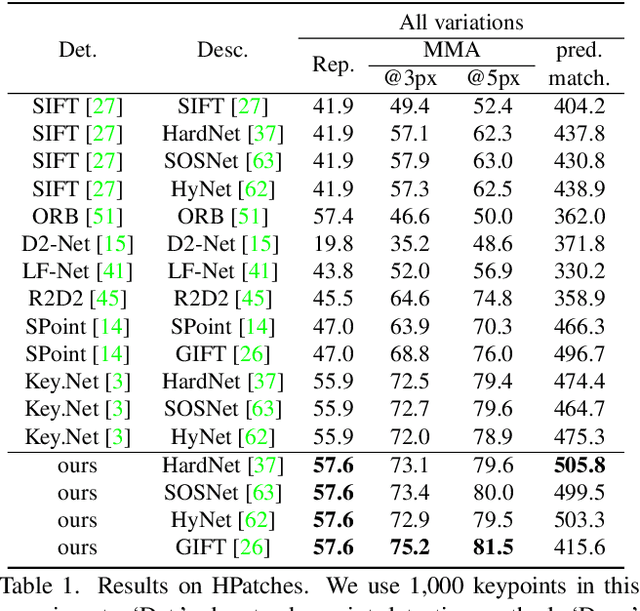
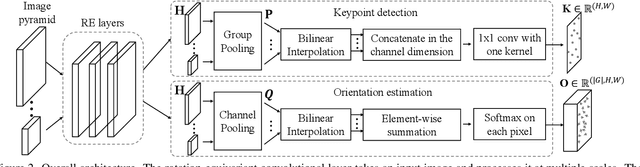
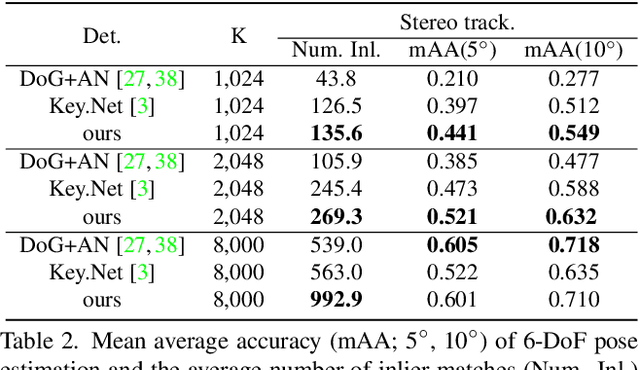
Detecting robust keypoints from an image is an integral part of many computer vision problems, and the characteristic orientation and scale of keypoints play an important role for keypoint description and matching. Existing learning-based methods for keypoint detection rely on standard translation-equivariant CNNs but often fail to detect reliable keypoints against geometric variations. To learn to detect robust oriented keypoints, we introduce a self-supervised learning framework using rotation-equivariant CNNs. We propose a dense orientation alignment loss by an image pair generated by synthetic transformations for training a histogram-based orientation map. Our method outperforms the previous methods on an image matching benchmark and a camera pose estimation benchmark.
Towards Understanding and Mitigating Audio Adversarial Examples for Speaker Recognition
Jun 07, 2022
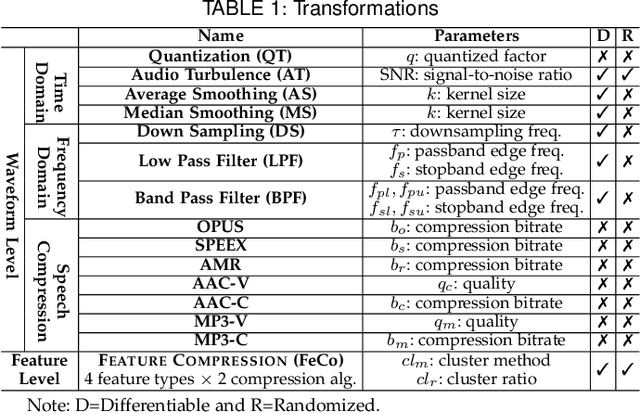
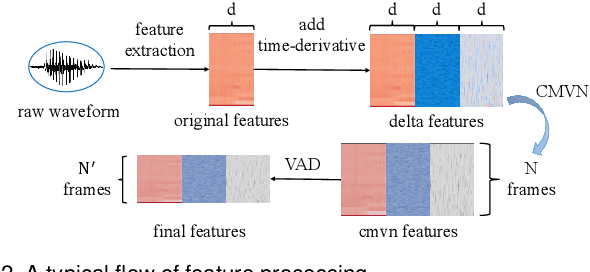
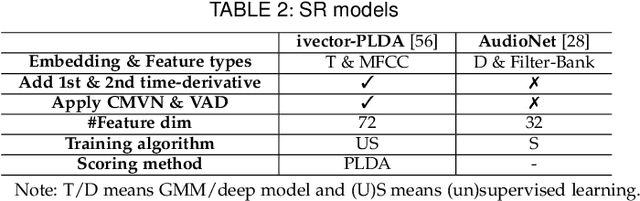
Speaker recognition systems (SRSs) have recently been shown to be vulnerable to adversarial attacks, raising significant security concerns. In this work, we systematically investigate transformation and adversarial training based defenses for securing SRSs. According to the characteristic of SRSs, we present 22 diverse transformations and thoroughly evaluate them using 7 recent promising adversarial attacks (4 white-box and 3 black-box) on speaker recognition. With careful regard for best practices in defense evaluations, we analyze the strength of transformations to withstand adaptive attacks. We also evaluate and understand their effectiveness against adaptive attacks when combined with adversarial training. Our study provides lots of useful insights and findings, many of them are new or inconsistent with the conclusions in the image and speech recognition domains, e.g., variable and constant bit rate speech compressions have different performance, and some non-differentiable transformations remain effective against current promising evasion techniques which often work well in the image domain. We demonstrate