 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Residual-guided Personalized Speech Synthesis based on Face Image
Apr 01, 2022
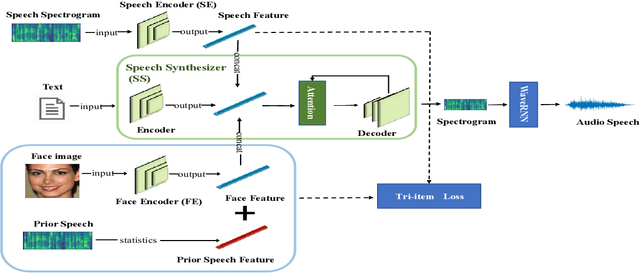
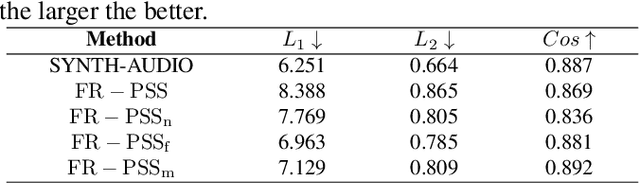
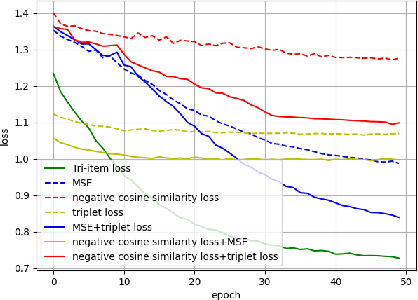

Previous works derive personalized speech features by training the model on a large dataset composed of his/her audio sounds. It was reported that face information has a strong link with the speech sound. Thus in this work, we innovatively extract personalized speech features from human faces to synthesize personalized speech using neural vocoder. A Face-based Residual Personalized Speech Synthesis Model (FR-PSS) containing a speech encoder, a speech synthesizer and a face encoder is designed for PSS. In this model, by designing two speech priors, a residual-guided strategy is introduced to guide the face feature to approach the true speech feature in the training. Moreover, considering the error of feature's absolute values and their directional bias, we formulate a novel tri-item loss function for face encoder. Experimental results show that the speech synthesized by our model is comparable to the personalized speech synthesized by training a large amount of audio data in previous works.
Human keypoint detection for close proximity human-robot interaction
Jul 15, 2022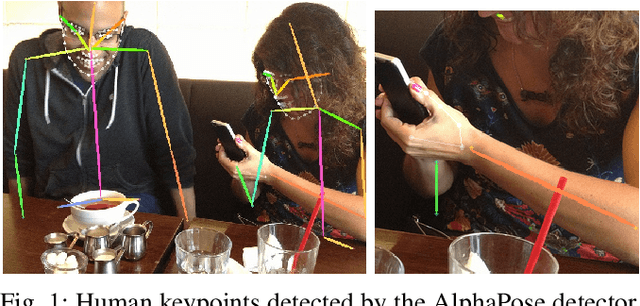
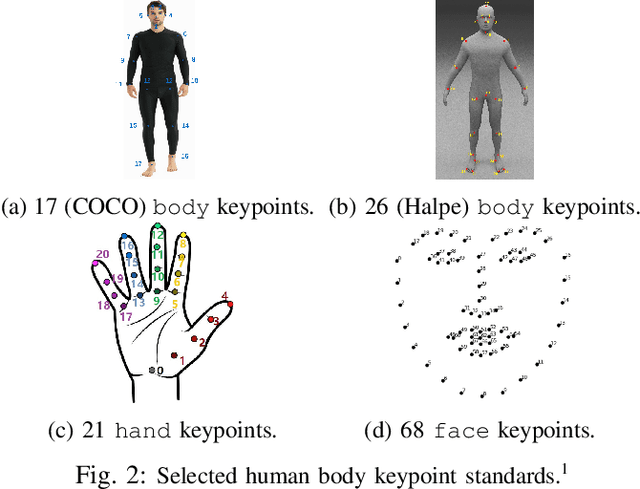

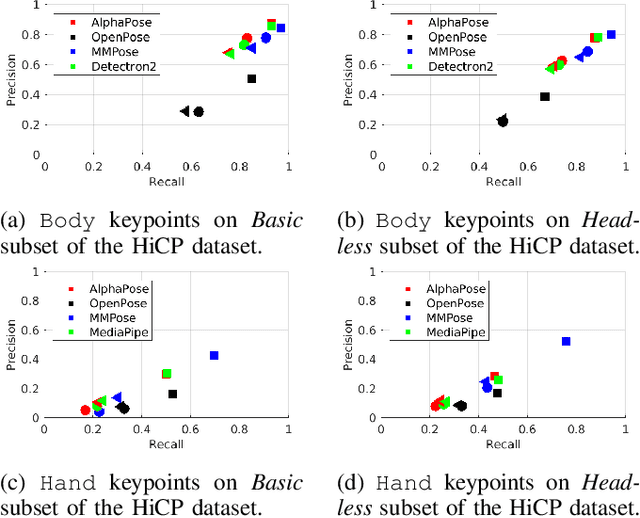
We study the performance of state-of-the-art human keypoint detectors in the context of close proximity human-robot interaction. The detection in this scenario is specific in that only a subset of body parts such as hands and torso are in the field of view. In particular, (i) we survey existing datasets with human pose annotation from the perspective of close proximity images and prepare and make publicly available a new Human in Close Proximity (HiCP) dataset; (ii) we quantitatively and qualitatively compare state-of-the-art human whole-body 2D keypoint detection methods (OpenPose, MMPose, AlphaPose, Detectron2) on this dataset; (iii) since accurate detection of hands and fingers is critical in applications with handovers, we evaluate the performance of the MediaPipe hand detector; (iv) we