 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Large-Scale Benchmark for Food Image Segmentation
May 12, 2021

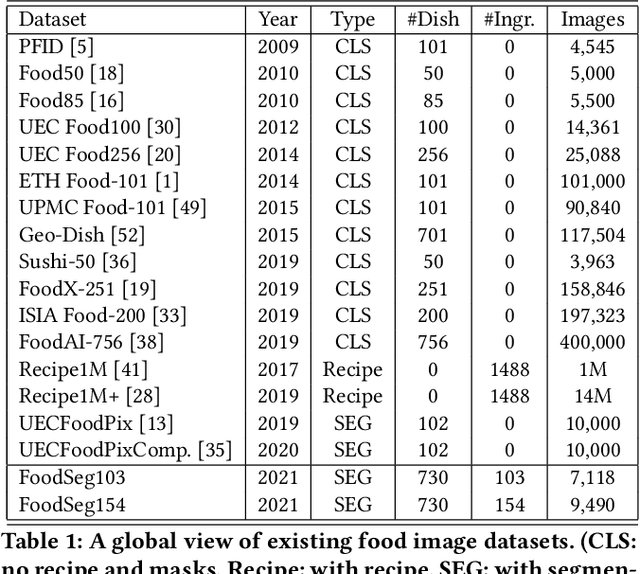

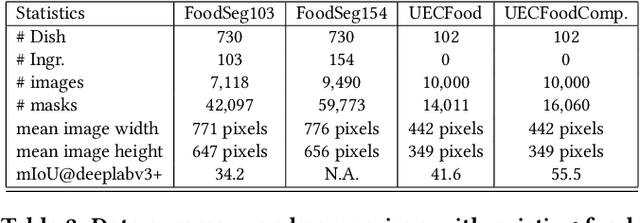
Food image segmentation is a critical and indispensible task for developing health-related applications such as estimating food calories and nutrients. Existing food image segmentation models are underperforming due to two reasons: (1) there is a lack of high quality food image datasets with fine-grained ingredient labels and pixel-wise location masks -- the existing datasets either carry coarse ingredient labels or are small in size; and (2) the complex appearance of food makes it difficult to localize and recognize ingredients in food images, e.g., the ingredients may overlap one another in the same image, and the identical ingredient may appear distinctly in different food images. In this work, we build a new food image dataset FoodSeg103 (and its extension FoodSeg154) containing 9,490 images. We annotate these images with 154 ingredient classes and each image has an average of 6 ingredient labels and pixel-wise masks. In addition, we propose a multi-modality pre-training approach called ReLeM that explicitly equips a segmentation model with rich and semantic food knowledge. In experiments, we use three popular semantic segmentation methods (i.e., Dilated Convolution based, Feature Pyramid based, and Vision Transformer based) as baselines, and evaluate them as well as ReLeM on our new datasets. We believe that the FoodSeg103 (and its extension FoodSeg154) and the pre-trained models using ReLeM can serve as a benchmark to facilitate future works on fine-grained food image understanding. We make all these datasets and methods public at \url{https://xiongweiwu.github.io/foodseg103.html}.
