 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PVO: Panoptic Visual Odometry
Jul 04, 2022
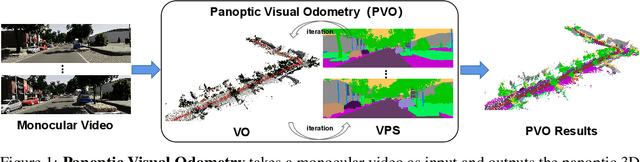
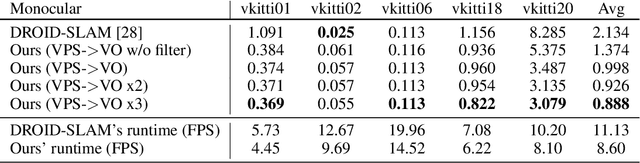
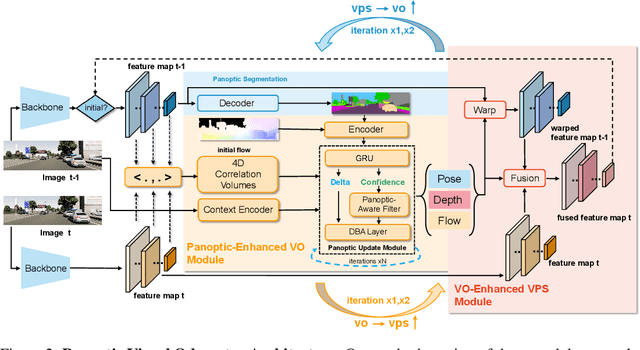

We present a novel panoptic visual odometry framework, termed PVO, to achieve a more comprehensive modeling of the scene's motion, geometry, and panoptic segmentation information. PVO models visual odometry (VO) and video panoptic segmentation (VPS) in a unified view, enabling the two tasks to facilitate each other. Specifically, we introduce a panoptic update module into the VO module, which operates on the image panoptic segmentation. This Panoptic-Enhanced VO module can trim the interference of dynamic objects in the camera pose estimation by adjusting the weights of optimized camera poses. On the other hand, the VO-Enhanced VPS module improves the segmentation accuracy by fusing the panoptic segmentation result of the current frame on the fly to the adjacent frames, using geometric information such as camera pose, depth, and optical flow obtained from the VO module. These two modules contribute to each other through a recurrent iterative optimization. Extensive experiments demonstrate that PVO outperforms state-of-the-art methods in both visual odometry and video panoptic segmentation tasks. Code and data are available on the project webpage: \urlstyle{tt} \textcolor{url_color}{\url{https://zju3dv.github.io/pvo/}}.
SHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Domain Adaptation
Jun 16, 2022
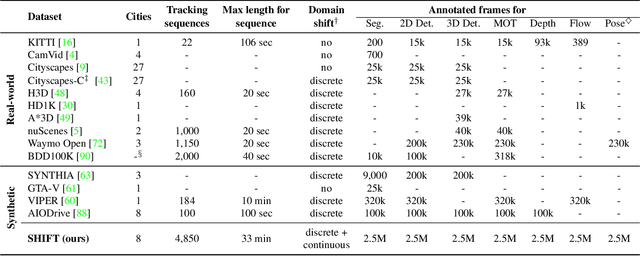
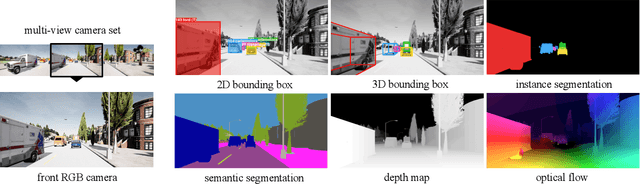

Adapting to a continuously evolving environment is a safety-critical challenge inevitably faced by all autonomous driving systems. Existing image and video driving datasets, however, fall short of capturing the mutable nature of the real world. In this paper, we introduce the largest multi-task synthetic dataset for autonomous driving, SHIFT. It presents discrete and continuous shifts in cloudiness, rain and fog intensity, time of day, and vehicle and pedestrian density. Featuring a comprehensive sensor suite and annotations for several mainstream perception tasks, SHIFT allows investigating the degradation of a perception system performance at increasing levels of domain shift, fostering the development of continuous adaptation strategies to mitigate this problem and assess model robustness and generality. Our dataset and benchmark toolkit are publicly available at www.vis.xyz/shift.