deploy the algorithms on a humanoid robot with an RGB-D camera on its head and evaluate the performance in 3D human keypoint detection. A motion capture system is used as reference. The best performing whole-body keypoint detectors in close proximity were MMPose and AlphaPose, but both had difficulty with finger detection. Thus, we propose a combination of MMPose or AlphaPose for the body and MediaPipe for the hands in a single framework providing the most accurate and robust detection. We also analyse the failure modes of individual detectors -- for example, to what extent the absence of the head of the person in the image degrades performance. Finally, we demonstrate the framework in a scenario where a humanoid robot interacting with a person uses the detected 3D keypoints for whole-body avoidance maneuvers.
Lessons learned from the NeurIPS 2021 MetaDL challenge: Backbone fine-tuning without episodic meta-learning dominates for few-shot learning image classification
Jun 15, 2022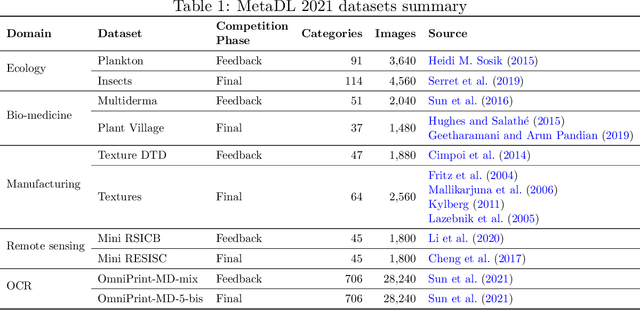

Although deep neural networks are capable of achieving performance superior to humans on various tasks, they are notorious for requiring large amounts of data and computing resources, restricting their success to domains where such resources are available. Metalearning methods can address this problem by transferring knowledge from related tasks, thus reducing the amount of data and computing resources needed to learn new tasks. We organize the MetaDL competition series, which provide opportunities for research groups all over the world to create and experimentally assess new meta-(deep)learning solutions for real problems. In this paper, authored collaboratively between the competition organizers and the top-ranked participants, we describe the design of the competition, the datasets, the best experimental results, as well as the top-ranked methods in the NeurIPS 2021 challenge, which attracted 15 active teams who made it to the final phase (by outperforming the baseline), making over 100 code submissions during the feedback phase. The solutions of the top participants have been open-sourced. The lessons learned include that learning good representations is essential for effective transfer learning.