that the proposed novel feature-level transformation combined with adversarial training is rather effective compared to the sole adversarial training in a complete white-box setting, e.g., increasing the accuracy by 13.62% and attack cost by two orders of magnitude, while other transformations do not necessarily improve the overall defense capability. This work sheds further light on the research directions in this field. We also release our evaluation platform SPEAKERGUARD to foster further research.
Privacy-Preserving Face Recognition with Learnable Privacy Budgets in Frequency Domain
Jul 18, 2022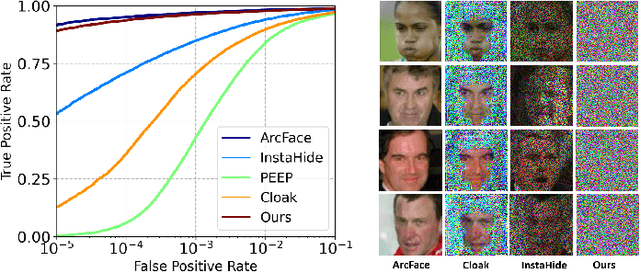

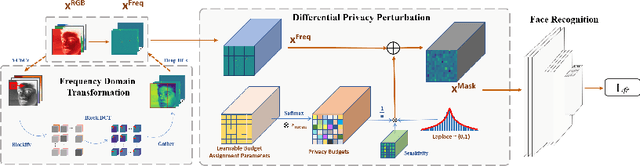
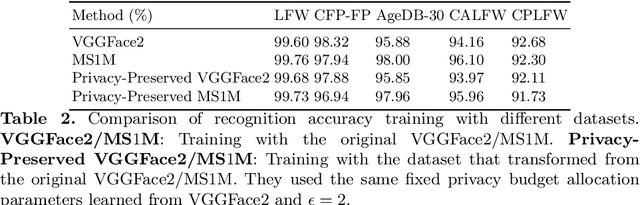
Face recognition technology has been used in many fields due to its high recognition accuracy, including the face unlocking of mobile devices, community access control systems, and city surveillance. As the current high accuracy is guaranteed by very deep network structures, facial images often need to be transmitted to third-party servers with high computational power for inference. However, facial images visually reveal the user's identity information. In this process, both untrusted service providers and malicious users can significantly increase the risk of a personal privacy breach. Current privacy-preserving approaches to face recognition are often accompanied by many side effects, such as a significant increase in inference time or a noticeable decrease in recognition accuracy. This paper proposes a privacy-preserving face recognition method using differential privacy in the frequency domain. Due to the utilization of differential privacy, it offers a guarantee of privacy in theory. Meanwhile, the loss of accuracy is very slight. This method first converts the original image to the frequency domain and removes the direct component termed DC. Then a privacy budget allocation method can be learned based on the loss of the back-end face recognition network within the differential privacy framework. Finally, it adds the corresponding noise to the frequency domain features. Our method performs very well with several classical face recognition test sets according to the extensive experiments.