Collaborative Filtering-Based Method for Low-Resolution and Details Preserving Image Denoising
Jul 10, 2021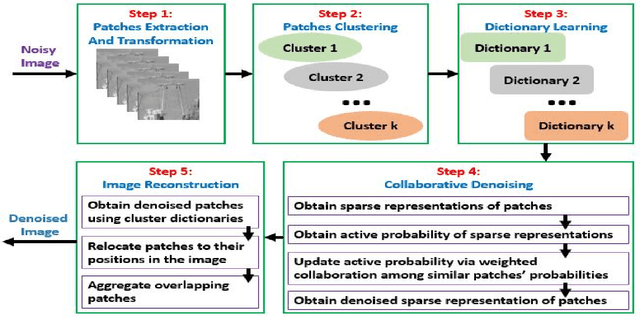
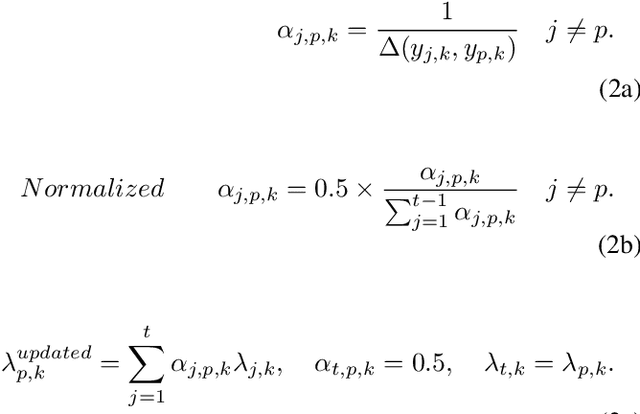
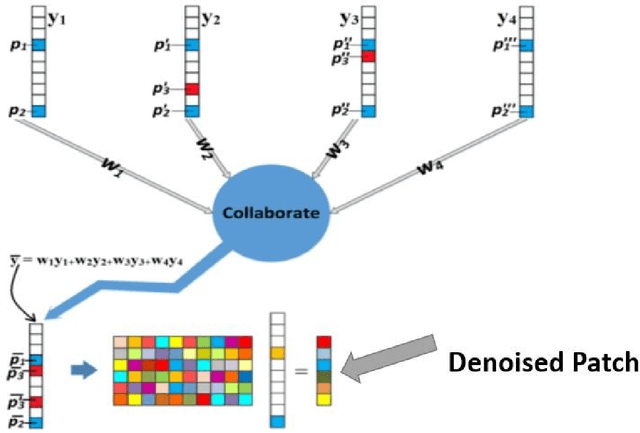
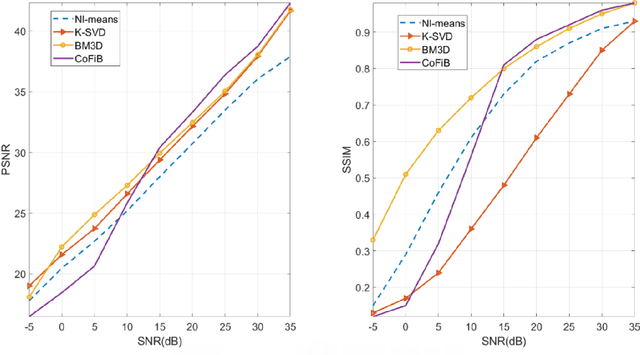
Over the years, progressive improvements in denoising performance have been achieved by several image denoising algorithms that have been proposed. Despite this, many of these state-of-the-art algorithms tend to smooth out the denoised image resulting in the loss of some image details after denoising. Many also distort images of lower resolution resulting in a partial or complete structural loss. In this paper, we address these shortcomings by proposing a collaborative filtering-based (CoFiB) denoising algorithm. Our proposed algorithm performs weighted sparse domain collaborative denoising by taking advantage of the fact that similar patches tend to have similar sparse representations in the sparse domain. This gives our algorithm the intelligence to strike a balance between image detail preservation and noise removal. Our extensive experiments showed that our proposed CoFiB algorithm does not only preserve the image details but also perform excellently for images of any given resolution where many denoising algorithms tend to struggle, specifically at low resolutions.