Underwater Image Restoration via Contrastive Learning and a Real-world Dataset
Jun 20, 2021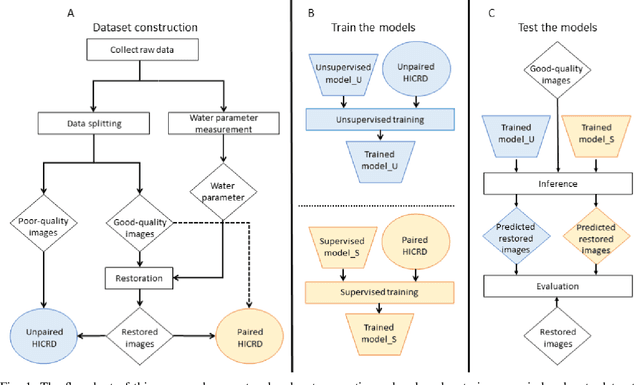
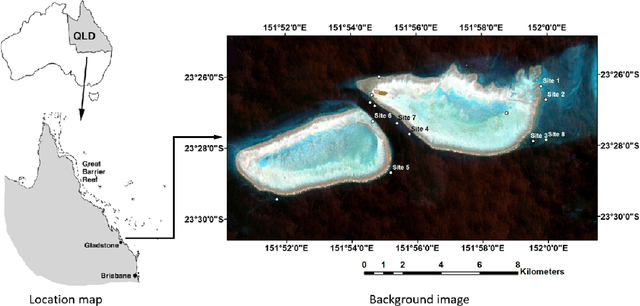
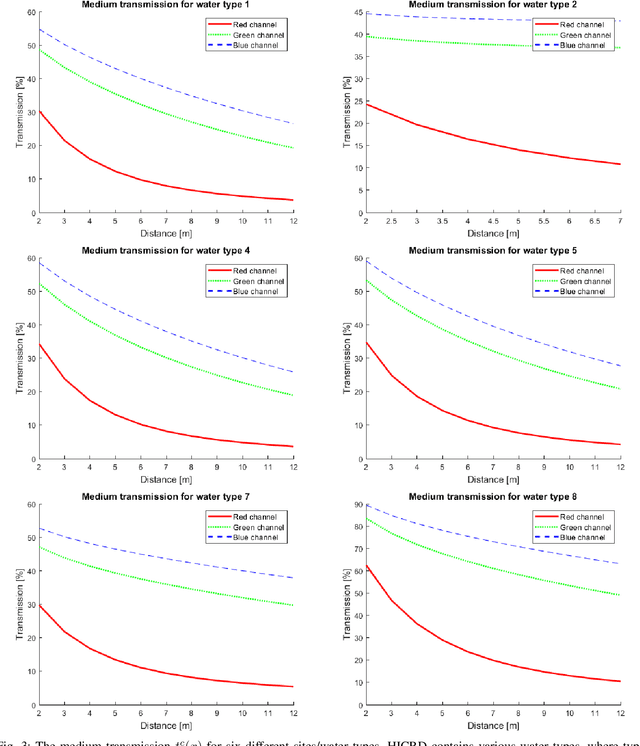
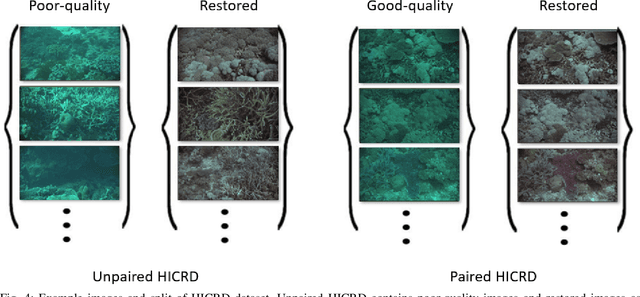
Underwater image restoration is of significant importance in unveiling the underwater world. Numerous techniques and algorithms have been developed in the past decades. However, due to fundamental difficulties associated with imaging/sensing, lighting, and refractive geometric distortions, in capturing clear underwater images, no comprehensive evaluations have been conducted of underwater image restoration. To address this gap, we have constructed a large-scale real underwater image dataset, dubbed `HICRD' (Heron Island Coral Reef Dataset), for the purpose of benchmarking existing methods and supporting the development of new deep-learning based methods. We employ accurate water parameter (diffuse attenuation coefficient) in generating reference images. There are 2000 reference restored images and 6003 original underwater images in the unpaired training set. Further, we present a novel method for underwater image restoration based on unsupervised image-to-image translation framework. Our proposed method leveraged contrastive learning and generative adversarial networks to maximize the mutual information between raw and restored images. Extensive experiments with comparisons to recent approaches further demonstrate the superiority of our proposed method. Our code and dataset are publicly available at GitHub.