Step-Wise Hierarchical Alignment Network for Image-Text Matching
Jun 11, 2021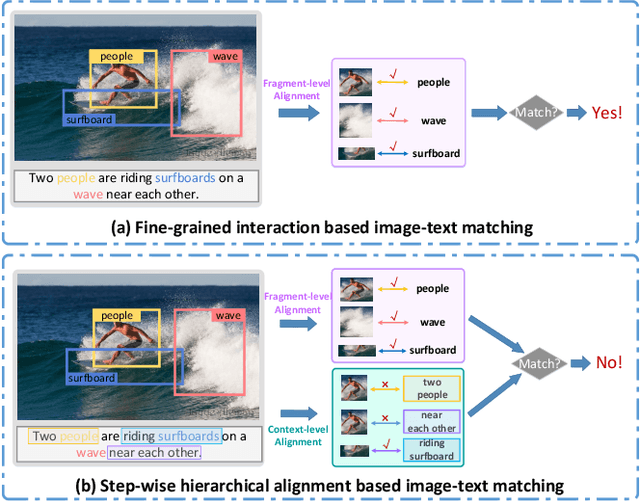
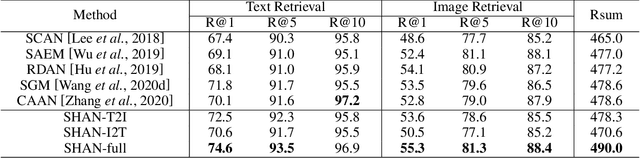
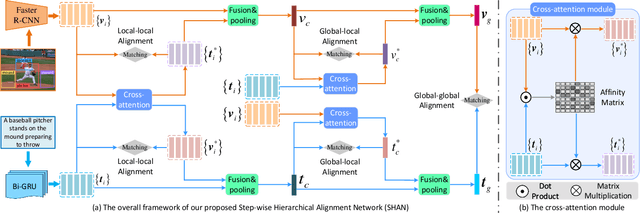
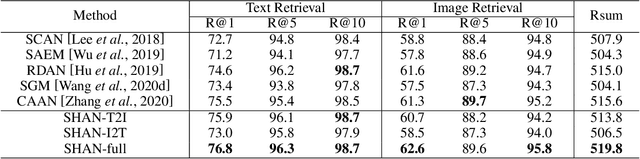
Image-text matching plays a central role in bridging the semantic gap between vision and language. The key point to achieve precise visual-semantic alignment lies in capturing the fine-grained cross-modal correspondence between image and text. Most previous methods rely on single-step reasoning to discover the visual-semantic interactions, which lacks the ability of exploiting the multi-level information to locate the hierarchical fine-grained relevance. Different from them, in this work, we propose a step-wise hierarchical alignment network (SHAN) that decomposes image-text matching into multi-step cross-modal reasoning process. Specifically, we first achieve local-to-local alignment at fragment level, following by performing global-to-local and global-to-global alignment at context level sequentially. This progressive alignment strategy supplies our model with more complementary and sufficient semantic clues to understand the hierarchical correlations between image and text. The experimental results on two benchmark datasets demonstrate the superiority of our proposed method.