Self-supervised High-fidelity and Re-renderable 3D Facial Reconstruction from a Single Image
Nov 16, 2021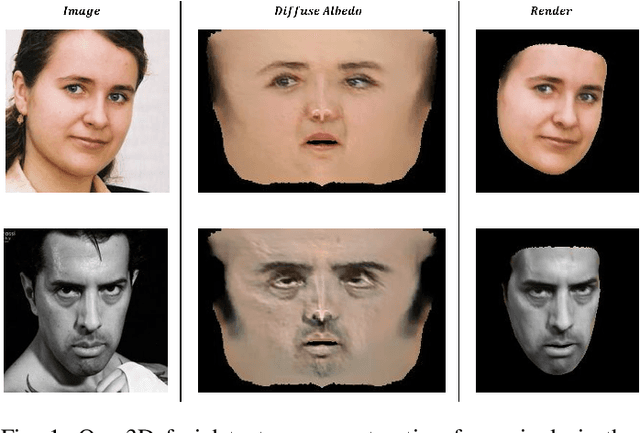

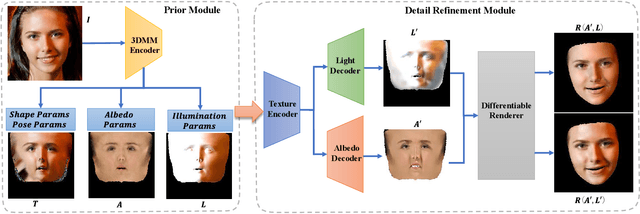

Reconstructing high-fidelity 3D facial texture from a single image is a challenging task since the lack of complete face information and the domain gap between the 3D face and 2D image. The most recent works tackle facial texture reconstruction problem by applying either generation-based or reconstruction-based methods. Although each method has its own advantage, none of them is capable of recovering a high-fidelity and re-renderable facial texture, where the term 're-renderable' demands the facial texture to be spatially complete and disentangled with environmental illumination. In this paper, we propose a novel self-supervised learning framework for reconstructing high-quality 3D faces from single-view images in-the-wild. Our main idea is to first utilize the prior generation module to produce a prior albedo, then leverage the detail refinement module to obtain detailed albedo. To further make facial textures disentangled with illumination, we present a novel detailed illumination representation which is reconstructed with the detailed albedo together. We also design several regularization loss functions on both the albedo side and illumination side to facilitate the disentanglement of these two factors. Finally, thanks to the differentiable rendering technique, our neural network can be efficiently trained in a self-supervised manner. Extensive experiments on challenging datasets demonstrate that our framework substantially outperforms state-of-the-art approaches in both qualitative and quantitative comparisons.
Correspondence Matters for Video Referring Expression Comprehension
Jul 21, 2022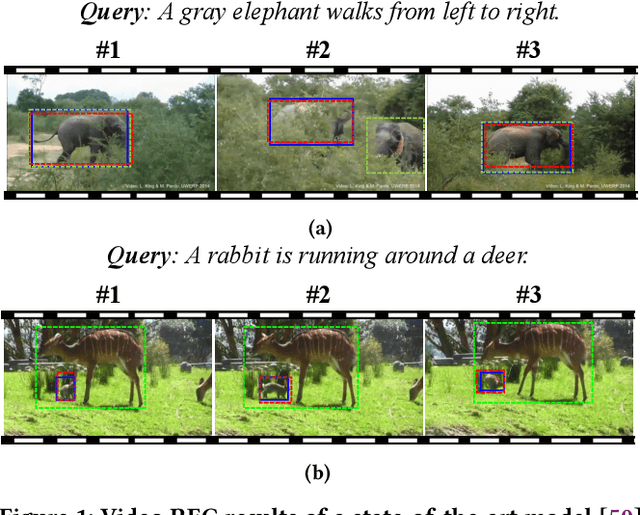
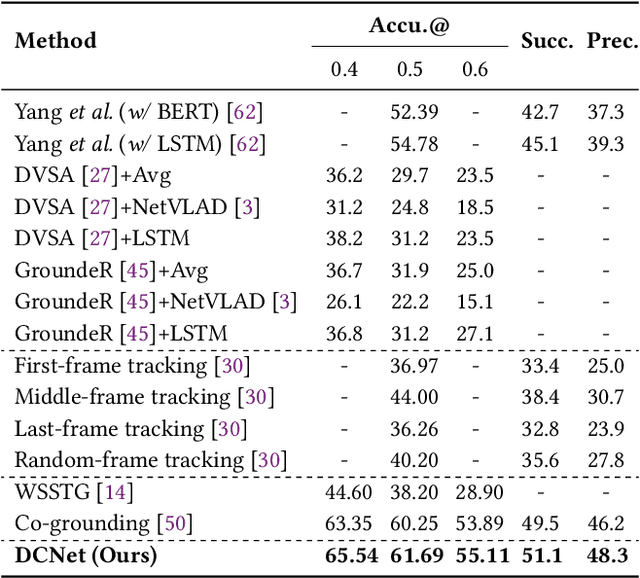

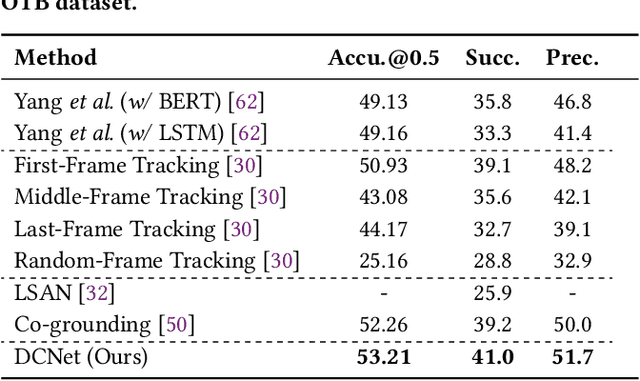
We investigate the problem of video Referring Expression Comprehension (REC), which aims to localize the referent objects described in the sentence to visual regions in the video frames. Despite the recent progress, existing methods suffer from two problems: 1) inconsistent localization results across video frames; 2) confusion between the referent and contextual objects. To this end, we propose a novel Dual Correspondence Network (dubbed as DCNet) which explicitly enhances the dense associations in both the inter-frame and cross-modal manners. Firstly, we aim to build the inter-frame correlations for all existing instances within the frames. Specifically, we compute the inter-frame patch-wise cosine similarity to estimate the dense alignment and then perform the inter-frame contrastive learning to map them close in feature