High Resolution Solar Image Generation using Generative Adversarial Networks
Jun 07, 2021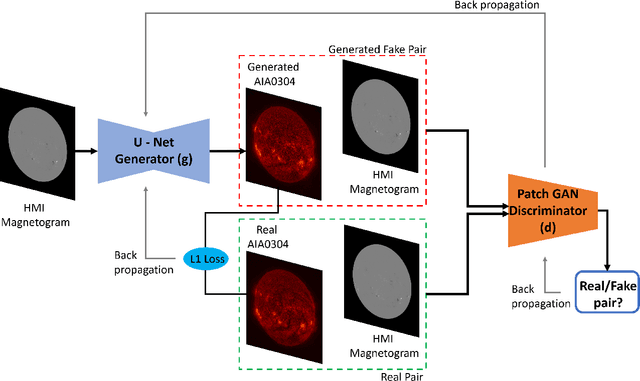
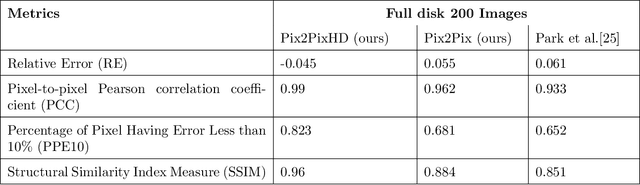
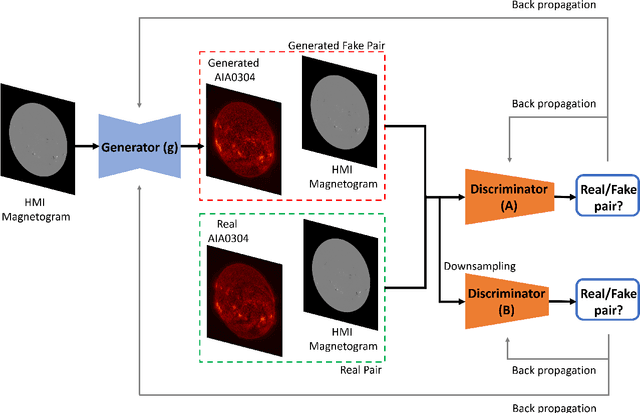

We applied Deep Learning algorithm known as Generative Adversarial Networks (GANs) to perform solar image-to-image translation. That is, from Solar Dynamics Observatory (SDO)/Helioseismic and Magnetic Imager(HMI) line of sight magnetogram images to SDO/Atmospheric Imaging Assembly(AIA) 0304-{\AA} images. The Ultraviolet(UV)/Extreme Ultraviolet(EUV) observations like the SDO/AIA0304-{\AA} images were only made available to scientists in the late 1990s even though the magenetic field observations like the SDO/HMI have been available since the 1970s. Therefore by leveraging Deep Learning algorithms like GANs we can give scientists access to complete datasets for analysis. For generating high resolution solar images we use the Pix2PixHD and Pix2Pix algorithms. The Pix2PixHD algorithm was specifically designed for high resolution image generation tasks, and the Pix2Pix algorithm is by far the most widely used image to image translation algorithm. For training and testing we used the data for the year 2012, 2013 and 2014. The results show that our deep learning models are capable of generating high resolution(1024 x 1024 pixels) AIA0304 images from HMI magnetograms. Specifically, the pixel-to-pixel Pearson Correlation Coefficient of the images generated by Pix2PixHD and original images is as high as 0.99. The number is 0.962 if Pix2Pix is used to generate images. The results we get for our Pix2PixHD model is better than the results obtained by previous works done by others to generate AIA0304 images. Thus, we can use these models to generate AIA0304 images when the AIA0304 data is not available which can be used for understanding space weather and giving researchers the capability to predict solar events such as Solar Flares and Coronal Mass Ejections. As far as we know, our work is the first attempt to leverage Pix2PixHD algorithm for SDO/HMI to SDO/AIA0304 image-to-image translation.