Proper Reuse of Image Classification Features Improves Object Detection
Apr 01, 2022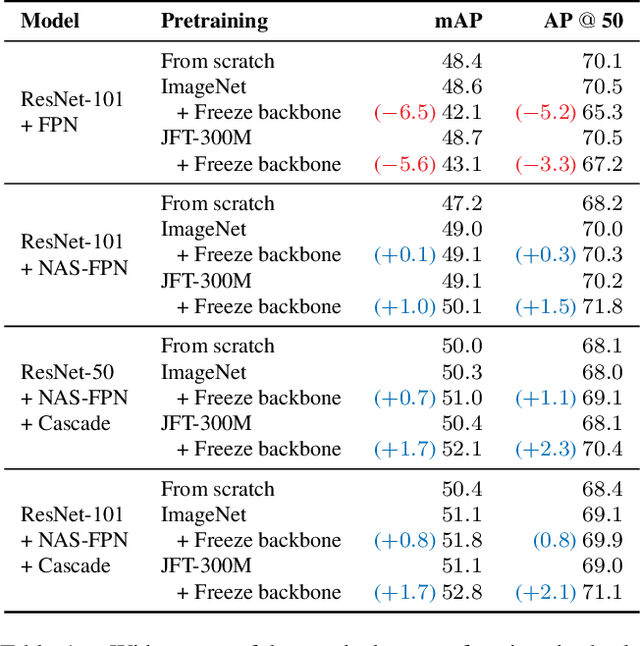
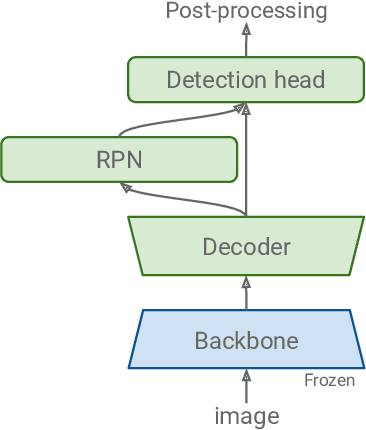
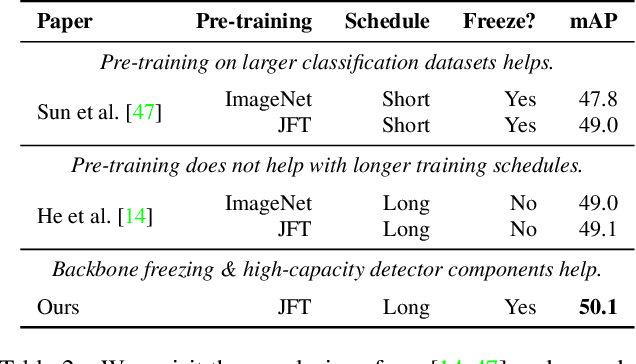

A common practice in transfer learning is to initialize the downstream model weights by pre-training on a data-abundant upstream task. In object detection specifically, the feature backbone is typically initialized with Imagenet classifier weights and fine-tuned on the object detection task. Recent works show this is not strictly necessary under longer training regimes and provide recipes for training the backbone from scratch. We investigate the opposite direction of this end-to-end training trend: we show that an extreme form of knowledge preservation -- freezing the classifier-initialized backbone -- consistently improves many different detection models, and leads to considerable resource savings. We hypothesize and corroborate experimentally that the remaining detector components capacity and structure is a crucial factor in leveraging the frozen backbone. Immediate applications of our findings include performance improvements on hard cases like detection of long-tail object classes and computational and memory resource savings that contribute to making the field more accessible to researchers with access to fewer computational resources.
Unsupervised Image Decomposition with Phase-Correlation Networks
Oct 08, 2021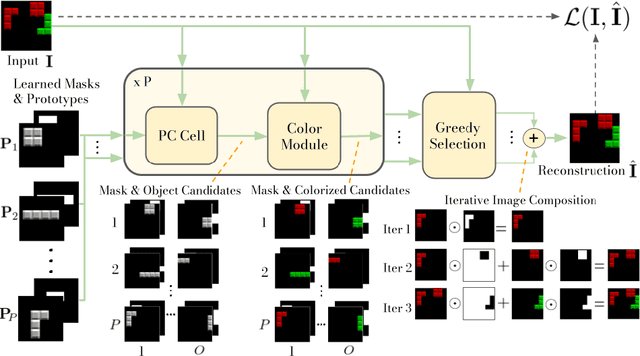
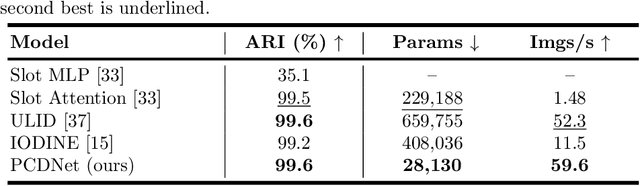
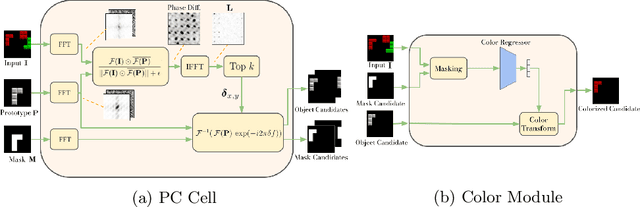