space. Secondly, we propose to build the fine-grained patch-word alignment to associate each patch with certain words. Due to the lack of this kind of detailed annotations, we also predict the patch-word correspondence through the cosine similarity. Extensive experiments demonstrate that our DCNet achieves state-of-the-art performance on both video and image REC benchmarks. Furthermore, we conduct comprehensive ablation studies and thorough analyses to explore the optimal model designs. Notably, our inter-frame and cross-modal contrastive losses are plug-and-play functions and are applicable to any video REC architectures. For example, by building on top of Co-grounding, we boost the performance by 1.48% absolute improvement on Accu.@0.5 for VID-Sentence dataset.
Understanding Aesthetics with Language: A Photo Critique Dataset for Aesthetic Assessment
Jun 17, 2022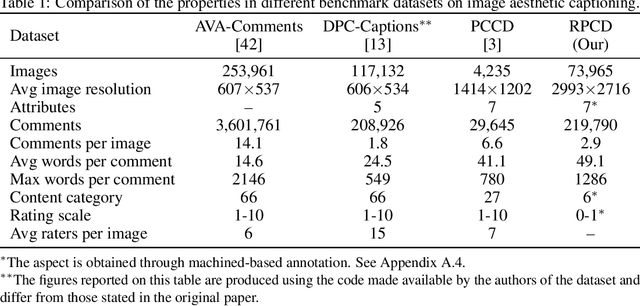

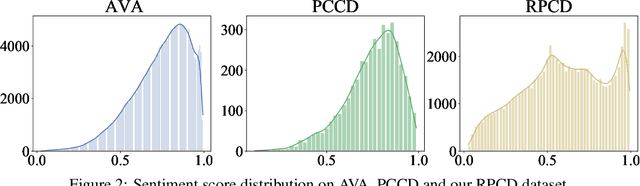
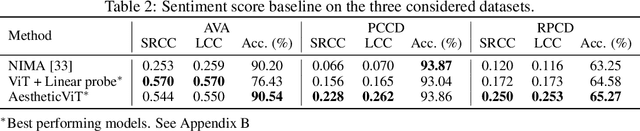
Computational inference of aesthetics is an ill-defined task due to its subjective nature. Many datasets have been proposed to tackle the problem by providing pairs of images and aesthetic scores based on human ratings. However, humans are better at expressing their opinion, taste, and emotions by means of language rather than summarizing them in a single number. In fact, photo critiques provide much richer information as they reveal how and why users rate the aesthetics of visual stimuli. In this regard, we propose the Reddit Photo Critique Dataset (RPCD), which contains tuples of image and photo critiques. RPCD consists of 74K images and 220K comments and is collected from a Reddit community used by hobbyists and professional photographers to improve their photography skills by leveraging constructive community feedback. The proposed dataset differs from previous aesthetics datasets mainly in three aspects, namely (i) the large scale of the dataset and the extension of the comments criticizing different aspects of the image, (ii) it contains mostly UltraHD images, and (iii) it can easily be extended to new data as it is collected through an automatic pipeline. To the best of our knowledge, in this work, we propose the first attempt to estimate the aesthetic quality of visual stimuli from the critiques. To this end, we exploit the polarity of the sentiment of criticism as an indicator of aesthetic judgment. We demonstrate how sentiment polarity correlates positively with the aesthetic judgment available for two aesthetic assessment benchmarks. Finally, we experiment with several models by using the sentiment scores as a target for ranking images. Dataset and baselines are available (https://github.com/mediatechnologycenter/aestheval).