The Mean Dimension of Neural Networks -- What causes the interaction effects?
Jul 11, 2022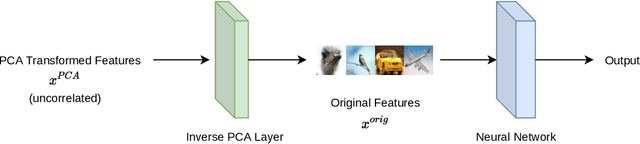

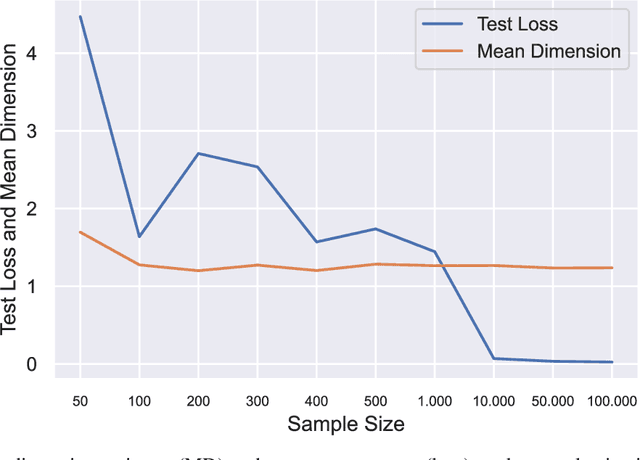
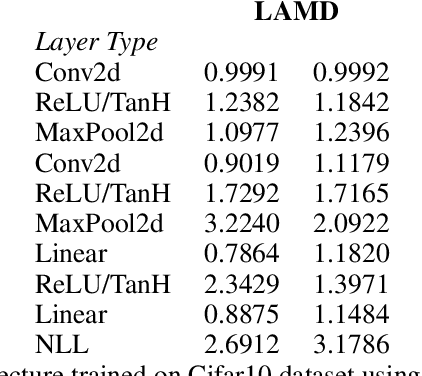
Owen and Hoyt recently showed that the effective dimension offers key structural information about the input-output mapping underlying an artificial neural network. Along this line of research, this work proposes an estimation procedure that allows the calculation of the mean dimension from a given dataset, without resampling from external distributions. The design yields total indices when features are independent and a variant of total indices when features are correlated. We show that this variant possesses the zero independence property. With synthetic datasets, we analyse how the mean dimension evolves layer by layer and how the activation function impacts the magnitude of interactions. We then use the mean dimension to study some of the most widely employed convolutional architectures for image recognition (LeNet, ResNet, DenseNet). To account for pixel correlations, we propose calculating the mean dimension after the addition of an inverse PCA layer that allows one to work on uncorrelated PCA-transformed features, without the need to retrain the neural network. We use the generalized total indices to produce heatmaps for post-hoc explanations, and we employ the mean dimension on the PCA-transformed features for cross comparisons of the artificial neural networks structures. Results provide several insights on the difference in magnitude of interactions across the architectures, as well as indications on how the mean dimension evolves during training.