The ability to decompose scenes into their object components is a desired property for autonomous agents, allowing them to reason and act in their surroundings. Recently, different methods have been proposed to learn object-centric representations from data in an unsupervised manner. These methods often rely on latent representations learned by deep neural networks, hence requiring high computational costs and large amounts of curated data. Such models are also difficult to interpret. To address these challenges, we propose the Phase-Correlation Decomposition Network (PCDNet), a novel model that decomposes a scene into its object components, which are represented as transformed versions of a set of learned object prototypes. The core building block in PCDNet is the Phase-Correlation Cell (PC Cell), which exploits the frequency-domain representation of the images in order to estimate the transformation between an object prototype and its transformed version in the image. In our experiments, we show how PCDNet outperforms state-of-the-art methods for unsupervised object discovery and segmentation on simple benchmark datasets and on more challenging data, while using a small number of learnable parameters and being fully interpretable.
Difference in Euclidean Norm Can Cause Semantic Divergence in Batch Normalization
Jul 06, 2022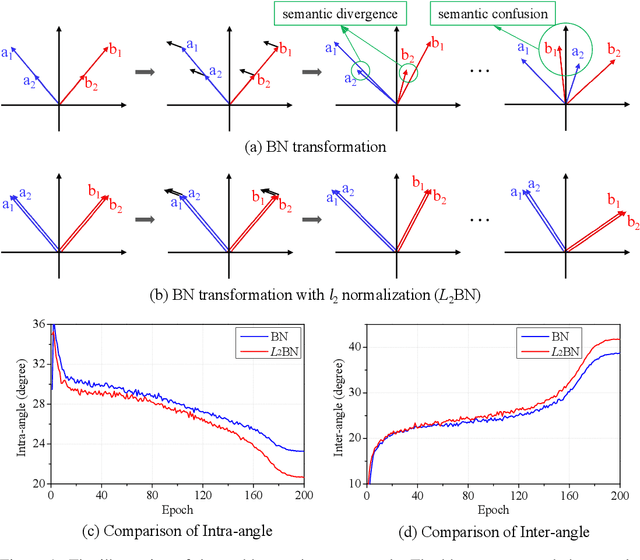

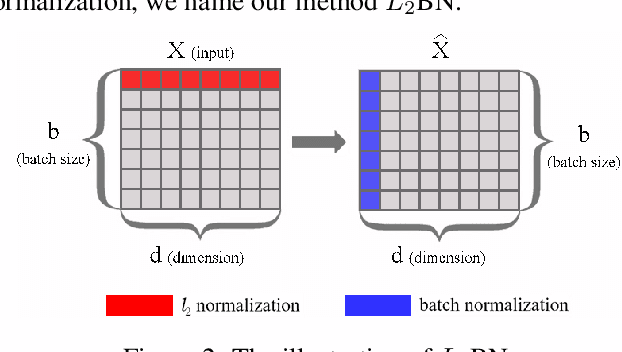
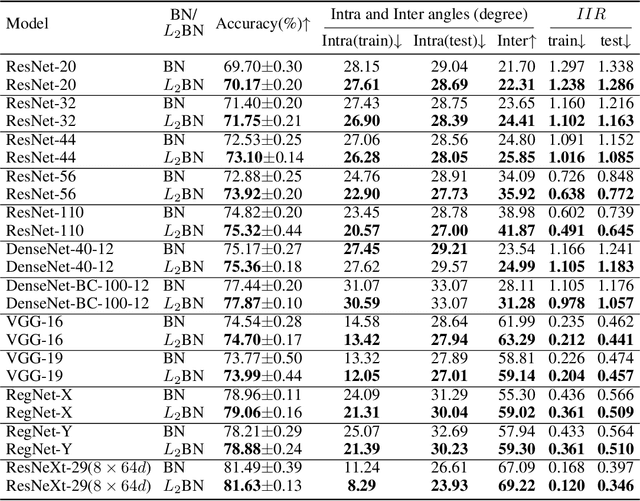
In this paper, we show that the difference in Euclidean norm of samples can make a contribution to the semantic divergence and even confusion, after the spatial translation and scaling transformation in batch normalization. To address this issue, we propose an intuitive but effective method to equalize the Euclidean norms of sample vectors. Concretely, we $l_2$-normalize each sample vector before batch normalization, and therefore the sample vectors are of the same magnitude. Since the proposed method combines the $l_2$ normalization and batch normalization, we name our method as $L_2$BN. The $L_2$BN can strengthen the compactness of intra-class features and enlarge the discrepancy of inter-class features. In addition, it can help the gradient converge to a stable scale. The $L_2$BN is easy to implement and can exert its effect without any additional parameters and hyper-parameters. Therefore, it can be used as a basic normalization method for neural networks. We evaluate the effectiveness of $L_2$BN through extensive experiments with various models on image classification and acoustic scene classification tasks. The experimental results demonstrate that the $L_2$BN is able to boost the generalization ability of various neural network models and achieve considerable performance improvements.
Multi-Semantic Image Recognition Model and Evaluating Index for explaining the deep learning models
Sep 28, 2021
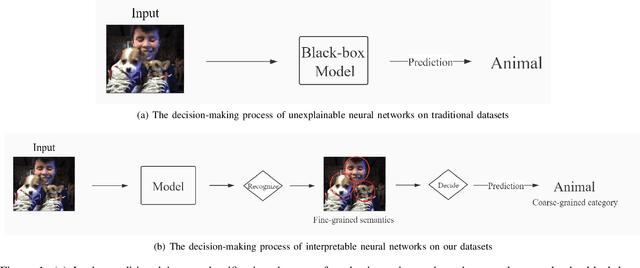
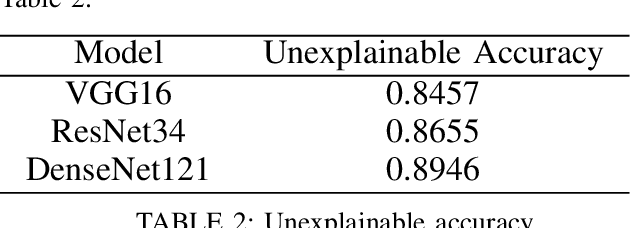
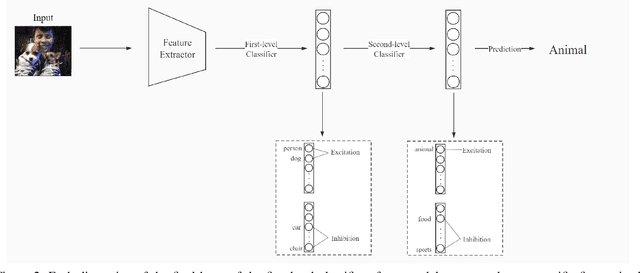
Although deep learning models are powerful among various applications, most deep learning models are still a black box, lacking verifiability and interpretability, which means the decision-making process that human beings cannot understand. Therefore, how to evaluate deep neural networks with explanations is still an urgent task. In this paper, we first propose a multi-semantic image recognition model, which enables human beings to understand the decision-making process of the neural network. Then, we presents a new evaluation index, which can quantitatively assess the model interpretability. We also comprehensively summarize the semantic information that affects the image classification results in the judgment process of neural networks. Finally, this paper also exhibits the relevant baseline performance with current state-of-the-art deep learning models.