Neural Implicit Dictionary via Mixture-of-Expert Training
Jul 08, 2022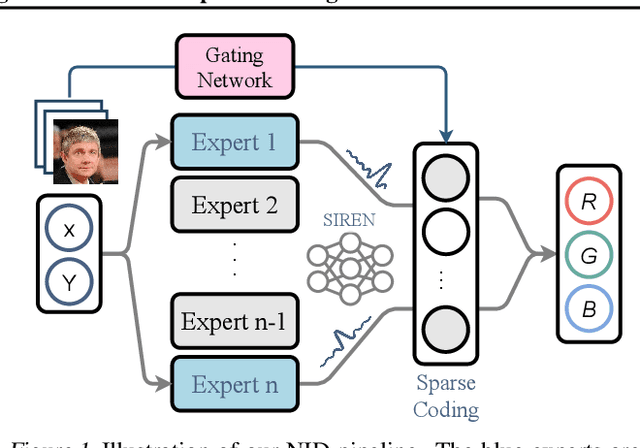
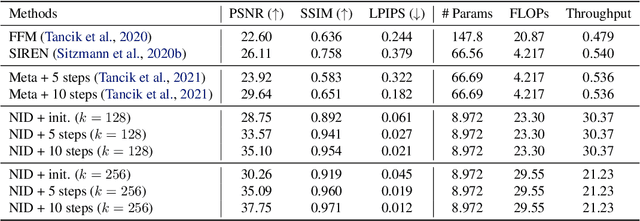

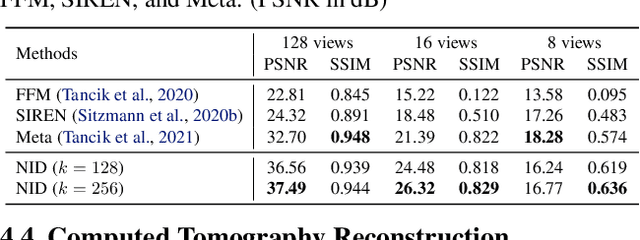
Representing visual signals by coordinate-based deep fully-connected networks has been shown advantageous in fitting complex details and solving inverse problems than discrete grid-based representation. However, acquiring such a continuous Implicit Neural Representation (INR) requires tedious per-scene training on tons of signal measurements, which limits its practicality. In this paper, we present a generic INR framework that achieves both data and training efficiency by learning a Neural Implicit Dictionary (NID) from a data collection and representing INR as a functional combination of basis sampled from the dictionary. Our NID assembles a group of coordinate-based subnetworks which are tuned to span the desired function space. After training, one can instantly and robustly acquire an unseen scene representation by solving the coding coefficients. To parallelly optimize a large group of networks, we borrow the idea from Mixture-of-Expert (MoE) to design and train our network with a sparse gating mechanism. Our experiments show that, NID can improve reconstruction of 2D images or 3D scenes by 2 orders of magnitude faster with up to 98% less input data. We further demonstrate various applications of NID in image inpainting and occlusion removal, which are considered to be challenging with vanilla INR. Our codes are available in https://github.com/VITA-Group/Neural-Implicit-Dict.
Single-View View Synthesis in the Wild with Learned Adaptive Multiplane Images
May 24, 2022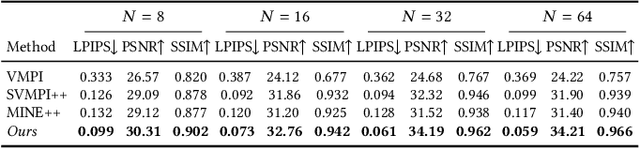
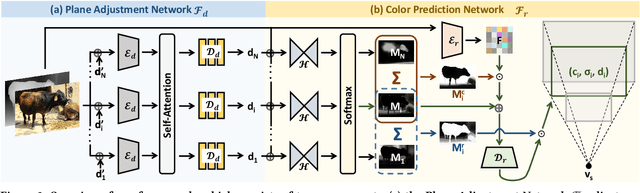
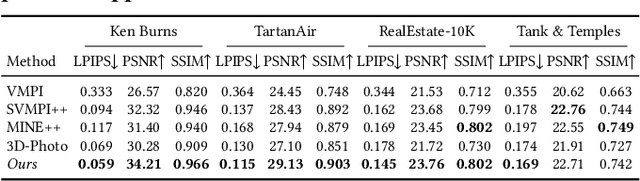
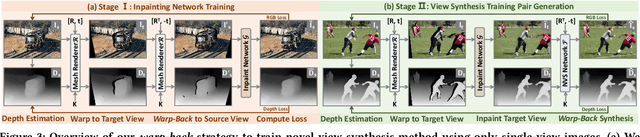
This paper deals with the challenging task of synthesizing novel views for in-the-wild photographs. Existing methods have shown promising results leveraging monocular depth estimation and color inpainting with layered depth representations. However, these methods still have limited capability to handle scenes with complex 3D geometry. We propose a new method based on the multiplane image (MPI) representation. To accommodate diverse scene layouts in the wild and tackle the difficulty in producing high-dimensional MPI contents, we design a network structure that consists of two novel modules, one for plane depth adjustment and another for depth-aware color prediction. The former adjusts the initial plane positions using the RGBD context feature and an attention mechanism. Given adjusted depth values, the latter predicts the color and density for each plane separately with proper inter-plane interactions achieved via a feature masking strategy. To train our method, we construct large-scale stereo training data using only unconstrained single-view image collections by a simple yet effective warp-back strategy. The experiments on both synthetic and real datasets demonstrate that our trained model works remarkably well and achieves state-of-the-art results.