Your Autoregressive Generative Model Can be Better If You Treat It as an Energy-Based One
Jun 26, 2022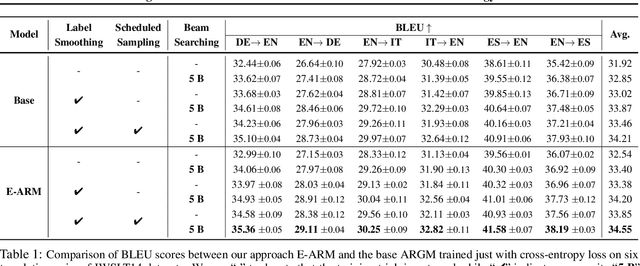
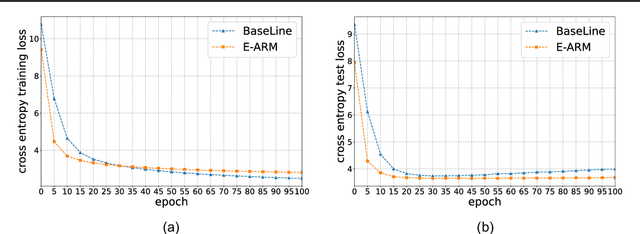

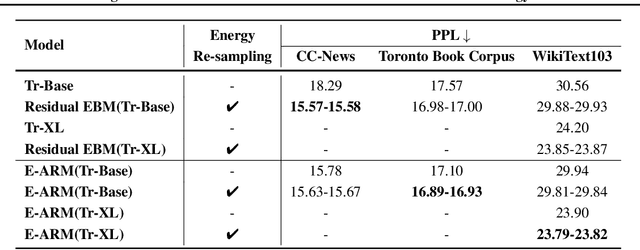
Autoregressive generative models are commonly used, especially for those tasks involving sequential data. They have, however, been plagued by a slew of inherent flaws due to the intrinsic characteristics of chain-style conditional modeling (e.g., exposure bias or lack of long-range coherence), severely limiting their ability to model distributions properly. In this paper, we propose a unique method termed E-ARM for training autoregressive generative models that takes advantage of a well-designed energy-based learning objective. By leveraging the extra degree of freedom of the softmax operation, we are allowed to make the autoregressive model itself be an energy-based model for measuring the likelihood of input without introducing any extra parameters. Furthermore, we show that E-ARM can be trained efficiently and is capable of alleviating the exposure bias problem and increase temporal coherence for autoregressive generative models. Extensive empirical results, covering benchmarks like language modeling, neural machine translation, and image generation, demonstrate the effectiveness of the proposed approach.
Neural Implicit Dictionary via Mixture-of-Expert Training
Jul 08, 2022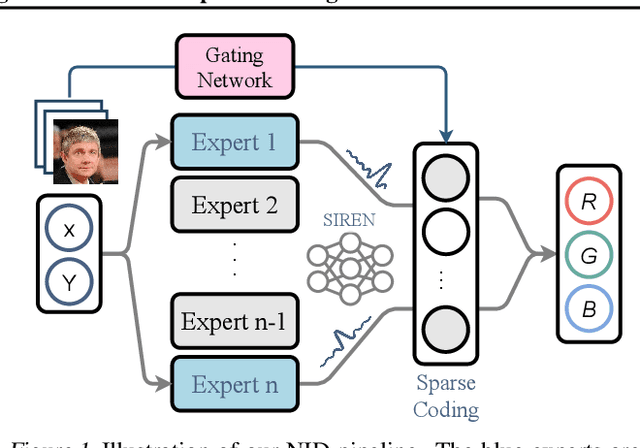
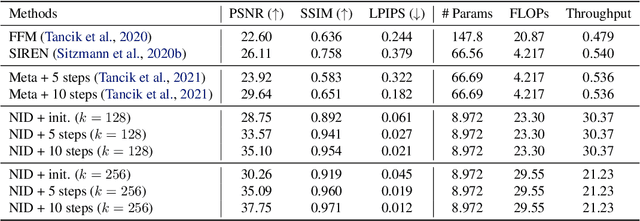

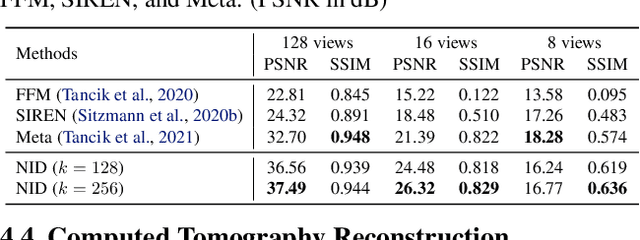
Representing visual signals by coordinate-based deep fully-connected networks has been shown advantageous in fitting complex details and solving inverse problems than discrete grid-based representation. However, acquiring such a continuous Implicit Neural Representation (INR) requires tedious per-scene training on tons of signal measurements, which limits its practicality. In this paper, we present a generic INR framework that achieves both data and training efficiency by learning a Neural Implicit Dictionary (NID) from a data collection and representing INR as a functional combination of basis sampled from the dictionary. Our NID assembles a group of coordinate-based subnetworks which are tuned to span the desired function space. After training, one can instantly and robustly acquire an unseen scene representation by solving the coding coefficients. To parallelly optimize a large group of networks, we borrow the idea from Mixture-of-Expert (MoE) to design and train our network with a sparse gating mechanism. Our experiments show that, NID can improve reconstruction of 2D images or 3D scenes by 2 orders of magnitude faster with up to 98% less input data. We further demonstrate various applications of NID in image inpainting and occlusion removal, which are considered to be challenging with vanilla INR. Our codes are available in https://github.com/VITA-Group/Neural-Implicit-Dict.