PD-GAN: Probabilistic Diverse GAN for Image Inpainting
May 05, 2021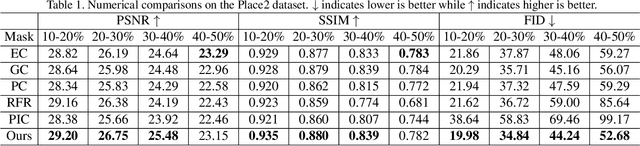
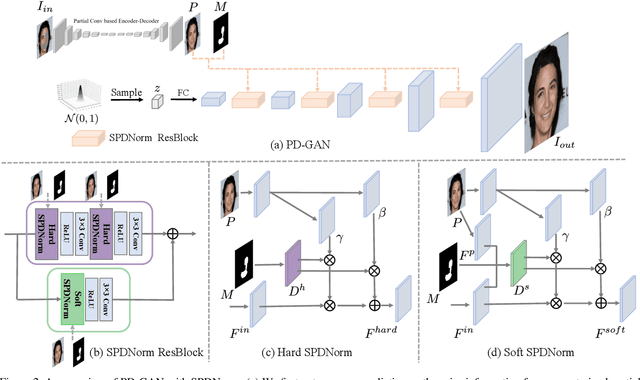
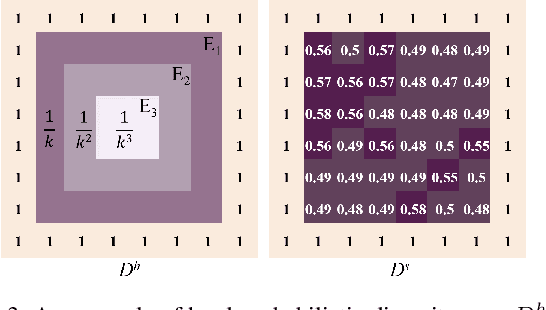
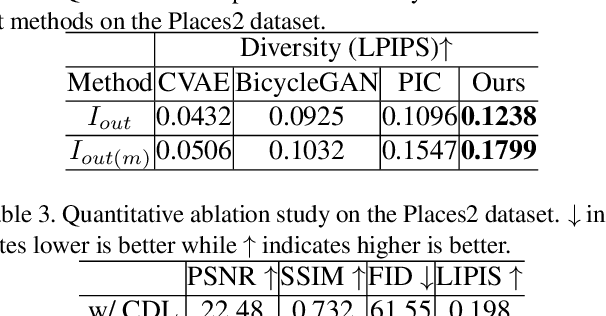
We propose PD-GAN, a probabilistic diverse GAN for image inpainting. Given an input image with arbitrary hole regions, PD-GAN produces multiple inpainting results with diverse and visually realistic content. Our PD-GAN is built upon a vanilla GAN which generates images based on random noise. During image generation, we modulate deep features of input random noise from coarse-to-fine by injecting an initially restored image and the hole regions in multiple scales. We argue that during hole filling, the pixels near the hole boundary should be more deterministic (i.e., with higher probability trusting the context and initially restored image to create natural inpainting boundary), while those pixels lie in the center of the hole should enjoy more degrees of freedom (i.e., more likely to depend on the random noise for enhancing diversity). To this end, we propose spatially probabilistic diversity normalization (SPDNorm) inside the modulation to model the probability of generating a pixel conditioned on the context information. SPDNorm dynamically balances the realism and diversity inside the hole region, making the generated content more diverse towards the hole center and resemble neighboring image content more towards the hole boundary. Meanwhile, we propose a perceptual diversity loss to further empower PD-GAN for diverse content generation. Experiments on benchmark datasets including CelebA-HQ, Places2 and Paris Street View indicate that PD-GAN is effective for diverse and visually realistic image restoration.