Task Discrepancy Maximization for Fine-grained Few-Shot Classification
Jul 04, 2022
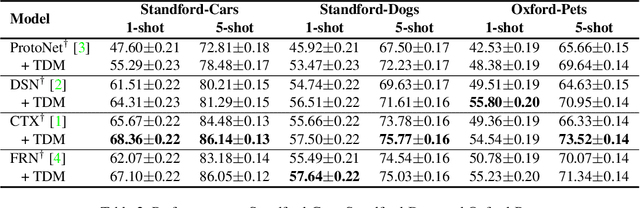
Recognizing discriminative details such as eyes and beaks is important for distinguishing fine-grained classes since they have similar overall appearances. In this regard, we introduce Task Discrepancy Maximization (TDM), a simple module for fine-grained few-shot classification. Our objective is to localize the class-wise discriminative regions by highlighting channels encoding distinct information of the class. Specifically, TDM learns task-specific channel weights based on two novel components: Support Attention Module (SAM) and Query Attention Module (QAM). SAM produces a support weight to represent channel-wise discriminative power for each class. Still, since the SAM is basically only based on the labeled support sets, it can be vulnerable to bias toward such support set. Therefore, we propose QAM which complements SAM by yielding a query weight that grants more weight to object-relevant channels for a given query image. By combining these two weights, a class-wise task-specific channel weight is defined. The weights are then applied to produce task-adaptive feature maps more focusing on the discriminative details. Our experiments validate the effectiveness of TDM and its complementary benefits with prior methods in fine-grained few-shot classification.
* Accepted to CVPR 2022 as an oral presentation. Code is available at https://github.com/leesb7426/CVPR2022-Task-Discrepancy-Maximization-for-Fine-grained-Few-Shot-Classification
Preservational Learning Improves Self-supervised Medical Image Models by Reconstructing Diverse Contexts
Sep 09, 2021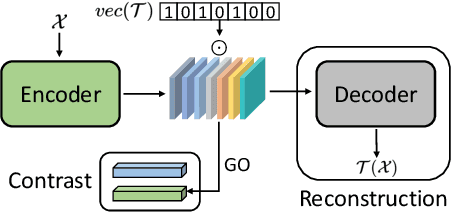
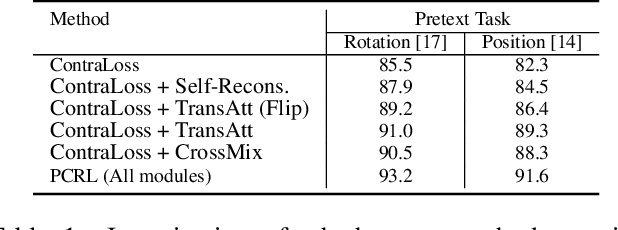
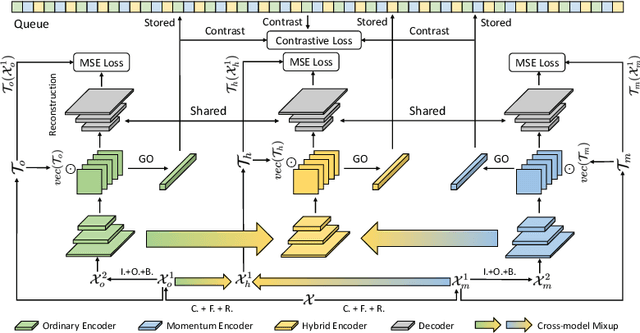
Preserving maximal information is one of principles of designing self-supervised learning methodologies. To reach this goal, contrastive learning adopts an implicit way which is contrasting image pairs. However, we believe it is not fully optimal to simply use the contrastive estimation for preservation. Moreover, it is necessary and complemental to introduce an explicit solution to preserve more information. From this perspective, we introduce Preservational Learning to reconstruct diverse image contexts in order to preserve more information in learned representations. Together with the contrastive loss, we present Preservational Contrastive Representation Learning (PCRL) for learning self-supervised medical representations. PCRL provides very competitive results under the pretraining-finetuning protocol, outperforming both self-supervised and supervised counterparts in 5 classification/segmentation tasks substantially.