Deep Learning for Omnidirectional Vision: A Survey and New Perspectives
May 24, 2022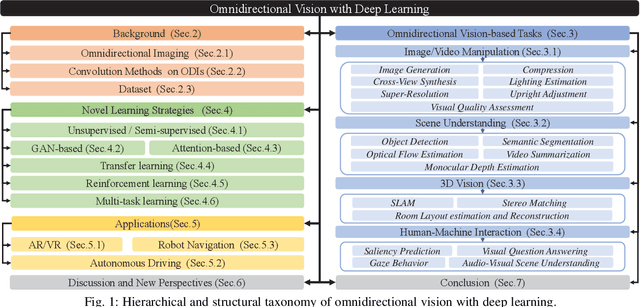
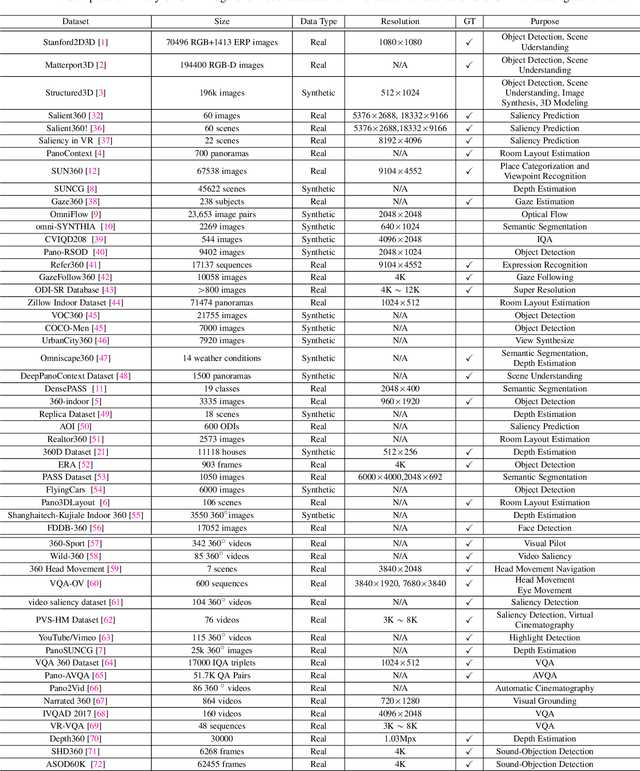


Omnidirectional image (ODI) data is captured with a 360x180 field-of-view, which is much wider than the pinhole cameras and contains richer spatial information than the conventional planar images. Accordingly, omnidirectional vision has attracted booming attention due to its more advantageous performance in numerous applications, such as autonomous driving and virtual reality. In recent years, the availability of customer-level 360 cameras has made omnidirectional vision more popular, and the advance of deep learning (DL) has significantly sparked its research and applications. This paper presents a systematic and comprehensive review and analysis of the recent progress in DL methods for omnidirectional vision. Our work covers four main contents: (i) An introduction to the principle of omnidirectional imaging, the convolution methods on the ODI, and datasets to highlight the differences and difficulties compared with the 2D planar image data; (ii) A structural and hierarchical taxonomy of the DL methods for omnidirectional vision; (iii) A summarization of the latest novel learning strategies and applications; (iv) An insightful discussion of the challenges and open problems by highlighting the potential research directions to trigger more research in the community.