Adversarially robust segmentation models learn perceptually-aligned gradients
Apr 03, 2022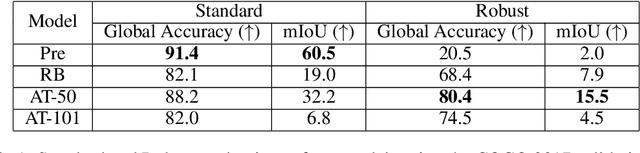



The effects of adversarial training on semantic segmentation networks has not been thoroughly explored. While previous work has shown that adversarially-trained image classifiers can be used to perform image synthesis, we have yet to understand how best to leverage an adversarially-trained segmentation network to do the same. Using a simple optimizer, we demonstrate that adversarially-trained semantic segmentation networks can be used to perform image inpainting and generation. Our experiments demonstrate that adversarially-trained segmentation networks are more robust and indeed exhibit perceptually-aligned gradients which help in producing plausible image inpaintings. We seek to place additional weight behind the hypothesis that adversarially robust models exhibit gradients that are more perceptually-aligned with human vision. Through image synthesis, we argue that perceptually-aligned gradients promote a better understanding of a neural network's learned representations and aid in making neural networks more interpretable.
Playing Tic-Tac-Toe Games with Intelligent Single-pixel Imaging
May 07, 2022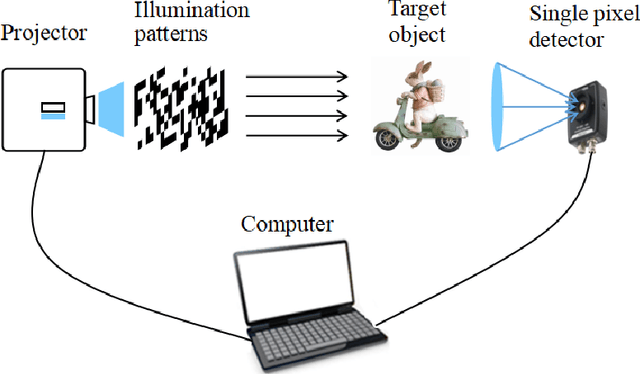

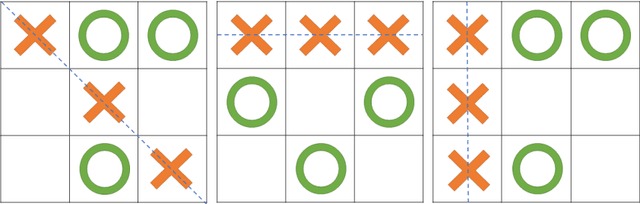

Single-pixel imaging (SPI) is a novel optical imaging technique by replacing a two-dimensional pixelated sensor with a single-pixel detector and pattern illuminations. SPI have been extensively used for various tasks related to image acquisition and processing. In this work, a novel non-image-based task of playing Tic-Tac-Toe games interactively is merged into the framework of SPI. An optoelectronic artificial intelligent (AI) player with minimal digital computation can detect the game states, generate optimal moves and display output results mainly by pattern illumination and single-pixel detection. Simulated and experimental results demonstrate the feasibility of proposed scheme and its unbeatable performance against human players.