TINC: Temporally Informed Non-Contrastive Learning for Disease Progression Modeling in Retinal OCT Volumes
Jun 30, 2022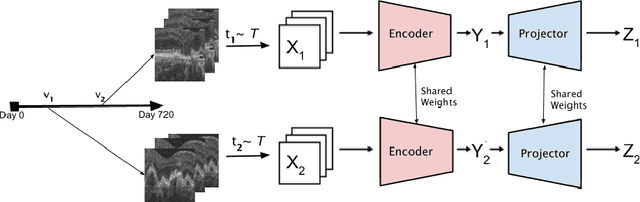

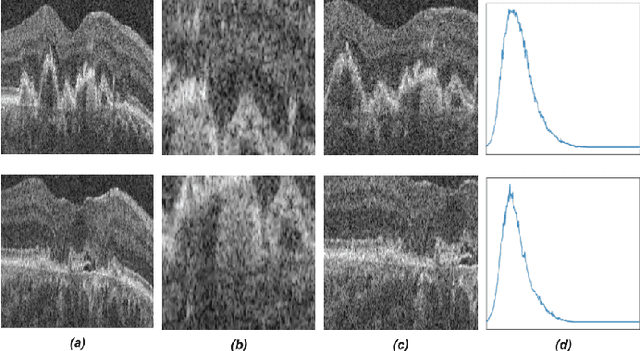

Recent contrastive learning methods achieved state-of-the-art in low label regimes. However, the training requires large batch sizes and heavy augmentations to create multiple views of an image. With non-contrastive methods, the negatives are implicitly incorporated in the loss, allowing different images and modalities as pairs. Although the meta-information (i.e., age, sex) in medical imaging is abundant, the annotations are noisy and prone to class imbalance. In this work, we exploited already existing temporal information (different visits from a patient) in a longitudinal optical coherence tomography (OCT) dataset using temporally informed non-contrastive loss (TINC) without increasing complexity and need for negative pairs. Moreover, our novel pair-forming scheme can avoid heavy augmentations and implicitly incorporates the temporal information in the pairs. Finally, these representations learned from the pretraining are more successful in predicting disease progression where the temporal information is crucial for the downstream task. More specifically, our model outperforms existing models in predicting the risk of conversion within a time frame from intermediate age-related macular degeneration (AMD) to the late wet-AMD stage.
Evolving Image Compositions for Feature Representation Learning
Jun 16, 2021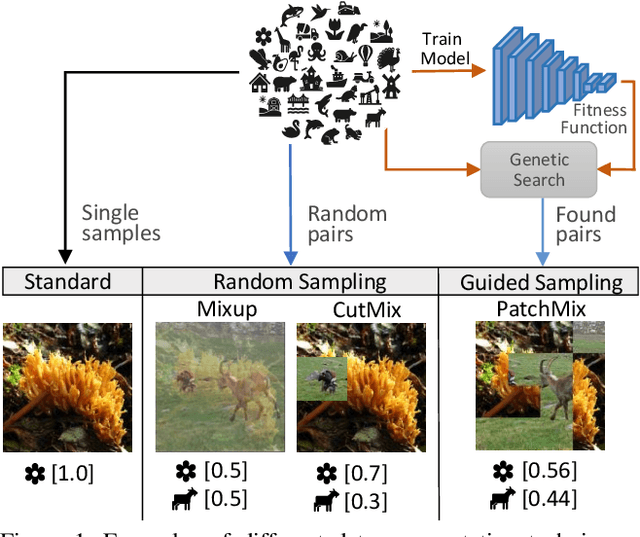
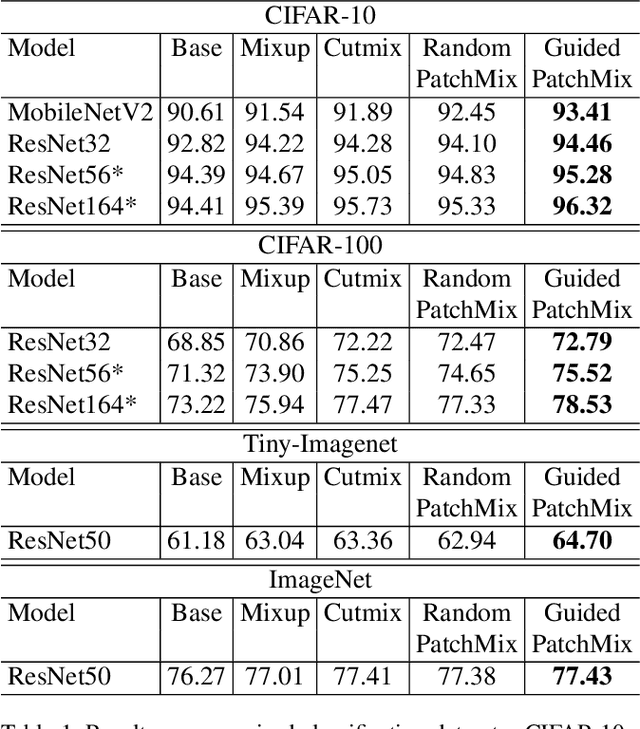
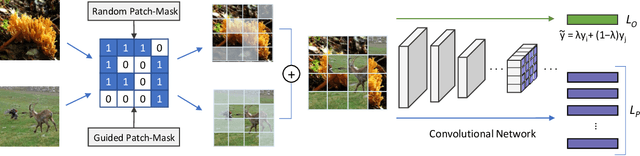
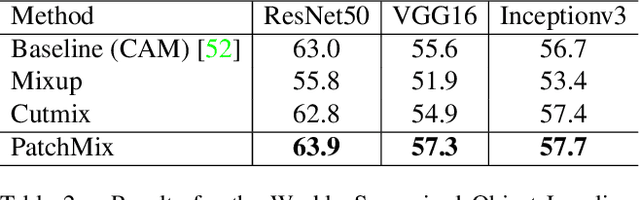
Convolutional neural networks for visual recognition require large amounts of training samples and usually benefit from data augmentation. This paper proposes PatchMix, a data augmentation method that creates new samples by composing patches from pairs of images in a grid-like pattern. These new samples' ground truth labels are set as proportional to the number of patches from each image. We