Defending Against Image Corruptions Through Adversarial Augmentations
Apr 02, 2021
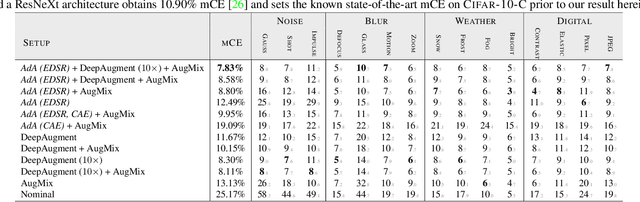
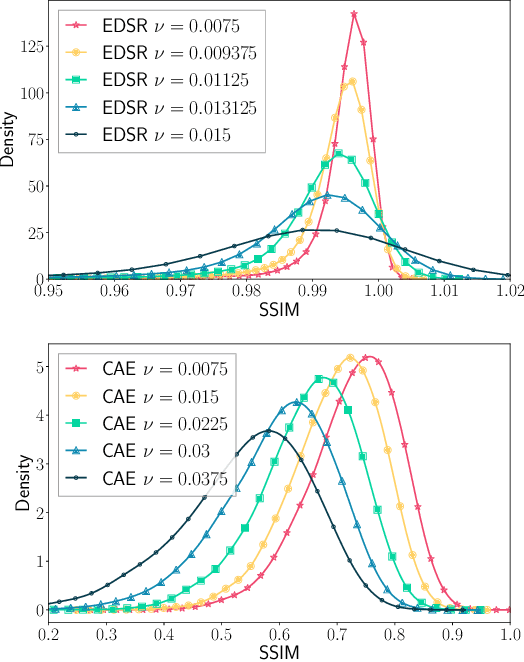
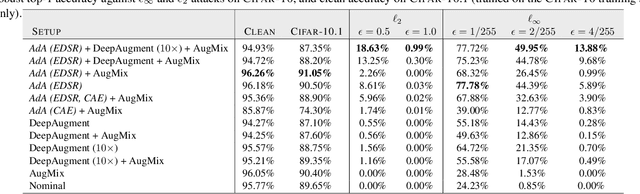
Modern neural networks excel at image classification, yet they remain vulnerable to common image corruptions such as blur, speckle noise or fog. Recent methods that focus on this problem, such as AugMix and DeepAugment, introduce defenses that operate in expectation over a distribution of image corruptions. In contrast, the literature on $\ell_p$-norm bounded perturbations focuses on defenses against worst-case corruptions. In this work, we reconcile both approaches by proposing AdversarialAugment, a technique which optimizes the parameters of image-to-image models to generate adversarially corrupted augmented images. We theoretically motivate our method and give sufficient conditions for the consistency of its idealized version as well as that of DeepAugment. Our classifiers improve upon the state-of-the-art on common image corruption benchmarks conducted in expectation on CIFAR-10-C and improve worst-case performance against $\ell_p$-norm bounded perturbations on both CIFAR-10 and ImageNet.
Task Discrepancy Maximization for Fine-grained Few-Shot Classification
Jul 04, 2022
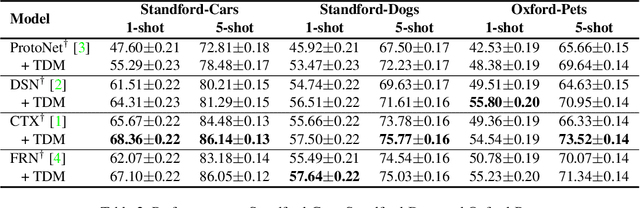
Recognizing discriminative details such as eyes and beaks is important for distinguishing fine-grained classes since they have similar overall appearances. In this regard, we introduce Task Discrepancy Maximization (TDM), a simple module for fine-grained few-shot classification. Our objective is to localize the class-wise discriminative regions by highlighting channels encoding distinct information of the class. Specifically, TDM learns task-specific channel weights based on two novel components: Support Attention Module (SAM) and Query Attention Module (QAM). SAM produces a support weight to represent channel-wise discriminative power for each class. Still, since the SAM is basically only based on the labeled support sets, it can be vulnerable to bias toward such support set. Therefore, we propose QAM which complements SAM by yielding a query weight that grants more weight to object-relevant channels for a given query image. By combining these two weights, a class-wise task-specific channel weight is defined. The weights are then applied to produce task-adaptive feature maps more focusing on the discriminative details. Our experiments validate the effectiveness of TDM and its complementary benefits with prior methods in fine-grained few-shot classification.
* Accepted to CVPR 2022 as an oral presentation. Code is available at https://github.com/leesb7426/CVPR2022-Task-Discrepancy-Maximization-for-Fine-grained-Few-Shot-Classification