Segmenting white matter hyperintensities on isotropic three-dimensional Fluid Attenuated Inversion Recovery magnetic resonance images: A comparison of Deep learning tools on a Norwegian national imaging database
Jul 18, 2022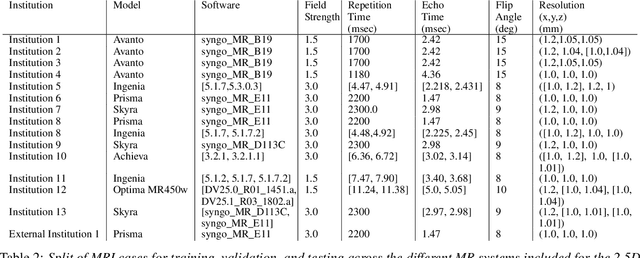
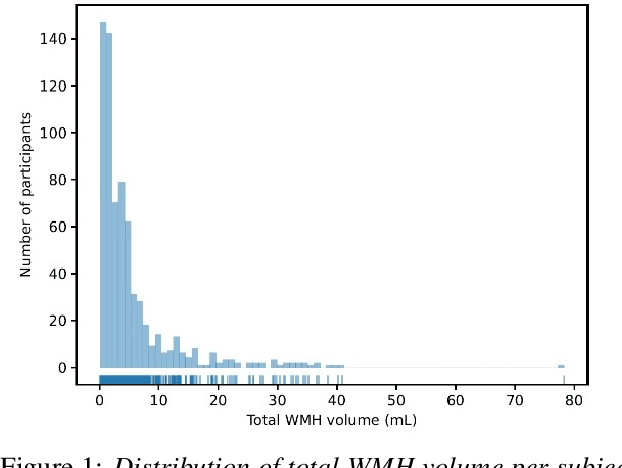

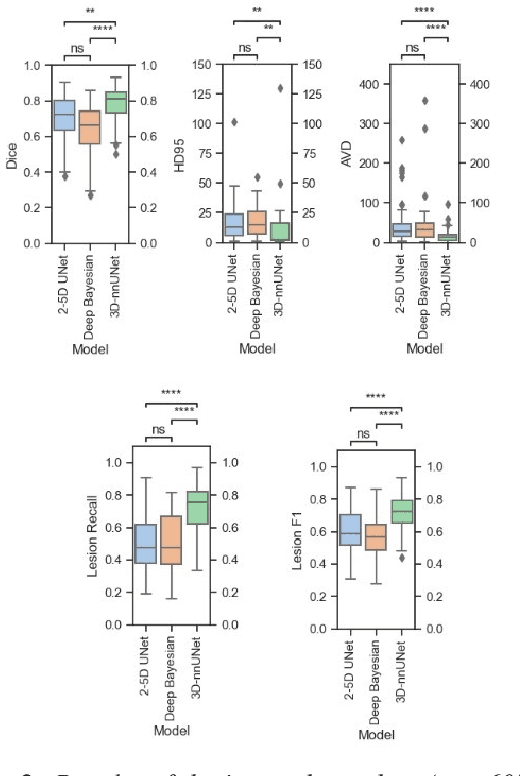
Introduction Automated segmentation of white matter hyperintensities (WMHs) is an essential step in neuroimaging analysis of Magnetic Resonance Imaging (MRI). Fluid Attenuated Inversion Recovery (FLAIR-weighted) is an MRI contrast that is particularly useful to visualize and quantify WMHs, a hallmark of cerebral small vessel disease and Alzheimer's disease (AD). Clinical MRI protocols migrate to a three-dimensional (3D) FLAIR-weighted acquisition to enable high spatial resolution in all three voxel dimensions. The current study details the deployment of deep learning tools to enable automated WMH segmentation and characterization from 3D FLAIR-weighted images acquired as part of a national AD imaging initiative. Materials and methods Among 642 participants (283 male, mean age: (65.18 +/- 9.33) years) from the DDI study, two in-house networks were trained and validated across five national collection sites. Three models were tested on a held-out subset of the internal data from the 642 participants and an external dataset with 29 cases from an international collaborator. These test sets were evaluated independently. Five established WMH performance metrics were used for comparison against ground truth human-in-the-loop segmentation. Results Of the three networks tested, the 3D nnU-Net had the best performance with an average dice similarity coefficient score of 0.78 +/- 0.10, performing better than both the in-house developed 2.5D model and the SOTA Deep Bayesian network. Conclusion With the increasing use of 3D FLAIR-weighted images in MRI protocols, our results suggest that WMH segmentation models can be trained on 3D data and yield WMH segmentation performance that is comparable to or better than state-of-the-art without the need for including T1-weighted image series.