then add a set of additional losses at the patch-level to regularize and to encourage good representations at both the patch and image levels. A ResNet-50 model trained on ImageNet using PatchMix exhibits superior transfer learning capabilities across a wide array of benchmarks. Although PatchMix can rely on random pairings and random grid-like patterns for mixing, we explore evolutionary search as a guiding strategy to discover optimal grid-like patterns and image pairing jointly. For this purpose, we conceive a fitness function that bypasses the need to re-train a model to evaluate each choice. In this way, PatchMix outperforms a base model on CIFAR-10 (+1.91), CIFAR-100 (+5.31), Tiny Imagenet (+3.52), and ImageNet (+1.16) by significant margins, also outperforming previous state-of-the-art pairwise augmentation strategies.
One Loss for Quantization: Deep Hashing with Discrete Wasserstein Distributional Matching
May 31, 2022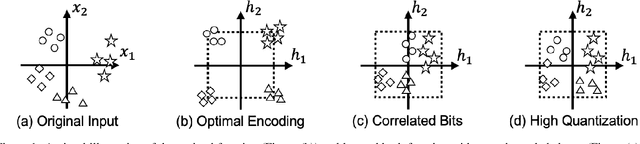
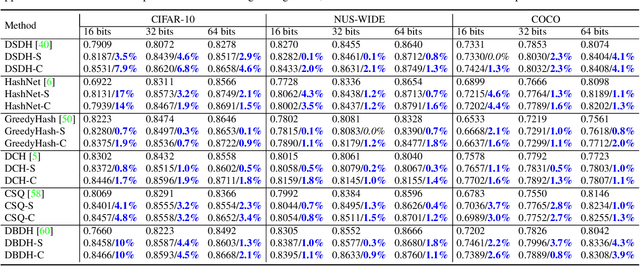
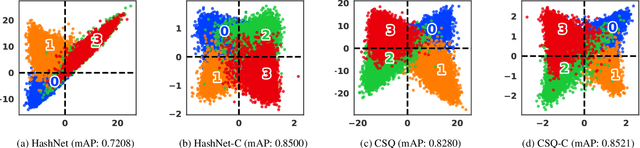
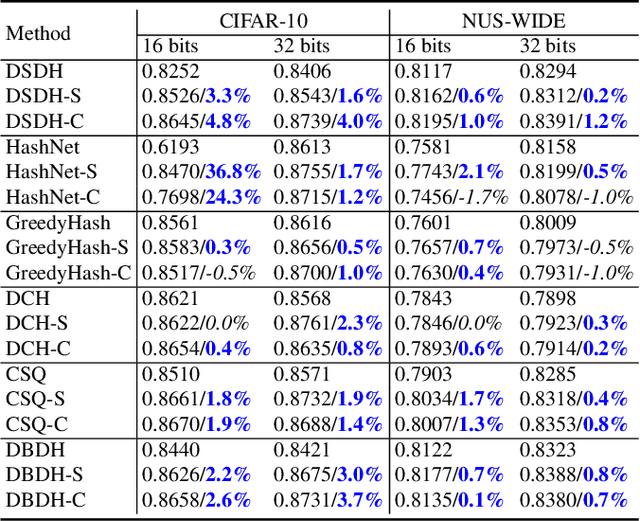
Image hashing is a principled approximate nearest neighbor approach to find similar items to a query in a large collection of images. Hashing aims to learn a binary-output function that maps an image to a binary vector. For optimal retrieval performance, producing balanced hash codes with low-quantization error to bridge the gap between the learning stage's continuous relaxation and the inference stage's discrete quantization is important. However, in the existing deep supervised hashing methods, coding balance and low-quantization error are difficult to achieve and involve several losses. We argue that this is because the existing quantization approaches in these methods are heuristically constructed and not effective to achieve these objectives. This paper considers an alternative approach to learning the quantization constraints. The task of learning balanced codes with low quantization error is re-formulated as matching the learned distribution of the continuous codes to a pre-defined discrete, uniform distribution. This is equivalent to minimizing the distance between two distributions. We then propose a computationally efficient distributional distance by leveraging the discrete property of the hash functions. This distributional distance is a valid distance and enjoys lower time and sample complexities. The proposed single-loss quantization objective can be integrated into any existing supervised hashing method to improve code balance and quantization error. Experiments confirm that the proposed approach substantially improves the performance of several representative hashing~methods.
Game State Learning via Game Scene Augmentation
Jul 04, 2022

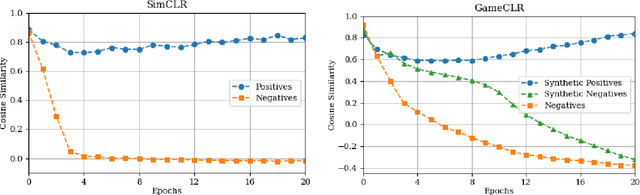
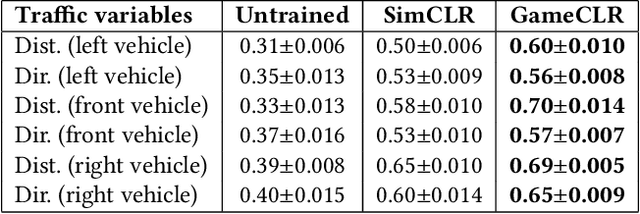
Having access to accurate game state information is of utmost importance for any game artificial intelligence task including game-playing, testing, player modeling, and procedural content generation. Self-Supervised Learning (SSL) techniques have shown to be capable of inferring accurate game state information from the high-dimensional pixel input of game's rendering into compressed latent representations. Contrastive Learning is one such popular paradigm of SSL where the visual understanding of the game's images comes from contrasting dissimilar and similar game states defined by simple image augmentation methods. In this study, we introduce a new game scene augmentation technique -- named GameCLR -- that takes advantage of the game-engine to define and synthesize specific, highly-controlled renderings of different game states, thereby, boosting contrastive learning performance. We test our GameCLR contrastive learning technique on images of the CARLA driving simulator environment and compare it against the popular SimCLR baseline SSL method. Our results suggest that GameCLR can infer the game's state information from game footage more accurately compared to the baseline. The introduced approach allows us to conduct game artificial intelligence research by directly utilizing screen pixels as input.